Исследуйте безграничные возможности технологии Retrival Enhanced Generation (RAG): Vector+KG RAG, Self-RAG, интеграция многовекторного ретривера и мультимодальной RAG.
Исследуйте безграничные возможности технологии Retrival Enhanced Generation (RAG): Vector+KG RAG, Self-RAG, интеграция многовекторного ретривера и мультимодальной RAG.
Потому что вся идея RAG заключается в том, чтобы сначала разбить текст на разные куски, а затем сохранить их в векторной базе данных. При фактическом использовании будет рассчитано сходство между вопросом пользователя и текстовым блоком, и будут вызваны первые k фрагментов и вопросы, которые будут объединены для генерации слов-подсказок и ввода в большую модель. и наконец ответ будет получен.
Точки оптимизации:
- оптимизация Как сегментировать текст,Размер фрагмента и размер перекрытия являются настраиваемыми параметрами.
- многочастный отзыв,При извлечении можно использовать куски меньшей длины.,Затем используйте фрагменты большей длины, чтобы получить более полную контекстную информацию при вводе в большую модель.
- оптимизациявектор Модель,Используйте высокопроизводительные векторы Модель,Например, bge, который мы сейчас используем,Возможность тонкой настройки векторной модели позволяет добиться лучших результатов.
- Добавить изменение порядка,Векторная модель запоминает большее количество фрагментов,Затем используйте Модель переупорядочения, чтобы отфильтровать меньшее количество фрагментов и ограничить подсказки.
- Подскажите слово оптимизация,Добавление соответствующих ограничений на слова подсказки может сделать выходные результаты Da Model более стабильными.,более высокое качество
Оптимизация RAG делится на два направления: оптимизация основных функций RAG и оптимизация архитектуры RAG. О них мы поговорим отдельно.
1.Оптимизация основных функций RAG.
Чтобы оптимизировать основные функции RAG, нам нужно начать с процесса RAG [1], и на каждом этапе мы можем выполнить соответствующую оптимизацию сцены.
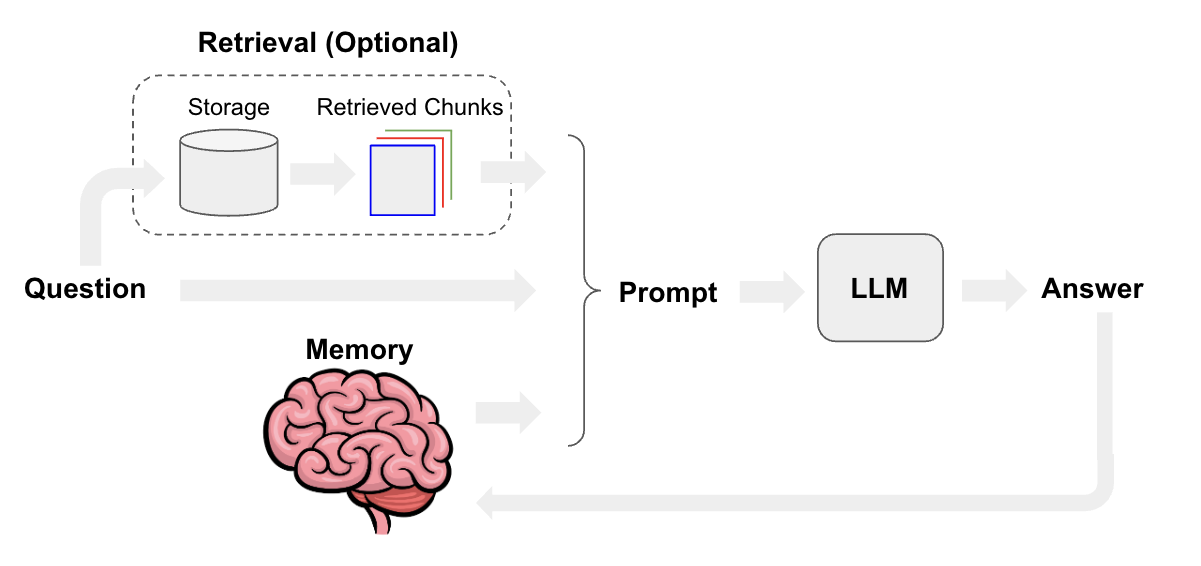
В рабочем процессе RAG можно оптимизировать следующие модули: сегментацию блоков документов, модель внедрения текста, оптимизацию оперативного проектирования и итерацию большой модели. Ниже приводится отдельное описание каждого модуля.
- Разбиение документа на части:Установите соответствующее перекрытие между блоками, сегментацию блоков документов с различной степенью детализации, сегментацию документов на основе семантики, суммирование блоков документов.。
- Встраивание текста Модель: на основе нового корпуса, тонкая настройка встраивания Модель, динамическое представление.
- Быстрая оптимизация проекта: шаблон оптимизации добавляет ограничения на подсказки и возможность быстрого переписывания слов.
- Итерация большой модели: на на основе Положительная обратная связь Модель тонкой настройки, количественная тренировка восприятия, обеспечивающая большие context window Рассуждения Модели.
Кроме того, также может быть обработана коллекция блоков документов, вызванных запросом, например, фильтрация метаданных [7] и переупорядочение для уменьшения количества блоков документов [2].
2.Оптимизация архитектуры RAG
2.1 Vector+KG RAG
В классической архитектуре RAG для улучшения контекста используются только векторные базы данных. Этот метод имеет некоторые недостатки, такие как невозможность получения сопутствующих знаний на большие расстояния [3] и низкая плотность информации.
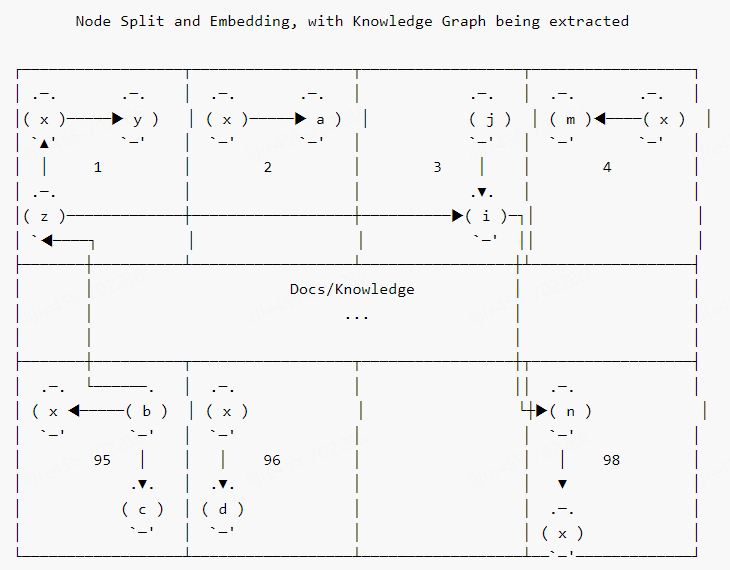
Решаема ли эта проблема? Ответ: да. Лучшее решение — добавить KG (стратегию улучшения контекста [Knowledge Graph]) параллельно с векторной библиотекой. Схема ее технической архитектуры примерно следующая [4]:

