Использование преимуществ серии AI: Технический анализ ключевой роли глубокого обучения в AIGC
AIGC (контент, генерируемый искусственным интеллектом) — это важный прорыв в современной области искусственного интеллекта, который используется при создании контента, такого как текст, изображения, аудио и видео. Технология глубокого обучения играет ключевую роль в AIGC, предоставляя мощные модели и алгоритмы, которые могут автоматически изучать закономерности в данных и генерировать новый контент. В этой статье будет представлен подробный анализ основных принципов технологии глубокого обучения, ее применения в AIGC и связанных с ней примеров кода.
1. Обзор технологии глубокого обучения
1.1 Основные принципы глубокого обучения
Глубокое обучение — это метод машинного обучения с искусственной нейронной сетью в качестве ядра. Он абстрагирует и извлекает особенности данных слой за слоем с помощью многоуровневых нейронных сетей. Модели глубокого обучения обновляют веса с помощью алгоритма обратного распространения ошибки, что позволяет модели постоянно обучаться и повышать точность. Общие архитектуры глубокого обучения включают сверточные нейронные сети (CNN), рекуррентные нейронные сети (RNN), генеративно-состязательные сети (GAN) и т. д.
1.2 Преимущества глубокого обучения при создании контента
Преимущество глубокого обучения в AIGC заключается в его мощной способности к обучению, которая позволяет изучать сложные закономерности на основе больших объемов данных и генерировать высококачественный текст, изображения, аудио и другой контент. С помощью предварительно обученных моделей (таких как GPT, DALL·E, StyleGAN и т. д.) глубокое обучение может генерировать креативный и персонализированный контент, чего трудно достичь с помощью традиционных алгоритмов.
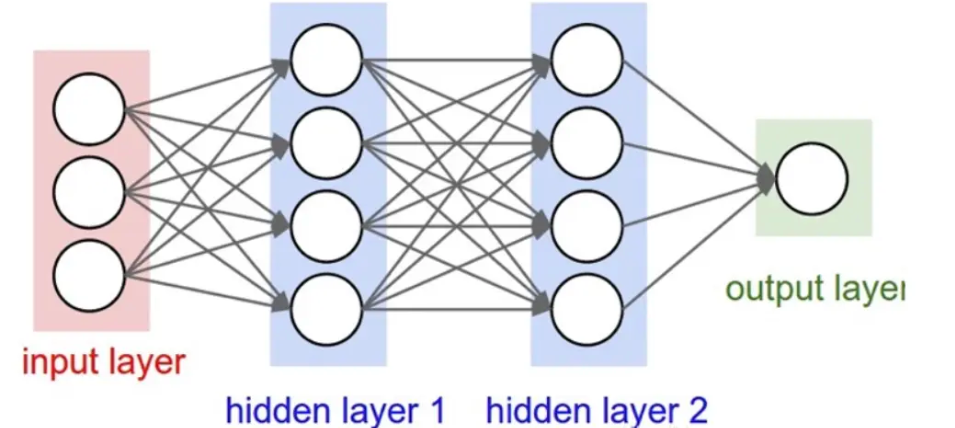
2. Применение глубокого обучения в AIGC
2.1 Генерация текста
Генерация текста является важной областью применения AIGC. Использование моделей глубокого обучения, таких как GPT (генеративная модель предварительного обучения), позволяет генерировать контекстно-зависимый текст на естественном языке. Эти модели обучаются на больших объемах текстовых данных и могут генерировать насыщенные, грамматически правильные статьи, разговоры и даже стихи.
2.2 Генерация изображения
Глубокое обучение позволило добиться замечательных достижений в области генерации изображений с помощью генеративно-состязательных сетей (GAN). GAN состоит из двух сетей: генератора и дискриминатора. Генератор отвечает за генерацию изображений, а дискриминатор — за различение истинных и ложных изображений. Посредством взаимных игр GAN может генерировать высококачественные изображения, такие как генерация лиц, передача художественного стиля и т. д.
2.3 Генерация аудио и видео
Глубокое обучение также играет важную роль в создании аудио и видео. Модели на основе RNN или Transformer могут генерировать реалистичную речь или даже голос конкретного человека. В области создания видео модели глубокого обучения могут синтезировать новые действия или сцены, тем самым обеспечивая автоматическое производство и редактирование видео.
3. Примеры технологий генерации глубокого обучения
В этом разделе мы рассмотрим генерацию текста и изображений в качестве примеров, чтобы продемонстрировать практическое применение глубокого обучения в AIGC.
3.1 Пример генерации текста на основе GPT-2
GPT-2 Это одна из классических моделей глубокого обучения для генерации текста. Код ниже показывает, как использовать Hugging. FaceизtransformersБиблиотека для генерации текста на естественном языке:
from transformers import GPT2LMHeadModel, GPT2Tokenizer
