Исследование архитектуры высокой доступности MySQL: анализ репликации «главный-подчиненный», стратегия коммутации, оптимизация задержки и выбор архитектуры
Краеугольный камень высокой доступности MySQL
В распределенной системе один узел не может предоставлять услуги при возникновении сбоя, что может привести к долгосрочной недоступности услуг, тем самым влияя на работу других узлов с очень серьезными последствиями.
для В целях обеспечения высокой доступности услуг,Часто за счет резервирования узлов (добавление подчиненных узлов с теми же функциями),Выполняется при возникновении сбоя Переключение главный-подчиненный, пусть подчиненный узел станет новым главным узлом, чтобы продолжать предоставлять услуги
Например: главный-подчиненный MySQL, главный-подчиненный Redis, главный-подчиненный брокера MQ... Идеи в целом схожи.
В качестве краеугольного камня обеспечения высокой доступности незаменима архитектура «господин-подчиненный». В этой статье будут рассмотрены некоторые детали MySQL master-slave.
binlog
Являясь журналом для логического восстановления данных, binlog является основой для синхронизации данных «главный-подчиненный» и восстановления данных.
binlogточкадлятри формата:statement、row、mixed
Оператор: SQL, который записывает операции записи. Оператор является легким и быстрым для передачи. Использование этого формата может привести к несогласованности данных.(потому чтодля Среды, в которых находятся ведомое устройство и хост, различаются.,Например, если время подчиненного устройства отличается от времени главного устройства,,используя функцию now())
строка: записывает изменение данных. Объем данных большой, передача медленная. Данные можно восстановить в случае неправильной работы (обратная операция). Данные согласованы во время синхронизации между главным и подчиненным устройствами.
смешанный: сочетает в себе преимущества оператора и строки для автоматического смешивания и выбора форматов.
В большинстве случаев используется строковый формат, поскольку данные согласованы и их можно восстановить.
репликация главный-подчиненный
Как упоминалось в предыдущих статьях, когда получена операция записи и данные необходимо изменить, для обеспечения согласованности данных будут записаны журнал отмены (атомарность), журнал повторного выполнения (постоянство), binlog и другие журналы.
Когда главный узел получает данные, измененные в результате операции записи, ему также необходимо изменить данные на подчиненном узле для достижения согласованности данных.
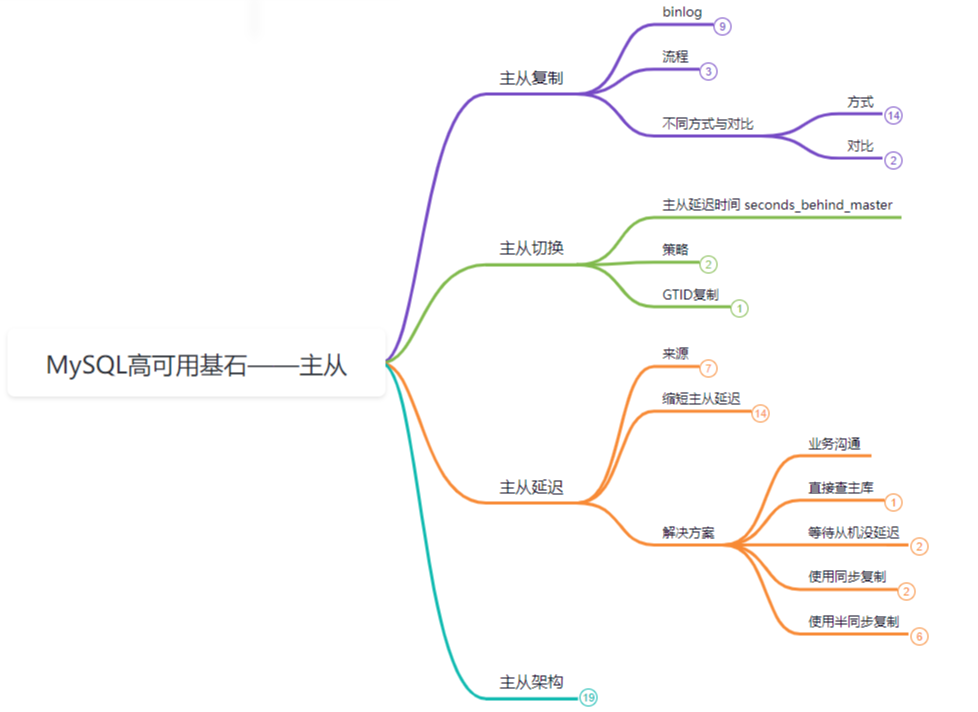
Данные в репликации главный-подчиненный опираются на binlog. Общий процесс разделен на три этапа:
- Поток дампа главного узла отслеживает изменения в бинлоге и уведомляет подчиненный узел.
- Подчиненный узел использует поток ввода-вывода для получения binlog и записи его в локальный журнал реле (журнал реле).
- Подчиненный узел использует потоки SQL для восстановления данных на основе журнала ретрансляции.
После записи журнала на одном компьютере вы можете отправить ответ на транзакцию.,В зависимости от различных стадий реагирования главный и подчиненный,репликация главный-подчиненныйиз Способточкадля Различный:
Синхронная репликация: все подчиненные узлы отвечают (данные восстанавливаются) до того, как ответит главный узел, низкая производительность, высокая согласованность данных.
Асинхронная репликация: главный узел отвечает сразу после уведомления подчиненного узла. Он имеет лучшую производительность, но возникают задержки и проблемы с согласованностью данных.
Полусинхронная репликация: пока существует подчиненный узел, отвечающий главному узлу, он будет отвечать. Один главный и один подчиненный узел соответствуют синхронной репликации. Тайм-аут сети снижается до асинхронной репликации.
Улучшенная полусинхронная репликация. На основе полусинхронной репликации главный узел фиксирует транзакцию только после получения ответа. Согласованность данных будет лучше, чем при полусинхронной, но производительность будет немного хуже.
Отложенная репликация: подчиненный узел задерживает восстановление данных на определенный период времени, чтобы можно было выполнить откат данных даже в случае возникновения неправильной работы.
Переключение главный-подчиненный
При выходе из строя хоста необходимо переключиться с слейва на хост
разные стратегии
Переключение общего промежуточного программного обеспечения главный-подчиненный Все может быть только вCAPВторое теоретически выполняется.,Прямо сейчасТолько надежный (C) или доступный (A) может быть удовлетворен при отказоустойчивости раздела (P)
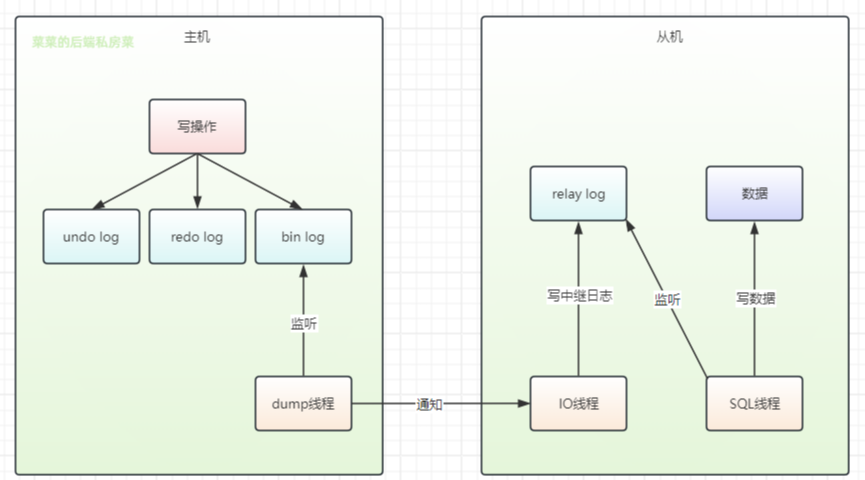
В binlog будет записываться время операции записи главного узла, а подчиненный узел будет поддерживать seconds_behind_master зафиксировать задержку главный-подчиненныйвремя
В соответствии с надежной стратегией вам необходимо дождаться, пока старый подчиненный узел завершит все восстановление данных (то есть, Seconds_behind_master равен 0), прежде чем он станет главным узлом и предоставит услуги записи.
В этот период предоставляются только услуги чтения, услуги записи предоставляться не могут.,потому чтоэтотНадежная стратегия теряет определенную часть удобства использования, в зависимости от времени задержки главный-подчиненный.
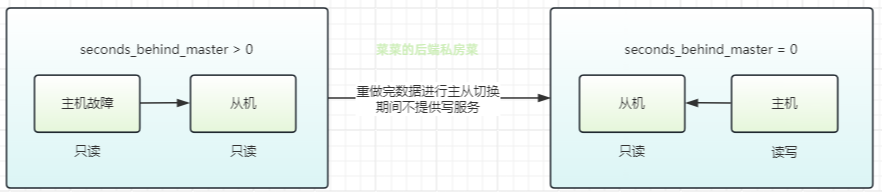
В соответствии с доступной политикой подчиненный узел будет немедленно назначен новым главным узлом для предоставления услуг чтения и записи. В некоторых сценариях данные могут быть несогласованными.
Предположим, что идентификатор увеличивается автоматически, формат записи — (идентификатор, имя) и добавляются новые данные a, b, c.
- Главный узел отключился, когда были добавлены (1,a), (2,b), (3,c).
- Подчиненный узел может только повторять данные (1,a), (2,b), пока (3,c) все еще находится в журнале реле.
- В это время старый подчиненный узел становится новым главным узлом и продолжает предоставлять услуги записи. Необходимо добавить d. После добавления d данные журнала реле будут восстановлены.
Если используется операторный или смешанный формат binlog, будут добавлены (3,d) и (4,c).
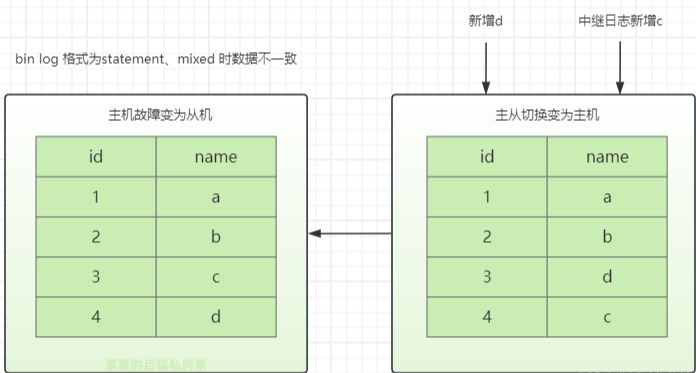
Если формат строки, будет сообщено об ошибке конфликта первичного ключа. После добавления (3,d) журнал реле будет иметь вид (3,c).
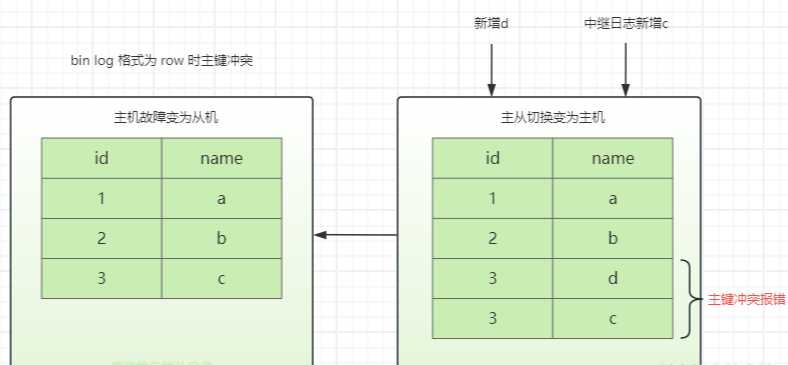