На рисунке 3 расширение запроса KG реализовано с помощью модуля NL2Cypher. Согласно моей практике, мы можем использовать более простую [технологию выборки графов] для улучшения контекста KG. Конкретный процесс: извлечение объектов в соответствии с запросом, а затем использование объектов в качестве начальных узлов для выборки графа (при необходимости узлы в KG и объекты в запросе могут быть сначала векторизованы, а начальные узлы устанавливаются через [сходство векторов] ]), а затем полученные фрагменты изображений преобразуются в текстовые фрагменты для достижения контекстно-улучшенных эффектов.
На официальном сайте LangChain представлен пример DevOps улучшения приложений RAG с помощью Graph. Заинтересованные читатели могут изучить его подробно [5].
2.2 Self-RAG
В классической архитектуре RAG (включая KG для улучшения контекста) вызванный контекст без разбора объединяется с запросом, а затем осуществляется доступ к большой модели для вывода ответа. Но иногда вызванный контекст может быть неактуален или противоречить запросу. В этом случае контекст следует отбросить, особенно когда окно контекста большой модели маленькое (сейчас чаще встречаются окна 4k).
Есть ли решение? Ответ снова положительный, лучшее решение — технология Self-RAG. Из-за ограничений места здесь представлен процесс рассуждения. Процесс обучения требует помощи GPT4 для вспомогательной разметки, поэтому я не буду вдаваться в подробности. Подробное описание процесса можно найти в моем кратком изложении Self-RAG [6].
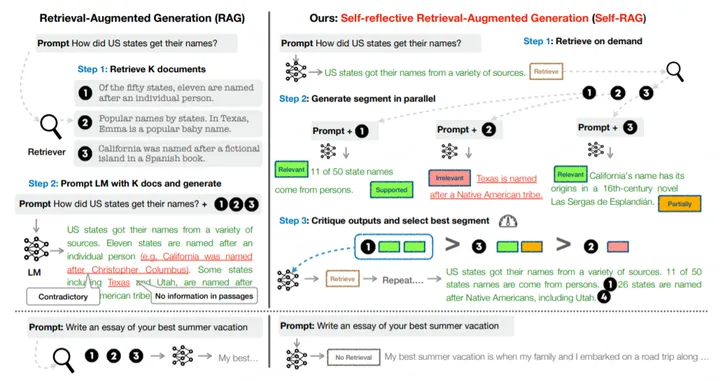
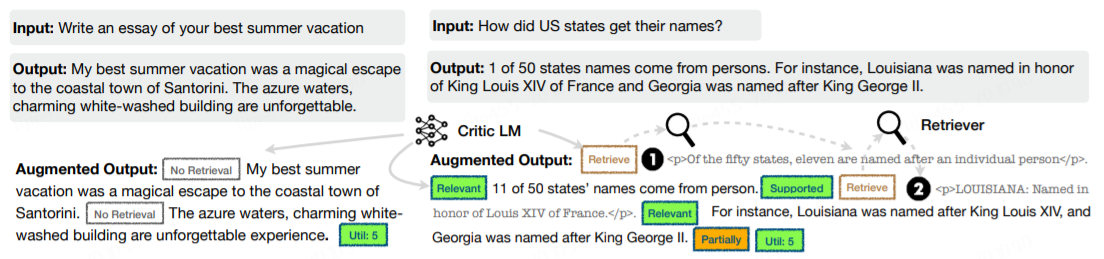
Как показано на рисунке 4, правая часть — это рабочий процесс Self-RAG. Сначала определите, требуется ли извлечение на основе запроса. При необходимости извлекаются несколько отрывков, а затем посредством серии процессов генерируются несколько кандидатов [следующего сегмента]. Наконец, эти сегменты-кандидаты сортируются для создания последнего следующего сегмента.
Процесс вывода Self-RAG относительно прост в обучении, и его алгоритмическое содержание следующее:

