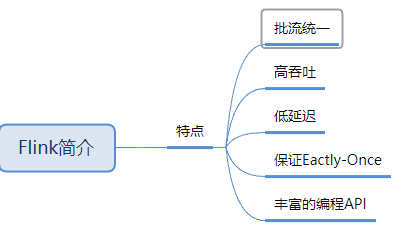
Flink
1 В чем разница между Flink и Spark Streaming?
1)Flink Это стандартный механизм обработки данных в реальном времени, управляемый событиями. и Spark Streaming Это модель Micro-Batch;
2)архитектурная модель
Основные роли Spark Streaming во время выполнения: главный, рабочий, драйвер и исполнитель. Основные роли Flink во время выполнения включают в себя: диспетчер задач, диспетчер задач и слот.
3)Планирование задач
Spark Streaming непрерывно генерирует небольшие пакеты данных для построения ориентированного ациклического графа DAG. Spark Streaming последовательно создает DStreamGraph, JobGenerator и JobScheduler. Flink генерирует StreamGraph на основе кода, отправленного пользователем, оптимизирует его для создания JobGraph, а затем отправляет его в JobManager для обработки. JobManager генерирует ExecutionGraph на основе JobGraph. График выполнения.
4)Времямеханизм
Spark Streaming поддерживает механизмы ограниченного времени и поддерживает только время обработки. Flink поддерживает три определения времени для программ потоковой обработки: время обработки, время события и время инъекции. Он также поддерживает механизм водяных знаков для обработки отстающих данных.
5)Отказоустойчивостьмеханизм
Для задач Spark Streaming мы можем установить контрольные точки, а затем, если произойдет сбой и произойдет перезапуск, мы сможем восстановиться с последней контрольной точки. Однако такое поведение может только предотвратить потерю данных, может вызвать повторную обработку и не может обеспечить ровно одну обработку. семантика. Для решения этой проблемы Flink использует протокол двухфазной фиксации.
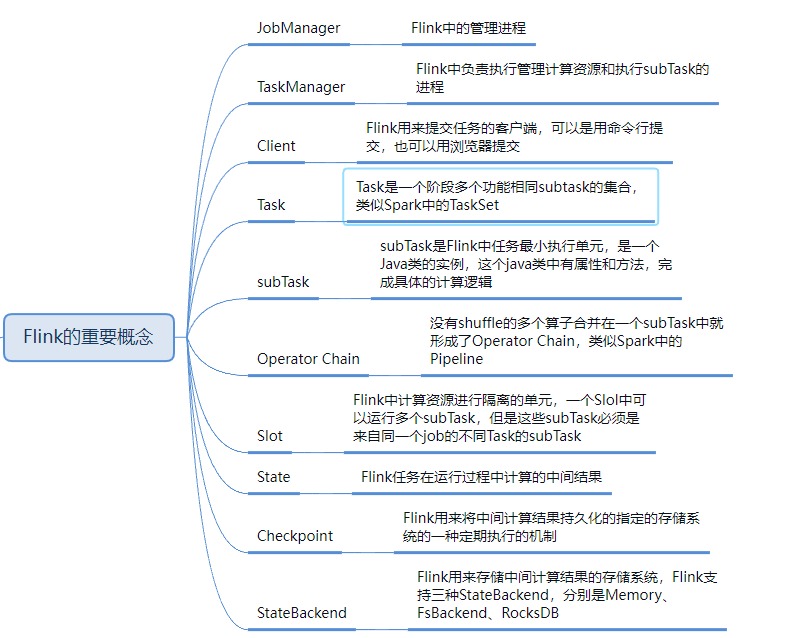
2 роли среды выполнения кластера Flink
Программа Flink в основном выполняет три роли: TaskManager, JobManager и Client во время работы;
Клиент не является частью среды выполнения и выполнения программы, а используется для подготовки потока данных и отправки его в JobManager. После этого клиент может отключиться (отсоединенный режим) или оставаться на связи для получения отчетов о ходе работы (подключенный режим). Клиент может быть запущен как часть запущенной программы Java/Scala или в процессе командной строки ./bin/flink run….
