Интерфейсная часть может получить доступ к любой крупной модели для исследования через LangChain.
1. Введение
В настоящее время появляется все больше продуктов с большими моделями. Microsoft интегрировала возможности больших моделей в пакет Office Family. Google интегрировала в пакет Google Family Bucket большие модели, такие как поисковые системы, почтовые ящики, карты и видео-сайты. Meta использует возможности искусственного интеллекта. обслуживать рекламодателей и помогать им писать маркетинговые тексты, создавать чертежи рекламных концепций...
Студентам, изучающим фронтенд, также интересно узнать, как идти в ногу с тенденцией создания больших моделей. Ниже приводится некоторый процесс исследования с помощью langchain.
1.1 Изучение сценариев использования
● Сценарии создания копирайтинга.
Применение больших моделей в сценариях копирайтинга становится все более распространенным, предоставляя предприятиям и частным лицам эффективные и качественные решения для создания копирайтинга.
● Сценарий документа Справочного центра.
Справочный центр представляет собой подробное руководство по эксплуатации, призванное помочь пользователям лучше использовать продукт и предоставлять пользователям результаты вопросов и ответов, чтобы помочь им быстро приступить к работе.
2. Большие модельные решения
Стоимость предварительного обучения очень высока. Тонкая настройка модели и хинт-инжиниринг (внесение знаний в контекст) также являются методами оптимизации производительности больших языковых моделей, но они различны по способам реализации и целям. Точная настройка более эффективна, чем обучение модели с нуля, и обычно дает лучшие результаты, а разработка ключевых слов больше подходит для некоторых конкретных задач.
2.1 Предварительная тренировка
Характеристики обычных моделей предварительного обучения: для обучения требуется большой набор данных, и данные уже имеют базовые функции и глубокие абстрактные функции. В то же время они потребляют много вычислительного времени и вычислительных ресурсов, и что это такое. Обучаемые каждый раз могут быть неприменимы, а точность низкая. Модель имеет низкую способность к обобщению и склонна к переобучению и другим проблемам.
2.2 Точная настройка модели
Fine Tune — это метод оптимизации вывода больших языковых моделей для конкретных задач и приложений. Это требует дальнейшей корректировки и оптимизации некоторых параметров или внешних параметров модели на конкретном наборе данных. Целью точной настройки модели является изменение параметров самой модели в процессе обучения, чтобы она могла лучше выполнять конкретную задачу. Точная настройка модели по-прежнему требует обработки данных и вычислительных ресурсов, что также может привести к увеличению вычислительных затрат.
2.3 Оперативный проект (привнесение знаний в контекст)
Инжиниринг подсказок (внесение знаний в контекст) — это подход к раскрытию потенциала больших языковых моделей путем тщательного проектирования и оптимизации входных данных для них. Он направляет модель на получение более точных и релевантных результатов для различных задач путем создания конкретных текстовых входных данных (называемых подсказками). Совет: проекту не требуется изменять саму модель, но он оптимизирует производительность модели за счет корректировки входных данных. Преимущество оперативного проекта в том, что он может быстро адаптироваться под разные задачи и сценарии без переобучения модели. Его можно использовать «из коробки» и очень быстро внедрить приложение.
Например, мы хотим, чтобы помощник давал имена нашим питомцам, например:
Дайте моей собаке имя -> молния
Дайте моей черной собаке имя, которое будет забавным и легко запоминающимся. -> Сяохэй
Дайте моему питомцу {xxx} имя -> xxx
Дайте моему {yyyyy} домашнему животному {xxxx} имя, которое будет забавным и легко запоминающимся. -> xxxx
Простейший помощник по присвоению имен домашним животным можно реализовать путем прямого вызова API-интерфейса большой модели. Однако, поскольку нам нужно больше возможностей и ограничений на сцене, прямой вызов API может привести к превышению лимита токена, нехватке долговременной памяти, безопасности данных. и т. д. Вопрос, библиотеки с открытым исходным кодом LangChain и llamaIndex были созданы в октябре и ноябре 2022 года соответственно, чтобы упростить разработку приложений ИИ.
2.4 Большая модель
Отечественные и зарубежныебольшая модель Высокоскоростная итерация, каждая большая и маленькая фабрика реализовала свою большую модель, чтобы вступить в войну сотен моделей и тысяч моделей, большая Прикладная часть модели также будет процветать. На прикладном уровне мы стараемся использовать разные размеры. возможность модели реализовать оперативное проектирование. В настоящее время в LangChain много больших Реализация чат-модели модели, встраивание и векторная библиотека, но некоторые из них до сих пор недоступны, что требует от нас сделать это самостоятельно, чтобы предоставить технологию. Лангчейн способствует лучшей поддержке разработки наших приложений.
3. Технология Лангчейн
LangChain — это среда разработки приложений, основанная на языковых моделях. Она обеспечивает соединение языковых моделей с другими источниками данных и позволяет языковым моделям взаимодействовать со своей средой. Она обеспечивает поддержку основных модулей, таких как схема, модель, подсказки и индексы. Простое понимание — это среда разработки для набора протоколов. Она разделяет технологии, необходимые для разработки ИИ, на небольшие элементы. Нет необходимости изобретать велосипед, комбинируя элементы один за другим, можно реализовать различные сценарии для облегчения разработки. и помощь. Чтобы повысить эффективность разработки приложений искусственного интеллекта, сообщество открытого исходного кода очень популярно. Кроме того, интерфейс можно разработать с использованием TypeScript.
3.1 Общая архитектура LangChain
Выше приведена общая схема архитектуры LangChain.
Модели: поддерживаются различные типы моделей и интеграция моделей.
Подсказки: включая управление подсказками, оптимизацию подсказок и сериализацию подсказок.
Память. Память — это концепция сохранения состояния между вызовами цепочки/агента. Говорят, что он может осуществлять долговременную память.
Индексы. Языковые модели, как правило, более эффективны в сочетании с собственными текстовыми данными.
Цепочки. Цепочки — это не просто один вызов LLM, а серия вызовов (будь то вызов LLM или другой утилиты), которые можно интегрировать с другими инструментами и обеспечить сквозную цепочку вызовов для общих приложений. Каждый вопрос и ответ в диалоге — это одноэтапная операция. Многие сложные сцены будут разбиты на несколько операций. Результаты первой цепочки необходимо внести на вход второй цепочки.
Агенты: Агенты вовлекают LLM в принятие решения о действии, выполнение этого действия, просмотр наблюдения и повторение процесса до завершения. Исполнители более высокого уровня распределяют и выполняют задачи, определяют, что необходимо сделать для завершения операции, и координируют обязанности по совместной работе.
Популяризация и улучшение API-интерфейсов больших моделей позволяют нам сосредоточиться на разработке приложений. К лучшим практическим сценариям относятся:
1. Вопросы и ответы
2.Поиск
3. Резюме
3.2 Установка библиотек, связанных с LangChain
LangChain написан на TypeScript.
pnpm add langchainpnpm add @langchain/communitypnpm add @langchain/core3.3 Модель LangChain
Модель — это различные типы моделей и поддерживаемые интеграции моделей. Она может взаимодействовать с различными языковыми моделями через этот интерфейс и поддерживает модели завершения текста (LLM), модели чата (ChatModel) и модели внедрения текста (Embedding).
Модели завершения текста (LLM) — это модель машинного обучения, основанная на языковых моделях. Они автоматически определяют наиболее вероятное следующее завершение текста на основе контекста и языковых правил контекста, то есть вводят фрагмент текстового содержимого и выводят фрагмент. текстовый контент.
Модель чата (ChatModel) — это вариант языковой модели. Модель чата использует языковую модель и предоставляет интерфейс, основанный на «сообщениях чата», то есть вводе набора сообщений чата и выводе сообщения чата.
Модель встраивания текста (Embedding) преобразует слова или предложения в плотные векторные представления. В векторном пространстве семантически схожие слова оказываются ближе. Его роль в LangChain — уменьшение размерности, семантический поиск и классификация текста. Уменьшение размерности — это встраивание слов, которое помогает уменьшить размерность текстовых данных, упрощая их обработку для моделей машинного обучения. Семантический поиск и встраивание текста обеспечивают эффективный поиск на основе семантического сходства между запросами и документами, повышая релевантность результатов поиска. Классификация текста с использованием внедрений в качестве входных данных для моделей классификации повышает производительность таких задач, как анализ настроений и классификация тем.
3.4 LangChain-ChatModel
LangChain предоставляет множество моделей чатов, таких как ChatOpenAI, Google Vertex AI и т. д., которые можно использовать прямо из коробки.
ChatOpenAI import { ChatOpenAI } from "langchain/chat_models/openai";
Google Vertex AI import { ChatGoogleVertexAI } from "langchain/chat_models/googlevertexai";Если вы не нашли нужную модель чата в LangChain, вы можете самостоятельно реализовать модель чата на основе LangChain. Нам нужно всего лишь реализовать интерфейс завершения любой большой модели в соответствии со спецификацией LangChain, а затем опубликовать его в NPM. например пакет @xxxx/xxxx-langchain, ниже приведен пример использования:
XXXXXAI import { XXXXXAI } from "@xxxx/xxxx-langchain/langchain/chat_models/xxxxai";
const model = new XXXXXAI({
apiKey: process.env.xxx_API_KEY
});
model.call("Кто вы?");Принцип реализации:
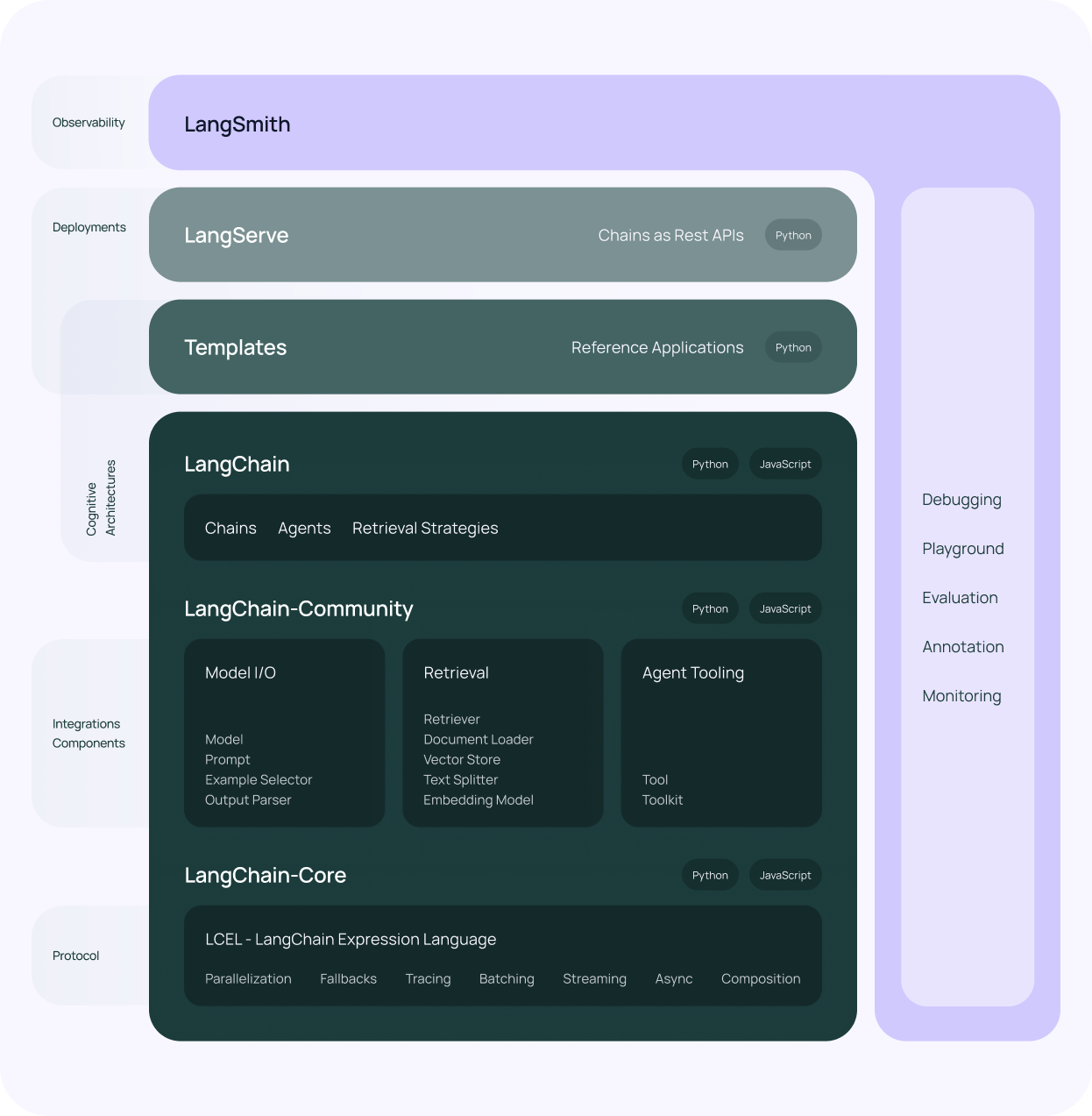