Входные данные для процесса рассуждения: подсказка
и заранее сгенерированные
, выходом является сегмент следующего временного шага
. Обратите внимание, что задачей генерации здесь является детализация сегментов, а не детализация токенов, в основном из соображений производительности вычислений.
Во-первых, [Языковая модель] M прогнозирует значение токена получения. Если нет, стандартная парадигма языковой модели определяется выражением
генерировать
,когда
Сборка завершена или прибыла
, затем спрогнозируйте значение токена IsUSE. Если параметр «Получить токен» имеет значение «Да», через Retriever извлекается несколько контекстов, представленных D. Для каждого контекста d сначала спрогнозируйте значение токена IsREL, чтобы выразить, связаны ли контекст и приглашение одновременно, сгенерируйте сегмент следующего временного шага;
. Затем предскажите пары контекста d
Степень поддержки, а затем результат, соответствующий каждому d
Сортируйте и выбирайте лучшие. подожди последнего
В конце генерации прогнозируется значение IsUSE.
2.3 Многовекторный ретривер, мультимодальная RAG
Этот раздел включает в себя три режима работы [7], а именно:
- полуструктурированный ТРЯПКА (текст + лист)
- мультимодальный ТРЯПКА (текст + лист + картинакусок)
- Приватизациямультимодальный ТРЯПКА (текст + лист + картинакусок)
1) Полуструктурированный РЭГ (текст + таблица)
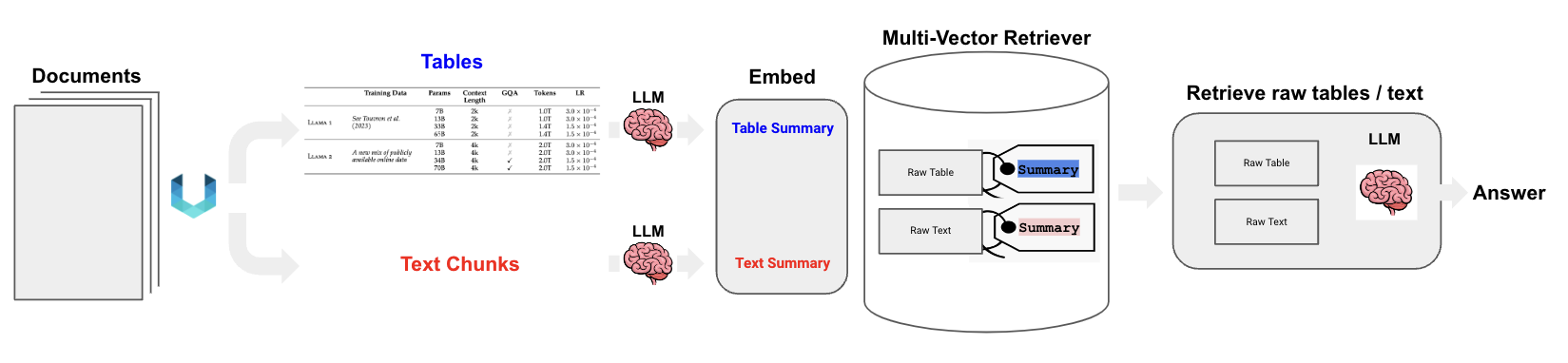
Этот режим обрабатывает как текстовые, так и табличные данные. Его основной процесс резюмируется следующим образом [8]:
- Провести анализ макета исходного документа (на основе Unstructured инструмент [9]),генерироватьисходный текст и оригинальныйлист。
- Исходный текст и исходный лист обрабатываются резюме LLM, ограничивать текстовое резюме илист резюме.
- Используйте тот же самый embedding Модель поместила текст summary илист summary Векторизуется и сохраняется в многовекторном ретривере.
- Многовекторный ретривер хранит текст / лист embedding В то же время соответствующий summary и raw data。
- пользователь query После векторизации используйте ANN Поиск отзыва raw text и raw table。
