Исследование новой эры создания видео с помощью искусственного интеллекта: Винсент Видео Сора против RunwayML, Pika и StableVideo — кто будет лидировать в будущем
Исследование новой эры создания видео с помощью искусственного интеллекта: Винсент Видео Сора против RunwayML, Pika и StableVideo — кто будет лидировать в будущем

Sora сразу произвела фурор благодаря успеху в увеличении продолжительности сгенерированного ИИ видео до одной минуты в сочетании с высокой точностью и высоким качеством демонстрационного видео. До появления Sora Runway всегда считался выбором по умолчанию для видеороликов, создаваемых ИИ, особенно после запуска модели второго поколения в ноябре прошлого года. Runway также называли «MidJourney of AI video». Модель второго поколения Gen-2 не только решает проблему низкой когерентности между кадрами в видеороликах первого поколения, сгенерированных AI, но и дает хорошие результаты в процессе генерации видео из изображений.
Одним из самых шокирующих технологических прорывов Sora является длина выводимого видео. Runway может генерировать 4-секундное видео, которое пользователи могут продлить до 16 секунд, что является самым длинным рекордом для видео, созданного искусственным интеллектом, в 2023 году. Stable Video также предлагает 4-секундные видеоролики, а Pika — 3-секундные видеоролики. В связи с этим Сора бросила вызов своим конкурентам, установив ограничение по времени в одну минуту. По сути, Sora, Pika и Runway используют аналогичную базовую модель, а именно модель диффузии. Разница в том, что Sora изменила логику реализации и заменила архитектуру U-Net на архитектуру Transformer.
1. Сравнение отображения видеоэффектов Винсента:
1.1 Эффект модели до соры
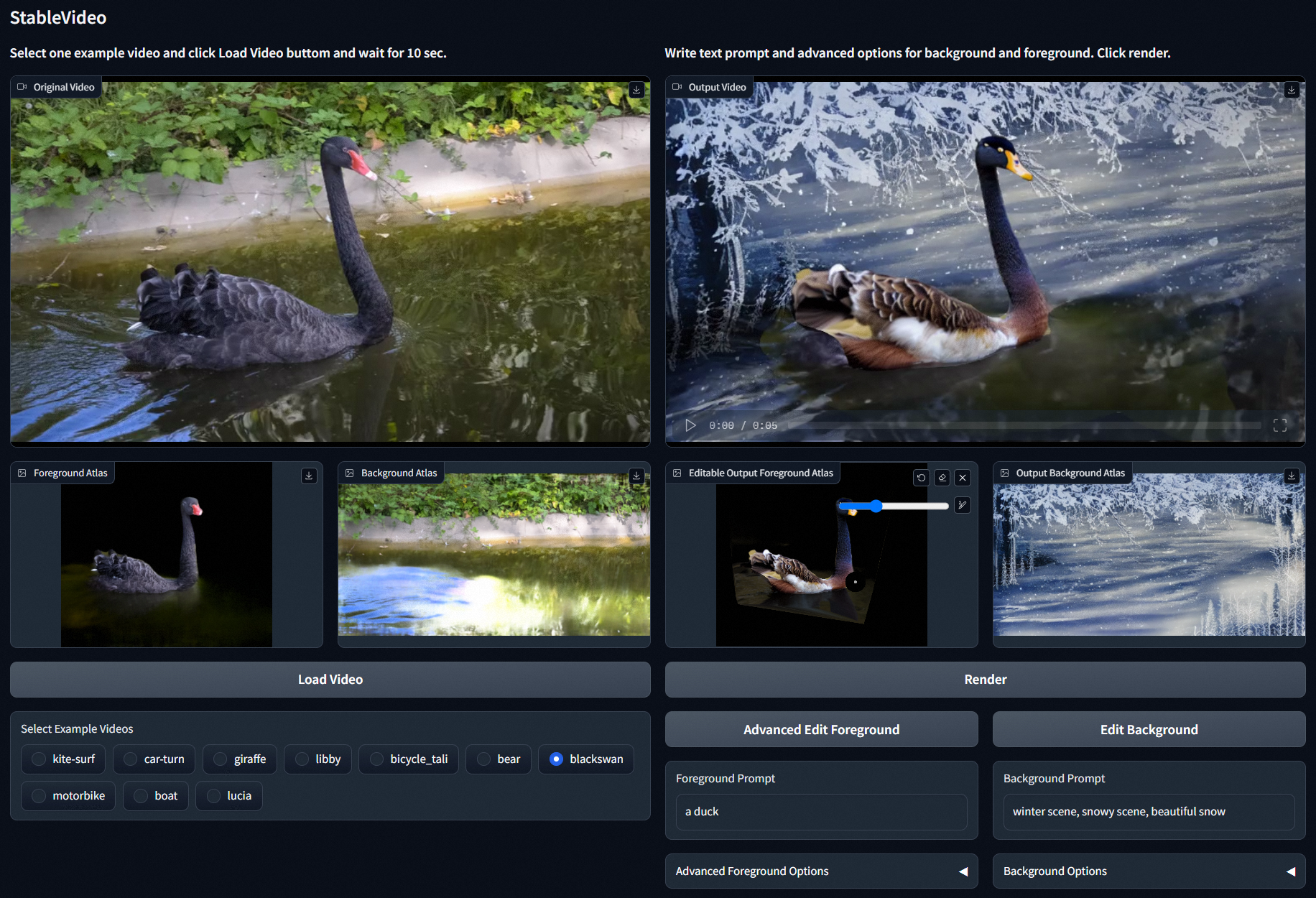
- Стабильное отображение видеоэффектов




