Исследование Меты о законе масштабирования для рекомендательных систем глубокого обучения
Автор | Помидор любит яйца Организация | https://zhuanlan.zhihu.com/p/688913185
Привет всем, это NewBeeNLP. Сегодня взгляните на исследование Meta о законе масштабирования, системе рекомендаций по глубокому обучению.
Ноль, бумажная информация
- Название диссертации: Вуконг: К закону масштабирования для крупномасштабных рекомендаций
- Ссылка на статью: https://arxiv.org/abs/2403.02545.
- Информация об авторе: Все авторы из Meta.
1. Общее резюме
В данной статье рассматривается вопрос. Поскольку количество параметров в плотном слое рекомендательной системы (то есть в слое расчета, отличном от таблицы внедрения) продолжает увеличиваться, будут ли постепенно увеличиваться рекомендуемые показатели?
В этой статье дан однозначный ответ, т. Внутренний набор данных со 146 миллиардами записей и 720 функциями. постепенно расширяйте параметры Плотного слоя, Объем расчета обучения WuKong, модели, предложенной в этой статье, варьируется от 1GFLOP/пример увеличивается до 100 GFLOP/example(100 GFLOP/пример эквивалентен шкале вычислений GPT3), шкала параметра плотного слоя варьируется от 0,74B до 17B, а соответствующие показатели производительности демонстрируют тенденцию к постоянному улучшению.
Общий вклад этой статьи:
- Предложена новая структура кроссовера признаков.,По имени Вуконг,Наилучшие результаты достигнуты в эпизодах с офлайн-данными
- Об этом сообщает Система рекомендацийсерединаизScale Law,Что касается вычислительной сложности, модель Воконга обеспечивает стабильность роста примерно на два порядка. Учетверение обучающих вычислений приведет к улучшению производительности на 0,1%.
Я имею в виду, что Meta недавно сообщила о явлении закона масштаба в модели генеративных рекомендаций, предложенном различными группами. Для получения подробной информации обратитесь к следующим вопросам:
- Как оценить последний документ Meta об алгоритме рекомендаций: унифицированные генеративные рекомендации впервые победили иерархическую архитектуру глубинных системных рекомендаций? https://www.zhihu.com/question/646766849
2. Стратегии Укуна и Чешуи
2.1 Функциональный модуль
Элементы имеют блочную конструкцию: размер каждого элемента имеет Меньшие подразмерности служат базовыми единицами. (Например, обычно используются 32 измерения, которые можно разделить на четыре базовые единицы по 8 измерений), а затем для важных функций можно использовать больше базовых единиц, чтобы получить более длинные размеры объекта.
Функции переменной длины могут принести некоторые эффекты. Вы также можете обучать блоки полной длины во время обучения, а затем использовать функцию Featuredropout для удаления соответствующих блоков.
Во время кроссовера объектов каждая единица будет использоваться как независимый объект для участия в кроссовере (сохранение постоянной длины единицы будет способствовать кроссоверу функций).
2.2 Wukong
В целом, Wukong — это относительно распространенная категория моделей CTR. Она использует структуру, которая сначала использует слой Wukong для выполнения пересечения функций, а затем использует MLP для генерации результатов прогнозирования.
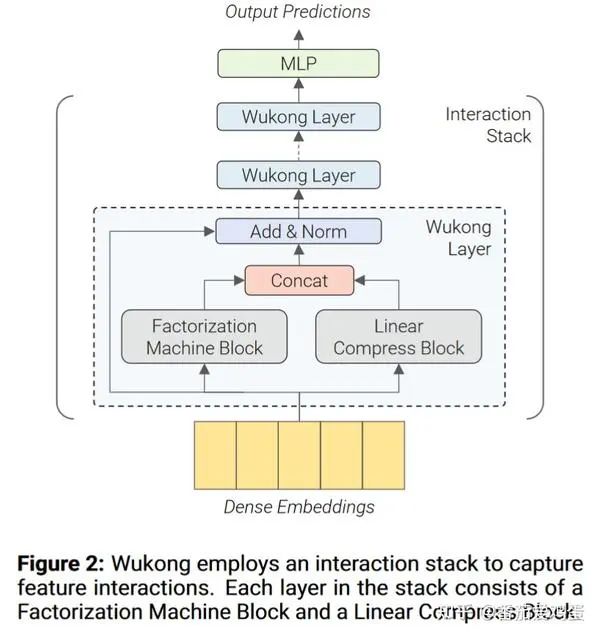
Как показано на рисунке выше, каждый уровень Wukong содержит блок машины факторизации (сокращенно FMB) и блок линейного сжатия (сокращенно LCB). Наконец, выходные данные двух модулей соединяются и добавляются остаточные связи и LayerNorm.
Предположим, что характеристическая матрица определенного образца. Конкретная формула расчета слоя Вуконг выглядит следующим образом:
ФМБ работает следующим образом:
FM — это модуль функционального кроссовера, и в этой статье для захвата кроссовера высокого порядка используется структура, аналогичная DCNv2. Среди них, то есть сначала сжать количество признаков до , а затем вычислить перекрестный результат. Наконец, FMB выводит матрицу функций.
LCB выглядит следующим образом
