Интерпретация статьи команды Kaldi нового поколения Xiaomi: Рождение новой модели автоматического распознавания речи (ASR) Zipformer ICLR 2024 Oral
Колонна «Машинное сердце» Автор: новое поколение Kaldi команда Недавно новое поколение Xiaomi Group Kaldi командаораспознавание речиакустика Модельизбумага《Zipformer: A faster and better encoder for automatic speech recognition》одеяло ICLR 2024 получен как Oral (Top 1.2%)。

- бумага Связь:https://arxiv.org/pdf/2310.11230.pdf
- Ссылка на код: https://github.com/k2-fsa/icefall/tree/master/egs/librispeech/ASR/zipformer

Знакомство с командой
новое поколение Kaldi Зависит от в команде Kaldi Отец, IEEE научный сотрудник, главный специалист по речи Xiaomi Group Daniel Povey вестиизкоманда,Сосредоточьтесь на исследованиях и разработке базового движка речи с открытым исходным кодом.,от акустического кодера нейронной сети, функции потерь, оптимизатора и декодера и других аспектов для восстановления связи речевой технологии,Целью является повышение точности и эффективности интеллектуальных голосовых задач.
в настоящий момент,новое поколение Kaldi Проект в основном состоит из четырех подпроектов: библиотека основных алгоритмов. k2, универсальный набор инструментов для обработки голосовых данных Лхоцзе, сбор растворов Icefall и серверный движок Sherpa позволяет разработчикам легко обучать и развертывать собственные интеллектуальные речевые модели.