Несогласованность данных может возникнуть при использовании доступных стратегий. Использование строки заранее выявит несогласованность данных.
на основеGTIDиз Переключение главный-подчиненный
Идентификатор глобальной транзакции GTID
Формат: server_uuid:gno.
server_uuid — идентификатор узла
gno — идентификатор транзакции (полученный при отправке транзакции, глобально увеличивающийся)
в ходе выполнения Переключение главный-подчиненныйчас,Смещение журнала синхронизированных данных различно для каждого подчиненного узла.,Как правило, мы находим подчиненный узел с последним смещением и новый главный узел (это смещение должно быть обнаружено при эксплуатации и обслуживании).
существовать Идентификатор глобальной транзакции После выхода GTID,binlogКаждая транзакция имеет соответствующийизGTIDтогда все в порядкеАвтоматически находить смещения по GTID,Не требуется ручное позиционирование
задержка главный-подчиненный
источник
По умолчанию репликация главный-подчиненный будет использовать асинхронную репликацию, а в архитектуре «господин-подчиненный»Обычно будет использоваться чтение и запись.точка Оставлять,Операции записи хост-службы,Операция чтения подчиненной службы
Из-за использования асинхронной репликации будет определенная задержка в обеспечении согласованности данных между главным и подчиненным устройствами. Физически главный и подчиненный устройства будут размещены в одном компьютерном зале, а сетевая связь будет игнорироваться. Самая большая стоимость — это процесс. анализа журнала и восстановления данных подчиненным потоком SQL.
Если восстановленные данные представляют собой большую транзакцию, это приведет к длительной задержке. Например, выполнение пакетной операции на хосте занимает 5 секунд, и столько же времени потребуется на подчиненном устройстве (ресурсы примерно равны). такой же)
Возможно, что операция чтения будет выполнена после операции записи. Если подчиненная база данных в это время не переделала данные, это приведет к несоответствию данных, которые невозможно будет обнаружить после записи.
Давайте сначала посмотрим, в каких ситуациях задержка главного-подчиненного может оказаться слишком длительной:
- Частое чтение и запись (высокий TPS) в часы пик работы, подчиненная машина должна не только синхронизировать данные, но и обрабатывать операции чтения.
- Обработка крупных транзакций, крупные транзакции приводят к слишком длительным задержкам
- Конфигурация ведомого оборудования низкая, из-за чего оно не может поддерживать скорость ввода-вывода хоста.
- Главная и подчиненная машины могут иметь разные параметры (буферный пул, параметры ввода-вывода...).
- Сам слейв является отложенной копией
...
когдазадержка главный-подчиненныйслишком долгочас Вы можете рассмотреть возможность использования сокращения программы Задерживать:
- Настройте стратегию очистки диска журнала повтора \ bin и улучшите операции ввода-вывода.
- мониторинг канала (уведомление изменено на мониторинг)
- Параллельное копирование с подчиненного устройства
Когда параллельная копия подчиненного устройства передается с помощью журнала повторов и журнала бункера, на этапе подготовки журнала повторов не возникает конфликта блокировок, и они могут выполняться параллельно.