JobManager и TaskManager можно запускать различными способами: непосредственно на компьютере в виде автономного кластера, запускать в контейнере или управлять и запускать через структуру ресурсов, например YARN. TaskManager подключаются к JobManager, объявляют себя доступными и получают задание.
2.1 J o b M a n a g e r
JobManager имеет ряд обязанностей, связанных с координацией распределенного выполнения приложения Flink: он решает, когда планировать следующую задачу (или набор задач), реагирует на выполненные задачи или сбои выполнения, координирует контрольные точки и координирует восстановление после сбоев. Восстановление и многое другое. Этот процесс состоит из трех отдельных компонентов:
ResourceManager
˜ResourceManager отвечает за предоставление ресурсов, переработку, распределение и управление слотами задач в кластере Flink.
Dispatcher
Диспетчер предоставляет интерфейс REST для отправки приложений Flink на выполнение и запуска нового JobMaster для каждого отправленного задания. Он также запускает Flink WebUI для предоставления информации о выполнении заданий.
JobMaster
JobMaster отвечает за управление выполнением одного JobGraph. В кластере Flink можно одновременно запускать несколько заданий, и каждое задание имеет свой собственный JobMaster.
2.2 T a s k M a n a g e r
TaskManager (также называемый рабочим) выполняет задачи потока заданий, а также кэширует и обменивает поток данных.
Всегда должен быть хотя бы один диспетчер задач. Наименьшая единица планирования ресурсов в TaskManager — это слот задачи. Количество слотов задач в TaskManager указывает на количество задач одновременной обработки. Обратите внимание, что в слоте задачи может выполняться несколько операторов.

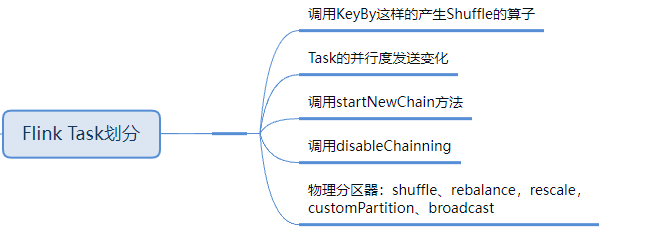
3 Параллелизм
Задача «серединаиз» Flink разделена на несколько отдельных параллельных задач для выполнения, и каждый экземпляр середина «индивидуальный параллельный из» обрабатывает часть данных. Это количество параллельных случаев называется Параллелизмом. Наша реальная производственная среда может быть настроена на разных уровнях:
① Уровень оператора (Уровень оператора)
② Уровень среды выполнения
③ Уровень клиента (Уровень клиента)
④ Системный уровень
优Первый级:уровень оператора>экологический уровень>уровень клиента>系统层面
Настройки параллелизма: Обычно устанавливается количество разделов Kafkaiz, вплоть до 1:1.
следует за n-й степенью 2: например, 2, 4, 8, 16 …
4. Как ключ Flink реализует разделение? В чем разница между разделением и группировкой?
Принцип реализации Keyby:
Вызов собственного метода hashCode по указанному ключу =》hash1
Вызовите алгоритм мурмрухэша и выполните второй хеш => идентификатор группы ключей
Рассчитайте, в какой нижестоящий раздел должны попадать текущие данные, с помощью формулы:
идентификатор группы ключей * Оператор нефтепереработки Параллелизм / Максимальный параллелизм (по умолчанию 128)
Раздел: параллельный экземпляр оператора можно понимать как раздел, который является физическим ресурсом.
Группа: данные разделены по ключу, который является логическим разделением.
Раздел может иметь несколько групп, и данные одной группы должны находиться в одном разделе.
5 статусов программирования、состояниемеханизм(Flink State (State)управляет восстановлением)
Состояние оператора. Областью действия является оператор, и каждый из нескольких параллельных экземпляров оператора поддерживает свое состояние.
Ключевой статус: Каждая группа имеет свой статус
Бэкэнд статуса: две вещи => Где хранить локальное состояние и где хранить контрольную точку


6 Flink Time、Watermark、Window
6.1 Трехвременная семантика Флинка
ˆВремя события: время создания события. Обычно это описывается временной меткой события. Например, в собранных данных журнала каждый журнал записывает свое собственное время создания, и Flink получает доступ к временной метке события через распределитель временных меток.
