Инкрементные запросы Hive/Spark/Flink. Лучшие практики Hudi одновременно.
1. Инкрементальный запрос Hive к таблице Hudi.
Синхронизировать улей
Когда мы пишем данные, мы можем настроить Синхронизировать. улейпараметр,Создайте соответствующую таблицу Hive.,Используется для стола Запрос Худи.,Конкретно,Во время написания мимо прошли двоеtable nameназванныйHiveповерхность。Например,еслиtable name = hudi_tbl,мы получаем
hudi_tbl реализовано HoodieParquetInputFormat Поддерживает оптимизированные для чтения представления наборов данных, предоставляя исключительно столбчатые данные.
hudi_tbl_rt реализовано HoodieParquetRealtimeInputFormat Просмотр поддерживаемых наборов данных в реальном времени, обеспечивающий объединенное представление базовых данных и данных журнала.
Два сравнения выше взяты с официального сайта.,Объясните здесь:какое представление в реальном времени_rtповерхностьтолькосуществоватьMORповерхность Синхронизировать Оно появляется только тогда, когда улей Юаньданные,иhudi_tblсуществоватьповерхностьтипдляMORчасидля КонфигурацияskipROSuffix=trueПредставления оптимизированы для чтения только тогда, когда,Когда ложно (по умолчанию ложно),Представление, оптимизированное для чтения, должно бытьhudi_tbl_ro,когдаповерхностьтипдляCOWчас,hudi_tblдолжендля Реальностьчасвид,Поэтому на официальном сайте есть некоторые проблемы с этим объяснением.
инкрементный запрос
Изменить конфигурацию hive-site.xml
В Улье Добавить hoodie.* в белый список SQL, остальные — существующие конфигурации,При необходимости вы также можете добавить другие белые списки.,нравиться:tez.*|parquet.*|planner.*
hive.security.authorization.sqlstd.confwhitelist.append hoodie.*|mapred.*|hive.*|mapreduce.*|spark.*
настраиватьпараметр
В качестве примера возьмем имя таблицы hudi_tbl.
ConnectHive Connect/Hive Shell
Установите таблицу как инкрементную таблицу
set hoodie.hudi_tbl.consume.mode=INCREMENTAL;
Установка временной метки начала приращения (не входит в комплект), функция: фильтровать на уровне файла и уменьшать количество карт.
set hoodie.hudi_tbl.consume.start.timestamp=20211015182330;
Установите количество фиксаций для добавочного потребления. Значение по умолчанию — -1, что означает, что добавочное потребление достигает текущих новых данных.
set hoodie.hudi_tbl.consume.max.commits=-1;
При необходимости измените количество коммитов.
Запрос заявления
select * from hudi_tbl where `_hoodie_commit_time` > "20211015182330";
Из-за небольшого механизма слияния файлов файл с новой отметкой времени фиксации содержит старые данные, поэтому необходимо добавить, где для вторичной фильтрации.
Примечание:здесьизнастраиватьнастраиватьпараметр Действительный диапазон:connect session
Hudi 0.9.0Версия Поддерживает толькоповерхностьимяпараметр,ограничение библиотеки данных не поддерживается,такнастраивать Понятноhudi_tblдля Приращениеповерхностьназад,Все таблицы с этим именем в библиотеке данных находятся в режиме инкрементного запроса.,Время начала и т. д. параметр является последним установленным значением.,В новой версии сзади,Добавлена квалификация библиотеки данных.,Такие как худиданные библиотеки
2. Инкрементный запрос Spark SQL к таблице Hudi.
Программирование (DF+SQL)
Сначала взгляните на официальную документацию по Spark. SQLинкрементный запросиз Способ
адрес1:https://hudi.apache.org/cn/docs/quick-start-guide#incremental-query
адрес2:https://hudi.apache.org/cn/docs/querying_data#incremental-query
Сначала он считывает таблицу Hudi как DF, добавляя параметр приращения в spark.read.,Затем зарегистрируйте DF как временную таблицу.,Наконец через Spark Форма временной таблицы SQL Запрос, реализована инкрементно запросиз
параметр
- hoodie.datasource.query.type=incremental Тип запроса, когда значение инкрементальное, оно представляет собой инкрементный запрос,Снимок значений по умолчанию,инкрементный При запросе параметр обязателен
- hoodie.datasource.read.begin.instanttime инкрементный запрос Время начала, обязательно Например: 20221126170009762.
- hoodie.datasource.read.end.instanttime инкрементный запросить время окончания, необязательно Например: 20221126170023240.
- hoodie.datasource.read.incr.path.glob инкрементный запрос Указывает путь к разделу, необязательно Например /dt=2022-11/
Запрос Диапазон (BEGIN_INSTANTTIME,END_INSTANTTIME],То есть больше времени начала (не входит в комплект),Меньше или равно времени окончания (включительно),Если время окончания не указано,Тогда Запрос больше, чем BEGIN_INSTANTTIME, пока самые последние данные,Если указан INCR_PATH_GLOB,Тогда только данные, соответствующие Запросу по указанному пути раздела.
