InstantMesh: эффективное создание 3D-сетей из одного изображения с использованием крупномасштабных моделей реконструкции с разреженным представлением.
Автор: Цзялэ Сюй, Вэйхао Чэн, Имин Гао и др.
Составлено: East Coast из-за @немного искусственного интеллекта и немного интеллекта

краткое содержание:В этой статье предлагаетсяInstantMesh,Это платформа прямой связи для оперативного создания 3D-сетей из однопроекционных изображений.,В настоящее время он имеет превосходное качество генерации и значительную масштабируемость обучения.
Объединив преимущества стандартной модели диффузии с несколькими представлениями и модели реконструкции с разреженными представлениями, основанной на архитектуре LRM [14], InstantMesh способен создавать разнообразные 3D-объекты за 10 секунд. Чтобы повысить эффективность обучения и использовать больше геометрического контроля, такого как глубина и нормали, мы интегрируем в нашу структуру модуль извлечения дифференцируемых изоповерхностей и оптимизируем непосредственно сеточное представление.
Результаты общедоступных наборов данных показывают, что InstantMesh значительно превосходит другие современные эталонные модели преобразования изображения в 3D как качественно, так и количественно.

01 представлять
Генерация 3D-объектов (активов) из изображений с одним видом может облегчить широкий спектр приложений, таких как виртуальная реальность, промышленный дизайн, игры и анимация и т. д. Мы стали свидетелями революции в создании изображений и видео с появлением крупномасштабных диффузионных моделей [37, 38], обученных на данных миллиарда масштабов, способных генерировать яркие и творческие изображения из сигналов открытого домена. Однако повторение этого успеха в создании 3D-изображений сталкивается с проблемами из-за ограниченного размера наборов 3D-данных и неравномерного качества аннотаций.
Чтобы решить проблему нехватки 3D-данных, предыдущие исследования изучали сжатие априорных 2D-диффузии в 3D-представления и использование стратегий пошаговой оптимизации. DreamFusion [34] предложил метод фракционной дистилляции (SDS), который совершил прорыв в 3D-синтезе открытого мира. Однако SDS с использованием текста в 2D-моделях часто сталкивается с многогранной проблемой — проблемой «Януса». Чтобы улучшить согласованность 3D, последующие исследования [35] предложили метод, основанный на Zero123 [23], новом перспективном генераторе, точно настроенном на основе Stable Diffusion [37]. В серии исследований [42, 50, 26, 24, 47] были предложены многоперспективные генеративные модели, в которых процесс оптимизации может руководствоваться несколькими новыми перспективами одновременно.
Методы 2D-дистилляции обладают мощными возможностями генерации с нулевой выборкой, но они отнимают много времени и непрактичны в реальных приложениях. С появлением крупномасштабных наборов 3D-данных в открытом мире [8, 9] новаторские исследования [14, 13, 45] показывают, что токены изображений могут быть напрямую сопоставлены с 3D-представлениями с помощью новой модели крупномасштабной реконструкции (LRM) ( Типа триплана). Основанная на высокомасштабируемой архитектуре Transformer, LRM указывает перспективное направление для быстрого создания высококачественных 3D-объектов (ассетов). Тем временем компания Instant3D [19] предложила метод прогнозирования трехмерной формы с помощью расширенного LRM с многопроекционным вводом. Этот метод объединяет LRM с моделями генерации изображений, значительно улучшая возможности обобщения.
Метод LRM использует триплан в качестве трехмерного представления и MLP для синтеза новых перспектив. Несмотря на мощные возможности представления геометрии и текстур, декодирование трипланов требует процесса объемного рендеринга с интенсивным использованием памяти, что серьезно влияет на масштаб обучения. Кроме того, дорогостоящие вычислительные затраты затрудняют использование RGB и геометрической информации высокого разрешения (например, глубины и нормалей) для контроля. Чтобы повысить эффективность обучения, в недавних исследованиях предпринимаются попытки использовать функцию Гаусса [18] в качестве трехмерного представления, которое эффективно для визуализации эффектов, но не подходит для геометрического моделирования. В нескольких параллельных исследованиях [63, 54] было решено использовать методы оптимизации дифференцируемой поверхности [39, 40] непосредственно на сеточном представлении для контроля. Однако они используют архитектуру на основе CNN, которая ограничивает их гибкость в обработке различных входных данных и ограничивает масштабируемость обучения для более крупных наборов данных, которые могут существовать в будущем.