где — весовая матрица, — гиперпараметр, определяющий количество выходных сжатых вложений, — количество вложений в i-м слое.
2.3 Параметры, соответствующие шкале
Вуконг в основном настраивает следующие параметры масштаба.
- l : Количество уровней в стеке взаимодействия.
- n_F: количество вложений, созданных FMB
- n_L: количество вложений, сгенерированных LCB
- k: Оптимизировать количество вложений сжатия в FM.
- MLP: количество слоев и размер FC в MLP FMB.
В статье упоминается, что они сначала усилили l, а затем усилили другие параметры.
3. Результаты экспериментов
3.1 Офлайн-сравнение общедоступных наборов данных
Вот краткий обзор результатов сравнения. Для детальных настроек вы можете обратиться непосредственно к статье.
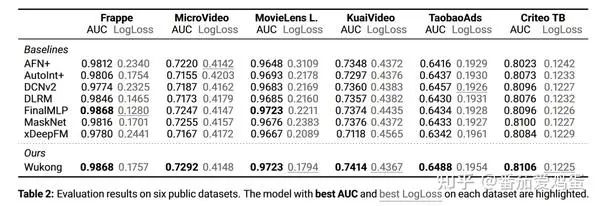
Видно, что Wukong также хорошо работает с этими наборами данных.
3.2 Эксперименты на внутреннем наборе данных Meta
Это основное содержание данной статьи. Давайте уделим пристальное внимание его настройкам подробно.
3.2.1 Набор данных и экспериментальная установка
- Сбор данных: этот сборник данных содержит в общей сложности 146B предметы, есть 720 разные характеристики. Каждая характеристика описывает элемент или атрибут пользователя. С этим набором данных связаны две задачи: (Задача1) Предсказать, проявит ли пользователь интерес к элементу (например, клик) и (Задача2) Произойдёт ли конверсия (например, лайк, внимание) на)。
- Настройки обучения:Длина всех вложений установлена равной 160, а размер не увеличивается с увеличением масштаба плотного слоя.. Используйте Adam для обучения плотного слоя и обучения внедрению. Для стола Rowwise Adagrad。Размер пакета установлен на 262 144, каждый обучающий экземпляр будет использовать 128 или 256 графических процессоров H100.。
- Введение в некоторые показатели
- GFLOP/пример: Гига операций с плавающей запятой в примере
- PF-days:PF-days Общий объем обучающих вычислений эквивалентен запуску компьютера с более чем 1 PetaFLOP/s беговая машина 1 небо.
- #Params: Размер модели измеряется количеством параметров в модели. встраивание Размер таблицы фиксирован 627B параметр.
- Relative LogLoss: относительно фиксированной базовой линии. LogLoss улучшать.Относительное улучшение LogLoss на 0,02% в этом наборе данных считается значительным.。
3.2.2 Экспериментальные результаты
Согласно приложению параметры каждой точки отбора проб Укун устанавливаются следующим образом:
График улучшения производительности строится в зависимости от объема расчета следующим образом:
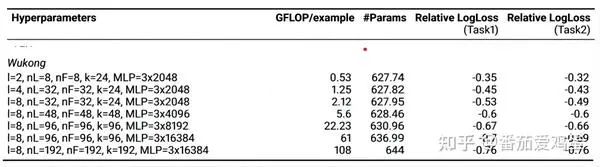
Видно, что по мере увеличения объема обучающих вычислений логарифмические потери неуклонно уменьшаются. Согласно заключению статьи, Wukong Поддерживает правило масштабирования на два порядка сложности модели, что примерно эквивалентно увеличению сложности каждый раз, когда она увеличивается в четыре раза. 0.1%。
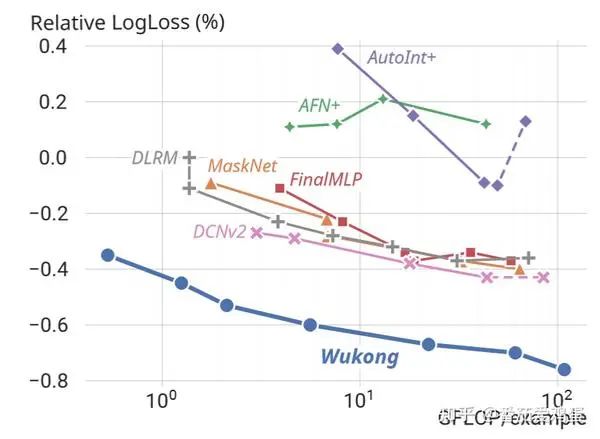
Авторы также построили аналогичные результаты на основе количества параметров модели.
Так в какие же модули эффективнее добавлять параметры и расчеты? Рисунок ниже также дает определенный ответ.
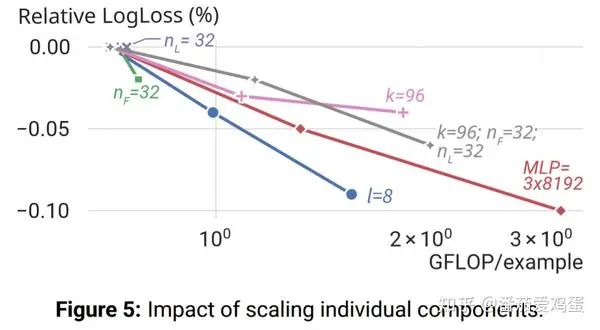
Можно заметить, что параметры n_F и l, связанные с поперечным сечением объекта, значительно улучшились. Комбинация k, n_F, n_L также дает хороший эффект. Улучшение параметров MLP также дает эффект, но увеличение n_L само по себе не дает эффекта. (Я считаю, что большинство из них, связанных с пересечением функций и, наконец, с MLP, более эффективны)
Приложение: Чепуха
Закон масштабирования все еще относительно ясен. За счет увеличения вычислительных затрат на взаимодействие функций можно добиться повышения производительности, что также очень интуитивно понятно. Немного жаль, что он не предполагает моделирования последовательностей. Конечно, рекомендуемые требования к задержке вычислений намного превышают требования LLM. Как уместить больше вычислений в единицу времени — это тоже техническая задача.