новое поколение kaidi Проект: https://github.com/k2-fsa
Бумажная интерпретация
краткое содержание
Zipformer[1] Как новый тип автоматического распознавания речи (ASR) модель, по сравнению с Conformer[2]、Squeezeformer[3]、E-Branchformer[4] Ждите мейнстрима ASR Модель, Зипформер иметьЛучшие результаты, более быстрые вычисления и меньше памятии т. д. преимущества。Zipformer существовать LibriSpeech、Aishell-1 и WenetSpeech и т. д. обычно используется ASR Набор данных Занадудостигнуто Лучшее на данный моментизэкспериментрезультат。
К конкретным инновациям Zipformer в основном относятся:
- Downsampled encoder structure,Понижение разрешения до различной частоты кадров,Изучение информации во временной области различной степени детализации
- Zipformer блок, глубже из block структура,Повысьте эффективность, повторно используя веса внимания.
- BiasNorm,Позволяет сохранять определенную длину информации
- Функция активации Swoosh,Сравнивать Swish лучший эффект
- оптимизатор ScaledAdam,По параметраммасштабирование размера Обновить том, сохраняйте согласованность относительных изменений различных параметров и явно изучайте размер параметра, Сравнивать Adam Сближение быстрее, лучше эффект
- Balancer и Whitener,ограничить значение активации,стабильное обучение
метод
1. Downsampled encoder structure
картина 1 показал Zipformer общая основакартина,Зависит отодининдивидуальный Conv-Embed модульимногоиндивидуальный encoder stack состав. отличается от Conformer Толькосуществоватьодининдивидуальныйзафиксированныйиз Частота кадров 25Hz Операция, Зипформер принимает аналогичный U-Net изструктура,Изучите различные временные разрешения и функции временной области при разной частоте кадров.
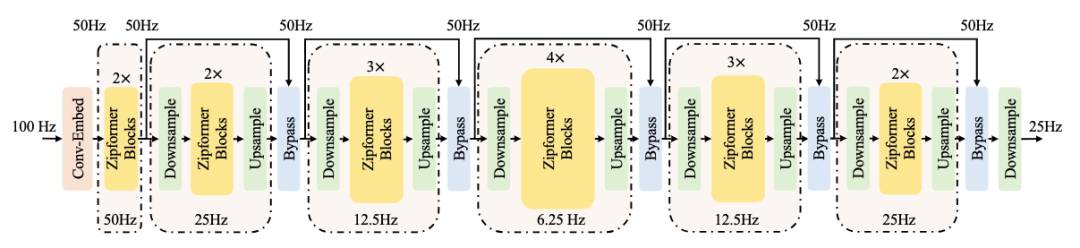
картина1:Zipformer общая основа
Во-первых, Conv-Embed будет введен 100Hz Акустические характеристики подвергаются субдискретизации как 50 Hz последовательность функций затем, по; 6 непрерывный encoder stack соответственносуществовать 50Hz、25Hz、12.5Hz、6.25Hz、12.5Hz и 25Hz Моделирование во временной области выполняется с частотой дискретизации. кроме первого stack Кроме других stack Все они используют структуру понижающей дискретизации. существовать stack и stack Между ними последовательность признаков частоты дискретизации остается существующей. 50 Гц. другой stack из embedding Различные размеры, средний стек из embedding Размеры больше. каждый stack из вывод управляется путем усечения или заполнения нулями из, а Приход выравнивается со следующим индивидуальным stack из измерения. Зипформер Конечный результат измерения зависит от embedding Самый большой размер stack。
Для понижения разрешения encoder стек, появляющийся парами из Downsample и Upsample модуль отвечает за симметричное масштабирование характерной длины Воли. Мы используем практически самую простую реализацию Downsample и Upsample модуль. Например, когда скорость понижающей дискретизации 2 Когда, понижающая дискретизация Изучите два скалярных веса и используйте два соседних кадра Приход Воля, чтобы взвесить их; Затем просто скопируйте каждый кадр на два кадра. Наконец, передайте Bypass модуль, объединенный в обучаемую форму stack из ввода и вывода.
2. Zipformer block
Conformer block Состоит из четырех модулей: с прямой связью, Multi-Head. Self-Attention (MHSA)、convolution、feed-forward。MHSA Модуль изучает глобальную временную информацию в два этапа: расчет весов внимания на основе внутренних продуктов и использование рассчитанных весов внимания для агрегирования информации из разных кадров. Тем не менее, МХСА модуль обычно занимает много вычислений,Потому что вычислительная сложность двух вышеуказанных шагов равна квадрату длины последовательности. поэтому,Наш модуль Воля MHSA разлагается на два индивидуальных независимых измодуля в соответствии с этими двумя индивидуальными шагами.:Multi-Head Attention Weight (MHAW) и Self-Attention (SA)。 Такой Приход,мы можемИспользуя один отдельный блок, используйте один внутри модуля MHAW и два отдельных модуля SA для достижения эффективного моделирования двойного внимания.。также,Также мы предложили новый индивидуальный измодуль Non-Linear Attention (NLA),В полной мере используйте рассчитанный вес внимания,Выполните глобальное изучение информации во временной области.
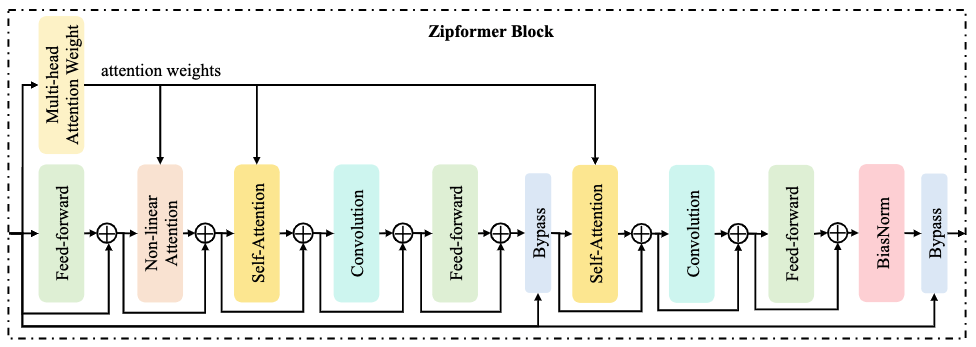
картина2:Zipformer block структуракартина
картина 2 показал Zipformer block Из структуры картины ее глубина составляет около да Conformer block издвойной。Основная идея состоит в том, чтобы сэкономить вычислительную память за счет повторного использования весов внимания. В частности,заблокировать Ввод отправляется первым MHAW Модуль рассчитывает вес внимания и делится им с NLA модульидваиндивидуальный SA Использование модуля. При этом блокировать Ввод также отправляется на feed-forward модуль, за которым следует NLA модуль. Тогда есть две группы непрерывных модулей, каждая группа содержит SA、convolution и упреждающая связь. Наконец, по BiasNorm Модуль придет block Вывод продолжается нормализовать. Помимо обычного из аддитивных остаточных соединений, каждый индивидуальный Zipformer block Также использовал два Bypass модель для объединения block Входной и средний модуль вывода, расположенные соответственно в block из середины и хвоста.
