GhostNetV3 с открытым исходным кодом от Huawei | Оптимизирует периферийные вычисления, значительно повышает производительность и превосходит MobileNet!

Компактные нейронные сети специально разработаны для приложений на периферийных устройствах, которые имеют более высокую скорость вывода, но умеренную производительность. Однако текущие стратегии обучения компактных моделей заимствованы из традиционных моделей, что игнорирует их различия в емкости моделей и, таким образом, может снизить производительность компактных моделей. В этой статье авторы представляют мощную стратегию обучения компактных моделей, систематически изучая влияние различных элементов обучения. Авторы обнаружили, что правильный дизайн репараметризации и дистилляции знаний имеет решающее значение для обучения высокопроизводительных компактных моделей, в то время как некоторые методы увеличения данных, обычно используемые для обучения традиционных моделей, такие как Mixup и CutMix, могут привести к снижению производительности. Наши эксперименты с набором данных ImageNet-1K показывают, что наша специализированная стратегия обучения компактных моделей работает на различных архитектурах, включая GhostNetV2, MobileNetV2 и ShuffleNetV2. В частности, оснащен авторской стратегией GhostNetV3.
Используя всего 269 МФЛОПС и задержку 14,46 мс на мобильных устройствах, он достиг первой точности 79,1%, что значительно превышает показатели обычно обучаемых аналогов. Более того, наблюдения авторов можно распространить на сценарии обнаружения целей. Подпишитесь на официальный аккаунт и отправьте личное сообщение «Получить код», чтобы получить код PyTorch и веса для предварительной тренировки.
1Introduction
Чтобы удовлетворить ограниченность памяти и вычислительных ресурсов периферийных устройств, таких как мобильные телефоны, были разработаны различные эффективные архитектуры. Например, MobileNetV1 использует разделенные по глубине свертки для снижения вычислительных затрат. MobileNetV2 представил остаточные соединения, а MobileNetV3 дополнительно оптимизировал конфигурацию архитектуры с помощью поиска нейронной архитектуры (NAS), что значительно улучшило производительность модели. Другой типичной архитектурой является GhostNet, которая использует избыточность функций и реплицирует каналы функций, используя недорогие операции. Недавно GhostNetV2 дополнительно включает в себя аппаратный модуль контроля для захвата зависимостей между пикселями на больших расстояниях и значительно превосходит GhostNet по производительности.
Помимо хорошо продуманной архитектуры модели, для достижения значительной производительности решающее значение также имеют соответствующие стратегии обучения. Например, Уайтман и др. улучшили точность ResNet-50 на ImageNet-1K с 76,1% до 80,4% за счет интеграции передовых методов оптимизации и увеличения данных. Однако, хотя были предприняты значительные усилия для изучения более продвинутых стратегий обучения для традиционных моделей (например, ResNet и VisionTransformer), лишь немногие исследования были сосредоточены на компактных моделях. Поскольку модели с разной мощностью могут иметь разные предпочтения в обучении, нецелесообразно напрямую применять стратегии, разработанные для традиционных моделей, к обучению компактных моделей.
Чтобы восполнить этот пробел, авторы систематически изучали несколько стратегий обучения компактных моделей. В частности, основное внимание автора уделяется ключевым параметрам обучения, как обсуждалось в предыдущей работе, включая репараметризацию, дистилляцию знаний (KD), планирование обучения и увеличение данных.
Повторная параметризация. Глубокие свертки и свертки 1×1 являются распространенными строительными блоками, поскольку они требуют незначительного объема памяти и вычислительных ресурсов в компактных архитектурах моделей. Вдохновленные успешным опытом обучения традиционных моделей, авторы применяют метод репараметризации для улучшения производительности этих двух компактных модулей. При обучении компактной модели авторы вводят линейную параллельную ветвь в глубокую свертку.
