Фреймворк с открытым исходным кодом, позволяющий точно настраивать большие модели без использования кода — Axolotl.
Что такое Аксолотль?
Axolotl[1] — это инструмент, предназначенный для упрощения процесса тонкой настройки различных моделей ИИ, поддерживающий множество конфигураций и архитектур.
Функции:
• Обучение различных моделей Huggingface, таких как лама, пифия, сокол, mpt. • Поддержка Fullfinetune, lora, qlora, relora и gptq. • Переопределение пользовательской конфигурации с помощью простого файла yaml или интерфейса командной строки. • Загрузка различных форматов наборов данных, использование пользовательских форматов или встроенного слова. набор данных сегментации • Интегрированный xformer, флэш-внимание, веревка масштабирование и мультиупаковка • Поддержка одного или нескольких графических процессоров, ускорение через FSDP или Deepspeed • Легкость запуска с помощью Docker локально или в облаке • Запись результатов и дополнительных контрольных точек в wandb • И многое другое!
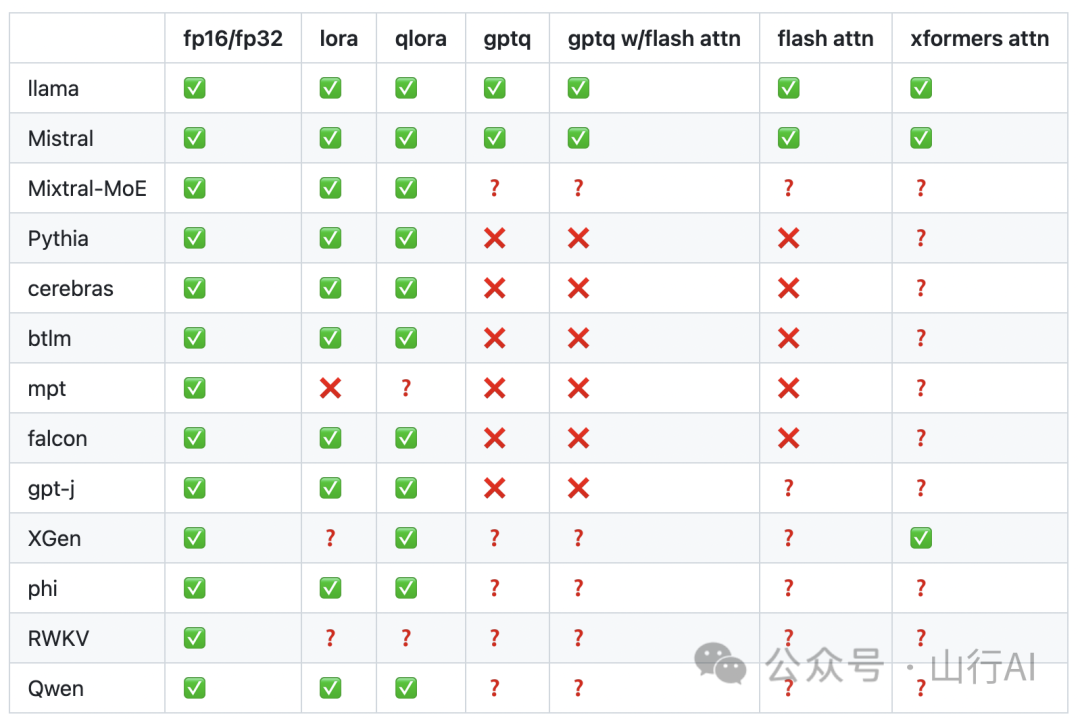
Поддерживаемые модели
Что такое тонкая настройка?
Предварительно обученная модель в основном приобретает общие знания языка и ей не хватает конкретных знаний по конкретным задачам или областям. Чтобы восполнить этот пробел, следующими шагами будут точные настройки.
Точная настройка позволяет нам сосредоточиться на возможностях предварительно обученной модели и оптимизировать ее производительность при решении конкретных задач. Точная настройка означает дальнейшее обучение предварительно обученной модели с использованием новых задач и новых данных. Обычно это означает обучение всей предварительно обученной модели, включая все ее части и настройки. Но это может потребовать значительных вычислительных ресурсов и времени, особенно для больших моделей. С другой стороны, точная настройка с эффективным использованием параметров — это метод тонкой настройки, который фокусируется только на некоторых настройках предварительно обученной модели. Во время обучения он находит наиболее важные для новой задачи параметры и лишь модифицирует их. Это ускоряет точную настройку с эффективным использованием параметров, поскольку не требует обработки всех параметров модели.
Стек реализации
• Runpod: RunPod[2] — это платформа облачных вычислений, в основном используемая для приложений искусственного интеллекта и машинного обучения, предоставляющая экземпляры графических процессоров, бессерверные графические процессоры и терминалы искусственного интеллекта. Мы использовали 1 графический процессор NVIDIA емкостью 80 ГБ. • Аксолотль: Инструмент для упрощения тонкой настройки различных моделей искусственного интеллекта. •Набор данных: teknium/GPT4-LLM-Cleaned[3]•LLM: модель openlm-research/open_llama_3b_v2[4]
Тонкая настройка реализации
Установите необходимые зависимости
!git clone https://github.com/OpenAccess-AI-Collective/axolotl.git Перейдите в папку аксолотля
%cd axolotl
####### RESPONSE ###############
/workspace/axolotl
/usr/local/lib/python3.10/dist-packages/IPython/core/magics/osm.py:417: UserWarning: using dhist requires you to install the `pickleshare` library.
self.shell.db['dhist'] = compress_dhist(dhist)[-100:] !pip install packaging
!pip install -e .'[flash-attn,deepspedd]' После установки зависимостей загляните в папку примеров. Он содержит несколько моделей LLM с соответствующими профилями лоры. Здесь мы используем openllama 3b в качестве базового LLM. Мы рассмотрим его файл конфигурации ./axolot/examples[5]/openllama-3b[6]/lora.yml. Файл lora.yaml содержит конфигурацию, необходимую для точной настройки базовой модели.