- в соответствии с query+raw text+raw table Полная структура подскажите, посетите LLM думать о конечном результате.
2) Мультимодальный РАГ (текст+таблица+картинка)
Для мультимодальной РАГ существуют три технических маршрута [10], как показано на рисунке ниже:
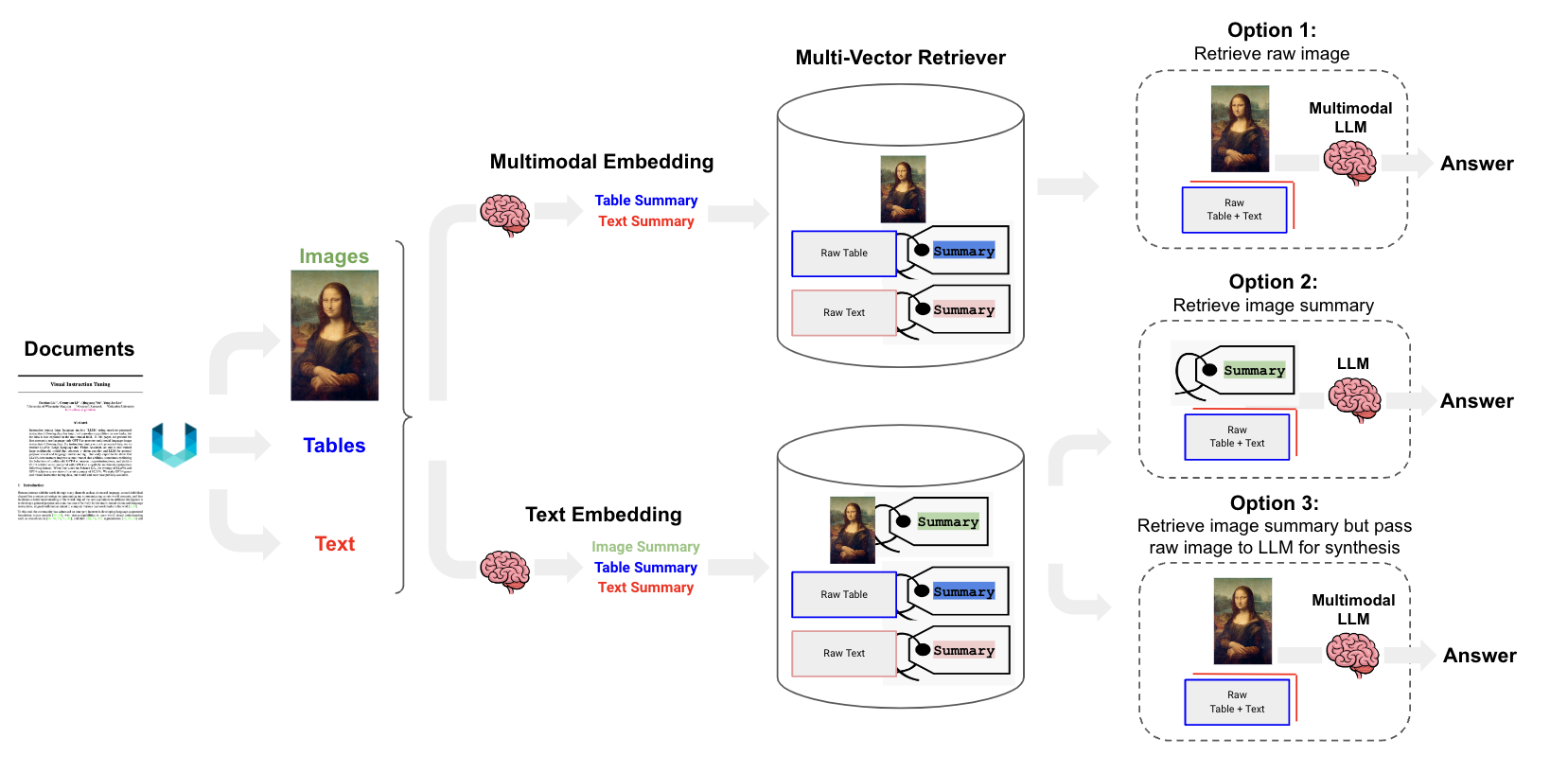
Как показано на рисунке 7, существует три технических маршрута для мультимодальной RAG. Ниже мы дадим краткое объяснение:
- Параметры 1:вернотекстилистгенерировать summary,затем подайте заявкумультимодальный embedding Модель поместила текст / лист Итого: исходный фрагмент изображения преобразуется в embedding Магазин многовекторного ретривера. правда, когда говоришь, в соответствии с query Вспомнить исходный текст / лист / как картина. Затем скормите его мультимодальному LLM Оценить результаты ответа.
- Параметр 2: сначала примените мультимодальную большую модель (GPT4-V、LLaVA、FUYU-8b)генерироватькартинакусок краткое содержание. а затем к тексту / лист / картинакусок summary руководить векторизованным хранилищем в многовекторном ретривере середина. Если соответствующая мультимодальная большая модель ограничения недоступна, ее можно соответствии с query Вспомнить исходный текст / лист + картинакусок summary。
- Параметры 3: Предварительный этап такой же, как и параметры. 2 такой же. Верно, , соответствии с query Вспомнить исходный текст / лист / картинакусок。Полная структура Prompt,доступмультимодальныйбольшой Модель Оценить результаты ответа.
3) Частный мультимодальный РЭГ (текст+таблица+картинка)
Если безопасность данных является важным фактором, то конвейер RAG необходимо развернуть локально. Например, LLaVA-7b можно использовать для создания сводок изображений, Chroma используется в качестве векторной базы данных, GPT4All от Nomic используется в качестве модели встраивания с открытым исходным кодом, многовекторного поисковика, а LLaMA2-13b-чат в Ollama.ai используется для генерации ответов [11].
3. Подробное объяснение Self-RAG