Чтобы использовать REST API (дополнение), предоставляемое большой моделью для завершения текста, пользователь вводит фрагмент текста приглашения, и модель выдает соответствующий вывод в соответствии с текстовым приглашением. В основном он реализует метод генерации. Ниже приведен код. пример.
export class xxxxAI extends BaseChatModel {
_combineLLMOutput?(...llmOutputs: (Record<string, any> | undefined)[]): Record<string, any> | undefined {
throw new Error("Method not implemented.");
}
_llmType(): string {
throw new Error("Method not implemented.");
}
_generate(messages: BaseMessage[], options: this["ParsedCallOptions"], runManager?: CallbackManagerForLLMRun | undefined): Promise<ChatResult> {
throw new Error("Method not implemented.");
}
}Библиотека лангчейна Шенпа
Ниже приводится реализация ZhipuAI.
import {
BaseChatModel,
type BaseChatModelParams,
} from "@langchain/core/language_models/chat_models";
import {
AIMessage,
type BaseMessage,
ChatMessage,
} from "@langchain/core/messages";
import { type ChatResult } from "@langchain/core/outputs";
import { type CallbackManagerForLLMRun } from "@langchain/core/callbacks/manager";
import { getEnvironmentVariable } from "@langchain/core/utils/env";
import { encodeApiKey } from "../utils/zhipuai.js";
export type ZhipuMessageRole = "system" | "assistant" | "user";
interface ZhipuMessage {
role: ZhipuMessageRole;
content: string;
}
/**
* Interface representing a request for a chat completion.
*
* See https://open.bigmodel.cn/dev/howuse/model
*/
type ModelName =
| (string & NonNullable<unknown>)
// will be deprecated models
| "chatglm_pro" // deprecated in 2024-12-31T23:59:59+0800,point to glm-4
| "chatglm_std" // deprecated in 2024-12-31T23:59:59+0800,point to glm-3-turbo
| "chatglm_lite" // deprecated in 2024-12-31T23:59:59+0800,point to glm-3-turbo
// GLM-4 more powerful on Q/A and text generation, suitable for complex dialog interactions and deep content creation design.
| "glm-4" // context size: 128k
| "glm-4v" // context size: 2k
// ChatGLM-Turbo
| "glm-3-turbo" // context size: 128k
| "chatglm_turbo"; // context size: 32k
interface ChatCompletionRequest {
model: ModelName;
messages?: ZhipuMessage[];
do_sample?: boolean;
stream?: boolean;
request_id?: string;
max_tokens?: number | null;
top_p?: number | null;
top_k?: number | null;
temperature?: number | null;
stop?: string[];
}
interface BaseResponse {
code?: string;
message?: string;
}
interface ChoiceMessage {
role: string;
content: string;
}
interface ResponseChoice {
index: number;
finish_reason: "stop" | "length" | "null" | null;
delta: ChoiceMessage;
message: ChoiceMessage;
}
/**
* Interface representing a response from a chat completion.
*/
interface ChatCompletionResponse extends BaseResponse {
choices: ResponseChoice[];
created: number;
id: string;
model: string;
request_id: string;
usage: {
completion_tokens: number;
prompt_tokens: number;
total_tokens: number;
};
output: {
text: string;
finish_reason: "stop" | "length" | "null" | null;
};
}
/**
* Interface defining the input to the ZhipuAIChatInput class.
*/
export interface ChatZhipuAIParams {
/**
* @default "glm-3-turbo"
*/
modelName: ModelName;
/** Whether to stream the results or not. Defaults to false. */
streaming?: boolean;
/** Messages to pass as a prefix to the prompt */
messages?: ZhipuMessage[];
/**
* API key to use when making requests. Defaults to the value of
* `ZHIPUAI_API_KEY` environment variable.
*/
zhipuAIApiKey?: string;
/** Amount of randomness injected into the response. Ranges
* from 0 to 1 (0 is not included). Use temp closer to 0 for analytical /
* multiple choice, and temp closer to 1 for creative
* and generative tasks. Defaults to 0.95
*/
temperature?: number;
/** Total probability mass of tokens to consider at each step. Range
* from 0 to 1 Defaults to 0.7
*/
topP?: number;
/**
* Unique identifier for the request. Defaults to a random UUID.
*/
requestId?: string;
/**
* turn on sampling strategy when do_sample is true,
* do_sample is false, temperature、top_p will not take effect
*/
doSample?: boolean;
/**
* max value is 8192,defaults to 1024
*/
maxTokens?: number;
stop?: string[];
}
function messageToRole(message: BaseMessage): ZhipuMessageRole {
const type = message._getType();
switch (type) {
case "ai":
return "assistant";
case "human":
return "user";
case "system":
return "system";
case "function":
throw new Error("Function messages not supported yet");
case "generic": {
if (!ChatMessage.isInstance(message)) {
throw new Error("Invalid generic chat message");
}
if (["system", "assistant", "user"].includes(message.role)) {
return message.role as ZhipuMessageRole;
}
throw new Error(`Unknown message type: ${type}`);
}
default:
throw new Error(`Unknown message type: ${type}`);
}
}
export class ChatZhipuAI extends BaseChatModel implements ChatZhipuAIParams {
static lc_name() {
return "ChatZhipuAI";
}
get callKeys() {
return ["stop", "signal", "options"];
}
get lc_secrets() {
return {
zhipuAIApiKey: "ZHIPUAI_API_KEY",
};
}
get lc_aliases() {
return undefined;
}
zhipuAIApiKey?: string;
streaming: boolean;
doSample?: boolean;
messages?: ZhipuMessage[];
requestId?: string;
modelName: ChatCompletionRequest["model"];
apiUrl: string;
maxTokens?: number | undefined;
temperature?: number | undefined;
topP?: number | undefined;
stop?: string[];
constructor(fields: Partial<ChatZhipuAIParams> & BaseChatModelParams = {}) {
super(fields);
this.zhipuAIApiKey = encodeApiKey(
fields?.zhipuAIApiKey ?? getEnvironmentVariable("ZHIPUAI_API_KEY")
);
if (!this.zhipuAIApiKey) {
throw new Error("ZhipuAI API key not found");
}
this.apiUrl = "https://open.bigmodel.cn/api/paas/v4/chat/completions";
this.streaming = fields.streaming ?? false;
this.messages = fields.messages ?? [];
this.temperature = fields.temperature ?? 0.95;
this.topP = fields.topP ?? 0.7;
this.stop = fields.stop;
this.maxTokens = fields.maxTokens;
this.modelName = fields.modelName ?? "glm-3-turbo";
this.doSample = fields.doSample;
}
/**
* Get the parameters used to invoke the model
*/
invocationParams(): Omit<ChatCompletionRequest, "messages"> {
return {
model: this.modelName,
request_id: this.requestId,
do_sample: this.doSample,
stream: this.streaming,
temperature: this.temperature,
top_p: this.topP,
max_tokens: this.maxTokens,
stop: this.stop,
};
}
/**
* Get the identifying parameters for the model
*/
identifyingParams(): Omit<ChatCompletionRequest, "messages"> {
return this.invocationParams();
}
/** @ignore */
async _generate(
messages: BaseMessage[],
options?: this["ParsedCallOptions"],
runManager?: CallbackManagerForLLMRun
): Promise<ChatResult> {
const parameters = this.invocationParams();
const messagesMapped: ZhipuMessage[] = messages.map((message) => ({
role: messageToRole(message),
content: message.content as string,
}));
const data = parameters.stream
? await new Promise<ChatCompletionResponse>((resolve, reject) => {
let response: ChatCompletionResponse;
let rejected = false;
let resolved = false;
this.completionWithRetry(
{
...parameters,
messages: messagesMapped,
},
true,
options?.signal,
(event) => {
const data: ChatCompletionResponse = JSON.parse(event.data);
if (data?.code) {
if (rejected) {
return;
}
rejected = true;
reject(new Error(data?.message));
return;
}
const { delta, finish_reason } = data.choices[0];
const text = delta.content;
if (!response) {
response = {
...data,
output: { text, finish_reason },
};
} else {
response.output.text += text;
response.output.finish_reason = finish_reason;
response.usage = data.usage;
}
void runManager?.handleLLMNewToken(text ?? "");
if (finish_reason && finish_reason !== "null") {
if (resolved || rejected) return;
resolved = true;
resolve(response);
}
}
).catch((error) => {
if (!rejected) {
rejected = true;
reject(error);
}
});
})
: await this.completionWithRetry(
{
...parameters,
messages: messagesMapped,
},
false,
options?.signal
).then<ChatCompletionResponse>((data) => {
if (data?.code) {
throw new Error(data?.message);
}
const { finish_reason, message } = data.choices[0];
const text = message.content;
return {
...data,
output: { text, finish_reason },
};
});
const {
prompt_tokens = 0,
completion_tokens = 0,
total_tokens = 0,
} = data.usage;
const { text } = data.output;
return {
generations: [
{
text,
message: new AIMessage(text),
},
],
llmOutput: {
tokenUsage: {
promptTokens: prompt_tokens,
completionTokens: completion_tokens,
totalTokens: total_tokens,
},
},
};
}
/** @ignore */
async completionWithRetry(
request: ChatCompletionRequest,
stream: boolean,
signal?: AbortSignal,
onmessage?: (event: MessageEvent) => void
) {
const makeCompletionRequest = async () => {
const response = await fetch(this.apiUrl, {
method: "POST",
headers: {
...(stream ? { Accept: "text/event-stream" } : {}),
Authorization: `Bearer ${this.zhipuAIApiKey}`,
"Content-Type": "application/json",
},
body: JSON.stringify(request),
signal,
});
if (!stream) {
return response.json();
}
if (response.body) {
// response will not be a stream if an error occurred
if (
!response.headers.get("content-type")?.startsWith("text/event-stream")
) {
onmessage?.(
new MessageEvent("message", {
data: await response.text(),
})
);
return;
}
const reader = response.body.getReader();
const decoder = new TextDecoder("utf-8");
let data = "";
let continueReading = true;
while (continueReading) {
const { done, value } = await reader.read();
if (done) {
continueReading = false;
break;
}
data += decoder.decode(value);
let continueProcessing = true;
while (continueProcessing) {
const newlineIndex = data.indexOf("\n");
if (newlineIndex === -1) {
continueProcessing = false;
break;
}
const line = data.slice(0, newlineIndex);
data = data.slice(newlineIndex + 1);
if (line.startsWith("data:")) {
const value = line.slice("data:".length).trim();
if (value === "[DONE]") {
continueReading = false;
break;
}
const event = new MessageEvent("message", { data: value });
onmessage?.(event);
}
}
}
}
};
return this.caller.call(makeCompletionRequest);
}
_llmType(): string {
return "zhipuai";
}
/** @ignore */
_combineLLMOutput() {
return [];
}
}3.5 LangChain-Embedding