Видно, что эффект в целом более очевиден, и можно увидеть разницу.
1.2 Сравнение основных моделей генерации видео Sora VS RunwayML, Pika
Трудность в том, чтобы позволить машинам генерировать видео, «реалистична». Например, в телеобъективе и короткофокусном объективе в одном и том же видео внешний вид человека не изменится, при вращении камеры щенок, стоящий на обрыве, должен двигаться вровень со обрывом, если откусить там кусок хлеба; станет на один кусок хлеба меньше. И появятся следы от зубов... Эта логика может показаться людям очевидной, но модели ИИ сложно понять различную логику и связи между предыдущим кадром и следующим кадром.
Во-первых, мы должны подчеркнуть разницу между генеративными моделями ИИ и традиционным поиском информации. Традиционный поиск основан на изображениях и извлечении информации из фиксированных мест в базе данных. Он имеет высокую точность, но не позволяет делать выводы из одного случая в другие случаи. Генеративная модель ИИ не запоминает сами данные, но изучает и осваивает определенный метод генерации языка, изображений или видео из большого объема данных, создавая «новые» возможности, которые трудно объяснить.
Источник:https://twitter.com/samsheffer/status/1758205467682357732_
Конечно, когда Сора присоединится к войне за поколение видео, наибольший успех принесут конкурирующие модели, такие как Runway, Pika, SDV, Google и Meta. Увидев эффект генерации Соры, многие люди полагают, что Сора нанес удар по уменьшению размерности этим «предшественникам». Так ли это на самом деле? Некоторые блоггеры в Твиттере уже провели сравнения.

Этот блоггер ввел одну и ту же подсказку в четыре модели Sora, Pika, Runway и Stable Video:
Красивый заснеженный Токио полон людей, и камера движется по шумным городским улицам, следя за несколькими людьми, наслаждающимися прекрасным снежным днем, делающими покупки в близлежащих киосках, и великолепными лепестками сакуры, трепещущими на ветру вместе со снежинками.
Видно, что по сравнению с тремя другими моделями генерации видео Sora имеет существенные преимущества по продолжительности генерации и когерентности.

Источник:https://twitter.com/gabor/status/1758282791547232482_
Таких сравнений много, например, ввод одной и той же подсказки: «Помет щенков золотистого ретривера играет в снегу, их головы высунулись из снега и были покрыты снегом».

Источник:https://twitter.com/DailyUpdatesNet/status/1758646902751670355_
Другой пример — ввести ту же подсказку «Несколько огромных шерстистых мамонтов идут по заснеженной траве, их длинный мех нежно развевается на ветру. Вдалеке заснеженные деревья и величественные заснеженные горы. Днем Солнечный свет, огоньки Облака и солнце вдалеке создают теплое сияние, а вид с низкой камеры потрясающе запечатлевает крупных пушистых млекопитающих с прекрасными фотографиями и глубиной резкости».
Хотя и Runway, и Pika работают хорошо, качество сборки Sora намного выше.

