Инструмент распределенного планирования задач — подробное объяснение структуры Xxl-job.
Привет всем, я Серая Обезьяна.
Недавно разработанные функции должны использовать запланированные задачи для резервного копирования базы данных и запланированного удаления файлов, поэтому мы исследовали несколько текущих основных платформ запланированных задач и после сравнения выбрали xxl-задание, о котором мы поговорим сегодня, поэтому в этой статье: В основном я делюсь с вами кратким обзором обучения xxl-job и рассказываю, как элегантно использовать xxl-job для реализации запланированных задач в распределенных проектах.
Сравнение существующих структур запланированных задач
Прежде чем использовать xxl-job, мы также сравнили некоторые существующие на рынке платформы запланированных задач, а именно:
Функция | quartz | Elastic-job | Xxl-job |
|---|---|---|---|
Шардинг задач | Не поддерживается | поддерживать | поддерживать |
Полная документация | Полный | Полный | Полный |
Управление интерфейсом | никто | иметь | иметь |
Сложность | Простой | Более сложный | Простой |
компания | OpenSymphony | Dangdang.com | Персональный (Дяньпин) |
недостаток | Нет интерфейса управления, Нет поддерживается Шардинг задач,Не подходит для распределенных сцен.,Необходимо сохранить бизнес-QuartzJobBean в базовой таблице данных.,Система довольно навязчивая. | Необходимо внедрить Zookeeper, что увеличивает сложность системы и высокие затраты на ее использование. | Путем получения блокировок базы данных обеспечивается уникальность выполняемых в кластере задач, но производительность оставляет желать лучшего. |
Почему стоит выбрать Xxl-job?
Учитывая, что мы являемся распределенным проектом и бизнес-обработка запланированных задач относительно независима, нам необходимо учитывать некоторые ключевые факторы при выборе инфраструктуры запланированных задач, и Xxl-job как раз отвечает этим потребностям:
- Визуальный интерфейс управления:Xxl-job Обеспечить интуитивно понятный и простой в использовании визуальный интерфейс управления, что позволяет нам легко управлять и контролировать запланированные задачи。
- Распределенное планирование задач:дляраспределенныйсистема,Xxl-job Обеспечивает мощное Распределенное планирование Возможности решения задач позволяют легко реализовать распределение и выполнение задач в кластере.
- Журнал выполнения задач:Xxl-job поддерживать Журнал выполнения запись и просмотр задач, что помогает оперативно обнаруживать и решать проблемы при выполнении задач.
- поддержка динамического добавления и удаления задач:Xxl-jobПозволяет динамически добавлять иудалитьЗадача,Никому не нужно останавливать всю службу.
- Меньше взлома кода:запланированные задачиотносительно независимый,кадр, у которого есть серьезные нарушения кода, определенно не будет рассматривать это.,И xxl-job полностью использует метод аннотаций.,Низкая стоимость использования,И совместимость лучше.
Подводя итог, мы наконец решили использовать xxl-job в качестве структуры запланированных задач.
Далее я познакомлю вас с основными принципами и практическим использованием xxl-job:
Введение в xxl-job
XXL-JOBэтолегкий Распределенное планирование задачплатформа。Особенностиплатформаизменять,Легко развернуть,Развивайтесь быстро、изучатьПростой、легкий、Легко расширить.
В основном комплектуются диспетчерским центром и исполнителем запланированные Выполнение задачи. Диспетчерский центр отвечает за единое планирование, а исполнитель – за получение расписания и его исполнение. и Сейчасxxl-jobУже открытый исходный код и подключен ко многимкомпанияонлайн-линия продуктов,Готов к использованию прямо из коробки. Итак, условно говоря, есть много информации, на которую вы можете сослаться.,Техническая реализация также относительно зрелая.,xxl-job предоставляет очень полную справочную документацию.,Заинтересованные друзья могут также прочитать следующее:
Платформа распределенного планирования задач XXL-JOB
Идеи оформления Xxl-работ:
Идея дизайна xxl-job может быть аналогична Nacos. Центр планирования xxl-job можно рассматривать как центр регистрации nacos, который регистрирует услуги в центре регистрации nacos, а xxl-job регистрирует запланированные задачи по одному. один. Идите в «Диспетчерский центр».
- Xxl-job абстрагирует поведение планирования на общедоступной платформе «центра планирования», но сама платформа не несет бизнес-логики. «Центр планирования» отвечает за инициирование запросов планирования.
- Задачи абстрагируются в разрозненные JobHandlers и передаются «исполнителю» для унифицированного управления. «Исполнитель» отвечает за получение запросов планирования и выполнение соответствующей бизнес-логики в JobHandler.
- Таким образом, части «расписание» и «задачи» могут быть отделены друг от друга, чтобы улучшить общую стабильность и масштабируемость системы;
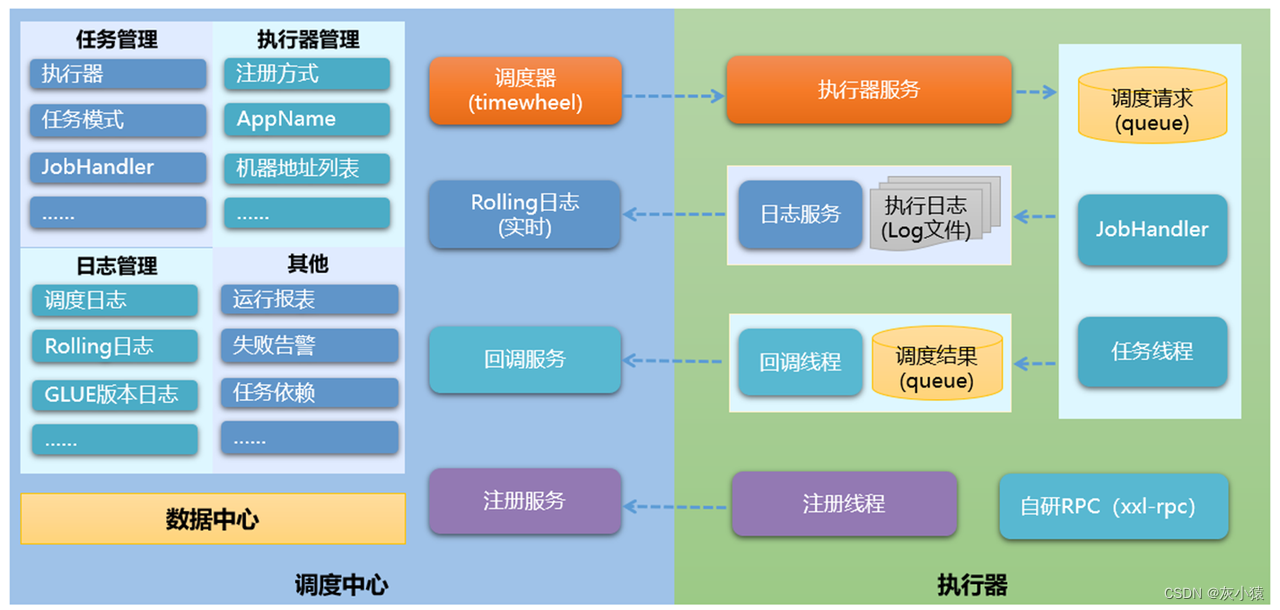
Основная структура Xxl-job
Модуль планирования (центр планирования)
Отвечает за управление информацией о планировании и выдачу запросов на планирование в соответствии с конфигурацией планирования. Он не отвечает за бизнес-код. Отделение системы планирования от задач повышает доступность и стабильность системы, а производительность системы планирования больше не ограничивается модулем задач;