LangChain также предоставляет множество моделей встраивания текста, таких как ChatOpenAI, Google Vertex AI и т. д., которые также можно использовать прямо из коробки. Он может преобразовывать текст в высококачественные векторные данные, например: {"встраивание": -0.006929283495992422,-0.005336422007530928,...-4.547132266452536e-05,-0.024047505110502243}, что позволяет получить более точный ответ
import { OpenAIEmbeddings } from "langchain/embeddings/openai";
import { GoogleVertexAIEmbeddings } from "langchain/embeddings/googlevertexai";Если вы не нашли нужную модель внедрения текста в LangChain, вы также можете реализовать модель внедрения текста на основе LangChain. Например, если мы хотим реализовать XXXXEmbeddings, класс XXXXEmbeddings может помочь нам реализовать вопросы и ответы, а также семантический поиск на основе базы знаний. Самым большим преимуществом по сравнению с тонкой настройкой является то, что он не требует обучения и может добавлять новый контент. в реальном времени без однократного добавления нового контента. Просто тренируйтесь один раз, и стоимость во всех аспектах намного ниже, чем тонкая настройка. Затем вы можете опубликовать его в NPM, например, опубликовать пакет @xxxx/xxxx-langchain. пример использования:
import { XXXXEmbeddings } from "@xxxx/xxxx-langchain/langchain/embeddings/xxxxai";
const embeddings = new XXXXEmbeddings({
apiKey: process.env.xxxxx_API_KEY
});
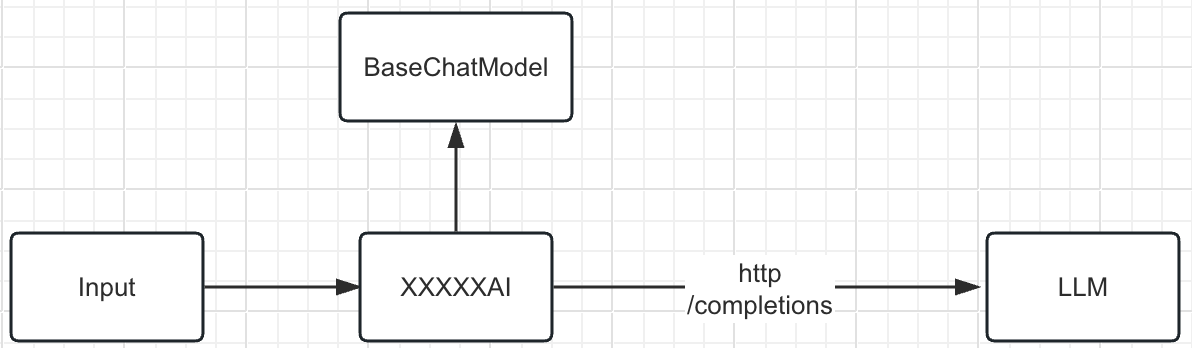
embeddings.embedQuery("Кто вы?")Принцип реализации:
XXXXEmbeddings использует REST API большой модели (/embeddings) для создания внедрений для заданного текста. Он используется для обобщения документов, текстов или больших объемов данных, а также в сценариях вопросов и ответов. Он преобразует текст и другой контент в многомерные массивы, которые можно использовать для последующего расчета и поиска сходств. В основном он реализует два метода. : embed_documents и embed_query. Он предоставляет два метода: embedDocuments и embedQuery. Самая большая разница заключается в том, что эти два метода имеют разные интерфейсы: один обрабатывает несколько документов, а другой — один документ. Ниже приведен пример кода
export class XXXX AIEmbeddings extends Embeddings {
constructor(fields?: any) {
super(fields ?? {});
}
embedDocuments(documents: string[]): Promise<number[][]> {
throw new Error("Method not implemented.");
}
embedQuery(document: string): Promise<number[]> {
throw new Error("Method not implemented.");
}
}Библиотека лангчейна Шенпа
Ниже приведена реализация VoyageEmbedding.
import { getEnvironmentVariable } from "@langchain/core/utils/env";
import { Embeddings, type EmbeddingsParams } from "@langchain/core/embeddings";
import { chunkArray } from "@langchain/core/utils/chunk_array";
/**
* Interface that extends EmbeddingsParams and defines additional
* parameters specific to the VoyageEmbeddings class.
*/
export interface VoyageEmbeddingsParams extends EmbeddingsParams {
modelName: string;
/**
* The maximum number of documents to embed in a single request. This is
* limited by the Voyage AI API to a maximum of 8.
*/
batchSize?: number;
}
/**
* Interface for the request body to generate embeddings.
*/
export interface CreateVoyageEmbeddingRequest {
/**
* @type {string}
* @memberof CreateVoyageEmbeddingRequest
*/
model: string;
/**
* Text to generate vector expectation
* @type {CreateEmbeddingRequestInput}
* @memberof CreateVoyageEmbeddingRequest
*/
input: string | string[];
}
/**
* A class for generating embeddings using the Voyage AI API.
*/
export class VoyageEmbeddings
extends Embeddings
implements VoyageEmbeddingsParams
{
modelName = "voyage-01";
batchSize = 8;
private apiKey: string;
basePath?: string = "https://api.voyageai.com/v1";
apiUrl: string;
headers?: Record<string, string>;
/**
* Constructor for the VoyageEmbeddings class.
* @param fields - An optional object with properties to configure the instance.
*/
constructor(
fields?: Partial<VoyageEmbeddingsParams> & {
verbose?: boolean;
apiKey?: string;
}
) {
const fieldsWithDefaults = { ...fields };
super(fieldsWithDefaults);
const apiKey =
fieldsWithDefaults?.apiKey || getEnvironmentVariable("VOYAGEAI_API_KEY");
if (!apiKey) {
throw new Error("Voyage AI API key not found");
}
this.modelName = fieldsWithDefaults?.modelName ?? this.modelName;
this.batchSize = fieldsWithDefaults?.batchSize ?? this.batchSize;
this.apiKey = apiKey;
this.apiUrl = `${this.basePath}/embeddings`;
}
/**
* Generates embeddings for an array of texts.
* @param texts - An array of strings to generate embeddings for.
* @returns A Promise that resolves to an array of embeddings.
*/
async embedDocuments(texts: string[]): Promise<number[][]> {
const batches = chunkArray(texts, this.batchSize);
const batchRequests = batches.map((batch) =>
this.embeddingWithRetry({
model: this.modelName,
input: batch,
})
);
const batchResponses = await Promise.all(batchRequests);
const embeddings: number[][] = [];
for (let i = 0; i < batchResponses.length; i += 1) {
const batch = batches[i];
const { data: batchResponse } = batchResponses[i];
for (let j = 0; j < batch.length; j += 1) {
embeddings.push(batchResponse[j].embedding);
}
}
return embeddings;
}
/**
* Generates an embedding for a single text.
* @param text - A string to generate an embedding for.
* @returns A Promise that resolves to an array of numbers representing the embedding.
*/
async embedQuery(text: string): Promise<number[]> {
const { data } = await this.embeddingWithRetry({
model: this.modelName,
input: text,
});
return data[0].embedding;
}
/**
* Makes a request to the Voyage AI API to generate embeddings for an array of texts.
* @param request - An object with properties to configure the request.
* @returns A Promise that resolves to the response from the Voyage AI API.
*/
private async embeddingWithRetry(request: CreateVoyageEmbeddingRequest) {
const makeCompletionRequest = async () => {
const url = `${this.apiUrl}`;
const response = await fetch(url, {
method: "POST",
headers: {
"Content-Type": "application/json",
Authorization: `Bearer ${this.apiKey}`,
...this.headers,
},
body: JSON.stringify(request),
});
const json = await response.json();
return json;
};
return this.caller.call(makeCompletionRequest);
}
}3.6 Роли LangChain в больших моделях
В диалоге большой модели есть три роли: помощник (ИИ), система (система) и пользователь (человек). Понимание этих трех ролей может помочь лучше реализовать приложения ИИ.
Роль system (система) в основном отвечает за предоставление контекстной информации и начальных инструкций модели. Это помогает модели понять, как отвечать на вопросы, заданные пользователями. Хотя системные роли не обязательны, для достижения наилучших результатов важно включать хотя бы одну базовую системную роль.
Например: вы являетесь интерфейсным роботом, который помогает пользователям отвечать на вопросы по кодированию.
Пользователь (человек) получает необходимую информацию, задавая вопросы или отправляя запросы ассистенту.
Например: помогите мне создать быструю очередь
помощник (ИИ) помощник будет генерировать ответы на основе ролей системы и вопросов, заданных пользователями.
Например: хххххх
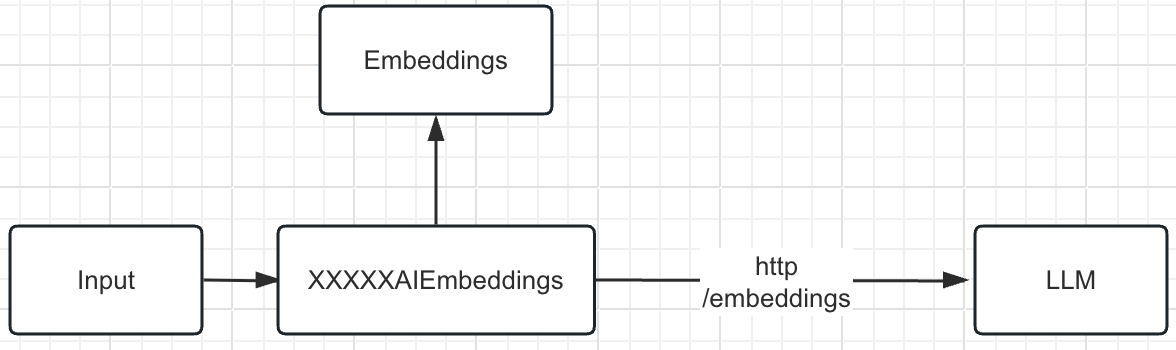
3.7 Тип сообщения LangChain
LangChain предоставляет следующие классы сообщений: AIMessage, HumanMessage, SystemMessage, FunctionMessage, ToolMessage и ChatMessage. Все они интегрируют базовый класс BaseMessage и соответствуют различным ролям.
Роль | Тип сообщения | пример |
|---|---|---|
assistant | AIMessage | Прогноз погоды в Шанхае на завтра: солнечно, с сильным ветром. Температура 2°С. |
user | HumanMessage | Как погода в Шанхае? |
system | SystemMessage | Вы ассистент хххх. |
function | FunctionMessage | {'role': 'function', 'name': 'get_function', 'content': 'xxxxx'} |
HumanMessage — сообщение, введенное пользователем.
AIMessage — большая языковая модель сообщений для общения с людьми.
SystemMessage — системное сообщение, обычно отправляемое в начале разговора.
ChatMessage — это настраиваемый тип сообщения.
FunctionMessage — функциональное сообщение.
ToolMessage — сообщение инструмента.
Chat Message History
Класс ChatMessageHistory отвечает за запоминание всех данных предыдущего взаимодействия в чате, которые затем можно передать обратно в модель, агрегировать или иным образом объединить. Это помогает поддерживать контекст и улучшает понимание модели разговора.
3.8 LangChain-векторная библиотека
Библиотека векторов — это база данных, оптимизированная для хранения документов и их вложений. Она в основном используется для поиска изображений, аудио, текста и других областях. Ее основная особенность заключается в том, что она может эффективно хранить и извлекать крупномасштабные векторные данные.
LangChain также предоставляет множество готовых методов хранения векторов, таких как Chroma (встроенная база данных Apache 2.0 с открытым исходным кодом), Redis и RediSearch, который поддерживает семантический поиск по сходству векторов.
Если вы не нашли в LangChain базу данных векторов, которую хотите использовать, вы можете реализовать собственный интерфейс базы данных векторов в соответствии со спецификацией LangChain, а затем опубликовать ее в NPM, например опубликовать пакет @xxxx/xxxxx-langchain. Ниже приведен пример использования:
import { LangchainXXXXStore} from"@xxxx/xxxxx-langchain"
const textSplitter = new RecursiveCharacterTextSplitter({ chunkSize: 100, chunkOverlap: 0 });
const docs = await textSplitter.createDocuments(["text"]); const vectorStoreVec = await LangchainVectorStore.fromDocuments( docs,
new XXXXXAIEmbeddings({
apiKey: "xxxxxxxxxxxxxxx"
}),
{
url: "xxxxxxxxx",
username: "xxxxxxxxx",
key: "xxxxxxxxxxxxxxxxx",
timeout: 10,
databaseName: "xxxxxxxxx",
collectionName: "xxxxxxxxx"
});
vectorStoreVec.asRetriever()Принцип реализации:
Используйте REST API базы данных векторов для таких операций, как запись и запрос данных, для хранения векторов, расчета и извлечения сходства, а также объедините его с платформой langchain, чтобы в основном реализовать три метода: addVectors, addDocuments иlikeitySearchVectorWithScore. Ниже приведен пример кода