Источник:https://twitter.com/keitowebai/status/1758384152670577136_
Другие сравнили Pika 1.0 (апрель прошлого года) с Sora и посетовали, что менее чем за год видео, созданные ИИ, претерпели потрясающие изменения.
Оригинальное видео:https://twitter.com/QuintinAu/status/1758536835595124910_
В то же время больше авторов также опубликовали видео, созданные с помощью Sora, что еще раз подтверждает возможности Sora по созданию супервидео.
Например, введите подсказку «Огромный собор полон кошек. Куда ни глянь, кошки. Мужчина заходит в собор и кланяется гиганту Элвису, сидящему на троне».

Источник:https://twitter.com/billpeeb/status/1758650919430848991_
Например, введите подсказку «Жуткий дом с привидениями, дружелюбными фонариками из тыквы и призрачными персонажами приветствует у входа любителей сладостей, фотография с наклоном и сдвигом».

Источник:https://twitter.com/billpeeb/status/1758658884582142310_
Например, введите подсказку «Человек из воды гулял и посетил художественную галерею со множеством прекрасных произведений искусства в разных стилях».

Источник:https://twitter.com/_tim_brooks/status/1758666264032280683_
Например, введите подсказку «Реальное видео людей, отдыхающих на пляже, и из воды выходит акула, удивляя всех».

Источник:https://twitter.com/_tim_brooks/status/1758655323576164830_
2. Технический отчет Sora-OpenAI

Адрес технического отчета https://openai.com/research/video-generation-models-as-world-simulators
В своем техническом отчете OpenAI суммировала некоторые часто используемые методы генерации и моделирования видео в предыдущих моделях, включая рекуррентные сети, генеративно-состязательные сети, авторегрессионные трансформаторы и диффузионные модели. Они могут создавать только короткие видеоролики фиксированного размера.
OpenAI подчеркивает в своем техническом отчете:
(1) Метод, который преобразует все типы визуальных данных в единое представление, позволяющее крупномасштабное обучение генеративных моделей;
(2) Провести качественную оценку возможностей и ограничений Sora.
В последнее время генерация видео стала важным направлением в области ИИ. Во многих предыдущих работах изучалось направление генеративного моделирования видеоданных, включая рекуррентные сети, генеративно-состязательные сети, авторегрессионные преобразователи и диффузионные модели. Эти работы обычно сосредоточены на небольшом классе визуальных данных, более коротких видеороликах или видеороликах фиксированного размера. Напротив, Sora от OpenAI представляет собой общую модель визуальных данных, которая может генерировать видео и изображения различной продолжительности, соотношений сторон и разрешений, а также выводить видео высокой четкости продолжительностью до одной минуты.
2.1 Преобразование визуальных данных в патчи
OpenAI черпает вдохновение из замечательных общих возможностей больших языковых моделей, достигаемых путем обучения на данных в масштабе Интернета. LLM смогла создать новую парадигму, отчасти благодаря инновационным способам использования токенов. Исследователи умело объединили множество модальностей текста — код, математику и различные естественные языки. В этой работе OpenAI рассматривает, как модели, генерирующие визуальные данные, могут унаследовать преимущества этого подхода. В больших языковых моделях есть текстовые токены, а в Sora — визуальные патчи. Предыдущие исследования показали, что патчи являются эффективным представлением моделей визуальных данных. OpenAI обнаружила, что патчи представляют собой масштабируемое и эффективное представление обучающих моделей, генерирующих различные типы видео и изображений.

