Искусство обучения больших моделей: четырехэтапный путь от предварительного обучения к обучению с подкреплением
Искусство обучения больших моделей: четырехэтапный путь от предварительного обучения к обучению с подкреплением
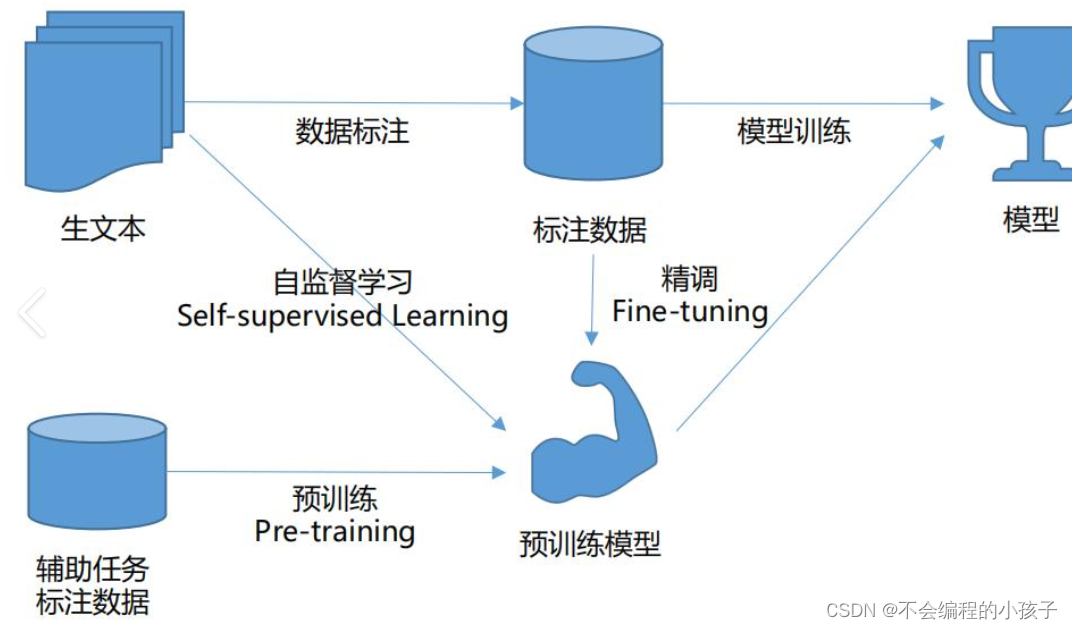
В сегодняшней области искусственного интеллекта крупномасштабные модели стали важной силой, способствующей технологическому прогрессу, благодаря своим превосходным характеристикам и широким перспективам применения. Обучение такой сложной модели — это не однодневная работа, а требует четырех тщательно разработанных этапов: предварительное обучение, контролируемая точная настройка (SFT), обучение модели вознаграждения и точная настройка обучения с подкреплением (RL). В этой статье будут подробно рассмотрены эти четыре этапа, раскрыты техническая логика и детали реализации каждого этапа.
1. Предтренировочный этап (Pretraining)
Основные цели: Создайте базовую модель с общим пониманием широкого спектра данных. На этапе предварительного обучения фиксируются статистические закономерности и основная структура языка, изображений или других типов данных, позволяя модели обучаться на крупномасштабных немаркированных наборах данных. На этом этапе обычно используются стратегии самостоятельного обучения, такие как модели языка в маске (например, BERT) или контрастное обучение (например, SimCLR).
Детали реализации: Модель пытается предсказать скрытые части или найти сходство в изображениях, изучая внутренние характеристики данных в неконтролируемой среде. Этот этап требует много вычислительных ресурсов, а размер модели часто бывает очень большим, чтобы ее можно было лучше обобщить для различных задач.
Сценарии применения: Предварительно обученные модели, такие как BERT и RoBERTa, широко используются в области обработки естественного языка, закладывая прочную основу для последующей тонкой настройки и адаптации к конкретным задачам.
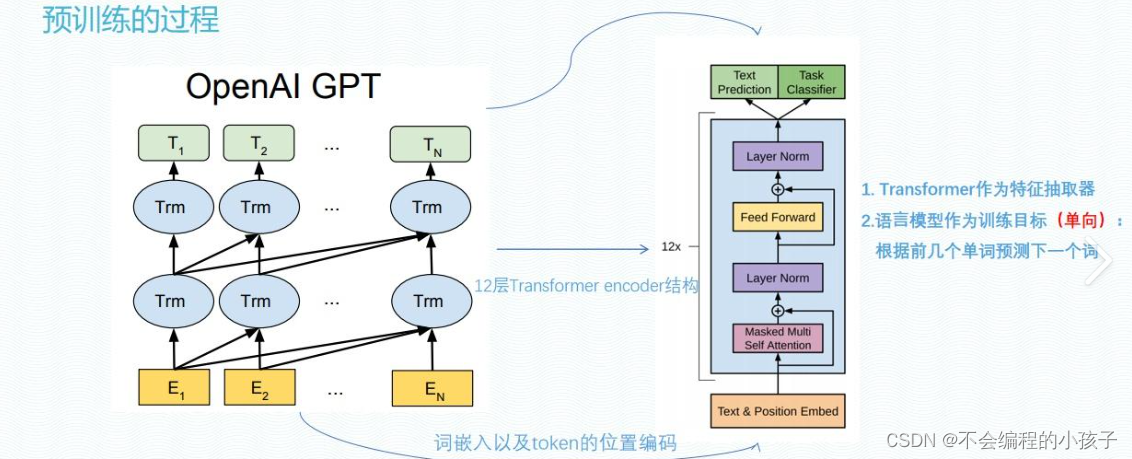
2. Контролируемая точная настройка (SFT).