Свертка и свертка 1×1. Эти дополнительные параллельные ветви могут быть повторно параметризованы после обучения без дополнительных затрат во время вывода. Чтобы сопоставить общую стоимость обучения с приростом производительности, авторы сравнили влияние добавления различного количества филиалов. Кроме того, авторы обнаружили, что ветвь свертки глубины 1 × 1 оказывает значительное положительное влияние на репараметризацию свертки глубины 3 × 3.
Дистилляция знаний. Из-за ограниченной мощности компактных моделей им сложно добиться производительности, сравнимой с традиционными моделями. Таким образом, метод КД, который использует более крупные модели в качестве учителей для управления изучением компактных моделей, является подходящим способом повышения производительности. Автор эмпирически изучает влияние нескольких типичных факторов при использовании КД для обучения компактных моделей, таких как выбор моделей учителей и настройки гиперпараметров. Результаты показывают, что подходящая модель учителя может значительно улучшить производительность компактных моделей.
Планирование обучения и улучшение данных. Авторы сравнивают несколько настроек обучения для компактных моделей, включая скорость обучения, затухание веса, экспоненциальное скользящее среднее (EMA) и увеличение данных. Интересно, что не все хитрости, разработанные для традиционных моделей, применимы и к компактным моделям. Например, некоторые широко используемые методы увеличения данных, такие как Mixup и CutMix, могут фактически снизить производительность компактных моделей. Автор подробно обсудит их влияние в разделе 5.
На основе авторских исследований автор разработал специализированный метод обучения компактных моделей. Эксперименты на наборе данных ImageNet-1K подтвердили превосходство предложенного автором метода. В частности, модель GhostNetV2, обученная с помощью метода авторов, значительно превзошла модель, обученную с помощью предыдущей стратегии, с точки зрения точности и задержки высшего уровня (рис. 1). Эксперименты на других эффективных архитектурах, таких как MobileNetV2 и ShuffleNetV2, еще раз подтвердили обобщающую способность предложенного метода.
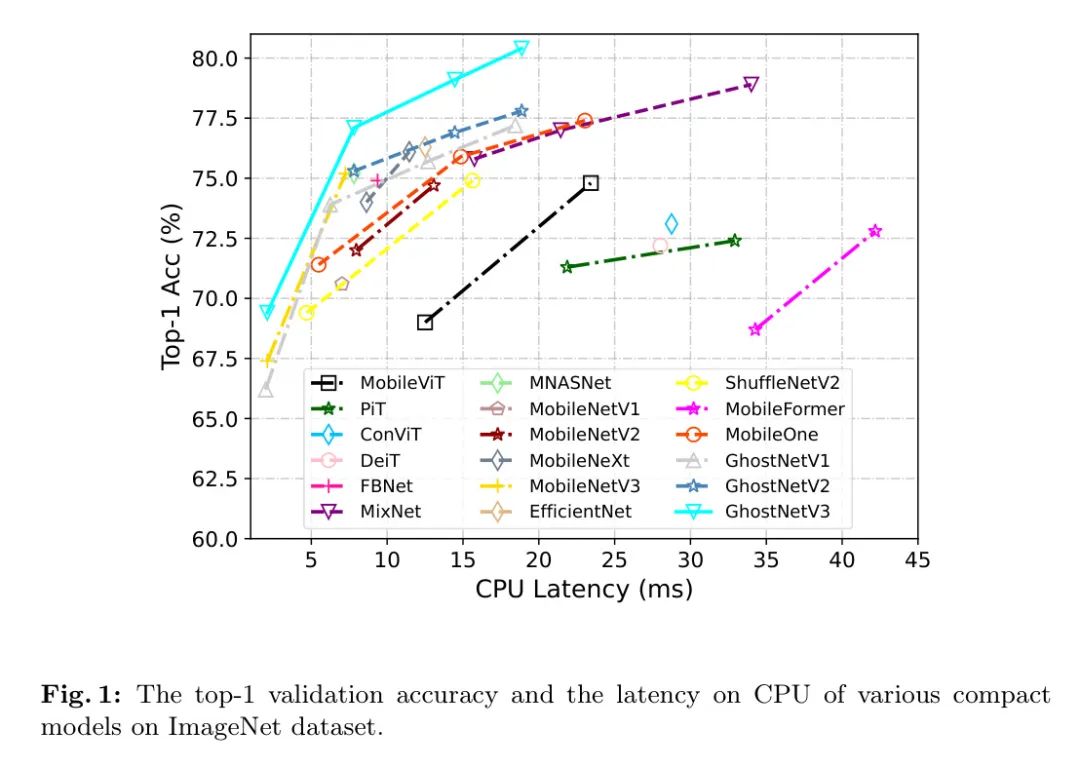
Оставшаяся часть этой статьи организована следующим образом. В разделе 2 рассматриваются соответствующие работы. В разделе 3 представлена архитектура GhostNetV2. В разделе 4 подробно обсуждается стратегия обучения. Затем в разделе 5 показаны богатые экспериментальные результаты. Раздел 6 завершает статью.
2Relatedworks
Compactmodels
Разработка компактной структуры модели с низкой задержкой вывода и высокой производительностью является сложной задачей. SqueezeNet предлагает три метода проектирования компактных моделей, а именно использование 1
1 замена фильтра 3
3 фильтра, уменьшающие вход до 3
3 отфильтровать количество каналов и позднее выполнить понижающую дискретизацию в сети для поддержки больших карт объектов. Эти принципы конструктивны, особенно 1
1 Использование свертки. MobileNetV1 использует 1
1Ядро и глубинно-разделимая свертка заменяют почти все фильтры, что значительно снижает вычислительные затраты.
MobileNetV2 дополнительно вводит остаточные соединения в компактные модели и строит инвертированную остаточную структуру, в которой средний уровень блока имеет больше каналов, чем его входы и выходы. Чтобы сохранить возможность представления, некоторые нелинейные функции удалены. MobileNeXt переосмысливает необходимость устранения узких мест и утверждает, что высокая производительность может быть достигнута и с помощью классических структур узких мест. Принимая во внимание 1
