Играйте с AIGC: установите Ollama на Ubuntu 24.04 LTS, испытайте большие модели Llama3 8B и Qwen 32B.
Играйте с AIGC: установите Ollama на Ubuntu 24.04 LTS, испытайте большие модели Llama3 8B и Qwen 32B.
2024 Практические документы по эксплуатации и обслуживанию Cloud Native, 2019 г. 99 оригинальный проект Нет. 016 Глава |Веселиться Серия АИГК «2024» Нет. 005 Глава
Привет,добро пожаловать вКвалифицирован в эксплуатации и обслуживании。
Контент, которым сегодня поделились, Веселиться AIGC「2024」 в серии документов Ubuntu 24.04 LTS Установить Ollama, Испытайте большую модель Llama3 8B и Qwen 32B。
В этой статье будет подробно описано, как Ubuntu 24.04 LTS в, принять Docker Самые популярные инструменты для управления развертыванием контейнеров и запуска больших моделей. Ollama。
При этом мы будем использовать Ollama Скачать большую модель Llama3 8B и qwen 32B, испытайте и исследуйте эффект вопросов и ответов двух крупных моделей с открытым исходным кодом.
1. Предварительные условия
1.1 Аппаратная среда
- Сервер виртуализации: Ke Nao X99-D3, память DDR3 128 ГБ (4 * 32 ГБ), процессор Intel E5-2698Bv3
- видеокарта:Версия NVIDIA P106 16G 2 кусок
- Облачный хост AI: системный диск 8C, 32G, 40G, диск данных 500G (большая модель относительно большая, непосредственно разделена на диск с оптимизированным режимом 500G)
1.2 Программная среда
- Платформа виртуализации:Proxmox Virtual Environment 8.0.4
- AI Облачная хост-система: Ubuntu 24.04 LTS
- Docker:26.1.1
- NVIDIA Container Toolkit:1.15
- Ollama:0.1.34
1.3 Конфигурация операционной системы
Система Ubuntu 24.04 LTS Установить конфигурацию,Пожалуйста, обратитесь к документациистроить AI Облачный хост крупной модели, Ubuntu 24.04 LTS Установить Docker и NVIDIA Container Toolkit。Установить NVIDIA Драйвер видеокарты, NVIDIA Container Toolkit и Docker。