Основные цели: Адаптируйте предварительно обученные общие модели к конкретным задачам. Путем точной настройки помеченных наборов данных для конкретной предметной области модели изучают выходные шаблоны для конкретных задач, таких как анализ настроений, распознавание именованных объектов или классификация изображений.
Детали реализации: На основе предварительно обученной модели добавляются дополнительные выходные слои и используются стратегии контролируемого обучения для настройки параметров модели с целью минимизации ошибок прогнозирования. Обучающие данные на этом этапе относительно небольшие, но узконаправленные, что позволяет модели лучше выполнять конкретные задачи.
Сценарии применения: Например, анализ настроений медицинских записей будет точно настроен на основе предварительно обученных языковых моделей с использованием медицинских текстов, аннотированных эмоциями.
3. Моделирование вознаграждения
Основные цели: Разработать критерии оценки поведения модели. В некоторых сложных или открытых задачах простых правильных/неправильных обозначений недостаточно для управления модельным обучением. Модели вознаграждения помогают модели производить продукцию более высокого качества, присваивая ей оценки (вознаграждения).
Детали реализации: Создайте модель вознаграждения, назначая баллы вознаграждения за различное поведение или созданный контент модели с помощью ручных или автоматизированных методов. Для этого необходимо разработать разумную функцию вознаграждения, чтобы гарантировать, что цели, преследуемые моделью, соответствуют фактическим целям задачи.
Сценарии применения: В системах генеративного диалога модели вознаграждения могут использоваться для оценки связности, информационной насыщенности и удовлетворенности пользователей диалогом, побуждая модель генерировать более естественные и полезные ответы.
4. Этап тонкой настройки Reinforcement Learning (Reinforcement Learning, RL)
Основные цели: Оптимизируйте стратегию принятия решений модели посредством взаимодействия с окружающей средой. На этапе обучения с подкреплением используются сигналы вознаграждения, позволяющие модели учиться методом проб и ошибок в конкретной среде и постоянно оптимизировать свою стратегию поведения для максимизации долгосрочных вознаграждений.
Детали реализации: Модель действует в окружающей среде, корректируя свою стратегию на основе обратной связи, предоставляемой моделью вознаграждения. Для этого часто используются такие методы, как методы политического градиента, при которых модель постепенно учится делать оптимальный выбор в течение многих итераций.
Сценарии применения: В таких сценариях, как игровой искусственный интеллект и автоматическая навигация роботов, обучение с подкреплением позволяет модели самостоятельно изучать лучшую стратегию в динамичной среде и достигать эффективных возможностей решения проблем.
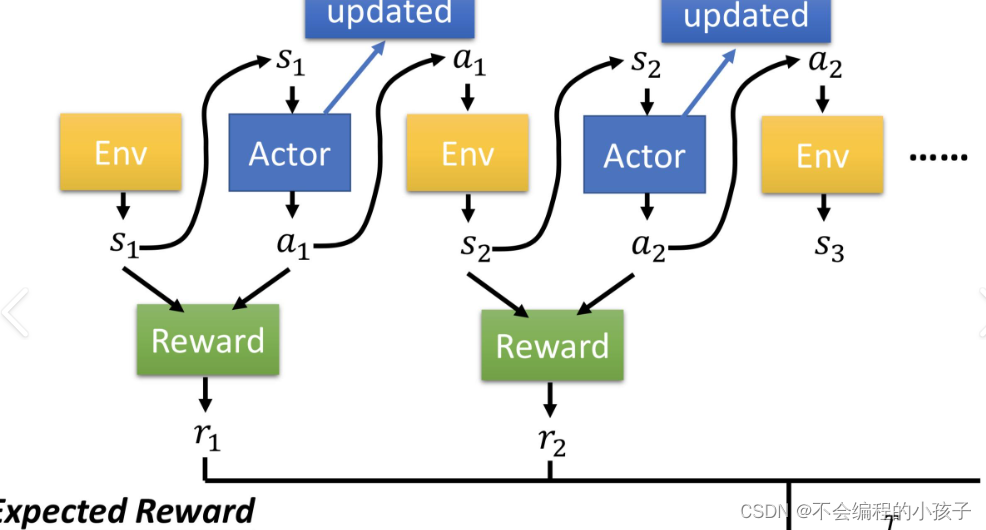
Заключение
Эти четыре этапа представляют собой систематический процесс обучения: от обширного базового предварительного обучения до тонкой настройки для конкретных задач и расширенной оптимизации стратегии. Каждый шаг направлен на то, чтобы сделать модель более интеллектуальной и эффективной для решения конкретных задач приложения. Поскольку технология продолжает развиваться, этот процесс продолжает оптимизироваться, подталкивая большие модели к более широким и глубоким областям применения.



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
