[Искусственный интеллект] Конвейер Трансформеров (10): видеоклассификация (видео-классификация)
1. Введение
Pipeline (конвейер) — это минималистичный способ использования абстракции рассуждений больших моделей в библиотеке преобразователей Huggingface. Все большие модели делятся на аудио (Audio), компьютерное зрение (Computer Vision), обработку естественного языка (NLP), мультимодальные (Multimodal). ) и другие 4 большие категории, а также 28 малых категорий задач (задач). Охватывает в общей сложности 320 000 моделей.
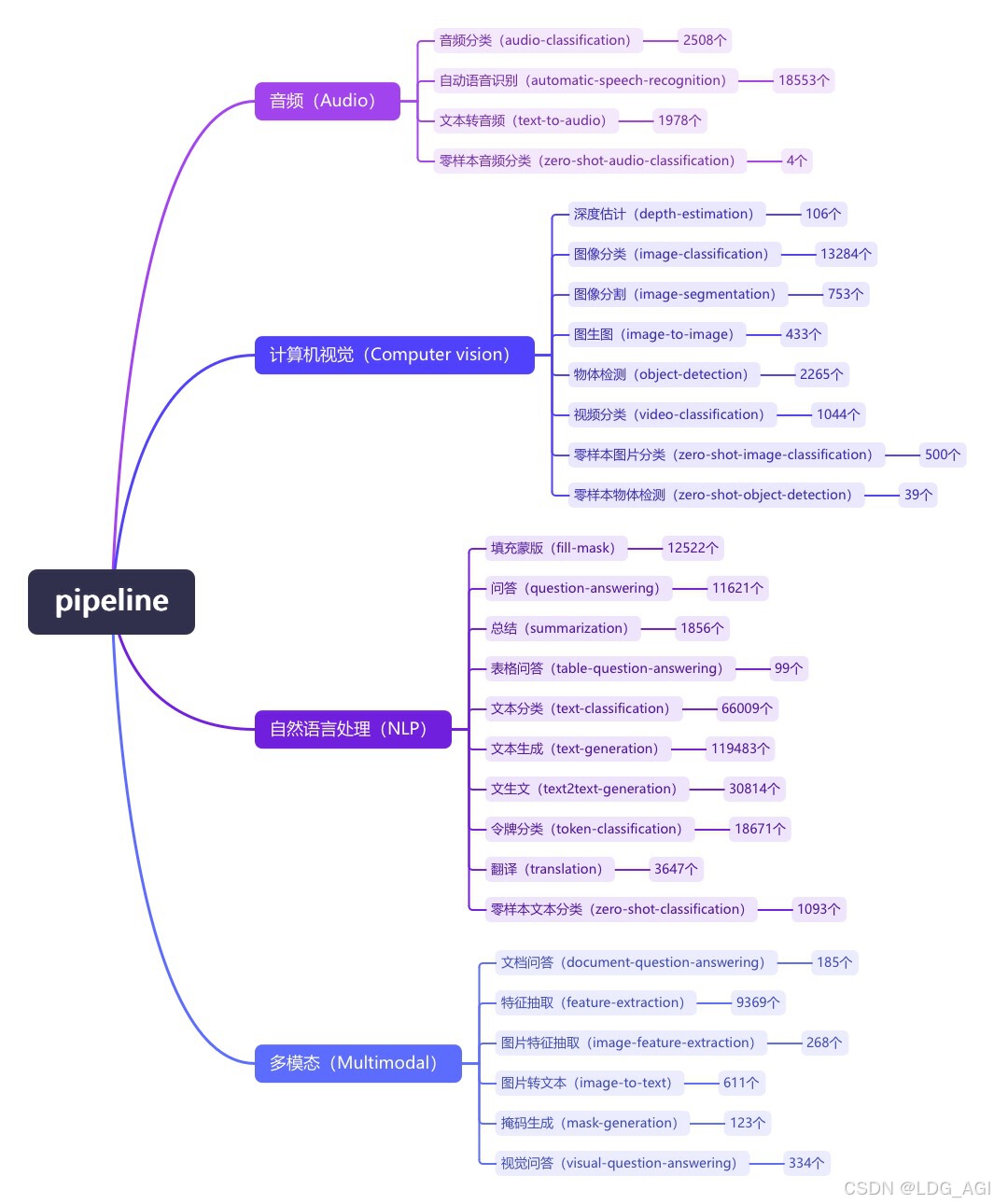
Сегодня я представляю шестую статью о компьютерном зрении CV: классификация видео (видео-классификация). В библиотеке HuggingFace имеется 1100 моделей классификации видео.