2. Установить Ollama
Мы используем Docker Compose для развертывания Ollama, что более удобно для последующего управления и обновлений.
2.1 Создать каталог данных
mkdir -p /data/containers/ollama/data2.2 Отредактируйте файл docker-compose.yml.
Создать документ конфигурации,vi /data/containers/ollama/docker-compose.yml
name: 'ollama'
services:
ollama:
restart: always
image: ollama/ollama
container_name: ollama
runtime: nvidia
environment:
- TZ=Asia/Shanghai
- NVIDIA_VISIBLE_DEVICES=all
networks:
- ai-tier
ports:
- "11434:11434"
volumes:
- ./data:/root/.ollama
networks:
ai-tier:
name: ai-tier
driver: bridge
ipam:
config:
- subnet: 172.22.1.0/24проиллюстрировать:
ipam Настроить
ai-tierСетевой адрес сети. runtime: nvidia использовать nvidia среда выполнения контейнера NVIDIA_VISIBLE_DEVICES=all использоватьвсе GPU
2.3 Создайте и запустите сервис Ollama
- Запустить службу
cd /data/containers/ollama
docker compose up -d- После правильного выполнения результат вывода будет следующим:
root@AI-LLM-Prod:/data/containers/ollama# docker compose up -d
[+] Running 4/4
✔ ollama Pulled 46.8s
✔ 3c645031de29 Pull complete 10.1s
✔ 2fc4741feb27 Pull complete 12.3s
✔ 8ce449dca7ea Pull complete 43.0s
[+] Running 2/2
✔ Network ai-tier Created 0.1s
✔ Container ollama Started 0.6s Уведомление: Нет.При однократном выполнении он загрузится ollama зеркало
2.4 Проверка статуса контейнера
- Посмотреть статус контейнера Оллама
root@AI-LLM-Prod:/data/containers/ollama# docker compose ps
NAME IMAGE COMMAND SERVICE CREATED STATUS PORTS
ollama ollama/ollama "/bin/ollama serve" ollama About a minute ago Up About a minute 0.0.0.0:11434->11434/tcp, :::11434->11434/tcp- Просмотр журналов службы Оллама
# По журналу Ollama Есть ли какая-нибудь аномалия
docker compose logs -fИсходное содержимое журнала следующее:
root@AI-LLM-Prod:/data/containers/ollama# docker compose logs -f
ollama | 2024/05/09 07:26:31 routes.go:989: INFO server config env="map[OLLAMA_DEBUG:false OLLAMA_LLM_LIBRARY: OLLAMA_MAX_LOADED_MODELS:1 OLLAMA_MAX_QUEUE:512 OLLAMA_MAX_VRAM:0 OLLAMA_NOPRUNE:false OLLAMA_NUM_PARALLEL:1 OLLAMA_ORIGINS:[http://localhost https://localhost http://localhost:* https://localhost:* http://127.0.0.1 https://127.0.0.1 http://127.0.0.1:* https://127.0.0.1:* http://0.0.0.0 https://0.0.0.0 http://0.0.0.0:* https://0.0.0.0:*] OLLAMA_RUNNERS_DIR: OLLAMA_TMPDIR:]"
ollama | time=2024-05-09T07:26:31.408Z level=INFO source=images.go:897 msg="total blobs: 0"
ollama | time=2024-05-09T07:26:31.409Z level=INFO source=images.go:904 msg="total unused blobs removed: 0"
ollama | time=2024-05-09T07:26:31.409Z level=INFO source=routes.go:1034 msg="Listening on [::]:11434 (version 0.1.34)"
ollama | time=2024-05-09T07:26:31.409Z level=INFO source=payload.go:30 msg="extracting embedded files" dir=/tmp/ollama1747465736/runners
ollama | time=2024-05-09T07:26:35.670Z level=INFO source=payload.go:44 msg="Dynamic LLM libraries [cpu cpu_avx cpu_avx2 cuda_v11 rocm_v60002]"
ollama | time=2024-05-09T07:26:35.670Z level=INFO source=gpu.go:122 msg="Detecting GPUs"
ollama | time=2024-05-09T07:26:35.691Z level=INFO source=gpu.go:127 msg="detected GPUs" count=2 library=/usr/lib/x86_64-linux-gnu/libcuda.so.535.171.04
ollama | time=2024-05-09T07:26:35.691Z level=INFO source=cpu_common.go:11 msg="CPU has AVX2"3. Загрузите локальную большую модель
Ollama Запускайте с помощью контейнерного развертывания. Требуются ежедневные команды управленияиспользовать docker метод, добавьте перед формальной командой docker exec -it ollama。
3.1 Скачать Лама 3
