Использование преимуществ серии AI: AI расширяет возможности редактирования видео: как технология автоматизации меняет создание контента
Видео стало одной из самых распространенных форм выражения в современном мире производства контента, однако редактирование видео часто представляет собой трудоемкий и сложный процесс. Благодаря быстрому развитию контента, генерируемого искусственным интеллектом (AIGC), технология интеллектуального редактирования видео постепенно стала мощным инструментом для повышения эффективности редактирования видео. В этой статье мы углубимся в то, как искусственный интеллект повышает эффективность редактирования видео, продемонстрируем реализацию связанных технологий и объясним конкретный процесс работы на примерах кода.
1. Что такое умное редактирование видео?
Интеллектуальное редактирование видео — это технология, которая использует технологию искусственного интеллекта для автоматизации и интеллектуального управления процессом редактирования видео. Он не только помогает редакторам автоматически обрезать видео, но также автоматически добавляет специальные эффекты, музыку, субтитры и генерирует полный видеоконтент на основе предустановленных стилей и стратегий редактирования.
1.1 Основные функции интеллектуального редактирования видео
- Автоматически обрезать клипы:проходитьAIАнализируйте видеоконтент,Автоматически находите лучшую точку редактирования и обрезайте видеоклипы.
- Распознавание и классификация сцен:на основетехнология компьютерного зрения,ИИ может определять различные сценарии,И провести классификационную обработку.
- Соответствие эмоций и контента:Основано на эмоциях и ритме видео.,ИИ может автоматически выбирать подходящую фоновую музыку, субтитры и спецэффекты.
1.2 Разница между AIGC и традиционным редактированием
Традиционное редактирование основано на ручных операциях редактора и требует множества ручных корректировок на временной шкале. Технология AIGC может автоматически решать эти утомительные задачи посредством обучения алгоритмов машинного обучения, что значительно сокращает производственный цикл и снижает затраты на рабочую силу.
2. Принцип реализации технологии видеомонтажа AI.
Ключом к технологии интеллектуального редактирования видео являются несколько основных технологий искусственного интеллекта: компьютерное зрение, обработка естественного языка (NLP) и модели машинного обучения. Ниже мы шаг за шагом объясним, как эти технологии играют роль в интеллектуальном редактировании видео.
2.1 Технология компьютерного зрения
Компьютерное зрение идентифицирует ключевой контент, такой как персонажи, переходы между сценами, действия и эмоции, анализируя каждый кадр видео. Это позволяет ИИ автоматически обнаруживать важные сегменты видео и предоставлять основу для последующего редактирования.
import cv2
import numpy as np
# Загрузить видео
cap = cv2.VideoCapture('input_video.mp4')
# Чтение кадров видео
while cap.isOpened():
ret, frame = cap.read()
if not ret:
break
# Использование OpenCV для обнаружения сцен (например, обнаружения переключения сцен)
gray_frame = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
# Простой алгоритм обнаружения сцены
edges = cv2.Canny(gray_frame, 100, 200)
cv2.imshow('Scene Detection', edges)
if cv2.waitKey(1) & 0xFF == ord('q'):
break
cap.release()
cv2.destroyAllWindows()В приведенном выше коде мы используем библиотеку OpenCV для загрузки и обработки видео для простого обнаружения краев. Это фундаментальный шаг в анализе компьютерного зрения при интеллектуальном редактировании видео.
2.2 НЛП и автоматическое создание видеосубтитров
Помимо визуальной информации, видеоролики часто содержат большое количество голосового контента. С помощью технологии обработки естественного языка ИИ может автоматически генерировать субтитры, соответствующие видеоконтенту, и редактировать видео на основе интонации голоса и содержания.
import speech_recognition as sr
# Создание распознавателя речи
recognizer = sr.Recognizer()
# Загрузить аудиофайлы
with sr.AudioFile('audio_clip.wav') as source:
audio_data = recognizer.record(source)
# Используйте Google API для распознавания речи и преобразования в текст.
text = recognizer.recognize_google(audio_data)
print(f"Автоматически сгенерированные субтитры: {text}")вышекодпоказывает, как использоватьPythonизspeech_recognitionБиблиотека будет в видеоиз Конвертировать аудио в субтитры。Этот шаг может значительно сэкономить ручной ввод субтитров при редактировании видео.извремя。