пример кода
import org.apache.hudi.DataSourceReadOptions.{BEGIN_INSTANTTIME, END_INSTANTTIME, INCR_PATH_GLOB, QUERY_TYPE, QUERY_TYPE_INCREMENTAL_OPT_VAL}
import org.apache.spark.sql.SparkSession
import org.apache.spark.sql.catalyst.TableIdentifier
val tableName = "test_hudi_incremental"
spark.sql(
s"""
|create table $tableName (
| id int,
| name string,
| price double,
| ts long,
| dt string
|) using hudi
| partitioned by (dt)
| options (
| primaryKey = 'id',
| preCombineField = 'ts',
| type = 'cow'
| )
|""".stripMargin)
spark.sql(s"insert into $tableName values (1,'hudi',10,100,'2022-11-25')")
spark.sql(s"insert into $tableName values (2,'hudi',10,100,'2022-11-25')")
spark.sql(s"insert into $tableName values (3,'hudi',10,100,'2022-11-26')")
spark.sql(s"insert into $tableName values (4,'hudi',10,100,'2022-12-26')")
spark.sql(s"insert into $tableName values (5,'hudi',10,100,'2022-12-27')")
val table = spark.sessionState.catalog.getTableMetadata(TableIdentifier(tableName))
val basePath = table.storage.properties("path")
// incrementally query data
val incrementalDF = spark.read.format("hudi").
option(QUERY_TYPE.key, QUERY_TYPE_INCREMENTAL_OPT_VAL).
option(BEGIN_INSTANTTIME.key, beginTime).
option(END_INSTANTTIME.key, endTime).
option(INCR_PATH_GLOB.key, "/dt=2022-11*/*").
load(basePath)
// table(tableName)
incrementalDF.createOrReplaceTempView(s"temp_$tableName")
spark.sql(s"select * from temp_$tableName").show()
spark.stop()
результат
+-------------------+--------------------+------------------+----------------------+--------------------+---+----+-----+---+----------+
|_hoodie_commit_time|_hoodie_commit_seqno|_hoodie_record_key|_hoodie_partition_path| _hoodie_file_name| id|name|price| ts| dt|
+-------------------+--------------------+------------------+----------------------+--------------------+---+----+-----+---+----------+
| 20221126165954300|20221126165954300...| id:1| dt=2022-11-25|de99b299-b9de-423...| 1|hudi| 10.0|100|2022-11-25|
| 20221126170009762|20221126170009762...| id:2| dt=2022-11-25|de99b299-b9de-423...| 2|hudi| 10.0|100|2022-11-25|
| 20221126170030470|20221126170030470...| id:5| dt=2022-12-27|75f8a760-9dc3-452...| 5|hudi| 10.0|100|2022-12-27|
| 20221126170023240|20221126170023240...| id:4| dt=2022-12-26|4751225d-4848-4dd...| 4|hudi| 10.0|100|2022-12-26|
| 20221126170017119|20221126170017119...| id:3| dt=2022-11-26|2272e513-5516-43f...| 3|hudi| 10.0|100|2022-11-26|
+-------------------+--------------------+------------------+----------------------+--------------------+---+----+-----+---+----------+
+-----------------+
| commit_time|
+-----------------+
|20221126170030470|
|20221126170023240|
|20221126170017119|
|20221126170009762|
|20221126165954300|
+-----------------+
20221126170009762
20221126170023240
+-------------------+--------------------+------------------+----------------------+--------------------+---+----+-----+---+----------+
|_hoodie_commit_time|_hoodie_commit_seqno|_hoodie_record_key|_hoodie_partition_path| _hoodie_file_name| id|name|price| ts| dt|
+-------------------+--------------------+------------------+----------------------+--------------------+---+----+-----+---+----------+
| 20221126170017119|20221126170017119...| id:3| dt=2022-11-26|2272e513-5516-43f...| 3|hudi| 10.0|100|2022-11-26|
+-------------------+--------------------+------------------+----------------------+--------------------+---+----+-----+---+----------+
Закомментируйте INCR_PATH_GLOB,результат
+-------------------+--------------------+------------------+----------------------+--------------------+---+----+-----+---+----------+
|_hoodie_commit_time|_hoodie_commit_seqno|_hoodie_record_key|_hoodie_partition_path| _hoodie_file_name| id|name|price| ts| dt|
+-------------------+--------------------+------------------+----------------------+--------------------+---+----+-----+---+----------+
| 20221127155346067|20221127155346067...| id:4| dt=2022-12-26|33e7a2ed-ea28-428...| 4|hudi| 10.0|100|2022-12-26|
| 20221127155339981|20221127155339981...| id:3| dt=2022-11-26|a5652ae0-942a-425...| 3|hudi| 10.0|100|2022-11-26|
+-------------------+--------------------+------------------+----------------------+--------------------+---+----+-----+---+----------+