поддержка Визуальное, простое и динамическое управление и информация по планированию,Включает создание задач,возобновлять,удалить,Сигнализация разработки и задач GLUE и т. д.,Все вышеперечисленные операции вступят в силу в режиме реального времени.,В то же время, поддержка отслеживает результаты планирования и выполняет бревно.,поддерживатьприводFailover。
Интерфейс диспетчерского центра:
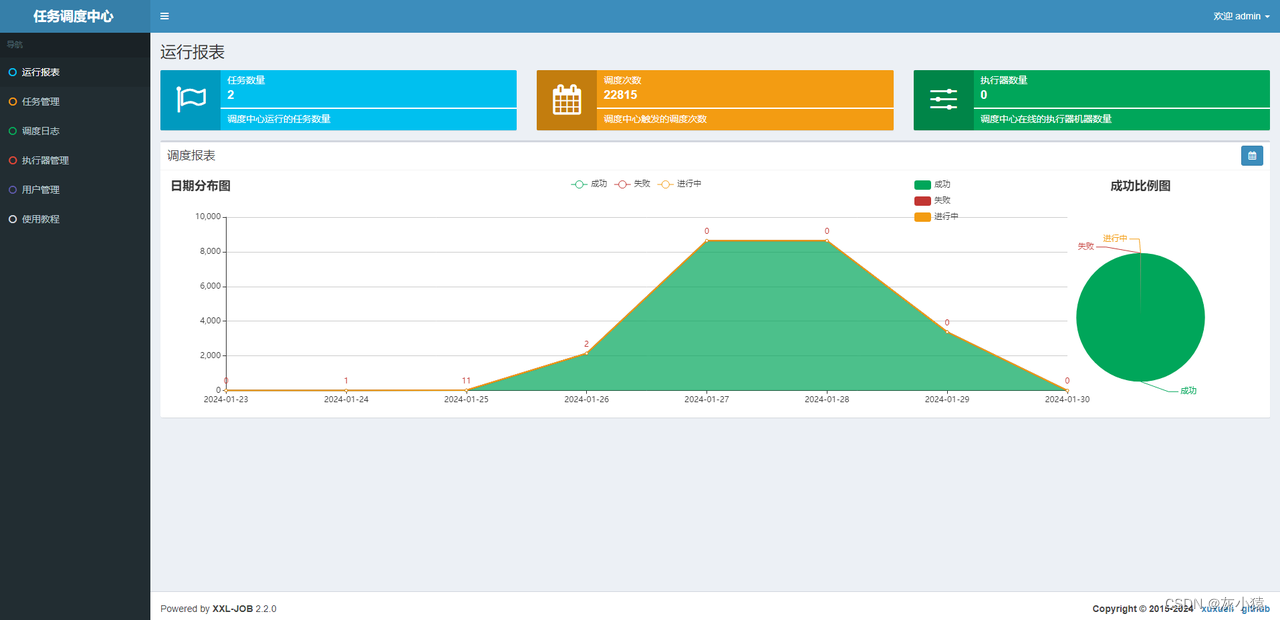
Исполнительный модуль (исполнитель)
Отвечает за получение отправки от «Центра планирования» и выполнение логики задач. Модуль задач фокусируется на таких операциях, как выполнение задач, что делает разработку и обслуживание более эффективными и действенными; он получает запросы на выполнение, запросы на завершение и бревно-запросы из «Центра планирования».
Ниже представлена общая схема архитектуры проекта Xxl-job:
Схема архитектуры Xxl-Job
xxl-job принцип работы и этапы использования
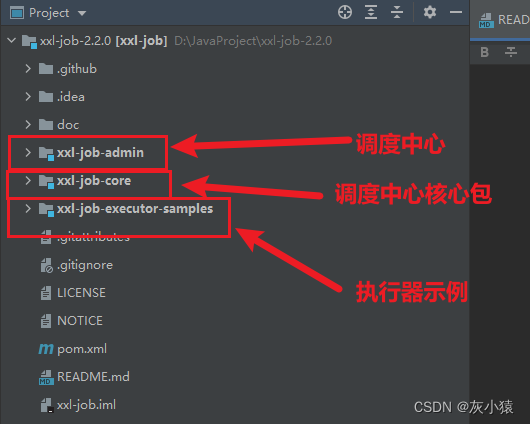
Шаг 1. Перенесите проект Xxl-job на локальный компьютер.
Сначала зайдите на gitee и загрузите исходный код проекта xxl-job. Рекомендуется выбрать более новую и стабильную версию. Я выбрал версию V2.2.0.
Адрес проекта:https://gitee.com/xuxueli0323/xxl-job
После импорта проекта в IDEA структура проекта выглядит следующим образом:
Шаг 2. Настройте диспетчерский центр
Сначала найдите файл сценария sql в исходном коде в папке doc, запустите файл сценария в локальном MySQL, а затем создайте базу данных диспетчерского центра. Эта база данных в основном используется для хранения и хранения некоторых данных, настроенных диспетчерским центром позже. статистика.
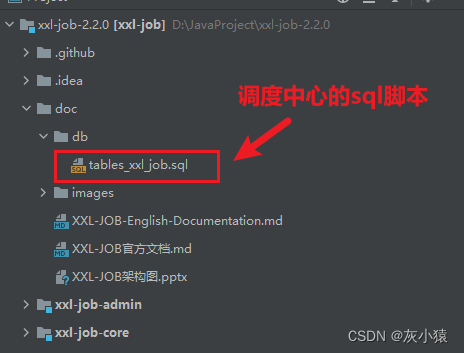
Функция таблицы данных в скрипте sql описывается следующим образом:
Введение в таблицу базы данных xxl-job
lxxl_job_group: таблица информации об исполнителе, содержащая информацию об исполнителе задач; lxxl_job_info: Таблица расширенной информации о планировании: Используется для сохранения расширенной информации о задачах планирования XXL-JOB, такой как группировка задач, имя задачи, адрес машины, исполнитель, входные параметры выполнения, электронные письма с сигналами тревоги и т. д.; lxxl_job_lock:Планирование таблица блокировки задач, в распределенной среде, чтобы гарантировать, что только один узел одновременно выполняет одну и ту же задачу, необходимо использовать распределенную блокировку для достижения взаимоисключающего выполнения задач ; lxxl_job_log: Таблица журнала планирования: Используется для сохранения исторической информации о планировании задач XXL-JOB, такой как результаты планирования, результаты выполнения, входные параметры планирования, планирование машин и исполнителей и т. д.; lxxl_job_log_report: Планирование краткого отчета: Пользовательское хранилище XXL-JOB Планирование Отчет о задачахбревно будет использоваться на странице функции отчета диспетчерского центра; lxxl_job_logglue: Задача GLUEбревно: используется для сохранения истории обновлений GLUE, используется для поддержки функции обратного отслеживания версии GLUE; lxxl_job_registry: реестр исполнителей, поддерживающий онлайн-информацию об адресах компьютеров исполнителей и диспетчерских центров; lxxl_job_user: таблица пользователей системы; |
|---|
- lxxl_job_group:приводинформацияповерхность,Хранить информацию об исполнителе задач;
- lxxl_job_info:Таблица информации о расширении планирования: Используется для сохранения расширенной информации о задачах планирования XXL-JOB, такой как группировка задач, имя задачи, адрес машины, исполнитель, входные параметры выполнения, электронные письма с сигналами тревоги и т. д.;
- lxxl_job_lock:Планирование таблица блокировки задач, в распределенной среде, чтобы гарантировать, что только один узел одновременно выполняет одну и ту же задачу, необходимо использовать распределенную блокировку для достижения взаимоисключающего выполнения задач ;
- lxxl_job_log:Планированиебревноповерхность: Используется для сохранения исторической информации о планировании задач XXL-JOB, такой как результаты планирования, результаты выполнения, входные параметры планирования, планирование машин и исполнителей и т. д.;
- lxxl_job_log_report:Планированиебревногазетаповерхность:Пользовательское хранилищеXXL-JOBПланирование Отчет о задачахбревно будет использоваться на странице функции отчета диспетчерского центра;
- lxxl_job_logglue:ЗадачаGLUEбревно:для сохраненияGLUEвозобновлятьистория,Отслеживание версий для поддержки функцииGLUE;
- lxxl_job_registry:приводзарегистрироватьсяповерхность,Поддерживать информацию об адресах машин онлайн-исполнителя и диспетчерского центра;
- lxxl_job_user:системапользовательповерхность;
Основная конфигурация конфигурационного центра
После создания базы данных необходимо настроить диспетчерский центр в файле конфигурации диспетчерского центра.
Основная конфигурация конфигурационного центраследующее:
### xxl-job, datasource Подключение к базе данных диспетчерского центра, подключение к локальной базе данных
spring.datasource.url=jdbc:mysql://127.0.0.1:3306/xxl_job?useUnicode=true&characterEncoding=UTF-8&autoReconnect=true&serverTimezone=Asia/Shanghai
spring.datasource.username=root
spring.datasource.password=root_pwd
spring.datasource.driver-class-name=com.mysql.cj.jdbc.Driver
### datasource-pool Конфигурация пула соединений с базой данных
spring.datasource.type=com.zaxxer.hikari.HikariDataSource
spring.datasource.hikari.minimum-idle=10
spring.datasource.hikari.maximum-pool-size=30
spring.datasource.hikari.auto-commit=true
spring.datasource.hikari.idle-timeout=30000
spring.datasource.hikari.pool-name=HikariCP