В этой работе мы предлагаем InstantMesh, платформу прямого распространения для создания высококачественных 3D-сеток из одного изображения. Учитывая входное изображение, InstantMesh сначала использует модель диффузии с несколькими представлениями для создания согласованных трехмерных изображений с несколькими изображениями, а затем использует крупномасштабную модель реконструкции разреженных представлений для непосредственного прогнозирования трехмерной сетки. Весь процесс может быть завершен за секунды. . Благодаря интеграции дифференцируемого модуля извлечения изоповерхностей наша модель реконструкции применяет геометрический контроль непосредственно на поверхности сетки, достигая удовлетворительной эффективности обучения и качества генерации сетки. Наша модель построена на архитектуре на основе LRM и обладает превосходной масштабируемостью обучения.
эксперимент Результаты показывают,InstantMesh значительно превосходит другие современные методы преобразования изображения в 3D как качественно, так и количественно. Мы надеемся, что InstantMesh сможет стать мощной базовой моделью для преобразования изображения в 3D.,И внести существенный вклад в область 3D-генеративного искусственного интеллекта.
02 Связанная работа
Ранние попытки преобразования изображения в 3D были сосредоточены в основном на задачах реконструкции одного изображения. С появлением диффузионных моделей новаторская работа исследовала 3D-генеративное моделирование на основе условий изображения, исследуя различные представления, такие как облака точек, сетки, сетки SDF и нейронные поля. Хотя эти методы достигли удовлетворительного прогресса, их трудно обобщить на объекты открытого мира из-за ограниченного размера обучающих данных.
Появление мощных моделей диффузии текста в изображение вдохновило на идею интеграции априорной 2D-диффузии в 3D-поля нейронного излучения и принятия стратегии пошаговой оптимизации. Оценочная дистилляционная выборка (SDS), предложенная DreamFusion, демонстрирует превосходную производительность при обработке текста с нулевой выборкой по сравнению с 3D-синтезом и значительно превосходит альтернативы на основе CLIP. Однако методы, основанные на SDS, часто сталкиваются с многогранными проблемами, также известными как проблема «Януса». Zero123 подтвердил, что Stable Diffusion можно настроить для создания новых видов, условно относящихся к позе камеры. Благодаря новому руководству по представлению, предоставленному Zero123, новейшие методы преобразования изображения в 3D демонстрируют улучшенную согласованность 3D и способность генерировать разумные формы из изображений с открытой областью.
Многоракурсная диффузионная модель.чтобы решитьZero123Проблемы несогласованности между несколькими созданными представлениями,Некоторые работы направлены на точную настройку 2D-моделей диффузии.,Одновременное объединение нескольких представлений одного и того же объекта. С 3D-согласованными многопроекционными изображениями,Для получения 3D-объектов можно применять различные методы.,Например, оптимизация SDS, метод реконструкции нейронной поверхности, трехмерная диффузионная модель в условиях нескольких представлений и т. д. Для дальнейшего улучшения возможностей обобщения и согласованности нескольких представлений.,В некоторых недавних работах временные априорные положения используются в моделях распространения видео для генерации нескольких представлений.
Реконструируйте модели в масштабе.крупный масштаб3DДоступность наборов данных позволяет тренировать высокообобщенные модели реконструкции.,Для прямого преобразования изображения в 3D. Крупномасштабная модель реконструкции демонстрирует, что магистральная сеть трансформаторов может эффективно отображать токены изображений в неявное 3D с многопроекционным контролем. триплан. Instant3D дополнительно расширяет модель крупномасштабной реконструкции до разреженных входных данных, что значительно улучшает качество реконструкции. Вдохновленные Instant3D, LGM и GRM используют 3D-гауссовы функции вместо представления triplaneNeRF, тем самым обеспечивая превосходную эффективность рендеринга и избегая необходимости в процессе объемного рендеринга с интенсивным использованием памяти. Однако функции Гаусса имеют недостатки в явном геометрическом моделировании и качественном выделении поверхностей. Учитывая успех методов оптимизации нейронных сеток, были выбраны параллельные MVD2 и CRM для оптимизации непосредственно представления сетки для достижения эффективного обучения и высококачественного моделирования геометрии и текстур. В отличие от их сверточных сетевых архитектур, наша модель построена на модели крупномасштабной реконструкции и использует чисто трансформаторную архитектуру, обеспечивающую более высокую гибкость и масштабируемость обучения.