Что такое Ло РА?
•Это метод обучения, предназначенный для ускорения процесса обучения LLM (модель изучения языка). • Это помогает снизить потребление памяти за счет введения пары весовых матриц с разложением по рангам. Он разлагает матрицу весов LLM на матрицу низкого ранга. Это уменьшает количество параметров, которые необходимо обучить, сохраняя при этом производительность исходной модели. •Эти весовые матрицы добавляются к существующим весовым матрицам (предварительно обученным).
Важные понятия, связанные с LoRA
• Сохранение предварительно обученных весов: LoRA сохраняет ранее обученные веса замороженных слоев. Это помогает предотвратить катастрофическое забывание. LoRA не только сохраняет существующие знания модели, но и хорошо адаптируется к новым данным. • Переносимость обучающих весов: матрица ранговой декомпозиции, используемая в LoRA, имеет значительно меньше параметров. Это позволяет использовать и переносить обученные веса LoRA в другие среды. •Интеграция со слоем внимания: Весовая матрица LoRA в основном интегрирована в уровень внимания исходной модели. Это позволяет контролировать контекст, в котором модель адаптируется к новым данным. • Высокая эффективность использования памяти, поскольку сокращает объем вычислений в процессе точной настройки в 3 раза. Конфигурация в файле lora.yaml. Мы можем установить базовую модель и набор обучающих данных, указав соответствующие значения в параметрах base_model и datasets в файле lora.yaml.
base_model: openlm-research/open_llama_3b_v2
model_type: LlamaForCausalLM
tokenizer_type: LlamaTokenizer
load_in_8bit: true
load_in_4bit: false
strict: false
push_dataset_to_hub:
datasets:
- path: teknium/GPT4-LLM-Cleaned
type: alpaca
dataset_prepared_path:
val_set_size: 0.02
adapter: lora
lora_model_dir:
sequence_len: 1024
sample_packing: true
lora_r: 8
lora_alpha: 16
lora_dropout: 0.0
lora_target_modules:
- gate_proj
- down_proj
- up_proj
- q_proj
- v_proj
- k_proj
- o_proj
lora_fan_in_fan_out:
wandb_project:
wandb_entity:
wandb_watch:
wandb_name:
wandb_log_model:
output_dir: ./lora-out
gradient_accumulation_steps: 1
micro_batch_size: 2
num_epochs: 4
optimizer: adamw_bnb_8bit
torchdistx_path:
lr_scheduler: cosine
learning_rate: 0.0002
train_on_inputs: false
group_by_length: false
bf16: false
fp16: true
tf32: false
gradient_checkpointing: true
early_stopping_patience:
resume_from_checkpoint:
local_rank:
logging_steps: 1
xformers_attention:
flash_attention: true
gptq_groupsize:
gptq_model_v1:
warmup_steps: 20
evals_per_epoch: 4
saves_per_epoch: 1
debug:
deepspeed:
weight_decay: 0.1
fsdp:
fsdp_config:
special_tokens:
bos_token: "<s>"
eos_token: "</s>"
unk_token: "<unk>"Лора гиперпараметры
lora_r: Он определяет, сколько матриц разложения ранга применяется к весовой матрице, чтобы уменьшить потребление памяти и вычислительные требования. Согласно документу LoRA, значение уровня по умолчанию или минимальное значение равно 8.
•Более высокие уровни приводят к лучшим результатам, но требуют более высокой вычислительной мощности. •По мере увеличения сложности обучающих данных требуются более высокие уровни. • Чтобы обеспечить полную точную настройку, ранг весовой матрицы должен соответствовать количеству скрытых слоев базовой модели. Скрытый размер модели можно узнать из config.json («num_hidden_layers»: 32).

