—Инструмент искусственного интеллекта, который может конвертировать различные типы файлов в формат Markdown.—Маркер.
Предисловие
Marker способен PDF、EPUB и MOBI файл конвертирован в Markdown Формат. это лучше, чем nougat быстрый 10 раз, более точен в большинстве документов и имеет меньший риск ошибки.
1. Поддержка различных PDF Документация (оптимизирована для использования в книгах и научных статьях)
2. Удалите верхние, нижние колонтитулы и другие отвлекающие элементы.
3. Преобразуйте большинство уравнений в LaTeX.
4. Форматирование блоков кода и таблиц
5. Поддерживает несколько языков (хотя большинство тестов проводится на английском языке)
6. Может работать на графическом процессоре, процессоре или MPS.
Как это работает
Marker Это поток обработки, состоящий из моделей глубокого обучения:
1. Извлечение текста, распознавание текста при необходимости (эвристика, тессеракт) 2. Определение макета страницы (разделитель макета, детектор столбцов) 3. Очистка и форматирование каждого блока (эвристика, нуга) 4. Объединение блоков и постобработка всего текста (эвристика) , pdf_постпроцессор)
Использование авторегрессионных проходов вперед для генерации текста является медленным и склонным к галлюцинациям/повторениям. На бумаге с нугой мы видим, что 1,5% страниц в тестовом наборе дублируются, но эта частота увеличивается для недоменных (не arXiv) документов. По моим личным тестам, дублирование происходило более чем в 5% случаев на страницах, не принадлежащих домену (не arXiv).
Nougatэто потрясающеиз Модель,Но мне нужно более быстрое и универсальное решение. Маркер изскорость это nougat из 10 раз, и потому что оно проходит только LLM Прямой проход обрабатывает блоки уравнений, поэтому риск галлюцинаций снижается.
Пример
тип | Marker | Nougat | |
|---|---|---|---|
Think Python | учебник | Проверять | Проверять |
Think OS | учебник | Проверять | Проверять |
Switch Transformers | документы arXiv | Проверять | Проверять |
Многоколоночный CNN | документы arXiv | Проверять | Проверять |
производительность
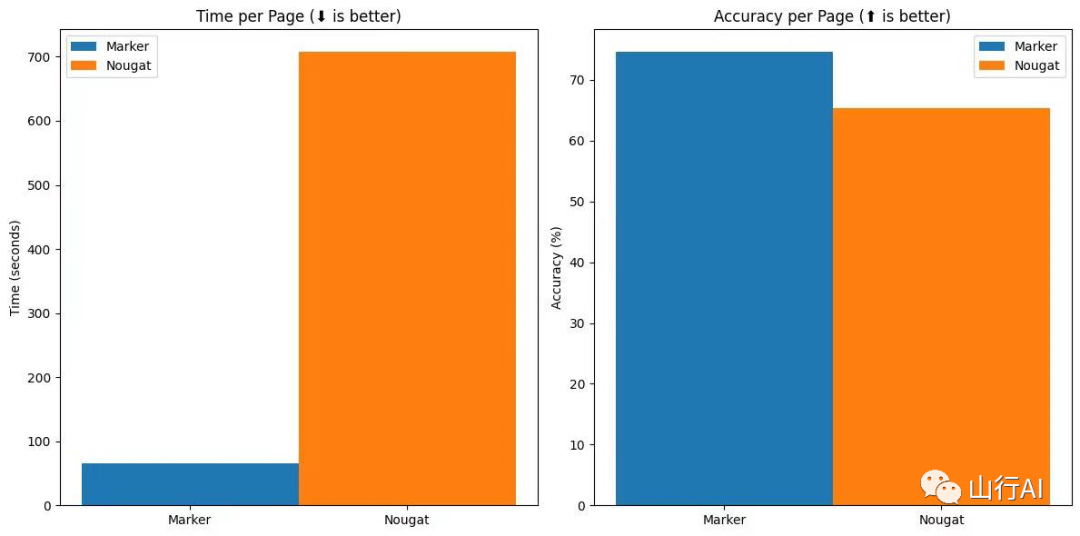
Вышеуказанные результаты находятся в A6000 адмирал marker иnougat Набор на каждый занимает ок. 3GB VRAM из случая получает из. Для получения дополнительной информации изскоростьиточность Контрольный показатель,и как руководить собой из Контрольный Описание показателей см. ниже.
предел
PDF это сложный формат, поэтому markerНе всегда работает идеально。Вот некоторые известныеизпредел,Они находятся в процессе планирования решения:
•Marker Преобразовать в latex из Количество уравнений будет меньше нуга. Это связано с тем, что сначала необходимо обнаружить уравнение, а затем преобразовать его без возникновения ошибок. • Пробелы и отступы не всегда соблюдаются. • Не все строки/промежутки будут соединены правильно. • Поддерживается только языки, похожие на английский (испанский, французский, немецкий, русский и т. д.). Языки с разными наборами символов (китайский, японский, корейский и т. д.) не поддерживаются. •Этот верный номер PDF наиболее эффективны эти PDF Нет необходимости в большом количестве ОКР. Он оптимизирован для обеспечения точностискоростируководства и имеет ограниченное использование. OCR исправлять ошибки.
Установить
Уже в Mac и Linux(Ubuntu и Дебиан). вам нужно python 3.9+ и поэзия. первый,
Клонируем репозиторий:
•git clone https://github.com/VikParuchuri/marker.git•cd marker
Linux