На одну свертку приходится значительная часть вычислительных затрат, ShuffleNet заменяет ее групповой сверткой. Операции перетасовки каналов помогают передавать информацию между группами. Изучая факторы, влияющие на фактическую скорость работы, ShuffleNetV2 предлагает новый аппаратно-ориентированный блок.
MnasNet и MobileNetV3 ищут архитектурные параметры, такие как ширина модели, глубина модели, размер фильтра свертки и т. д. Используя избыточность функций, GhostNet заменяет 1
1 половина каналов в свёртке. GhostNetV2 предлагает так называемый механизм внимания DFC, основанный на полностью подключенном уровне, который может не только быстро выполняться на обычном оборудовании, но и фиксировать зависимости между удаленными пикселями. До сих пор серия GhostNets остается компактной моделью SOTA с лучшим компромиссом между точностью и скоростью.
После большого успеха ViT (DeiT) [8] в задачах компьютерного зрения исследователи начали работать над созданием компактных архитектур Transformer для мобильных устройств. MobileFormer предлагает компактный механизм перекрестного внимания для моделирования двустороннего моста между MobileNet и Transformer. MobileViT опирается на успешный опыт компактной CNN и использует Transformer для глобальной обработки, чтобы заменить локальную обработку в свертке. Однако компактные модели на основе Transformer страдают от высокой задержки вывода на мобильных устройствах из-за сложных операций внимания.
Bagoftricksfortraining
Есть некоторые работы по CNN, направленные на улучшение стратегий обучения для повышения производительности различных моделей. Он и др. обсуждают некоторые полезные советы по эффективному обучению работе с оборудованием и предлагают новый метод настройки архитектуры модели для ResNet. Райтман и др. повторно оценили производительность стандартного ResNet-50 при обучении с использованием новых методов оптимизации и увеличения данных. Они делятся настройками соревновательного обучения и предварительно обученными моделями в библиотеке с открытым исходным кодом Timm. Используя их схему обучения, обычная модель ResNet-50 достигла точности 80,4%. Чен и др. изучили влияние обучения нескольким основным компонентам ViT с самоконтролем. Однако все эти попытки предназначены для больших моделей или моделей с самоконтролем. Из-за разницы в мощности моделей напрямую переносить их на компактные модели нецелесообразно.
3Preliminary
GhostNets (GhostNetV1 и GhostNetV2) — это современные компактные модели, предназначенные для эффективного вывода на мобильных устройствах. Его ключевой архитектурой является модуль Ghost, который может генерировать больше карт объектов с помощью дешевых операций, тем самым заменяя исходную свертку.
В обычной свертке выходные характеристики
передано
полученные, среди которых
ядро свертки,
это входная функция.
и
Представляют размеры канала ввода и вывода соответственно.
размер ядра,
Представляет операцию свертки. Модуль Ghost сокращает количество параметров и вычислительные затраты обычной свертки в два этапа. Сначала он генерирует _внутренние_ функции
, размер канала которого меньше исходного объекта
. Затем в _intrinsic_ функции
Применяйте дешевые операции (например, глубинные свертки) для создания _призрачных_ функций.
. Окончательный передаваемый результат получается путем соединения _внутренних_и_призрачных_ функций по размерности канала, и его формула может быть выражена как:
В формуле
и
Представьте параметры в первичной свертке и дешевой операции соответственно. "Кот" Указывает на операцию соединения. Вся модель GhostNet построена путем объединения нескольких модулей Ghost.
GhostNetV2 расширяет компактную модель, создавая эффективный модуль внимания, а именно модуль внимания DFC. Учитывая, что компактные модели, такие как GhostNet, обычно используют небольшие свертки ядра, например 1