2.3 Машинное обучение и автоматическое редактирование
Алгоритмы машинного обучения могут автоматически идентифицировать важные сегменты видео, такие как боевые сцены, переходные абзацы и т. д., обучаясь на больших объемах данных. Обычно используемые алгоритмы включают сверточные нейронные сети (CNN) в глубоком обучении, которые могут выявлять закономерности в видео и выполнять интеллектуальную обработку.
Например, обучив классификатор видео распознавать боевые сцены:
from keras.models import Sequential
from keras.layers import Dense, Conv2D, MaxPooling2D, Flatten
from keras.preprocessing.image import ImageDataGenerator
# Создайте простую сверточную нейронную сеть (CNN).
model = Sequential()
model.add(Conv2D(32, (3, 3), activation='relu', input_shape=(64, 64, 3)))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Flatten())
model.add(Dense(units=128, activation='relu'))
model.add(Dense(units=1, activation='sigmoid'))
# Скомпилировать модель
model.compile(optimizer='adam', loss='binary_crossentropy', metrics=['accuracy'])
# Подготовьте данные обучения с помощью инструментов увеличения данных.
train_datagen = ImageDataGenerator(rescale=1./255)
training_set = train_datagen.flow_from_directory('video_frames', target_size=(64, 64), batch_size=32, class_mode='binary')
# Модель обучения
model.fit(training_set, steps_per_epoch=100, epochs=5)В этом примере кода показано, как использовать сверточную нейронную сеть (CNN) для создания простой модели классификации сцен действия, которая поможет ИИ идентифицировать важные клипы в видео, тем самым обеспечивая автоматическое редактирование.
3. Сценарии применения интеллектуального редактирования видео.
Технология интеллектуального редактирования видео не ограничивается автоматическим редактированием, ее также можно применять в следующих сценариях:
3.1 Быстро создавайте видеоролики для социальных сетей
Учитывая популярность платформ для коротких видео, создателям контента необходимо создавать большое количество видеороликов за короткий период времени. Интеллектуальная технология редактирования видео может автоматически генерировать видеоконтент, соответствующий требованиям платформ социальных сетей, снижая нагрузку на редакторов.
3.2 Автоматическое создание трейлеров к фильмам
В киноиндустрии интеллектуальные технологии монтажа позволяют автоматически анализировать содержание фильмов и создавать трейлеры к ним, отвечающие ожиданиям аудитории. Благодаря искусственному интеллекту, определяющему эмоции и ключевые сцены, трейлеры могут эффективно демонстрировать основные моменты фильма.
3.3 Онлайн-обучение и обучающие видеоролики
В сфере онлайн-образования интеллектуальное редактирование видео может автоматически превращать длинные видеокурсы в необходимый контент или автоматически создавать видеоролики в стиле лекций на основе учебного контента для повышения эффективности обучения.
4. Будущее развитие редактирования видео с помощью искусственного интеллекта
С дальнейшим развитием технологий искусственного интеллекта интеллектуальное редактирование видео станет более точным и персонализированным. В будущем технология редактирования видео с использованием искусственного интеллекта сможет автоматически генерировать персонализированный контент для редактирования на основе интересов, хобби и эмоциональной обратной связи аудитории. Кроме того, с увеличением вычислительной мощности станет возможным интеллектуальное редактирование в реальном времени.
4.1 Расширенные инструменты редактирования, взаимодействующие с ИИ
Будущие инструменты редактирования видео будут больше ориентированы на сотрудничество между ИИ и редакторами. ИИ может не только автоматически выполнять простые задачи редактирования, но также выполнять более сложные настройки сюжета и конструкции переходов в соответствии с инструкциями редактора.
4.2 Мультимодальное редактирование
Будущая технология интеллектуального редактирования видео также будет поддерживать мультимодальный анализ, способный не только идентифицировать визуальный и аудиоконтент, но и обрабатывать текст, эмоции и внешние отзывы, что еще больше повысит интеллектуальность видеопроизводства.
5. Проблемы интеллектуального редактирования видео