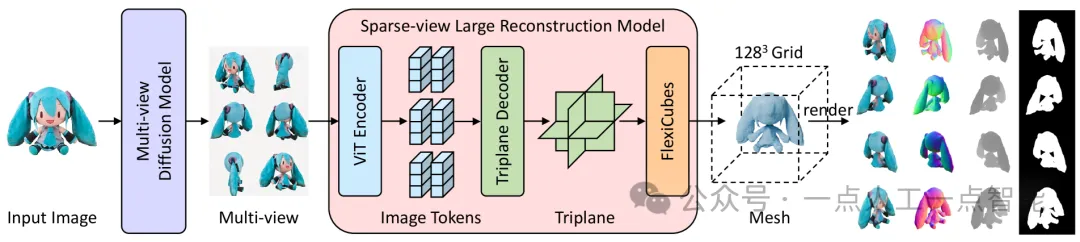
03 Архитектура InstantMesh
Похоже на: Instant3D, автор многоракурсная диффузионная модельG_Mи Крупномасштабная реконструкция модели с редкими видамиG_Rкомпозиция。Данное входное изображениеI,многоракурсная диффузионная модельG_Mгенерировать3DСогласованные многопросмотровые изображения,Затем Введите это Крупномасштабная реконструкция модели с редкими видамиG_Rкачественно реконструировать3Dсетка。мы сейчаспредставлять Мы готовим данные、Технические улучшения в архитектуре моделей и стратегиях обучения.
3.1 Многоракурсная диффузионная модель
Технически наша модель реконструкции с разреженным представлением может использовать любое изображение точки обзора в качестве входных данных, поэтому мы можем интегрировать произвольные генеративные модели с несколькими представлениями в нашу структуру, позволяя создавать объекты из текста в 3D и из изображения в 3D, такие как MVDream, ImageDream, SyncDreamer, СПАД и СВ3Д. Мы выбрали Zero123++ из-за его надежной согласованности нескольких представлений и индивидуального распределения точек обзора, охватывающего как верхнюю, так и нижнюю части трехмерного объекта.
Спиннер на белом фоне:Данное входное изображение,Zero123++ генерирует серое фоновое изображение размером 960×640.,6 многоракурсных изображений представлены в сетке 3×2. на практике,Мы заметили, что сгенерированный фон был непоследовательным в разных областях изображения.,и происходит изменение значений RGB,Это приводит к тому, что в результатах реконструкции появляются плавающие зернистые и облачные артефакты. и,Разреженные модели реконструкции также обычно обучаются на белых фоновых изображениях. Чтобы удалить серый фон,Нам нужно использовать сторонние библиотеки или модели.,Однако согласованность сегментации между несколькими представлениями не может быть гарантирована. поэтому,Мы решили настроить Zero123++ для синтеза единообразных изображений белого фона.,Обеспечьте стабильность последующего процесса реконструкции разреженного представления.
Подготовка данных и детали тонкой настройки:мы следуемZero123++Распределение камер для подготовки данных для точной настройки。Конкретно,Для каждой 3D-модели в подмножестве LVIS Objaverse.,Мы визуализируем изображение запроса и 6 целевых изображений.,Все на белом фоне. Азимут, высота и расстояние до камеры изображения запроса выбираются случайным образом из заранее определенного диапазона. Позы шести целевых изображений состоят из смещенных абсолютных углов места 20° и -10°.,Угол азимута, связанный с изображением запроса, начинается с 30°.,Каждая поза увеличивается на 60°.
В процессе доводки,Мы используем изображение запроса в качестве условия,А 6 целевых изображений объединяются в сетку 3×2 для шумоподавления. Следуйте подходу Zero123++.,Мы принимаем стратегию линейного шума и прогнозируемую потерю L1. Также мы случайным образом изменяем размер условного изображения,Адаптируйте модель к различным входным разрешениям и создавайте четкие изображения. Так как цель тонкой настройки как раз и заключается в замене цвета фона,Так что сходится очень быстро. Конкретно,Мы используем скорость обучения1.0 \times 10^{-5}и Размер партии48в условияхUNetруководить1000шаг тонкой настройки。Доработанная модель полностью сохранена.Zero123++изгенерироватьспособность,и постоянно создает изображения с белым фоном.
3.2 Реконструкция крупномасштабной модели с редкими видами
наспредставлять Модель реконструкции разреженного представленияG_RПодробности,Модель прогнозирует сетки на основе сгенерированных многовидовых изображений. Архитектура модели была изменена и улучшена.,Улучшено по сравнению с Instant3D.
Подготовка данных:насиз训练数据集是从Objaverse数据集中渲染из多视图图像композицияиз。Конкретно,Мы визуализируем изображение размером 512×512, глубину и нормаль из 32 случайных точек обзора для каждого объекта в наборе данных. также,Для обучения нашей модели мы используем выбранное высококачественное подмножество.
Целью фильтрации является удаление объектов, отвечающих любому из следующих условий: (i) объекты без наложения текстур, (ii) визуализированное изображение занимает менее 10% поля зрения под любым углом, (iii) содержит несколько отдельных объекты, (iv) объекты без информации заголовка, предоставленной набором данных Cap3D, и (v) объекты низкого качества. Классификацию объектов «низкого качества» можно определить на основе наличия в метаданных таких тегов, как «lowpoly» и его вариантов (например, «low_poly»). Применяя наши критерии фильтрации, мы отфильтровали около 270 тысяч экземпляров высокого качества из исходных 800 тысяч объектов в наборе данных Objaverse.