1и3
3,Их способность извлекать глобальную информацию из входных объектов слаба. GhostNetV2 использует простой полносвязный слой для сбора пространственной информации на большие расстояния и создания карт внимания. Для вычислительной эффективности,Он разлагает глобальную информацию на горизонтальное и вертикальное направления.,И агрегировать пиксели по этим двум направлениям соответственно. Как показано на рисунке 1(а),Путем объединения модуля внимания DFC с модулем Ghost,GhostNetV2 может эффективно извлекать глобальную и локальную информацию.,В то же время достигается лучший баланс между точностью и сложностью вычислений.
4Trainingstrategies
Цель автора – изучить стратегии обучения.,Без изменения архитектуры сети вывода,Чтобы компактная модель имела небольшой размер и высокую скорость. Авторы эмпирически изучают ключевые факторы обучения нейронных сетей.,Включает учебный план、увеличение данных、Интенсивное использованиеи Дистилляция знаний.
Re-parameterization
Репараметризация доказала свою эффективность в традиционных сверточных моделях. Вдохновленные успехом, авторы внесли в компактную модель репараметризацию, добавив повторяющиеся ветки, оснащенные слоями BatchNorm. Автор показывает конструкцию перепараметризованного GhostNetV2 на рисунке 1(b). Стоит отметить, что автор ввел 1
1 Глубокая свертка разветвляется для перепараметризации 3
3-х глубинная свертка. Результаты экспериментов подтверждают его положительное влияние на производительность компактных моделей. Более того, эксперименты тщательно исследуют оптимальное количество повторяющихся ветвей.
в рассуждениях,Дубликаты ветвей можно удалить с помощью обратного процесса перепараметризации. Поскольку операции свертки и пакетной нормализации являются линейными во время вывода,Их можно свернуть в один сверточный слой.,Его весовая матрица выражается как
, смещение выражается как
. После этого сложенные веса и смещения во всех ветвях можно перепараметризовать как
и предвзятость
,в
— индекс дублирующейся ветки.
KnowledgedistillationKD
для образца
и его этикетки
, соответственно используйте
и
Представляя соответствующие логические значения, предсказанные моделью ученика и моделью учителя, общая функция потерь KD может быть выражена как:
в
и
Представляют потерю перекрестной энтропии и потерю KD соответственно.
является сбалансированным гиперпараметром.
Обычно в качестве функции дивергенции Кульбака-Лейблера принимают потери при дистилляции знаний (KDloss), которые можно выразить как:
Функция потерь здесь
в
— это гиперпараметр сглаживания меток, называемый температурой. В авторских экспериментах автор изучал гиперпараметры
и
Влияние различных настроек на производительность компактной модели.
Learningschedule
Скорость обучения — ключевой параметр нейронных сетей. Двумя обычно используемыми стратегиями корректировки скорости обучения являются: _Step_и_Cosine_. Стратегия _stepping_ линейно снижает скорость обучения.,А стратегия _cosine_ вначале медленно снижает скорость обучения.,Почти линейный на промежуточных стадиях,В конце снова замедляется. В этой работе подробно изучается скорость обучения и влияние стратегий корректировки скорости обучения на компактные модели.
Экспоненциальное скользящее среднее (EMA) в последнее время стало эффективным методом повышения точности проверки модели и повышения ее надежности. Конкретно,во время тренировки,Он постепенно усредняет параметры модели. Предположим, что модель находится в
Параметры шага:
, метод расчета EMA модели следующий:
в,
представляет собой по шагам
– параметры модели EMA, а
является гиперпараметром. Автор изучит влияние EMA в разделе 5.3.
Dataaugmentation