Хотя интеллектуальная технология редактирования видео приносит много удобств, она по-прежнему сталкивается с некоторыми проблемами при практическом применении. Эти проблемы включают в себя сложность понимания видеоконтента, сложность обработки в реальном времени и ограничения персонализированного редактирования. Чтобы ИИ мог лучше служить создателям контента, крайне важно решить эти проблемы.
5.1 Сложность понимания видеоконтента
Понимание видеоконтента предполагает комплексную обработку мультимодальной информации, включающей визуальную, звуковую и текстовую. Хотя существующие технологии искусственного интеллекта могут распознавать определенные сцены и объекты, способности искусственного интеллекта к пониманию все еще недостаточны, когда речь идет о сложных сценах или высокохудожественных фильмах. Например, при редактировании эмоциональных сцен ИИ часто испытывает трудности с точной оценкой эмоциональных поворотных моментов и эмоционального напряжения.
Решение: мультимодальное глубокое обучение
Мультимодальная технология глубокого обучения может улучшить комплексное понимание видеоконтента ИИ за счет интеграции изображений, аудио и текстовых данных. Вот простой пример кода, показывающий, как использовать TensorFlow для обработки мультимодальных данных:
import tensorflow as tf
from tensorflow.keras import layers
# Ввод изображения
image_input = tf.keras.Input(shape=(64, 64, 3), name='image_input')
x1 = layers.Conv2D(32, (3, 3), activation='relu')(image_input)
x1 = layers.MaxPooling2D(pool_size=(2, 2))(x1)
x1 = layers.Flatten()(x1)
# Ввод текста
text_input = tf.keras.Input(shape=(100,), name='text_input')
x2 = layers.Embedding(input_dim=5000, output_dim=64)(text_input)
x2 = layers.LSTM(128)(x2)
# Аудиовход
audio_input = tf.keras.Input(shape=(500,), name='audio_input')
x3 = layers.Dense(128, activation='relu')(audio_input)
# Объединить мультимодальный ввод
combined = layers.concatenate([x1, x2, x3])
output = layers.Dense(1, activation='sigmoid')(combined)
# Создать модель
model = tf.keras.Model(inputs=[image_input, text_input, audio_input], outputs=output)
model.compile(optimizer='adam', loss='binary_crossentropy', metrics=['accuracy'])
# Распечатать структуру модели
model.summary()Приведенный выше код показывает, как построить простую мультимодальную модель, которая сочетает в себе ввод изображений, текста и аудио, что может помочь ИИ более полно понять сложный контент в видео.
5.2 Сложность обработки в реальном времени
Редактирование видео включает в себя большую обработку данных, особенно при работе с видео высокого разрешения или длительными видео, что делает обработку в реальном времени огромной проблемой. Существующие системы искусственного интеллекта часто требуют предварительной обработки и автономных вычислений и не могут реагировать в режиме реального времени, что особенно важно в таких прикладных сценариях, как редактирование видео в реальном времени.
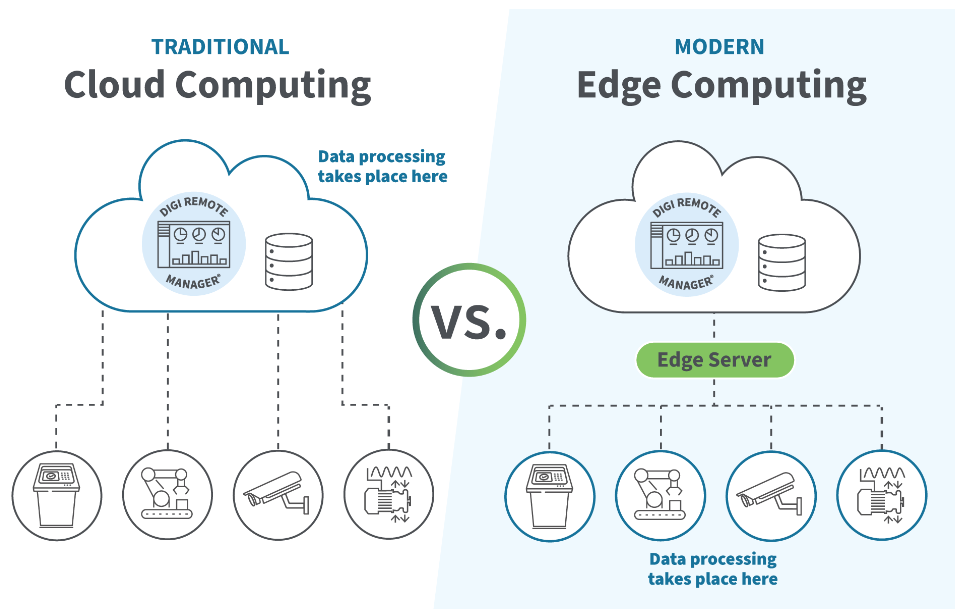
Решение: периферийные вычисления и модели оптимизации
Технология периферийных вычислений может распределить некоторые вычислительные задачи на локальные устройства или пограничные узлы, снижая нагрузку на центральные серверы и обеспечивая более быстрое время отклика. В то же время с помощью таких технологий, как сжатие модели, сокращение и количественная оценка, можно снизить вычислительную сложность модели и дополнительно повысить эффективность обработки в реальном времени.
Например, используйте TensorFlow Lite для сжатия и ускорения модели:
import tensorflow as tf
# Загрузка предварительной модели обучения
model = tf.keras.models.load_model('my_model.h5')
# Преобразование в TensorFlow Облегченный формат
converter = tf.lite.TFLiteConverter.from_keras_model(model)
tflite_model = converter.convert()
# Сохраните модель как файл .tflite.
with open('model.tflite', 'wb') as f:
f.write(tflite_model)Преобразовав модель в облегченный формат TensorFlow Lite, мы можем запускать ее на мобильных или периферийных устройствах, что позволяет более эффективно редактировать видео.
5.3 Ограничения персонализированного редактирования
Большинство современных стратегий интеллектуального редактирования видео основаны на общих правилах, которые сложно удовлетворить индивидуальные потребности каждого пользователя. Например, пользователи могут захотеть редактировать видео в разных стилях и эмоциональных тонах, но ИИ часто не может понять это субъективное предпочтение.