# Загрузите предварительно обученную модель и токенизатор
model_name = 'gpt2'
model = GPT2LMHeadModel.from_pretrained(model_name)
tokenizer = GPT2Tokenizer.from_pretrained(model_name)
# Напишите текст подсказки
input_text = "Artificial intelligence is revolutionizing"
input_ids = tokenizer.encode(input_text, return_tensors='pt')
# генерировать текст
output = model.generate(input_ids, max_length=100, num_return_sequences=1)
# Раскодируйте сгенерированный текст
generated_text = tokenizer.decode(output[0], skip_special_tokens=True)
print("Generated Text:\n", generated_text)объяснять:
- Для генерации текста мы использовали модель GPT-2 Hugging Face. Сначала мы определяем приглашение для ввода и кодируем его в формат, понятный модели. Затем модель генерирует следующий текст по запросу.
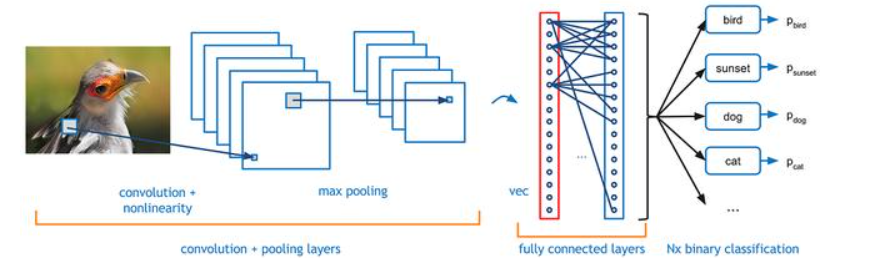
3.2 Пример генерации изображения на основе GAN
При создании изображений GAN является широко используемой моделью. В приведенном ниже коде показано, как генерировать изображения рукописных цифр с помощью инфраструктуры GAN в TensorFlow:
import tensorflow as tf
from tensorflow.keras import layers
import numpy as np
import matplotlib.pyplot as plt
# модель генератора
def build_generator():
model = tf.keras.Sequential()
model.add(layers.Dense(256, input_dim=100))
model.add(layers.LeakyReLU(alpha=0.2))
model.add(layers.Dense(512))
model.add(layers.LeakyReLU(alpha=0.2))
model.add(layers.Dense(1024))
model.add(layers.LeakyReLU(alpha=0.2))
model.add(layers.Dense(28 * 28 * 1, activation='tanh'))
model.add(layers.Reshape((28, 28, 1)))
return model
# модель дискриминатора
def build_discriminator():
model = tf.keras.Sequential()
model.add(layers.Flatten(input_shape=(28, 28, 1)))
model.add(layers.Dense(512))
model.add(layers.LeakyReLU(alpha=0.2))
model.add(layers.Dense(256))
model.add(layers.LeakyReLU(alpha=0.2))
model.add(layers.Dense(1, activation='sigmoid'))
return model
# Модель ГАН
def build_gan(generator, discriminator):
discriminator.trainable = False
model = tf.keras.Sequential([generator, discriminator])
return model
# Загрузить данные MNIST
(x_train, _), (_, _) = tf.keras.datasets.mnist.load_data()
x_train = (x_train - 127.5) / 127.5
x_train = np.expand_dims(x_train, axis=-1)
# Инициализируйте генератор и дискриминатор
generator = build_generator()
discriminator = build_discriminator()
gan = build_gan(generator, discriminator)
# Скомпилировать модель
discriminator.compile(optimizer='adam', loss='binary_crossentropy', metrics=['accuracy'])
gan.compile(optimizer='adam', loss='binary_crossentropy')
# Обучение ГАН
def train_gan(epochs=10000, batch_size=128):
for epoch in range(epochs):
# Обучение дискриминатора
idx = np.random.randint(0, x_train.shape[0], batch_size)
real_imgs = x_train[idx]
noise = np.random.normal(0, 1, (batch_size, 100))
fake_imgs = generator.predict(noise)
real_y = np.ones((batch_size, 1))
fake_y = np.zeros((batch_size, 1))
d_loss_real = discriminator.train_on_batch(real_imgs, real_y)
d_loss_fake = discriminator.train_on_batch(fake_imgs, fake_y)
# обучающий генератор
noise = np.random.normal(0, 1, (batch_size, 100))
valid_y = np.ones((batch_size, 1))
g_loss = gan.train_on_batch(noise, valid_y)
if epoch % 1000 == 0:
print(f"Epoch {epoch}, D Loss Real: {d_loss_real}, D Loss Fake: {d_loss_fake}, G Loss: {g_loss}")
plot_generated_images(epoch, generator)
# создать изображение
def plot_generated_images(epoch, generator, examples=10):
noise = np.random.normal(0, 1, (examples, 100))
generated_imgs = generator.predict(noise)
generated_imgs = 0.5 * generated_imgs + 0.5 # Масштабировать до диапазона [0,1]
plt.figure(figsize=(10, 2))
for i in range(examples):
plt.subplot(1, 10, i + 1)