spring.datasource.hikari.max-lifetime=900000
spring.datasource.hikari.connection-timeout=10000
spring.datasource.hikari.connection-test-query=SELECT 1
### xxl-job, email Настройте сервер электронной почты для отправки электронных писем с сигналами тревоги при возникновении исключений выполнения или планирования.
spring.mail.host=smtp.qq.com
spring.mail.port=25
spring.mail.username=xxx@qq.com
spring.mail.password=xxx
spring.mail.properties.mail.smtp.auth=true
spring.mail.properties.mail.smtp.starttls.enable=true
spring.mail.properties.mail.smtp.starttls.required=true
spring.mail.properties.mail.smtp.socketFactory.class=javax.net.ssl.SSLSocketFactory
### xxl-job, access token Токен аутентификации. Этот токен должен соответствовать токену исполнителя и используется для взаимной аутентификации между диспетчерским центром и исполнителем.
xxl.job.accessToken=
### xxl-job, i18n (default is zh_CN, and you can choose "zh_CN", "zh_TC" and "en") Международная конфигурация
xxl.job.i18n=zh_CN
## xxl-job, triggerpool max size Конфигурация пула потоков
xxl.job.triggerpool.fast.max=200
xxl.job.triggerpool.slow.max=100
### xxl-job, log retention days Количество дней, в течение которых сохраняется файл бревно диспетчерского центра. Значение по умолчанию больше или равно 7 дням. Если оно меньше 7 или -1, по умолчанию не сохраняется бревно.
xxl.job.logretentiondays=30На этом этапе диспетчерский центр настроен. Запустите службу администрирования напрямую и получите доступ к адресу по умолчанию:
http://127.0.0.1:8080/xxl-job-admin,(Этот исполнитель адреса будет использовать,в качестве обратного адреса)
Вы можете войти на домашнюю страницу диспетчерского центра. Учетная запись для входа по умолчанию — «admin/123456». После входа в систему рабочий интерфейс будет выглядеть так, как показано ниже:
Шаг 3. Настройте исполнителя
# Порт сервера
server.port=8081
# no web
#spring.main.web-environment=false
# log config
logging.config=classpath:logback.xml
### xxl-job admin address list, such as "http://address" or "http://address01,http://address02"
### Адрес диспетчерского центра, используемый для отправки запланированных задача Зарегистрироваться по этому адресу
xxl.job.admin.addresses=http://127.0.0.1:8080/xxl-job-admin
### xxl-job, access token Токен аутентификации. Этот токен должен соответствовать токену исполнителя и используется для взаимной аутентификации между диспетчерским центром и исполнителем.
xxl.job.accessToken=
### xxl-job executor appname Название привода
xxl.job.executor.appname=xxl-job-executor-sample
### xxl-job executor registry-address: default use address to registry , otherwise use ip:port if address is null
### Плановые казни Адрес задачи, просто выберите и настройте этот адрес, а также следующие IP и порт.
xxl.job.executor.address=
### xxl-job executor server-info Плановые казни Адрес и номер порта задачи. Этот номер порта не может совпадать с номером порта службы-исполнителя, указанной выше.
xxl.job.executor.ip=127.0.0.1
xxl.job.executor.port=9999
### xxl-job executor log-path Операция бревно сохранить адрес
xxl.job.executor.logpath=/data/applogs/xxl-job/jobhandler
### xxl-job executor log-retention-days Количество дней для сохранения операции на стороне исполнителя. Оно вступит в силу, если оно больше или равно 3. Если оно меньше 3 или -1, оно не будет сохранено по умолчанию.
xxl.job.executor.logretentiondays=30Принцип реализации актуатора
Исполнитель на самом деле является встроенным сервером с портом по умолчанию 9999 (элемент конфигурации: xxl.job.executor.port).
в начале проекта,приводвстречапроходить“@JobHandler”идентифицироватьSpringв контейнере“Задачи по шаблону компонентов”,Он управляется с использованием атрибута value аннотации в качестве ключа.
Когда «исполнитель» получает запрос на планирование из «Центра планирования», если типом задачи является «Режим компонента», он будет соответствовать «задаче режима компонента» в контейнере Spring, а затем вызовет свой метод выполнения для выполнения задачи. логика.
Если типом задачи является «режим GLUE», будет загружен код GLUE, будет создан экземпляр Java-объекта и будет внедрен зависимый сервис Spring (примечание: сервис Spring, внедренный в код Glue, должен существовать в контейнере Spring проект «исполнитель»), а затем вызовите метод выполнения для выполнения логики задачи.
Шаг 4. Напишите код выполнения задачи
Существует два способа написания кода выполнения задачи.,Один из них — написание кода задачи в фоновом режиме с помощью шаблона Bean.,Другой — писать сценарии задач прямо в диспетчерском центре через режим GLUE.,Ниже мы представим использование каждого метода соответственно.
Режим выполнения задачи
Шаблон боба (форма класса)
Задачи по шаблону компонентов,поддерживать классовый подход к развитию,Каждая задача соответствует классу Java.
преимущество:
- Никаких ограничений по среде проекта.,Хорошая совместимость. Даже проект нирамка,Например, проекты, начатые непосредственно основным методом, также могут обеспечить поддержку.,
недостаток:
- Для каждой задачи требуется класс Java, что приводит к напрасной трате классов;
- Не Процесс автоматически сканирует задачи и внедряет их в контейнер исполнителя, требуется ручное внедрение.
Этот метод обычно подходит для проектов без рамок.,специфическийЭтапы разработки следующие:
1. Настройте соответствующую конфигурацию xxl.job в файле свойств исполнителя (возможно, модуля вашего проекта).