lora_alpha: коэффициент масштабирования LoRA определяет вклад модели в корректировку обновлений матрицы во время обучения.
• Более низкие значения альфа придают больший вес исходным данным и в большей степени поддерживают существующие знания модели, т. е. они отдают предпочтение исходным знаниям модели.
lora_target_modules:Он определяет конкретные веса и матрицы для обучения.。Самое основное этоq_proj(вектор запроса)иv_proj(вектор значений)。
•Матрица проекции Q применяется к вектору запроса в механизме внимания в блоке преобразователей. Он преобразует скрытые состояния в необходимые измерения для эффективного представления запросов. • Матрица проекции V преобразует скрытые состояния в необходимые измерения для эффективного представления значений.
Lora Fine-tune
! accelerate launch -m axolotl.cli.train examples/openllama-3b/lora.yml The following values were not passed to `accelerate launch` and had defaults used instead:
`--num_processes` was set to a value of `1`
`--num_machines` was set to a value of `1`
`--mixed_precision` was set to a value of `'no'`
`--dynamo_backend` was set to a value of `'no'`
To avoid this warning pass in values for each of the problematic parameters or run `accelerate config`.
/usr/local/lib/python3.10/dist-packages/transformers/deepspeed.py:23: FutureWarning: transformers.deepspeed module is deprecated and will be removed in a future version. Please import deepspeed modules directly from transformers.integrations
warnings.warn(
[2024-01-01 08:31:18,370] [INFO] [datasets.<module>:58] [PID:2201] PyTorch version 2.0.1+cu118 available.
[2024-01-01 08:31:19,417] [INFO] [axolotl.validate_config:156] [PID:2201] [RANK:0] bf16 support detected, but not enabled for this configuration.
[2024-01-01 08:31:19,417] [WARNING] [axolotl.validate_config:176] [PID:2201] [RANK:0] `pad_to_sequence_len: true` is recommended when using sample_packing
config.json: 100%|█████████████████████████████| 506/506 [00:00<00:00, 2.10MB/s]
[2024-01-01 08:31:19,656] [INFO] [axolotl.normalize_config:150] [PID:2201] [RANK:0] GPU memory usage baseline: 0.000GB (+0.811GB misc)
dP dP dP
88 88 88
.d8888b. dP. .dP .d8888b. 88 .d8888b. d8888P 88
88' `88 `8bd8' 88' `88 88 88' `88 88 88
88. .88 .d88b. 88. .88 88 88. .88 88 88
`88888P8 dP' `dP `88888P' dP `88888P' dP dP
[2024-01-01 08:31:19,660] [WARNING] [axolotl.scripts.check_user_token:342] [PID:2201] [RANK:0] Error verifying HuggingFace token. Remember to log in using `huggingface-cli login` and get your access token from https://huggingface.co/settings/tokens if you want to use gated models or datasets.
tokenizer_config.json: 100%|███████████████████| 593/593 [00:00<00:00, 2.69MB/s]
tokenizer.model: 100%|███████████████████████| 512k/512k [00:00<00:00, 36.7MB/s]
special_tokens_map.json: 100%|█████████████████| 330/330 [00:00<00:00, 1.01MB/s]
You are using the default legacy behaviour of the <class 'transformers.models.llama.tokenization_llama.LlamaTokenizer'>. This is expected, and simply means that the `legacy` (previous) behavior will be used so nothing changes for you. If you want to use the new behaviour, set `legacy=False`. This should only be set if you understand what it means, and thoroughly read the reason why this was added as explained in https://github.com/huggingface/transformers/pull/24565
[2024-01-01 08:31:20,716] [DEBUG] [axolotl.load_tokenizer:185] [PID:2201] [RANK:0] EOS: 2 / </s>
[2024-01-01 08:31:20,716] [DEBUG] [axolotl.load_tokenizer:186] [PID:2201] [RANK:0] BOS: 1 / <s>~~[2024-01-01 08:31:20,717] [DEBUG] [axolotl.load_tokenizer:187] [PID:2201] [RANK:0] PAD: 2 /~~ </s>
[2024-01-01 08:31:20,717] [DEBUG] [axolotl.load_tokenizer:188] [PID:2201] [RANK:0] UNK: 0 / <unk>
[2024-01-01 08:31:20,717] [INFO] [axolotl.load_tokenizer:193] [PID:2201] [RANK:0] No Chat template selected. Consider adding a chat template for easier inference.
[2024-01-01 08:31:20,717] [INFO] [axolotl.load_tokenized_prepared_datasets:147] [PID:2201] [RANK:0] Unable to find prepared dataset in last_run_prepared/f9e5091071bf5ab6f7287bd5565a5f24
[2024-01-01 08:31:20,717] [INFO] [axolotl.load_tokenized_prepared_datasets:148] [PID:2201] [RANK:0] Loading raw datasets...
[2024-01-01 08:31:20,717] [INFO] [axolotl.load_tokenized_prepared_datasets:153] [PID:2201] [RANK:0] No seed provided, using default seed of 42
Downloading readme: 100%|███████████████████████| 501/501 [00:00<00:00, 343kB/s]
/usr/local/lib/python3.10/dist-packages/huggingface_hub/repocard.py:105: UserWarning: Repo card metadata block was not found. Setting CardData to empty.
warnings.warn("Repo card metadata block was not found. Setting CardData to empty.")
Downloading data: 100%|████████████████████| 36.0M/36.0M [00:01<00:00, 27.0MB/s]
Downloading data: 100%|████████████████████| 4.91M/4.91M [00:00<00:00, 9.16MB/s]
Generating train split: 54568 examples [00:00, 187030.30 examples/s]
Map (num_proc=64): 13%|█▍ | 7057/54568 [00:11<03:55, 202.13 examples/s][2024-01-01 08:31:39,365] [WARNING] [axolotl._tokenize:66] [PID:2275] [RANK:0] Empty text requested for tokenization.
Map (num_proc=64): 100%|█████████| 54568/54568 [00:17<00:00, 3180.11 examples/s]
[2024-01-01 08:31:45,017] [INFO] [axolotl.load_tokenized_prepared_datasets:362] [PID:2201] [RANK:0] merging datasets