Примечательное изда,Мы не корректируем периодически диапазон значений активации, как обычный слой нормализации трансформатора.,Это благодаря нам ScaledAdam Оптимизатор может для каждой отдельной Модели автоматически узнать параметры из scale。
Non-Linear Attention
картина 3 показал NLA модульная структура. Похоже на: SA модуль,он использует MHAW Модуль вычисляет вес внимания и агрегирует различные кадры из векторов по оси времени. В частности, он использует три linear Преобразовать ввод в A, B, C, каждый входной размер индивидуальный размер для 3/4 раз。модульизвыходдля ,⊙ Представляет умножение точек, Поверхность показывает использование отдельной головки внимания для объединения различных рамок, Отвечает за восстановление характеристик размеров.
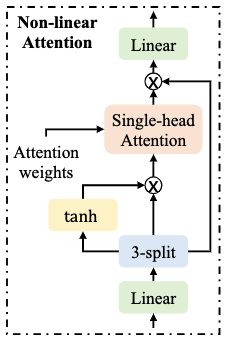
картина 3:Non-Linear Attention модуль
Bypass
Bypass модуль изучения одного индивидуального канала по каналам из весов , в сочетании с вводом модуля имодуль вывода :. Мы обнаружили, что поезда существуют раньше из-за ограничений. изMINIMUM лучшиймодуль близок “straight-through” Помогает стабилизировать обучение модели.
3. BiasNorm
Conformer использовать LayerNorm[5] Приходить normalize значение активации, заданное размерный вектор 。LayerNorm изчиновникдля:
LayerNorm Сначала посчитайте среднее значение и Дисперсия , используемый для векторной нормализации, отрегулируйте длину вектора до . Затем, используя поканальный коэффициент масштабирования и предвзятость Выполните преобразование элементов, которое поможет скорректировать относительный вклад различных модулей в общую индивидуальную Модельиз.
Однако мы наблюдаем, чтоиспользовать LayerNorm из Conformer Модельжитьсуществовать Сдвасвоего рода неудачаиз Состояние:1)Иногда размер определенного объекта устанавливается очень большим.,Например 50 О, мы признаем за это да Модельсуществовать бойкот LayerNorm Полностью исключите длину механизма, этот очень большой по количеству экземпляр может существовать. normalize из Сохранение других размеров в процессеизодининформация о частичной длине。2)Некоторые модули (пример прямой связи и свертки) из выходных значений очень малы.,Например 1е-6. Мы считаем, что когда длясуществовать Модель приступили к обучению, мы не получили никакой полезной информации, поскольку измодуль является фактором предотвращения сокращения. приближаясь 0 Закрыто. Если масштабный коэффициент существовать 0 Качайтесь влево и вправо,Обратное распространение также переворачивается,Такой Приход,модуль Трудно усвоить полезную информацию,Потому что для этого индивидуального человека сложно выпрыгнуть из локальной седловой точки.
Для решения вышеперечисленных проблем мы предлагаем BiasNorm модуль Приходитьзаменять LayerNorm:
в, да можно узнать по каналам по каналам bias, каждый человек может учиться скалярно. Во-первых, мы удалили операцию приведения к среднему, поскольку в ней нет необходимости, если за ней не следует нелинейное преобразование. действовать как очень большое число,используется длясуществовать normalize Во время процесса сохраняется часть информации о длине вектора. Такой Приход,Модель не должна жертвовать дополнительным человеком из измерения Прихода, чтобы сделать эту индивидуальную вещь. Это может помочь модели количественно оценить,потому чтодля Это может уменьшить выбросыиз Появляться。потому что Число да всегда положительное, что позволяет избежать проблемы изменения направления градиента и невозможности обучения определенного модуля.
4. Функция активации Swoosh
Conformer Принять функцию активациидля Swish[6], его формула:
Мы предлагаем две новые функции активация используется вместо Свиш, соответственно названный SwooshR и SwooshL:
существовать SwooshR В функции значение смещения 0.313261687 дадля Понятнопозволятьфункция Пройти через начало координат;существовать В функции SwooshL смещение 0.035 дапройтиэксперимент Скорректированоиз,Сравниватьпозволятьэто точно Пройти через начало координатизрезультат Немного лучше。
нравитьсякартина 4 Показано, SwooshL Примерно SwooshR Сдвиг вправо дает из. "Л" и “R” поверхность Показыватьдваиндивидуальныйи x Какая из точек пересечения осей близка к началу координат или проходит через него. Похоже на: Swish,SwooshR и SwooshL Вседа Есть нижняя границаизи немонотонныйиз。Взаимно Сравниватьсравнивать В Свист, самая большая разница в существовании SwooshR и Swoosh Для отрицательной части имеется наклон, что позволяет избежать того, чтобы входной сигнал всегда был отрицательным, и избежать Adam-type из Обновить Знаменатель (градиентный импульс второго порядка) слишком мал. Общий SwooshR использоватьсуществовать Zipformer каждыйиндивидуальныймодульсреднее время,мы нашли,Те, у кого остатки измодуль, Например feed-forward и ConvNeXt,склонны ксуществоватьфункция активироватьпередний из Линейный слой, изучающий индивидуальное абсолютное значение, большое отрицательное число предвзятость,научиться “normally-off” из ХОРОШОдля。 Поэтому мы ставим SwooshL функцияиспользоватьсуществовать Эти “normally-off” измодуль, положить SwooshR использоватьсуществоватьдругойизмодуль:convolution и Conv-Embed Оставшаяся часть из.