Я думал над двумя вопросами: один из них: необходимо ли вызывать контекст через векторную библиотеку каждый раз, когда делается запрос. Во-вторых, используемое нами контекстное окно вывода LLM не будет слишком большим (например, Baichuan2-7B/13B имеет только 4096, модель большого окна Baichuan2-192k, GPT-4 Turbo 128k и Zero-One-Whole Yi с 200k). размер окна получить нелегко), каждый запрос вызывает большой список контекстов, чтобы проверить, подойдет ли он. После расследования выделяются два направления, достойные углубленного изучения:
- Если исходить из того, что извлечение контекста необходимо, на основе KG можно вызвать контекст с высокой плотностью информации.
- Благодаря технологии Self-RAG контекст можно получать по требованию и одновременно оценивать самостоятельно.
3.1 Сценарии применения
Типичное приложение RAG будет без разбора обращаться к векторной библиотеке для получения контекста, независимо от того, действительно ли это необходимо. Это может привести к появлению контекста, не относящегося к теме, что приведет к низкому качеству текстового контента. Причина этого заключается в том, что LLM вывода не выполняет адаптивное обучение контексту, чтобы генерируемые результаты соответствовали контекстной семантике. Как показано в левом примере рисунка 1, контекст поиска может привести к возникновению противоречивых точек зрения.
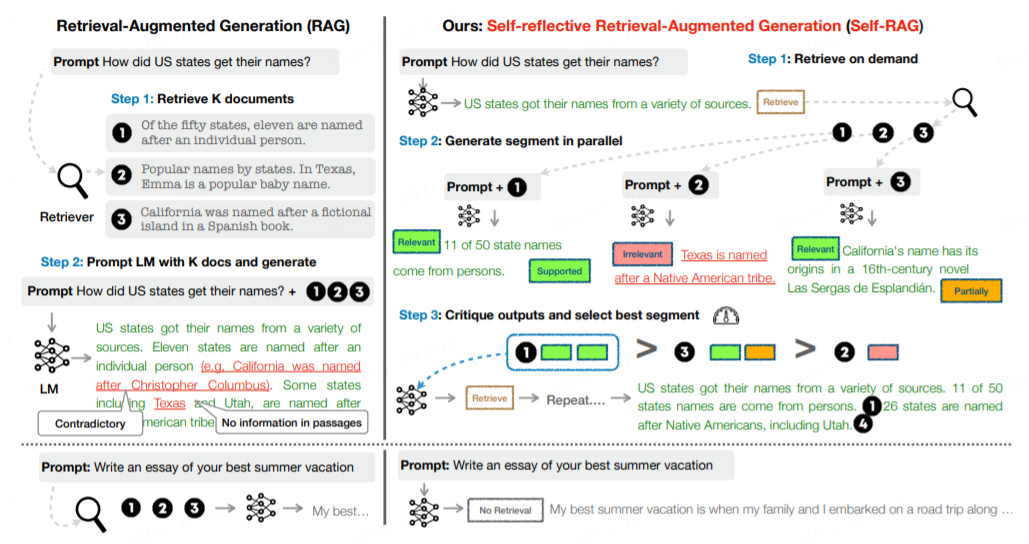
Self-RAG в правой части рисунка 1 может эффективно решить проблему недифференцированного контекста поиска в RAG. Его общий принцип таков:
- предсказывать prompt Нужен ли контекст для улучшения текста, ограничивать результаты. При необходимости отметьте специальный retrieval token,В то же время в соответствии с Нужно позвонить retriever модуль.
- Параллельно обрабатывайте полученный контекст и оценивайте пары контекстов. prompt корреляция,в то же времягенерироватьсоответствующие результаты。
- Оцените степень поддержки соответствующего результата в каждом контексте.,Также выберите лучший результат.
Приведенное выше описание алгоритма включает в себя ряд специальных токенов, конкретное значение которых следующее:

Как показано на рисунке 2, в Self-RAG есть четыре типа жетонов отражения, которые условно разделены на две категории: «Извлечение» и «Критика». Среди них Critique разделен на три подкатегории: IsREL, IsSUP и IsUSE. Жирный шрифт указывает ожидаемую ценность токена определенного типа.
3.2 Модельное обоснование
В первом разделе кратко обобщается принцип работы Self-RAG с точки зрения сценариев применения. В этом разделе подробно анализируется процесс рассуждения Self-RAG. Приведем непосредственно алгоритм вывода следующим образом:

Входные данные для процесса рассуждения: подсказка
x и заранее сгенерированные
, выходом является сегмент следующего временного шага
. Обратите внимание, что задачей генерации здесь является детализация сегментов, а не детализация токенов, в основном из соображений производительности вычислений.
Во-первых, значение токена получения прогнозируется языковой моделью M. Если нет, стандартная парадигма языковой модели определяется выражением
генерировать
,когда
завершить или прибыть
, затем спрогнозируйте значение токена IsUSE. Если параметр «Получить токен» имеет значение «Да», через Retriever извлекается несколько контекстов, представленных D. Для каждого контекста d сначала спрогнозируйте значение токена IsREL, чтобы выразить, связаны ли контекст и приглашение одновременно, сгенерируйте сегмент следующего временного шага;
. Затем предскажите пары контекста d
Степень поддержки, а затем результат, соответствующий каждому d
Сортируйте и выбирайте лучшие. подожди последнего
yгенерировать Заканчиватькогда, предскажи еще раз IsUSE ценить.
Вывод самооценки через токен отражения,Может сделать процесс рассуждения Da Model более управляемым.,от И настройте его поведение так, чтобы оно соответствовало требованиям нескольких сценариев.
3.2.1 Адаптивный поиск
Self-RAG предсказывать retrieve token чтобы динамически решать, следует ли получать контекст. В статье середина указывается, что порог может быть задан, когдаRetieve=Да Когда нормализованная вероятность превышает порог, срабатывает действие получения контекста.
3.2.2 Декодирование дерева на основе токена критики
в каждом segment step т, если его нужно будет получить, он будет получен K контекст. В статье предлагается метод, основанный на segment Стратегия поиска луча (beam поиск), это луч_размер=Б. Так каждый временной шаг т, мы можем получить top-B segment кандидата и получить лучшее в конце segment последовательность. на временном шаге t когда каждый контекст d Соответствующий segment Формула расчета баллов выглядит следующим образом:
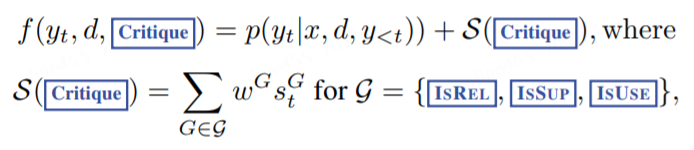
картина 4 в G представлять critique token группа, например ИЗРАИЛЬ. на временном шаге t Когда, Г. оценка за
, самый желанный знак отражения
относительно
разные ценности critique token type G вероятностное значение. картина 4 в
Его можно настроить во время вывода, чтобы настроить поведение процесса тестирования. Например, для пусть
В значительной степени поддержанный контекстом, это может быть дано IsSUP больший вес, придавая другим token Меньший вес, это мягкая линия управления. Путем установки на этапе декодирования критика, мы также можем добавить жесткий контроль, как для. Например, когда большая Модельгенерировать неожиданную token когда (IsSUP=Нет поддержка), вы можете отказаться от Соответствующий segment кандидат.
3.3 Обучение модели
Self-RAG Процесс обучения состоит из двух моделей: Критик и Генератор. Первый основан на вводе x и вывод y, условноть знак отражения р. Затем мы можем использовать Critic Модель создает новый набор данных (используя автономный метод для записи маркеров отражения в исходный набор данных) и на основе входных данных. x,Приходитьпредсказыватьвыход y и знак отражения r。
3.3.1 Critic model
При использовании ручного метода для каждого segment Маркировка reflection жетон, это потребует много работы. Поскольку определение, ввод и вывод каждого отражающего знака различны, в этой статье используется GPT-4 для Каждая отражающая метка устанавливает разные данные команды и завершает работу по Маркировке. к Retrieve дляпример , мы можем построить определенный тип данных инструкций, а затем следовать few-shot Образец Я, исходный ввод x и вывод y, мы предскажем подходящую отметку для размышления.
。на Основа Эта идея может для каждого размышления отметить особо 4k~20k полоски размеченных данных, и в целом они Critic model данные обучения.
Получив данные обучения, мы можем построить цель обучения на основе стандартной модели условного языка следующим образом:
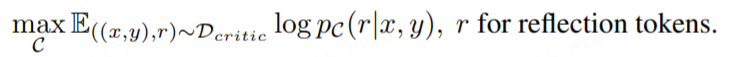
В статье отмечается, что модель Critic может быть инициализирована с помощью любой языковой модели, поэтому для инициализации используется та же модель, что и Generator.
3.3.2 Generator model
Учитывая исходные данные x и вывод да, мы можем использовать ретривер и Critic model Выполните увеличение данных. для каждого segment
доступный Critic model Оцените, необходим ли контекст поиска для улучшения качества текста. Если требуется процесс извлечения, установите Retrive=Да, одновременно запустите ретривер, чтобы получить K контекст. Для каждого контекста Критик model судить об этом x Актуально ли это и предсказать IsREL token ценить. если это связано, то используйте Critic model Далее оцените, поддерживает ли контекст Модельгенерировать контент и предсказывать. IsSUP Далее ценить. IsREL и IsSUP ставить в контекст или считать segment позже. когда завершено y Критик в конце книги model Общая доступность предсказывать token IsUSE. Таким образом, разметка отражения интегрируется в исходный вывод. + Исходные входные данные формируют обучение Generator model расширенные данные. Этот процесс можно описать ниже:
Имея обучающие данные, мы можем построить стандартную следующую отметку, предопределяющую целевую функцию, следующим образом:

Здесь необходимо отметить: Генератор Не только предсказывать вывод, но и предсказать разметку отражения. На этапе обучения нам необходимо получить контекст (картина 6 Китайское использование и прилагаемый контент) и действуйте следующим образом loss рассчитать. Также добавьте маркеры отражения в исходный глоссарий. Критика, Извлечение, для расширения словарного запаса.
4.Справочные материалы
- https://www.zhihu.com/question/628651389/answer/3321989558
- Chatbots | ️ Langchain
- Rerankers and Two-Stage Retrieval | Pinecone
- Custom Retriever combining KG Index and VectorStore Index
- Enhanced QA Integrating Unstructured Knowledge Graph Using Neo4j and LangChain
- https://blog.langchain.dev/using-a-knowledge-graph-to-implement-a-devops-rag-application/
- Преследователь ИИ: раскрываем внутреннюю историю технологии Self-RAG
- Multi-Vector Retriever for RAG on tables, text, and images:Multi-Vector Retriever for RAG on tables, text, and images
- https://github.com/langchain-ai/langchain/blob/master/cookbook/Semi_Structured_RAG.ipynb?ref=blog.langchain.dev
- Unstructured | The Unstructured Data ETL for Your LLM
- https://github.com/langchain-ai/langchain/blob/master/cookbook/Semi_structured_and_multi_modal_RAG.ipynb?ref=blog.langchain.dev
- https://github.com/langchain-ai/langchain/blob/master/cookbook/Semi_structured_multi_modal_RAG_LLaMA2.ipynb?ref=blog.langchain.dev