Параллельная репликация основана на групповой фиксации в двухфазной фиксации. Вы можете настроить следующие два параметра, чтобы увеличить время групповой фиксации, замедлить запись на хосте и ускорить повтор данных на подчиненном компьютере.
binlog_group_commit_sync_delay Сколько микросекунд нужно задержать перед звонком fsync
binlog_group_commit_sync_no_delay_count Сколько раз накопилось до звонка fsync
Решения для несогласованности данных
во избежание длительной задержки главный-подчиненный,Подчиненная машина должна иметь те же параметры и конфигурацию, что и главная машина.,и избегать больших событий
В периоды пиковой нагрузки по-прежнему могут возникать несоответствия данных, вызванные задержкой главного-подчиненного, чтобы их избежать.
- коммуникационный бизнес:ждатьостаться на некоторое времячасмежду,Например, после того, как пользователь изменил информацию, статус проверки
- Чтения с сильной согласованностью также передаются в основную библиотеку.:Таким образом, его не будетсуществоватьзадержка главный-подчиненный,Простота в использовании, большое количество строго согласованных операций чтения вызовет большую нагрузку на хост.
- Нет задержки в ожидании ведомого устройства (три метода оценки):
- Сравните секунды_behind_master, чтобы увидеть, равно ли оно 0. Если оно равно 0, это означает, что задержки нет.
- Сравните позиции Master_Log_File и Read_Master_Log_Pos (последняя позиция главной библиотеки) на ведущем и подчиненном устройствах Relay_Master_Log_File и Exec_Master_Log_Pos (последняя позиция выполнения резервной библиотеки), чтобы определить, совпадают ли они. Если они одинаковы, они будут одинаковыми. не задерживайся.
- Сравните наборы GTID Retieved_Gtid_Set и Executed_Gtid_Set на подчиненном компьютере (набор GTID всех журналов, полученных резервной базой данных, и набор GTID всех выполнений, завершенных резервной базой данных. Если они одинаковы, задержки не будет).
Это решение имеет большую степень детализации (по сути, ему нужно только определить, была ли переделана транзакция, здесь всегда определяется, есть ли задержка. Если есть задержка в пиковый период, оно будет ждать решения и). не используется.
- модифицированная репликация главный-подчиненный метод для синхронной репликации: высокая согласованность данных, низкая производительность.
- модифицированная репликация Главный-подчиненный метод полусинхронной репликации: один главный и один подчиненный — то же самое, что и синхронная репликация. Запрос под одним главным и несколькими подчиненными неопределенен и требует определения, была ли переделана транзакция.
Вариант 5 требует детальной оценки того, была ли транзакция переделана на подчиненной машине. Существует два способа, и реализация относительно сложна.
Определить смещение
select master_pos_wait(file, pos,[timeout]) Используется для определения того, превысило ли текущее смещение позицию
file — это файл binlog, pos — смещение, а timeout — время ожидания.
При использовании полусинхронной репликации один подчиненный узел ответил, и другие подчиненные узлы должны вот-вот ответить, поэтому вы можете подождать в течение 50 мс, 100 мс...