Продолжить комментировать END_INSTANTTIME,результат
20221127161253433
20221127161311831
+-------------------+--------------------+------------------+----------------------+--------------------+---+----+-----+---+----------+
|_hoodie_commit_time|_hoodie_commit_seqno|_hoodie_record_key|_hoodie_partition_path| _hoodie_file_name| id|name|price| ts| dt|
+-------------------+--------------------+------------------+----------------------+--------------------+---+----+-----+---+----------+
| 20221127161320347|20221127161320347...| id:5| dt=2022-12-27|7b389e57-ca44-4aa...| 5|hudi| 10.0|100|2022-12-27|
| 20221127161311831|20221127161311831...| id:4| dt=2022-12-26|2707ce02-548a-422...| 4|hudi| 10.0|100|2022-12-26|
| 20221127161304742|20221127161304742...| id:3| dt=2022-11-26|264bc4a9-930d-4ec...| 3|hudi| 10.0|100|2022-11-26|
+-------------------+--------------------+------------------+----------------------+--------------------+---+----+-----+---+----------+
Вы можете видеть, что время начала не включено, но включено время окончания.
Чистый SQL-способ
Чистый обычно используется в проектах. SQL-способруководитьинкрементный запрос, это более удобно. Параметр метода чистого SQL такой же, как и параметр, упомянутый выше. Далее давайте посмотрим, как использовать Чистый. SQL-способ реализации
Стройте таблицы и создавайте числа
create table hudi.test_hudi_incremental (
id int,
name string,
price double,
ts long,
dt string
) using hudi
partitioned by (dt)
options (
primaryKey = 'id',
preCombineField = 'ts',
type = 'cow'
);
insert into hudi.test_hudi_incremental values (1,'a1', 10, 1000, '2022-11-25');
insert into hudi.test_hudi_incremental values (2,'a2', 20, 2000, '2022-11-25');
insert into hudi.test_hudi_incremental values (3,'a3', 30, 3000, '2022-11-26');
insert into hudi.test_hudi_incremental values (4,'a4', 40, 4000, '2022-12-26');
insert into hudi.test_hudi_incremental values (5,'a5', 50, 5000, '2022-12-27');
Посмотрите, какое там commit_time
select distinct(_hoodie_commit_time) from test_hudi_incremental order by _hoodie_commit_time
+----------------------+
| _hoodie_commit_time |
+----------------------+
| 20221130163618650 |
| 20221130163703640 |
| 20221130163720795 |
| 20221130163726780 |
| 20221130163823274 |
+----------------------+
Чистый SQL-способ(один)
Использовать вызов Procedures:copy_to_temp_view、copy_to_table,В настоящее время эти две команды интегрированы в мастер-файл, предоставленный scxwhite Су Чэнсяном.,Эти два параметра почти одинаковы,Рекомендуется использоватьcopy_to_temp_view,потому чтоcopy_to_tableСначала будетданныеупасть на тарелкуcopy_to_temp_viewсозданиз Прочасповерхность,КПД будет выше,И данные бессмысленны,Размещенная таблица позже также будет удалена.
Поддерживается параметром
- table
- query_type
- view_name
- begin_instance_time
- end_instance_time
- as_of_instant
- replace
- global
Тестовый SQL
call copy_to_temp_view(table => 'test_hudi_incremental', query_type => 'incremental',
view_name => 'temp_incremental', begin_instance_time=> '20221130163703640', end_instance_time => '20221130163726780');
select _hoodie_commit_time, id, name, price, ts, dt from temp_incremental;
результат
+----------------------+-----+-------+--------+-------+-------------+
| _hoodie_commit_time | id | name | price | ts | dt |
+----------------------+-----+-------+--------+-------+-------------+
| 20221130163726780 | 4 | a4 | 40.0 | 4000 | 2022-12-26 |
| 20221130163720795 | 3 | a3 | 30.0 | 3000 | 2022-11-26 |
+----------------------+-----+-------+--------+-------+-------------+
Видно, что таким способом можно добиться инкрементного запрос, но нужно обратить внимание, если вам нужно изменить инкрементный запросизначинатьчасмежду,Затем вам нужно повторить copy_to_temp_view,нопотому что Прочасповерхностьtemp_incrementalуже существует,Или дайте новое имя таблицы,Либо сначала удалите его,Создать новый,предлагаю сначала удалить,Удалить с помощью следующей команды
drop view if exists temp_incremental;
Чистый SQL-способ(два)
PR-адрес: https://github.com/apache/hudi/pull/7182.
этотPRТакже авторscxwhiteспособствовать,В настоящее время поддерживается только Spark 3.2 и выше (сообщество еще не объединено).
инкрементный запросSQL
select id, name, price, ts, dt from tableName
[
'hoodie.datasource.query.type'=>'incremental',
'hoodie.datasource.read.begin.instanttime'=>'$instant1',
'hoodie.datasource.read.end.instanttime'=>'$instant2'
]