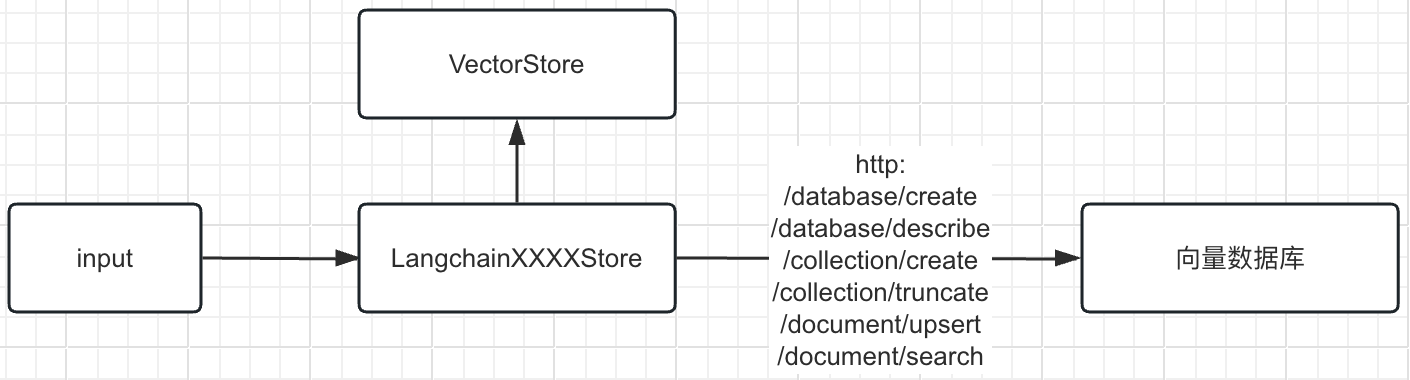
export class LangchainXXXXStore extends VectorStore {
_vectorstoreType(): string {
throw new Error("Method not implemented.");
}
addVectors(vectors: number[][], documents: DocumentInterface<Record<string, any>>[], options?: { [x: string]: any; } | undefined): Promise<void | string[]> {
throw new Error("Method not implemented.");
}
addDocuments(documents: DocumentInterface<Record<string, any>>[], options?: { [x: string]: any; } | undefined): Promise<void | string[]> {
throw new Error("Method not implemented.");
}
similaritySearchVectorWithScore(query: number[], k: number, filter?: this["FilterType"] | undefined): Promise<[DocumentInterface<Record<string, any>>, number][]> {
throw new Error("Method not implemented.");
}
}Библиотека лангчейна Шенпа
Ниже приведена реализация AstraDBVectorStore.
import * as uuid from "uuid";
import { AstraDB } from "@datastax/astra-db-ts";
import { Collection } from "@datastax/astra-db-ts/dist/collections";
import { CreateCollectionOptions } from "@datastax/astra-db-ts/dist/collections/options.js";
import {
AsyncCaller,
AsyncCallerParams,
} from "@langchain/core/utils/async_caller";
import { Document } from "@langchain/core/documents";
import type { EmbeddingsInterface } from "@langchain/core/embeddings";
import { chunkArray } from "@langchain/core/utils/chunk_array";
import { maximalMarginalRelevance } from "@langchain/core/utils/math";
import {
MaxMarginalRelevanceSearchOptions,
VectorStore,
} from "@langchain/core/vectorstores";
export type CollectionFilter = Record<string, unknown>;
export interface AstraLibArgs extends AsyncCallerParams {
token: string;
endpoint: string;
collection: string;
namespace?: string;
idKey?: string;
contentKey?: string;
collectionOptions?: CreateCollectionOptions;
batchSize?: number;
}
export type AstraDeleteParams = {
ids: string[];
};
export class AstraDBVectorStore extends VectorStore {
declare FilterType: CollectionFilter;
private astraDBClient: AstraDB;
private collectionName: string;
private collection: Collection | undefined;
private collectionOptions: CreateCollectionOptions | undefined;
private readonly idKey: string;
private readonly contentKey: string; // if undefined the entirety of the content aside from the id and embedding will be stored as content
private readonly batchSize: number; // insertMany has a limit of 20 documents
caller: AsyncCaller;
_vectorstoreType(): string {
return "astradb";
}
constructor(embeddings: EmbeddingsInterface, args: AstraLibArgs) {
super(embeddings, args);
const {
token,
endpoint,
collection,
collectionOptions,
namespace,
idKey,
contentKey,
batchSize,
...callerArgs
} = args;
this.astraDBClient = new AstraDB(token, endpoint, namespace);
this.collectionName = collection;
this.collectionOptions = collectionOptions;
this.idKey = idKey ?? "_id";
this.contentKey = contentKey ?? "text";
this.batchSize = batchSize && batchSize <= 20 ? batchSize : 20;
this.caller = new AsyncCaller(callerArgs);
}
/**
* Create a new collection in your Astra DB vector database and then connects to it.
* If the collection already exists, it will connect to it as well.
*
* @returns Promise that resolves if connected to the collection.
*/
async initialize(): Promise<void> {
await this.astraDBClient.createCollection(
this.collectionName,
this.collectionOptions
);
this.collection = await this.astraDBClient.collection(this.collectionName);
console.debug("Connected to Astra DB collection");
}
/**
* Method to save vectors to AstraDB.
*
* @param vectors Vectors to save.
* @param documents The documents associated with the vectors.
* @returns Promise that resolves when the vectors have been added.
*/
async addVectors(
vectors: number[][],
documents: Document[],
options?: string[]
) {
if (!this.collection) {
throw new Error("Must connect to a collection before adding vectors");
}
const docs = vectors.map((embedding, idx) => ({
[this.idKey]: options?.[idx] ?? uuid.v4(),
[this.contentKey]: documents[idx].pageContent,
$vector: embedding,
...documents[idx].metadata,
}));
const chunkedDocs = chunkArray(docs, this.batchSize);
const batchCalls = chunkedDocs.map((chunk) =>
this.caller.call(async () => this.collection?.insertMany(chunk))
);
await Promise.all(batchCalls);
}
/**
* Method that adds documents to AstraDB.
*
* @param documents Array of documents to add to AstraDB.
* @param options Optional ids for the documents.
* @returns Promise that resolves the documents have been added.
*/
async addDocuments(documents: Document[], options?: string[]) {
if (!this.collection) {
throw new Error("Must connect to a collection before adding vectors");
}
return this.addVectors(
await this.embeddings.embedDocuments(documents.map((d) => d.pageContent)),
documents,
options
);
}
/**
* Method that deletes documents from AstraDB.
*
* @param params AstraDeleteParameters for the delete.
* @returns Promise that resolves when the documents have been deleted.
*/
async delete(params: AstraDeleteParams) {
if (!this.collection) {
throw new Error("Must connect to a collection before deleting");
}
for (const id of params.ids) {
console.debug(`Deleting document with id ${id}`);
await this.collection.deleteOne({
[this.idKey]: id,
});
}
}
/**
* Method that performs a similarity search in AstraDB and returns and similarity scores.
*
* @param query Query vector for the similarity search.
* @param k Number of top results to return.
* @param filter Optional filter to apply to the search.
* @returns Promise that resolves with an array of documents and their scores.
*/
async similaritySearchVectorWithScore(
query: number[],
k: number,
filter?: CollectionFilter
): Promise<[Document, number][]> {
if (!this.collection) {
throw new Error("Must connect to a collection before adding vectors");
}
const cursor = await this.collection.find(filter ?? {}, {
sort: { $vector: query },
limit: k,
includeSimilarity: true,
});
const results: [Document, number][] = [];
await cursor.forEach(async (row: Record<string, unknown>) => {
const {
$similarity: similarity,
[this.contentKey]: content,
...metadata
} = row;
const doc = new Document({
pageContent: content as string,
metadata,
});
results.push([doc, similarity as number]);
});
return results;
}
/**
* Return documents selected using the maximal marginal relevance.
* Maximal marginal relevance optimizes for similarity to the query AND diversity
* among selected documents.
*
* @param {string} query - Text to look up documents similar to.
* @param {number} options.k - Number of documents to return.
* @param {number} options.fetchK - Number of documents to fetch before passing to the MMR algorithm.
* @param {number} options.lambda - Number between 0 and 1 that determines the degree of diversity among the results,
* where 0 corresponds to maximum diversity and 1 to minimum diversity.
* @param {CollectionFilter} options.filter - Optional filter
*
* @returns {Promise<Document[]>} - List of documents selected by maximal marginal relevance.
*/
async maxMarginalRelevanceSearch(
query: string,
options: MaxMarginalRelevanceSearchOptions<this["FilterType"]>
): Promise<Document[]> {
if (!this.collection) {
throw new Error("Must connect to a collection before adding vectors");
}
const queryEmbedding = await this.embeddings.embedQuery(query);
const cursor = await this.collection.find(options.filter ?? {}, {
sort: { $vector: queryEmbedding },
limit: options.k,
includeSimilarity: true,
});
const results = (await cursor.toArray()) ?? [];
const embeddingList: number[][] = results.map(
(row) => row.$vector as number[]
);
const mmrIndexes = maximalMarginalRelevance(
queryEmbedding,
embeddingList,
options.lambda,
options.k
);
const topMmrMatches = mmrIndexes.map((idx) => results[idx]);
const docs: Document[] = [];
topMmrMatches.forEach((match) => {
const { [this.contentKey]: content, ...metadata } = match;
const doc: Document = {
pageContent: content as string,
metadata,
};
docs.push(doc);
});
return docs;
}
/**
* Static method to create an instance of AstraDBVectorStore from texts.
*
* @param texts The texts to use.
* @param metadatas The metadata associated with the texts.
* @param embeddings The embeddings to use.
* @param dbConfig The arguments for the AstraDBVectorStore.
* @returns Promise that resolves with a new instance of AstraDBVectorStore.
*/
static async fromTexts(
texts: string[],
metadatas: object[] | object,
embeddings: EmbeddingsInterface,
dbConfig: AstraLibArgs
): Promise<AstraDBVectorStore> {
const docs: Document[] = [];
for (let i = 0; i < texts.length; i += 1) {
const metadata = Array.isArray(metadatas) ? metadatas[i] : metadatas;
const doc = new Document({
pageContent: texts[i],
metadata,
});
docs.push(doc);
}
return AstraDBVectorStore.fromDocuments(docs, embeddings, dbConfig);
}
/**
* Static method to create an instance of AstraDBVectorStore from documents.
*
* @param docs The Documents to use.
* @param embeddings The embeddings to use.
* @param dbConfig The arguments for the AstraDBVectorStore.
* @returns Promise that resolves with a new instance of AstraDBVectorStore.
*/
static async fromDocuments(
docs: Document[],
embeddings: EmbeddingsInterface,
dbConfig: AstraLibArgs
): Promise<AstraDBVectorStore> {
const instance = new this(embeddings, dbConfig);
await instance.initialize();
await instance.addDocuments(docs);
return instance;
}
/**
* Static method to create an instance of AstraDBVectorStore from an existing index.
*
* @param embeddings The embeddings to use.
* @param dbConfig The arguments for the AstraDBVectorStore.
* @returns Promise that resolves with a new instance of AstraDBVectorStore.
*/
static async fromExistingIndex(
embeddings: EmbeddingsInterface,
dbConfig: AstraLibArgs
): Promise<AstraDBVectorStore> {
const instance = new this(embeddings, dbConfig);
await instance.initialize();
return instance;
}
}4. Сценарная практика
4.1 Сценарий генерации копирайтинга
Используя LLM для получения более точных и контекстуальных ответов, он также может эффективно снизить вероятность введения в заблуждение информации.