Если время ожидания истекло, вы можете снова проверить хост в бизнесе. Следует отметить, что если время ожидания истекло, это эквивалентно повторному обращению к хосту.
С помощью этого SQL вы можете определить, была ли выполнена транзакция, основываясь на смещении в основном журнале базы данных (выполнение возвращает 0):
- Когда операция записи завершена, получается информация о файле binlog и смещении.
- Имея эти два параметра плюс период ожидания, используйте этот SQL, чтобы определить, был ли он выполнен.
- Если возвращается 0 (выполнено), проверьте ведомое устройство, в противном случае проверьте ведущее устройство (обратите внимание на ограничение тока)
Решение GTID
Идея Решения GTID аналогична вышеописанной
select wait_for_executed_gtid_set(gtid_set, [timeout])
Функция SQL — определить, был ли выполнен набор GTID. Он возвращает 0 и 1 после таймаута.
Процесс аналогичен:
- Получить коллекцию GTID во время операции записи
- Определите, выполнило ли ведомое устройство транзакцию на основе набора GTID.
- Запрос выполнен, в противном случае проверьте основную базу данных или ограничьте текущий поток.
архитектура «господин-подчиненный»
Благодаря репликации данных binlog, архитектура «господин-подчиненный» может быть очень богатой и использоваться по своему усмотрению.
Один ведущий и один подчиненный: главный отвечает за запись, а подчиненный отвечает за чтение, а давление чтения и записи делится поровну.
Один ведущий и несколько подчиненных устройств: главный отвечает за запись, а подчиненные — за чтение. Подходит больше для чтения, чем для записи.
Горячий резерв с двойным главным устройством: два узла являются ведущими и подчиненными друг для друга, а давление чтения и записи разделено поровну, но существует проблема синхронизации цикла.
Когда узлы AB являются ведомыми друг для друга, A получает запрос на запись и ему необходимо повторить журнал бункера для B. После того, как B переделает его (эквивалентно запросу на запись), B перепишет журнал бункера для A, что приведет к для циклической синхронизации данных.
Перенос идентификатора узла (идентификатора сервера) при синхронизации данных решает проблему циклической синхронизации.
A получает запрос на запись и передает binlog B со своим собственным идентификатором. После того, как B переделывает его, он передает binlog A. A обнаруживает, что идентификатор сервера в binlog является его собственным, и не переделывает его.
Подвести итог
Эта статья начинается с высокой доступности MySQL и рассказывает о репликации в MySQL. главный-подчиненный、выключатель、Задерживать、Архитектура и т. д.
Формат операторов binlog-записей SQL. Объем данных небольшой, передача быстрая, но это может привести к несогласованности данных.
Формат строки binlog записывает измененные данные. Объем данных большой, и передача данных происходит медленно. Неправильную работу данных можно исправить.
Смешанный бинлог использует преимущества оператора и строки, но это все равно приведет к несогласованности данных в доступных стратегиях.