Решение: адаптивное редактирование, основанное на отзывах пользователей.
Внедряя механизм обратной связи с пользователем, ИИ может адаптивно обучаться в соответствии с предпочтениями пользователя и постепенно корректировать стратегию редактирования. Например, процесс редактирования можно оптимизировать с помощью обучения с подкреплением, что позволит ИИ автоматически корректироваться на основе оценок пользователей или отзывов.
Вот простой пример обучения с подкреплением, показывающий, как оптимизировать стратегию отсечения с помощью обратной связи:
import numpy as np
# Определить среду обучения с подкреплением
class VideoEditingEnv:
def __init__(self):
self.state = np.random.rand(10)
self.steps = 0
def step(self, action):
reward = np.random.choice([1, -1]) # Имитация обратной связи с пользователем
self.steps += 1
done = self.steps >= 10
return self.state, reward, done
def reset(self):
self.steps = 0
return np.random.rand(10)
# Обучение с помощью Q-learning
class QLearningAgent:
def __init__(self, n_actions, n_states):
self.q_table = np.zeros((n_states, n_actions))
self.learning_rate = 0.1
self.discount_factor = 0.9
self.exploration_rate = 0.1
def choose_action(self, state):
if np.random.rand() < self.exploration_rate:
return np.random.choice([0, 1]) # Случайный выбор действий
return np.argmax(self.q_table[state])
def learn(self, state, action, reward, next_state):
predict = self.q_table[state, action]
target = reward + self.discount_factor * np.max(self.q_table[next_state])
self.q_table[state, action] += self.learning_rate * (target - predict)
# Создание сред и агентов
env = VideoEditingEnv()
agent = QLearningAgent(n_actions=2, n_states=10)
# проводить обучение
for episode in range(100):
state = env.reset()
done = False
while not done:
action = agent.choose_action(state)
next_state, reward, done = env.step(action)
agent.learn(state, action, reward, next_state)
state = next_stateБлагодаря этому механизму обратной связи ИИ может постепенно изучать предпочтения пользователей и оптимизировать стратегии редактирования видео на основе обратной связи, тем самым предоставляя более персонализированные услуги.
6. Будущие тенденции развития
Благодаря быстрому развитию технологий интеллектуального редактирования видео мы можем ожидать новых инноваций в будущем. Вот несколько возможных направлений тренда:
6.1 Более эффективный алгоритм адаптивного обучения
В будущем, с разработкой более эффективных алгоритмов адаптивного обучения, ИИ сможет лучше понимать личные предпочтения пользователей и автоматически вносить адаптивные корректировки при редактировании. Это сделает персонализированный сервис редактирования видео более точным и отвечающим уникальным потребностям каждого создателя.
6.2 Бесшовное мультимодальное взаимодействие
Благодаря постоянному совершенствованию технологии мультимодальной обработки будущие интеллектуальные инструменты редактирования видео смогут лучше понимать и обрабатывать аудио, текстовую и визуальную информацию в видео, обеспечивая более плавное редактирование. Это сделает процесс редактирования видео более интуитивно понятным и плавным.
6.3 Полностью автоматическое создание и редактирование контента
В конечном итоге появится полностью автоматизированная система создания и редактирования контента, и ИИ сможет автоматически генерировать и редактировать полный видеоконтент на основе заданного стиля и эмоциональных требований. Это не только значительно повысит эффективность производства видео, но и предоставит создателям контента больше творческой свободы.
7. Заключение
Интеллектуальное редактирование видео, являющееся одним из важных приложений AIGC, показало свой огромный потенциал во многих областях. Благодаря таким технологиям, как компьютерное зрение, обработка естественного языка и обучение с подкреплением, ИИ может значительно повысить эффективность производства видеоконтента. Ожидается, что в условиях будущего развития интеллектуальное редактирование видео станет основным инструментом создания видеоконтента, предоставляя создателям контента больше возможностей и творческого пространства.
Благодаря примерам технологий и кода, приведенным в этой статье, читатели смогут получить более глубокое понимание принципов реализации технологии интеллектуального редактирования видео, а также дальнейшие исследования и исследования, основанные на реальных сценариях применения.