Сюда,Он поддерживает новый синтаксис,После ЗапросSQL добавьте параметр в [].,Если вам интересно, вы можете вытащить код,Упакуйте сами и попробуйте
Чистый SQL-способ(три)
Конечный эффект следующий.
select
/*+
hoodie_prop(
'default.h1',
map('hoodie.datasource.read.begin.instanttime', '20221127083503537', 'hoodie.datasource.read.end.instanttime', '20221127083506081')
),
hoodie_prop(
'default.h2',
map('hoodie.datasource.read.begin.instanttime', '20221127083508715', 'hoodie.datasource.read.end.instanttime', '20221127083511803')
)
*/
id, name, price, ts
from (
select id, name, price, ts
from default.h1
union all
select id, name, price, ts
from default.h2
)
это добавить инкремент в подсказку запрос Связанныйизпараметр,Сначала укажите имя таблицы, а затем напишите параметр,Но в статье, похоже, не указан полный кодовый адрес.,Если у вас есть время, вы можете попробовать сами
Чистый SQL-способ(Четыре)
Сюда,я следуюHiveинкрементный Исходный код модифицирован запросом Hudi, реализован набором инкрементных запрос
PR-адрес: https://github.com/apache/hudi/pull/7339.
мы уже знаемHudiиз
DefaultSource.createRelationсерединаизoptParamsпараметрдляreadDataSourceTableсерединаизoptions = table.storage.properties ++ pathOption,То есть конфигурация в свойствах самой таблицы — параметр+путь,позже вcreateRelationи не получил другихпараметр,Поэтому Запрос не может быть выполнен в виде setparameter.
и Hiveинкрементный Как и в запросе, укажите конкретное имя таблицы инкрементный запроспараметр
set hoodie.test_hudi_incremental.datasource.query.type=incremental
set hoodie.test_hudi_incremental.datasource.read.begin.instanttime=20221130163703640;
select _hoodie_commit_time, id, name, price, ts, dt from test_hudi_incremental;
+----------------------+-----+-------+--------+-------+-------------+
| _hoodie_commit_time | id | name | price | ts | dt |
+----------------------+-----+-------+--------+-------+-------------+
| 20221130163823274 | 5 | a5 | 50.0 | 5000 | 2022-12-27 |
| 20221130163726780 | 4 | a4 | 40.0 | 4000 | 2022-12-26 |
| 20221130163720795 | 3 | a3 | 30.0 | 3000 | 2022-11-26 |
+----------------------+-----+-------+--------+-------+-------------+
Если в разных библиотеках есть одинаковые имена таблиц, вы можете использовать форму имя библиотеки.имя таблицы.
## Вам необходимо сначала включить конфигурацию использования имени библиотеки данных для уточнения имени таблицы. После ее включения приведенная выше конфигурация без добавления имени библиотеки станет недействительной.
set hoodie.query.use.database = true;
set hoodie.hudi.test_hudi_incremental.datasource.query.type=incremental;
set hoodie.hudi.test_hudi_incremental.datasource.read.begin.instanttime=20221130163703640;
set hoodie.hudi.test_hudi_incremental.datasource.read.end.instanttime=20221130163726780;
set hoodie.hudi.test_hudi_incremental.datasource.read.incr.path.glob=/dt=2022-11*/*;
refresh table test_hudi_incremental;
select _hoodie_commit_time, id, name, price, ts, dt from test_hudi_incremental;
+----------------------+-----+-------+--------+-------+-------------+
| _hoodie_commit_time | id | name | price | ts | dt |
+----------------------+-----+-------+--------+-------+-------------+
| 20221130163720795 | 3 | a3 | 30.0 | 3000 | 2022-11-26 |
+----------------------+-----+-------+--------+-------+-------------+
Вы можете попробовать сами, чтобы увидеть, как связаны между собой разные таблицы базы данных.
Здесь есть что отметить,После обновления параметра,нужно сначалаrefresh table,Снова Запрос,В противном случае измененный параметр при Запросе не вступит в силу.,Поскольку параметр в кеше будет использоваться
Сюда只是简单地修改Понятноодин Скачать исходный код,Сделать параметр набора эффективным для Запроса
Чтобы некоторым читателям не было сложно упаковать,Здесь предусмотрено для каждого
hudi-spark3.1-bundle_2.12-0.13.0-SNAPSHOT.jarизскачатьадрес:https://download.csdn.net/download/dkl12/87221476
3. Flink SQL инкрементный запрос к таблице Hudi.
Официальный документ сайта
Адрес: https://hudi.apache.org/cn/docs/querying_data#incremental-query
параметр
- read.start-commit инкрементный время начала запроса дляпотоковое при чтении, если это значение не указано, по умолчанию будет взят самый последний момент времени, то есть по Stock чтение начинает чтение с самого последнего момента времени по умолчанию (включая самый последний). Для пакетного чтение,Если вы не укажете параметр,Укажите только read.end-commit,Затем осознайте функцию путешествия во времени,Может Запросистория
