Иллюстрация на 10 000 слов | Углубленный взгляд на мультиплексирование ввода-вывода
Привет всем, меня зовут «Юньшу Программирование». Сегодня мы поговорим о мультиплексировании ввода-вывода.
Статья была впервые опубликована на WeChat Официальный аккаунт:Юньшу Программирование Подпишитесь на официальный аккаунт, чтобы получить: 1. Обмен проектами от крупных производителей 2. Обмен различными техническими принципами 3. Рекомендация внутри отдела
Предисловие
через фронтиз Мы уже знаем статью「данные Бао КонгHTTPслой->TCPслой->IPслой->сетевая карта->Интернет->глазизлокальный сервер」а также「данные Как посылка идет от сетевого кабеля к процессу?,существоватьпо заявкеиспользовать」с участиемиз Знание。 В этой статье мы продолжим знакомить вас с различными деталями сетевого программирования и принципами мультиплексирования ввода-вывода.
Благодаря этой статье вы сможете узнать:
- Разница, преимущества и недостатки между блокирующим и неблокирующим вводом-выводом;
- Принцип мультиплексирования ввода-вывода и почему это высокая производительность;
- выберите принцип、Преимущества и недостатки;
- принцип опроса, преимущества и недостатки;
- Электронный опрос, преимущества и недостатки
- Являются ли select, poll и epoll синхронными или асинхронными операциями ввода-вывода?
- Различия между триггером epoll по краю и горизонтальным триггером, подходящие сценарии
- Почему неблокирующий ввод-вывод лучше всего подходит для сетевого программирования Linux?
- Определения событий ввода-вывода в общей сети Linux
1. Начните с сетевого звонка
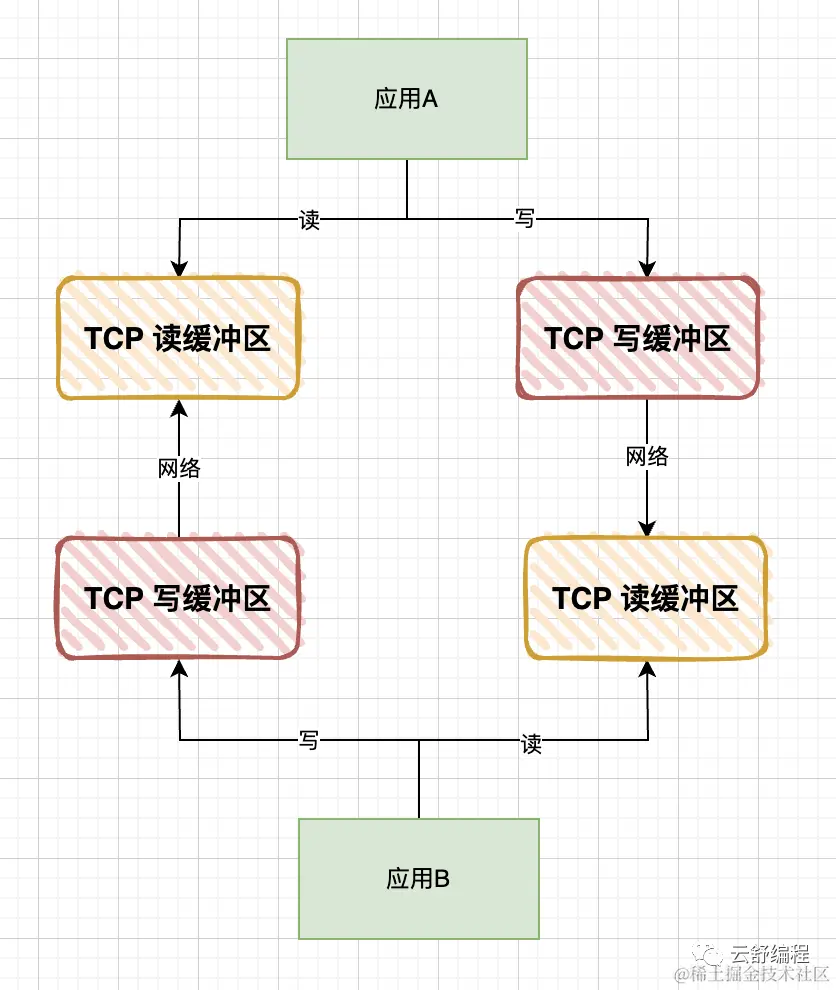
Предположим, что приложение A хочет запросить у приложения B получение данных, тогда оно выполнит следующие шаги:
- Приложение A записывает сообщение запроса в свой собственный буфер записи TCP.
- Сообщение запроса приложения A достигает буфера чтения TCP приложения B через сетевой кабель.
- После того как приложение B получает сообщение запроса, оно выполняет обработку бизнес-логики.
- После завершения обработки бизнес-логики приложения B ответное сообщение записывается в собственный буфер записи TCP, а затем достигает буфера чтения TCP приложения A через сетевой кабель.
Теперь сосредоточимся на приложении А. После того, как приложение А отправит запрос, оно начнет вызывать системные вызовы для чтения данных из буфера чтения TCP. Поскольку невозможно узнать, когда приложение Б вернет данные ответа, то возникнут две ситуации:
- Приложение B отвечает очень быстро. Когда приложение A читает буфер TCP, оно уже вернуло данные ответа. Тогда приложение А сможет успешно получить данные, и все будут счастливы.
- Приложение B отвечает медленно. Когда приложение A читает буфер TCP, оно еще не вернуло данные ответа. В настоящее время операционная система стоит перед двумя вариантами: Вариант 1: заблокируйте текущий вызов приложения A и подождите, пока приложение B достигнет буфера, прежде чем повторно активировать приложение A. Вариант 2. Сообщите приложению А, что ваш запрос еще не поступил и вы можете запросить его позже.