На более высоком уровне OpenAI преобразует видео в фрагменты, сначала сжимая их в скрытое пространство более низкой размерности, а затем разлагая представление на пространственно-временные фрагменты.
- (Авторегрессия) генерация длинного видео
Одним из главных достижений Sora является способность создавать очень длинные видеоролики. Разница между созданием 2-секундного видео и 1-минутного видео огромна. В Sora этого можно достичь с помощью совместного прогнозирования кадров, позволяющего использовать авторегрессионную выборку, но основная проблема заключается в том, как учесть накопление ошибок и поддерживать качество/согласованность.
2.2 Сеть сжатия видео
Sora реализует инновацию, объединяющую модели Transformer и диффузии, сначала преобразуя различные типы визуальных данных в единое представление визуальных данных (визуальный патч), затем сжимая исходное видео в низкомерное скрытое пространство и разлагая визуальное представление на пространство и time (эквивалент токена Трансформера), позволяющий Соре тренироваться и создавать видео в этом скрытом пространстве. Затем выполните добавление и шумоподавление. После ввода патча шума Сора генерирует видео, предсказывая исходный «чистый» патч. OpenAI обнаружила, что чем больше объем обучающих вычислений, тем выше будет качество выборки. Особенно после крупномасштабного обучения Сора продемонстрировал «появившуюся» способность моделировать определенные атрибуты реального мира. Вот почему OpenAI называет модель генерации видео «симулятором мира» и приходит к выводу, что дальнейшее расширение модели видео — это многообещающий путь к моделированию физического и цифрового мира.
Обучается сеть, уменьшающая размерность визуальных данных. Сеть принимает необработанное видео в качестве входных данных и выводит скрытое представление, сжатое во времени и пространстве. Сора обучается работе с этим сжатым скрытым пространством, а затем генерирует видео. OpenAI также обучает соответствующую модель декодера отображать сгенерированное скрытое представление обратно в пространство пикселей.
- пространственно-временные потенциальные пятна
Учитывая сжатое входное видео, OpenAI извлекает серию пространственно-временных патчей, которые служат токенами для Трансформера. Эта схема также работает для изображений, поскольку изображения можно просматривать как отдельные кадры видео. Представление OpenAI на основе патчей позволяет Sora тренироваться на видео и изображениях различного разрешения, продолжительности и соотношения сторон. Во время вывода OpenAI может контролировать размер сгенерированного видео, располагая случайно инициализированные патчи в сетке соответствующего размера.
- Масштабирующий преобразователь для генерации видео
Сора — это диффузионная модель; с учетом входных участков шума (и обусловливающей информации, такой как текстовые подсказки), модель обучена прогнозировать исходные «чистые» участки. Важно отметить, что Сора является диффузионным Трансформатором. Transformer продемонстрировал отличные возможности масштабирования в различных областях, включая языковое моделирование, компьютерное зрение и генерацию изображений.

В этой работе OpenAI обнаружила, что диффузионные трансформаторы также эффективно масштабируются для видеомоделей. Ниже OpenAI показывает сравнение образцов видео с фиксированными начальными числами и входными данными во время обучения. По мере увеличения обучающих вычислений качество выборки значительно улучшается.

