Инновационная практика YOLO11: новое многомасштабное сверточное внимание (MSCA) добавлено к ситуации увеличения количества очков в разных местах сети | Как инновационные точки могут эффективно увеличивать количество очков в своих собственных наборах данных и решать такие проблемы, как увеличение и потеря очков ?
💡💡💡Проблема, которую решает эта статья: почему точка инновации не увеличивается в собственном наборе данных или даже не уменьшается? ? ?
💡💡💡Анализ причин: разные наборы данных имеют неодинаковую производительность при добавлении инновационных точек — это нормально. Даже если они размещены в разных местах сети, в некоторых местах баллы увеличиваются, а в некоторых — уменьшаются! ! !
💡💡💡Как решить: поместите точки инноваций в разные сетевые местоположения и предоставьте соответствующие файлы yaml. Всегда найдется тот, который может эффективно увеличить количество очков в вашем наборе данных. Поэтому вам все равно придется проводить больше экспериментов и пробовать разные вещи, и, возможно, вы сможете добиться неожиданных результатов! ! !
💡💡💡Ситуация с увеличением очков: Исходное mAP50 составляет 0,768, а улучшенная структурная диаграмма 1 показывает, что mAP50 составляет 0,788., mAP50 улучшенной структурной диаграммы 2 составляет 0,792, а mAP50 улучшенной структурной диаграммы 3 составляет 0.775
Структурная схема улучшения 1:
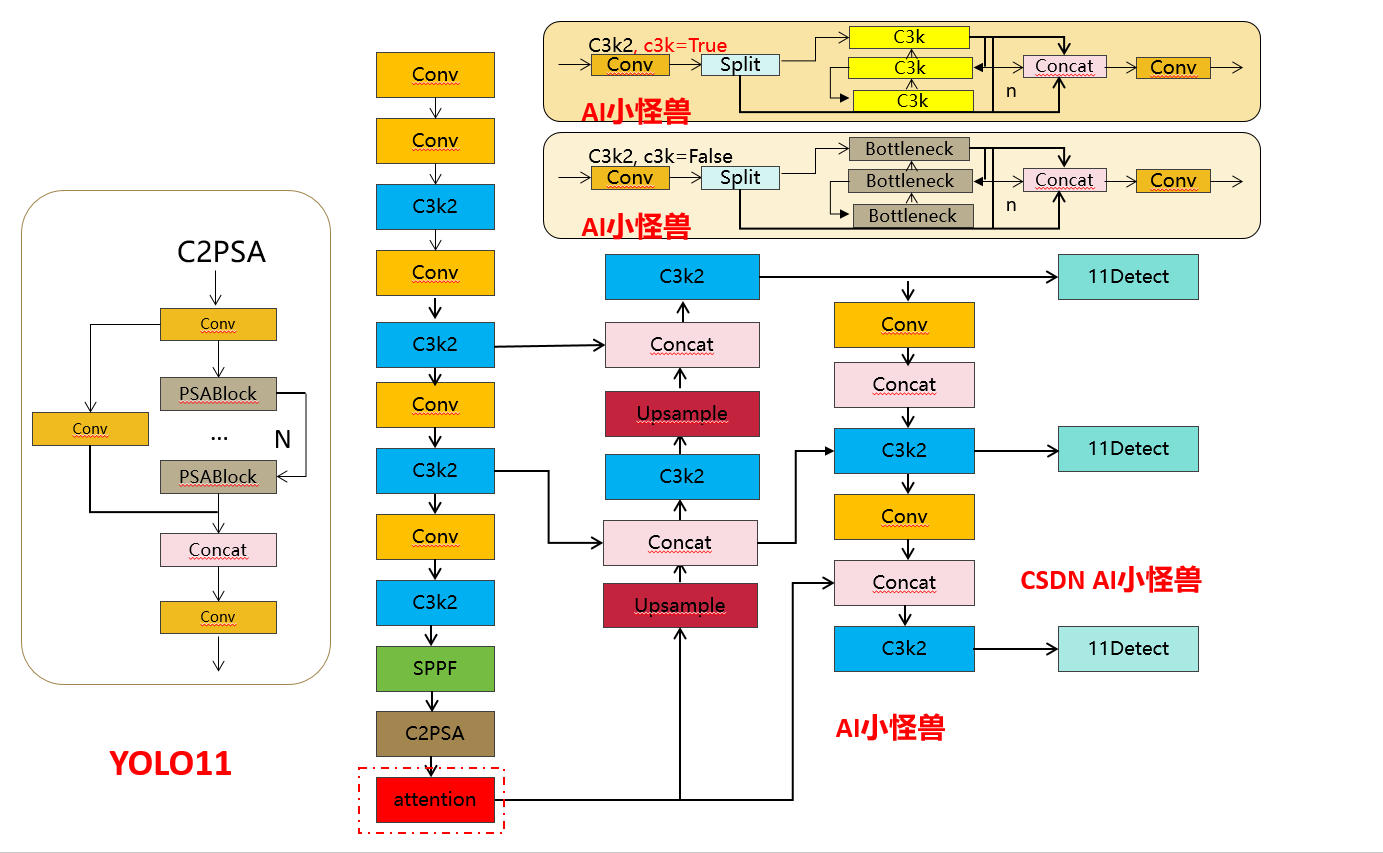
Структурная схема улучшения 2:
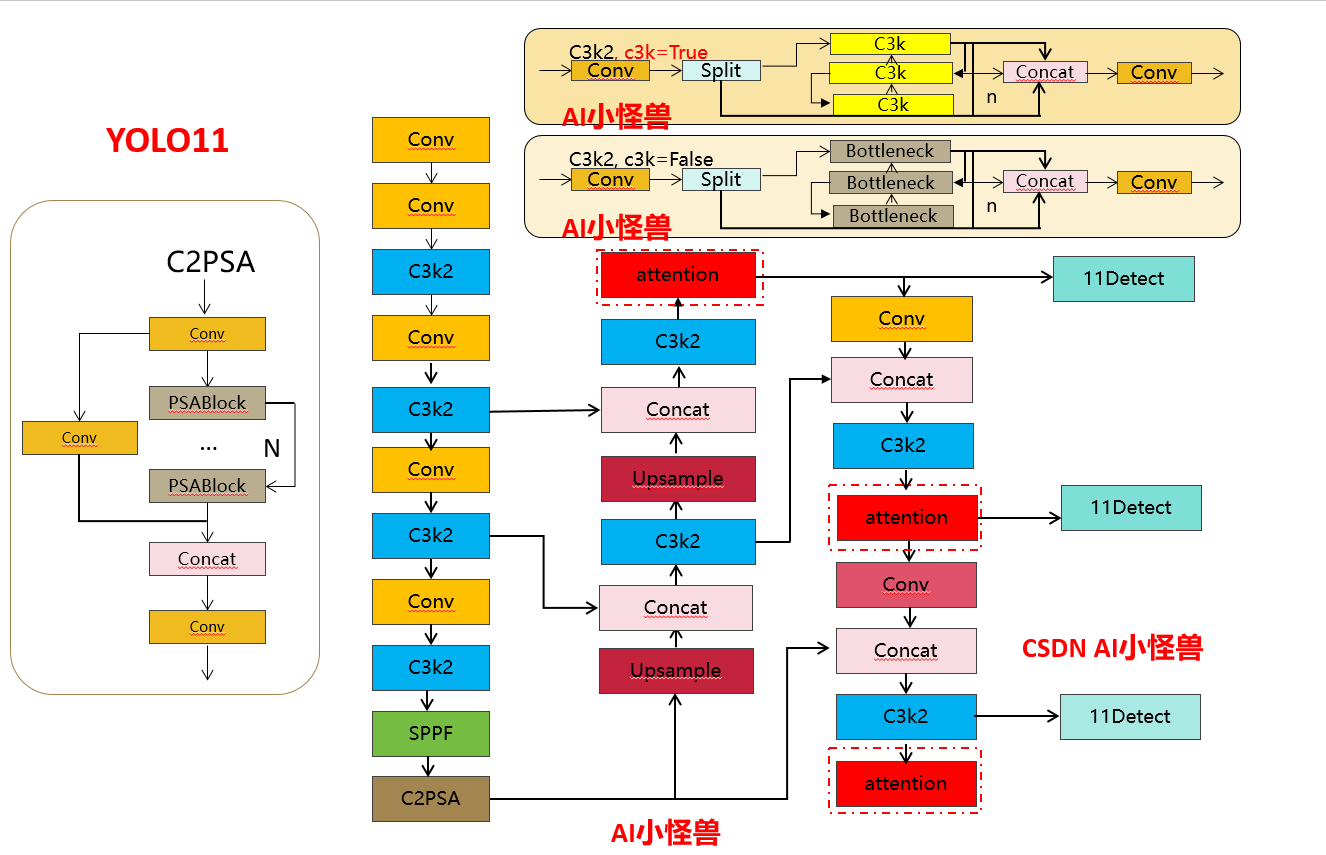
Структурная схема улучшения 3:
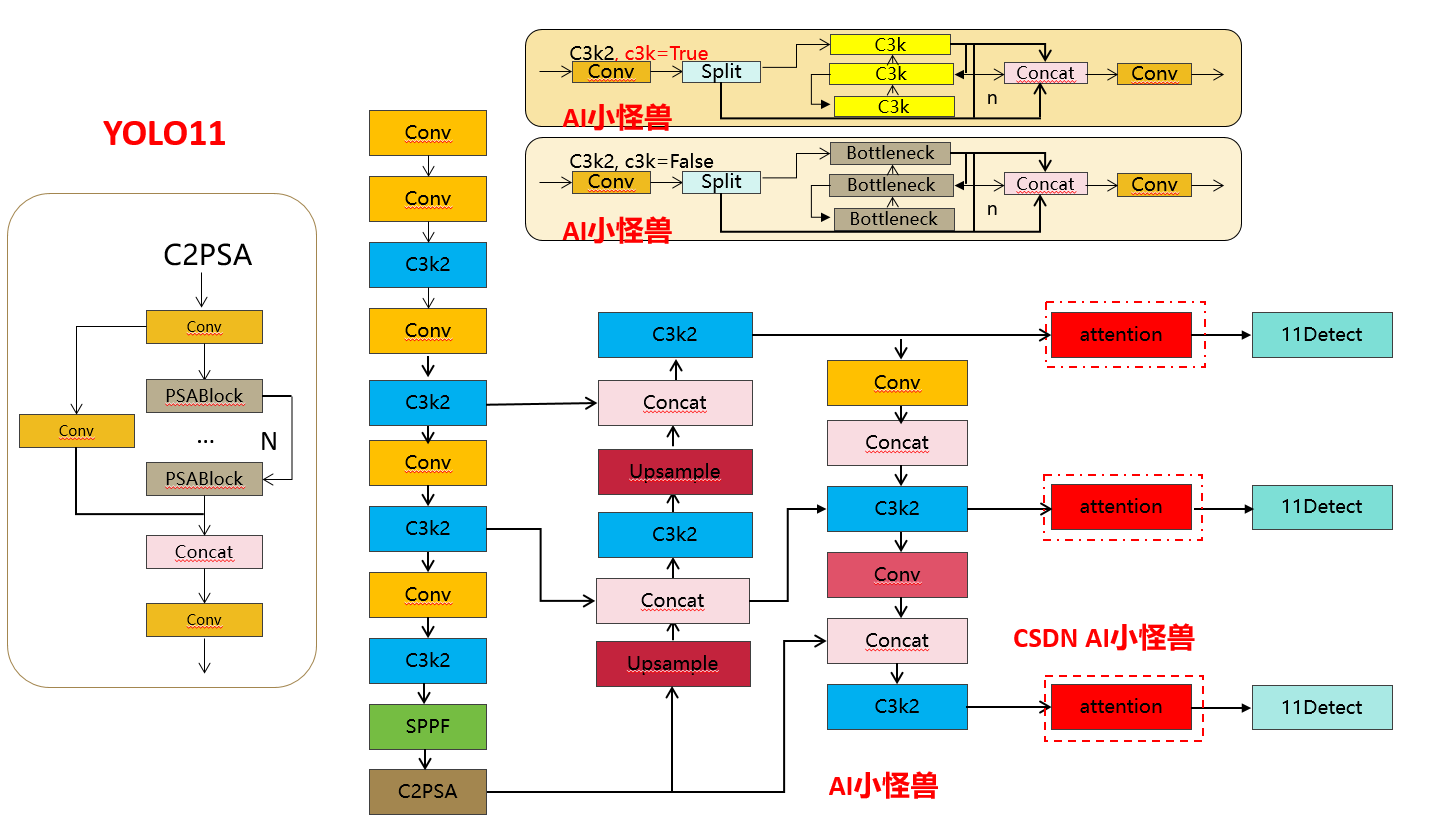
1.Введение YOLO11
Ultralytics YOLO11 — передовая, современная модель.,Он основан на успехе предыдущих выпусков YOLO.,и представляет новые функции и улучшения,для дальнейшего улучшения производительности и гибкости。YOLO11 спроектирован так, чтобы быть быстрым, точным и простым в использовании, что делает его отличным выбором для различных задач обнаружения и отслеживания объектов, сегментации экземпляров, классификации изображений и задач оценки позы.
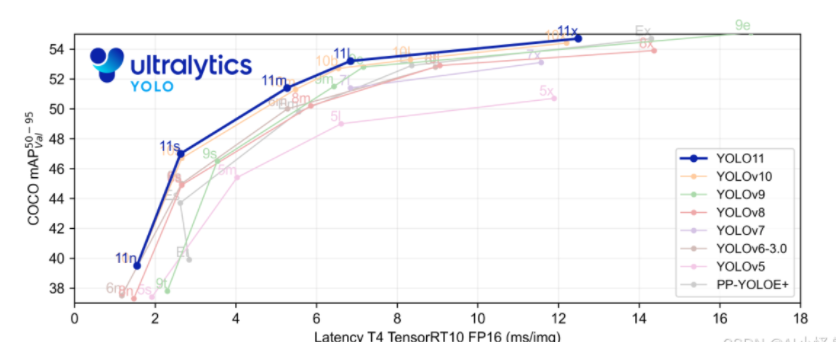