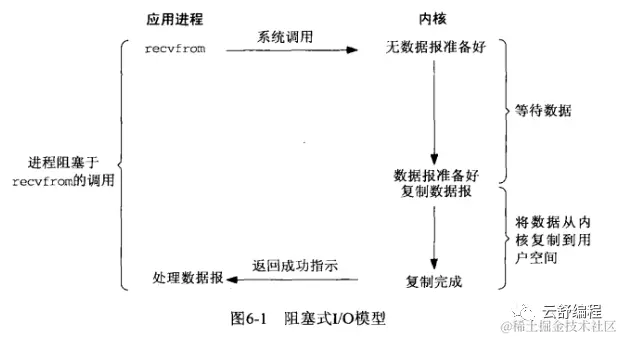
2. Блокировка ввода-вывода
Первый вариант — это то, что мы часто называем блокировкой ввода-вывода. Академическая точка зрения: когда пользовательский процесс инициирует вызов чтения, если данные ядра не готовы, операционная система завершит процесс и перейдет в состояние ожидания (без потребления ресурсов ЦП). Процесс не будет разбужен до тех пор, пока данные не будут готовы или не произойдет ошибка. Весь процесс показан на рисунке:
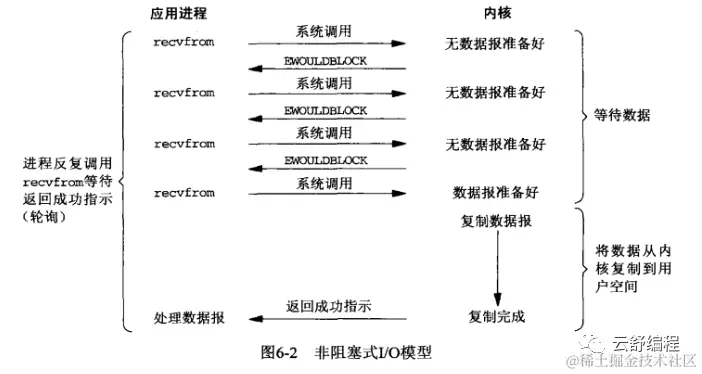
3. Неблокирующий ввод-вывод
Второй вариант — это то, что мы часто называем неблокирующим вводом-выводом. Академическая точка зрения: когда пользовательский процесс инициирует вызов чтения, если данные ядра не готовы, операционная система вернет ошибку EAGAIN. На основании этой ошибки пользовательский процесс может решить, что данные не готовы, и может запросить. еще раз позже. Если ядро подготавливает данные во время опроса, пользовательский процесс может скопировать данные в пространство пользователя. Весь процесс показан на рисунке:
4. Мультиплексирование ввода-вывода
Блокирующий и неблокирующий ввод-вывод — наиболее распространенные ранние модели сетевого программирования, но у них есть фатальные недостатки. Рассмотрим следующий сценарий:
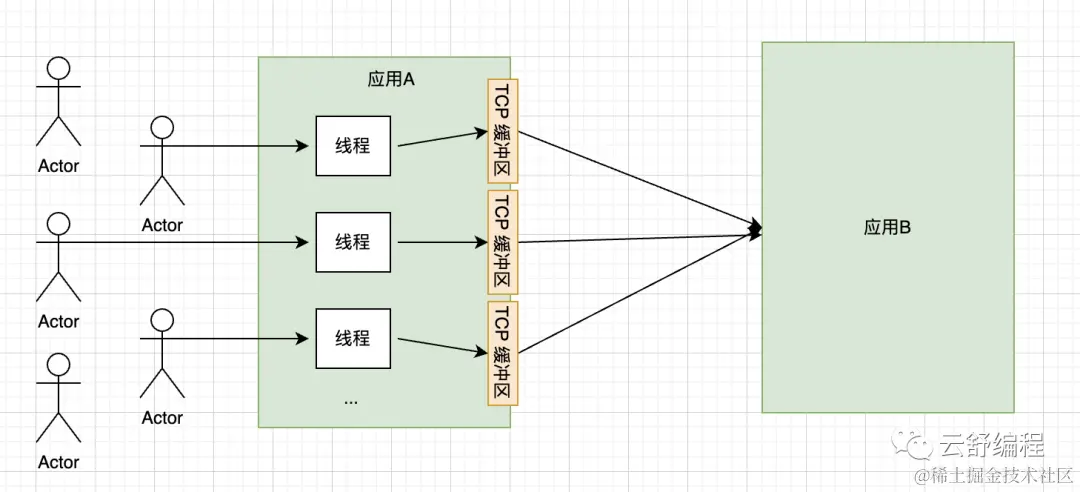
- Каждый запрос пользователя должен обслуживаться отдельным пользователем.,В то же время приложению B необходимо запросить завершение бизнес-логики.
- Так как мы не знаем, когда вернутся данные ответа приложения Biz.,Тогда вы можете выбрать только блокирующий или неблокирующий ввод-вывод для опроса.
Однако блокировка ввода-вывода приведет к приостановке потока, а неблокирующий ввод-вывод приведет к тому, что поток останется в состоянии опроса. Обе ситуации предотвратят освобождение или повторное использование потока. По мере увеличения количества пользовательских запросов приложению A приходится создавать больше потоков. Однако для операционной системы существует верхний предел количества создаваемых потоков, и слишком большое количество потоков приведет к увеличению времени на переключение потоков. В серьезных случаях система может зависнуть и не сможет предоставлять внешние службы. Это также известная проблема C10K.
Чтобы решить эту проблему, люди придумали план: использовать один или несколько потоков для мониторинга нескольких сетевых запросов и позволить им завершить этап подготовки данных. Когда данные готовы, соответствующий поток назначается для чтения данных, поэтому небольшое количество потоков можно использовать для обслуживания большого количества сетевых запросов. Это мультиплексирование ввода-вывода.
❝ Повторное использование мультиплексирования ввода-вывода относится к повторному использованию потоков, а не соединений ввода-вывода; цель состоит в том, чтобы позволить небольшому количеству потоков обрабатывать несколько соединений ввода-вывода. ❞