plt.imshow(generated_imgs[i, :, :, 0], cmap='gray')
plt.axis('off')
plt.show()
# Начать обучение
train_gan()объяснять:
- Модель генератора отвечает за генерацию поддельных изображений, а модель дискриминатора отвечает за различение реальных и поддельных изображений. GAN обучаются путем сопоставления генератора и дискриминатора друг с другом, при этом генератор постоянно улучшает качество генерируемых изображений до тех пор, пока у дискриминатора не возникнут трудности с различением реальных и поддельных изображений.
4. Будущие перспективы глубокого обучения в AIGC
Глубокое обучение привело к быстрому развитию AIGC, но оно все еще находится на ранних стадиях. В будущем, благодаря постоянному расширению масштаба модели и постоянной оптимизации алгоритмов, AIGC не только ограничится генерацией контента, но также войдет в область понимания контента и его расширенного создания. Модели глубокого обучения, такие как Transformer, Diffusion и т. д., также будут играть более важную роль в более сложных задачах создания контента.
5. Глубокие генеративные модели: от GAN до Transformer
В AIGC глубокие генеративные модели являются одной из основных движущих сил. Эволюция генеративных моделей сопровождалась технологическим прогрессом глубокого обучения, постепенно расширяющимся от традиционной генеративно-состязательной сети (GAN) до широко используемой в настоящее время архитектуры Transformer.
5.1 Генеративно-состязательная сеть (GAN)
Генеративно-состязательная сеть (GAN) — знаковая технология в области AIGC. GAN состоит из двух частей: генератора и дискриминатора. Генератор генерирует изображения посредством случайного шума, а дискриминатор пытается определить, является ли изображение реальным или сгенерированным. Оба процесса вместе продвигаются через состязательное обучение, где цель генератора — сделать дискриминатор неспособным различать настоящие и поддельные изображения.
Хотя GAN успешно генерирует высококачественные изображения, у него есть некоторые ограничения, такие как нестабильное обучение, склонность к сбоям и неспособность эффективно обрабатывать сложные мультимодальные данные. Однако новаторские идеи GAN заложили основу для глубоких генеративных моделей и вдохновили на разработку последующих более сложных моделей.
Пример кода: создание изображений художественного стиля на основе GAN
Объединив систему глубокого обучения и предварительно обученную модель, можно добиться создания изображений в художественном стиле. Следующий код реализует простую генерацию стилизованного изображения на основе GAN:
import tensorflow as tf
from tensorflow.keras import layers
import numpy as np
# Модель определения генератора
def build_generator():
model = tf.keras.Sequential()
model.add(layers.Dense(256, input_dim=100))
model.add(layers.LeakyReLU(alpha=0.2))
model.add(layers.Dense(512))
model.add(layers.LeakyReLU(alpha=0.2))
model.add(layers.Dense(1024))
model.add(layers.LeakyReLU(alpha=0.2))
model.add(layers.Dense(28 * 28 * 1, activation='tanh'))
model.add(layers.Reshape((28, 28, 1)))
return model
# Дискриминатор и генератор конкурируют друг с другом за создание стилизованных изображений.
generator = build_generator()
noise = np.random.normal(0, 1, (1, 100))
generated_image = generator.predict(noise)
# Нарисуйте полученное изображение
import matplotlib.pyplot as plt
plt.imshow(generated_image[0, :, :, 0], cmap='gray')
plt.show()объяснять: Приведенный выше код показывает простую архитектуру генератора. Благодаря состязательному обучению этот тип генератора может создавать изображения художественного стиля.
5.2 Генеративная модель на основе Трансформера