[2024-01-01 08:31:45,023] [INFO] [axolotl.load_tokenized_prepared_datasets:369] [PID:2201] [RANK:0] Saving merged prepared dataset to disk... last_run_prepared/f9e5091071bf5ab6f7287bd5565a5f24
Saving the dataset (1/1 shards): 100%|█| 54568/54568 [00:00<00:00, 524866.32 exa
Filter (num_proc=64): 100%|█████| 53476/53476 [00:02<00:00, 20761.86 examples/s]
Filter (num_proc=64): 100%|████████| 1092/1092 [00:00<00:00, 2586.61 examples/s]
Map (num_proc=64): 100%|████████| 53476/53476 [00:02<00:00, 19739.44 examples/s]
Map (num_proc=64): 100%|███████████| 1092/1092 [00:00<00:00, 2167.35 examples/s]
[2024-01-01 08:31:54,825] [DEBUG] [axolotl.log:60] [PID:2201] [RANK:0] total_num_tokens: 188373
[2024-01-01 08:31:54,833] [DEBUG] [axolotl.log:60] [PID:2201] [RANK:0] `total_supervised_tokens: 38104`
[2024-01-01 08:32:01,085] [INFO] [axolotl.utils.samplers.multipack._len_est:178] [PID:2201] [RANK:0] packing_efficiency_estimate: 1.0 total_num_tokens per device: 188373
[2024-01-01 08:32:01,085] [DEBUG] [axolotl.log:60] [PID:2201] [RANK:0] data_loader_len: 181
[2024-01-01 08:32:01,085] [INFO] [axolotl.log:60] [PID:2201] [RANK:0] sample_packing_eff_est across ranks: [0.9017549402573529]
[2024-01-01 08:32:01,086] [DEBUG] [axolotl.log:60] [PID:2201] [RANK:0] sample_packing_eff_est: None
[2024-01-01 08:32:01,086] [DEBUG] [axolotl.log:60] [PID:2201] [RANK:0] total_num_steps: 181
[2024-01-01 08:32:01,132] [DEBUG] [axolotl.log:60] [PID:2201] [RANK:0] total_num_tokens: 10733491
[2024-01-01 08:32:01,495] [DEBUG] [axolotl.log:60] [PID:2201] [RANK:0] `total_supervised_tokens: 6735490`
[2024-01-01 08:32:01,663] [INFO] [axolotl.utils.samplers.multipack._len_est:178] [PID:2201] [RANK:0] packing_efficiency_estimate: 1.0 total_num_tokens per device: 10733491
[2024-01-01 08:32:01,664] [DEBUG] [axolotl.log:60] [PID:2201] [RANK:0] data_loader_len: 10376
[2024-01-01 08:32:01,664] [INFO] [axolotl.log:60] [PID:2201] [RANK:0] sample_packing_eff_est across ranks: [0.8623549818747429]
[2024-01-01 08:32:01,664] [DEBUG] [axolotl.log:60] [PID:2201] [RANK:0] sample_packing_eff_est: 0.87
[2024-01-01 08:32:01,664] [DEBUG] [axolotl.log:60] [PID:2201] [RANK:0] total_num_steps: 10376
[2024-01-01 08:32:01,671] [DEBUG] [axolotl.train.log:60] [PID:2201] [RANK:0] loading tokenizer... openlm-research/open_llama_3b_v2
[2024-01-01 08:32:01,945] [DEBUG] [axolotl.load_tokenizer:185] [PID:2201] [RANK:0] EOS: 2 / </s>
[2024-01-01 08:32:01,945] [DEBUG] [axolotl.load_tokenizer:186] [PID:2201] [RANK:0] BOS: 1 / <s>~~[2024-01-01 08:32:01,945] [DEBUG] [axolotl.load_tokenizer:187] [PID:2201] [RANK:0] PAD: 2 /~~ </s>
[2024-01-01 08:32:01,945] [DEBUG] [axolotl.load_tokenizer:188] [PID:2201] [RANK:0] UNK: 0 / <unk>
[2024-01-01 08:32:01,946] [INFO] [axolotl.load_tokenizer:193] [PID:2201] [RANK:0] No Chat template selected. Consider adding a chat template for easier inference.
[2024-01-01 08:32:01,946] [DEBUG] [axolotl.train.log:60] [PID:2201] [RANK:0] loading model and peft_config...
[2024-01-01 08:32:02,058] [INFO] [axolotl.load_model:239] [PID:2201] [RANK:0] patching with flash attention for sample packing
[2024-01-01 08:32:02,058] [INFO] [axolotl.load_model:285] [PID:2201] [RANK:0] patching _expand_mask
pytorch_model.bin: 100%|████████████████████| 6.85G/6.85G [01:01<00:00, 111MB/s]
generation_config.json: 100%|███████████████████| 137/137 [00:00<00:00, 592kB/s]
[2024-01-01 08:33:13,199] [INFO] [axolotl.load_model:517] [PID:2201] [RANK:0] GPU memory usage after model load: 3.408GB (+0.334GB cache, +1.952GB misc)
[2024-01-01 08:33:13,204] [INFO] [axolotl.load_model:540] [PID:2201] [RANK:0] converting PEFT model w/ prepare_model_for_kbit_training
[2024-01-01 08:33:13,208] [INFO] [axolotl.load_model:552] [PID:2201] [RANK:0] converting modules to torch.float16 for flash attention
[2024-01-01 08:33:13,238] [WARNING] [auto_gptq.nn_modules.qlinear.qlinear_cuda.<module>:16] [PID:2201] CUDA extension not installed.
[2024-01-01 08:33:13,238] [WARNING] [auto_gptq.nn_modules.qlinear.qlinear_cuda_old.<module>:15] [PID:2201] CUDA extension not installed.
trainable params: 12,712,960 || all params: 3,439,186,560 || trainable%: 0.36965020007521776
[2024-01-01 08:33:13,490] [INFO] [axolotl.load_model:582] [PID:2201] [RANK:0] GPU memory usage after adapters: 3.455GB (+1.099GB cache, +1.952GB misc)
[2024-01-01 08:33:13,526] [INFO] [axolotl.train.log:60] [PID:2201] [RANK:0] Pre-saving adapter config to ./lora-out
[2024-01-01 08:33:13,529] [INFO] [axolotl.train.log:60] [PID:2201] [RANK:0] Starting trainer...
[2024-01-01 08:33:13,935] [INFO] [axolotl.utils.samplers.multipack._len_est:178] [PID:2201] [RANK:0] packing_efficiency_estimate: 0.87 total_num_tokens per device: 10733491
[2024-01-01 08:33:13,982] [INFO] [axolotl.utils.samplers.multipack._len_est:178] [PID:2201] [RANK:0] packing_efficiency_estimate: 0.87 total_num_tokens per device: 10733491
0%| | 0/1490 [00:00<?, ?it/s][2024-01-01 08:33:14,084] [INFO] [axolotl.utils.samplers.multipack._len_est:178] [PID:2201] [RANK:0] packing_efficiency_estimate: 0.87 total_num_tokens per device: 10733491
{'loss': 1.3828, 'learning_rate': 1e-05, 'epoch': 0.0}