Структурная схема выглядит следующим образом:
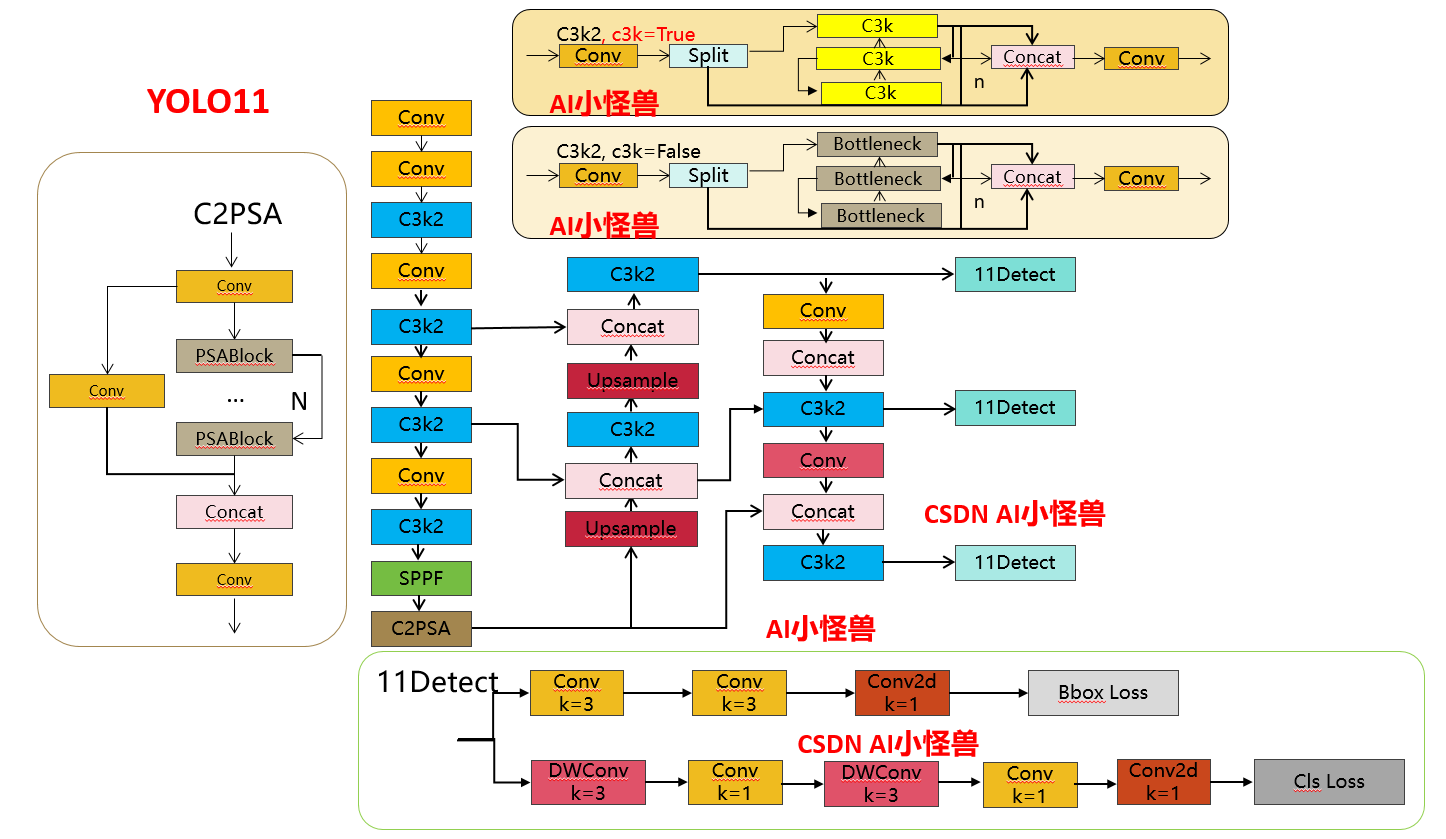
1.1 C3k2
C3k2, структурная схема следующая