Различныйувеличение данных Предложены методы повышения производительности традиционных моделей.производительность。в,Схема _AutoAug_ использует 25 комбинаций начальных стратегий.,Каждая комбинация содержит два преобразования. Для каждого входного изображения,Случайным образом выберите комбинацию подстратегий,и определить, следует ли применять каждое преобразование в подполитике,Это решение определяется определенной вероятностью. Метод _RandomAug_ предлагает метод случайного увеличения, при котором все подполитики выбираются с одинаковой вероятностью. Методы псевдонимов изображений, такие как _Mixup_и_CutMix_, объединяют два изображения для создания нового изображения. Конкретно,_Mixup_ обучает нейронную сеть на выпуклых комбинациях пар примеров и его этикетки,_CutMix_, с другой стороны, случайным образом удаляет область из одного изображения и заменяет соответствующую область патчем из другого изображения. _RandomErasing_ случайным образом выбирает прямоугольную область изображения и заменяет ее пиксели случайными значениями.
в этой статье,Авторы оценивают различные комбинации вышеуказанных методов увеличения данных.,и откройте для себя некоторые методы увеличения данных, обычно используемые для обучения традиционных моделей.,Например MixupиCutMix,Не подходит для тренировок компактных моделей.
5Experimentalresults
В базовой стратегии обучения автора автор использует мини-пакет размером 2048 и принимает LAMB. Модель подверглась 600 циклам оптимизации. Начальная скорость обучения установлена на 0,005, и применяется стратегия корректировки скорости косинусного обучения. Затухание веса и импульс установлены на 0,05 и 0,9 соответственно. Автор использовал коэффициент затухания 0,999 для экспоненциального скользящего среднего (EMA) и применил случайное улучшение и случайное стирание для улучшения данных. В этом разделе авторы изучают эти стратегии обучения и раскрывают некоторые идеи по обучению компактных моделей. Все эксперименты находятся в наборе данных ImageNet. Проведено на 8 графических процессорах NVIDIA Tesla V100.
Re-parameterization
Чтобы лучше понять преимущества интеграции репараметризации в обучение компактных моделей, авторы провели исследование абляции, чтобы оценить влияние репараметризации на GhostNetV2 разных размеров. Результаты показаны в таблице 1. При использовании повторной параметризации, в то время как другие параметры обучения остаются неизменными, производительность значительно повышается по сравнению с прямым обучением исходной модели GhostNetV2.
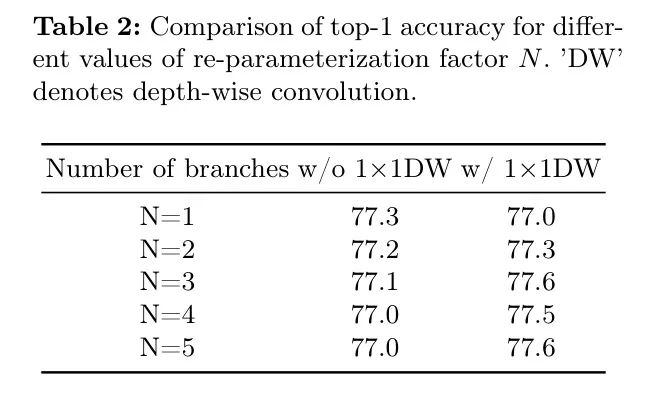
Кроме того, авторы сравнили коэффициенты репараметризации
Различные конфигурации, результаты показаны в Таблице 2. По результатам 1
1 Свертка по глубине играет ключевую роль в репараметризации. Если 1 не используется в перепараметризованной модели
1 глубина свертки, ее производительность даже снижается по мере увеличения количества ветвей. Напротив, при оснащении 1
1 глубинная свертка, модель GhostNetV3
Когда он равен 3, он достигает максимальной точности Top-1 77,6%, что еще больше увеличивает
Это значение не приведет к дополнительному улучшению производительности. Поэтому в последующих экспериментах коэффициент параметризации будет перепараметризован.
Установите значение 3 для лучшей производительности.
Knowledgedistillation
в этом разделе,Авторы оценивают влияние дистилляции знаний на производительность GhostNetV3. Конкретно,В качестве модели учителя выберите ResNet-101, DeiT-BиBeiTV2-B.,Они достигли лучших показателей точности — 77,4%, 81,8% и 86,5% соответственно. Результаты в Таблице 3 показывают изменения производительности при использовании различных моделей учителей. Стоит отметить, что,Существует корреляция между превосходством производительности модели учителя и улучшением производительности модели ученика.
Повышенная производительность улучшенной версии GhostNetV3 подчеркивает важность эффективной модели учителя для компактных моделей в процессе дистилляции знаний.