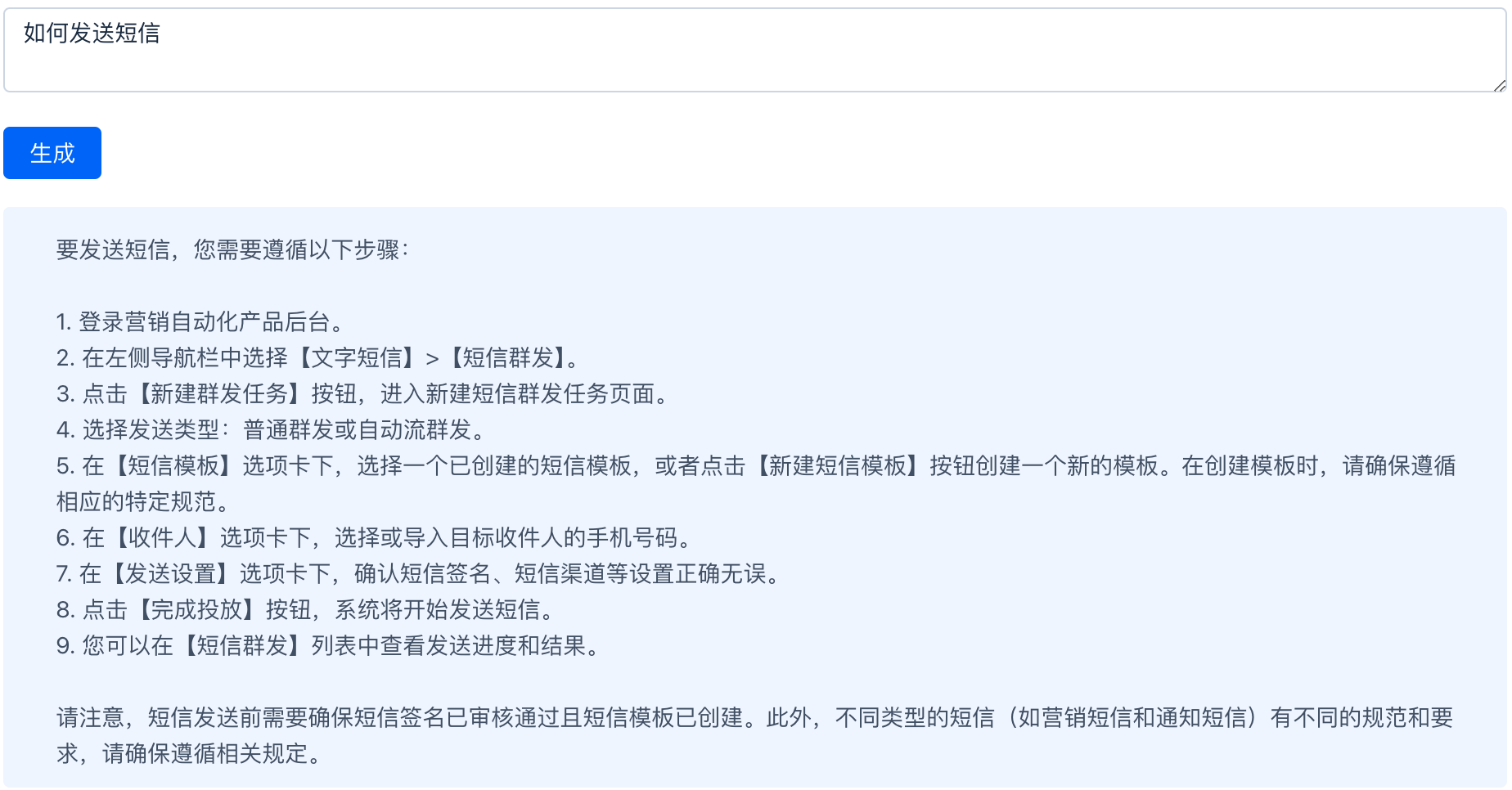
В этом сценарии в основном используется следующая Роль: AI、человек、система,И используйте метод ChatPromptTemplate.from_messages(xxx),Интегрируйте и создайте робота для генерации копирайтинга。prompt Шаблон относится к повторяемому способу создания подсказок. Он содержит текстовую строку («шаблон»), которая принимает набор параметров от конечного пользователя и генерирует приглашение.
Пример:
private systemTemplate = `Вы помощник по маркетинговому копирайтингу. Контент, который вам нужно создать, представляет собой маркетинговый шаблон в диапазоне {input} и выводит три элемента одновременно.`;
private humanTemplate = "{text}";
private chatPromptTemplate = ChatPromptTemplate.fromMessages([
["system", this.systemTemplate],
["human", this.humanTemplate]
]);
const model = new XXXXAI({
apiKey: process.env.xxxx_API_KEY,
temperature,
topP
})
model.call(chatPromptTemplate).formatMessages({
input: «Продвижение событий»,
text: "Вкусная лапша быстрого приготовления"
}))Сгенерированная подсказка запроса выглядит следующим образом:
{
"messages": [
{
"role": "system",
"content": «Вы помощник по маркетинговому копирайтингу. Контент, который вам нужно создать, представляет собой маркетинговый шаблон в рамках продвижения мероприятия и выводит три элемента одновременно».
},
{
"role": "user",
"content": "Вкусная лапша быстрого приготовления"
}
]
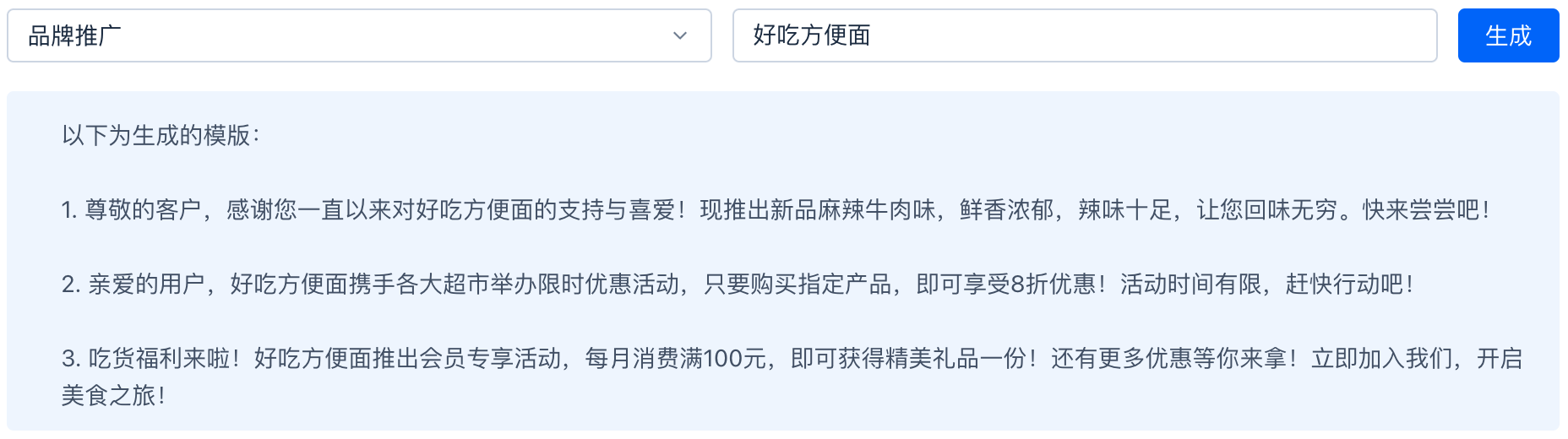
}Эффект разведки заключается в следующем:
4.2 Сценарий справочного документа
Документы справочного центра помогают пользователям понять методы работы продукта и меры предосторожности.
● Традиционный метод поиска:
Для традиционного поиска справочных документов нам необходимо хранить содержимое справочного документа в хранилище ES и получать результаты поиска с помощью возможностей поиска ES. В настоящее время сопоставление ключевых слов основано на словах. Трудно получить содержание слов со схожим значением, а эффективность поиска относительно низкая. С точки зрения технической реализации поиск по словам по-прежнему имеет преимущества, заключающиеся в том, что он быстрый и дешевый. .
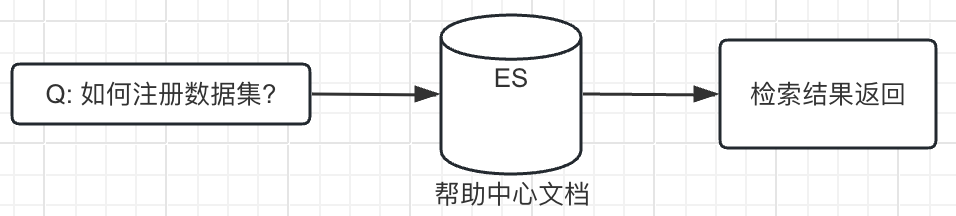
Традиционный поиск Пример:


● Метод большой модели:
Конечно, мы можем использовать большие модели напрямую. Обычные большие модели обучаются на общедоступных данных и имеют определенные ограничения в знаниях. Они не знают содержания наших справочных документов, поэтому ответы, которые они получают после вопросов, — это серьезная ерунда, наша помощь. документы являются общедоступным контентом и не связаны с безопасностью данных. Конечно, мы можем точно настроить модель с помощью содержимого документа, но это сложно и затратно.

● Метод улучшения поиска RAG:
Технология улучшения поиска RAG — это технология поиска + технология подсказок LLM. Это технология, которая может понимать контекст, генерировать, а не просто извлекать и рекомбинировать контент. Это практика объединения больших моделей с внешними данными и доступа к приложениям искусственного интеллекта на основе существующих данных. Приложение ИИ запоминает разговоры пользователя и анализирует разговоры пользователя, чтобы создать новый контекст. Таким образом, база данных LangChain+vector — очень хороший способ реализации RGA. Извлечение помогает большой модели предоставить больше контекста, чтобы сделать ответ более точным. После извлечения возвращается топк сходства, который затем объединяется в новое приглашение.
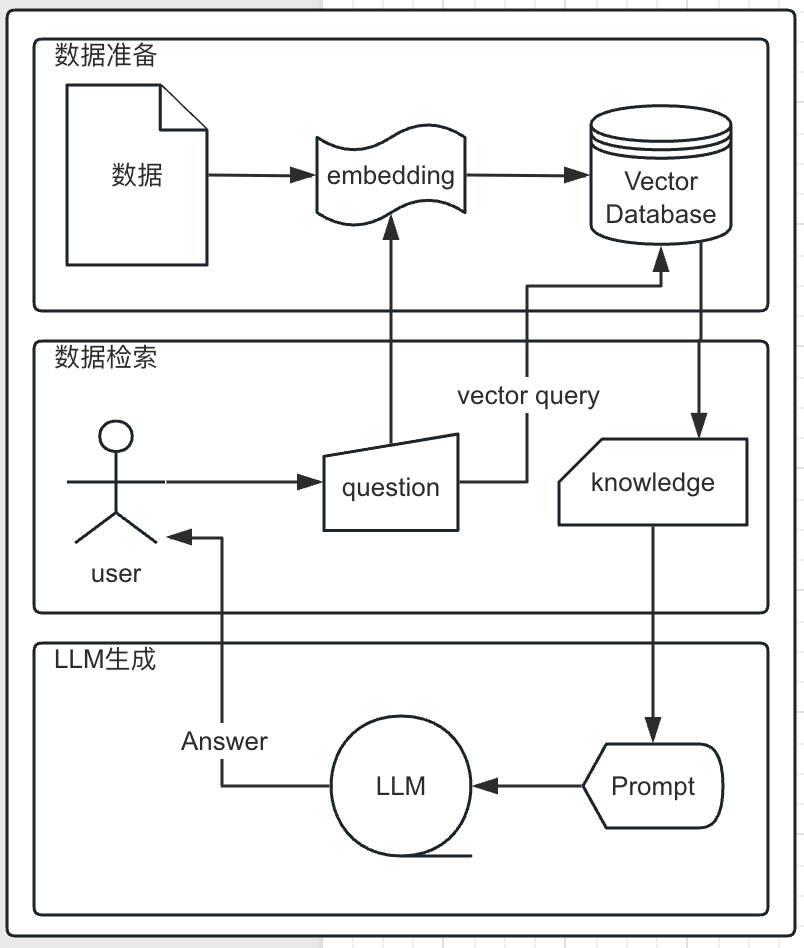
Общий рабочий процесс RAG
Подготовка данных:Получите соответствующую информацию из внешних источников знаний.,выполнять обработку данных,Повторная векторизация и сохранение в векторной базе данных.
Поиск: Преобразуйте запрос пользователя в вектор и сравните контекстную информацию в базе данных векторов. С помощью поиска по сходству вы можете найти наиболее подходящий топ. k данные.
Улучшение: Запрос пользователя и полученная информация объединяются в подсказки на основе заранее заданного шаблона подсказки.
генерировать: Получение расширенного содержимого подсказок в большую языковую модель (LLM) для получения желаемого результата.
Справочный центр документации RGA реализует весь процесс:
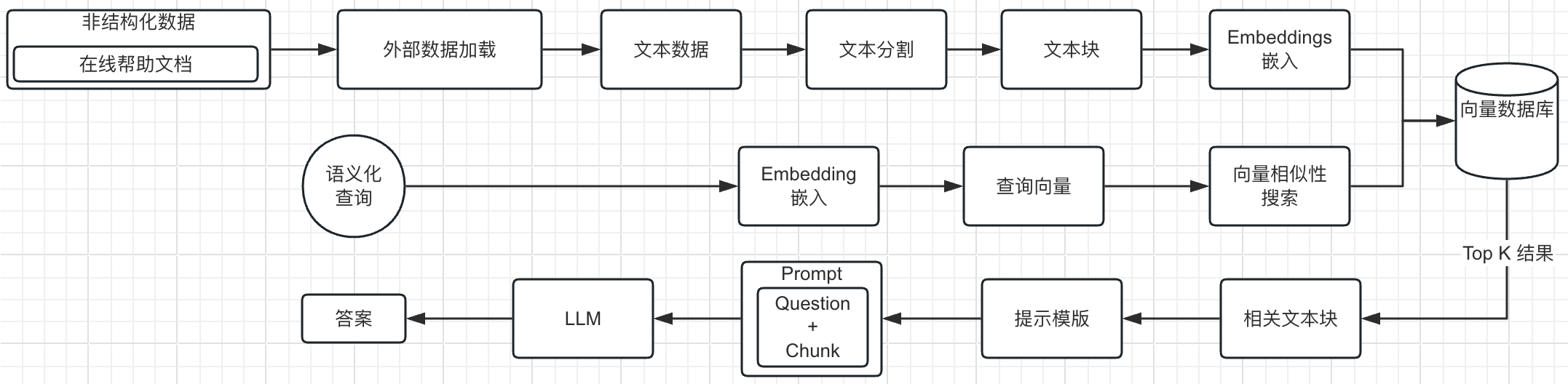
1. Получите исходный документ и разделите его на текстовые фрагменты. Разделите каждый справочный документ на части, страница за страницей.
2. Затем сохраните текстовый блок в векторной базе данных.
3. Во время запроса извлекайте блоки текста путем встраивания с использованием фильтров сходства и/или ключевых слов.
4. Выполните комплексный ответ.
Подготовка и поиск данных