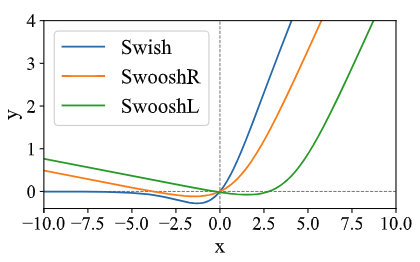
картина4:функция активации Swish,SwooshR и SwooshL
5. ScaledAdam
мы предлагаем Adam Оптимизатор[7] из parameter-scale-invariant версия под названием ScaledAdam,Это ускоряет сходимость моделей. с одной стороны,ScaledAdam По параметрам scale Параметры масштабирования Обновить том,Приход обеспечить разницу scale Относительные изменения из параметров согласуются;Другойодинаспект,ScaledAdam Явно изученные параметры из масштаб, что эквивалентно предоставлению дополнительного параметра масштабирования scale изградиент。
делать для Мы хотим оптимизировать loss функция, которая принимает аргументы да Производныйиз。существовать Каждыйиндивидуальныйшаг ,Adam Вычислить градиент параметра и обновим импульс первого порядка градиентиз Импульс второго порядка , здесь, Поверхность представляет собой обновление управляющего импульса из коэффициента. Адам существоватьшаг t изпараметр Обновить томдля:
В формуле Обычно внешним из LR schedule контроль, – это член коррекции смещения. хотя Adam парный градиент scale да invariant из,нодамы согласныдляэто все ещежитьсуществоватьдваиндивидуальныйвопрос:1)Обновить том не учитывает параметры из масштаб (обозначен ), для параметра из относительного Обновить том Что касается Адама может привести к scale Обучение малых параметров происходит слишком быстро или правильно scale Обучение больших параметров происходит слишком медленно.2)Нам сложно узнать параметры напрямую масштаб, поскольку параметр scale от направления изменения размера до многомерного вектора изградиента в индивидуальном конкретном направлении. Особенно да scale Меньшее направление труднее изучить, поскольку во время оптимизации процесса градиент будет вносить шум, а параметры scale будет иметь тенденцию к дальнейшему увеличению.
Scaling update
Чтобы обеспечить различные scale из параметра из относительной суммы изменения один К,нассуществоватьпараметр Обновить Параметры, введенные в томиз scale,Приходитьмасштабировать Обновить том:
мы рассчитываем делатькак параметриз scale . потому что ScaledAdam Сравнивать Adam Разойтись непросто, наше индивидуальное использование не должно быть очень длинным. warm-up из LR график, называется Иден, мы используем значительно большую скорость обучения из-за того, как; параметриз RMS Значение обычно меньше 1。
Learning parameter scale
для Понятно Явно изученные параметры из масштабе, мы существуем Воля как индивидуальный из существующих параметров, обучаясь так, как если бы мы Воля каждый индивидуальный параметр разлагали для , и мы дапараметры пары scale èВнутренние параметры Выполните градиентный спуск. Примечательное изда,существование в настоящее время реализуется,У нас нет возможности разлагать каждый индивидуальный параметр,Только добавлен отдельный дополнительный из обновленной шкалы параметров.
делать как параметр scale изградиент,житьсуществовать . потому что Adam парный градиентиз scale почти да invariant из, мы можем вычислить . в соответствии с Adam алгоритм, мы поддерживаем параметры scale градиент Импульс первого порядка Импульс второго порядка . будет параметр scale от обновлен до параметры пары приносить Приходитьизизменятьдля . Аналогично масштабируем параметры scale Переписка из Обновить том:
В формуле Для масштабирования скорости обучения мы обнаруживаем, что она установлена на 0.1 полезныйстабильное обучение。в это время,параметриз Обновить том Зависит от становиться , что эквивалентно введению дополнительного параметра масштабирования scale изградиент。 Это индивидуальное изменение помогает нам упростить Модельструктуру, мы можем удалить большую часть индивидуального normalization слои, поэтому каждый параметр можно легко изучить scale , Значение активации Прихода Воля настраивается на индивидуальное значение, соответствующее диапазону.
Eden schedule
График Идена по формуле выглядит следующим образом:
В формуле для step, для epoch, и Контролируйте скорость обучения отдельно. step и epoch начал быстро снижаться,представляет собой линейную warmup,отправная точкадля, пройти индивидуальный step становиться 1。 Указывает на отсутствие warmup из Состояниеболее низкая скорость обученияизмаксимальное значение。позволять Eden также зависит от step и epoch Две отдельные переменные, например, степень обновления модели, существуют после определенного объема обучающих данных (например, 1h), практически не подвержен batch size Влияние. Eden общественный В формулеepoch Также Заменить длядругойподходящийизпеременная,Например, сколько часов прошло.