2. Класс, реализующий запланированные задачи, наследует «IJobHandler»: «com.xxl.job.core.handler.IJobHandler»;
3. Пропишите соответствующий код задачи в методе Execute().
package com.xuxueli.executor.sample.frameless.jobhandler;
import com.xxl.job.core.biz.model.ReturnT;
import com.xxl.job.core.handler.IJobHandler;
import com.xxl.job.core.log.XxlJobLogger;
import java.util.concurrent.TimeUnit;
/**
* Пример обработчика задач (шаблон Bean)
*
* Этапы разработки:
* 1. Наследовать «IJobHandler»: «com.xxl.job.core.handler.IJobHandler»;
* 2. Зарегистрируйтесь на заводе-изготовителе привода: в "JFinalCoreConfig.initXxlJobExecutor" При ручной регистрации значение ключа аннотации соответствует значению атрибута JobHandler новой задачи в диспетчерском центре.
* 3. Выполнить бревно: нужно пройти "XxlJobLogger.log" Печать исполнения бревно;
*
* @author xuxueli 2015-12-19 19:43:36
*/
public class DemoJobHandler extends IJobHandler {
@Override
public ReturnT<String> execute(String param) throws Exception {
XxlJobLogger.log("XXL-JOB, Hello World.");
for (int i = 0; i < 5; i++) {
XxlJobLogger.log("beat at:" + i);
TimeUnit.SECONDS.sleep(2);
}
return SUCCESS;
}
}4. Напишите файл конфигурации FrameLessXxlJobConfig, чтобы зарегистрировать класс запланированной задачи.
5. Зарегистрируйтесь в фабрике исполнителя: вручную зарегистрируйтесь в «JFinalCoreConfig.initXxlJobExecutor». Значение ключа аннотации соответствует значению атрибута JobHandler новой задачи в диспетчерском центре. 3. Журнал выполнения: вам необходимо распечатать журнал выполнения через «XxlJobLogger.log»;
package com.xuxueli.executor.sample.frameless.config;
import com.xuxueli.executor.sample.frameless.jobhandler.CommandJobHandler;
import com.xuxueli.executor.sample.frameless.jobhandler.DemoJobHandler;
import com.xuxueli.executor.sample.frameless.jobhandler.HttpJobHandler;
import com.xuxueli.executor.sample.frameless.jobhandler.ShardingJobHandler;
import com.xxl.job.core.executor.XxlJobExecutor;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import java.io.IOException;
import java.io.InputStreamReader;
import java.util.Properties;
/**
* @author xuxueli 2018-10-31 19:05:43
*/
public class FrameLessXxlJobConfig {
private static Logger logger = LoggerFactory.getLogger(FrameLessXxlJobConfig.class);
private static FrameLessXxlJobConfig instance = new FrameLessXxlJobConfig();
public static FrameLessXxlJobConfig getInstance() {
return instance;
}
private XxlJobExecutor xxlJobExecutor = null;
/**
* init
*/
public void initXxlJobExecutor() {
// registry jobhandler
XxlJobExecutor.registJobHandler("demoJobHandler", new DemoJobHandler());
XxlJobExecutor.registJobHandler("shardingJobHandler", new ShardingJobHandler());
XxlJobExecutor.registJobHandler("httpJobHandler", new HttpJobHandler());
XxlJobExecutor.registJobHandler("commandJobHandler", new CommandJobHandler());
// load executor prop
Properties xxlJobProp = loadProperties("xxl-job-executor.properties");
// init executor
xxlJobExecutor = new XxlJobExecutor();
xxlJobExecutor.setAdminAddresses(xxlJobProp.getProperty("xxl.job.admin.addresses"));
xxlJobExecutor.setAccessToken(xxlJobProp.getProperty("xxl.job.accessToken"));
xxlJobExecutor.setAppname(xxlJobProp.getProperty("xxl.job.executor.appname"));
xxlJobExecutor.setAddress(xxlJobProp.getProperty("xxl.job.executor.address"));
xxlJobExecutor.setIp(xxlJobProp.getProperty("xxl.job.executor.ip"));
xxlJobExecutor.setPort(Integer.valueOf(xxlJobProp.getProperty("xxl.job.executor.port")));
xxlJobExecutor.setLogPath(xxlJobProp.getProperty("xxl.job.executor.logpath"));
xxlJobExecutor.setLogRetentionDays(Integer.valueOf(xxlJobProp.getProperty("xxl.job.executor.logretentiondays")));
// start executor
try {
xxlJobExecutor.start();
} catch (Exception e) {
logger.error(e.getMessage(), e);
}
}
/**
* destory
*/
public void destoryXxlJobExecutor() {
if (xxlJobExecutor != null) {
xxlJobExecutor.destroy();
}
}
public static Properties loadProperties(String propertyFileName) {
InputStreamReader in = null;
try {
ClassLoader loder = Thread.currentThread().getContextClassLoader();
in = new InputStreamReader(loder.getResourceAsStream(propertyFileName), "UTF-8");;
if (in != null) {
Properties prop = new Properties();
prop.load(in);
return prop;
}
} catch (IOException e) {
logger.error("load {} error!", propertyFileName);
} finally {
if (in != null) {
try {
in.close();
} catch (IOException e) {
logger.error("close {} error!", propertyFileName);
}
}
}
return null;
}
}Шаблон объекта (форма метода)
Задачи по шаблону компонентов,поддерживать подход к разработке, основанный на методах,Каждой задаче соответствует метод.
преимущество:
- Для каждой задачи необходимо разработать только один метод.,и добавить”@XxlJob”Просто аннотируйте,Удобнее и быстрее. Поддержка автоматически сканирует задачи и внедряет их в контейнер исполнителя.
недостаток:
- Требуется среда контейнера Spring;
Написан в виде методов в режиме Bean запланированные. Метод задач более дружественен к проектам Spring и более удобен в использовании, поэтому обычно рекомендуется использовать этот метод для написания запланированных задачи。
Шаги реализации в целом аналогичны форме класса.,Но разница в том, что использование формы метода не требует каждогоЗадачаСоздать новыйиздобрый。специфическийизЭтапы разработки следующие:
1. Настройте соответствующую конфигурацию xxl.job в свойствах или файле yaml исполнителя (возможно, модуль вашего проекта). Конкретная конфигурация была упомянута в конфигурации исполнителя выше.
2. Весной В экземпляре Bean при разработке метода Job требование к формату метода следующее: "public ReturnT<String> execute(String param)" 3. Добавьте аннотации к методу Job. "@XxlJob(value="имя пользовательского обработчика задания", init = «Метод инициализации JobHandler», destroy = «Метод уничтожения JobHandler»)», значение значения аннотации соответствует значению атрибута JobHandler новой задачи в диспетчерском центре.
package com.xxl.job.executor.service.jobhandler;
import com.xxl.job.core.biz.model.ReturnT;
import com.xxl.job.core.handler.IJobHandler;
import com.xxl.job.core.handler.annotation.XxlJob;
import com.xxl.job.core.log.XxlJobLogger;
import com.xxl.job.core.util.ShardingUtil;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.stereotype.Component;
import java.io.BufferedInputStream;
import java.io.BufferedReader;
import java.io.DataOutputStream;
import java.io.InputStreamReader;
import java.net.HttpURLConnection;
import java.net.URL;
import java.util.Arrays;
import java.util.concurrent.TimeUnit;
/**
* Пример разработки XxlJob (режим Bean)
*
* Этапы разработки:
* 1. Весной В экземпляре Bean при разработке метода Job требование к формату метода следующее: "public ReturnT<String> execute(String param)"
* 2. Добавьте аннотации к методу Job. "@XxlJob(value="имя пользовательского обработчика задания", init = «Метод инициализации JobHandler», destroy = «Метод уничтожения JobHandler»)», значение значения аннотации соответствует значению атрибута JobHandler новой задачи в диспетчерском центре.
* 3. Выполнить бревно: нужно пройти "XxlJobLogger.log" Печать исполнения бревно;
*
* @author xuxueli 2019-12-11 21:52:51
*/
@Component
public class SampleXxlJob {
private static Logger logger = LoggerFactory.getLogger(SampleXxlJob.class);
/**
* 1. Пример простой задачи (режим Bean)
*/
@XxlJob("demoJobHandler")
public ReturnT<String> demoJobHandler(String param) throws Exception {
XxlJobLogger.log("XXL-JOB, Hello World.");
for (int i = 0; i < 5; i++) {
XxlJobLogger.log("beat at:" + i);
TimeUnit.SECONDS.sleep(2);
}
return ReturnT.SUCCESS;
}
/**
* 2. Шард-трансляции задач
*/
@XxlJob("shardingJobHandler")
public ReturnT<String> shardingJobHandler(String param) throws Exception {
// Параметры шардинга
ShardingUtil.ShardingVO shardingVO = ShardingUtil.getShardingVo();
XxlJobLogger.log("Параметры шардинга: порядковый номер текущего фрагмента = {}, Общее количество осколков = {}", shardingVO.getIndex(), shardingVO.getTotal());
// бизнес-логика
for (int i = 0; i < shardingVO.getTotal(); i++) {
if (i == shardingVO.getIndex()) {
XxlJobLogger.log(" {} кусок, Фрагмент попадания начинает обработку", i);
} else {
XxlJobLogger.log(" {} кусок, пренебрегать", i);
}
}
return ReturnT.SUCCESS;
}
/**
* 3. Задачи командной строки
*/
@XxlJob("commandJobHandler")
public ReturnT<String> commandJobHandler(String param) throws Exception {
String command = param;
int exitValue = -1;
BufferedReader bufferedReader = null;
try {
// command process
Process process = Runtime.getRuntime().exec(command);
BufferedInputStream bufferedInputStream = new BufferedInputStream(process.getInputStream());
bufferedReader = new BufferedReader(new InputStreamReader(bufferedInputStream));
// command log
String line;
while ((line = bufferedReader.readLine()) != null) {
XxlJobLogger.log(line);
}
// command exit
process.waitFor();
exitValue = process.exitValue();
} catch (Exception e) {
XxlJobLogger.log(e);
} finally {
if (bufferedReader != null) {
bufferedReader.close();
}
}
if (exitValue == 0) {
return IJobHandler.SUCCESS;
} else {
return new ReturnT<String>(IJobHandler.FAIL.getCode(), "command exit value("+exitValue+") is failed");
}
}
/**
* 4. Кроссплатформенные HTTP-задачи
* Пример параметра:
* "url: http://www.baidu.com\n" +
* "method: get\n" +
* "data: content\n";
*/
@XxlJob("httpJobHandler")
public ReturnT<String> httpJobHandler(String param) throws Exception {
// param parse
if (param==null || param.trim().length()==0) {
XxlJobLogger.log("param["+ param +"] invalid.");
return ReturnT.FAIL;
}
String[] httpParams = param.split("\n");
String url = null;
String method = null;
String data = null;
for (String httpParam: httpParams) {
if (httpParam.startsWith("url:")) {
url = httpParam.substring(httpParam.indexOf("url:") + 4).trim();
}
if (httpParam.startsWith("method:")) {
method = httpParam.substring(httpParam.indexOf("method:") + 7).trim().toUpperCase();
}
if (httpParam.startsWith("data:")) {
data = httpParam.substring(httpParam.indexOf("data:") + 5).trim();
}
}
// param valid
if (url==null || url.trim().length()==0) {
XxlJobLogger.log("url["+ url +"] invalid.");
return ReturnT.FAIL;
}
if (method==null || !Arrays.asList("GET", "POST").contains(method)) {
XxlJobLogger.log("method["+ method +"] invalid.");
return ReturnT.FAIL;
}
// request
HttpURLConnection connection = null;
BufferedReader bufferedReader = null;
try {
// connection
URL realUrl = new URL(url);
connection = (HttpURLConnection) realUrl.openConnection();
// connection setting
connection.setRequestMethod(method);
connection.setDoOutput(true);
connection.setDoInput(true);
connection.setUseCaches(false);
connection.setReadTimeout(5 * 1000);
connection.setConnectTimeout(3 * 1000);
connection.setRequestProperty("connection", "Keep-Alive");