Введите вид и разрешение:во время тренировки,Мы случайным образом выбираем набор из 6 изображений в качестве входных данных.,И еще 4 изображения используйте в качестве сигналов наблюдения для каждого объекта. Чтобы соответствовать выходному разрешению Zero123++,Размер всех входных изображений изменяется до 320 × 320 пикселей. В процессе умозаключения,Мы используем 6 изображений, сгенерированных Zero123++, в качестве входных данных для модели реконструкции.,и исправить позы камеры. Следует отметить, что,Наша архитектура на основе Transformer может использовать различное количество входных представлений.,Таким образом, в некоторых случаях возможно использовать меньше входных представлений для реконструкции.,Это может облегчить проблему несогласованности нескольких представлений.
Сетка как 3D-представление:Ранее на основеLRMвывод методаtriplane,Для синтеза изображения необходим воксельный рендеринг. во время тренировки,Воксельный рендеринг потребляет много памяти,Контроль изображений и нормалей высокого разрешения затруднен. В целях повышения эффективности тренировок и качества реконструкции,Мы интегрируем модуль выделения дифференцируемых изоповерхностей FlexiCubes в нашу модель реконструкции. Благодаря эффективной растеризации сетки,Мы можем использовать изображения в полном разрешении и дополнительную геометрическую информацию для контроля.,Такие как глубина и нормальный,Не разрезая их на части. Применение этих геометрических наблюдений выгодно отличается от трехплоскостных. Сетка, извлеченная с помощью NeRF, может получить более гладкий результат. Кроме того, использование представления сетки позволяет легко применять дополнительные этапы постобработки для улучшения результатов, такие как SDS-оптимизация или запекание текстур. Это осталось для дальнейшей работы.
В отличие от LRM с одним представлением, наша модель реконструкции принимает в качестве входных данных 6 представлений и требует больше памяти для перекрестного внимания между токенами триплана и токенами изображений. Мы заметили, что обучение такого масштабного Трансформера с нуля занимает много времени. Для более быстрой сходимости мы инициализируем нашу модель, используя предварительно обученные веса из OpenLRM, реализации LRM с открытым исходным кодом. Мы принимаем следующую двухэтапную стратегию обучения.
Этап 1: Обучение NeRF.на первом этапе,нассуществоватьtriplane Тренируйтесь на представлениях NeRF и повторно используйте предыдущие знания из предварительно обученного OpenLRM. Чтобы обеспечить ввод с несколькими изображениями, мы добавляем слой модуляции позы камеры AdaLN в кодировщик изображений ViT, чтобы токены выходного изображения учитывали позу, следуя подходу Instant3D, и удаляем исходный слой модуляции камеры в декодере триполосок LRM. На этом этапе обучения мы используем две функции потерь: потерю изображения и потерю маски:
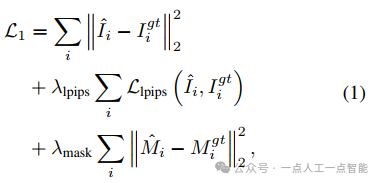
в,\hat{I}_i、I^{gt}_i、\hat{M}_iиM^{gt}_iСоответственно представляютiВизуализированное изображение вида、реальное изображение、渲染из遮罩и真实из遮罩。во время тренировки,наснастраивать\lambda_{lpips}=2.0 ,\lambda_{mask}=1.0 ,и используйте метод косинусного отжига, чтобы изменить скорость обучения с4.0 \times 10^{-4}вырождаться в4.0 \times 10^{-5}。дляруководить高分辨率из训练,Наша модель отображает фрагменты изображений размером 192×192.,И используйте обрезанное реальное размером от 192×192 до 512×512. изображениекусокруководитьконтролировать。
Этап 2: Обучение на сетке.на втором этапе,Переходим на сеточное представление для эффективного обучения,и применить дополнительные геометрические наблюдения。нас ВоляFlexiCubes [40] интегрирован в нашу модель реконструкции для извлечения сетчатых поверхностей из неявных триплоскостных полей. оригинальный триплан Модуль рендеринга NeRF включает в себя MLP плотности и MLP цвета. Мы повторно используем MLP плотности для прогнозирования SDF, одновременно добавляя два дополнительных MLP для прогнозирования деформаций и весов, необходимых для FlexiCubes.
Для поля плотностиf(x)=d,x\in \mathbb{R}^3,Точки внутри объекта имеют большие значения.,в то время как точки вне объекта имеют меньшие значения,иSDFполеg(x)=sэто наоборот。поэтому,насинициализировать последнийSDF MLPвес слояw \in \mathbb{R}^Cипредвзятостьb\in \mathbb{R}следующее:

В последнем слое исходной плотности MLP.,w_d \in \mathbb{R}^Cиb_d \in \mathbb{R}соответственновыражатьмассаипредвзятость,\tauвыражатьплотностьполе使用из等值面阈值。изменить последнееMLPВходные объекты слоя выражаются какf\in \mathbb{R}^C,Тогда у нас есть:
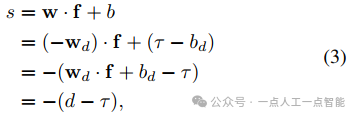
При такой инициализации мы инвертируем «направление» поля плотности, чтобы оно соответствовало направлению SDF, и гарантируем, что границы изоповерхности изначально лежат в наборе уровня 0 поля SDF. Опытным путем мы обнаружили, что такая инициализация повышает стабильность обучения и скорость сходимости FlexiCubes. Функция потерь на втором этапе:
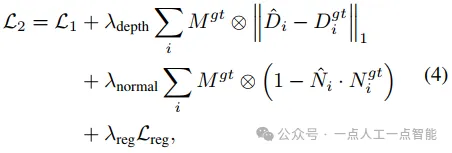
в,\hat{D}_i,D^{gt}_i,\hat{N}_iиN^{gt}_iСоответственно представляютiГлубина рендеринга вида,истинная глубина,Рендеринг нормалейинастоящий нормальный。\otimesПредставляет поэлементный продукт,\mathcal{L}_{reg}выражатьFlexiCubesсрок регуляризации。во время тренировки,наснастраивать\lambda _{depth}=0.5,\lambda _{normal}=0.2,\lambda _{reg}=0.01 ,и используйте скорость обучения4.0 \times 10^{-5}из余弦退火приезжать 0. У нас есть 8 NVIDIA H800 На графическом процессоре выполняются два этапа обучения модели.
Улучшение и возмущение камеры.Перестроение модели с использованием пространства просмотра[13, 45, 44, 65] разные,Наша модель реконструирует 3D-объекты в каноническом мировом пространстве.,вzОсь совмещена с антигравитационным направлением。В целях дальнейшего улучшения3DМасштаб объектаи方向из鲁棒性,Мы выполняем случайное вращение и масштабирование входных поз многоракурсной камеры. Учитывая, что многоракурсные изображения, созданные Zero123++, могут не соответствовать предопределенным позам камеры.,Мы также добавляем случайный шум к параметрам камеры перед подачей их в кодировщик изображений ViT.
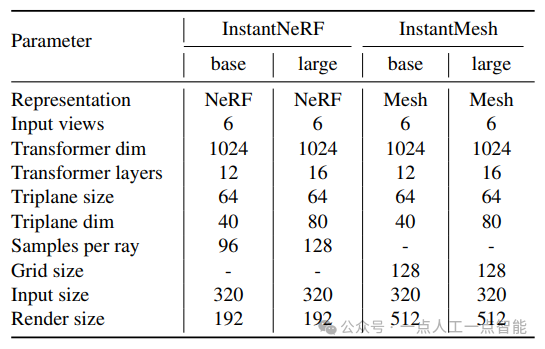
Варианты модели.в этой статье,Мы предоставляем четыре варианта модели реконструкции разреженного представления.,Двое из Фазы 1 и двое из Фазы 2 соответственно. Мы называем каждую модель в соответствии с ее 3D-представлением («NeRF» или «Mesh») и масштабом ее параметров («базовый» или «большой»). Подробная информация о каждой модели представлена в Таблице 1. Учитывая, что различные 3D-представления и масштабы моделей могут повысить удобство использования в различных сценариях применения.,Мы публикуем вес всех 4 моделей. Мы считаем, что наша работа может служить мощной базовой моделью от изображений до 3D.,Продвигайте будущие исследования в области 3D-генеративного искусственного интеллекта.
04 эксперимент
в этом разделе,Проводим эксперимент,Количественно и качественно сравните нашу InstantMesh с существующими современными методами преобразования изображения в 3D.
4.1 экспериментнастраивать
набор данных.нас Используйте два общедоступных набора данныхруководить Количественная оценка эффективности,то есть Google Scanned Объекты (GSO) [10] и OmniObject3D (Omni3D) [55]. GSO содержит около 1000 объектов, и мы случайным образом выбираем 300 из них в качестве оценочного набора. Для Omni3D мы выбрали 28 общих категорий, а затем выбрали по 5 лучших объектов из каждой категории, всего 130 объектов (в некоторых категориях было менее 5 объектов) в качестве оценочного набора.
Чтобы оценить визуальное качество 2D сгенерированных 3D-сеток, мы создали два набора оценки изображений для GSO и Omni3D соответственно. В частности, мы представляем 21 изображение каждого объекта на орбитальных траекториях при среднем азимуте и различных углах места {30°, 0°, -30°}. Поскольку Omni3D также включает в себя базовые виды, случайно выбранные из верхней полусферы объекта, мы случайным образом выбрали 16 видов и создали дополнительный оценочный набор изображений для Omni3D.
базовый уровень.нас Воля提出изInstantMeshи4базовый уровеньруководить Сравнивать:(i) TripoSR [45]: Реализация LRM с открытым исходным кодом, показывающая лучшую на сегодняшний день производительность реконструкции с одним представлением (ii) LGM [44]: Крупномасштабная гауссовая модель на основе Unet для восстановления гауссиан на основе сгенерированных многопроекционных изображений (iii) CRM [54]: Модель сверточной реконструкции на основе Unet для восстановления трехмерных сеток на основе сгенерированных многоракурсных изображений и нормализованного координатного отображения (CCM); sv3D [47]: Модель условной диффузии изображения, основанная на стабильной диффузии видео, которая генерирует орбитальные видеоролики объектов. Мы оцениваем только задачу синтеза нового представления, поскольку создание 3D-сеток непосредственно из ее выходных данных не является простым.