Мультиплексирование ввода-вывода в основном реализуется с помощью следующих функций: select, poll и epoll.
select
select — самая ранняя функция в Linux, поддерживающая мультиплексирование ввода-вывода.
выберите принцип
Мониторинг нескольких событий ввода-вывода можно выполнить с помощью функции выбора.
#define __FD_SETSIZE 1024
typedef struct {
unsigned long fds_bits[__FD_SETSIZE / (8 * sizeof(long))];
} __kernel_fd_set;
struct timeval {
time_t tv_sec; /* seconds */
suseconds_t tv_usec; /* microseconds */
};
//Объявление функции
int select(int nfds, fd_set *readfds, fd_set *writefds, fd_set *exceptfds, struct timeval *timeout);Параметры функции:
- readfds: ядро определяет, доступен ли для чтения сбор данных изIOда. Если вы хотите, чтобы ядро помогало определять, доступен ли ввод-вывод для чтения,Вам необходимо вручную добавить дескриптор файла в сбор.
- writefds: ядро определяет, доступен ли для записи сбор данных изIOда. То же, что и readfds, необходимо добавить вручную.
- кроме fds: ядро определяет, является ли сбор данных изIOда ненормальным. То же, что и readfds, необходимо добавить вручную.
- nfds: наибольшее значение файлового дескриптора среди трех вышеперечисленных. + 1, например собиратьда{0,1,4}, затем maxfd то есть 5
- timeout: период ожидания, в течение которого пользователь может вызвать select.
- Установите значение NULL, что указывает на отсутствие I/O происходит событие, тогда select Продолжайте ждать.
- Установите ненулевое значение, что означает ожидание в течение фиксированного периода времени перед возвратом из вызова блокировки выбора.
- установлен на 0 означает отсутствие ожидания и возврат произойдет сразу после завершения обнаружения.
Возвращаемое значение функции:
- Больше 0: успех,Возвращает общее количество готовых изIO в сборе.
- Равно -1: вызов не выполнен.
- Равно 0: нет готового ввода-вывода.
Как видно из приведенного выше объявления функции выбора, fd_set по сути является массивом. Чтобы облегчить работу с массивом, операционная система предоставляет следующие функции:
// Удалить файловый дескриптор fd из setсобирать
void FD_CLR(int fd, fd_set *set);
// Определите, находится ли дескриптор файла fdдасуществоватьsetсобирать в
int FD_ISSET(int fd, fd_set *set);
// Добавить дескриптор файла fd в setсобирать
void FD_SET(int fd, fd_set *set);
// вставь сетсобирать, Все файловые дескрипторы, соответствующие флагу из, установлены в 0.
void FD_ZERO(fd_set *set); выберите Недостатки
- Ограничение длины fd_set: поскольку fd_set по сути является массивом, а операционная система ограничивает его длину, она может принимать только значения файлового дескриптора в пределах 1024.
- выбрать функцию из возвращаемого значения daint,в результате каждого возврата,Пользователь должен вручную определить, какие значения в сборе были изменены на 1 (изменение на 1из означает, что генерируется событие готовности ввода-вывода).