- Переменная продолжительность, разрешение, соотношение сторон
Предыдущие методы создания изображений и видео часто требовали изменения размера, обрезки или обрезки видео до стандартного размера, например 256x256 для 4-секундного видео. Вместо этого исследование показало, что обучение исходному размеру данных дает следующие преимущества:
Во-первых, это гибкость выборки: Sora может сэмплировать широкоэкранное видео с разрешением 1920x1080p, вертикальное видео с разрешением 1920x1080p и все, что между ними. Это позволяет Sora создавать контент для разных устройств непосредственно с их исходным соотношением сторон. Sora также позволяет быстро создавать прототипы контента меньшего размера, а затем генерировать его в полном разрешении — и все это с использованием одной и той же модели.
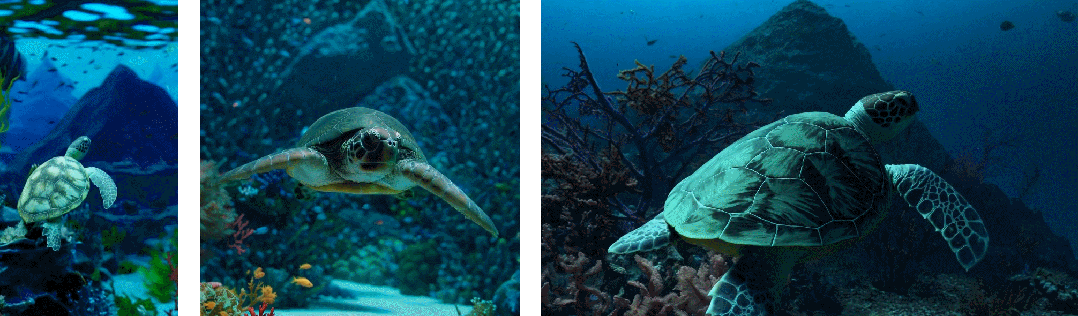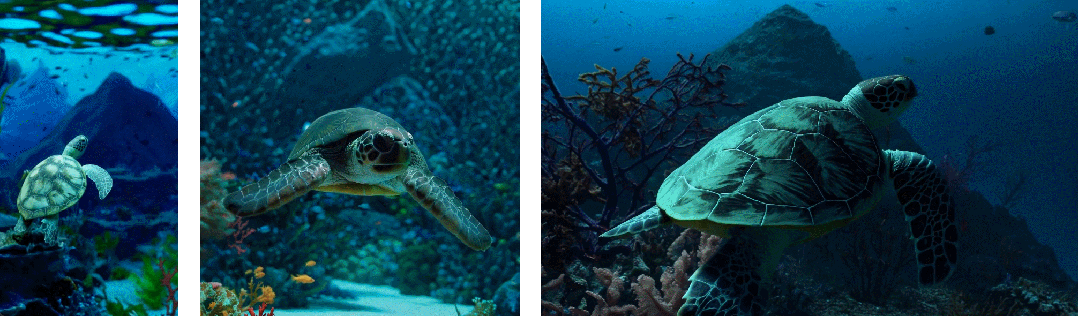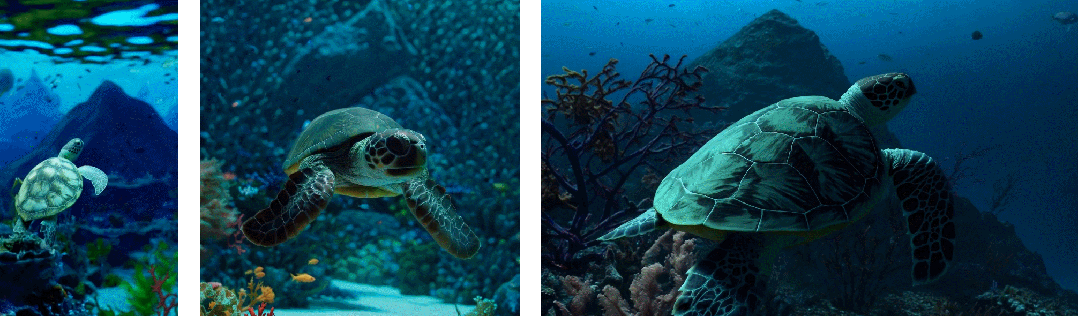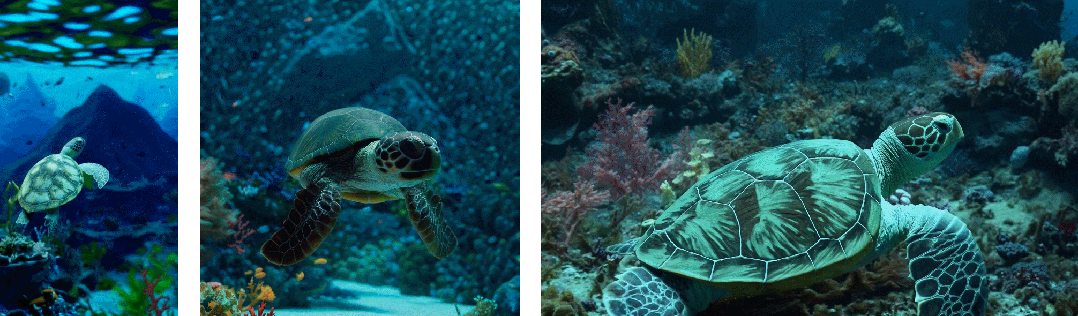
Второе — улучшить композицию кадра и контента: исследователи эмпирически обнаружили, что обучение с использованием исходного соотношения сторон видео может улучшить композицию контента и качество кадров. При сравнении Sora с другими моделями последняя обрезает все обучающие видео на квадраты, что является обычной практикой при обучении генеративных моделей. Видео, созданное моделью, обученной с использованием квадратной обрезки (слева), на которой объект видео виден лишь частично. Для сравнения, в видео, созданном Сорой (справа), содержание кадров улучшено.