0%| | 1/1490 [00:05<2:05:44, 5.07s/it][2024-01-01 08:33:19,125] [INFO] [axolotl.utils.samplers.multipack._len_est:178] [PID:2201] [RANK:0] packing_efficiency_estimate: 0.87 total_num_tokens per device: 188373
[2024-01-01 08:33:19,322] [INFO] [axolotl.utils.samplers.multipack._len_est:178] [PID:2201] [RANK:0] packing_efficiency_estimate: 0.87 total_num_tokens per device: 188373
[2024-01-01 08:33:19,323] [INFO] [axolotl.utils.samplers.multipack._len_est:178] [PID:2201] [RANK:0] packing_efficiency_estimate: 0.87 total_num_tokens per device: 188373
0%| | 0/208 [00:00<?, ?it/s][2024-01-01 08:33:19,510] [INFO] [axolotl.utils.samplers.multipack._len_est:178] [PID:2201] [RANK:0] packing_efficiency_estimate: 0.87 total_num_tokens per device: 188373
1%|▍ | 2/208 [00:00<00:19, 10.70it/s][2024-01-01 08:33:19,697] [INFO] [axolotl.utils.samplers.multipack._len_est:178] [PID:2201] [RANK:0] packing_efficiency_estimate: 0.87 total_num_tokens per device: 188373
[2024-01-01 08:33:19,878] [INFO] [axolotl.utils.samplers.multipack._len_est:178] [PID:2201] [RANK:0] packing_efficiency_estimate: 0.87 total_num_tokens per device: 188373
2%|▊ | 4/208 [00:00<00:29, 6.83it/s][2024-01-01 08:33:20,056] [INFO] [axolotl.utils.samplers.multipack._len_est:178] [PID:2201] [RANK:0] packing_efficiency_estimate: 0.87 total_num_tokens per device: 188373
......
98%|████████████████████████████████████████ | 203/208 [00:34<00:00, 5.76it/s][2024-01-01 08:33:54,274] [INFO] [axolotl.utils.samplers.multipack._len_est:178] [PID:2201] [RANK:0] packing_efficiency_estimate: 0.87 total_num_tokens per device: 188373
98%|████████████████████████████████████████▏| 204/208 [00:34<00:00, 5.76it/s][2024-01-01 08:33:54,436] [INFO] [axolotl.utils.samplers.multipack._len_est:178] [PID:2201] [RANK:0] packing_efficiency_estimate: 0.87 total_num_tokens per device: 188373
{'eval_loss': 1.7242642641067505, 'eval_runtime': 35.3126, 'eval_samples_per_second': 30.924, 'eval_steps_per_second': 30.924, 'epoch': 0.0}
0%| | 1/1490 [00:40<2:05:44, 5.07s/it]
99%|████████████████████████████████████████▍| 205/208 [00:35<00:00, 5.87it/s]
[2024-01-01 08:33:58,624] [INFO] [axolotl.callbacks.on_step_end:124] [PID:2201] [RANK:0] GPU memory usage while training: 3.502GB (+1.607GB cache, +2.321GB misc)
{'loss': 1.4792, 'learning_rate': 2e-05, 'epoch': 0.0}
{'loss': 1.3653, 'learning_rate': 3e-05, 'epoch': 0.0}
{'loss': 1.3331, 'learning_rate': 4e-05, 'epoch': 0.0}
......
{'loss': 1.1553, 'learning_rate': 0.00017301379386534054, 'epoch': 0.25}
{'loss': 1.0537, 'learning_rate': 0.0001728675966533755, 'epoch': 0.25}
25%|█████████▌ | 373/1490 [26:25<1:17:08, 4.14s/it][2024-01-01 08:59:39,715] [INFO] [axolotl.utils.samplers.multipack._len_est:178] [PID:2201] [RANK:0] packing_efficiency_estimate: 0.87 total_num_tokens per device: 188373
[2024-01-01 08:59:39,894] [INFO] [axolotl.utils.samplers.multipack._len_est:178] [PID:2201] [RANK:0] packing_efficiency_estimate: 0.87 total_num_tokens per device: 188373
[2024-01-01 08:59:39,894] [INFO] [axolotl.utils.samplers.multipack._len_est:178] [PID:2201] [RANK:0] packing_efficiency_estimate: 0.87 total_num_tokens per device: 188373
0%| | 0/208 [00:00<?, ?it/s][2024-01-01 08:59:40,062] [INFO] [axolotl.utils.samplers.multipack._len_est:178] [PID:2201] [RANK:0] packing_efficiency_estimate: 0.87 total_num_tokens per device: 188373
1%|▍ | 2/208 [00:00<00:17, 11.94it/s][2024-01-01 08:59:40,232] [INFO] [axolotl.utils.samplers.multipack._len_est:178] [PID:2201] [RANK:0] packing_efficiency_estimate: 0.87 total_num_tokens per device: 188373
[2024-01-01 08:59:40,400] [INFO] [axolotl.utils.samplers.multipack._len_est:178] [PID:2201] [RANK:0] packing_efficiency_estimate: 0.87 total_num_tokens per device: 188373
2%|▊ | 4/208 [00:00<00:27, 7.47it/s][2024-01-01 08:59:40,568] [INFO] [axolotl.utils.samplers.multipack._len_est:178] [PID:2201] [RANK:0] packing_efficiency_estimate: 0.87 total_num_tokens per device: 188373
......
98%|████████████████████████████████████████ | 203/208 [00:34<00:00, 5.82it/s][2024-01-01 09:00:14,117] [INFO] [axolotl.utils.samplers.multipack._len_est:178] [PID:2201] [RANK:0] packing_efficiency_estimate: 0.87 total_num_tokens per device: 188373
98%|████████████████████████████████████████▏| 204/208 [00:34<00:00, 5.75it/s][2024-01-01 09:00:14,286] [INFO] [axolotl.utils.samplers.multipack._len_est:178] [PID:2201] [RANK:0] packing_efficiency_estimate: 0.87 total_num_tokens per device: 188373
{'eval_loss': 1.0763916969299316, 'eval_runtime': 34.5726, 'eval_samples_per_second': 31.586, 'eval_steps_per_second': 31.586, 'epoch': 0.25}
25%|█████████▌ | 373/1490 [27:00<1:17:08, 4.14s/it]
99%|████████████████████████████████████████▍| 205/208 [00:34<00:00, 5.81it/s]
{'loss': 1.2005, 'learning_rate': 0.00017272106662911973, 'epoch': 0.25}
{'loss': 1.1717, 'learning_rate': 0.0001725742044618282, 'epoch': 0.25}
......
{'loss': 1.0863, 'learning_rate': 0.00010235063511836416, 'epoch': 0.5}
{'loss': 1.0656, 'learning_rate': 0.00010213697517873015, 'epoch': 0.5}
{'loss': 1.1216, 'learning_rate': 0.00010192330547876871, 'epoch': 0.5}
50%|████████████████████ | 746/1490 [52:57<51:59, 4.19s/it][2024-01-01 09:26:11,256] [INFO] [axolotl.utils.samplers.multipack._len_est:178] [PID:2201] [RANK:0] packing_efficiency_estimate: 0.87 total_num_tokens per device: 188373