2. Классификация видео (видео-классификация)
2.1 Обзор
Классификация видео — это задача присвоения меток или категорий всем видео. Предполагается, что каждое видео будет иметь только одну категорию. Модели классификации видео принимают видео в качестве входных данных и возвращают прогноз о том, к какой категории принадлежит видео.
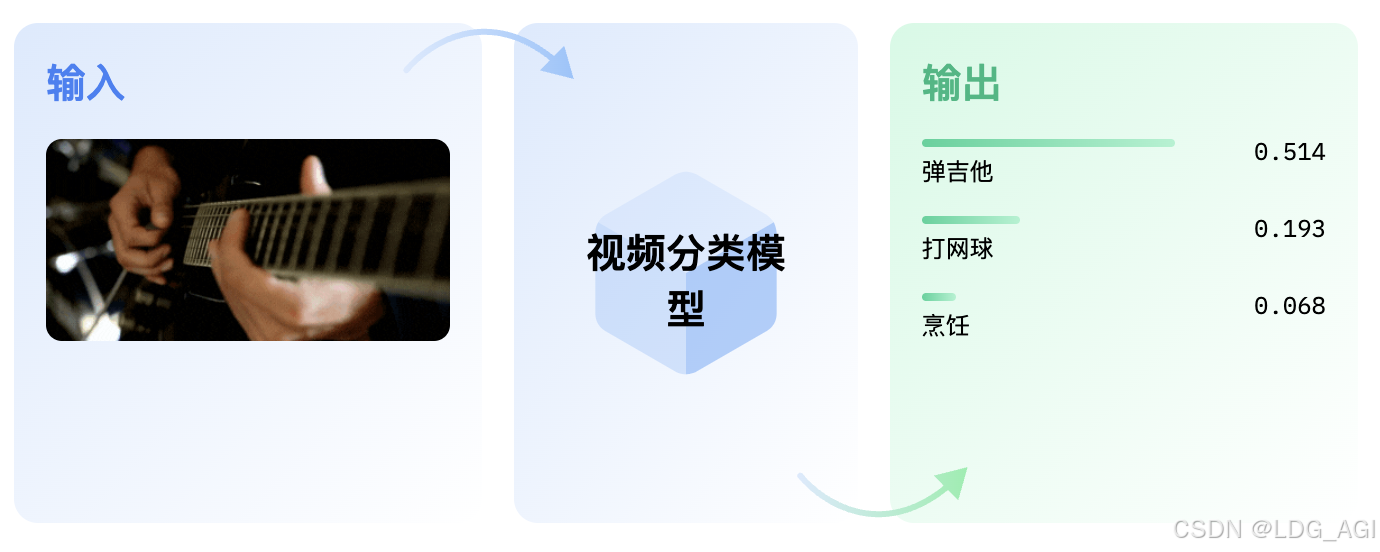
2.2 Технические принципы
Наиболее типичной моделью классификации видео (видео-классификации) является серия xclip от Microsoft. Xclip является расширением модели клипа и использует (видео-текст) сравнительное обучение и обучение. Microsoft предоставляет модели, обученные с использованием различных разрешений блоков, включая microsoft/xclip-base-patch32, microsoft/xclip-base-patch16 и т. д. Например, microsoft/xclip-base-patch32, размер разрешения блока — 32, и используется каждое видео. 8 Кадры обучаются с разрешением 224x224。Подробные документы можно найти в《Expanding Language-Image Pretrained Models for General Video Recognition》
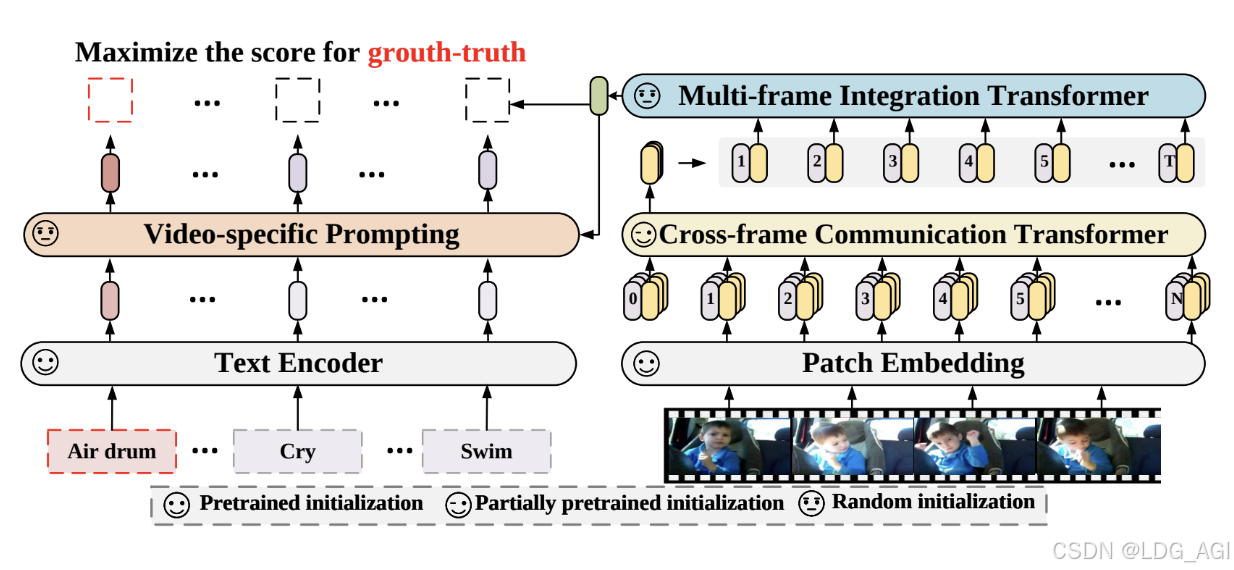
2.3 Сценарии применения
- Проверка и фильтрация контента. Автоматически идентифицируйте видеоконтент, фильтруйте незаконный, жестокий и контент для взрослых, чтобы обеспечить соответствие платформе.