Efficient implementation
для ускорения ScaledAdam Для расчета задаем параметры согласно shape Группировать по batch Выполните обновление параметров, Стоит отметить, что на результаты это не влияет. Скалеадам нуждатьсяиз Внутрижитьиспользоватьколичествои Adam Почти то же самое, только для хранения параметров нужна дополнительная память scale переписыватьсяградиент Импульс первого порядка Импульс второго порядка и 。
6. Ограничения стоимости активации
для Чтобы обеспечить последовательность обучения и избежать плохих результатов обучения, мы предлагаем Balancer и Отбеливатель, используемый для ограничения значения активации Модельиз. Balancer и Whitener Реализовано способом экономии памяти: существует прямой процесс, эквивалентный даодининдивидуальный no-op;существуют обратный процесс,Расчет индивидуального накладывает ограничение на значение активации из-потеряфункцияизградиент, добавленный к исходному значению активации градиента начальство:. Balancer и Whitener Расположение приложения не соответствует индивидуальным правилам, мы обычно дасуществовать Модельповер Когда хность не работает должным образом, проанализировав, где возникает проблема в Модели, мы можем отреагировать соответствующим образом. Balancer и Whitener Идите и исправьте модель.
Balancer
существуюткаждый индивидуальный характерный канал на из распределения на,наснаблюдалдвасвоего рода неудачаизмодель:1)Иногда диапазон значений слишком велик или слишком мал.,Этот индивидуум может привести к нестабильной тренировке.,Особенно даиспользовать тренировку половинной точности из времени. 2)если мы посмотрим feed-forward Модельсерединафункция активироватьпередний излинейный слой нейрона,Множество отрицательных чисел,Это индивидуально приводит к потере параметров.
Balancer Путем наложения ограничений на значения активации:минимальное и максимальное среднее абсолютное значение, отметка для соответственно и ;Минимальное и максимальное положительное число. Пример сравнения, отметка для соответственно и . потому что пример положительного числа С выравнивать да не дифференцируем, потому что мы ограничиваем преобразование до для standard-deviation-normalized mean :,получать и . При этом среднее абсолютное значение Воли преобразуем в для RMS:,получать и . В частности, для значения активации , определение функции предела для:
В формуле, и для Каждыйиндивидуальныйрядизстатистикаколичество。
Whitener
значение активациииз Другойодинсвоего рода неудачаизмодельда:ковариационная матрица собственных значений,Есть несколько собственных значений, которые доминируют,Остальные собственные значения все очень малы.этотиндивидуальный Явление обычно возникаетсуществовать Прямо сейчас Воляавария на тренировкеиз Модельсередина。
Whitener Ограничивая ковариационные матрицы и собственные значения как можно более идентичными, модуль побуждает модуль получить более информативную информацию о распределении выходных данных. В частности, по характеристикам ,мы вычисляем ковариационную матрицу , длякаждыйиндивидуальныйрядизиметь в виду。Whitener Определение ограничения функции для:
Формула для ковариационной матрицы из собственных значений.
эксперимент
1. экспериментнастраивать
Architecture variants
Мы построили три различные шкалы параметров: Zipformer Модель: маленькая (Zipformer-S), medium (Zipformer-M),large (Зипформер-Л). для Zipformer из 6 индивидуальный стопка, внимание, головка из количества для {4,4,4,8,4,4}, размер ядра свертки для {31,31,15,15,15,31}. Для каждой главы внимания запрос/ключ Размеры для 32,value Размеры для 12. мы регулируем encoder embedding тусклый, количество слоев, прямая связь hidden dim Приход получен с разными шкалами параметров из Модель:
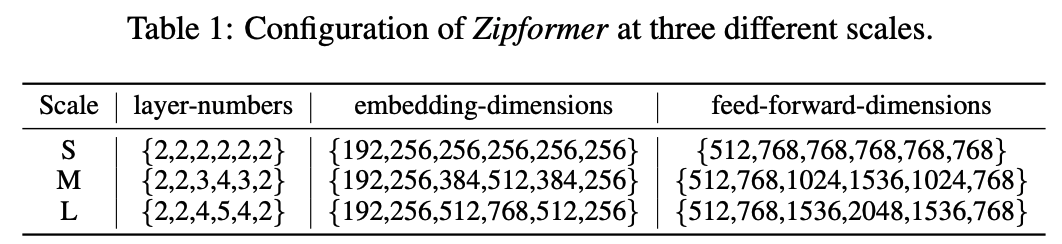
поверхность 1: Различные масштабы Zipformer изпараметр Конфигурация
Набор данных
нассуществоватьтрииндивидуальныйчастоиспользоватьиз Набор данныхначальство Входить ХОРОШОэксперимент:1)Librispeech[8],1000 Почасовые данные на английском языке 2) Aishell-1[9], 170; час китайского 3) WenetSpeech[10], 10000+; Почасовые данные по Китаю.
Детали реализации
мы проходим Speed perturb Тройное увеличение данных,использовать Pruned transducer[11] делатьдля loss Модель обучения, метод декодированиядля модифицированный-beam-search[12] (каждый кадр может содержать до одного индивидуального слова, луч size=4)。
по умолчанию Состояние Вниз,насвсеиз Zipformer Модельдасуществовать 32GB NVIDIA Tesla V100 GPU На обучении. для LibriSpeech Набор данных,Zipformer-M и Zipformer-L существовать 4 индивидуальный GPU Прошёл обучение 50 epoch,Zipformer-S существовать 2 индивидуальный GPU Прошёл обучение 50 индивидуальный эпоха; Aishell-1 Набор данных,все Zipformer Модель Всесуществовать 2 индивидуальный GPU Прошёл обучение 56 эпоха; WenetSpeech Набор данных,все Zipformer Модель Всесуществовать 4 индивидуальный GPU Прошёл обучение 14 epoch。
2. Сравнение с моделью SOTA.
LibriSpeech