Llama 3 Открытый исходный код 8B и 70B Модели с двумя размерами параметров, так как видеопамять наших дуальных карт имеет только 32G,70B Ты определенно не умеешь бегать, поэтому ты можешь только испытать это llama3:8b Модель.
Выполните следующую команду для загрузки llama3:8b:
docker exec -it ollama ollama pull llama3:8bПосле правильного выполнения результат вывода будет следующим:
root@AI-LLM-Prod:/data/containers/ollama# docker exec -it ollama ollama pull llama3:8b
pulling manifest
pulling 00e1317cbf74... 100% ▕████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████ 4.7 GB
pulling 4fa551d4f938... 100% ▕████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████ 12 KB
pulling 8ab4849b038c... 100% ▕████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████ 254 B
pulling 577073ffcc6c... 100% ▕████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████ 110 B
pulling ad1518640c43... 100% ▕████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████ 483 B
verifying sha256 digest
writing manifest
removing any unused layers
successВся модель имеет размер 4,7 ГБ, а скорость загрузки в моей сети может достигать около 70 МБ/с.
3.2 Скачать qwen
Qwen 1.5 Открытый исходный код 6 большая модель , включать 0.5B, 1.8B, 4B (default), 7B, 14B, 32B (new) and 72Б. в соответствии с 32G Видеопамять, давайте испытаем ее 32B Каков эффект.
Выполните следующую команду для загрузки qwen:32b(вся модель 18 GB):
docker exec -it ollama ollama pull qwen:32bПосле правильного выполнения результат вывода будет следующим:
root@AI-LLM-Prod:/data/containers/ollama# docker exec -it ollama ollama pull qwen:32b
pulling manifest
pulling 936798ec2285... 100% ▕█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████ 18 GB
pulling 6b53223f338a... 100% ▕█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████ 6.9 KB
