ICCV 2023 | Имитатор: персонализированная голосовая 3D-анимация лица
источник:ICCV 2023 Название диссертации:Imitator: Personalized Speech-driven 3D Facial Animation Бумажная ссылка:https://arxiv.org/abs/2301.00023 Автор статьи:Balamurugan Thambiraja и др. Организация контента: Линь Цзунхао В данной статье предлагается метод персонализированного голосового управления. 3D человеческое лицоанимацияизметод Имитатор, метод может изучать детали, специфичные для личности, из краткого ввода видео и генерировать поверхность лиц, которая соответствует стилю речи и чертам лица целевого человека, а также двугубные согласные («м», «б», «р»), что обеспечивает точную губную позу. закрытие. Много экспериментповерхности ясно Imitator На основе входного аудио генерируется выразительная анимация лица, что значительно улучшает синхронизацию губ и сохраняет стиль речи персонажа.
введение

картина 1:Imitator это голосовой драйвер для персонализированного 3D Новый метод с анимацией человеческого лица. Учитывая последовательность аудио и встраивание персонализированного стиля в качестве входных данных, мы генерируем индивидуальные последовательности движений и обеспечиваем точное смыкание губ для двугубных согласных («m», «b», «p»). Стиль встраивания тела можно узнать из краткого справочного видео (5 секунды).
голосовое управление 3D Анимация человеческого лица широко исследовалась. Современный метод искажает топологию лица целевого человека для одновременного ввода аудио, но не учитывает стиль речи и характеристики лица конкретного человека, что приводит к нереалистичным и неточным движениям губ. Для решения этой проблемы мы предлагаем голосовое управлениечеловеческое лицоповерхность Синтез любвиметод Имитатор, метод может изучать детали личности из краткого входного видео и генерировать выражения лица, соответствующие стилю речи и чертам лица целевого человека. В частности, мы создаем большой набор данных о поверхности грани, который будет тренироваться независимо от стиля. Transformer, как априор поверхности лица, управляемый аудио, затем использует априор для оптимизации стиля речи конкретного человека на основе короткого справочного видео. Чтобы тренироваться предварительно, мы вводим на Функция потери двугубных согласных для обнаружения основы, обеспечивающая разумное закрытие губ, тем самым повышая подлинность генерируемых ощущений поверхности. Благодаря обширным исследованиям пользователей экспериментов мы демонстрируем Imitator Улучшена синхронизация губ 49% и генерирует выразительную анимацию лица на основе входного звука, сохраняя при этом стиль речи персонажа. Основные положения данной статьи резюмируются следующим образом:
- Мы предлагаем облегченную разговорную адаптацию стиляметод,Генерация и декодирование специфической идентичности посредством разделения родовых визем.,Эффективно адаптируйте стиль речи нового персонажа на основе краткого справочного видео.
- Мы ввели новую потерю контакта губ,на основа Физиологическая основа двугубных согласных («м», «б», «р») улучшает смыкание губ.
метод
Модельная архитектура
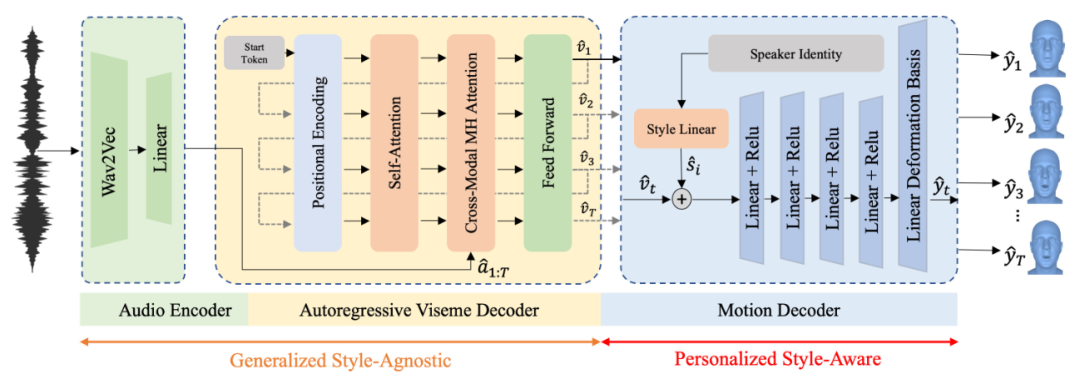
картина 2. Наша архитектура принимает звук в качестве входного сигнала и Wav2Vec 2.0 кодирование. Аудиовстроенный в Авторегрессионный декодер вокселей Генерация функций движения. адаптация стилядекодер Движение сопоставляет эти особенности движения с поверхностью граней, специфичной для личности, то есть смещениями вершин относительно сетки шаблона.
аудиокодер
Мы используем универсальную речевую модель для кодирования входного звука. В частности, мы используем Wav2Vec 2.0. исходный Wav2Vec на основе CNN Архитектура, призванная генерировать значимый человеческий потенциал, существует на поверхности. Он работает самоконтролируемым и полуконтролируемым образом, используя контрастные потери для прогнозирования значения после текущего входного голоса, что позволяет модели учиться на большом количестве немаркированных данных. Wav2Vec 2.0 Путем количественной оценки потенциаласуществоватьповерхность Показыватьиинтегрированныйна основе Transformer Архитектура расширяет эту идею. Мы используем линейную интерполяцию для Wav2Vec 2.0 Выходной сигнал повторно дискретизируется, чтобы соответствовать частоте дискретизации движения, в результате чего
Контекстное представление кадров
。
Авторегрессионный декодер вокселей
визуальный декодер
Принятие контекстного представления аудиопоследовательности в качестве входных данных и создание независимых от стиля воксельных функций авторегрессионным способом.
. Эти особенности виземы описывают деформацию губ с учетом контекстного звука и предыдущих особенностей виземы. Мы используем классическую архитектуру Transformer в качестве декодера вокселей, который обучается на основе аудиофункций.
независимые от идентичности визуальные особенности
картографии. Авторегрессионный воксельный кодер определяется как:
в,