C3k2,Унаследовано от классаC2f,Среди них установите False или True через c3k, чтобы решить, использовать ли C3k илиBottleneck
Код реализации ultralytics/nn/modules/block.py
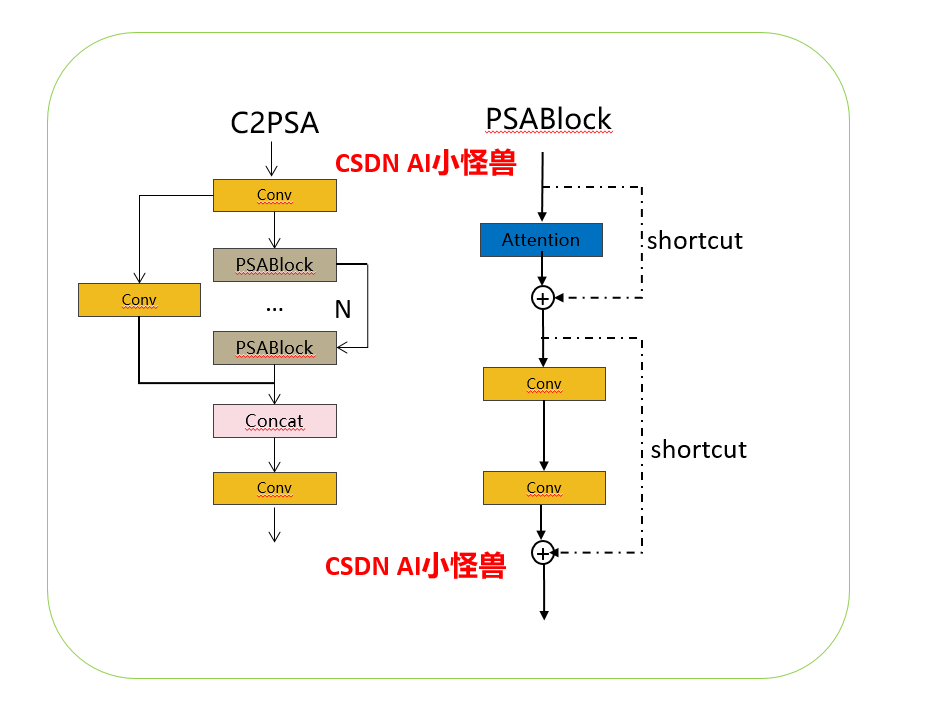
1.2 Введение в C2PSA
Опираясь на структуру PSA V10, мы реализовали C2PSA и C2fPSA и в итоге выбрали C2PSA на основе C2 (может, увеличение лучше?)
Код реализации ultralytics/nn/modules/block.py
1.3 11. Обнаружение. Введение.
Головка обнаружения классификации представляет DWConv (более легкий, обеспечивает точки улучшения для последующих вторичных инноваций), структурная схема выглядит следующим образом (отличие от V8):