- каждый звонок выберите, все должно быть fd собирать Копирование из пользовательского режима в режим ядра,Когда много ФД,Накладные расходы огромны.
- Поскольку fd_set по сути является массивом, ядро линейно сканирует весь массив. fd_set, определяет, есть ли событие готовности ввода-вывода, что приводит к мониторингу дескриптора fd По мере роста числа его производительность будет линейно снижаться.
poll
Poll — еще одна технология мультиплексирования ввода-вывода, появившаяся после выбора. По сравнению с select, он использует другой метод хранения файловых дескрипторов, а также устраняет ограничение на количество файловых дескрипторов.
принцип опроса
struct pollfd {
int fd; /* file descriptor */
short events; /* events to look for */
short revents; /* events returned */
};
int poll(struct pollfd *fds, unsigned long nfds, int timeout); Параметры функции:
- fds:struct Массив типа pollfd, Сохраняет дескриптор файла, который необходимо обнаружить, struct pollfd состоит из трех членов:
- fd: дескриптор файла, делегированный для обнаружения ядра.
- события: делегированное обнаружение ядра изfdсобытие (вход、выход、ошибка),Каждое событие имеет несколько значений
- revents: это исходящий параметр,данные записываются ядром,Сохраните результаты после обнаружения ядра
- nfds: описывает размер массива fds.
- timeout: Укажите продолжительность блокировки функции опроса
- -1: всегда заблокировано,Пока не готов изолятор обнаружения изIOсобытия,Затем функция разблокировки возвращает
- 0: нет блокировки,Независимо от того, готова ли сбор данных об обнаружении из IOсобытия.,Функция немедленно возвращает значение
- Больше 0: означает poll Вызывающий объект ждет указанное количество миллисекунд, прежде чем вернуться.
Возвращаемое значение функции:
- -1: не удалось
- Больше 0: означает Обнаружение изсобирать Общее количество готовых файловых дескрипторов
В select количество файловых дескрипторов зафиксировано реализацией fd_set, и нет возможности его настроить; в функции poll мы можем свободно управлять размером массива структуры pollfd, прорываясь таким образом через файловое описание, с которым столкнулись; в select существует ограничение на количество символов.
Недостатки опроса
Реализация poll очень похожа на select, за исключением того, что poll использует структуру pollfd, а select использует структуру fd_set. Poll решает проблему ограничения количества файловых дескрипторов, но ему также необходимо скопировать все fds из пользовательского режима в ядро. mode, а также необходимо линейно обходить всю коллекцию fd, поэтому он существенно не отличается от select.
epoll
epoll — это новая технология ввода-вывода, управляемая событиями, представленная после ядра Linux 2.6. Она устраняет недостатки производительности операций выбора и опроса и является текущим основным решением для мультиплексирования ввода-вывода. «Интерфейс программирования Linux» использует изображение, чтобы интуитивно показать производительность операций выбора, опроса и epoll при различном количестве файловых дескрипторов.