это обучаемый параметр. Мы используем стартовый токен для обозначения начала последовательности из-за длины последовательности.
задается длиной входного аудио, поэтому токен завершения не используется. Мы кодируем время, добавляя синусоиды к воксельным функциям.
чтобы ввести информацию о времени в последовательность:
Учитывая входную последовательность с позиционной кодировкой
мы используем многоголовое самовнимание для генерации контекстных представлений, взвешенных по релевантности входных данных. Эти контекстные представления и звуковые функции
В качестве входных данных для кросс-модального многоголового блока внимания. Последний слой прямой связи сопоставляет выходные данные слоя внимания к звуку и движению с встраиваниями вокселей.
。
декодер движения
Наша цель — получить независимые от стиля воксельные функции.
и встраивание индивидуального стиля.
Создание индивидуальной 3D-анимации лица
. Наш декодер Движение состоит из двух частей: слоя внедрения стиля и блока синтеза движения. Устанавливаем горячую кодировку идентичности для тренированного набора. Уровень внедрения стилей принимает информацию об идентичности в качестве входных данных для создания внедрений стиля, которые кодируют определенные движения идентичности.
. К функции вокселей добавлено внедрение стиля.
и подается в блок синтеза движения. Блоки синтеза движения состоят из нелинейных слоев.,Сопоставление воксельных элементов с учетом стилей в пространстве движения, определяемом базисом линейной деформации. существоватьтренироваться в процессе,Базис деформации извлекается из всех идентификаторов в наборе данных.,И может применяться к стилям, выходящим за пределы тренироваться идентичности посредством тонкой настройки. окончательный результат сетки
Его получают путем добавления расчетного относительного смещения вершин к шаблонной сетке тела.
тренироваться
насиспользоватьавторегрессионныйтренироватьсяплансуществовать VOCAset dataSET тренировать нашу модель, определяя следующие потери:
в,
Определите потерю вершин при реконструкции,
Определить потерю скорости,
Измерьте контакт губ. Веса
,
,
。
потери на реконструкцию
потери на реконструкцию
для:
в,
на время
индекс последовательности
Сетка правды
это прогнозируемое значение.
потеря скорости
Наш декодер Движение использует независимые воксельные функции в качестве входных данных для генерации выражений лица. Чтобы улучшить временную согласованность прогнозов, мы вводим потерю скорости
:
потеря контакта губ
использовать