Код реализации ultralytics/nn/modules/head.py
2. Как обучить набор данных NEU-DET
2.1.1 Введение в наборы данных
Вы можете использовать его, напрямую перенеся v8
2.2.2 Как тренироваться
import warnings
warnings.filterwarnings('ignore')
from ultralytics import YOLO
if __name__ == '__main__':
model = YOLO('ultralytics/cfg/models/11/yolo11-EMA_attention.yaml')
#model.load('yolov8n.pt') # loading pretrain weights
model.train(data='data/NEU-DET.yaml',
cache=False,
imgsz=640,
epochs=200,
batch=8,
close_mosaic=10,
device='0',
optimizer='SGD', # using SGD
project='runs/train',
name='exp',
)
2.2.3 Визуализация результатов обучения
YOLO11n summary (fused): 238 layers, 2,583,322 parameters, 0 gradients, 6.3 GFLOPs
Class Images Instances Box(P R mAP50 mAP50-95): 100%|██████████| 21/21 [00:07<00:00, 2.93it/s]
all 324 747 0.765 0.679 0.768 0.433
crazing 47 104 0.678 0.337 0.508 0.22
inclusion 71 190 0.775 0.705 0.79 0.398
patches 59 149 0.808 0.859 0.927 0.636
pitted_surface 61 93 0.81 0.667 0.779 0.483
rolled-in_scale 56 117 0.684 0.593 0.67 0.317
scratches 54 94 0.833 0.915 0.934 0.544
3.Введение в MSCAВнимание