pulling 62fbfd9ed093... 100% ▕█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████ 182 B
pulling f02dd72bb242... 100% ▕█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████ 59 B
pulling e8fe47255a86... 100% ▕█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████ 484 B
verifying sha256 digest
writing manifest
removing any unused layers
success3.3 Просмотр больших моделей, загруженных локально
root@AI-LLM-Prod:/data/containers/ollama# docker exec -it ollama ollama list
NAME ID SIZE MODIFIED
llama3:8b a6990ed6be41 4.7 GB 19 minutes ago
qwen:32b 26e7e8447f5d 18 GB About a minute ago4. Llama3 8B vs Qwen 32B
Далее я выберу несколько вопросов с точки зрения меня волнующих и сравню их. Llama3 8B и Qwen 32B Какой из них сильнее, а какой слабее, какой из них больше подходит для ваших местных потребностей в выборе крупных моделей?
Тестирование вопроса относительно простое,Просто для развлечения. не имеет особой репрезентативности,На практике необходимо проводить достаточные испытания в соответствии с потребностями.
Я привык использовать графические инструменты общения ChatBox позвонить Llama3 8B и Qwen 32B, проведите тест с диалогом вопросов и ответов.
4.1 Серия вопросов для умственно отсталых барменов
вопрос 1: Я купил фунт корня лотоса, почему половина фунта пуста?
вопрос 2: Почему мои родители не пригласили меня на свадьбу, когда поженились?
- Llama3 8B результаты ответа
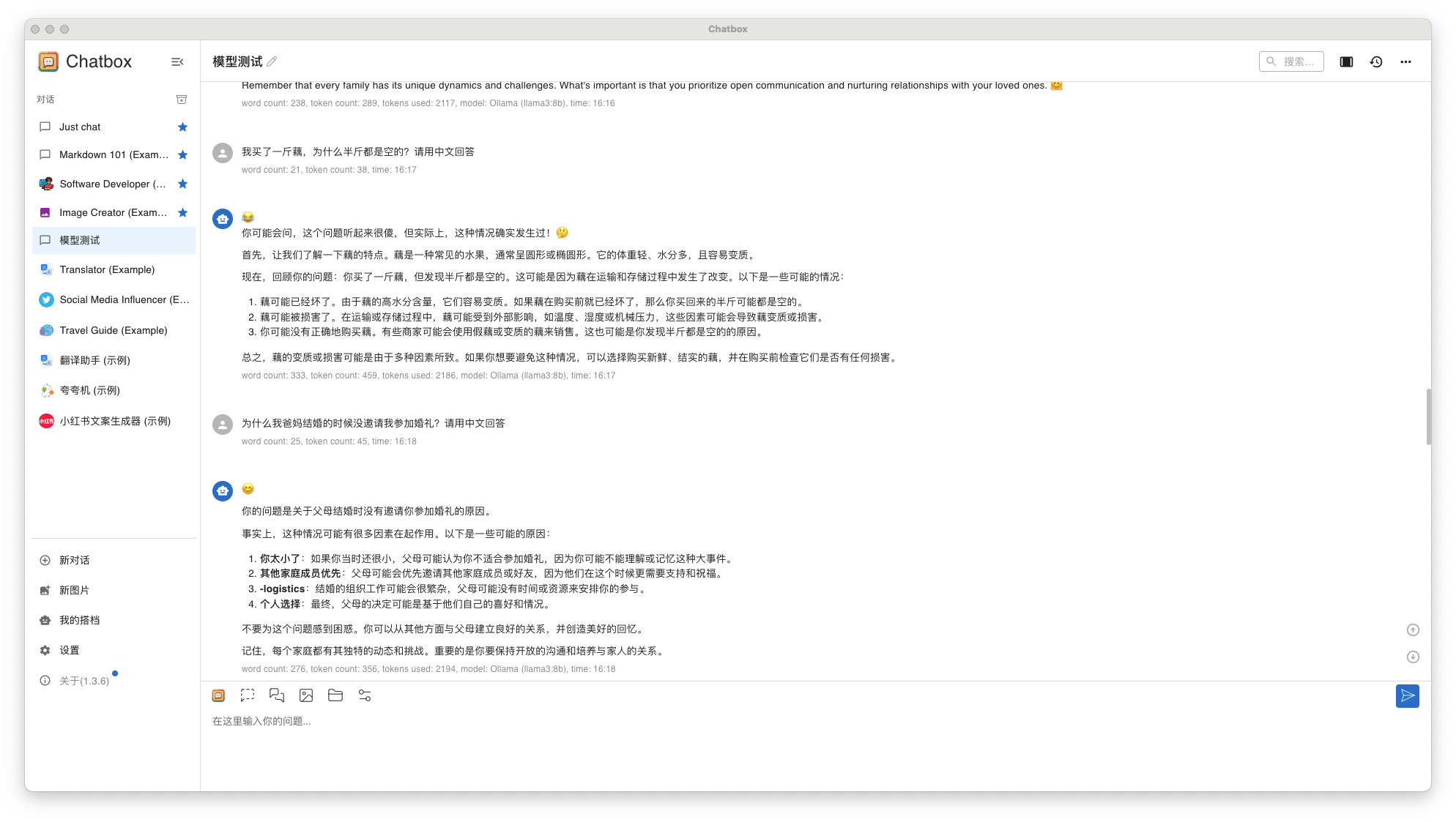
Если вы хотите получить ответы на китайском языке, пожалуйста, добавьте "Пожалуйста, ответьте на китайском"。и,Ни один из этих двух ответов не был удовлетворительным.
- Qwen 32B результаты ответа
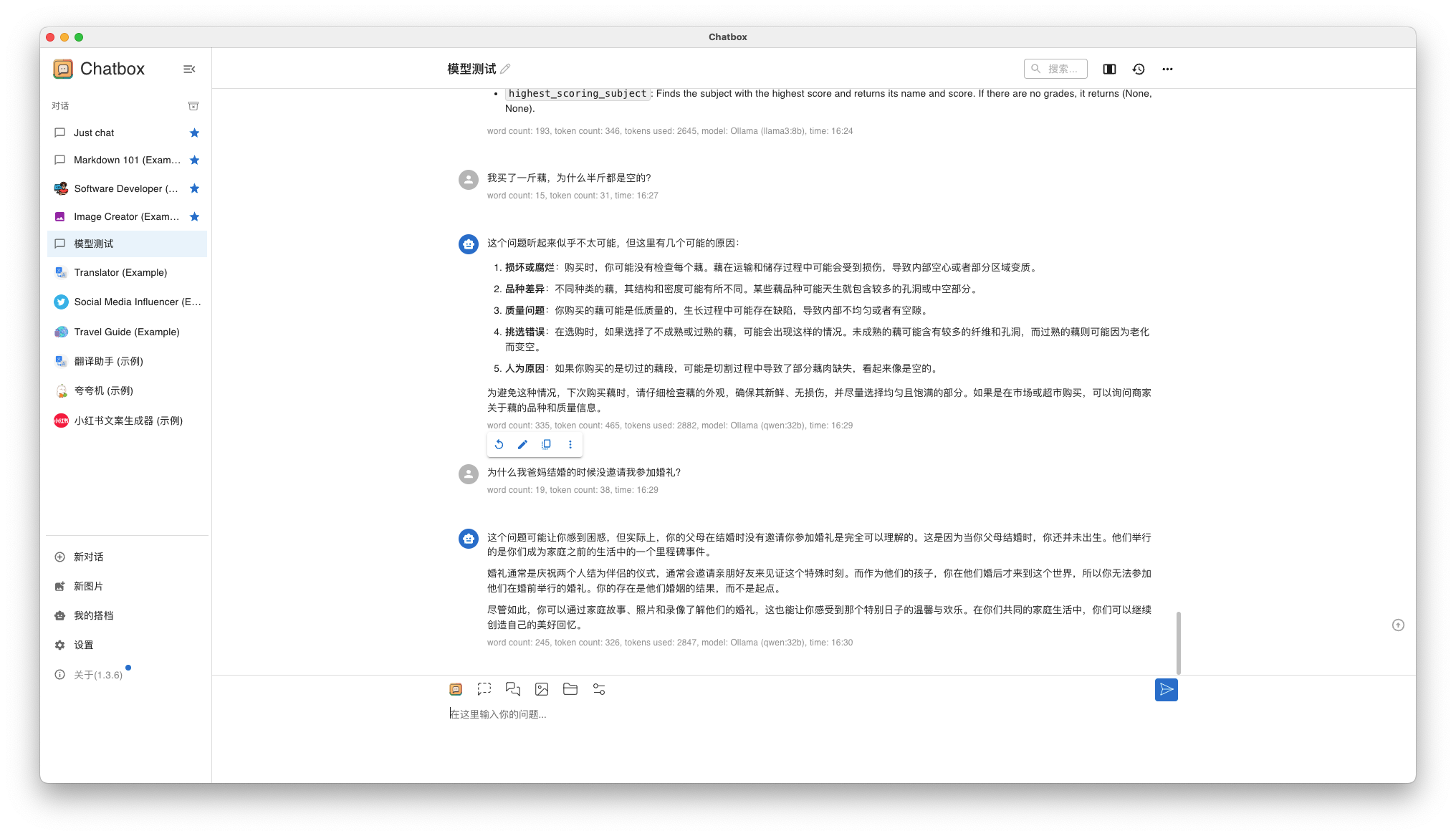
Ответ на вопрос Нет.one практически такой же, как и на вопрос Llama3 8B, а ответ на вопрос Нет.two вполне удовлетворительный.