Выполнение тренироваться приводит к тому, что модель учит среднестатистическую мимику лица, что приводит к неточному смыканию губ. С этой целью мы ввели новый двугубный согласный («м», «б», «р») потеря. контакта губа. В частности, мы автоматически аннотировали VOCAset Количество вхождений этих согласных в определяет следующую утрату губы:
в,
Прогнозы взвешены по Гауссу на основе двугубных аннотаций согласных. В частности, для кадров с такими согласными
существовать
значение, в противном случае это
。
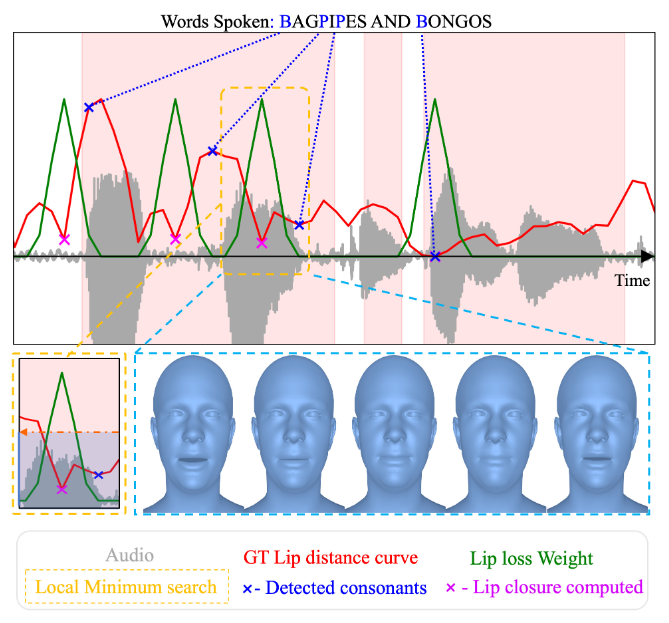
картина 3: в VOCAset Двугубные согласные («м», «б», «р») и соответствующие им смыкания губ автоматически добавляются в последовательность. мы используем Torch Audio для выравнивания текста и аудио. Чтобы обнаружить фактическое смыкание губ, мы ищем локальный минимум на кривой расстояния до губ (красный) в окне, предшествующем обнаруженной согласной. Вес потери губ устанавливается на фиксированное значение функции Гаусса.
адаптация стиля
Учитывая короткое видео нового объекта, мы используем MICA для отслеживания лица
。на На основе ссылочных данных мы сначала оптимизируем встраивание стиля говорящего
, а затем используйте
и
Утрата совместно улучшенной линейной деформации основы. В нашем эксперименте мы обнаружили, что эта двухэтапная адаптация имеет решающее значение для обобщения на новые входы аудио, поскольку она повторно использует декодер. Претренироваться информация для движения. При инициализации внедрения стиля мы фокусируемся на стиле речи. Мы предварительно вычисляем все воксельные функции один раз.
и оптимизируйте стиль речи, чтобы воспроизвести отслеживаемое лицо
. Затем мы уточняем основу линейного движения декодера, чтобы он соответствовал деформациям, специфичным для личности (например, асимметричным движениям губ).
эксперимент
Количественные результаты
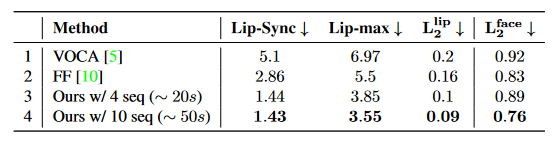
поверхность 1:VOCAset начальствоиз Количественные результаты. Наш метод значительно превосходит базовый метод, особенно Lip-Sync улучшенный 49%,Lip-max улучшенный 36%。
Качественные результаты
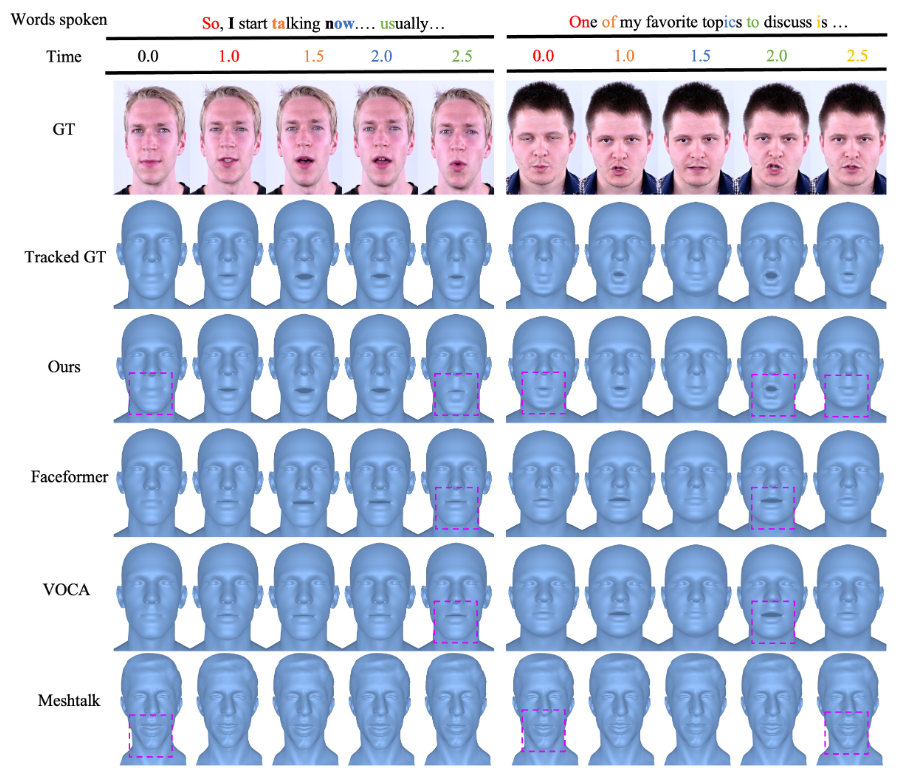
картина 4: с VOCA、FaceformerиMeshTalk качественное сравнение.
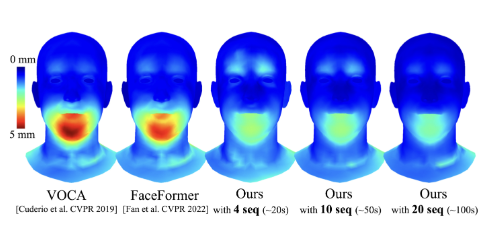
картина 5: в VOCAset среднее значение на тестовом наборе L2 Сравнение ошибок расстояния вершин.
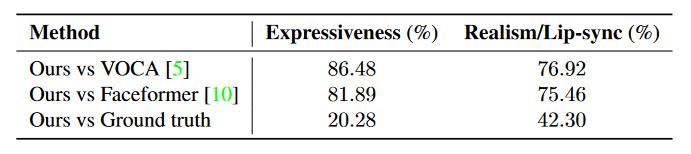
поверхность 2: в VOCAset Восприятие на тестовом наборе A/B Исследование пользователей. и VOCAиFaceformer по сравнению с,насизметодболее популярный。