бумага:https://arxiv.org/pdf/2209.08575.pdf
Аннотация: Представляем SegNeXt, простую архитектуру сверточной сети для семантической сегментации. За счет эффективности самовнимания при кодировании пространственной информации,В последнее время модели на основе Transformer доминируют в области семантической сегментации. в этой статье,Мы демонстрируем, что сверточное внимание кодирует контекстную информацию более эффективно, чем механизм самообслуживания в Transformer.。В этой статье повторно рассматриваются существующие успешные схемы сегментации и обнаруживаются несколько ключевых ингредиентов, которые помогают улучшить производительность.,тем самым побуждая насРазработана новая сверточная архитектура внимания.планSegNeXt。Без каких-либо необычных ингредиентов,Наш SegNeXt значительно улучшает предыдущую производительность в популярных тестах (Включая ADE20K, Городские пейзажи, COCO-Stuff, Pascal VOC).,Pascal Контекст и iSAID) работа по новейшим методикам. Стоит отметить, что SegNeXt работает лучше, чем EfficientNet-L2. w/ NAS-FPN и использует только 1/10 своих параметров в Паскале. VOC В тесте 2012 года он достиг 90,6% в рейтинговом списке. млн. SegNeXt достигает в среднем ~2,0% по сравнению с современными методами с такими же или меньшими вычислениями в наборе данных ad20k. млн улучшений.
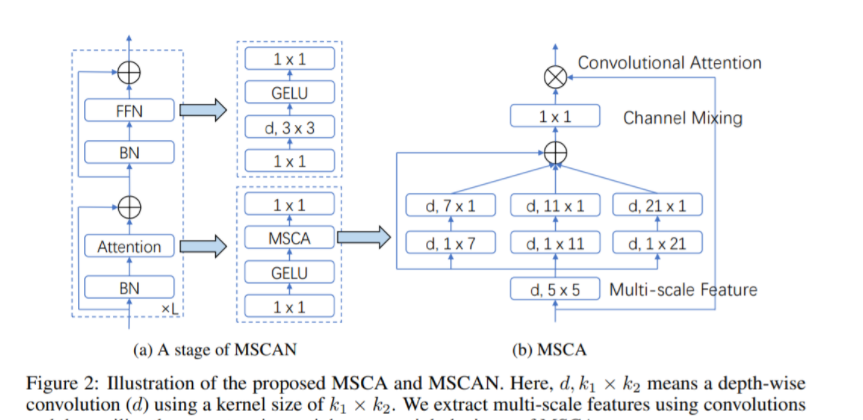
РазработанныйНовый модуль многомасштабного сверточного внимания (MSCA). Как показано на рисунке 2 Как показано на (a), MSCA состоит из трех частей: свертка глубины объединяет локальную информацию, свертка полосы глубины с несколькими ветвями фиксирует многомасштабный контекст, а свертка 1 × 1 моделирует взаимосвязь между различными каналами.
4.Как присоединиться к MSCAAttention в YOLO11
4.1 модификация Yaml
Предоставляйте разнообразные Методы модификации MSCAAttention добавляются в разные места в сети. Всегда найдется подходящий для вас набор данных.
4.1.1 yolo11-MSCAAttention.yaml
# Ultralytics YOLO 🚀, AGPL-3.0 license
# YOLO11 object detection model with P3-P5 outputs. For Usage examples see https://docs.ultralytics.com/tasks/detect
# Parameters
nc: 80 # number of classes
scales: # model compound scaling constants, i.e. 'model=yolo11n.yaml' will call yolo11.yaml with scale 'n'
# [depth, width, max_channels]
n: [0.50, 0.25, 1024] # summary: 319 layers, 2624080 parameters, 2624064 gradients, 6.6 GFLOPs
s: [0.50, 0.50, 1024] # summary: 319 layers, 9458752 parameters, 9458736 gradients, 21.7 GFLOPs
m: [0.50, 1.00, 512] # summary: 409 layers, 20114688 parameters, 20114672 gradients, 68.5 GFLOPs
l: [1.00, 1.00, 512] # summary: 631 layers, 25372160 parameters, 25372144 gradients, 87.6 GFLOPs
x: [1.00, 1.50, 512] # summary: 631 layers, 56966176 parameters, 56966160 gradients, 196.0 GFLOPs
# YOLO11n backbone
backbone:
# [from, repeats, module, args]
- [-1, 1, Conv, [64, 3, 2]] # 0-P1/2
- [-1, 1, Conv, [128, 3, 2]] # 1-P2/4
- [-1, 2, C3k2, [256, False, 0.25]]
- [-1, 1, Conv, [256, 3, 2]] # 3-P3/8
- [-1, 2, C3k2, [512, False, 0.25]]
- [-1, 1, Conv, [512, 3, 2]] # 5-P4/16
- [-1, 2, C3k2, [512, True]]
- [-1, 1, Conv, [1024, 3, 2]] # 7-P5/32
- [-1, 2, C3k2, [1024, True]]
- [-1, 1, SPPF, [1024, 5]] # 9
- [-1, 2, C2PSA, [1024]] # 10
- [-1, 1, MSCAAttention, []] # 11
# YOLO11n head
head:
- [-1, 1, nn.Upsample, [None, 2, "nearest"]]
- [[-1, 6], 1, Concat, [1]] # cat backbone P4
- [-1, 2, C3k2, [512, False]] # 14
- [-1, 1, nn.Upsample, [None, 2, "nearest"]]
- [[-1, 4], 1, Concat, [1]] # cat backbone P3
- [-1, 2, C3k2, [256, False]] # 17 (P3/8-small)
- [-1, 1, Conv, [256, 3, 2]]
- [[-1, 14], 1, Concat, [1]] # cat head P4
- [-1, 2, C3k2, [512, False]] # 20 (P4/16-medium)
- [-1, 1, Conv, [512, 3, 2]]
- [[-1, 11], 1, Concat, [1]] # cat head P5
- [-1, 2, C3k2, [1024, True]] # 23 (P5/32-large)
- [[17, 20, 23], 1, Detect, [nc]] # Detect(P3, P4, P5)
Результаты эксперимента следующие:
Исходное mAP50 составляет 0,768, а улучшенная структурная диаграмма 1 показывает, что mAP50 составляет 0,788.
YOLO11-MSCAAttention summary (fused): 247 layers, 2,677,274 parameters, 0 gradients, 6.4 GFLOPs
Class Images Instances Box(P R mAP50 mAP50-95): 100%|██████████| 21/21 [00:14<00:00, 1.46it/s]
all 324 747 0.735 0.721 0.788 0.439
crazing 47 104 0.667 0.404 0.57 0.238
inclusion 71 190 0.702 0.719 0.796 0.408
patches 59 149 0.851 0.946 0.955 0.638
pitted_surface 61 93 0.768 0.72 0.787 0.486
rolled-in_scale 56 117 0.659 0.644 0.714 0.321
scratches 54 94 0.762 0.894 0.908 0.542
4.1.2 yolo11-MSCAAttention1.yaml
# Ultralytics YOLO 🚀, AGPL-3.0 license
# YOLO11 object detection model with P3-P5 outputs. For Usage examples see https://docs.ultralytics.com/tasks/detect
# Parameters
nc: 80 # number of classes
scales: # model compound scaling constants, i.e. 'model=yolo11n.yaml' will call yolo11.yaml with scale 'n'
# [depth, width, max_channels]
n: [0.50, 0.25, 1024] # summary: 319 layers, 2624080 parameters, 2624064 gradients, 6.6 GFLOPs