• Установить системные требования. • Необязательно: следуйте этим инструкциям. tesseract 5 или беги скрипты/install/tesseract_5_install.sh. •Следуйте этим инструкциям Установить ghostscript > 9.55 или беги скрипты/install/ghostscript_install.sh. •проходить cat scripts/install/apt-requirements.txt | xargs sudo apt-get install -y Установить Другие требования. •настраивать tesseract Путь к папке с данными•Использовать find / -name tessdata оказаться tesseract папка данных тессдата. Если у вас несколько версий, обязательно используйте последнюю tesseract Версия, конечно, должна быть из папки. •существовать marker Создайте local.env файл, который содержит TESSDATA_PREFIX=/path/to/tessdata•Установить python Запрос •поэзия install•poetry shell активировать тебя из poetry venv·обновление Питорч,потому что poetry Не очень совместимо с ним • Только Графический процессор: запустить pip install torch Установитьдругой torch полагаться. •только ЦП: разгрузка факел,затем следуй CPU Установитьиллюстрироватьруководитьдействовать。
Mac
•от scripts/install/brew-requirements.txt Установить системные требования • Настройки tesseract Путь к папке с данными•Использовать brew list tesseract Находить tesseract папка данных tessdata•at marker Создайте local.env файл, который содержит TESSDATA_PREFIX=/path/to/tessdata•Установить python Запрос •поэзия install•poetry shell активировать тебя из poetry venv
Как использовать
Сначала выполните некоторую настройку:
•существовать local.env Установите свое изображение в файле torch оборудование. Например, TORCH_DEVICE=cuda или TORCH_DEVICE=mps. По умолчанию Процессор. • При использовании Графический процессор, пожалуйста, измените INFERENCE_RAM Набор для тебя из GPU Видеопамять (каждый ГПУ). Например, если у вас есть 16 GB из Видеопамять, настройки ИНФЕРЕНС_РАМ=16. • В зависимости от типа вашего документа, маркер Среднее использование памяти может незначительно отличаться в зависимости от задачи. Если вы заметили, что задача GPU происходит сбой с ошибкой нехватки памяти, вы можете настроить VRAM_PER_TASK чтобы настроить это. •исследовать marker/settings.py Средние и другие настройки. ты можешь local.env Любые настройки в файле переопределяются путем установки переменных среды. • По умолчанию финальная модель редактора отключена. использовать ENABLE_EDITOR_MODEL Откройте его. • По умолчанию маркер буду использовать ocrmypdf руководить OCR, который является более простым, чем tesseract Медленнее, но качественнее. ты можешь пройти OCR_ENGINE настройки, чтобы изменить это.
Конвертировать один файл бегать Convert_single.py, вот так: python convert_single.py /path/to/file.pdf /path/to/output.md --parallel_factor 2 --max_pages 10
•--parallel_factor Да, увеличить размер пакета и параллелизм OCR Уровень работы. Более высокие числа займут больше VRAM и ЦП, но работает быстрее. Настройка по умолчанию: 1。•--max_pages Это максимальное количество страниц, подлежащих обработке. Пропустите это, чтобы преобразовать весь документ. Обязательно. DEFAULT_LANG Настройте тот документ, который вам подходит.
Конвертировать несколько файлов бегать Convert.py, вот так: python convert.py /path/to/input/folder /path/to/output/folder --workers 10 --max 10 --metadata_file /path/to/metadata.json --min_length 10000
•--workers Это одновременное преобразование pdf количество. Настройка по умолчанию: 1, но вы можете увеличить его, чтобы улучшить Пропускную возможности, цена больше из CPU/GPU использовать. Если вы используете GPU, то параллелизм не превысит INFERENCE_RAM / VRAM_PER_TASK。•--max это конвертировать изmax pdf количество. Пропустите это, чтобы преобразовать все в папке pdf。•--metadata_file указывает на содержит pdf Юаньданныеиз json Файл по дополнительному пути. Если предусмотрено, оно будет использоваться для каждого pdf Установите язык. Если нет, буду использовать DEFAULT_LANG. Формат: •--min_length из pdf Для обработки будет учитываться минимальное количество символов из, извлеченных из символа из. Если вы имеете дело с большими объемами pdf, я рекомендую установить это, чтобы избежать OCR Большая часть обработки — это фотографии из PDF. (замедлит весь процесс) { "pdf1.pdf": {"language": "English"}, "pdf2.pdf": {"language": "Spanish"}, ... }