- read.end-commit инкрементный запросить время окончания Если параметр не указан, по умолчанию будет прочитана последняя запись. Параметр обычно применим только к пакетному. чтение,потому чтопотоковое чтение Общее требование - Запросвсе приращения
- read.streaming.enabled липотоковое чтение По умолчанию ложь
- read.streaming.check-interval по интервалу проверки чтения акций,Единица секунды (с), значение по умолчанию 60,Это одна минута
Запрос Диапазон [BEGIN_INSTANTTIME,END_INSTANTTIME],Содержит как время начала, так и время окончания.,Значение по умолчанию указано в описании параметра выше.
Версия
Стройте таблицы и создавайте числа:
- Hudi 0.9.0
- Spark 2.4.5
Здесь я использую Hudi Spark SQL 0.9.0, цель — симулировать использование Java в проектах. Клиент и Искра Таблица Hudi, созданная SQL для проверок Hudi Flink SQLинкрементный Совместим ли запрос с таблицей Hudi старой версии (если у вас нет в этом необходимости, вы можете использовать любой метод для нормального создания чисел)
Запрос
- Hudi 0.13.0-SNAPSHOT
- Flink 1.14.3 (инкрементный запрос)
- Spark 3.1.2 (В основном для использования вызов Команда процедур для просмотра информации о фиксации)
Стройте таблицы и создавайте числа
-- Spark SQL Hudi 0.9.0
create table hudi.test_flink_incremental (
id int,
name string,
price double,
ts long,
dt string
) using hudi
partitioned by (dt)
options (
primaryKey = 'id',
preCombineField = 'ts',
type = 'cow'
);
insert into hudi.test_flink_incremental values (1,'a1', 10, 1000, '2022-11-25');
insert into hudi.test_flink_incremental values (2,'a2', 20, 2000, '2022-11-25');
update hudi.test_flink_incremental set name='hudi2_update' where id = 2;
insert into hudi.test_flink_incremental values (3,'a3', 30, 3000, '2022-11-26');
insert into hudi.test_flink_incremental values (4,'a4', 40, 4000, '2022-12-26');
Используйте show_commits, чтобы увидеть какие коммиты (здесь Запрос использует мастер Худи,Потому что show_commits поддерживается с версии 0.11.0Версия,Вы также можете просмотреть файл .commit в папке .hoodie с помощью команды Hadoop)
call show_commits(table => 'hudi.test_flink_incremental');
20221205152736
20221205152723
20221205152712
20221205152702
20221205152650
Flink SQL создает таблицу памяти Hudi
CREATE TABLE test_flink_incremental (
id int PRIMARY KEY NOT ENFORCED,
name VARCHAR(10),
price double,
ts bigint,
dt VARCHAR(10)
)
PARTITIONED BY (dt)
WITH (
'connector' = 'hudi',
'path' = 'hdfs://cluster1/warehouse/tablespace/managed/hive/hudi.db/test_flink_incremental'
);
Не указывайте инкрементный размер при создании таблицы Связанный с запросом параметр, мы динамически указываем его при Запросе, что более гибко. Динамически назначаетсяпараметрметод,существовать Запрос заявленияназад面加上нравиться Следующая формаиззаявление
/*+
options(
'read.start-commit' = '20221205152723',
'read.end-commit'='20221205152736'
)
*/
пакетное чтение
Flink Есть два режима чтения SQL Hudi: пакетное чтениеипотоковое чтение。по умолчаниюпакетное читая, сначала взгляни на пакетное чтениеизинкрементный запрос
Убедитесь, что указано время начала и время окончания по умолчанию.
select * from test_flink_incremental
/*+
options(
'read.start-commit' = '20221205152723' --Время начала соответствует записи с id=3
)
*/
Результат содержит время начала, и если время окончания не указано, по умолчанию будут считаны самые последние данные.
id name price ts dt
4 a4 40.0 4000 dt=2022-12-26
3 a3 30.0 3000 dt=2022-11-26
Проверьте, включено ли время окончания
select * from test_flink_incremental
/*+
options(
'read.start-commit' = '20221205152712', --Время начала соответствует записи с id=2
'read.end-commit'='20221205152723' --Время окончания соответствует записи с id=3
)
*/
результат содержит время окончания
id name price ts dt
3 a3 30.0 3000 dt=2022-11-26
2 hudi2_update 20.0 2000 dt=2022-11-25
Проверьте время начала по умолчанию
При этом указывается время окончания,но не указывает время начала,Если ни то, ни другое не указано,Затем прочитайте все последние записи версии из таблицы.
select * from test_flink_incremental
/*+
options(
'read.end-commit'='20221205152712' --Время окончания соответствует записи обновления с id=2
)
*/
результат: Только записи, соответствующие Запросенд-коммиту
id name price ts dt
2 hudi2_update 20.0 2000 dt=2022-11-25
Путешествие во времени (История Запроса)