2.3 Понимание языка
Для обучения систем генерации текста в видео требуется большое количество видеороликов с соответствующими текстовыми субтитрами. Исследовательская группа применила к видео технологию повторных титров в DALL・E 3.
В частности, исследовательская группа сначала обучила высокоописательную модель генератора субтитров, а затем использовала ее для создания текстовых субтитров для всех видео в обучающем наборе. Исследовательская группа обнаружила, что обучение использованию информативных субтитров к видео улучшило точность текста, а также общее качество видео.
Как и в случае с DALL・E 3, исследовательская группа также использовала GPT для преобразования коротких запросов пользователя в более длинные и подробные субтитры, которые затем отправлялись в видеомодель. Это позволяет Sora создавать высококачественные видеоролики, точно соответствующие подсказкам пользователя.
- Используйте изображения и видео в качестве напоминаний
Мы видели много примеров преобразования текста в видео. Фактически, Сора также может использовать другие входные данные, например существующие изображения или видео. Это позволяет Sora выполнять различные задачи по редактированию изображений и видео — создавать идеальные зацикленные видеоролики, анимировать неподвижные изображения, продлевать время видео вперед или назад и многое другое.
Анимация изображения DALL-E
Просто введите изображение и подсказку, и Сора сгенерирует видео. Ниже показаны примеры видеороликов, созданных на основе изображений DALL-E 2 и DALL-E 3:

Собака в берете и черной водолазке

Изображение облака с Сорой
Расширение видеоконтента
Sora также имеет возможность расширять видеоконтент в начале или в конце. Ниже представлены три новых видео, которые Сора расширил назад из сгенерированного видео. Все новые видео начинаются по-разному и имеют одинаковую концовку.
С таким же успехом вы можете использовать этот метод для неограниченного расширения содержания видео и достижения «вечного движения в видеопроизводстве».
редактирование видео в видео
Модели диффузии вдохновляют на создание множества методов редактирования изображений и видео на основе текстовых подсказок. Исследовательская группа OpenAI применила к Sora один из этих методов, SDEdit, что позволило Sora изменять стиль и среду входного видео в условиях нулевого кадра.
Входное видео выглядит следующим образом:

Результат вывода:

Connected Video также может использовать Sora для постепенного перехода между двумя входными видео, создавая плавный переход между видео с совершенно разными темами и композициями сцен.


2.4 Возможность создания изображений
Сора также может генерировать изображения. Для этого OpenAI упорядочивает патчи гауссовского шума в пространственной сетке с временным масштабом в один кадр. Модель может генерировать изображения разных размеров до максимального разрешения 2048x2048.
возможности экстренного моделирования
OpenAI обнаружила, что видеомодели демонстрируют множество новых интересных возможностей при масштабном обучении. Эти способности позволяют Соре моделировать определенные аспекты людей, животных и окружающей среды в физическом мире. Эти свойства возникают без какой-либо явной индуктивной склонности к трем измерениям, объектам и т. д. — это чисто масштабные явления.
Трехмерная согласованность. Sora может создавать видео динамических движений камеры. Когда камера движется и вращается, персонажи и элементы сцены последовательно перемещаются в трехмерном пространстве.

Последовательность длинных последовательностей и постоянство цели. Серьезной проблемой для систем генерации видео является поддержание временной согласованности при выборке длинных видеороликов. OpenAI обнаружила, что, хотя Sora не всегда эффективно моделировала краткосрочные и долгосрочные зависимости, она все же делала это в большинстве случаев. Например, модели Сора сохраняют свое присутствие, даже когда люди, животные и объекты скрыты или выходят за пределы кадра. Аналогично, он может создавать несколько кадров одного и того же персонажа в одном образце и сохранять его внешний вид на протяжении всего видео.

Взаимодействуйте с миром. Иногда Сора может простыми способами имитировать действия, влияющие на состояние мира. Например, художник может оставить на холсте новые мазки, которые сохранятся со временем, или человек может съесть гамбургер и оставить следы от укусов.