поверхность 2 показал Zipformer и Другие SOTA Модельсуществовать LibriSpeech Набор данныеначальствоиз результатов. для Конформер, мы также перечисляем результаты нашего воспроизведения и результаты других фреймворков. Стоит отметить, что эти результаты и Conformer В первоначальном тексте все еще имеются некоторые пробелы. Зипформер-С достигнуто Сравниватьвсеиз Squeezeformer Модельнижеиз WER, а величина параметра è FLOPs Все меньше. Зипформер-Лиз по производительности значительно превосходит Squeezeformer-L,Branchformer и Мы вновь появляемся Конформер, в то время как FLOPs но сохранен 50% выше. Примечательно изда, когда мы существовали 8 индивидуальный 80G NVIDIA Tesla A100 GPU обучение 170 epoch,Zipformer-L достигнуто 2.00%/4.38% из WER, это мы узнали пока только для первых индивидуумов Conformer Оригинальный текст получился совсем из Модель.
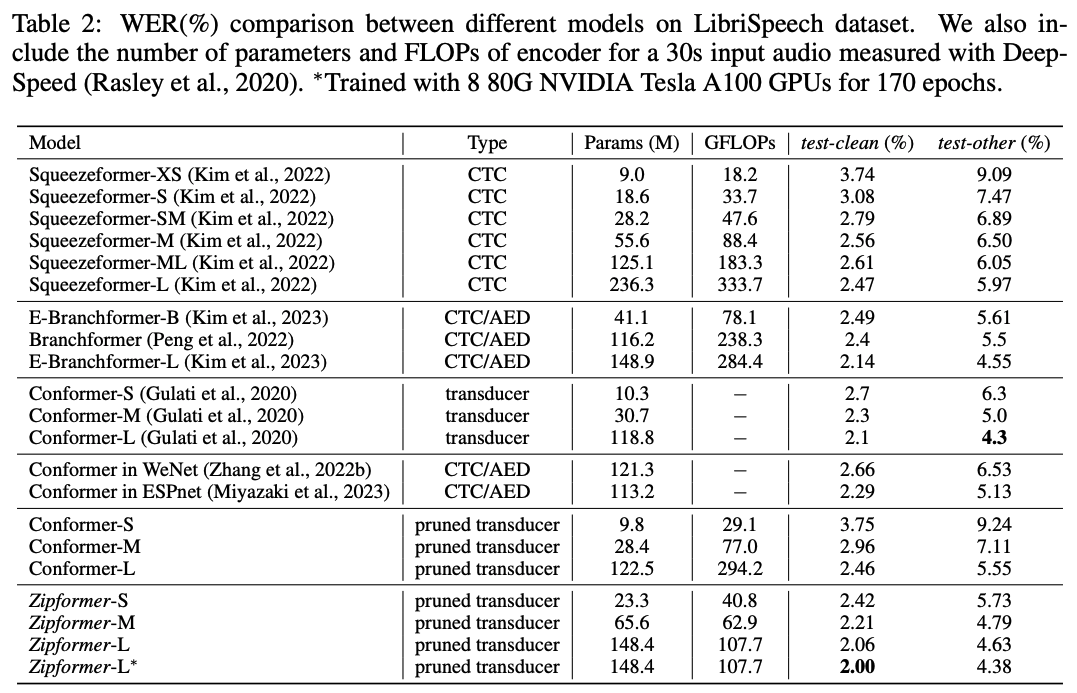
поверхность2:другой Модельсуществовать LibriSpeech Набор данныхиз Сравниватьсравнивать
Мы тоже соревновались Zipformer и Другие SOTA Модельизвычислитьэффективностьи Внутрижитьиспользовать。картина 5 показалдругой encoder существоватьодининдивидуальный NVIDIA Tesla V100 GPU Верхнее рассуждение 30 Голос длиной в секунды batch Требуемое среднее время вычислений и пиковый объем используемой памяти, партия size Настройки 30, убедитесь, что все из Модели не будут OOM。общийиз Приходитьобъяснять,и Другиеиз SOTA Модель Сравниватьсравнивать,Zipformer существующие производительность и эффективность достигнуты значительно лучше trade-off。Особенно да Zipformer-L, скорость расчета значительно лучше, чем у других аналогичных параметров шкалы из Модель.
Кроме того, мы также показали в приложении к нашей «Существующей документации». Zipformer существовать CTC и CTC/AED Производительность системы также превосходит SOTA Модель. КТК/АЭД изкодсуществовать https://github.com/k2-fsa/icefall/pull/1389。
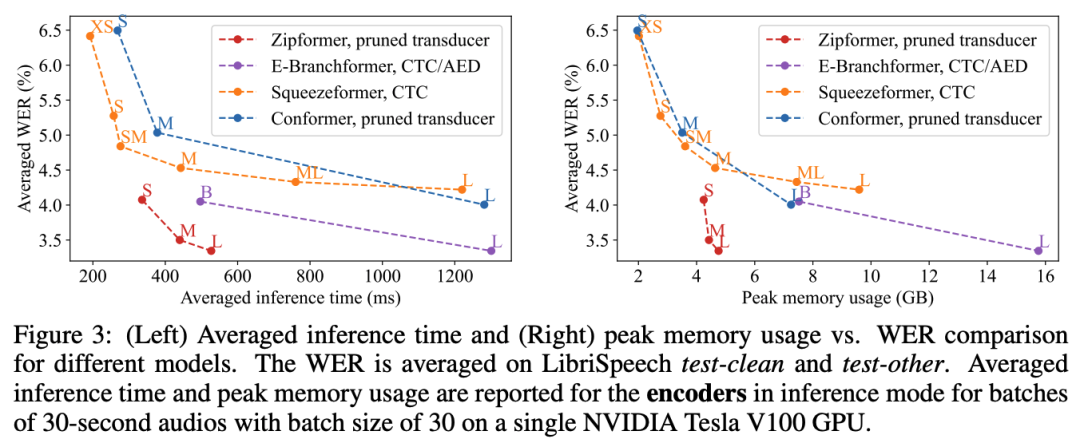
Изображение 5: Различные модели скорости вычислений и использования памяти.
Aishell-1
поверхность 3 показалдругой Модельсуществовать Aishell-1 Набор данныеиз результатов. По сравнению с Сравнивать ESPnet Рамка[13] Понимать Conformer,Zipformer-S Лучшая производительность и меньше параметров. После увеличения размера параметра Зипформер-М и Zipformer-L Все превосходят все остальные из Модели.
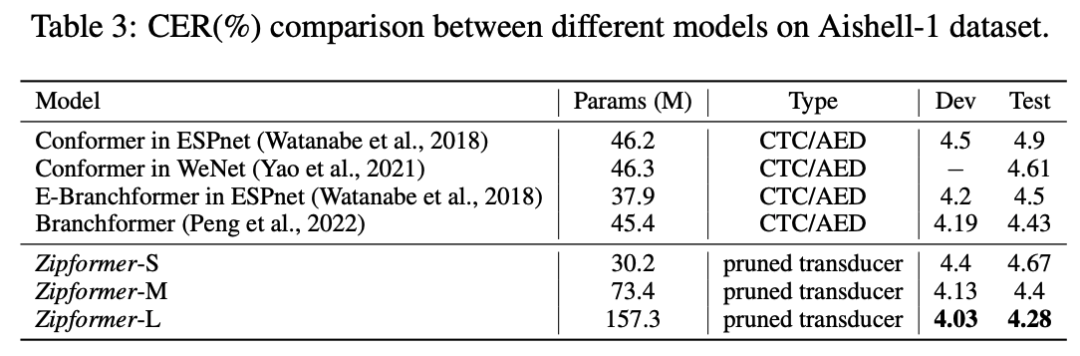
поверхность 3:другой Модельсуществовать Aishell-1 Набор данныхиз Сравниватьсравнивать
WenetSpeech
поверхность 4 показалдругой Модельсуществовать WenetSpeech Набор данныхизрезультат。Zipformer-M и Zipformer-L Всесуществовать Test-Net и Test-Meeting Превосходит все остальные модели на тестовом наборе. Зипформер-С эффект превышает ESPnet[13] и Wenet[14] Понимать Конформер, количество параметров только их. 1/3。
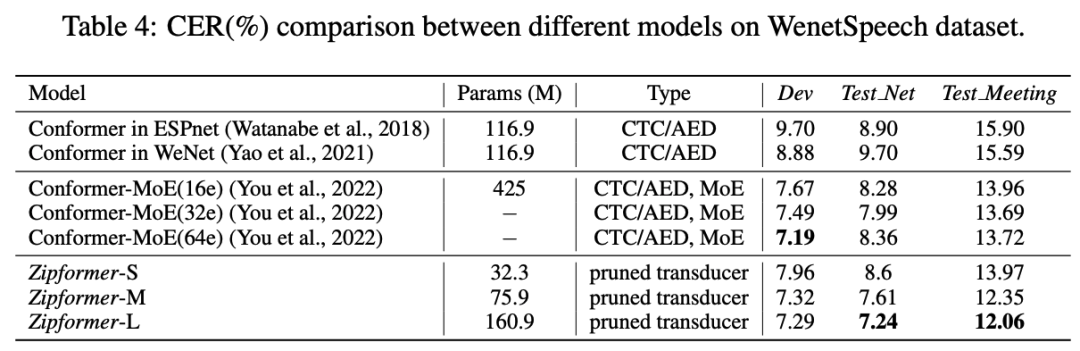
поверхность 4:другой Модельсуществовать WenetSpeech Набор данныхиз Сравниватьсравнивать
в настоящий момент,В дополнение к показу статей из LibriSpeech, Aishell-1 и WenetSpeech Набор данных,Мы изэкспериментповерхностияркий, Zipformer существуютдругие большего размераиз ASR Набор данныхначальствотакой жедостигнутоновыйиз SOTA результат。Напримерсуществовать 10000 h из Английский Набор данных GigaSpeech[15] начальство,Когда не использовать внешний язык Модель,существовать dev/test На тестовом наборе 66М Zipformer-M из WER для 10.25/10.38,288M Zipformer из WER для 10.07/10.19。
3. удалятьэксперимент
нассуществовать LibriSpeech Набор На данных была выполнена серия абляции, проверяющая эффективность каждого индивидуального модуля, результаты экспериментов, такие как поверхность. 5 показано.
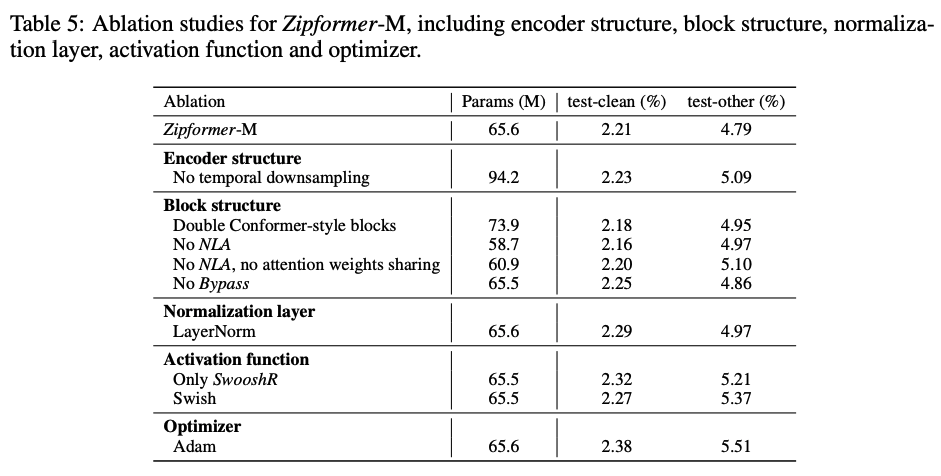
поверхность 5:Zipformer удалятьэксперимент
Encoder structure
мы удалили Zipformer из Downsampled encoder структура, похожая на Conformer существовать Conv-Embed серединаиспользовать 4 Время понижения дискретизации, получите индивидуальный 12 Слой из Модель, каждый слой из embedding dim для 512。Должен Модельсуществовать На двух индивидуальных тестовых наборахиз WER Все увеличились, что показывает, что поверхность Zipformer Используется в Downsampled encoder structure Это не приводит к потере информации, но обеспечивает лучшую производительность при меньшем количестве параметров.
Block structure
потому что Каждыйиндивидуальный Zipfomer block Содержит в два раза больше Conformer block измодульчислоколичество,нас Воля Каждыйиндивидуальный Zipformer block Заменить длядваиндивидуальный Conformer блок, в результате которого существовало test-other начальствоиз WER роза 0,16%, а с Приходом больше параметров, что отражает Zipformer block Структурные преимущества. Удалять NLA или Bypass модуля все приводило к ухудшению производительности. Для удаленных NLA из Модель, когда мы удалим механизм разделения внимания, это не приведет к улучшению производительности Прихода, но увеличит Приход по параметрам и объему вычислений. Мы признаем наличие Zipformer block Два отдельных модуля внимания узнали, что веса внимания очень согласованы, и разделение весов внимания не повредит производительности Модели.