Загрузчик документов: загружает документы из различных источников. В настоящее время существует два способа загрузки документов: загрузка файла и загрузка через Интернет.
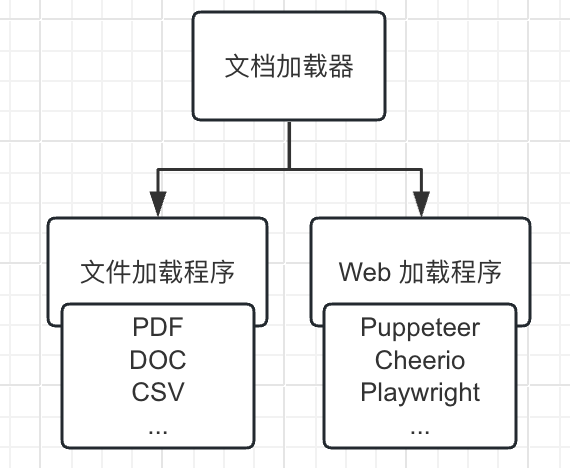
В настоящее время в этом предварительном исследовании мы используем загрузчик PDF-документов, и метод его использования следующий:
const loader = new PDFLoader("/Users/xxxxx/Desktop/xxxx.pdf");
const docs = await loader.load();Сегментация текста используется для разделения текста, поскольку каждый раз, когда мы отправляем текст в виде запроса в API большой модели или используем функцию внедрения, существует ограничение на количество символов.
Например, если мы отправим 300-страничный PDF-файл API большой модели и попросим его обобщить его, он обязательно сообщит об ошибке превышения максимального токена, поэтому здесь нам нужно использовать разделитель текста, чтобы разделить поступающий документ. из нашего загрузчика.
Существует общий предел длины содержимого в сообщениях большой модели. Если он превышает этот предел, содержимое начала будет обрезано и останется только содержимое хвоста.
const textSplitter = new RecursiveCharacterTextSplitter({ chunkSize: 100, chunkOverlap: 0 });
const docs = await textSplitter.createDocuments(["text"]); Рекомендуемый по умолчанию разделитель текста — RecursiveCharacterTextSplitter. По умолчанию он разделен символами «\n\n», «\n», «», «». Другие описания параметров: Как length_function вычисляет длину блока. По умолчанию подсчитываются только символы, но здесь обычно передается счетчик токенов. chunk_size: максимальный размер фрагментов (измеряется функцией длины). chunk_overlap: максимальное перекрытие между чанками. Было бы неплохо иметь некоторое перекрытие, чтобы сохранить некоторую непрерывность между блоками (например, сделать скользящее окно).
Поиск по вектору
import { LangchainXXXXStore } from "@xxxx/xxx-langchain"
const vectorStoreVec = await LangchainXXXXStore.fromDocuments(docs, this.embeddings, { url: "xxx", username: "xxx", key: "xxxxx", timeout: 10, databaseName: "xxxx", collectionName: "xxxxx"});
vectorStoreVec.asRetriever()Расширенная подсказка по поиску RAG
Шаблон запроса на документацию справочного центра:
`Use the following pieces of context to answer the question at the end. If you don't know the answer, just say that you don't know, don't try to make up an answer.{context}Question: {question}Answer in Chinaese:`;Пример подсказки добавлен в поиск RAG:
"Use the following pieces of context to answer the question at the end. If you don't know the answer, just say that you don't know, don't try to make up an answer.\n" +'Анализ событий количественно определяет одно или несколько событий с использованием таких показателей, как общее количество раз и общее количество людей, и детализирует несколько измерений. Анализ, проведение углубленных исследований и изучение поведения пользователей, а также настройка представлений анализа, таких как кривые диаграммы, гистограммы, таблицы и т. д. \n' +'Посредством различных операций настройки анализа событий можно анализировать данные в следующих сценариях: \n' +'●В мероприятии, выпущенном 10 минут назад, в какой версии участвует наибольшее количество пользователей и каково распределение различных брендов и моделей? \n' +'●В новой версии, выпущенной утром, какие каналы имеют самый высокий показатель просмотров видео пользователями? Насколько вы активны в каждый период времени? \n' +'●Каково распределение пользователей из Гуандуна на прошлой неделе, подписавшихся на трехдневное бесплатное пробное членство, по возрастным группам? \n' +'Кроме того, в пределах выбранного вами временного диапазона, помимо обычной детализации дней, недель и месяцев, вы также можете установить его на часы и минуты для достижения цели статистического мониторинга в реальном времени. \n' +'Как и другие модели анализа, вы можете загрузить данные результатов анализа в Excel, сохранить представление анализа, дать ему имя, удалить и добавить на панель мониторинга. \n' +'3.2.1.2 Выберите источник данных \n' +'Question: Что означает анализ событий\n' +'\n' +'Answer in Chinaese:'Эффект разведки заключается в следующем.
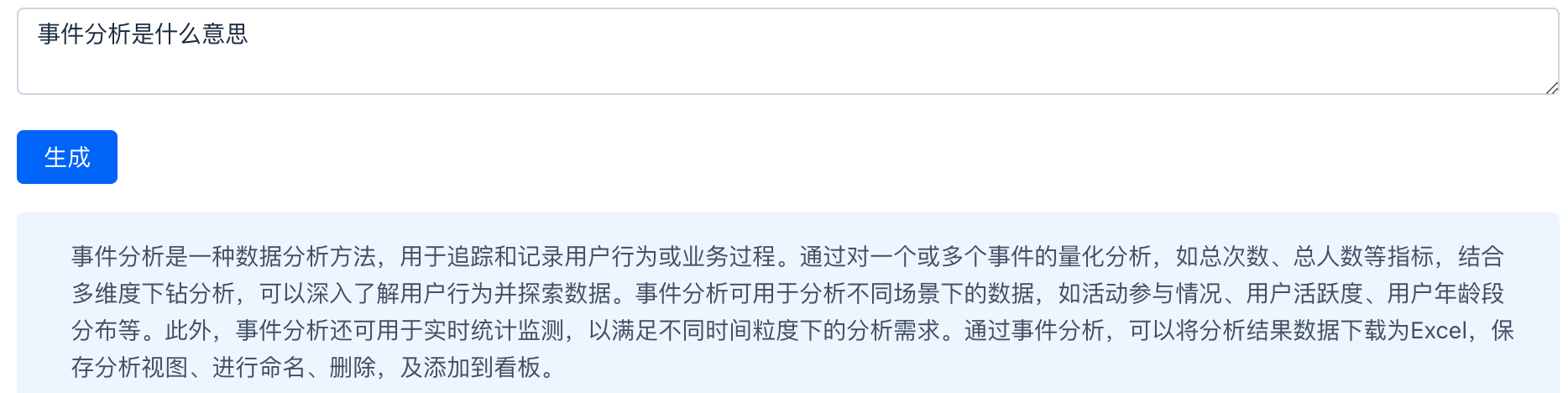
Метод улучшения поиска RAG может предоставить пользователям услуги запроса справочных документов в режиме реального времени, улучшить взаимодействие с пользователем и обеспечить быстрый ответ и точные ответы. Однако необходимо обеспечить точность и полноту содержимого справочных документов. все еще не соответствует контексту. Улучшите его надежность с помощью некоторых методов.
5. Инженерное решение
5.1 Использование koa для создания сервисов
В области интерфейсной разработки Koa — это популярная платформа Node.js для создания эффективных и надежных веб-приложений. Он предоставляет легкий, гибкий и выразительный API, позволяющий разработчикам легко создавать различные веб-сервисы.
import Koa from 'koa';
import Router from 'koa-router';
import bodyParser from 'koa-bodyparser';
const app: Koa = new Koa();
const router: Router = new Router();
app.use(bodyParser());
app.use(router.routes());
app.use(router.allowedMethods());
router.get('/', async (ctx: Koa.Context) => {
ctx.body = "666";
});
app.listen(80, () => {
console.log('Example app listening on port 80!');
});5.2 Производство зеркал
При изготовлении изображения необходимо сначала выбрать подходящее базовое изображение. Иногда требуется несколько попыток, чтобы выбрать правильное базовое изображение. При выборе версии Node.js необходимо учитывать требования библиотеки LangChain для Node.js. В некоторых образах вы можете напрямую установить версию Node.js 18 с помощью yum и убедиться в ее успешной работе.
Dockerfile делается следующим образом:
FROM xxxxxxxx:latest
LABEL maintainer="xxx"
WORKDIR /usr/local/services/xxxxxx
COPY package*.json ./
COPY tsconfig.json ./
COPY tsup.config.js ./
COPY turbo.json ./
COPY src ./src/
COPY langchain ./langchain/
RUN yum install -y nodejs
RUN npm install -g pnpm
RUN pnpm install
EXPOSE 80
CMD ["npm", "start"]5.3 Развертывание приложения
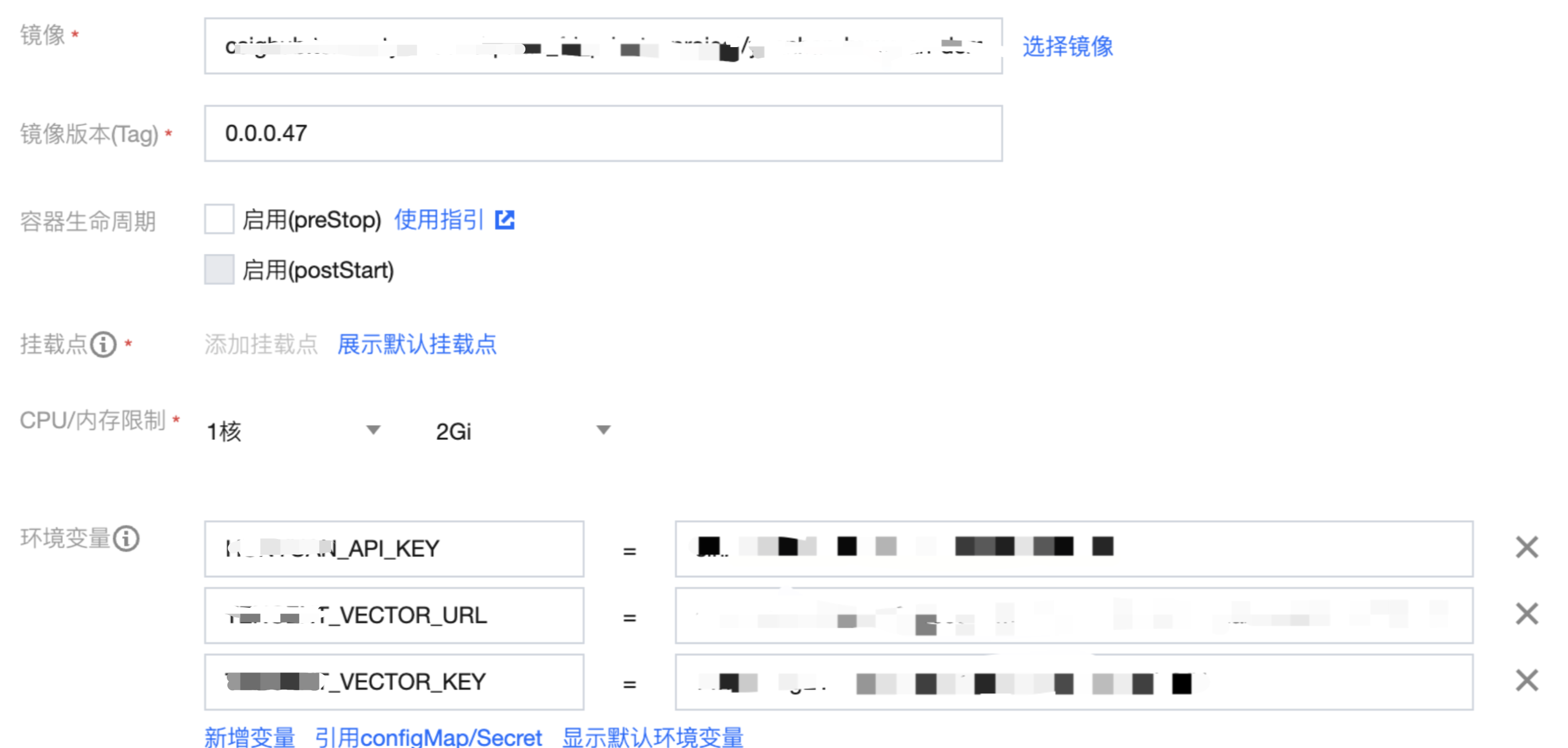
При развертывании приложения выберите образ, созданный указанным выше файлом docker, и установите соответствующие KEY и URL в переменных среды.