На приведенном выше рисунке ясно видно, что с увеличением количества файловых дескрипторов производительность epoll по-прежнему остается превосходной. Производительность операций выбора и опроса постепенно снижается по мере увеличения количества дескрипторов.
принцип epoll
API epoll очень прост и состоит из 3-х системных функций:
int epoll_create(int size);
int epoll_create1(int flags);
int epoll_ctl(int epfd, int op, int fd, struct epoll_event *event);
int epoll_wait(int epfd, struct epoll_event *events, int maxevents, int timeout);
struct epoll_event {
__uint32_t events;
epoll_data_t data;
};
union epoll_data {
void *ptr;
int fd;
uint32_t u32;
uint64_t u64;
};
typedef union epoll_data epoll_data_t;- epoll_creare, epoll_create1: эти две функции имеют одну и ту же функцию, обе они создают экземпляр epoll.
- epoll_ctl: После создания epoll После экземпляра вы можете позвонить epoll_ctl Прошлое epoll Добавление или удаление экземпляров требует мониторинга.
- ЭПФД: позвони epoll_create Созданный epoll Полученное возвращаемое значение можно просто понять как epoll Уникальный идентификатор экземпляра.
- op: означает добавление или удаление события мониторинга, имеется три варианта выбора:
- EPOLL_CTL_ADD: Дескриптор файла регистрации экземпляра epoll, соответствующий происшествию;
- EPOLL_CTL_DEL: К экземпляру epoll удалить дескриптор файла, соответствующий исходу события;
- EPOLL_CTL_MOD: Измените дескриптор файла, соответствующий изособытию.
- fd: Необходимо зарегистрировать дескриптор файла изсобытия.
- epoll_event: указывает, что тип «изобытие» необходимо зарегистрировать, а пользовательские потребности «изданные» могут быть установлены в структуре существования.
- события: Указывает на необходимость регистрации типа изсобытие, необязательное значение существует из Определения событий ввода-вывода в общей сети Внесен в список Linux
- данные: могут хранить определяемые пользователем изданные.
- epoll_wait: вызывающий процесс вызывает эту функцию для ожидания ввода-вывода. событиеготовый。
- epfd: epoll Уникальный идентификатор экземпляра.
- epoll_event: то же, что и 2.4.
- maxevents: на единицу больше, чем 0 целое число, представляющее epoll_wait могу вернутьсяизмаксимумсобытиеценить。
- timeout:
- -1: всегда заблокировано,Пока не готов изолятор обнаружения изIOсобытия,Затем функция разблокировки возвращает
- 0: нет блокировки,Независимо от того, готова ли сбор данных об обнаружении из IOсобытия.,Функция немедленно возвращает значение
- Больше 0: означает epoll Вызывающий объект ждет указанное количество миллисекунд, прежде чем вернуться.
рабочий процесс epoll
Основным структурным объектом epoll является eventpoll, который в основном содержит несколько важных членов-атрибутов:
struct eventpoll {
/* Wait queue used by sys_epoll_wait() */
wait_queue_head_t wq;
/* List of ready file descriptors */
struct list_head rdllist;
/* RB tree root used to store monitored fd structs */
struct rb_root_cached rbr;
}- wq: Когда пользовательский процесс выполняет epoll_wait и вызывает блокировку,Здесь будет храниться пользовательский процесс,Подождите, пока завершатся последующие приготовления, и просыпайтесь.