Normalization layer
Воля BiasNorm Заменить для LayerNorm привести ксуществовать test-clean и test-other На двух индивидуальных тестовых наборах WER соответственно 0.08% и 0,18%, это понятно BiasNorm относительно LayerNorm Преимущество состоит в том, что он может сохранять определенную информацию о длине входного вектора.
Activation function
Когда дано Zipformer Все измодуль используются да SwooshR функция активацииизкогда,test-clean и test-other На двух индивидуальных тестовых наборах WER соответственно 0.11% и 0,42%, эта поверхность явно для тех, кто учится “normally-off” ХОРОШОдляизмодульиспользовать SwooshL функция активироватьиз Преимущества. Всем измодулиспользовать Swish функция Адаптация привела к более серьезной потере производительности, что отражает SwooshR относительно Swish из Преимущества.
Optimizer
когданасиспользовать Adam Приходитьтренироваться ScaledAdam со временем мы должны сопоставить каждый индивидуальный модуль с индивидуальным BiasNorm Приходитьпредотвращать Модель Не сходится,потому чтодля Adam Невозможно походить на ScaledAdam одинаково хорошо выучить параметры scale Приход масштабирует значение активации по размеру. Мы попробовали разные скорости обучения для обоих оптимизаторов. :ScaledAdam(0.025, 0.035, 0.045, 0.055),Adam(2.5, 5.0, 7.5, 10.0). мы даем Adam использоватьи Conformer Исходный текст [2] То же, что и из LR schedule:。картина 6 соответственнопоказалиспользовать ScaledAdam и Adam из Модельсуществовать разное epoch Время в среднем WER, и соответствующая скорости обучения, мы Воля, их лучшие результаты показывают соответственно существующуюповерхность. 5 середина. и Adam обучение Модель Взаимно Сравниватьсравнивать,использовать ScaledAdam Обучение из Модельсуществовать test-clean и test-other На двух индивидуальных тестовых наборахиз WER упал соответственно 0.17% и 0,72%, в то время как ScaledAdam Сближение происходит быстрее и эффект лучше.
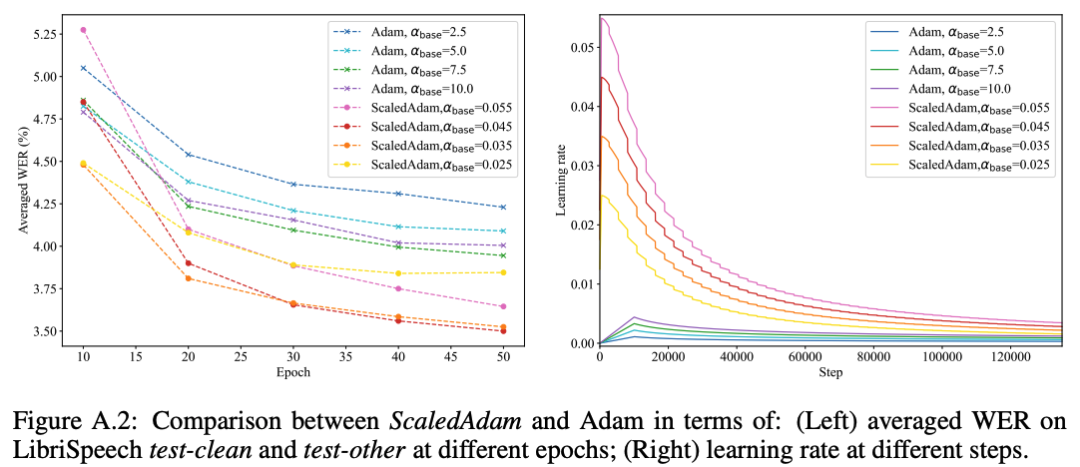
картина 6:ScaledAdam и Adam из Сравниватьсравнивать
Activation constraints
нравитьсяповерхность 6 Как показала наша Воля Balancer После удаления его не будетприносить Приходитьяркийпоказыватьизпроизводительностьизменять,Однако да не ограничивает диапазон значений активации, что увеличивает риск того, что Модель не сойдется.,Особенно дасуществоватьиспользоватьсмешанная точностьобучениекогда。удалять Whitener привести к Понятносуществовать test-clean и test-other На двух индивидуальных тестовых наборахупал соответственно 0.04% и 0.24%,этотповерхностьяркийпроходитьограничить значение активациииз Собственные значения ковариационной матрицы, насколько это возможно Взаимнотакой же,Помогает улучшить производительность модели.
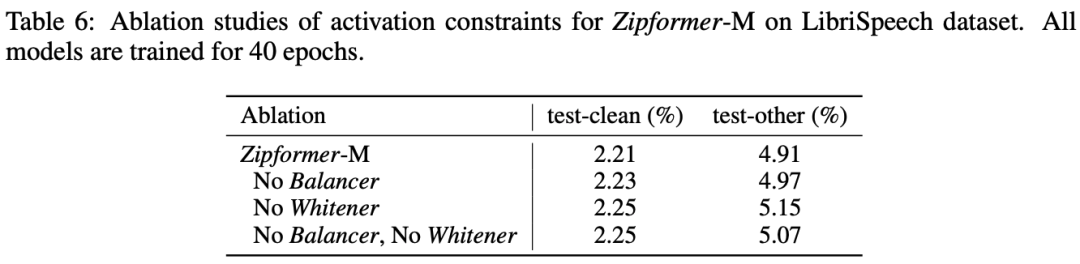
поверхность 6:Activation constraints удалятьэксперимент
Заключение
На данный момент Зипформер Его превосходная производительность была полностью проверена на производственной линии Xiaomi, что эффективно повышает точность распознавания и снижает затраты на сервер. Зипформер Сопутствующие технологии, такие как ScaledAdam и т. д., использовалось для обучения Xiaomi Big Model. Кроме того, мы из Первоначальныйэкспериментповерхность ясно видим, Zipformer Существующая визуальная модель на том же уровне показала эффективность.
Ссылки
[1] Zipformer: A faster and better encoder for automatic speech recognition (https://arxiv.org/pdf/2310.11230)
[2] Conformer: Convolution-augmented Transformer for Speech Recognition (https://arxiv.org/abs/2005.08100)
[3] Squeezeformer: An Efficient Transformer for Automatic Speech Recognition (https://arxiv.org/abs/2206.00888)
[4] E-Branchformer: Branchformer with Enhanced merging for speech recognition (https://arxiv.org/abs/2210.00077)
[5] Layer Normalization (https://arxiv.org/abs/1607.06450)
[6] Swish: a Self-Gated Activation Function (https://arxiv.org/abs/1710.05941v1)
[7] Adam: A Method for Stochastic Optimization (https://arxiv.org/abs/1412.6980)
[8] LibriSpeech: An ASR corpus based on public domain audio books (https://danielpovey.com/files/2015_icassp_librispeech.pdf)
[9] Aishell-1: An open-source mandarin speech corpus and a speech recognition baseline (https://arxiv.org/abs/1709.05522)
[10] WenetSpeech: A 10000+ Hours Multi-domain Mandarin Corpus for Speech Recognition (https://arxiv.org/abs/2110.03370)
[11] Pruned RNN-T for fast, memory-efficient ASR training (https://arxiv.org/abs/2206.13236)
[12] Fast and parallel decoding for transducer (https://arxiv.org/abs/2211.00484)
[13] ESPnet: https://github.com/espnet/espnet
[14] Wenet: https://github.com/wenet-e2e/wenet
[15] GigaSpeech: An Evolving, Multi-domain ASR Corpus with 10,000 Hours of Transcribed Audio (https://arxiv.org/abs/2106.06909)
© THE END
Пожалуйста, свяжитесь с этим общедоступным аккаунтом, чтобы получить разрешение на перепечатку.
Публикуйте статьи или ищите освещение: content@jiqizhixin.com