Успех модели Трансформера в области обработки естественного языка (НЛП) привел к ее широкому применению в AIGC, особенно в задачах мультимодальной генерации. В отличие от GAN, Transformer использует механизм самоконтроля, который может фиксировать долгосрочные зависимости во время обработки, что делает процесс генерации более эффективным. В последние годы генеративные модели на основе Transformer (такие как GPT, BERT, DALL·E, CLIP и т. д.) продемонстрировали большой потенциал и могут решать самые разные задачи — от генерации текста до генерации изображений.
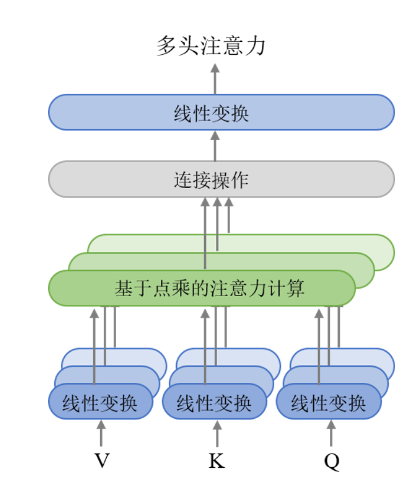
5.2.1 Применение GPT при генерации текста
Серия GPT (Generative Pre-trained Transformer) — важное применение архитектуры Transformer в области генерации текста. Он учится генерировать контент, контекстуально соответствующий входным данным, посредством самостоятельного обучения на основе крупномасштабных текстовых данных. По сравнению с GAN, модель Transformer обладает более сильными возможностями понимания контекста и может генерировать более длинные тексты с более высокой связностью.
Ниже показан пример генерации текста на основе GPT:
from transformers import GPT2LMHeadModel, GPT2Tokenizer
# Загрузите предварительно обученную модель и токенизатор
model = GPT2LMHeadModel.from_pretrained('gpt2')
tokenizer = GPT2Tokenizer.from_pretrained('gpt2')
# Введите текст подсказки
prompt = "Deep learning is revolutionizing artificial intelligence"
input_ids = tokenizer.encode(prompt, return_tensors='pt')
# генерировать текст
output = model.generate(input_ids, max_length=100, num_return_sequences=1)
generated_text = tokenizer.decode(output[0], skip_special_tokens=True)
# Вывод сгенерированного текста
print(generated_text)объяснять: С помощью модели GPT вводится простой текст подсказки, и модель может генерировать высококачественный последующий контент на основе контекста. Этот тип технологии генерации текста широко используется в диалоговых системах, автоматическом написании, генерации новостей и других областях.
5.2.2 DALL·E и мультимодальная генерация
DALL·E — это модель генерации изображений на основе преобразователя, предложенная OpenAI, которая может генерировать соответствующие изображения на основе текстовых описаний. Инновация DALL·E заключается в том, что она объединяет мультимодальность текста и изображений в одной модели и совместно обучает модель понимать текст и генерировать изображения. Этот тип технологий имеет большое значение для будущего творческого поколения, рекламного дизайна, редактирования изображений и других областей.
Рабочий механизм DALL·E основан на двух основных частях: кодировщике текста и декодере изображений. Кодер текста преобразует текст в векторное представление, а декодер изображения генерирует соответствующее изображение на основе вектора. Эта архитектура превосходно подходит для создания разнообразного и высококачественного контента.
6. Передовые применения других технологий глубокого обучения в AIGC
Помимо GAN и Transformer, другие отрасли глубокого обучения также нашли важное применение в AIGC.
6.1 Авторегрессионные модели
Модели авторегрессии имеют широкое применение в задачах генерации последовательностей, таких как генерация речи и прогнозирование временных рядов. Генерируя текущие выходные данные на каждом этапе и используя их в качестве входных данных для следующего шага, модель способна генерировать высокосвязное содержимое последовательности.
WaveNet — это типичное применение авторегрессионных моделей при генерации звука. Он генерирует высококачественную речь и музыку посредством пошагового прогнозирования форм звуковых сигналов. Подобные технологии имеют широкие перспективы применения в таких сценариях, как голосовые помощники и виртуальные певцы в области AIGC.