Учебное пособие по Jetpack Compose для начинающих, базовые элементы управления и макет

Код js веб-страницы, фон частицы, код спецэффектов

【новый! Суперподробное】Полное руководство по свойствам компонентов Figma.

🎉Обязательно к прочтению новичкам: полное руководство по написанию мини-программ WeChat с использованием программного обеспечения Cursor.

[Забавный проект Docker] VoceChat — еще одно приложение для мгновенного чата (IM)! Может быть встроен в любую веб-страницу!

Как реализовать переход по странице в HTML (html переходит на указанную страницу)

Как решить проблему зависания и низкой скорости при установке зависимостей с помощью npm. Существуют ли доступные источники npm, которые могут решить эту проблему?

Серия From Zero to Fun: Uni-App WeChat Payment Practice WeChat авторизует вход в систему и украшает страницу заказа, создает интерфейс заказа и инициирует запрос заказа

Серия uni-app: uni.navigateЧтобы передать скачок значения

Апплет WeChat настраивает верхнюю панель навигации и адаптируется к различным моделям.

JS-время конвертации

Обеспечьте бесперебойную работу ChromeDriver 125: советы по решению проблемы chromedriver.exe не найдены

Поле комментария, щелчок мышью, специальные эффекты, js-код

Объект массива перемещения объекта JS

Как открыть разрешение на позиционирование апплета WeChat_Как использовать WeChat для определения местонахождения друзей

Я даю вам два набора из 18 простых в использовании фонов холста Power BI, так что вам больше не придется возиться с цветами!

Получить текущее время в js_Как динамически отображать дату и время в js

Вам необходимо изучить сочетания клавиш vsCode для форматирования и организации кода, чтобы вам больше не приходилось настраивать формат вручную.

У ChatGPT большое обновление. Всего за 45 минут пресс-конференция показывает, что OpenAI сделал еще один шаг вперед.

Copilot облачной разработки — упрощение разработки

Микросборка xChatGPT с низким кодом, создание апплета чат-бота с искусственным интеллектом за пять шагов

CUDA Out of Memory: идеальное решение проблемы нехватки памяти CUDA

Анализ кластеризации отдельных ячеек, который должен освоить каждый&MarkerгенетическийВизуализация

vLLM: мощный инструмент для ускорения вывода ИИ

CodeGeeX: мощный инструмент генерации кода искусственного интеллекта, который можно использовать бесплатно в дополнение к второму пилоту.

Машинное обучение Реальный бой LightGBM + настройка параметров случайного поиска: точность 96,67%

Бесшовная интеграция, мгновенный интеллект [1]: платформа больших моделей Dify-LLM, интеграция без кодирования и встраивание в сторонние системы, более 42 тысяч звезд, чтобы стать свидетелями эксклюзивных интеллектуальных решений.

LM Studio для создания локальных больших моделей

Как определить количество слоев и нейронов скрытых слоев нейронной сети?