connection.setRequestProperty("Content-Type", "application/json;charset=UTF-8");
connection.setRequestProperty("Accept-Charset", "application/json;charset=UTF-8");
// do connection
connection.connect();
// data
if (data!=null && data.trim().length()>0) {
DataOutputStream dataOutputStream = new DataOutputStream(connection.getOutputStream());
dataOutputStream.write(data.getBytes("UTF-8"));
dataOutputStream.flush();
dataOutputStream.close();
}
// valid StatusCode
int statusCode = connection.getResponseCode();
if (statusCode != 200) {
throw new RuntimeException("Http Request StatusCode(" + statusCode + ") Invalid.");
}
// result
bufferedReader = new BufferedReader(new InputStreamReader(connection.getInputStream(), "UTF-8"));
StringBuilder result = new StringBuilder();
String line;
while ((line = bufferedReader.readLine()) != null) {
result.append(line);
}
String responseMsg = result.toString();
XxlJobLogger.log(responseMsg);
return ReturnT.SUCCESS;
} catch (Exception e) {
XxlJobLogger.log(e);
return ReturnT.FAIL;
} finally {
try {
if (bufferedReader != null) {
bufferedReader.close();
}
if (connection != null) {
connection.disconnect();
}
} catch (Exception e2) {
XxlJobLogger.log(e2);
}
}
}
/**
* 5. Пример задачи жизненного цикла: при инициализации и уничтожении задач поддержка настраивает соответствующую логику;
*/
@XxlJob(value = "demoJobHandler2", init = "init", destroy = "destroy")
public ReturnT<String> demoJobHandler2(String param) throws Exception {
XxlJobLogger.log("XXL-JOB, Hello World.");
return ReturnT.SUCCESS;
}
public void init(){
logger.info("init");
}
public void destroy(){
logger.info("destory");
}
}4. Журнал выполнения: вам необходимо распечатать журнал выполнения через «XxlJobLogger.log»;
5. Запишите файл конфигурации XxlJobConfig, чтобы прочитать конфигурацию XXL-JOB, настроенную в файле конфигурации.
package com.xxl.job.executor.core.config;
import com.xxl.job.core.executor.impl.XxlJobSpringExecutor;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
/**
* xxl-job config
*
* @author xuxueli 2017-04-28
*/
@Configuration
public class XxlJobConfig {
private Logger logger = LoggerFactory.getLogger(XxlJobConfig.class);
@Value("${xxl.job.admin.addresses}")
private String adminAddresses;
@Value("${xxl.job.accessToken}")
private String accessToken;
@Value("${xxl.job.executor.appname}")
private String appname;
@Value("${xxl.job.executor.address}")
private String address;
@Value("${xxl.job.executor.ip}")
private String ip;
@Value("${xxl.job.executor.port}")
private int port;
@Value("${xxl.job.executor.logpath}")
private String logPath;
@Value("${xxl.job.executor.logretentiondays}")
private int logRetentionDays;
@Bean
public XxlJobSpringExecutor xxlJobExecutor() {
logger.info(">>>>>>>>>>> xxl-job config init.");
XxlJobSpringExecutor xxlJobSpringExecutor = new XxlJobSpringExecutor();
xxlJobSpringExecutor.setAdminAddresses(adminAddresses);
xxlJobSpringExecutor.setAppname(appname);
xxlJobSpringExecutor.setAddress(address);
xxlJobSpringExecutor.setIp(ip);
xxlJobSpringExecutor.setPort(port);
xxlJobSpringExecutor.setAccessToken(accessToken);
xxlJobSpringExecutor.setLogPath(logPath);
xxlJobSpringExecutor.setLogRetentionDays(logRetentionDays);
return xxlJobSpringExecutor;
}
/**
* В таких ситуациях, как несколько сетевых карт и развертывание в контейнерах, вы можете использовать "spring-cloud-commons" предоставил "InetUtils" Компоненты можно гибко настроить для регистрации IP;
*
* 1. Вводим зависимости:
* <dependency>
* <groupId>org.springframework.cloud</groupId>
* <artifactId>spring-cloud-commons</artifactId>
* <version>${version}</version>
* </dependency>
*
* 2. Файл конфигурации или переменные запуска контейнера.
* spring.cloud.inetutils.preferred-networks: 'xxx.xxx.xxx.'
*
* 3. Получите IP
* String ip_ = inetUtils.findFirstNonLoopbackHostInfo().getIpAddress();
*/
}Ссылаясь на приведенный выше метод, вы можете писать запланированные задачи в коде, используя режим Bean.
Так каков же конкретный принцип работы запланированной задачи, реализованной таким образом?
Принцип реализации
Каждая Задача по шаблону компонентовВсеэтоSpringизBeanэкземпляр класса,оно поддерживается в“привод”проектизSpringв контейнере。Задачадобрый需要加“@JobHandler(value=”имя”)”аннотация,потому что“привод”встреча根据该аннотацияидентифицироватьSpringв контейнереизЗадача。 Класс задачи должен наследовать унифицированный интерфейс «IJobHandler», а логика задачи разрабатывается в методе выполнения, поскольку, когда «исполнитель» получает запрос на планирование из диспетчерского центра, он вызывает метод выполнения «IJobHandler», чтобы выполнить логику задачи. Как уже говорилось выше, помимо написания запланированных в проекте Помимо кода задач, есть еще способ написать запланированные прямо в диспетчерском центре. метод сценария задачи, преимущество этого метода в том, что даже если ваш проект онлайн, вы все равно можете добавлять или удалять запланированные задача,никтонужно приостановить проект.
Режим КЛЕЙ (Java)
Задания режима КЛЕЙ,Задачи хранятся в диспетчерском центре в виде исходного кода.,поддерживатьпроходитьWeb IDE обновляется онлайн, компилируется и вступает в силу в реальном времени, поэтому нет необходимости указывать JobHandler.
Этапы разработки:
1. Создайте новую задачу планирования в диспетчерском центре.
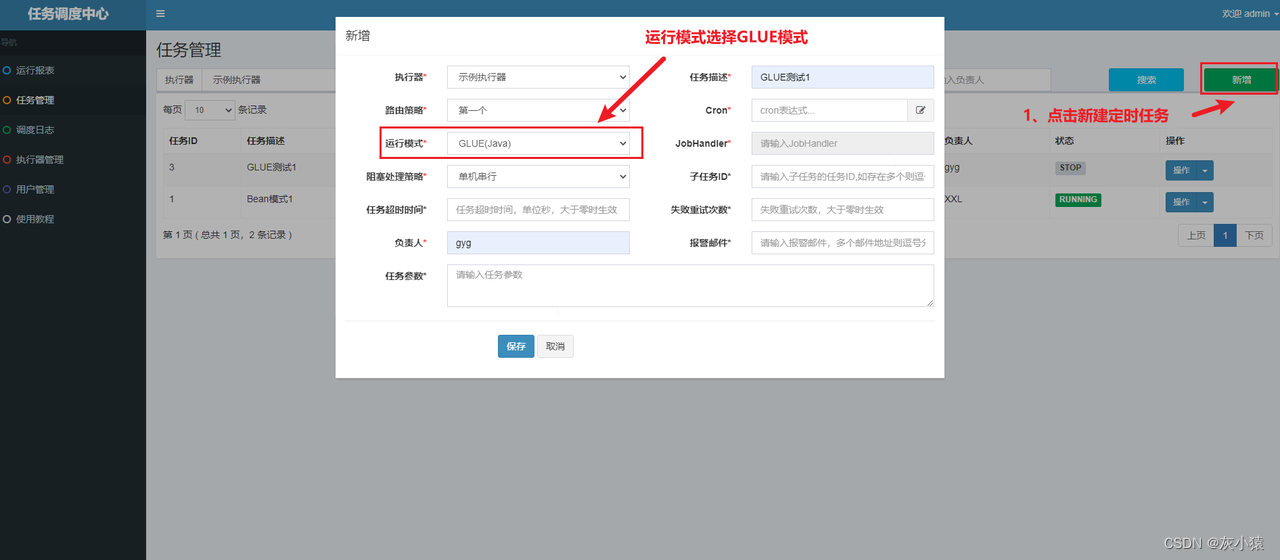
2. Используйте КЛЕЙ IDE, разрабатывайте код задачи прямо в диспетчерском центре (поддержка бэктрекинга версии кода).