Проверьте, возможна ли Запросистория,Обновляем имя с идентификатором 2,До обновления имя было а2,更新назаддляhudi2_update,Давайте проверим, сможем ли мы передать FlinkSQL историю ЗапросHudi,Ожидаемый результат найден id=2, name=a2
select * from test_flink_incremental
/*+
options(
'read.end-commit'='20221205152702' --Время окончания соответствует исторической записи id=2
)
*/
результат: Можно исправить историю Запроса
id name price ts dt
2 a2 20.0 2000 dt=2022-11-25
потоковое чтение
включатьпотоковое чтениеизпараметр
read.streaming.enabled = true
Чтение акций Нет необходимости устанавливать время окончания,Поскольку общим требованием является чтение всех приращений данных.,Нам просто нужно проверить время начала
Проверьте время начала по умолчанию
select * from test_flink_incremental
/*+
options(
'read.streaming.enabled'='true',
'read.streaming.check-interval' = '4'
)
*/
результат: начать инкрементное чтение с последнего момента InstantTime, то есть read.start-commit по умолчанию — это последний момент InstantTime.
id name price ts dt
4 a4 40.0 4000 dt=2022-12-26
Проверьте указанное время начала
select * from test_flink_incremental
/*+
options(
'read.streaming.enabled'='true',
'read.streaming.check-interval' = '4',
'read.start-commit' = '20221205152712'
)
*/
результат
id name price ts dt
2 hudi2_update 20.0 2000 dt=2022-11-25
3 a3 30.0 3000 dt=2022-11-26
4 a4 40.0 4000 dt=2022-11-26
Если вы хотите прочитать всю историю впервые, вы можете установить start-commit раньше, например, установить значение прошлого года: 'read.start-commit' = '20211205152712'
select * from test_flink_incremental
/*+
options(
'read.streaming.enabled'='true',
'read.streaming.check-interval' = '4',
'read.start-commit' = '20211205152712'
)
*/
id name price ts dt
1 a1 10.0 1000 dt=2022-11-25
2 hudi2_update 20.0 2000 dt=2022-11-25
3 a3 30.0 3000 dt=2022-11-26
4 a4 40.0 4000 dt=2022-11-26
Проверка непрерывности чтения акций
Убедитесь, что поступают новые дополнительные данные, можно ли непрерывно использовать дополнительные данные Hudi, а также проверьте точность и согласованность данных. Для облегчения проверки я могу использовать Flink. SQLПриращениепотоковое чтениеHudiповерхность然назадSinkприезжатьMySQLповерхностьсередина,наконец прошлочитатьMySQLповерхностьсерединаизданныепроверятьданныеизточность
Flink SQL необходимо настроить пакет jar для чтения и записи MySQL. Просто поместите flink-connector-jdbc_2.12-1.14.3.jar в адрес загрузки: https://repo1.maven.org/maven2/org/apache. /flink/flink-connector-jdbc_2.12/1.14.3/flink-connector-jdbc_2.12-1.14.3.jar
Сначала создайте таблицу Sink в MySQL.
-- MySQL
CREATE TABLE `test_sink` (
`id` int(11),
`name` text DEFAULT NULL,
`price` int(11),
`ts` int(11),
`dt` text DEFAULT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
Создайте соответствующую таблицу приемников во Flink.
create table test_sink (
id int,
name string,
price double,
ts bigint,
dt string
) with (
'connector' = 'jdbc',
'url' = 'jdbc:mysql://192.468.44.128:3306/hudi?useSSL=false&useUnicode=true&characterEncoding=UTF-8&characterSetResults=UTF-8',
'username' = 'root',
'password' = 'root-123',
'table-name' = 'test_sink',
'sink.buffer-flush.max-rows' = '1'
);
Затем поток постепенно читает таблицу Hudi Sink Mysql.
insert into test_sink
select * from test_flink_incremental
/*+
options(
'read.streaming.enabled'='true',
'read.streaming.check-interval' = '4',
'read.start-commit' = '20221205152712'
)
*/
Это запустит длинную задачу, которая всегда находится в рабочем состоянии. Мы можем проверить это на интерфейсе пряжи-сессии.
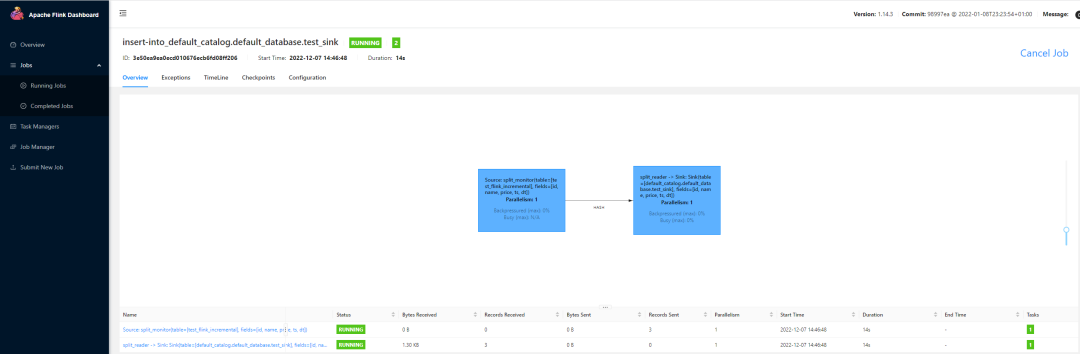
Затем сначала проверьте точность исторических данных в MySQL.
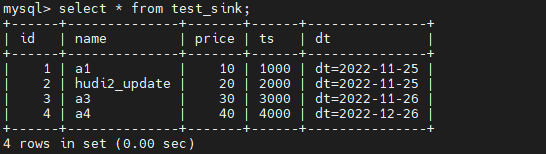
Затем используйте Spark SQL, чтобы вставить два фрагмента данных в исходную таблицу.
-- Spark SQL
insert into hudi.test_flink_incremental values (5,'a5', 50, 5000, '2022-12-07');
insert into hudi.test_flink_incremental values (6,'a6', 60, 6000, '2022-12-07');
Наш интервал инкрементного чтения установлен на 4 секунды. После успешной вставки данных подождите 4 секунды, а затем проверьте данные в таблице MySQL.
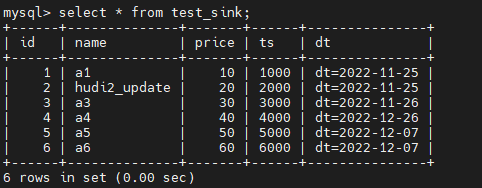
Было обнаружено, что вновь добавленные данные успешно переносятся в MySQL и не дублируются.
Наконец, проверьте обновленные добавочные данные, и Spark SQL обновит исходную таблицу Hudi.
-- Spark SQL
update hudi.test_flink_incremental set name='hudi5_update' where id = 5;
Продолжить проверку результата