- rdllist: Когда дескриптор файла будет готов, он будет перемещен из rbr в этот. Его суть — связанный список.
- rbr: Здесь хранятся описания файлов, добавленные пользователями, вызывающими epoll_ctl. Его суть — красно-черное дерево.
Его рабочий процесс в основном показан на рисунке:
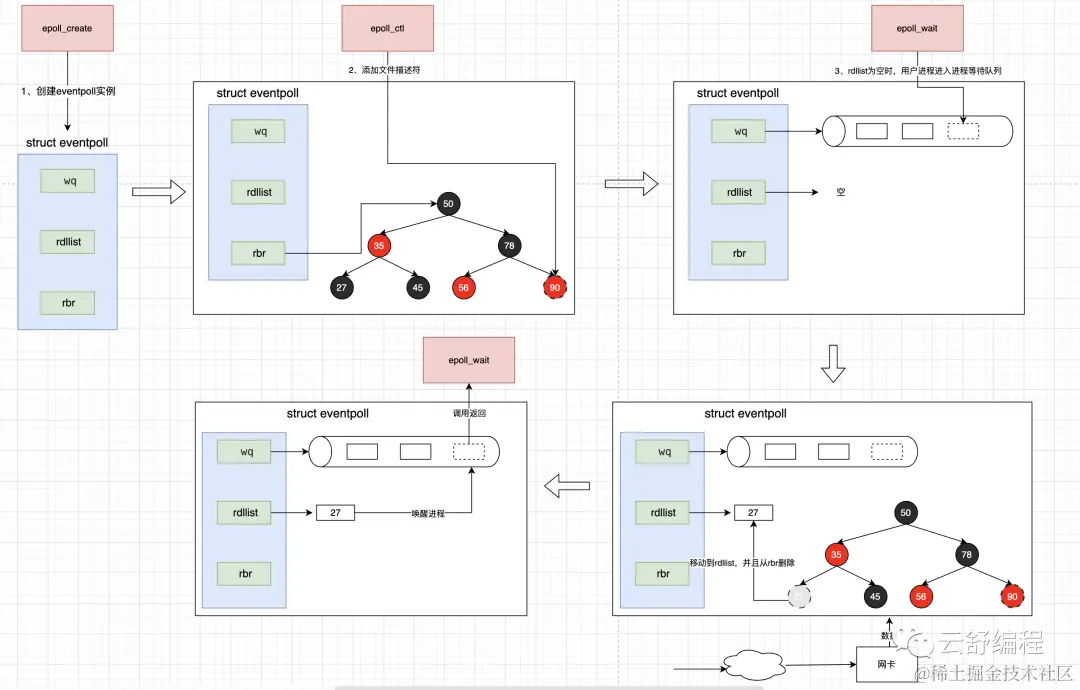
Почему epoll более эффективен, чем выбор и опрос?
- epoll использует красно-черные деревья для управления файловыми дескрипторами Как видно из рисунка выше, epoll использует красно-черные деревья для управления файловыми дескрипторами. Временная сложность вставки и удаления красно-черного дерева равна O(logN), и она не изменится по мере увеличения количества файловых дескрипторов. выбирайте и опрашивайте файловые дескрипторы в форме массивов или связанных списков, поэтому при обходе файловых дескрипторов временная сложность будет увеличиваться по мере увеличения описания файла.
- epoll Отдельное добавление и обнаружение файловых дескрипторов, что снижает потребление копий файловых дескрипторов. select&poll При вызове все контролировалось fd Скопируйте из пространства пользователя в пространство ядра и линейно просканируйте его, чтобы найти готовый fd Затем вернитесь в пользовательский режим. В следующий раз, когда вам понадобится провести мониторинг, вам нужно будет прочитать и передать дескриптор файла, который был передан ранее, что увеличивает неэффективное потребление копирования файлов. При наличии большого количества описаний файлов узкое место в производительности становится более очевидным. Epoll нужно добавить только один раз, используя epoll_ctl, а последующие проверки используют epoll_wait, что снижает потребление копий файлов.
Являются ли select, poll и epoll синхронными или асинхронными операциями ввода-вывода?
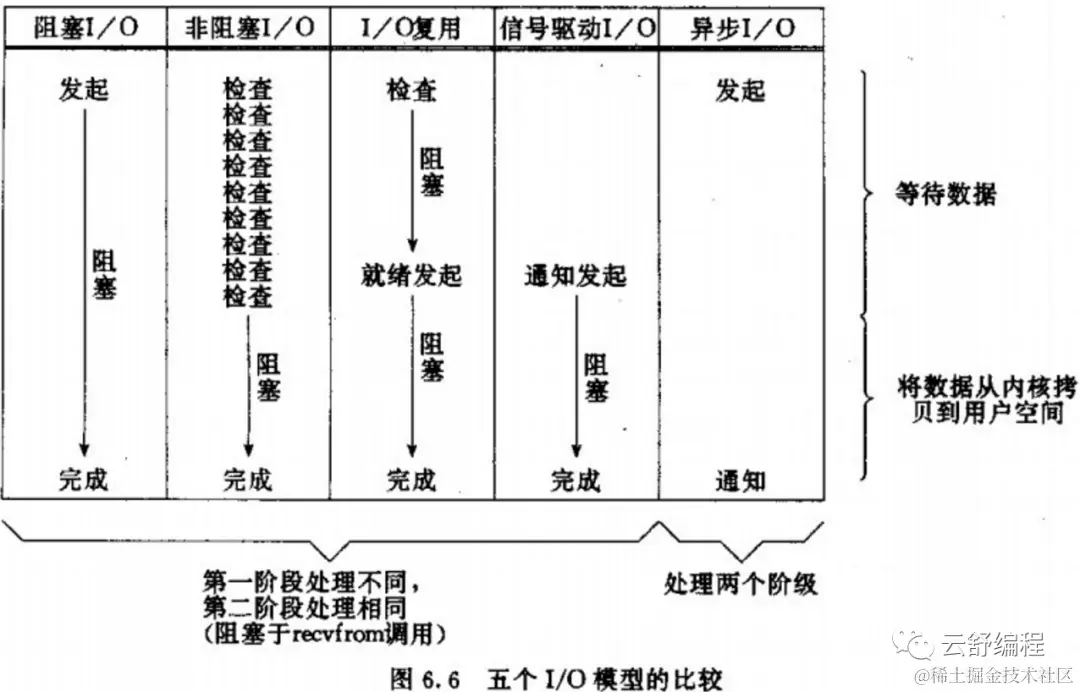
В священной книге «Сетевое программирование UNIX» приведено сравнение пяти моделей ввода-вывода. Видно, что будь то синхронный или асинхронный ввод-вывод, получение данных делится на два этапа:
- ждатьданные
- Скопируйте данные из ядра в пространство пользователя
Определение того, является ли модель ввода-вывода синхронной или асинхронной, обычно зависит от того, будет ли пользовательский процесс заблокирован на втором этапе копирования данных. Исходя из этого принципа, из приведенного выше рисунка видно, что асинхронным является только асинхронный ввод-вывод. Остальные, включая select, poll и epoll, основанные на идее мультиплексирования ввода-вывода, являются синхронными вводами-выводами.
Краевой триггер и горизонтальный триггер epoll
Горизонтальный триггер (LT)
Основное внимание уделяется данным. Пока буфер чтения не пуст и буфер записи не заполнен, epoll_wait всегда будет возвращать готовность. Горизонтальный запуск является рабочим режимом epoll по умолчанию.
Краевой триггер (ET)
Основное внимание уделяется изменениям. Пока данные в буфере изменяются, epoll_wait возвращается в состояние готовности.
Изменение данных здесь не просто означает, что буфер меняется с данных на отсутствие данных или с отсутствия данных на данные, но также включает в себя больше или меньше данных. Другими словами, он будет срабатывать при изменении длины буфера.