s: [0.50, 0.50, 1024] # summary: 319 layers, 9458752 parameters, 9458736 gradients, 21.7 GFLOPs
m: [0.50, 1.00, 512] # summary: 409 layers, 20114688 parameters, 20114672 gradients, 68.5 GFLOPs
l: [1.00, 1.00, 512] # summary: 631 layers, 25372160 parameters, 25372144 gradients, 87.6 GFLOPs
x: [1.00, 1.50, 512] # summary: 631 layers, 56966176 parameters, 56966160 gradients, 196.0 GFLOPs
# YOLO11n backbone
backbone:
# [from, repeats, module, args]
- [-1, 1, Conv, [64, 3, 2]] # 0-P1/2
- [-1, 1, Conv, [128, 3, 2]] # 1-P2/4
- [-1, 2, C3k2, [256, False, 0.25]]
- [-1, 1, Conv, [256, 3, 2]] # 3-P3/8
- [-1, 2, C3k2, [512, False, 0.25]]
- [-1, 1, Conv, [512, 3, 2]] # 5-P4/16
- [-1, 2, C3k2, [512, True]]
- [-1, 1, Conv, [1024, 3, 2]] # 7-P5/32
- [-1, 2, C3k2, [1024, True]]
- [-1, 1, SPPF, [1024, 5]] # 9
- [-1, 2, C2PSA, [1024]] # 10
# YOLO11n head
head:
- [-1, 1, nn.Upsample, [None, 2, "nearest"]]
- [[-1, 6], 1, Concat, [1]] # cat backbone P4
- [-1, 2, C3k2, [512, False]] # 13
- [-1, 1, nn.Upsample, [None, 2, "nearest"]]
- [[-1, 4], 1, Concat, [1]] # cat backbone P3
- [-1, 2, C3k2, [256, False]] # 16 (P3/8-small)
- [-1, 1, Conv, [256, 3, 2]]
- [[-1, 13], 1, Concat, [1]] # cat head P4
- [-1, 2, C3k2, [512, False]] # 19 (P4/16-medium)
- [-1, 1, Conv, [512, 3, 2]]
- [[-1, 10], 1, Concat, [1]] # cat head P5
- [-1, 2, C3k2, [1024, True]] # 22 (P5/32-large)
- [16, 1, MSCAAttention, []] # 23
- [19, 1, MSCAAttention, []] # 24
- [22, 1, MSCAAttention, []] # 25
- [[23, 24, 25], 1, Detect, [nc]] # Detect(P3, P4, P5)
Результаты эксперимента следующие:
Исходное mAP50 составляет 0,768, а улучшенная структурная диаграмма 2 показывает, что mAP50 составляет 0,792.
YOLO11-MSCAAttention1 summary (fused): 265 layers, 2,719,066 parameters, 0 gradients, 6.6 GFLOPs
Class Images Instances Box(P R mAP50 mAP50-95): 100%|██████████| 21/21 [00:10<00:00, 1.93it/s]
all 324 747 0.746 0.713 0.792 0.436
crazing 47 104 0.627 0.42 0.521 0.219
inclusion 71 190 0.776 0.747 0.834 0.43
patches 59 149 0.811 0.919 0.934 0.637
pitted_surface 61 93 0.766 0.688 0.787 0.472
rolled-in_scale 56 117 0.808 0.65 0.767 0.36
scratches 54 94 0.692 0.851 0.906 0.5
4.1.3 yolo11-MSCAAttention2.yaml
# Ultralytics YOLO 🚀, AGPL-3.0 license
# YOLO11 object detection model with P3-P5 outputs. For Usage examples see https://docs.ultralytics.com/tasks/detect
# Parameters
nc: 80 # number of classes
scales: # model compound scaling constants, i.e. 'model=yolo11n.yaml' will call yolo11.yaml with scale 'n'
# [depth, width, max_channels]
n: [0.50, 0.25, 1024] # summary: 319 layers, 2624080 parameters, 2624064 gradients, 6.6 GFLOPs
s: [0.50, 0.50, 1024] # summary: 319 layers, 9458752 parameters, 9458736 gradients, 21.7 GFLOPs
m: [0.50, 1.00, 512] # summary: 409 layers, 20114688 parameters, 20114672 gradients, 68.5 GFLOPs
l: [1.00, 1.00, 512] # summary: 631 layers, 25372160 parameters, 25372144 gradients, 87.6 GFLOPs
x: [1.00, 1.50, 512] # summary: 631 layers, 56966176 parameters, 56966160 gradients, 196.0 GFLOPs
# YOLO11n backbone
backbone:
# [from, repeats, module, args]
- [-1, 1, Conv, [64, 3, 2]] # 0-P1/2
- [-1, 1, Conv, [128, 3, 2]] # 1-P2/4
- [-1, 2, C3k2, [256, False, 0.25]]
- [-1, 1, Conv, [256, 3, 2]] # 3-P3/8
- [-1, 2, C3k2, [512, False, 0.25]]
- [-1, 1, Conv, [512, 3, 2]] # 5-P4/16
- [-1, 2, C3k2, [512, True]]
- [-1, 1, Conv, [1024, 3, 2]] # 7-P5/32
- [-1, 2, C3k2, [1024, True]]
- [-1, 1, SPPF, [1024, 5]] # 9
- [-1, 2, C2PSA, [1024]] # 10
# YOLO11n head
head:
- [-1, 1, nn.Upsample, [None, 2, "nearest"]]
- [[-1, 6], 1, Concat, [1]] # cat backbone P4
- [-1, 2, C3k2, [512, False]] # 13
- [-1, 1, nn.Upsample, [None, 2, "nearest"]]
- [[-1, 4], 1, Concat, [1]] # cat backbone P3
- [-1, 2, C3k2, [256, False]] # 16 (P3/8-small)
- [-1, 1, MSCAAttention, []] # 17
- [-1, 1, Conv, [256, 3, 2]]
- [[-1, 13], 1, Concat, [1]] # cat head P4
- [-1, 2, C3k2, [512, False]] # 20 (P4/16-medium)
- [-1, 1, MSCAAttention, []] # 21
- [-1, 1, Conv, [512, 3, 2]]
- [[-1, 10], 1, Concat, [1]] # cat head P5
- [-1, 2, C3k2, [1024, True]] # 24 (P5/32-large)
- [-1, 1, MSCAAttention, []] # 25
- [[17, 21, 25], 1, Detect, [nc]] # Detect(P3, P4, P5)
Результаты эксперимента следующие:
Исходное mAP50 составляет 0,768, а улучшенная структурная диаграмма 3 показывает, что mAP50 составляет 0,775.
YOLO11-MSCAAttention2 summary (fused): 265 layers, 2,719,066 parameters, 0 gradients, 6.6 GFLOPs
Class Images Instances Box(P R mAP50 mAP50-95): 100%|██████████| 21/21 [00:10<00:00, 1.98it/s]
all 324 747 0.72 0.717 0.775 0.413
crazing 47 104 0.632 0.404 0.533 0.239
inclusion 71 190 0.758 0.758 0.81 0.42
patches 59 149 0.792 0.926 0.944 0.636
pitted_surface 61 93 0.78 0.71 0.786 0.496
rolled-in_scale 56 117 0.662 0.62 0.682 0.329
scratches 54 94 0.698 0.884 0.894 0.36
5. Резюме
Если есть точки улучшения, которые не очевидны или точки отказа, рекомендуется разместить точки улучшения в разных местах сети для проверки осуществимости.