репликация При главном подчиненном поток дампа хоста отслеживает уведомление об изменении binlog и извлекает его из подчиненного устройства, а поток ввода-вывода подчиненного устройства записывает журнал в Realy. журнал ретрансляции журнала, а затем поток sql анализирует данные повторного выполнения журнала
Синхронная репликация требует, чтобы все подчиненные устройства реагировали, и имеет высокую согласованность, но имеет худшую производительность.
Асинхронная репликация по умолчанию имеет лучшую производительность, но может страдать от задержек в обеспечении согласованности данных.
Полусинхронная репликация требует ответа только от одного подчиненного устройства. Производительность нескольких подчиненных устройств выше, чем при синхронной репликации.
Расширенная полусинхронная репликация будет фиксировать транзакции только при ответе подчиненного устройства, что немного лучше, чем полусинхронная репликация.
Отложенная репликация позволяет ведомому устройству задержать повторную обработку данных на определенный период времени, и данные могут быть восстановлены после неправильной работы.
Переключение главный-подчиненныйчасможет только удовлетворитьCAPДвое из них,Достижение надежности приведет к невозможности записи в течение определенного периода времени.,Могут возникнуть несоответствия данных, если они доступны.
Настройте параметры и конфигурацию подчиненного устройства такими же, как у главного, и избегайте использования больших транзакций, чтобы главный-подчиненный не был слишком длинным.
Если задержка главного-подчиненного слишком длинная, вы можете расширить возможности ввода-вывода, отрегулировав параметры подчиненного ввода-вывода.
При возникновении проблем с согласованностью данных из-за задержки главный-подчиненный:
- коммуникационный бизнес,Могу ли я использовать промежуточные состояния, такие как просмотр?,ждать Задерживать Проверьте еще раз после
- Принудительно удалите хост, обратите внимание, что давление может быть слишком большим.
- Использование синхронной репликации, низкая производительность
- При использовании полусинхронной репликации одному ведущему и нескольким ведомым устройствам необходимо определить, выполняется ли транзакция (смещение/GTID), что сложно реализовать.
Часто используемая архитектура «господин-подчиненный» имеет: один ведущий и один ведомый, один ведущий и несколько ведомых, горячий резерв с двумя главными устройствами (через сервер id решает проблему синхронизации цикла)...
Наконец (не делайте этого просто так, просто нажмите три раза подряд, чтобы попросить о помощи~)
Эта статья включена в рубрику MySQL расширенныйдорога,заинтересованныйиз Студенты могут продолжитьсосредоточиться наох
Примечания и случаи этой статьи включены gitee-StudyJava、 github-StudyJava Заинтересованные студенты могут следить за статистикой и продолжать обращать внимание~
Если у вас есть какие-либо вопросы, вы можете обсудить их в области комментариев. Если вы считаете, что письмо Цай Цая хорошее, вы можете поставить лайк, подписаться на него и собрать его, чтобы поддержать его ~
Следите за Цай Цаем и делитесь более полезной информацией, общедоступный аккаунт: внутренняя кухня Цай Цая.
Я участвую в последнем конкурсе эссе для специального учебного лагеря Tencent Technology Creation 2024. Приходите и разделите со мной приз!