4.2 Проблемы программирования
вопрос 1:
Описание вопроса
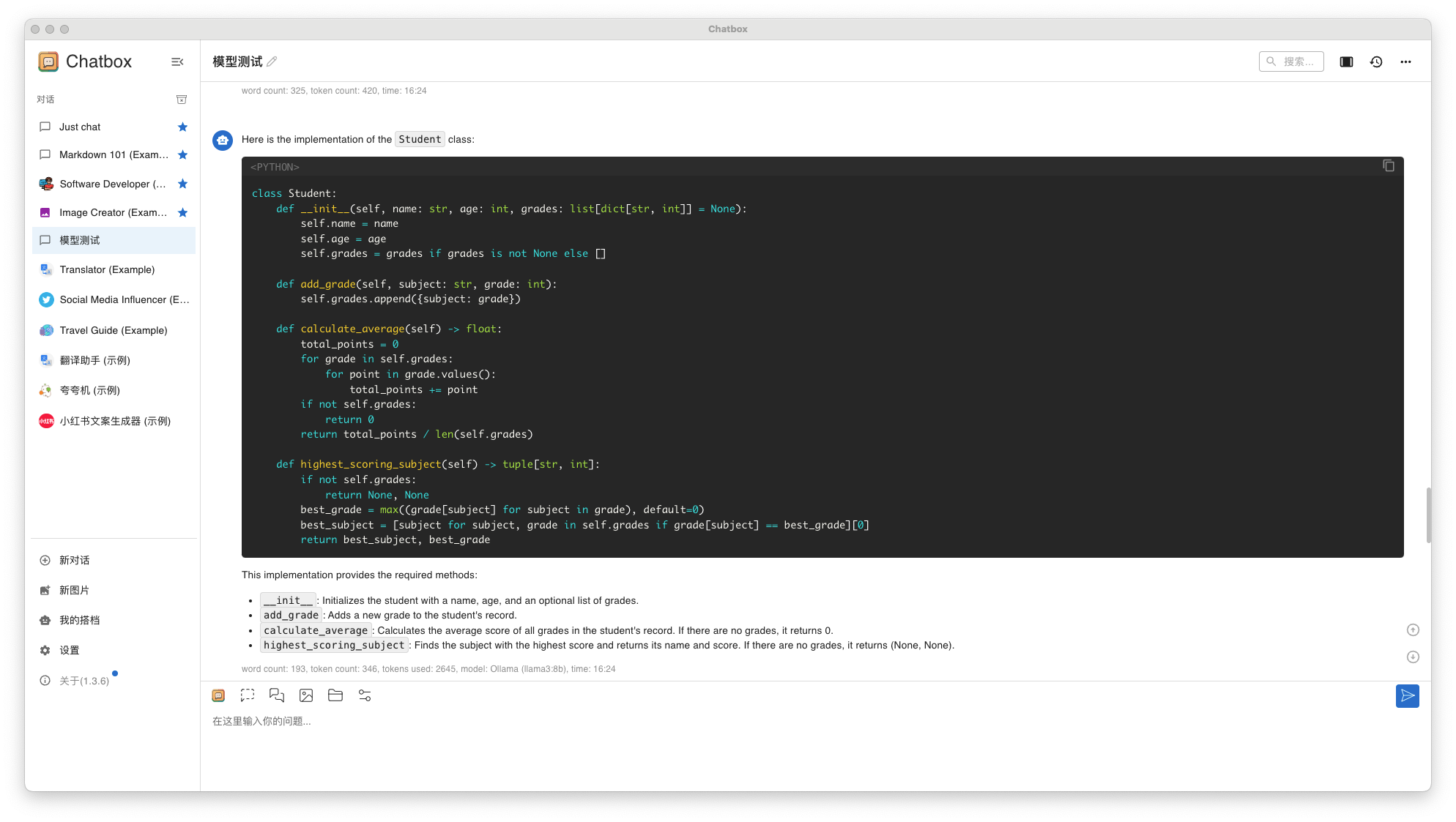
Придумайте имя под названием Student Класс, используемый для хранения информации об учениках. У каждого ученика есть имя, возраст и оценки. Вам необходимо реализовать следующие функции:
инициализация: Конструктор принимает имя, возраст и начальный список оценок (необязательный, по умолчанию пустой список).
Добавьте оценки: реализовать метод add_grade(grade: int), позволяет добавить новую оценку в список оценок учащегося.
Посчитаем средний балл: реализовать метод Calculate_average() возвращает средний балл всех оценок. Если список оценок пуст, возвращается 0.
Предметы с наибольшим количеством баллов: реализовать метод high_scoring_subject() возвращает кортеж, содержащий наивысший балл и соответствующее ему имя субъекта. Предположим, что название предмета и балл хранятся вместе в списке оценок в словарной форме, например: {'Math': 90, 'English': 85}. Если список оценок пуст, верните (None, None)。- Llama3 8B результаты ответа
- Qwen 32B результаты ответа
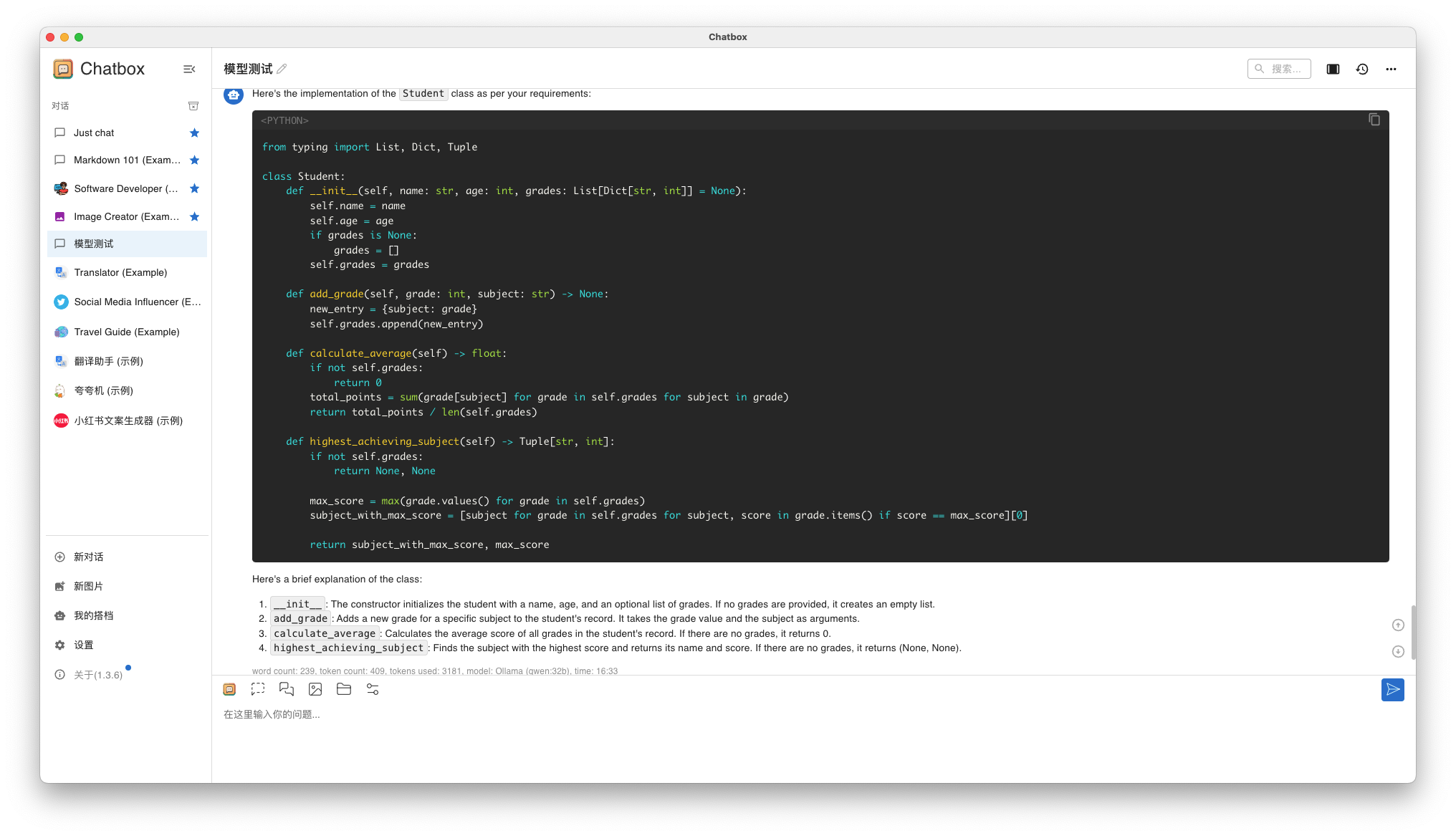
Оба человека ответили на английском, Llama3. Нет смысла отвечать так, но Qwen 32B Для меня этот ответ неприемлем. И ответы между ними очень похожи.
4.3 Комплексные вопросы
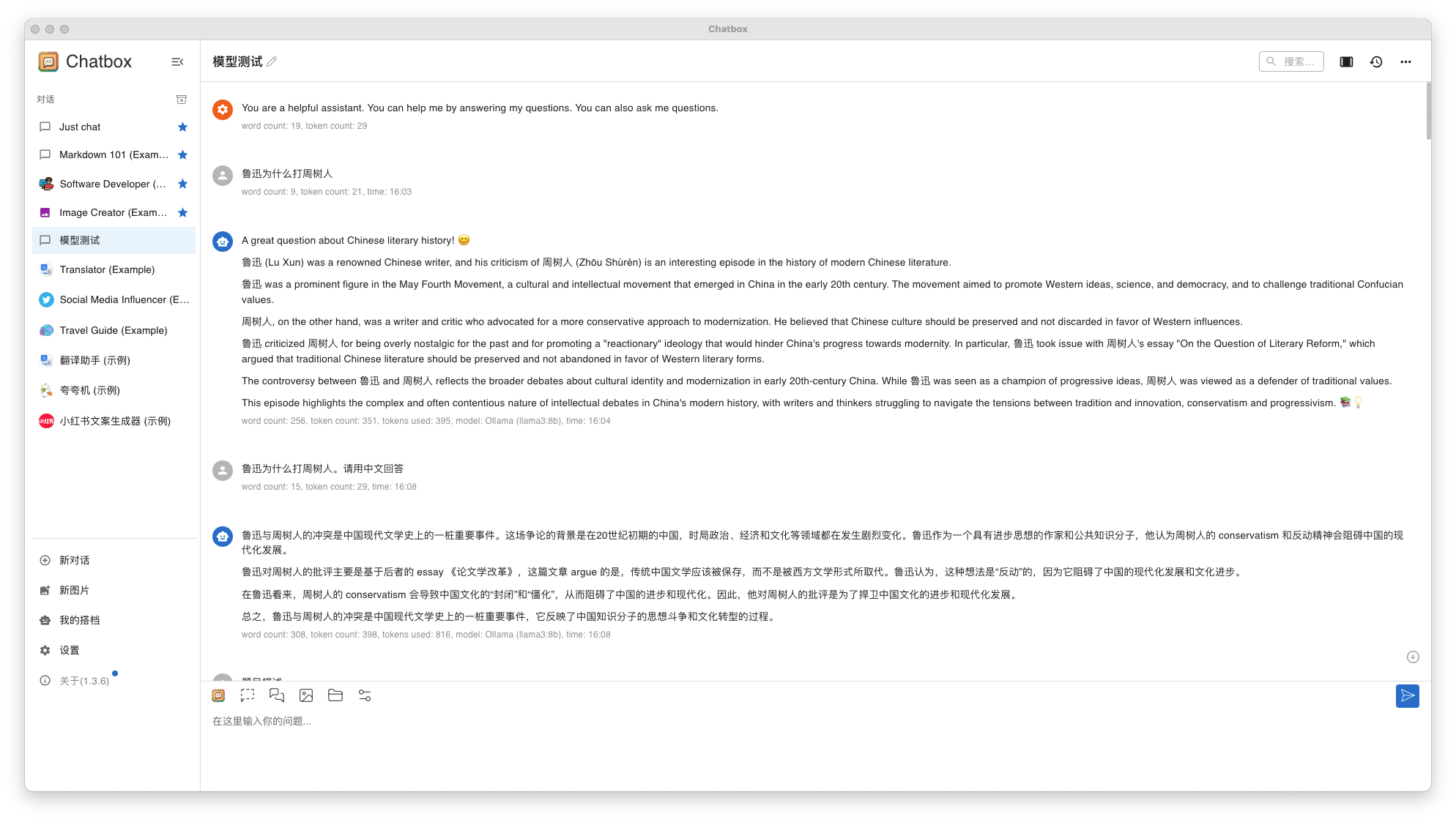
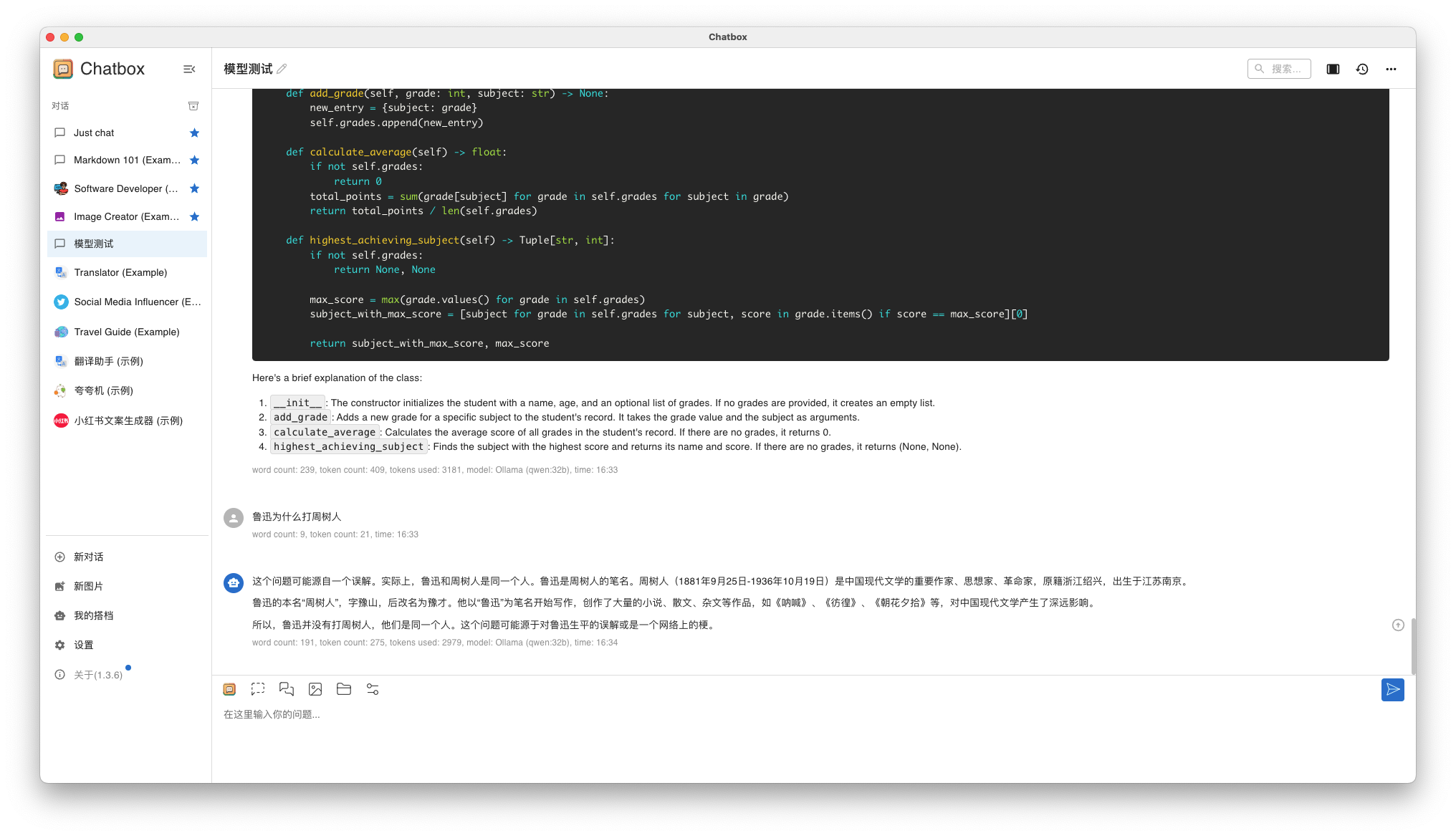
вопрос 1: Почему Лу Синь победил Чжоу Шуреня?
- Llama3 8B результаты ответа
- Qwen 32B результаты ответа
Итог теста:
- Llama3 8B и Qwen 32B Все может работать нормально, Квен. 32B Скорость вопросов и ответов немного медленная, но приемлемая.
- Ответ Llama3 8B средний, Qwen 32B немного лучше.
- Qwen Китайская поддержка в теории определенно лучше, и я, скорее всего,выберу ее в будущем. Qwen Глубина системыиспользовать