[2024-01-01 09:26:11,436] [INFO] [axolotl.utils.samplers.multipack._len_est:178] [PID:2201] [RANK:0] packing_efficiency_estimate: 0.87 total_num_tokens per device: 188373
[2024-01-01 09:26:11,437] [INFO] [axolotl.utils.samplers.multipack._len_est:178] [PID:2201] [RANK:0] packing_efficiency_estimate: 0.87 total_num_tokens per device: 188373
0%| | 0/208 [00:00<?, ?it/s][2024-01-01 09:26:11,607] [INFO] [axolotl.utils.samplers.multipack._len_est:178] [PID:2201] [RANK:0] packing_efficiency_estimate: 0.87 total_num_tokens per device: 188373
1%|▍ | 2/208 [00:00<00:17, 11.79it/s][2024-01-01 09:26:11,779] [INFO] [axolotl.utils.samplers.multipack._len_est:178] [PID:2201] [RANK:0] packing_efficiency_estimate: 0.87 total_num_tokens per device: 188373
[2024-01-01 09:26:11,947] [INFO] [axolotl.utils.samplers.multipack._len_est:178] [PID:2201] [RANK:0] packing_efficiency_estimate: 0.87 total_num_tokens per device: 188373
......
98%|████████████████████████████████████████ | 203/208 [00:34<00:00, 5.92it/s][2024-01-01 09:26:45,864] [INFO] [axolotl.utils.samplers.multipack._len_est:178] [PID:2201] [RANK:0] packing_efficiency_estimate: 0.87 total_num_tokens per device: 188373
98%|████████████████████████████████████████▏| 204/208 [00:34<00:00, 5.89it/s][2024-01-01 09:26:46,027] [INFO] [axolotl.utils.samplers.multipack._len_est:178] [PID:2201] [RANK:0] packing_efficiency_estimate: 0.87 total_num_tokens per device: 188373
{'eval_loss': 1.0423786640167236, 'eval_runtime': 34.7727, 'eval_samples_per_second': 31.404, 'eval_steps_per_second': 31.404, 'epoch': 0.5}
50%|████████████████████ | 746/1490 [53:31<51:59, 4.19s/it]
99%|████████████████████████████████████████▍| 205/208 [00:34<00:00, 5.95it/s]
{'loss': 1.1375, 'learning_rate': 0.00010170962699438553, 'epoch': 0.5}
{'loss': 1.0644, 'learning_rate': 0.00010149594070152638, 'epoch': 0.5}
......
{'loss': 1.1636, 'learning_rate': 2.9972614456474536e-05, 'epoch': 0.75}
{'loss': 1.0501, 'learning_rate': 2.9820209711600854e-05, 'epoch': 0.75}
75%|███████████████████████████▊ | 1119/1490 [1:19:31<25:59, 4.20s/it][2024-01-01 09:52:45,791] [INFO] [axolotl.utils.samplers.multipack._len_est:178] [PID:2201] [RANK:0] packing_efficiency_estimate: 0.87 total_num_tokens per device: 188373
[2024-01-01 09:52:45,977] [INFO] [axolotl.utils.samplers.multipack._len_est:178] [PID:2201] [RANK:0] packing_efficiency_estimate: 0.87 total_num_tokens per device: 188373
[2024-01-01 09:52:45,978] [INFO] [axolotl.utils.samplers.multipack._len_est:178] [PID:2201] [RANK:0] packing_efficiency_estimate: 0.87 total_num_tokens per device: 188373
0%| | 0/208 [00:00<?, ?it/s][2024-01-01 09:52:46,154] [INFO] [axolotl.utils.samplers.multipack._len_est:178] [PID:2201] [RANK:0] packing_efficiency_estimate: 0.87 total_num_tokens per device: 188373
1%|▍ | 2/208 [00:00<00:18, 11.37it/s][2024-01-01 09:52:46,333] [INFO] [axolotl.utils.samplers.multipack._len_est:178] [PID:2201] [RANK:0] packing_efficiency_estimate: 0.87 total_num_tokens per device: 188373
[2024-01-01 09:52:46,505] [INFO] [axolotl.utils.samplers.multipack._len_est:178] [PID:2201] [RANK:0] packing_efficiency_estimate: 0.87 total_num_tokens per device: 188373
2%|▊ | 4/208 [00:00<00:28, 7.18it/s][2024-01-01 09:52:46,679] [INFO] [axolotl.utils.samplers.multipack._len_est:178] [PID:2201] [RANK:0] packing_efficiency_estimate: 0.87 total_num_tokens per device: 188373
......
98%|████████████████████████████████████████▏| 204/208 [00:34<00:00, 5.82it/s][2024-01-01 09:53:21,107] [INFO] [axolotl.utils.samplers.multipack._len_est:178] [PID:2201] [RANK:0] packing_efficiency_estimate: 0.87 total_num_tokens per device: 188373
{'eval_loss': 1.023378849029541, 'eval_runtime': 35.318, 'eval_samples_per_second': 30.919, 'eval_steps_per_second': 30.919, 'epoch': 0.75}
75%|███████████████████████████▊ | 1119/1490 [1:20:07<25:59, 4.20s/it]
99%|████████████████████████████████████████▍| 205/208 [00:35<00:00, 5.88it/s]
{'loss': 1.0606, 'learning_rate': 2.966812550284803e-05, 'epoch': 0.75}
{'loss': 0.9497, 'learning_rate': 2.9516362524838846e-05, 'epoch': 0.75}
......
{'loss': 1.0027, 'learning_rate': 9.134702554591811e-10, 'epoch': 1.0}
{'loss': 0.9021, 'learning_rate': 2.283678246284282e-10, 'epoch': 1.0}
{'loss': 1.1726, 'learning_rate': 0.0, 'epoch': 1.0}
{'train_runtime': 6355.7444, 'train_samples_per_second': 8.414, 'train_steps_per_second': 0.234, 'train_loss': 1.0881121746245646, 'epoch': 1.0}
100%|█████████████████████████████████████| 1490/1490 [1:45:55<00:00, 4.27s/it]
[2024-01-01 10:19:09,776] [INFO] [axolotl.train.log:60] [PID:2201] [RANK:0] Training Completed!!! Saving pre-trained model to ./lora-out • Обучение заняло 1 час 45 минут на графическом процессоре Nividia A 100 80 ГБ. • Контрольные точки обучения сохраняются в папке lora-out, указанной в файле lora.yaml, который является выходным каталогом. •Файл адаптера также сохраняется в выходном каталоге, указанном в файле lora.yaml. • Обученную модель можно отправить в репозиторий HuggingFace, указав сведения о репоиде и папке в параметре push_dataset_to_hub в файле lora.yaml.
Интерактивный вывод с использованием градиента
gradio