мера.нас Оцениватьгенерировать资源из2Dвизуальное качествои3DГеометрическое качество。для2Dвизуальная оценка,Мы визуализируем новый вид из сгенерированной 3D-сетки.,и сравните это с истинным мнением,В качестве метрик используются PSNR, SSIM и LPIPS. Для оценки 3D-геометрии,Сначала мы выравниваем систему координат сгенерированной сетки с основной истинной сеткой.,Затем Воля所有сетка Переместитьи Масштабировать до нужного размера[-1, 1]³ куба. Мы используем 16 тыс. точек, отобранных для равномерной выборки поверхности, и сообщаем о расстоянии фаски (CD) и F-оценке (FS) с порогом 0,2.
4.2 Основные результаты
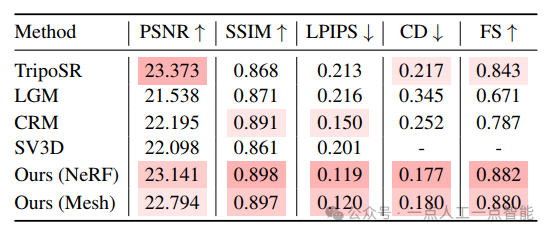
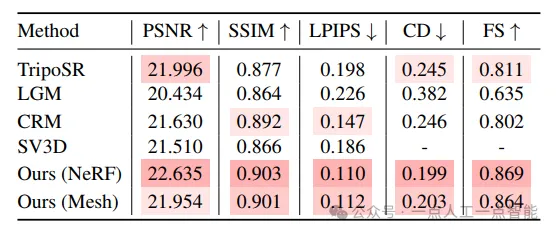
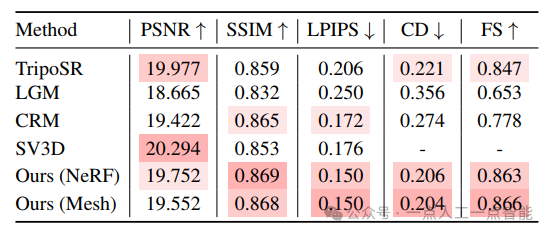
Количественные результаты.нассоответственносуществовать Таблица 2、Таблица 3и Таблица 4сообщается вдругой Оценивать集上из Количественные результаты.длякаждый индикатор,Выделяем тройку лучших результатов среди всех методов,Более темные цвета указывают на лучшие результаты. Для нашего подхода,Мы сообщаем о результатах, используя различные варианты модели реконструкции разреженного представления (например, «NeRF» и «Mesh»).
Из показателей синтеза нового 2D-представления мы видим, что InstantMesh значительно превосходит базовые методы SSIM и LPIPS, что указывает на то, что сгенерированные им результаты имеют лучшее визуальное качество. Как показано на рисунке 3, InstantMesh выглядит правдоподобно, тогда как базовый метод в новых представлениях часто выглядит искаженным. Мы также можем заметить, что PSNR InstantMesh немного ниже, чем лучший базовый уровень, что указывает на то, что новые представления менее верны основной истине на уровне пикселей, поскольку они «представлены» моделью диффузии с несколькими представлениями. Однако мы считаем, что качество восприятия более важно, чем точность, поскольку «поистине новый взгляд» должен быть неизвестен, а одно изображение должно быть использовано в качестве эталона для множества возможностей.
Что касается показателей трехмерной геометрии, InstantMesh значительно превосходит базовые методы на CD и FS, что указывает на более высокую точность генерируемых форм. Как видно из рисунка 3, InstantMesh представляет собой наиболее надежную геометрию среди всех методов. Благодаря масштабируемой архитектуре и адаптированным стратегиям обучения InstantMesh обеспечивает высочайшую производительность преобразования изображений в 3D.
Качественные результаты.для定性地СравниватьнасизInstantMeshи Другие базовые методы,Мы выбрали два изображения из оценочного набора ГСО.,и выбрал два изображения из интернета,И получили изображение в результате генерации 3D. Для каждой сгенерированной сетки,Мы визуализируем рендеринг текстур (вверху) и чистую геометрию (внизу) с двух разных точек зрения. Мы генерируем результаты, используя модель реконструкции разреженного представления варианта «Сетка».
Как показано на рисунке 3, 3D-сетка, созданная InstantMesh, демонстрирует значительно более правдоподобную геометрию и внешний вид. TripoSR может генерировать удовлетворительные результаты из изображений, стилизованных аналогично набору данных Objaverse, но ему не хватает воображения и он имеет тенденцию генерировать вырожденную геометрию и текстуры, когда входные изображения имеют более свободный стиль (рис. 3, строка 3, список 1). InstantMesh также может генерировать более четкие текстуры, чем TripoSR, благодаря контролю с высоким разрешением. LGM и CRM, подобно нашей структуре, сочетают модели диффузии с несколькими представлениями и модели реконструкции с разреженными представлениями, поэтому они также обладают возможностями воображения. Однако LGM демонстрирует искажения и очевидные несоответствия нескольких представлений, в то время как CRM испытывает трудности с созданием гладких поверхностей.