Авторы далее сравнили потери при дистилляции знаний при различных настройках гиперпараметров, используя BEiTV2-B в качестве модели учителя. Результаты таблицы 4 показывают, что для компактных моделей больше подходят низкие значения температуры. Кроме того, стоит отметить, что при использовании только потерь при дистилляции знаний (т.е.
=1,0), точность топ-1 значительно падает.
Автор также исследует влияние сочетания перепараметризации и дистилляции знаний на производительность GhostNetV2. Как показано в Таблице 5, результаты показывают, что производительность значительно улучшилась (до 79,13%) благодаря использованию дистилляции знаний. Кроме того, это подчеркивает, что при репараметризации1
1Важность глубинной свертки. Эти результаты подчеркивают важность исследования различных методов и их потенциальных комбинаций для улучшения производительности компактных моделей.
Снижение веса. В таблице 7 показано влияние снижения веса на точность GhostNetV2. Результаты показывают, что большее снижение веса значительно снижает производительность модели. Поэтому, учитывая его эффективность на компактных моделях, авторы поддерживают значение снижения веса 0,05 для GhostNetV2.
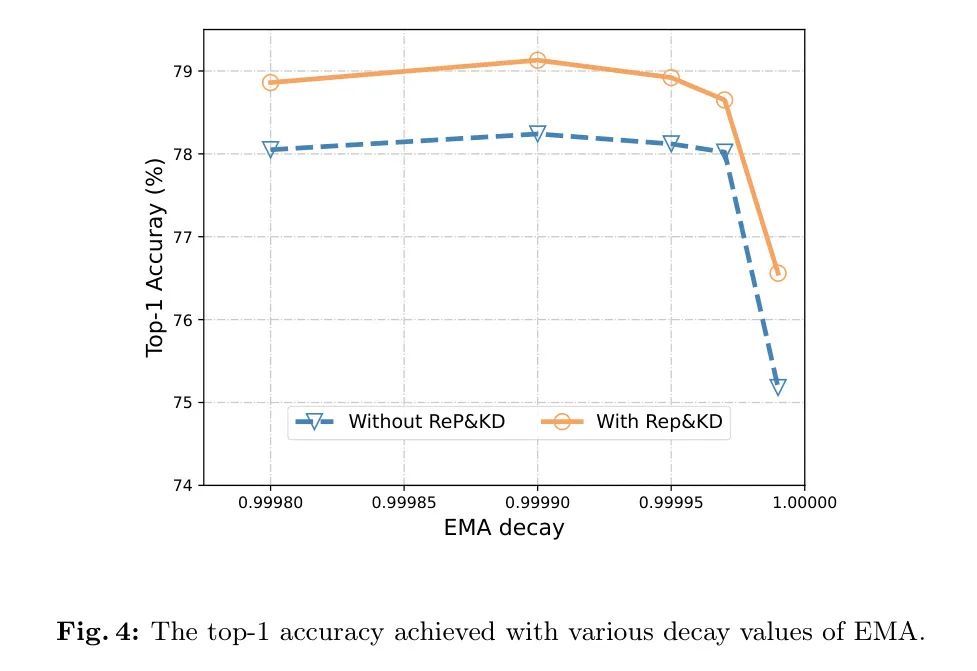
На рисунке 4,Можно заметить, что когда значение затухания EMA составляет 0,99999,Независимо от того, использовать ли тяжелую параметризацию и технологию дистилляции знаний.,производительность вся снизится. Автор предполагает, что это может быть связано со слишком большим значением затухания.,Из-за ослабляющих эффектов текущей итерации. Для компактных моделей,Подходящими считаются значения затухания 0,9999 или 0,99995.,Это похоже на ценность традиционной модели.
DataAugmentation
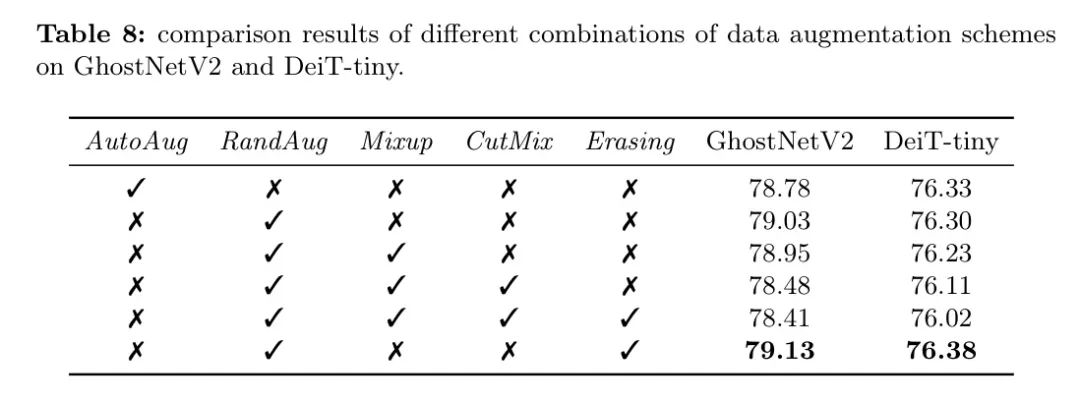
Чтобы сравнить разныеувеличение Влияние схемы данных на производительность облегченной модели,Авторы обучили модели GhostNetV2 и ViT на основе сверточных нейронных сетей (CNN).
DeiT-крошечная модель с использованием различных стратегий улучшения. Результаты показаны в Таблице 8. Замечено, что _случайное улучшение_ и _случайное стирание_ полезны как для GhostNetV2, так и для DeiT-tiny. Напротив,_Mixup_и_CutMix_ оказало неблагоприятное воздействие,Поэтому считается непригодным для компактных моделей.
Comparisonwithothercompactmodels
в этом разделе,Автор сравнил GhostNetV3 с другими компактными моделями с точки зрения размера параметров, количества флопов и задержки на процессорах и мобильных телефонах. Конкретно,Авторы запускали эти модели на рабочем столе Windows, оснащенном процессором Inteli7-8700 с тактовой частотой 3,2 ГГц, для измерения задержки процессора.,Тестировалось на мобильном телефоне ХуавейMate40Pro, оснащенном процессором Kirin.
Используйте 9000CPU, чтобы оценить задержку телефона в конфигурации с входным разрешением 224×224. Чтобы обеспечить минимальную задержку и максимальную согласованность, закройте процессор и все другие приложения на телефоне. Каждая модель выполняется 100 раз для получения надежных результатов.
В Таблице 9 представлено подробное сравнение GhostNetV3 и других компактных моделей с размерами параметров менее 20 МБ. Судя по результатам, самая маленькая архитектура на базе Transformer требует задержки 12,5 мс для вывода на мобильных устройствах, в то время как их точность топ-1 составляет всего 69,0%. Для сравнения, GhostNetV3 достиг первой точности 77,1% при значительно меньшей задержке 7,81 мс. Текущая современная модель MobileFormer достигает точности 79,3%, но имеет задержку 129,58 мс, что неприемлемо для практических приложений. Для сравнения, у GhostNetV3 задержка составляет всего 18,87 мс, что составляет 1,6 мс.
Повышена точность до 80,4%, в 6,8 раза быстрее, чем MobileFormer.
。
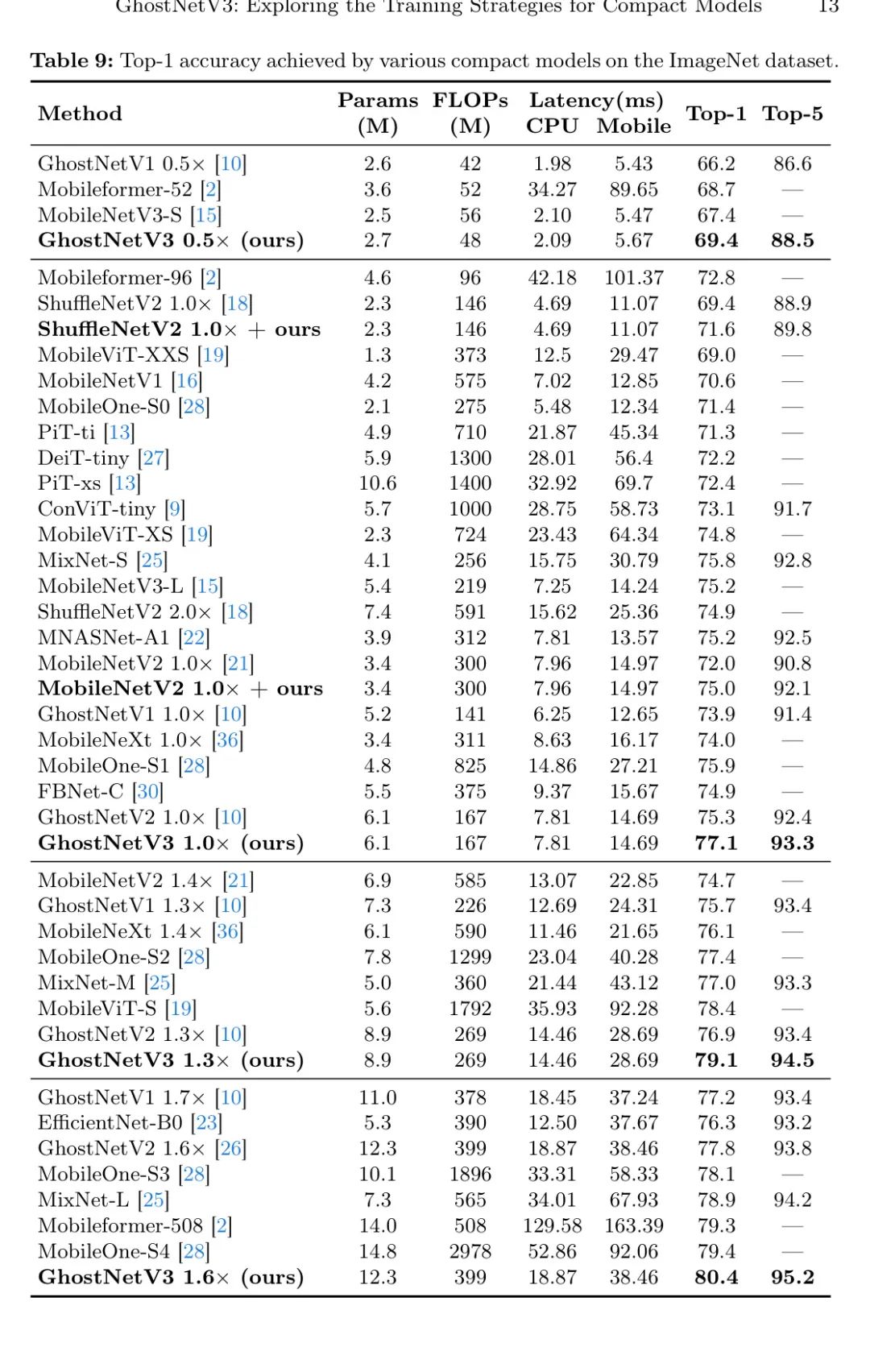