Вышеупомянутое — это все, чем я сегодня поделился. В следующем выпуске я расскажу, как развернуть Установить. Stable Diffusion и испытать мой AI Эффект рисования облачного хоста. Пожалуйста, продолжайте обращать внимание! ! !
Отказ от ответственности:
- Уровень автора ограничен,Несмотря на многочисленные проверки и проверки,Мы прилагаем все усилия для обеспечения точности содержания.,Однако могут быть и пропуски。Пожалуйста, дайте свой совет экспертам отрасли.。
- Содержание, описанное в этой статье, было проверено и протестировано только в реальных боевых условиях.,Читатели могут учиться и извлекать уроки из,ноКатегорически запрещено использовать непосредственно в производственной среде.。Автор не несет ответственности за любые вопросы, возникшие в связи с этим.!
Получите практическое видео из этой статьи.(пожалуйста, обрати внимание,Асинхронный выпуск документального видео,пожалуйста, сначаласосредоточиться на)
Если вам понравилась эта статья, поделитесь, добавьте в избранное, поставьте лайк и прокомментируйте! Пожалуйста, продолжайте обращать внимание @ Опытные в эксплуатации и обслуживании, вовремя смотрите больше хороших статей!
Добро пожаловать присоединиться «Планета знаний|Навыки эксплуатации и технического обслуживания» , получи больше KubeSphere, Kubernetes, облачная эксплуатация и обслуживание, автоматизированная эксплуатация и обслуживание, искусственный интеллект Практические навыки, такие как большие модели。В будущей карьере оператора и технического обслуживания я всегда буду сидеть в роли вашего второго пилота.。
Заявление об авторских правах
- Весь контент принадлежит оригиналу,Спасибо, что прочитали и собрали,Пожалуйста, свяжитесь с нами для получения разрешения на перепечатку. Воспроизведение без разрешения запрещено.。