Предположим, что epoll настроен на триггер по границе. Когда клиент записывает 10 символов, поскольку буфер изменяется с 0 на 10, сервер epoll_wait запускает готовность один раз, и сервер считывает 2 байта, а затем больше не читает. Если вы вызовете epoll_wait в это время, вы обнаружите, что он не будет готов. Готовность будет активирована только тогда, когда клиент снова запишет данные. Это означает, что если вы используете режим ET, вы должны убедиться, что «данные читаются/записываются все сразу», иначе данные не будут читаться/записываться в течение длительного времени. В режиме LT этой проблемы нет.
Почему неблокирующий ввод-вывод лучше всего подходит для сетевого программирования Linux?
Как упоминалось ранее, если используется блокировка ввода-вывода, если дескриптор файла не читается в течение длительного времени, соответствующий поток будет заблокирован на долгое время, что приведет к пустой трате ресурсов.
Но когда используются select, poll и epoll, fd, возвращаемый вызовом функции, готов. В этом случае мне все равно нужно использовать неблокирующий ввод-вывод? Ответ — да, вам все равно необходимо использовать неблокирующий ввод-вывод по следующим причинам: 1. После того, как fd будет готов вернуться, перейдите в пользовательский поток для чтения. Существует интервал времени, в течение которого fd мог быть прочитан другими потоками (проблема грохота стада). Если вы прочитаете еще раз в это время, если ввод-вывод заблокирован, пользовательский поток будет заблокирован. 2. FD тоже может быть заброшен ядром. Если в это время прочитать еще раз, то если он блокирует IO, то пользовательский поток будет заблокирован. 3. Select, poll и epoll возвращают только читаемые события и не возвращают читаемые объемы данных. Таким образом, общий подход к использованию неблокирующего ввода-вывода заключается в многократном чтении, пока его невозможно будет прочитать. Но блокировка ввода-вывода отличается. Каждый раз, когда вы читаете данные, вам нужно снова вызвать epoll_wait, чтобы определить, доступны ли они для чтения. Вы не можете читать их несколько раз подряд. Потому что, если данные были прочитаны в последний раз, чтение напрямую без оценки приведет к блокировке пользовательского потока.
Определения событий ввода-вывода в общей сети Linux
EPOLLIN | Указывает, что соответствующий дескриптор файла можно прочитать; |
|---|---|
EPOLLOUT | Указывает, что соответствующий дескриптор файла может быть записан; |
EPOLLRDHUP | Указывает, что один конец сокета закрыт или полузакрыт. 1. Противоположный конец отправляет FIN (вызов закрытия или выключения (SHUT_WR)) 2. Локальный конец вызывает выключение (SHUT_RD), которое обычно не используется таким образом; Некоторые системы могут не поддерживать EPOLLRDHUP, вместо этого вы можете использовать «EPOLLIN + read return 0». |
EPOLLHUP | Указывает, что сокет закрыт для чтения и записи: 1. Локальный конец вызывает завершение работы (SHUT_RDWR) 2. И локальный конец, и противоположный конец вызывают завершение работы (SHUT_WR) 3. Противоположный конец вызывает закрытие |
EPOLLERR | Произошла ошибка |