Аналоговый цифровой мир. Сора также может моделировать человеческие процессы, примером чего являются видеоигры. Сора может одновременно управлять игроками в Minecraft с помощью базовых стратегий, одновременно отображая мир и его динамику с высокой точностью. Просто упомяните «Minecraft» в субтитрах Соры, чтобы активировать эти функции без сэмплов.

Эти возможности демонстрируют, что продолжающееся расширение видеомоделей является многообещающим путем к разработке высокоэффективных симуляторов физического и цифрового миров, а также объектов, животных и людей внутри них.
2.5 Направления, которые можно оптимизировать в будущем
Как эмулятор Sora в настоящее время имеет множество ограничений. Например, он не может точно моделировать многие фундаментальные интерактивные физические явления, такие как разбитие стекла. Другие взаимодействия, такие как употребление пищи, не всегда приводят к правильным изменениям состояния объекта. На официальной домашней странице перечислены другие распространенные неисправности модели, такие как несоответствия в долгосрочных образцах или спонтанное появление объектов.


Однако возможности, продемонстрированные Сорой на данный момент, демонстрируют многообещающее направление в продолжении масштабирования видеомоделей, что также позволит более точно моделировать физический и цифровой миры, а также объекты, животных и людей в них.
Более подробную информацию можно найти в оригинальном техническом отчете Соры.
Справочные ссылки:https://openai.com/research/video-generation-models-as-world-simulators
3. Краткое содержание Соры

В исследовательской работе OpenAI «Модели генерации видео как симуляторы мира» исследуются методы крупномасштабного обучения моделей генерации на видеоданных. В этом исследовании особое внимание уделяется моделям условной диффузии текста, которые обучаются одновременно на видео и изображениях, обрабатывая данные различной продолжительности, разрешения и соотношения сторон. Самая крупная модель, упомянутая в исследовании, Sora, была способна генерировать высококачественное видео продолжительностью до минуты. Вот некоторые ключевые моменты из статьи:
Единое визуальное представление данных:Исследователи классифицировали все видыиз Визуальное преобразование данныхдляединыйизвыражать,Для проведения масштабного обучения генеративной модели. Сора В качестве своего представления он использует визуальные патчи, аналогичные текстовой разметке в моделях большого языка (LLM).сеть сжатия видео:Исследователи обучили сеть,Сжимайте исходное видео в низкоразмерное скрытое пространство.,и сделай этовыражатьавариядляпространственно-временной патч。Sora Тренируйтесь в этом сжатом скрытом пространстве и создавайте видеоролики.диффузионная модель:Sora это Модель диффузии, которая генерирует видео из входных шумовых патчей, прогнозируя исходные «чистые» патчи. Модель диффузии в языковом моделировании, компьютерное Такие области, как создание изображений, продемонстрировали значительную масштабируемость.Генерация видео и масштабируемость:Sora Способен генерировать видео различного разрешения, продолжительности и соотношения сторон, включая Full HD. Эта гибкость позволяет Sora Возможность создавать контент напрямую для разных устройств или быстро создавать прототипы контента перед созданием видео в полном разрешении.понимание языка:для Обучить систему генерации текста в видео,Нужно многоизвидеоисоответствующийизтекстовое название。Исследователи применили DALL·E 3 Техника переописания, представленная в разделе , сначала обучает генератор наглядных заголовков, а затем генерирует текстовые заголовки для всех видео в обучающем наборе.Редактирование изображений и видео:Sora Видео можно создавать не только на основе текстовых подсказок, но и на основе существующих изображений или видео. Это делает Sora Способность выполнять широкий спектр задач по редактированию изображений и видео, таких как создание идеально зацикленных видеороликов, анимация неподвижных изображений, продление видео вперед или назад и т. д.Возможности моделирования:когдавидео Когда модель обучается в большом масштабе,Они демонстрируют некоторые интересные и новые возможности.,делать Sora Способность моделировать такие аспекты физического мира, как динамическое движение камеры, долговременную согласованность и устойчивость объектов.
Хотя Sora демонстрирует потенциал в качестве симулятора, она все еще страдает от ряда ограничений, таких как недостаточная точность при моделировании основных физических взаимодействий, таких как разбитие стекла. Исследователи полагают, что продолжение расширения видеомодели — это многообещающий путь к разработке симуляторов физического и цифрового миров.
В этой статье представлен углубленный анализ модели Сора, демонстрирующий ее потенциал и проблемы в области генерации видео. Таким образом, OpenAI исследует, как можно использовать ИИ для лучшего понимания и моделирования окружающего мира.
- Справочные ссылки:
stable-diffusion-videos:https://github.com/nateraw/stable-diffusion-videos
StableVideo:https://github.com/rese1f/StableVideo
soraОфициальный сайт:https://openai.com/sora
soraОтчетиз Связь:https://openai.com/research/video-generation-models-as-world-simulators