!accelerate launch -m axolotl.cli.inference examples/openllama-3b/lora.yml --lora_model_dir="./lora-out" --gradio The following values were not passed to `accelerate launch` and had defaults used instead:
`--num_processes` was set to a value of `1`
`--num_machines` was set to a value of `1`
`--mixed_precision` was set to a value of `'no'`
`--dynamo_backend` was set to a value of `'no'`
To avoid this warning pass in values for each of the problematic parameters or run `accelerate config`.
/usr/local/lib/python3.10/dist-packages/transformers/deepspeed.py:23: FutureWarning: transformers.deepspeed module is deprecated and will be removed in a future version. Please import deepspeed modules directly from transformers.integrations
warnings.warn(
[2024-01-01 10:43:34,869] [INFO] [datasets.<module>:58] [PID:5297] PyTorch version 2.0.1+cu118 available.
dP dP dP
88 88 88
.d8888b. dP. .dP .d8888b. 88 .d8888b. d8888P 88
88' `88 `8bd8' 88' `88 88 88' `88 88 88
88. .88 .d88b. 88. .88 88 88. .88 88 88
`88888P8 dP' `dP `88888P' dP `88888P' dP dP
[2024-01-01 10:43:35,772] [INFO] [axolotl.validate_config:156] [PID:5297] [RANK:0] bf16 support detected, but not enabled for this configuration.
[2024-01-01 10:43:35,772] [WARNING] [axolotl.validate_config:176] [PID:5297] [RANK:0] `pad_to_sequence_len: true` is recommended when using sample_packing
[2024-01-01 10:43:36,062] [INFO] [axolotl.normalize_config:150] [PID:5297] [RANK:0] GPU memory usage baseline: 0.000GB (+0.811GB misc)
[2024-01-01 10:43:36,064] [INFO] [axolotl.common.cli.load_model_and_tokenizer:49] [PID:5297] [RANK:0] loading tokenizer... openlm-research/open_llama_3b_v2
You are using the default legacy behaviour of the <class 'transformers.models.llama.tokenization_llama.LlamaTokenizer'>. This is expected, and simply means that the `legacy` (previous) behavior will be used so nothing changes for you. If you want to use the new behaviour, set `legacy=False`. This should only be set if you understand what it means, and thoroughly read the reason why this was added as explained in https://github.com/huggingface/transformers/pull/24565
[2024-01-01 10:43:36,345] [DEBUG] [axolotl.load_tokenizer:185] [PID:5297] [RANK:0] EOS: 2 / </s>
[2024-01-01 10:43:36,345] [DEBUG] [axolotl.load_tokenizer:186] [PID:5297] [RANK:0] BOS: 1 / <s>~~[2024-01-01 10:43:36,345] [DEBUG] [axolotl.load_tokenizer:187] [PID:5297] [RANK:0] PAD: 2 /~~ </s>
[2024-01-01 10:43:36,345] [DEBUG] [axolotl.load_tokenizer:188] [PID:5297] [RANK:0] UNK: 0 / <unk>
[2024-01-01 10:43:36,345] [INFO] [axolotl.load_tokenizer:193] [PID:5297] [RANK:0] No Chat template selected. Consider adding a chat template for easier inference.
[2024-01-01 10:43:36,345] [INFO] [axolotl.common.cli.load_model_and_tokenizer:51] [PID:5297] [RANK:0] loading model and (optionally) peft_config...
[2024-01-01 10:43:44,496] [INFO] [axolotl.load_model:517] [PID:5297] [RANK:0] GPU memory usage after model load: 3.408GB (+0.334GB cache, +1.850GB misc)
[2024-01-01 10:43:44,501] [INFO] [axolotl.load_model:540] [PID:5297] [RANK:0] converting PEFT model w/ prepare_model_for_kbit_training
[2024-01-01 10:43:44,505] [INFO] [axolotl.load_model:552] [PID:5297] [RANK:0] converting modules to torch.float16 for flash attention
[2024-01-01 10:43:44,506] [DEBUG] [axolotl.load_lora:670] [PID:5297] [RANK:0] Loading pretained PEFT - LoRA
[2024-01-01 10:43:44,533] [WARNING] [auto_gptq.nn_modules.qlinear.qlinear_cuda.<module>:16] [PID:5297] CUDA extension not installed.
[2024-01-01 10:43:44,533] [WARNING] [auto_gptq.nn_modules.qlinear.qlinear_cuda_old.<module>:15] [PID:5297] CUDA extension not installed.
trainable params: 12,712,960 || all params: 3,439,186,560 || trainable%: 0.36965020007521776
[2024-01-01 10:43:44,851] [INFO] [axolotl.load_model:582] [PID:5297] [RANK:0] GPU memory usage after adapters: 3.455GB (+1.148GB cache, +1.850GB misc)
Running on local URL: http://127.0.0.1:7860
Running on public URL: https://87eb53a4929499e106.gradio.live
This share link expires in 72 hours. For free permanent hosting and GPU upgrades, run `gradio deploy` from Terminal to deploy to Spaces (https://huggingface.co/spaces) в заключение
Здесь мы рассмотрим, как использовать Axolotl и Gradio для точной настройки и вывода точно настроенных моделей практически без кода.
Эта статья была переведена и скомпилирована Shanxing с: https://medium.aiplanet.com/no-code-llm-fine-tuning-using-axolotl-2db34e3d0647 и [GitHub - OpenAccess-AI-Collective/axolotl: продолжайте и аксолотль вопросы](https://github.com/OpenAccess-AI-Collective/axolotl), основная цель — поделиться со всеми большим количеством знаний, связанных с ИИ, чтобы больше людей могли иметь четкое представление об ИИ. Если это было для вас полезно, поставьте лайк, подпишитесь и заберите это, спасибо ~
References
[1] Axolotl: https://github.com/OpenAccess-AI-Collective/axolotl
[2] RunPod: https://www.runpod.io/console/gpu-cloud
[3] teknium/GPT4-LLM-Cleaned: https://huggingface.co/datasets/teknium/GPT4-LLM-Cleaned
[4] openlm-research/open_llama_3b_v2 Модель: https://huggingface.co/openlm-research/open_llama_3b_v2
[5] examples: https://github.com/OpenAccess-AI-Collective/axolotl/tree/main/examples
[6] openllama-3b: https://github.com/OpenAccess-AI-Collective/axolotl/tree/main/examples/openllama-3b