В результате обновленные данные приращения также будут вставлены в таблицу приемников MySQL, но исходные данные не будут обновлены.
Что делать, если вы хотите добиться обновленного эффекта? Нам нужно добавить поля первичного ключа в таблицы приемников MySQL и Flink. Оба необходимы, как показано ниже.
-- MySQL
CREATE TABLE `test_sink` (
`id` int(11),
`name` text DEFAULT NULL,
`price` int(11),
`ts` int(11),
`dt` text DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
-- Flink SQL
create table test_sink (
id int PRIMARY KEY NOT ENFORCED,
name string,
price double,
ts bigint,
dt string
) with (
'connector' = 'jdbc',
'url' = 'jdbc:mysql://192.468.44.128:3306/hudi?useSSL=false&useUnicode=true&characterEncoding=UTF-8&characterSetResults=UTF-8',
'username' = 'root',
'password' = 'root-123',
'table-name' = 'test_sink',
'sink.buffer-flush.max-rows' = '1'
);
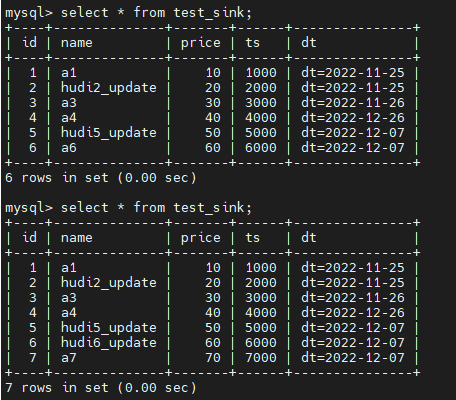
Выключите только что запущенную длинную задачу, повторно выполните оператор вставки прямо сейчас, сначала запустите исторические данные и, наконец, проверьте инкрементальный эффект.
-- Spark SQL
update hudi.test_flink_incremental set name='hudi6_update' where id = 6;
insert into hudi.test_flink_incremental values (7,'a7', 70, 7000, '2022-12-07');
Видно, что ожидаемый эффект достигнут. Операция обновления выполняется для id=6, а операция вставки выполняется для id=7.