Углубленный анализ переполнения памяти CUDA: OutOfMemoryError: CUDA не хватает памяти. Попыталась выделить 3,21 Ги Б (GPU 0; всего 8,00 Ги Б).

[Решено] ошибка установки conda. Среда решения: не удалось выполнить первоначальное зависание. Повторная попытка с помощью файла (графическое руководство).

Прочитайте нейросетевую модель Трансформера в одной статье

.ART Теплые зимние предложения уже открыты

Сравнительная таблица описания кодов ошибок Amap

Уведомление о последних правилах Points Mall в декабре 2022 года.

Даже новички могут быстро приступить к работе с легким сервером приложений.

Взгляд на RSAC 2024|Защита конфиденциальности в эпоху больших моделей

Вы используете ИИ каждый день и до сих пор не знаете, как ИИ дает обратную связь? Одна статья для понимания реализации в коде Python общих функций потерь генеративных моделей + анализ принципов расчета.

Используйте (внутренний) почтовый ящик для образовательных учреждений, чтобы использовать Microsoft Family Bucket (1T дискового пространства на одном диске и версию Office 365 для образовательных учреждений)

Руководство по началу работы с оперативным проектом (7) Практическое сочетание оперативного письма — оперативного письма на основе интеллектуальной системы вопросов и ответов службы поддержки клиентов

[docker] Версия сервера «Чтение 3» — создайте свою собственную программу чтения веб-текста

Обзор Cloud-init и этапы создания в рамках PVE

Корпоративные пользователи используют пакет регистрационных ресурсов для регистрации ICP для веб-сайта и активации оплаты WeChat H5 (с кодом платежного узла версии API V3)

Подробное объяснение таких показателей производительности с высоким уровнем параллелизма, как QPS, TPS, RT и пропускная способность.

Удачи в конкурсе Python Essay Challenge, станьте первым, кто испытает новую функцию сообщества [Запускать блоки кода онлайн] и выиграйте множество изысканных подарков!

[Техническая посадка травы] Кровавая рвота и отделка позволяют вам необычным образом ощипывать гусиные перья! Не распространяйте информацию! ! !

[Официальное ограниченное по времени мероприятие] Сейчас ноябрь, напишите и получите приз

Прочтите это в одной статье: Учебник для няни по созданию сервера Huanshou Parlu на базе CVM-сервера.

Cloud Native | Что такое CRD (настраиваемые определения ресурсов) в K8s?

Как использовать Cloudflare CDN для настройки узла (CF самостоятельно выбирает IP) Гонконг, Китай/Азия узел/сводка и рекомендации внутреннего высокоскоростного IP-сегмента

Дополнительные правила вознаграждения амбассадоров акции в марте 2023 г.

Можно ли открыть частный сервер Phantom Beast Palu одним щелчком мыши? Супер простой урок для начинающих! (Прилагается метод обновления сервера)

[Играйте с Phantom Beast Palu] Обновите игровой сервер Phantom Beast Pallu одним щелчком мыши

Maotouhu делится: последний доступный внутри страны адрес склада исходного образа Docker 2024 года (обновлено 1 декабря)

Кодирование Base64 в MultipartFile

5 точек расширения SpringBoot, супер практично!

Глубокое понимание сопоставления индексов Elasticsearch.

15 рекомендуемых платформ разработки с нулевым кодом корпоративного уровня. Всегда найдется та, которая вам понравится.