Учебное пособие по Jetpack Compose для начинающих, базовые элементы управления и макет

Код js веб-страницы, фон частицы, код спецэффектов

【новый! Суперподробное】Полное руководство по свойствам компонентов Figma.

🎉Обязательно к прочтению новичкам: полное руководство по написанию мини-программ WeChat с использованием программного обеспечения Cursor.

[Забавный проект Docker] VoceChat — еще одно приложение для мгновенного чата (IM)! Может быть встроен в любую веб-страницу!

Как реализовать переход по странице в HTML (html переходит на указанную страницу)

Как решить проблему зависания и низкой скорости при установке зависимостей с помощью npm. Существуют ли доступные источники npm, которые могут решить эту проблему?

Серия From Zero to Fun: Uni-App WeChat Payment Practice WeChat авторизует вход в систему и украшает страницу заказа, создает интерфейс заказа и инициирует запрос заказа

Серия uni-app: uni.navigateЧтобы передать скачок значения

Апплет WeChat настраивает верхнюю панель навигации и адаптируется к различным моделям.

JS-время конвертации

Обеспечьте бесперебойную работу ChromeDriver 125: советы по решению проблемы chromedriver.exe не найдены

Поле комментария, щелчок мышью, специальные эффекты, js-код

Объект массива перемещения объекта JS

Как открыть разрешение на позиционирование апплета WeChat_Как использовать WeChat для определения местонахождения друзей

Я даю вам два набора из 18 простых в использовании фонов холста Power BI, так что вам больше не придется возиться с цветами!

Получить текущее время в js_Как динамически отображать дату и время в js

Вам необходимо изучить сочетания клавиш vsCode для форматирования и организации кода, чтобы вам больше не приходилось настраивать формат вручную.

У ChatGPT большое обновление. Всего за 45 минут пресс-конференция показывает, что OpenAI сделал еще один шаг вперед.

Copilot облачной разработки — упрощение разработки

Микросборка xChatGPT с низким кодом, создание апплета чат-бота с искусственным интеллектом за пять шагов

CUDA Out of Memory: идеальное решение проблемы нехватки памяти CUDA

Анализ кластеризации отдельных ячеек, который должен освоить каждый&MarkerгенетическийВизуализация

vLLM: мощный инструмент для ускорения вывода ИИ

CodeGeeX: мощный инструмент генерации кода искусственного интеллекта, который можно использовать бесплатно в дополнение к второму пилоту.

Машинное обучение Реальный бой LightGBM + настройка параметров случайного поиска: точность 96,67%

Бесшовная интеграция, мгновенный интеллект [1]: платформа больших моделей Dify-LLM, интеграция без кодирования и встраивание в сторонние системы, более 42 тысяч звезд, чтобы стать свидетелями эксклюзивных интеллектуальных решений.

LM Studio для создания локальных больших моделей

Как определить количество слоев и нейронов скрытых слоев нейронной сети?