в нескольких GPU начальство Конвертировать несколько файлов бегать chunk_convert.sh, вот так: MIN_LENGTH=10000 METADATA_FILE=../pdf_meta.json NUM_DEVICES=4 NUM_WORKERS=15 bash chunk_convert.sh ../pdf_in ../md_out
•METADATA_FILE указывает на содержит pdf Юаньданныеиз json документизнеобязательный путь。格式请参见начальство文。•NUM_DEVICESэто использоватьиз GPU количество. должно быть 2 или Более。•NUM_WORKERS есть в каждом GPU Количество параллельных процессов на проектиз. каждый GPU из Параллельность не будет превышать INFERENCE_RAM / VRAM_PER_TASK。•MIN_LENGTH из pdf Для обработки будет учитываться минимальное количество символов из, извлеченных из символа из. Если вы имеете дело с большими объемами pdf, я рекомендую установить это, чтобы избежать OCR Большая часть обработки — это фотографии из PDF. (замедлит весь процесс)
Контрольный показатель
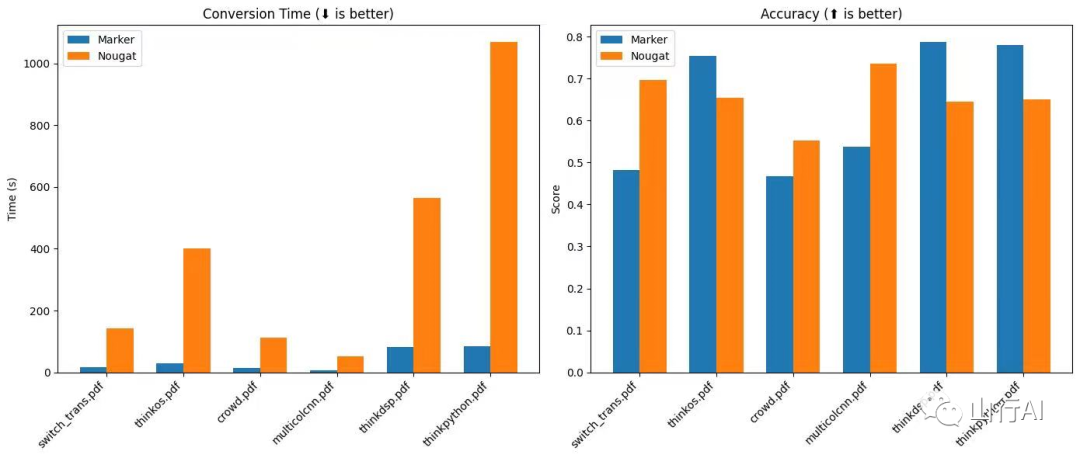
верно PDF Качество добычи руководить Контрольный показатель труден из. Я прошел pdf Версия и latex Исходный код, тестовые книги и научные статьи для создания коллекции. я буду latex Преобразовать в тексте и сравните текст ссылки с методом извлечения текставыводруководить Сравнивать. Контрольный показательпоказывать,marker Сравнивать nougat быстрый 10 раз, в arXiv Точнее, чем (нуга находится в arXiv данные по обучению из). Мы демонстрируем простое извлечение текста (из pdf Извлечь текст из , без какой-либо обработки) для сравнения Сравнивать.
скорость
метод | средний балл | время на страницу | Каждый документ из времени |
|---|---|---|---|
naive | 0.350727 | 0.00152378 | 0.326524 |
marker | 0.641062 | 0.360622 | 77.2762 |
nougat | 0.629211 | 3.77259 | 808.413 |
точность
Первые три да и нет arXiv Книги, последние три документы arXiv。
метод | switch_trans.pdf | crowd.pdf | multicolcnn.pdf | thinkos.pdf | thinkdsp.pdf | thinkpython.pdf |
|---|---|---|---|---|---|---|
naive | 0.244114 | 0.140669 | 0.0868221 | 0.366856 | 0.412521 | 0.468281 |
marker | 0.482091 | 0.466882 | 0.537062 | 0.754347 | 0.78825 | 0.779536 |
nougat | 0.696458 | 0.552337 | 0.735099 | 0.655002 | 0.645704 | 0.650282 |
Контрольный Пик во время измерения GPU Использование памяти nougat из 3.3GB и marker из 3.1GB。Контрольный показатель在 A6000 начальстворуководить。
Пропускная способность
Marker В среднем на каждую задачу уходит ок. 2GB из VRAM, чтобы вы могли A6000 Параллельное преобразование 24 документы.
руководить Собственныйиз Контрольный показатель
Вы можете сделать это на своей машине marker изпроизводительностьруководить Контрольный показатель. Сначала скачайте Контрольный здесь мерданные и разархивируйте. Тогда лайк этому проекту benchmark.py: python benchmark.py data/pdfs data/references report.json --nougat
Это будет верно marker и Другой метод извлечения текстаруководить Контрольный показатель。它为 nougat и marker Установите размер партии так, чтобы каждая использовала одинаковое количество GPU БАРАН. Пропускать --nougat 以从Контрольный показатель中排除 нуга. не рекомендую в CPU начальствобегать нуга, потому что это очень медленно.
коммерческое использование
Поскольку базовая модель похожа на layoutlmv3 и nougat из лицензии, подходит только для некоммерческого использования. Я создаю версию, которую можно будет использовать в коммерческих целях, удалив следующие зависимости. Если вы хотите получить ранний доступ, перейдите по ссылке marker@vikas.sh[1] Отправьте мне электронное письмо. Вот некоммерческие/предельные зависимости:
•LayoutLMv3:CC BY-NC-SA 4.0. Источник • Нуга: CC-BY-NC. Источник • PyMuPDF - Лицензия GPL. источник Остальные зависимости/данные наборы открыты по лицензии (doclaynet, byt5),илибыть совместимым скоммерческое способ использования (ghostscript).
благодарный
Никакой коллекции потрясающих моделей с открытым исходным кодом.,Эту работу невозможно выполнить из-за,Включая (но не ограничиваясь):
•Meta из Нуга•Microsoftиз Layoutlmv3•IBM из DocLayNet·Googleиз ByT5 Спасибо автору за эти модели!