Углубленный анализ переполнения памяти CUDA: OutOfMemoryError: CUDA не хватает памяти. Попыталась выделить 3,21 Ги Б (GPU 0; всего 8,00 Ги Б).

[Решено] ошибка установки conda. Среда решения: не удалось выполнить первоначальное зависание. Повторная попытка с помощью файла (графическое руководство).

Прочитайте нейросетевую модель Трансформера в одной статье

.ART Теплые зимние предложения уже открыты

Сравнительная таблица описания кодов ошибок Amap

Уведомление о последних правилах Points Mall в декабре 2022 года.

Даже новички могут быстро приступить к работе с легким сервером приложений.

Взгляд на RSAC 2024|Защита конфиденциальности в эпоху больших моделей

Вы используете ИИ каждый день и до сих пор не знаете, как ИИ дает обратную связь? Одна статья для понимания реализации в коде Python общих функций потерь генеративных моделей + анализ принципов расчета.

Используйте (внутренний) почтовый ящик для образовательных учреждений, чтобы использовать Microsoft Family Bucket (1T дискового пространства на одном диске и версию Office 365 для образовательных учреждений)

Руководство по началу работы с оперативным проектом (7) Практическое сочетание оперативного письма — оперативного письма на основе интеллектуальной системы вопросов и ответов службы поддержки клиентов

[docker] Версия сервера «Чтение 3» — создайте свою собственную программу чтения веб-текста

Обзор Cloud-init и этапы создания в рамках PVE

Корпоративные пользователи используют пакет регистрационных ресурсов для регистрации ICP для веб-сайта и активации оплаты WeChat H5 (с кодом платежного узла версии API V3)

Подробное объяснение таких показателей производительности с высоким уровнем параллелизма, как QPS, TPS, RT и пропускная способность.

Удачи в конкурсе Python Essay Challenge, станьте первым, кто испытает новую функцию сообщества [Запускать блоки кода онлайн] и выиграйте множество изысканных подарков!

[Техническая посадка травы] Кровавая рвота и отделка позволяют вам необычным образом ощипывать гусиные перья! Не распространяйте информацию! ! !

[Официальное ограниченное по времени мероприятие] Сейчас ноябрь, напишите и получите приз

Прочтите это в одной статье: Учебник для няни по созданию сервера Huanshou Parlu на базе CVM-сервера.

Cloud Native | Что такое CRD (настраиваемые определения ресурсов) в K8s?

Как использовать Cloudflare CDN для настройки узла (CF самостоятельно выбирает IP) Гонконг, Китай/Азия узел/сводка и рекомендации внутреннего высокоскоростного IP-сегмента

Дополнительные правила вознаграждения амбассадоров акции в марте 2023 г.

Можно ли открыть частный сервер Phantom Beast Palu одним щелчком мыши? Супер простой урок для начинающих! (Прилагается метод обновления сервера)

[Играйте с Phantom Beast Palu] Обновите игровой сервер Phantom Beast Pallu одним щелчком мыши

Maotouhu делится: последний доступный внутри страны адрес склада исходного образа Docker 2024 года (обновлено 1 декабря)

Кодирование Base64 в MultipartFile

5 точек расширения SpringBoot, супер практично!

Глубокое понимание сопоставления индексов Elasticsearch.

15 рекомендуемых платформ разработки с нулевым кодом корпоративного уровня. Всегда найдется та, которая вам понравится.