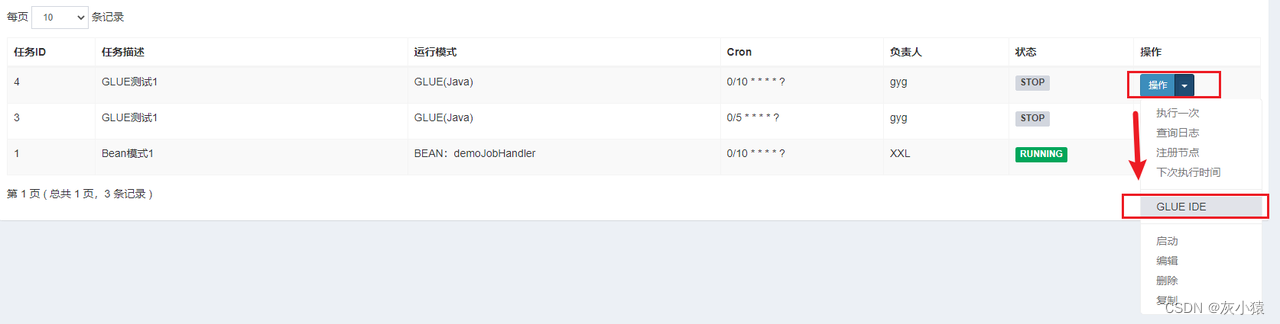
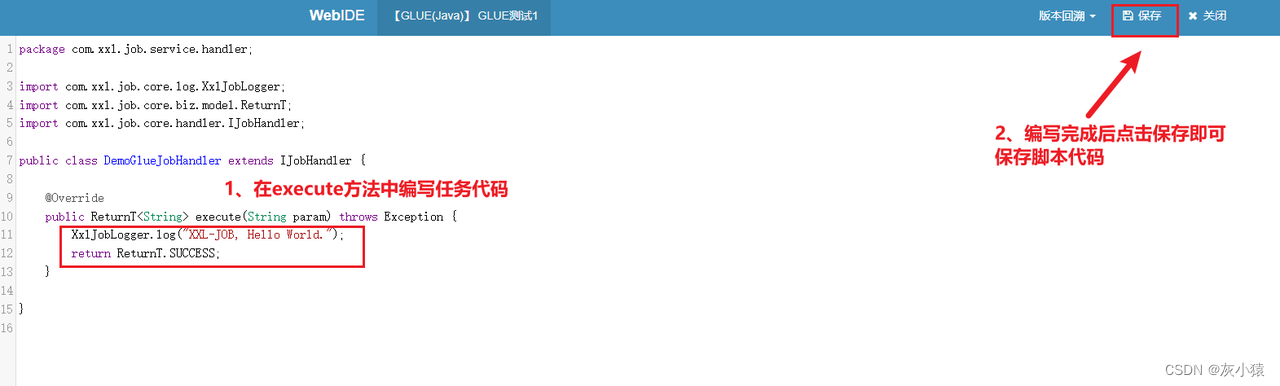
3. Включите выполнение, чтобы запустить задачу.
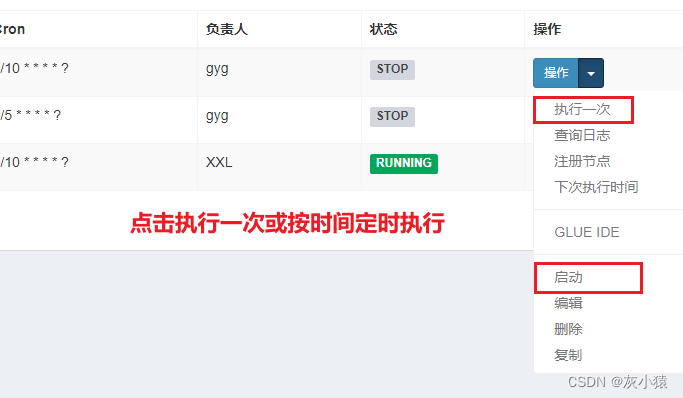
Режим GLUE (Shell, Python, PHP, NodeJS, Powershell)
Шаги выполнения сценариев на других языках задач режима GLUE такие же, как и для сценариев Java, поэтому я не буду здесь вдаваться в подробности.
Этапы разработки:
- Создайте новую задачу планирования в диспетчерском центре.
- Разработайте соответствующие сценарии прямо в диспетчерском центре.
- Начать выполнение
Тогда этот метод написания скриптов прямо в диспетчерском центре используется для выполнения запланированных метод задачи, конкретный принцип Что такое реализация?
Принцип реализации
Исходный код задачи-скрипта размещается в диспетчерском центре, а логика сценария запускается в исполнителе. Когда задача сценария запускается, исполнитель загружает исходный код сценария для создания файла сценария на компьютере исполнителя, а затем вызывает сценарий через код Java и записывает журнал вывода сценария в файл журнала задачи в режиме реального времени; что его можно просмотреть в режиме реального времени в диспетчерском центре. Мониторинг выполнения скриптов;
Шаг 5. Зарегистрируйте задачу в диспетчерском центре.
Операция регистрации задач в диспетчерском центре предназначена в основном для ситуации, когда для записи и выполнения задач используется режим Bean.,Потому что в этом случае, когда нет прописанного задания в диспетчерский центр,,Диспетчерский центр не знает, какие задачи использовать в качестве задач диспетчеризации.,
Причина, по которой режим GLUE не требует этого шага, заключается в том, что режим GLUE — это процесс регистрации задачи в диспетчерском центре при создании новой задачи.
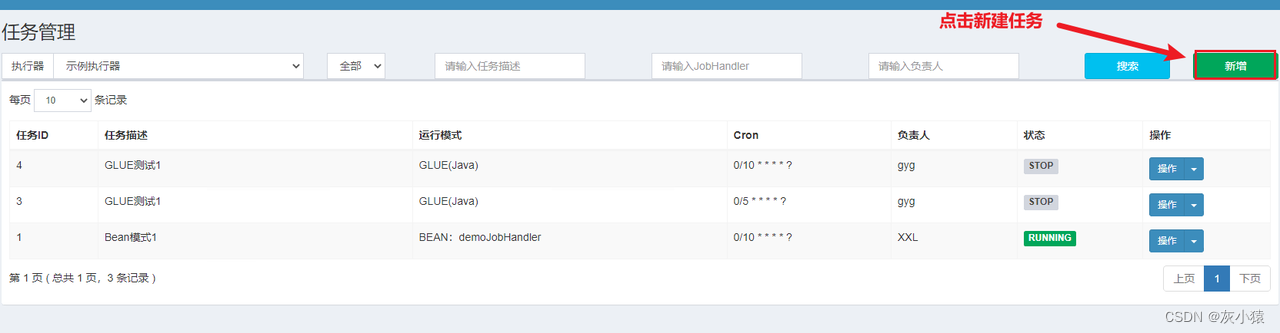
В качестве примера возьмем задачу регистрации в режиме Bean:
1. Сначала нажмите «Создать» в правой части интерфейса, чтобы создать новую задачу.
2. Во всплывающем окне новой задачи выберите режим BEAN. В это время соответствующее поле ввода JobHandler справа включено. В это время введите здесь уникальный идентификатор задачи, которую вы хотите зарегистрировать. вы определяете в фоновом коде имя, которое будет использоваться для этой задачи.
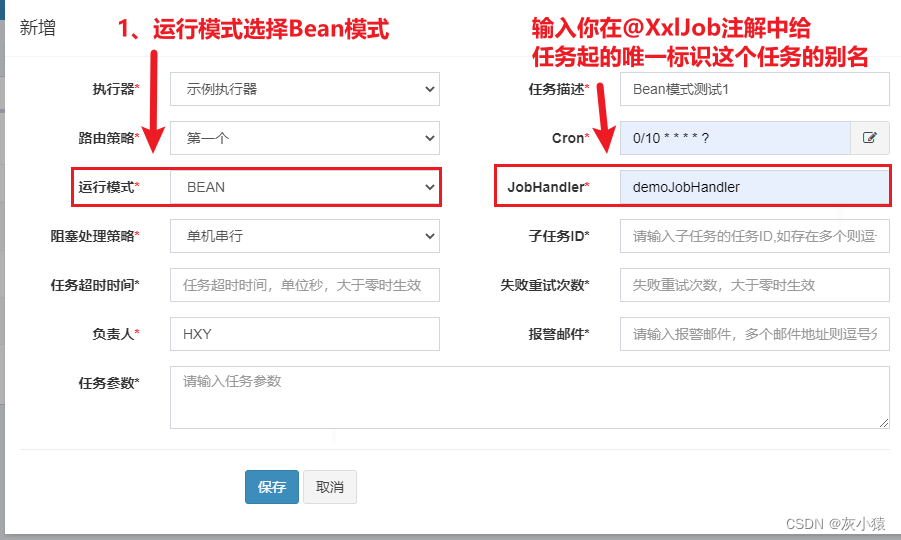
3. После заполнения остальных обязательных полей задача будет успешно зарегистрирована.
Далее следует использовать диспетчерский центр для выполнения задач,
Шаг 6: Диспетчерский центр выполняет задачу
никто Относительно того, является ли это новой (зарегистрированной) задачей в режиме BEAN или в режиме GLUE,После завершения нового творения,Задачи не будут выполняться сразу,Поэтому нам нужно вручную запускать задачу, когда мы хотим ее выполнить.,
Операция по запуску задачи следующая:
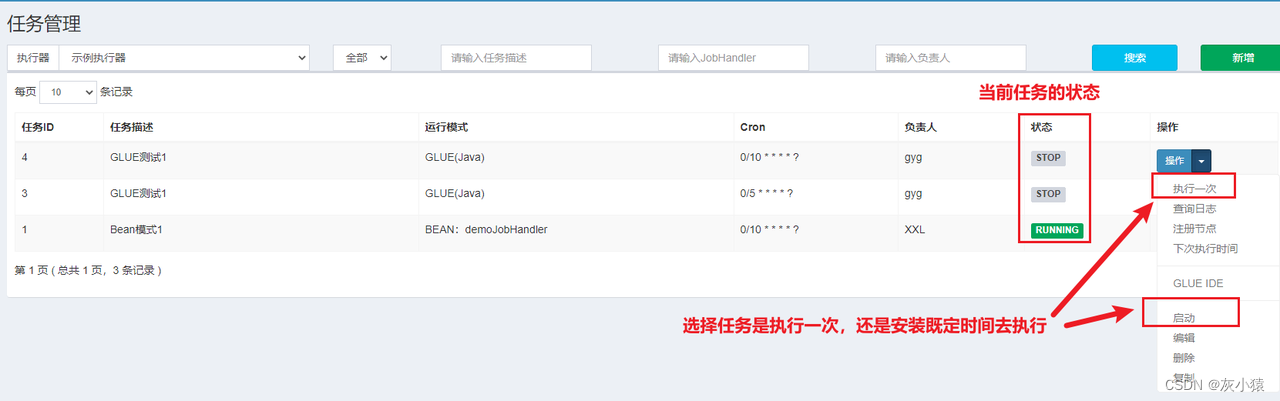
Просмотр журналов планирования задач
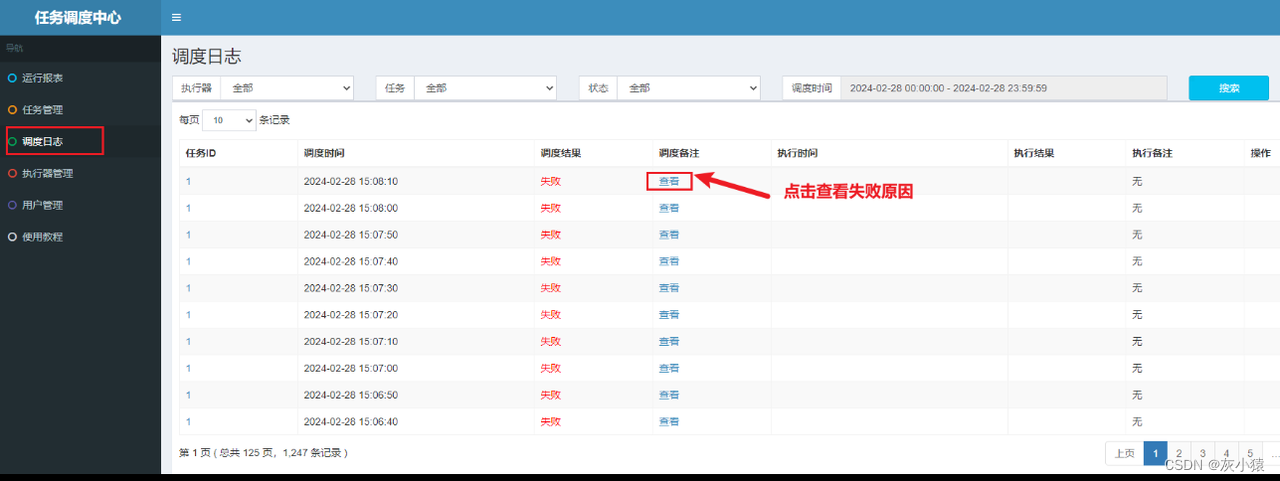
Если после выполнения задачи вы хотите проверить успешность или неудачу выполнения задачи, вы можете перейти в модуль «Журнал планирования», чтобы просмотреть его, нажать «Просмотр» в столбце «Примечания к планированию», а также просмотреть конкретные причины. за провал.
Выше представлен процесс выполнения всей задачи планирования. Подведем итог вышеописанному процессу:
Полный процесс планирования задач
- Сначала диспетчерский центр передает информацию о задании исполнителю. Информация о задаче здесь включает идентификатор задачи, параметры задачи и т. д. После получения задачи исполнитель сохранит информацию о задаче в собственной очереди задач, ожидая выполнения.
- Исполнитель непрерывно берет задачи из очереди задач и выполняет их. В процессе выполнения исполнитель будет отправлять в диспетчерский центр статус выполнения и результаты выполнения задачи. Статус задачи включает в себя «выполнение», «выполнение успешное», «выполнение не удалось» и т. д.
- После получения статуса задачи и результатов выполнения, отправленных исполнителем, диспетчерский центр обновит собственный статус задачи. Если выполнение задачи прошло успешно, диспетчерский центр пометит задачу как «выполненную», в противном случае — как «сбой выполнения».
- Во время выполнения задачи исполнитель будет регулярно отправлять пакеты Heartbeat в диспетчерский центр, чтобы гарантировать нормальное соединение между исполнителем и диспетчерским центром.
Сценарии использования Xxl-заданий
Ниже приводится список сценариев, в которых Xxl-job может использоваться в реальных проектах в качестве структуры задач для выполнения запланированных задач, и все это для того, чтобы сделать некоммерческие операции более эффективными. Подробности следующие:
- Бревно обработка: Когда система генерирует большое количество бревно файлов, создайте запланированные через XXL-JOB. задачи, регулярное сжатие, архивирование или загрузка файлов в облачное хранилище и другие операции.
- Выполнение сценариев. Даже если служба подключена к сети, сценарии в различных форматах все равно выполняются.
- Регулярное резервное копирование данных
- Регулярно удаляйте старые файлы
- Регулярно отправляйте электронные письма и т. д.
Выше приведены все руководства и общие принципы использования задачи распределенного планирования XXL-JOB. Если у вас есть вопросы, вы можете оставить сообщение или отправить мне личное сообщение, чтобы учиться вместе.
Я Маленькая Серая Обезьянка, увидимся в следующий раз!