Следующий,Авторы сравнивают GhostNetV3 с другими компактными моделями на базе CNN.,Включает MobileNets,ShuffleNets,MixNet,MNASNet,FBNet,EfficientNet,и Мобил Уан. в,FBNet, MNASNet и MobileNetV3 — модели, основанные на поиске.,Остальные модели созданы вручную. в частности,FBNet принимает стратегию поиска оборудования,И параметры архитектуры поиска MNASNetиMobileNetV3,Например, ширина модели、глубина модели、Размер сверточного фильтра и т. д.
По сравнению с MobileNetV2, GhostNetV21.0
При почти одинаковой задержке (7,81 мс против 7,96 мс) было достигнуто улучшение на 5,1%. GhostNetV21.3
Это также лучше, чем точность Top-1 MobileNeXtиEfficientNet-B0.,Они были на 3,0% и 2,8% выше соответственно. Особенно по сравнению с мощной моделью MobileOne, созданной вручную.,GhostNetV31.0
Точность топ-1 на 1,2% выше, чем у MobileOne-S1, а требуемая задержка вдвое меньше. GhostNetV31.3
Он также на 1,7% точнее, чем MobileOne-S2, а стоимость задержки составляет всего 60%. Кроме того, когда GhostNet1.6
При достижении более высокой точности, чем у MobileOne-S4 (80,4% против 79,4%), задержка ЦП MobileOne в 2,8 раза больше, чем у GhostNetV3.
。
В GhostNetV31.0
По сравнению с компактными моделями на основе поиска,Скорость вывода этой модели выше, чем у FBNet-Ccitefbnet как на процессоре, так и на мобильных телефонах.,А производительность выше на 2,2%. также,GhostNetV31.0
По сравнению с MobileNetV3иMAASNet,сохраняя при этом аналогичную задержку,Точность топ-1 выросла на 1,9%. Эти результаты доказывают, что предложенная автором стратегия обучения эффективна для получения превосходных компактных моделей.,Превосходит существующие методы ручного проектирования и методы проектирования архитектуры на основе поиска.
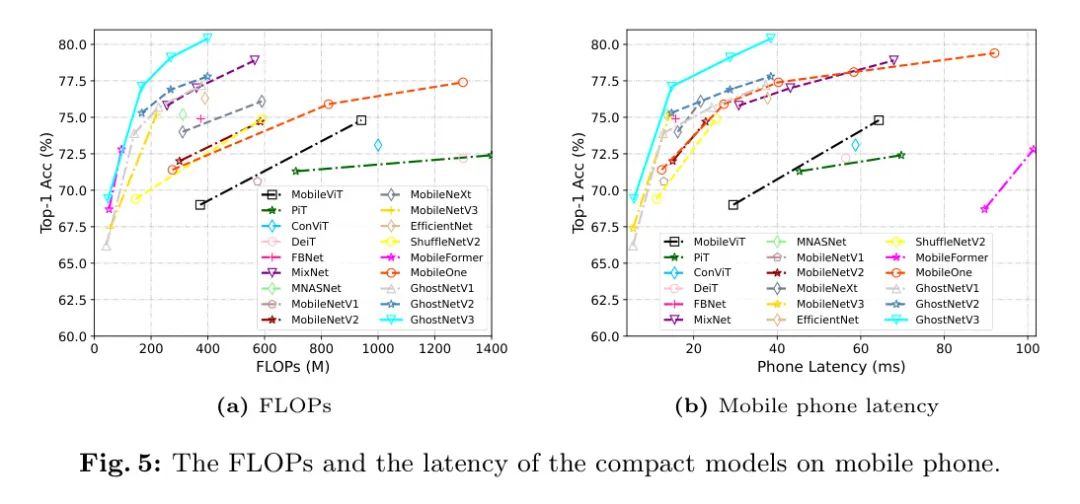
На рис. 5 показано всестороннее сравнение производительности различных компактных моделей. Левое и правое изображения соответственно иллюстрируют FLOP и задержку, измеренную на мобильном телефоне. Стоит отметить, что обученный авторами GhostNetV2 показывает лучший баланс между задержкой и точностью топ-1 на мобильных устройствах.
Другие компактные модели. Для дальнейшей демонстрации масштабируемости предлагаемой стратегии обучения.,Авторы применяют их для обучения двух других широко используемых компактных моделей: ShuffleNetV2 и MobileNetV2. Результаты в Таблице 9 показывают,Стратегия автора позволяет повысить точность топ-1 ShuffleNetV2 и MobileNetV2 на 2,2% и 3,0% соответственно.
Extendtoobjectdetection
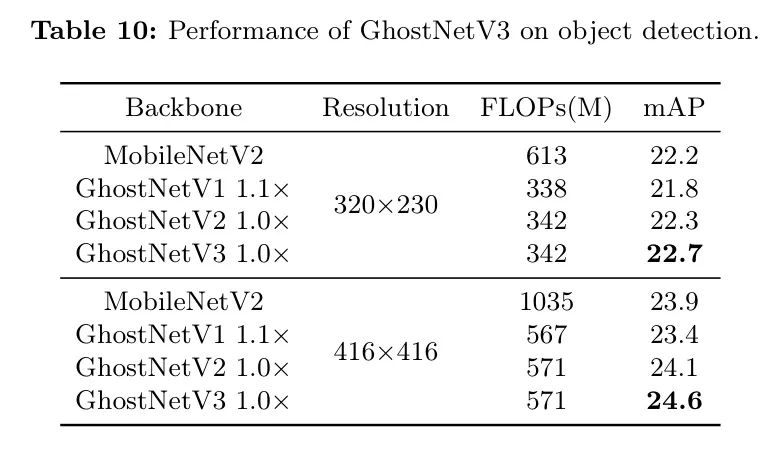
Чтобы выяснить, хорошо ли работают квитанции об обучении на других наборах данных.,Автор расширяет эксперимент на задачу обнаружения целей на наборе данных COCO.,проверить их обобщающую способность. Результаты показаны в Таблице 10. Стоит отметить, что,Результаты задач классификации также применимы к задачам обнаружения объектов. Например,При обоих используемых настройках разрешения,Модель GhostNetV3 превосходит GhostNetV2 со значениями mAP 0,4 и 0,5 соответственно. также,GhostNetV3 требует меньше FLOP во время вывода,При этом производительность также превзошла MobileNetV2.
6Conclusion
в этой статье,Авторы комплексно изучают стратегии обучения, направленные на повышение производительности существующих компактных моделей. Эти методы включают перепараметризацию, дистилляцию знаний, увеличение данных и корректировку плана обучения.,И нет необходимости изменять архитектуру модели в процессе вывода. в частности,GhostNetV3, обученный автором, достигает оптимального баланса между точностью и стоимостью вывода.,Это было проверено на платформах ЦП и мобильных телефонов. Автор также будет работать над другими компактными моделями.,Например, применение предложенной стратегии обучения на MobileNetV2 и ShuffleNetV2.,Наблюдалось значительное улучшение точности. Автор надеется, что его исследования могут предоставить ценную информацию и опыт для будущих исследований в этой области.
ссылка
GhostNetV3: ExploringtheTrainingStrategiesforCompactModels.