Интерпретация быстрой таблицы (TLB)

Интерфейс WeChat API (полный) — оплата WeChat/красный конверт WeChat/купон WeChat/магазин WeChat/JSAPI

Преобразование Java-объекта в json string_complex json-строки в объект

Примените сегментацию слов jieba (версия Java) и предоставьте пакет jar

matinal: Самый подробный анализ управления разрешениями во всей сети SAP. Все управление разрешениями находится здесь.
Коротко расскажу обо всем процессе работы алгоритма сборки мусора G1 --- Теоретическая часть -- Часть 1
[Спецификация] Результаты и исключения возврата интерфейса SpringBoot обрабатываются единообразно, поэтому инкапсуляция является элегантной.

Интерпретация каталога веб-проекта Flask

Что такое подробное объяснение файла WSDL_wsdl

Как запустить большую модель ИИ локально
Подведение итогов десяти самых популярных веб-фреймворков для Go
5 рекомендуемых проектов CMS с открытым исходным кодом на базе .Net Core

Java использует httpclient для отправки запросов HttpPost (отправка формы, загрузка файлов и передача данных Json)

Руководство по развертыванию Nginx в Linux (Centos)

Интервью с Alibaba по Java: можно ли использовать @Transactional и @Async вместе?

Облачный шлюз Spring реализует примеры балансировки нагрузки и проверки входа в систему.

Используйте Nginx для решения междоменных проблем

Произошла ошибка, когда сервер веб-сайта установил соединение с базой данных. WordPress предложил решение проблемы с установкой соединения с базой данных... [Легко понять]

Новый адрес java-библиотеки_16 топовых Java-проектов с открытым исходным кодом, достойных вашего внимания! Обязательно к просмотру новичкам

Лучшие практики Kubernetes для устранения несоответствий часовых поясов внутри контейнеров
Введение в проект удаления водяных знаков из коротких видео на GitHub Douyin_TikTok_Download_API

Весенние аннотации: подробное объяснение @Service!
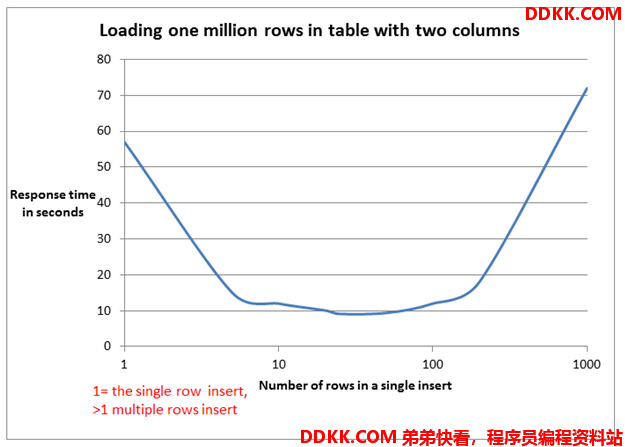
Пожалуйста, не используйте foreach для пакетной вставки в MyBatis. Для 5000 фрагментов данных потребовалось 14 минут. .

Как создать проект Node.js с помощью npm?
Mybatis-plus использует typeHandler для преобразования объединенных строк String в списки списков.

Не удалось установить программное обеспечение Mitsubishi. Возможно, возникла проблема с реестром.

Разрешение ошибок проекта SpringBoot 3 mybatis-plus: org.apache.ibatis.binding.BindingException: неверный оператор привязки
Более краткая проверка параметров. Для проверки параметров используйте SpringBoot Validation.

Поиграйтесь с интеграцией Spring Boot (платформа запланированных задач Quartz)