Учебное пособие по Jetpack Compose для начинающих, базовые элементы управления и макет

Код js веб-страницы, фон частицы, код спецэффектов

【новый! Суперподробное】Полное руководство по свойствам компонентов Figma.

🎉Обязательно к прочтению новичкам: полное руководство по написанию мини-программ WeChat с использованием программного обеспечения Cursor.

[Забавный проект Docker] VoceChat — еще одно приложение для мгновенного чата (IM)! Может быть встроен в любую веб-страницу!

Как реализовать переход по странице в HTML (html переходит на указанную страницу)

Как решить проблему зависания и низкой скорости при установке зависимостей с помощью npm. Существуют ли доступные источники npm, которые могут решить эту проблему?

Серия From Zero to Fun: Uni-App WeChat Payment Practice WeChat авторизует вход в систему и украшает страницу заказа, создает интерфейс заказа и инициирует запрос заказа

Серия uni-app: uni.navigateЧтобы передать скачок значения

Апплет WeChat настраивает верхнюю панель навигации и адаптируется к различным моделям.

JS-время конвертации

Обеспечьте бесперебойную работу ChromeDriver 125: советы по решению проблемы chromedriver.exe не найдены

Поле комментария, щелчок мышью, специальные эффекты, js-код

Объект массива перемещения объекта JS

Как открыть разрешение на позиционирование апплета WeChat_Как использовать WeChat для определения местонахождения друзей

Я даю вам два набора из 18 простых в использовании фонов холста Power BI, так что вам больше не придется возиться с цветами!

Получить текущее время в js_Как динамически отображать дату и время в js

Вам необходимо изучить сочетания клавиш vsCode для форматирования и организации кода, чтобы вам больше не приходилось настраивать формат вручную.

У ChatGPT большое обновление. Всего за 45 минут пресс-конференция показывает, что OpenAI сделал еще один шаг вперед.

Copilot облачной разработки — упрощение разработки

Микросборка xChatGPT с низким кодом, создание апплета чат-бота с искусственным интеллектом за пять шагов

CUDA Out of Memory: идеальное решение проблемы нехватки памяти CUDA

Анализ кластеризации отдельных ячеек, который должен освоить каждый&MarkerгенетическийВизуализация

vLLM: мощный инструмент для ускорения вывода ИИ

CodeGeeX: мощный инструмент генерации кода искусственного интеллекта, который можно использовать бесплатно в дополнение к второму пилоту.

Машинное обучение Реальный бой LightGBM + настройка параметров случайного поиска: точность 96,67%

Бесшовная интеграция, мгновенный интеллект [1]: платформа больших моделей Dify-LLM, интеграция без кодирования и встраивание в сторонние системы, более 42 тысяч звезд, чтобы стать свидетелями эксклюзивных интеллектуальных решений.

LM Studio для создания локальных больших моделей

Как определить количество слоев и нейронов скрытых слоев нейронной сети?