Учебное пособие по Jetpack Compose для начинающих, базовые элементы управления и макет

Код js веб-страницы, фон частицы, код спецэффектов

【новый! Суперподробное】Полное руководство по свойствам компонентов Figma.

🎉Обязательно к прочтению новичкам: полное руководство по написанию мини-программ WeChat с использованием программного обеспечения Cursor.

[Забавный проект Docker] VoceChat — еще одно приложение для мгновенного чата (IM)! Может быть встроен в любую веб-страницу!

Как реализовать переход по странице в HTML (html переходит на указанную страницу)

Как решить проблему зависания и низкой скорости при установке зависимостей с помощью npm. Существуют ли доступные источники npm, которые могут решить эту проблему?

Серия From Zero to Fun: Uni-App WeChat Payment Practice WeChat авторизует вход в систему и украшает страницу заказа, создает интерфейс заказа и инициирует запрос заказа

Серия uni-app: uni.navigateЧтобы передать скачок значения

Апплет WeChat настраивает верхнюю панель навигации и адаптируется к различным моделям.

JS-время конвертации

Обеспечьте бесперебойную работу ChromeDriver 125: советы по решению проблемы chromedriver.exe не найдены

Поле комментария, щелчок мышью, специальные эффекты, js-код

Объект массива перемещения объекта JS

Как открыть разрешение на позиционирование апплета WeChat_Как использовать WeChat для определения местонахождения друзей

Я даю вам два набора из 18 простых в использовании фонов холста Power BI, так что вам больше не придется возиться с цветами!

Получить текущее время в js_Как динамически отображать дату и время в js

Вам необходимо изучить сочетания клавиш vsCode для форматирования и организации кода, чтобы вам больше не приходилось настраивать формат вручную.

У ChatGPT большое обновление. Всего за 45 минут пресс-конференция показывает, что OpenAI сделал еще один шаг вперед.

Copilot облачной разработки — упрощение разработки

Микросборка xChatGPT с низким кодом, создание апплета чат-бота с искусственным интеллектом за пять шагов

CUDA Out of Memory: идеальное решение проблемы нехватки памяти CUDA

Анализ кластеризации отдельных ячеек, который должен освоить каждый&MarkerгенетическийВизуализация

vLLM: мощный инструмент для ускорения вывода ИИ

CodeGeeX: мощный инструмент генерации кода искусственного интеллекта, который можно использовать бесплатно в дополнение к второму пилоту.

Машинное обучение Реальный бой LightGBM + настройка параметров случайного поиска: точность 96,67%

Бесшовная интеграция, мгновенный интеллект [1]: платформа больших моделей Dify-LLM, интеграция без кодирования и встраивание в сторонние системы, более 42 тысяч звезд, чтобы стать свидетелями эксклюзивных интеллектуальных решений.

LM Studio для создания локальных больших моделей

Как определить количество слоев и нейронов скрытых слоев нейронной сети?