поверхность 3: видео снято на реальных людях A/B Исследования пользователей для оценки сходства и соответствия стиля речи целевой персоне.
удалятьэксперимент
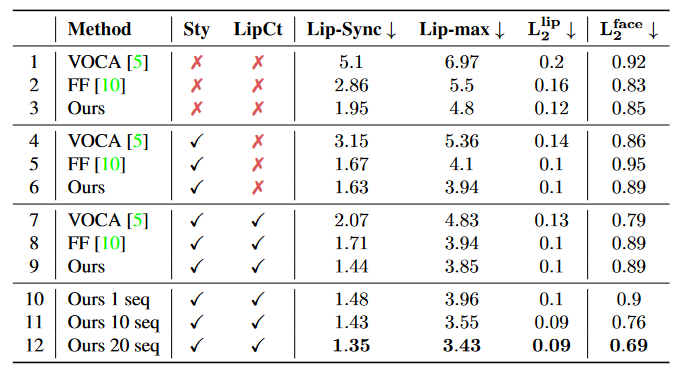
поверхность 4: О нашем методе и его компонентах. VOCAset Абляция на эксперименте. StyиLipCt поверхность Показыватьиспользоватьадаптация стиляипотеря контакта губ。
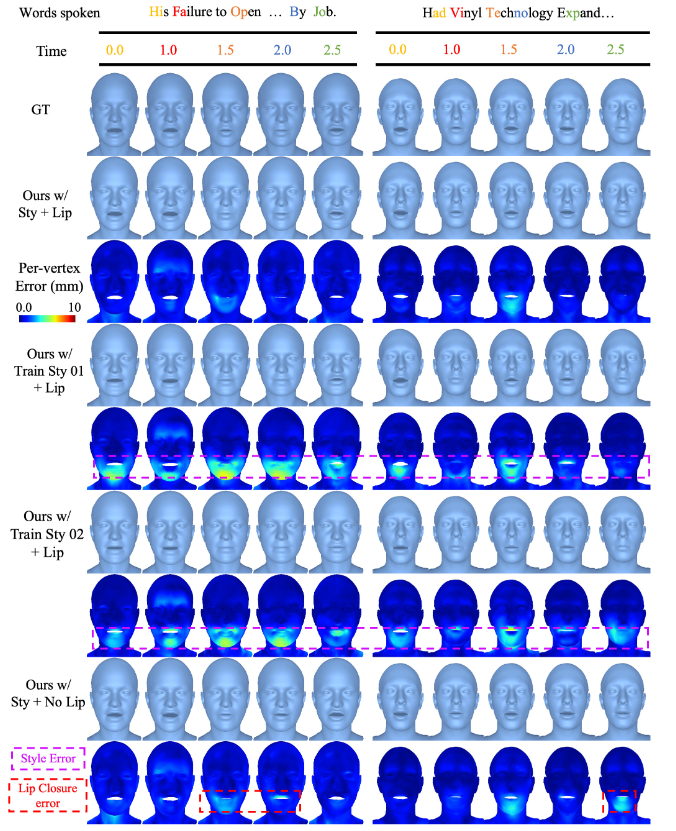
изображение 6: Качественное сравнение абляции. Мы представляем полный метод со стилем и потерей губ.,Метод способен генерировать персонализированную анимацию лиц. Концентрированные случайные стили заменяют оптимизированные стили, специфичные для личности.,Сгенерирует усредненную анимацию лица. Пурпурная поверхность указывает на то, что сгенерированные целевые символы поверхности не похожи.,В частности, морфам лица не хватает деталей, специфичных для личности. Устранение потери губы от цели тренироваться приведет к неточному смыканию губы.,Уменьшите реалистичность.
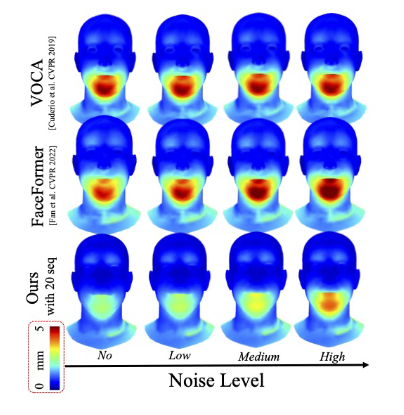
картина 7: Исследование чувствительности к звуковому шуму. в VOCAset Для оценки испытуемому добавляется белый шум.
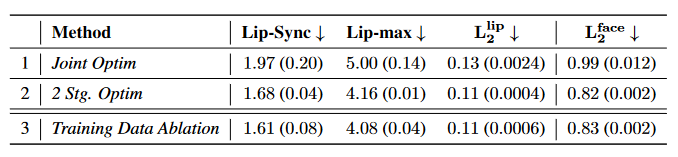
поверхность 5: Исследование по инициализации встраивания стилей и удалению тренированных данных.