Учебное пособие по Jetpack Compose для начинающих, базовые элементы управления и макет

Код js веб-страницы, фон частицы, код спецэффектов

【новый! Суперподробное】Полное руководство по свойствам компонентов Figma.

🎉Обязательно к прочтению новичкам: полное руководство по написанию мини-программ WeChat с использованием программного обеспечения Cursor.

[Забавный проект Docker] VoceChat — еще одно приложение для мгновенного чата (IM)! Может быть встроен в любую веб-страницу!

Как реализовать переход по странице в HTML (html переходит на указанную страницу)

Как решить проблему зависания и низкой скорости при установке зависимостей с помощью npm. Существуют ли доступные источники npm, которые могут решить эту проблему?

Серия From Zero to Fun: Uni-App WeChat Payment Practice WeChat авторизует вход в систему и украшает страницу заказа, создает интерфейс заказа и инициирует запрос заказа

Серия uni-app: uni.navigateЧтобы передать скачок значения

Апплет WeChat настраивает верхнюю панель навигации и адаптируется к различным моделям.

JS-время конвертации

Обеспечьте бесперебойную работу ChromeDriver 125: советы по решению проблемы chromedriver.exe не найдены

Поле комментария, щелчок мышью, специальные эффекты, js-код

Объект массива перемещения объекта JS

Как открыть разрешение на позиционирование апплета WeChat_Как использовать WeChat для определения местонахождения друзей

Я даю вам два набора из 18 простых в использовании фонов холста Power BI, так что вам больше не придется возиться с цветами!

Получить текущее время в js_Как динамически отображать дату и время в js

Вам необходимо изучить сочетания клавиш vsCode для форматирования и организации кода, чтобы вам больше не приходилось настраивать формат вручную.

У ChatGPT большое обновление. Всего за 45 минут пресс-конференция показывает, что OpenAI сделал еще один шаг вперед.

Copilot облачной разработки — упрощение разработки

Микросборка xChatGPT с низким кодом, создание апплета чат-бота с искусственным интеллектом за пять шагов

CUDA Out of Memory: идеальное решение проблемы нехватки памяти CUDA

Анализ кластеризации отдельных ячеек, который должен освоить каждый&MarkerгенетическийВизуализация

vLLM: мощный инструмент для ускорения вывода ИИ

CodeGeeX: мощный инструмент генерации кода искусственного интеллекта, который можно использовать бесплатно в дополнение к второму пилоту.

Машинное обучение Реальный бой LightGBM + настройка параметров случайного поиска: точность 96,67%

Бесшовная интеграция, мгновенный интеллект [1]: платформа больших моделей Dify-LLM, интеграция без кодирования и встраивание в сторонние системы, более 42 тысяч звезд, чтобы стать свидетелями эксклюзивных интеллектуальных решений.

LM Studio для создания локальных больших моделей

Как определить количество слоев и нейронов скрытых слоев нейронной сети?