6.2 Модели диффузии
Модель диффузии — это новая технология, появившаяся в области генерации изображений в последние годы. Он генерирует высококачественные реалистичные изображения, изучая распределение шума и обратно генерируя изображения. По сравнению с GAN, модель диффузии более стабильна в процессе обучения, а качество создаваемого изображения также выше.
Появление диффузионных моделей открывает новые возможности для художественного творчества и создания изображений. В будущем модель диффузии будет объединена с архитектурой Transformer, чтобы обеспечить более эффективные и качественные эффекты генерации в области AIGC.
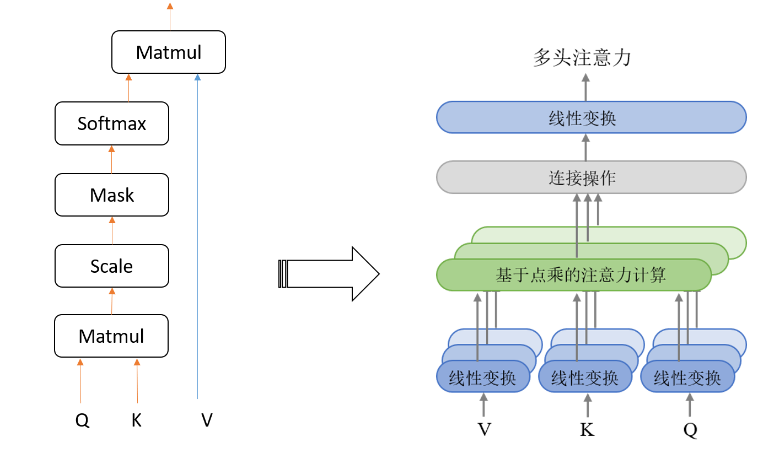
7. Будущие тенденции глубокого обучения и AIGC
Применение глубокого обучения в AIGC быстро расширяется, и будущие тенденции будут сосредоточены на эффективности моделей, мультимодальном слиянии и улучшении качества генерации. Вот некоторые возможные будущие технологические направления:
7.1 Облегчение и оптимизация модели
Современные глубокие генеративные модели, как правило, огромны по масштабу, требуют много времени для обучения и потребляют много ресурсов. Будущие исследования будут сосредоточены на облегчении и оптимизации моделей, особенно в сценариях с ограниченными ресурсами, а также на том, как повысить эффективность за счет сжатия моделей, дистилляции и других технологий.
7.2 Технология мультимодальной генерации
Технология мультимодальной генерации, такая как DALL·E, изначально показала свой потенциал, но в более сложных сценариях эффективность унифицированной обработки нескольких модальностей, таких как текст, изображение, видео и аудио, по-прежнему остается серьезной проблемой для AIGC. будущий вызов. Благодаря более мощным мультимодальным моделям Transformer системы будущего поколения будут иметь более широкие возможности генерации контента.
7.3 Совместное творчество человека и машины
Глубокое обучение может не только автоматически генерировать контент, но и сотрудничать с создателями-людьми, чтобы вдохновлять и предлагать идеи. В будущем система AIGC будет все больше сотрудничать с человеком и станет вспомогательным инструментом в творческом процессе, помогая художникам, писателям и т. д. выполнять сложные творческие задачи.
Подвести итог
Глубокое обучение играет ключевую роль в области AIGC (контента, сгенерированного искусственным интеллектом), обеспечивая реализацию задач мультимодальной генерации — от генерации изображений до генерации текста. Инновации GAN проложили путь в технологии генерации изображений, а внедрение Transformers позволило генеративным моделям генерировать высококачественный текст и изображения в более широком диапазоне контекстов. Благодаря GPT, DALL·E и другим моделям архитектуры Transformer компания AIGC продемонстрировала большой творческий потенциал, особенно в мультимодальном сочетании генеративного текста и изображений. В то же время другие технологии глубокого обучения, такие как авторегрессионные модели и модели диффузии, продолжают обогащать сценарии применения AIGC и хорошо справляются с задачами генерации речи, изображений и других задач.
В будущем тенденция развития глубокого обучения в AIGC будет вращаться вокруг упрощения моделей, развития технологий мультимодальной генерации и совместного творчества человека и машины. Поскольку эффективность моделей и качество генерации продолжают улучшаться, ожидается, что AIGC станет незаменимым творческим инструментом в искусстве, рекламе, новостях и других отраслях, что будет способствовать дальнейшим изменениям в автоматизированной генерации контента.