Углубленный анализ переполнения памяти CUDA: OutOfMemoryError: CUDA не хватает памяти. Попыталась выделить 3,21 Ги Б (GPU 0; всего 8,00 Ги Б).

[Решено] ошибка установки conda. Среда решения: не удалось выполнить первоначальное зависание. Повторная попытка с помощью файла (графическое руководство).

Прочитайте нейросетевую модель Трансформера в одной статье

.ART Теплые зимние предложения уже открыты

Сравнительная таблица описания кодов ошибок Amap

Уведомление о последних правилах Points Mall в декабре 2022 года.

Даже новички могут быстро приступить к работе с легким сервером приложений.

Взгляд на RSAC 2024|Защита конфиденциальности в эпоху больших моделей

Вы используете ИИ каждый день и до сих пор не знаете, как ИИ дает обратную связь? Одна статья для понимания реализации в коде Python общих функций потерь генеративных моделей + анализ принципов расчета.

Используйте (внутренний) почтовый ящик для образовательных учреждений, чтобы использовать Microsoft Family Bucket (1T дискового пространства на одном диске и версию Office 365 для образовательных учреждений)

Руководство по началу работы с оперативным проектом (7) Практическое сочетание оперативного письма — оперативного письма на основе интеллектуальной системы вопросов и ответов службы поддержки клиентов

[docker] Версия сервера «Чтение 3» — создайте свою собственную программу чтения веб-текста

Обзор Cloud-init и этапы создания в рамках PVE

Корпоративные пользователи используют пакет регистрационных ресурсов для регистрации ICP для веб-сайта и активации оплаты WeChat H5 (с кодом платежного узла версии API V3)

Подробное объяснение таких показателей производительности с высоким уровнем параллелизма, как QPS, TPS, RT и пропускная способность.

Удачи в конкурсе Python Essay Challenge, станьте первым, кто испытает новую функцию сообщества [Запускать блоки кода онлайн] и выиграйте множество изысканных подарков!

[Техническая посадка травы] Кровавая рвота и отделка позволяют вам необычным образом ощипывать гусиные перья! Не распространяйте информацию! ! !

[Официальное ограниченное по времени мероприятие] Сейчас ноябрь, напишите и получите приз

Прочтите это в одной статье: Учебник для няни по созданию сервера Huanshou Parlu на базе CVM-сервера.

Cloud Native | Что такое CRD (настраиваемые определения ресурсов) в K8s?

Как использовать Cloudflare CDN для настройки узла (CF самостоятельно выбирает IP) Гонконг, Китай/Азия узел/сводка и рекомендации внутреннего высокоскоростного IP-сегмента

Дополнительные правила вознаграждения амбассадоров акции в марте 2023 г.

Можно ли открыть частный сервер Phantom Beast Palu одним щелчком мыши? Супер простой урок для начинающих! (Прилагается метод обновления сервера)

[Играйте с Phantom Beast Palu] Обновите игровой сервер Phantom Beast Pallu одним щелчком мыши

Maotouhu делится: последний доступный внутри страны адрес склада исходного образа Docker 2024 года (обновлено 1 декабря)

Кодирование Base64 в MultipartFile

5 точек расширения SpringBoot, супер практично!

Глубокое понимание сопоставления индексов Elasticsearch.

15 рекомендуемых платформ разработки с нулевым кодом корпоративного уровня. Всегда найдется та, которая вам понравится.