Сравните варианты «NeRF» и «Mesh». Мы также качественно и количественно сравниваем варианты «Mesh» и «NeRF» нашей модели реконструкции с разреженным представлением. Как видно из таблиц 2, 3 и 4, вариант «NeRF» немного превосходит вариант «Mesh» по метрикам. Мы считаем, что это связано с ограниченным разрешением сетки FlexiCubes, что приводит к потере деталей при извлечении поверхности сетки. Однако, учитывая удобство, обеспечиваемое эффективным рендерингом сетки по сравнению с объемным рендерингом с интенсивным использованием памяти по сравнению с NeRF, падение показателей меньше и незначительно. Кроме того, мы также визуализируем некоторые результаты преобразования изображения в 3D для этих двух вариантов модели на рисунке 4. Применяя явный геометрический контроль, то есть глубину и нормали, вариант модели «Сетка» может создавать более гладкие поверхности по сравнению с сетками, извлеченными из полей плотности NeRF, что часто более привлекательно в практических приложениях.
05 в заключение
В этой работе мы предлагаем InstantMesh, платформу мгновенного преобразования изображений в 3D с открытым исходным кодом, которая использует крупномасштабную модель реконструкции на основе трансформатора с разреженным представлением для создания высококачественных 3D-объектов из изображений, сгенерированных многопроекционными диффузионными моделями.
На основе платформы Instant3D мы вводим представление на основе сетки и дополнительный геометрический контроль, что значительно повышает эффективность обучения и качество реконструкции. Мы также внесли улучшения в другие области, такие как подготовка данных и стратегии обучения.
Оценка общедоступных наборов данных показывает, что InstantMesh качественно и количественно превосходит другие современные методы преобразования изображения в 3D. InstantMesh стремится внести важный вклад в сообщество 3D-генеративного искусственного интеллекта, поддерживая исследователей и создателей.
ограничение.нас Уведомлениеприезжатьнасиз框架仍然存существовать一些局限性,Мы оставляем это как направление будущей работы.。(i)следоватьLRM [14] и Instant3D В [19] наш декодер трипланов на основе трансформатора генерирует трипланы размером 64x64, разрешение которых может стать узким местом для 3D-моделирования высокой четкости. (ii) На качество нашей 3D-генерации неизбежно влияет многоракурсная несогласованность диффузионной модели, но мы считаем, что эту проблему можно смягчить в будущем за счет использования более совершенных многоракурсных диффузионных архитектур. (iii) Хотя FlexiCubes может улучшить гладкость поверхности сетки и уменьшить количество артефактов при дополнительном геометрическом контроле, мы отмечаем, что по сравнению с NeRF они менее эффективны при моделировании крошечных и вытянутых структур (рис. 4, стр. 2 строки, 1 столбец).