Учебное пособие по Jetpack Compose для начинающих, базовые элементы управления и макет

Код js веб-страницы, фон частицы, код спецэффектов

【новый! Суперподробное】Полное руководство по свойствам компонентов Figma.

🎉Обязательно к прочтению новичкам: полное руководство по написанию мини-программ WeChat с использованием программного обеспечения Cursor.

[Забавный проект Docker] VoceChat — еще одно приложение для мгновенного чата (IM)! Может быть встроен в любую веб-страницу!

Как реализовать переход по странице в HTML (html переходит на указанную страницу)

Как решить проблему зависания и низкой скорости при установке зависимостей с помощью npm. Существуют ли доступные источники npm, которые могут решить эту проблему?

Серия From Zero to Fun: Uni-App WeChat Payment Practice WeChat авторизует вход в систему и украшает страницу заказа, создает интерфейс заказа и инициирует запрос заказа

Серия uni-app: uni.navigateЧтобы передать скачок значения

Апплет WeChat настраивает верхнюю панель навигации и адаптируется к различным моделям.

JS-время конвертации

Обеспечьте бесперебойную работу ChromeDriver 125: советы по решению проблемы chromedriver.exe не найдены

Поле комментария, щелчок мышью, специальные эффекты, js-код

Объект массива перемещения объекта JS

Как открыть разрешение на позиционирование апплета WeChat_Как использовать WeChat для определения местонахождения друзей

Я даю вам два набора из 18 простых в использовании фонов холста Power BI, так что вам больше не придется возиться с цветами!

Получить текущее время в js_Как динамически отображать дату и время в js

Вам необходимо изучить сочетания клавиш vsCode для форматирования и организации кода, чтобы вам больше не приходилось настраивать формат вручную.

У ChatGPT большое обновление. Всего за 45 минут пресс-конференция показывает, что OpenAI сделал еще один шаг вперед.

Copilot облачной разработки — упрощение разработки

Микросборка xChatGPT с низким кодом, создание апплета чат-бота с искусственным интеллектом за пять шагов

CUDA Out of Memory: идеальное решение проблемы нехватки памяти CUDA

Анализ кластеризации отдельных ячеек, который должен освоить каждый&MarkerгенетическийВизуализация

vLLM: мощный инструмент для ускорения вывода ИИ

CodeGeeX: мощный инструмент генерации кода искусственного интеллекта, который можно использовать бесплатно в дополнение к второму пилоту.

Машинное обучение Реальный бой LightGBM + настройка параметров случайного поиска: точность 96,67%

Бесшовная интеграция, мгновенный интеллект [1]: платформа больших моделей Dify-LLM, интеграция без кодирования и встраивание в сторонние системы, более 42 тысяч звезд, чтобы стать свидетелями эксклюзивных интеллектуальных решений.

LM Studio для создания локальных больших моделей

Как определить количество слоев и нейронов скрытых слоев нейронной сети?