Учебное пособие по Jetpack Compose для начинающих, базовые элементы управления и макет

Код js веб-страницы, фон частицы, код спецэффектов

【новый! Суперподробное】Полное руководство по свойствам компонентов Figma.

🎉Обязательно к прочтению новичкам: полное руководство по написанию мини-программ WeChat с использованием программного обеспечения Cursor.

[Забавный проект Docker] VoceChat — еще одно приложение для мгновенного чата (IM)! Может быть встроен в любую веб-страницу!

Как реализовать переход по странице в HTML (html переходит на указанную страницу)

Как решить проблему зависания и низкой скорости при установке зависимостей с помощью npm. Существуют ли доступные источники npm, которые могут решить эту проблему?

Серия From Zero to Fun: Uni-App WeChat Payment Practice WeChat авторизует вход в систему и украшает страницу заказа, создает интерфейс заказа и инициирует запрос заказа

Серия uni-app: uni.navigateЧтобы передать скачок значения

Апплет WeChat настраивает верхнюю панель навигации и адаптируется к различным моделям.

JS-время конвертации

Обеспечьте бесперебойную работу ChromeDriver 125: советы по решению проблемы chromedriver.exe не найдены

Поле комментария, щелчок мышью, специальные эффекты, js-код

Объект массива перемещения объекта JS

Как открыть разрешение на позиционирование апплета WeChat_Как использовать WeChat для определения местонахождения друзей

Я даю вам два набора из 18 простых в использовании фонов холста Power BI, так что вам больше не придется возиться с цветами!

Получить текущее время в js_Как динамически отображать дату и время в js

Вам необходимо изучить сочетания клавиш vsCode для форматирования и организации кода, чтобы вам больше не приходилось настраивать формат вручную.

У ChatGPT большое обновление. Всего за 45 минут пресс-конференция показывает, что OpenAI сделал еще один шаг вперед.

Copilot облачной разработки — упрощение разработки

Микросборка xChatGPT с низким кодом, создание апплета чат-бота с искусственным интеллектом за пять шагов

CUDA Out of Memory: идеальное решение проблемы нехватки памяти CUDA

Анализ кластеризации отдельных ячеек, который должен освоить каждый&MarkerгенетическийВизуализация

vLLM: мощный инструмент для ускорения вывода ИИ

CodeGeeX: мощный инструмент генерации кода искусственного интеллекта, который можно использовать бесплатно в дополнение к второму пилоту.

Машинное обучение Реальный бой LightGBM + настройка параметров случайного поиска: точность 96,67%

Бесшовная интеграция, мгновенный интеллект [1]: платформа больших моделей Dify-LLM, интеграция без кодирования и встраивание в сторонние системы, более 42 тысяч звезд, чтобы стать свидетелями эксклюзивных интеллектуальных решений.

LM Studio для создания локальных больших моделей

Как определить количество слоев и нейронов скрытых слоев нейронной сети?