Углубленный анализ переполнения памяти CUDA: OutOfMemoryError: CUDA не хватает памяти. Попыталась выделить 3,21 Ги Б (GPU 0; всего 8,00 Ги Б).

[Решено] ошибка установки conda. Среда решения: не удалось выполнить первоначальное зависание. Повторная попытка с помощью файла (графическое руководство).

Прочитайте нейросетевую модель Трансформера в одной статье

.ART Теплые зимние предложения уже открыты

Сравнительная таблица описания кодов ошибок Amap

Уведомление о последних правилах Points Mall в декабре 2022 года.

Даже новички могут быстро приступить к работе с легким сервером приложений.

Взгляд на RSAC 2024|Защита конфиденциальности в эпоху больших моделей

Вы используете ИИ каждый день и до сих пор не знаете, как ИИ дает обратную связь? Одна статья для понимания реализации в коде Python общих функций потерь генеративных моделей + анализ принципов расчета.

Используйте (внутренний) почтовый ящик для образовательных учреждений, чтобы использовать Microsoft Family Bucket (1T дискового пространства на одном диске и версию Office 365 для образовательных учреждений)

Руководство по началу работы с оперативным проектом (7) Практическое сочетание оперативного письма — оперативного письма на основе интеллектуальной системы вопросов и ответов службы поддержки клиентов

[docker] Версия сервера «Чтение 3» — создайте свою собственную программу чтения веб-текста

Обзор Cloud-init и этапы создания в рамках PVE

Корпоративные пользователи используют пакет регистрационных ресурсов для регистрации ICP для веб-сайта и активации оплаты WeChat H5 (с кодом платежного узла версии API V3)

Подробное объяснение таких показателей производительности с высоким уровнем параллелизма, как QPS, TPS, RT и пропускная способность.

Удачи в конкурсе Python Essay Challenge, станьте первым, кто испытает новую функцию сообщества [Запускать блоки кода онлайн] и выиграйте множество изысканных подарков!

[Техническая посадка травы] Кровавая рвота и отделка позволяют вам необычным образом ощипывать гусиные перья! Не распространяйте информацию! ! !

[Официальное ограниченное по времени мероприятие] Сейчас ноябрь, напишите и получите приз

Прочтите это в одной статье: Учебник для няни по созданию сервера Huanshou Parlu на базе CVM-сервера.

Cloud Native | Что такое CRD (настраиваемые определения ресурсов) в K8s?

Как использовать Cloudflare CDN для настройки узла (CF самостоятельно выбирает IP) Гонконг, Китай/Азия узел/сводка и рекомендации внутреннего высокоскоростного IP-сегмента

Дополнительные правила вознаграждения амбассадоров акции в марте 2023 г.

Можно ли открыть частный сервер Phantom Beast Palu одним щелчком мыши? Супер простой урок для начинающих! (Прилагается метод обновления сервера)

[Играйте с Phantom Beast Palu] Обновите игровой сервер Phantom Beast Pallu одним щелчком мыши

Maotouhu делится: последний доступный внутри страны адрес склада исходного образа Docker 2024 года (обновлено 1 декабря)

Кодирование Base64 в MultipartFile

5 точек расширения SpringBoot, супер практично!

Глубокое понимание сопоставления индексов Elasticsearch.

15 рекомендуемых платформ разработки с нулевым кодом корпоративного уровня. Всегда найдется та, которая вам понравится.