RasaGpt — платформа чат-ботов на основе Rasa и LLM.

Nomic Embed: воспроизводимая модель внедрения SOTA с открытым исходным кодом.

Улучшение YOLOv8: EMA основана на эффективном многомасштабном внимании, основанном на межпространственном обучении, и эффект лучше, чем у ECA, CBAM и CA. Малые цели имеют очевидные преимущества | ICASSP2023

Урок 1 серии Libtorch: Тензорная библиотека Silky C++

Руководство по локальному развертыванию Stable Diffusion: подробные шаги и анализ распространенных проблем

Полностью автоматический инструмент для работы с видео в один клик: VideoLingo

Улучшения оптимизации RT-DETR: облегченные улучшения магистрали | Support Paddle облегченный rtdetr-r18, rtdetr-r34, rtdetr-r50, rtdet

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | Деформируемое внимание с большим ядром (D-LKA Attention), большое ядро свертки улучшает механизм внимания восприимчивых полей с различными функциями

Создано Datawhale: выпущено «Руководство по тонкой настройке развертывания большой модели GLM-4»!

7B превышает десятки миллиардов, aiXcoder-7B с открытым исходным кодом Пекинского университета — это самая мощная модель большого кода, лучший выбор для корпоративного развертывания.

Используйте модель Huggingface, чтобы заменить интерфейс внедрения OpenAI в китайской среде.

Оригинальные улучшения YOLOv8: несколько новых улучшений | Сохранение исходной информации — алгоритм отделяемой по глубине свертки (MDSConv) |

Второй пилот облачной разработки | Быстро поиграйте со средствами разработки на базе искусственного интеллекта

Бесшовная интеграция, мгновенный интеллект [1]: платформа больших моделей Dify-LLM, интеграция с нулевым кодированием и встраивание в сторонние системы, более 42 тысяч звезд, чтобы стать свидетелями эксклюзивных интеллектуальных решений.

Решенная Ошибка | Загрузка PyTorch медленная: TimeoutError: [Errno 110] При загрузке факела истекло время ожидания — Cat Head Tiger

Brother OCR, библиотека с открытым исходным кодом для Python, которая распознает коды проверки.
Новейшее подробное руководство по загрузке и использованию последней демонстрационной версии набора данных COCO.

Выпущен отчет о крупной модели финансовой отрасли за 2023 год | Полный текст включен в загрузку |

Обычные компьютеры также могут работать с большими моделями, и вы можете получить личного помощника с искусственным интеллектом за три шага | Руководство для начинающих по локальному развертыванию LLaMA-3

Одной статьи достаточно для анализа фактора транскрипции SCENIC на Python (4)

Бросая вызов ограничениям производительности небольших видеокарт, он научит вас запускать большие модели глубокого обучения с ограниченными ресурсами, а также предоставит полное руководство по оценке и эффективному использованию памяти графического процессора!

Команда Fudan NLP опубликовала 80-страничный обзор крупномасштабных модельных агентов, в котором в одной статье представлен обзор текущего состояния и будущего агентов ИИ.

[Эксклюзив] Вы должны знать о новой функции JetBrains 2024.1 «Полнострочное завершение кода», чтобы решить вашу путаницу!

Краткое изложение базовых знаний о регистрации изображений 1.0

Новейшее подробное руководство по установке и использованию библиотеки cv2 (OpenCV, opencv-python) в Python.

Легко создайте локальную базу знаний для крупных моделей на основе Ollama+AnythingLLM.

[Решено] ошибка установки conda. Среда решения: не удалось выполнить первоначальное зависание решения. Повторная попытка с помощью файла (графическое руководство).

Одна статья поможет вам понять RAG (Retrival Enhanced Generation) | Введение в концепцию и теорию + практику работы с кодом (включая исходный код).

Эволюция архитектуры шлюза облачной разработки