- Поиск видео. Пользователи могут быстро находить интересующие видео с помощью тегов классификации, что повышает эффективность поиска.
- Образование и обучение: классифицируйте обучающие видео по темам, сложности и т. д., чтобы облегчить учащимся систематическое обучение.
- Развлечения и прямые трансляции. Управляйте контентом прямых трансляций по категориям, например игры, музыка, жизнь и т. д., чтобы зрителям было проще выбирать, что посмотреть.
- Анализ спортивных событий: быстро находите конкретные типы игр или анализ выступлений спортсменов посредством классификации.
2.4 параметры трубопровода
2.4.1 Параметры создания объекта конвейера
- model(PreTrainedModelилиTFPreTrainedModel)— Модель, которую конвейер будет использовать для прогнозирования. для PyTorch,Это требуетPreTrainedModelнаследовать;для TensorFlow,Это требуетУнаследовано от TFPreTrainedModel.
- image_processor ( BaseImageProcessor ) — Процессор изображений, который конвейер будет использовать для кодирования данных для Модели. Этот объект наследуется от BaseImageProcessor。
- modelcard(
strилиModelCard,Необязательный) — Карты моделей, принадлежащие этому конвейеру Модель. - framework(
str,Необязательный)— структура для использования,"pt"适用于 PyTorch или"tf"TensorFlow。Указанный фреймворк должен быть установлен。 - task(
str,По умолчанию"")— Идентификатор задачи конвейера. - num_workers(
int,Необязательный,По умолчанию 8)— 当管道将使用DataLoader(При передаче набора данных,существовать Pytorch Модель的 GPU выше), количество рабочих, которые будут использоваться. - batch_size(
int,Необязательный,По умолчанию 1)— 当管道将使用DataLoader(При передаче набора данных,Когда на графическом процессоре модели Pytorch,Размер используемой партии,для рассуждений,Это не всегда выгодно,Пожалуйста, прочитайтеИспользование конвейеров для пакетной обработки。 - args_parser(ArgumentHandler,Необязательный) - Ссылка на объект, ответственный за анализ предоставленных параметров конвейера.
- device(
int,Необязательный,По умолчанию -1)— CPU/GPU Серийный номер поддерживаемого устройства. установите его на -1 будет использовать ЦП, установка положительного числа приведет к соответствующему CUDA оборудование ID беги дальше Модель。Вы можете передать роднойtorch.deviceилиstrслишком - torch_dtype(
strилиtorch.dtype,Необязательный) - Отправить напрямуюmodel_kwargs(Просто более простой ярлык)использовать это Модельдоступная точность(torch.float16,,torch.bfloat16...или"auto") - binary_output(
bool,Необязательный,По умолчаниюFalse)——Флаг, указывающий, должен ли вывод канала быть в сериализованном формате.(Прямо сейчас рассол) или необработанные выходные данные (например, текст).
2.4.2 Параметры использования объекта конвейера
- video(
str,List[str])——Pipeline обрабатывает три типа видео:- Содержит ссылку на видео http связанная строка
- Строка, содержащая локальный путь к видео.
Конвейер может принимать одно видео или пакет видео, которые затем необходимо передать в виде строки. Все видеоролики должны быть в одном формате: все http-ссылки или все локальные пути.