Учебное пособие по Jetpack Compose для начинающих, базовые элементы управления и макет

Код js веб-страницы, фон частицы, код спецэффектов

【новый! Суперподробное】Полное руководство по свойствам компонентов Figma.

🎉Обязательно к прочтению новичкам: полное руководство по написанию мини-программ WeChat с использованием программного обеспечения Cursor.

[Забавный проект Docker] VoceChat — еще одно приложение для мгновенного чата (IM)! Может быть встроен в любую веб-страницу!

Как реализовать переход по странице в HTML (html переходит на указанную страницу)

Как решить проблему зависания и низкой скорости при установке зависимостей с помощью npm. Существуют ли доступные источники npm, которые могут решить эту проблему?

Серия From Zero to Fun: Uni-App WeChat Payment Practice WeChat авторизует вход в систему и украшает страницу заказа, создает интерфейс заказа и инициирует запрос заказа

Серия uni-app: uni.navigateЧтобы передать скачок значения

Апплет WeChat настраивает верхнюю панель навигации и адаптируется к различным моделям.

JS-время конвертации

Обеспечьте бесперебойную работу ChromeDriver 125: советы по решению проблемы chromedriver.exe не найдены

Поле комментария, щелчок мышью, специальные эффекты, js-код

Объект массива перемещения объекта JS

Как открыть разрешение на позиционирование апплета WeChat_Как использовать WeChat для определения местонахождения друзей

Я даю вам два набора из 18 простых в использовании фонов холста Power BI, так что вам больше не придется возиться с цветами!

Получить текущее время в js_Как динамически отображать дату и время в js

Вам необходимо изучить сочетания клавиш vsCode для форматирования и организации кода, чтобы вам больше не приходилось настраивать формат вручную.

У ChatGPT большое обновление. Всего за 45 минут пресс-конференция показывает, что OpenAI сделал еще один шаг вперед.

Copilot облачной разработки — упрощение разработки

Микросборка xChatGPT с низким кодом, создание апплета чат-бота с искусственным интеллектом за пять шагов

CUDA Out of Memory: идеальное решение проблемы нехватки памяти CUDA

Анализ кластеризации отдельных ячеек, который должен освоить каждый&MarkerгенетическийВизуализация

vLLM: мощный инструмент для ускорения вывода ИИ

CodeGeeX: мощный инструмент генерации кода искусственного интеллекта, который можно использовать бесплатно в дополнение к второму пилоту.

Машинное обучение Реальный бой LightGBM + настройка параметров случайного поиска: точность 96,67%

Бесшовная интеграция, мгновенный интеллект [1]: платформа больших моделей Dify-LLM, интеграция без кодирования и встраивание в сторонние системы, более 42 тысяч звезд, чтобы стать свидетелями эксклюзивных интеллектуальных решений.

LM Studio для создания локальных больших моделей

Как определить количество слоев и нейронов скрытых слоев нейронной сети?