CRUD используется уже два или три года. Как читать исходный код Spring?

Устраните проблему совместимости между версией Spring Boot и Gradle Java: возникла проблема при настройке корневого проекта «demo1» > Не удалось.

Научите вас шаг за шагом, как настроить Nginx.
Это руководство — все, что вам нужно для руководства по автономному развертыванию сервера для проектов Python уровня няни (рекомендуемый сборник).

Не удалось запустить docker.service — Подробное объяснение идеального решения ️

Настройка файлового сервера Samba в системе Linux Centos. Анализ NetBIOS (супер подробно)
Как настроить метод ssh в Git, как получить и отправить код через метод ssh

RasaGpt — платформа чат-ботов на основе Rasa и LLM.

Nomic Embed: воспроизводимая модель внедрения SOTA с открытым исходным кодом.

Улучшение YOLOv8: EMA основана на эффективном многомасштабном внимании, основанном на межпространственном обучении, и эффект лучше, чем у ECA, CBAM и CA. Малые цели имеют очевидные преимущества | ICASSP2023

Урок 1 серии Libtorch: Тензорная библиотека Silky C++

Руководство по локальному развертыванию Stable Diffusion: подробные шаги и анализ распространенных проблем

Полностью автоматический инструмент для работы с видео в один клик: VideoLingo

Улучшения оптимизации RT-DETR: облегченные улучшения магистрали | Support Paddle облегченный rtdetr-r18, rtdetr-r34, rtdetr-r50, rtdet

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | Деформируемое внимание с большим ядром (D-LKA Attention), большое ядро свертки улучшает механизм внимания восприимчивых полей с различными функциями

Создано Datawhale: выпущено «Руководство по тонкой настройке развертывания большой модели GLM-4»!

7B превышает десятки миллиардов, aiXcoder-7B с открытым исходным кодом Пекинского университета — это самая мощная модель большого кода, лучший выбор для корпоративного развертывания.

Используйте модель Huggingface, чтобы заменить интерфейс внедрения OpenAI в китайской среде.

Оригинальные улучшения YOLOv8: несколько новых улучшений | Сохранение исходной информации — алгоритм отделяемой по глубине свертки (MDSConv) |

Второй пилот облачной разработки | Быстро поиграйте со средствами разработки на базе искусственного интеллекта

Бесшовная интеграция, мгновенный интеллект [1]: платформа больших моделей Dify-LLM, интеграция с нулевым кодированием и встраивание в сторонние системы, более 42 тысяч звезд, чтобы стать свидетелями эксклюзивных интеллектуальных решений.

Решенная Ошибка | Загрузка PyTorch медленная: TimeoutError: [Errno 110] При загрузке факела истекло время ожидания — Cat Head Tiger

Brother OCR, библиотека с открытым исходным кодом для Python, которая распознает коды проверки.
Новейшее подробное руководство по загрузке и использованию последней демонстрационной версии набора данных COCO.

Выпущен отчет о крупной модели финансовой отрасли за 2023 год | Полный текст включен в загрузку |

Обычные компьютеры также могут работать с большими моделями, и вы можете получить личного помощника с искусственным интеллектом за три шага | Руководство для начинающих по локальному развертыванию LLaMA-3

Одной статьи достаточно для анализа фактора транскрипции SCENIC на Python (4)

Бросая вызов ограничениям производительности небольших видеокарт, он научит вас запускать большие модели глубокого обучения с ограниченными ресурсами, а также предоставит полное руководство по оценке и эффективному использованию памяти графического процессора!

Команда Fudan NLP опубликовала 80-страничный обзор крупномасштабных модельных агентов, в котором в одной статье представлен обзор текущего состояния и будущего агентов ИИ.