- top_k(
int,Необязательный,По умолчанию 5) — количество верхних меток, которые вернет конвейер. Если предоставленное количество превышает количество тегов, доступных в конфигурации модели.,по умолчанию будет указано количество тегов. - num_frames(
int,Необязательный,По умолчаниюself.model.config.num_frames)— Количество кадров, выбранных из видео, используемых для классификации. Если не указано, по умолчанию используется количество кадров, указанное в конфигурации модели. - frame_sampling_rate (
int,Необязательный,По умолчанию 1) — Частота дискретизации, используемая для выбора кадров из видео. Если не указано, по умолчанию используется 1, каждый кадр будет использован.
2.4 конвейер, реальный бой
Используйте hf_hub_download для загрузки или использования местных видео:

Я лично проверял, что конвейер использовать нельзя, поэтому использовал метод модели Auto. В отличие от использования Autotokenizer для обработки текста, для обработки изображений я использовал AutoImageProcessor (суть обработки видео заключается в том, чтобы сначала разбить видео на картинки, а затем обработать фотографии)
import os
os.environ["HF_ENDPOINT"] = "https://hf-mirror.com"
os.environ["CUDA_VISIBLE_DEVICES"] = "2"
import av
import torch
import numpy as np
from transformers import AutoImageProcessor, VideoMAEForVideoClassification,TimesformerForVideoClassification
from huggingface_hub import hf_hub_download
np.random.seed(0)
def read_video_pyav(container, indices):
'''
Декодируйте определенные кадры видео с помощью библиотеки PyAV.
Decode the video with PyAV decoder.
Args:
container (`av.container.input.InputContainer`): PyAV container.
indices (`List[int]`): List of frame indices to decode.
Returns:
result (np.ndarray): np array of decoded frames of shape (num_frames, height, width, 3).
'''
frames = []
container.seek(0)
start_index = indices[0]
end_index = indices[-1]
for i, frame in enumerate(container.decode(video=0)):
if i > end_index:
break
if i >= start_index and i in indices:
frames.append(frame)
return np.stack([x.to_ndarray(format="rgb24") for x in frames])
def sample_frame_indices(clip_len, frame_sample_rate, seg_len):
'''
Индекс кадров, выбранных из видео по определенным правилам.
Sample a given number of frame indices from the video.
Args:
clip_len (`int`): Total number of frames to sample.
frame_sample_rate (`int`): Sample every n-th frame.
seg_len (`int`): Maximum allowed index of sample's last frame.
Returns:
indices (`List[int]`): List of sampled frame indices
'''
converted_len = int(clip_len * frame_sample_rate)
end_idx = np.random.randint(converted_len, seg_len)
start_idx = end_idx - converted_len
indices = np.linspace(start_idx, end_idx, num=clip_len)
indices = np.clip(indices, start_idx, end_idx - 1).astype(np.int64)
return indices
# video clip consists of 300 frames (10 seconds at 30 FPS)
file_path = "./transformers_basketball.avi"
"""
file_path = hf_hub_download(
repo_id="nielsr/video-demo", filename="eating_spaghetti.mp4", repo_type="dataset"
)
"""
container = av.open(file_path)
# sample 16 frames
indices = sample_frame_indices(clip_len=16, frame_sample_rate=1, seg_len=container.streams.video[0].frames)
video = read_video_pyav(container, indices)
image_processor = AutoImageProcessor.from_pretrained("MCG-NJU/videomae-base-finetuned-kinetics")
#model = VideoMAEForVideoClassification.from_pretrained("MCG-NJU/videomae-base-finetuned-kinetics")
model = TimesformerForVideoClassification.from_pretrained("facebook/timesformer-base-finetuned-k400")
inputs = image_processor(list(video), return_tensors="pt")
with torch.no_grad():
outputs = model(**inputs)
logits = outputs.logits
# model predicts one of the 400 Kinetics-400 classes
predicted_label = logits.argmax(-1).item()
print(model.config.id2label[predicted_label])После выполнения автоматически загружайте файлы модели, стройте индексы, разделяйте кадры и прогнозируйте классификацию видео:
2.5 Рейтинг моделей
На Huggingface мы сортируем модели видеоклассификации (классификации видео) от высокой к низкой по объему загрузки. Топ-10 моделей в основном состоят из xclip от Microsoft, videomae от Нанкинского университета, Timesformer от Facebook и Vivit Model.
3. Резюме
В этой статье представлена видеоклассификация (видеоклассификация) конвейера трансформаторов с точки зрения обзора, технических принципов, параметров конвейера, практики работы с конвейерами, ранжирования моделей и т. д. Читатели могут использовать минималистичный код для развертывания классификации видео в компьютерном зрении. на модели конвейера (классификации видео), применяемой к сценариям дискриминации видео.



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