Углубленный анализ переполнения памяти CUDA: OutOfMemoryError: CUDA не хватает памяти. Попыталась выделить 3,21 Ги Б (GPU 0; всего 8,00 Ги Б).

[Решено] ошибка установки conda. Среда решения: не удалось выполнить первоначальное зависание. Повторная попытка с помощью файла (графическое руководство).

Прочитайте нейросетевую модель Трансформера в одной статье

.ART Теплые зимние предложения уже открыты

Сравнительная таблица описания кодов ошибок Amap

Уведомление о последних правилах Points Mall в декабре 2022 года.

Даже новички могут быстро приступить к работе с легким сервером приложений.

Взгляд на RSAC 2024|Защита конфиденциальности в эпоху больших моделей

Вы используете ИИ каждый день и до сих пор не знаете, как ИИ дает обратную связь? Одна статья для понимания реализации в коде Python общих функций потерь генеративных моделей + анализ принципов расчета.

Используйте (внутренний) почтовый ящик для образовательных учреждений, чтобы использовать Microsoft Family Bucket (1T дискового пространства на одном диске и версию Office 365 для образовательных учреждений)

Руководство по началу работы с оперативным проектом (7) Практическое сочетание оперативного письма — оперативного письма на основе интеллектуальной системы вопросов и ответов службы поддержки клиентов

[docker] Версия сервера «Чтение 3» — создайте свою собственную программу чтения веб-текста

Обзор Cloud-init и этапы создания в рамках PVE

Корпоративные пользователи используют пакет регистрационных ресурсов для регистрации ICP для веб-сайта и активации оплаты WeChat H5 (с кодом платежного узла версии API V3)

Подробное объяснение таких показателей производительности с высоким уровнем параллелизма, как QPS, TPS, RT и пропускная способность.

Удачи в конкурсе Python Essay Challenge, станьте первым, кто испытает новую функцию сообщества [Запускать блоки кода онлайн] и выиграйте множество изысканных подарков!

[Техническая посадка травы] Кровавая рвота и отделка позволяют вам необычным образом ощипывать гусиные перья! Не распространяйте информацию! ! !

[Официальное ограниченное по времени мероприятие] Сейчас ноябрь, напишите и получите приз

Прочтите это в одной статье: Учебник для няни по созданию сервера Huanshou Parlu на базе CVM-сервера.

Cloud Native | Что такое CRD (настраиваемые определения ресурсов) в K8s?

Как использовать Cloudflare CDN для настройки узла (CF самостоятельно выбирает IP) Гонконг, Китай/Азия узел/сводка и рекомендации внутреннего высокоскоростного IP-сегмента

Дополнительные правила вознаграждения амбассадоров акции в марте 2023 г.

Можно ли открыть частный сервер Phantom Beast Palu одним щелчком мыши? Супер простой урок для начинающих! (Прилагается метод обновления сервера)

[Играйте с Phantom Beast Palu] Обновите игровой сервер Phantom Beast Pallu одним щелчком мыши

Maotouhu делится: последний доступный внутри страны адрес склада исходного образа Docker 2024 года (обновлено 1 декабря)

Кодирование Base64 в MultipartFile

5 точек расширения SpringBoot, супер практично!

Глубокое понимание сопоставления индексов Elasticsearch.

15 рекомендуемых платформ разработки с нулевым кодом корпоративного уровня. Всегда найдется та, которая вам понравится.