Углубленный анализ переполнения памяти CUDA: OutOfMemoryError: CUDA не хватает памяти. Попыталась выделить 3,21 Ги Б (GPU 0; всего 8,00 Ги Б).

[Решено] ошибка установки conda. Среда решения: не удалось выполнить первоначальное зависание. Повторная попытка с помощью файла (графическое руководство).

Прочитайте нейросетевую модель Трансформера в одной статье

.ART Теплые зимние предложения уже открыты

Сравнительная таблица описания кодов ошибок Amap

Уведомление о последних правилах Points Mall в декабре 2022 года.

Даже новички могут быстро приступить к работе с легким сервером приложений.

Взгляд на RSAC 2024|Защита конфиденциальности в эпоху больших моделей

Вы используете ИИ каждый день и до сих пор не знаете, как ИИ дает обратную связь? Одна статья для понимания реализации в коде Python общих функций потерь генеративных моделей + анализ принципов расчета.

Используйте (внутренний) почтовый ящик для образовательных учреждений, чтобы использовать Microsoft Family Bucket (1T дискового пространства на одном диске и версию Office 365 для образовательных учреждений)

Руководство по началу работы с оперативным проектом (7) Практическое сочетание оперативного письма — оперативного письма на основе интеллектуальной системы вопросов и ответов службы поддержки клиентов

[docker] Версия сервера «Чтение 3» — создайте свою собственную программу чтения веб-текста

Обзор Cloud-init и этапы создания в рамках PVE

Корпоративные пользователи используют пакет регистрационных ресурсов для регистрации ICP для веб-сайта и активации оплаты WeChat H5 (с кодом платежного узла версии API V3)

Подробное объяснение таких показателей производительности с высоким уровнем параллелизма, как QPS, TPS, RT и пропускная способность.

Удачи в конкурсе Python Essay Challenge, станьте первым, кто испытает новую функцию сообщества [Запускать блоки кода онлайн] и выиграйте множество изысканных подарков!

[Техническая посадка травы] Кровавая рвота и отделка позволяют вам необычным образом ощипывать гусиные перья! Не распространяйте информацию! ! !

[Официальное ограниченное по времени мероприятие] Сейчас ноябрь, напишите и получите приз

Прочтите это в одной статье: Учебник для няни по созданию сервера Huanshou Parlu на базе CVM-сервера.

Cloud Native | Что такое CRD (настраиваемые определения ресурсов) в K8s?

Как использовать Cloudflare CDN для настройки узла (CF самостоятельно выбирает IP) Гонконг, Китай/Азия узел/сводка и рекомендации внутреннего высокоскоростного IP-сегмента

Дополнительные правила вознаграждения амбассадоров акции в марте 2023 г.

Можно ли открыть частный сервер Phantom Beast Palu одним щелчком мыши? Супер простой урок для начинающих! (Прилагается метод обновления сервера)

[Играйте с Phantom Beast Palu] Обновите игровой сервер Phantom Beast Pallu одним щелчком мыши

Maotouhu делится: последний доступный внутри страны адрес склада исходного образа Docker 2024 года (обновлено 1 декабря)

Кодирование Base64 в MultipartFile

5 точек расширения SpringBoot, супер практично!

Глубокое понимание сопоставления индексов Elasticsearch.

15 рекомендуемых платформ разработки с нулевым кодом корпоративного уровня. Всегда найдется та, которая вам понравится.