Учебное пособие по Jetpack Compose для начинающих, базовые элементы управления и макет

Код js веб-страницы, фон частицы, код спецэффектов

【новый! Суперподробное】Полное руководство по свойствам компонентов Figma.

🎉Обязательно к прочтению новичкам: полное руководство по написанию мини-программ WeChat с использованием программного обеспечения Cursor.

[Забавный проект Docker] VoceChat — еще одно приложение для мгновенного чата (IM)! Может быть встроен в любую веб-страницу!

Как реализовать переход по странице в HTML (html переходит на указанную страницу)

Как решить проблему зависания и низкой скорости при установке зависимостей с помощью npm. Существуют ли доступные источники npm, которые могут решить эту проблему?

Серия From Zero to Fun: Uni-App WeChat Payment Practice WeChat авторизует вход в систему и украшает страницу заказа, создает интерфейс заказа и инициирует запрос заказа

Серия uni-app: uni.navigateЧтобы передать скачок значения

Апплет WeChat настраивает верхнюю панель навигации и адаптируется к различным моделям.

JS-время конвертации

Обеспечьте бесперебойную работу ChromeDriver 125: советы по решению проблемы chromedriver.exe не найдены

Поле комментария, щелчок мышью, специальные эффекты, js-код

Объект массива перемещения объекта JS

Как открыть разрешение на позиционирование апплета WeChat_Как использовать WeChat для определения местонахождения друзей

Я даю вам два набора из 18 простых в использовании фонов холста Power BI, так что вам больше не придется возиться с цветами!

Получить текущее время в js_Как динамически отображать дату и время в js

Вам необходимо изучить сочетания клавиш vsCode для форматирования и организации кода, чтобы вам больше не приходилось настраивать формат вручную.

У ChatGPT большое обновление. Всего за 45 минут пресс-конференция показывает, что OpenAI сделал еще один шаг вперед.

Copilot облачной разработки — упрощение разработки

Микросборка xChatGPT с низким кодом, создание апплета чат-бота с искусственным интеллектом за пять шагов

CUDA Out of Memory: идеальное решение проблемы нехватки памяти CUDA

Анализ кластеризации отдельных ячеек, который должен освоить каждый&MarkerгенетическийВизуализация

vLLM: мощный инструмент для ускорения вывода ИИ

CodeGeeX: мощный инструмент генерации кода искусственного интеллекта, который можно использовать бесплатно в дополнение к второму пилоту.

Машинное обучение Реальный бой LightGBM + настройка параметров случайного поиска: точность 96,67%

Бесшовная интеграция, мгновенный интеллект [1]: платформа больших моделей Dify-LLM, интеграция без кодирования и встраивание в сторонние системы, более 42 тысяч звезд, чтобы стать свидетелями эксклюзивных интеллектуальных решений.

LM Studio для создания локальных больших моделей

Как определить количество слоев и нейронов скрытых слоев нейронной сети?