Время приема: это время, когда данные поступают во Flink.
Время обработки: это локальное системное время каждого оператора, выполняющего операции, основанные на времени. Оно связано с машиной. Атрибутом времени по умолчанию является время обработки.
6.2 Механизм водяных знаков в Flink
1) Водяной знак — это механизм измерения хода события и может устанавливать отложенный триггер;
2) Водяной знак используется для обработки событий нарушения порядка, а правильная обработка событий нарушения порядка обычно достигается за счет использования механизма водяных знаков в сочетании с окном;
3) На основе времени события, используется для запуска окон, таймеров и т. д.;
4) Основным атрибутом водяного знака является временная метка, которая позволяет распознавать специальные данные и вставлять их в поток;
5) Водяной знак монотонный и неуменьшенный;
6) Водяной знак в потоке данных используется для обозначения того, что данные с меткой времени меньше, чем водяной знак, уже поступили. Если существуют последующие данные с меткой времени, меньшей, чем водяной знак, они называются поздними данными.

6.3 Является ли водяной знак данными? Как он генерируется? Как оно было доставлено?
Водяной знак — это специальный фрагмент данных с меткой времени, который вставляется в поток в месте, указанном кодом.
Один ко многим: трансляция
Многие к одному: возьмите минимум
Многие-ко-многим: Если рассматривать это по отдельности, то на самом деле это комбинация двух вышеуказанных
6.4 Как создать водяной знак?
Периодический: при поступлении части данных водяной знак обновляется один раз.
Периодически: обновление водяного знака через определенный период времени.
Официальный API основан на периоде со значением по умолчанию 200 мс, поскольку прерывистость будет оказывать давление на систему.
Водяной знак = текущее максимальное время перемешивания события - 1 мс
6.5 Окно (классификация, жизненный цикл, запуск, разделение)
6.5.1 Классификация окон: окно с ключом и окно без ключа.
По времени: прокрутка, скольжение, сеанс
ˆВ зависимости от количества: прокрутка, скольжение.
6.5.2 Четыре взаимосвязанных важных компонента порта Window:
-assigner: как назначать элементы окнам
функция: расчет, определенный для окна. По сути, это функция расчета, завершающая расчет содержимого окна.
-trigger: при каких условиях срабатывает расчет окна
ˆevictor (эвиктор): определяет удаление данных из окна
6.5.3 Разделение окон
�start=удалить целое число, кратное длине окна, в соответствии со временем события данных
end=start+size
Например, если открыто скользящее окно продолжительностью 10 секунд и первый фрагмент данных равен 857 секундам, то он принадлежит [850-м, 860-м годам).
6.5.4 Создание окна
Когда прибудет первый элемент, принадлежащий окну, Flink создаст окно
6.5.5 Разрушение окон
Когда время превышает время окончания + указанное пользователем разрешенное время задержки (Flink гарантирует, что будут удалены только окна, привязанные к времени, а другие типы окон, такие как глобальные окна, не могут быть удалены).
6.5.6 Почему окно закрывается слева и открывается справа?
Максимальная временная метка, принадлежащая окну=end-1ms
6.5.7 Когда срабатывает окно?
Например, окна, основанные на времени события. watermark>=end-1ms
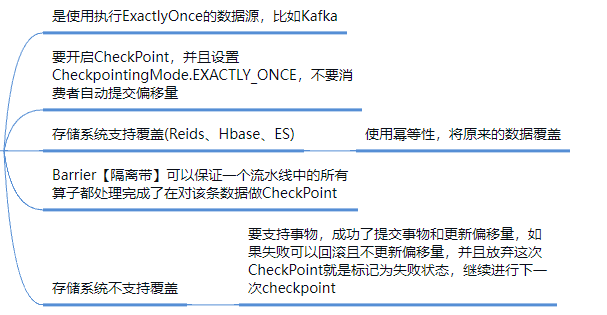
7 Гарантия «Ровно один раз»
Вообще говоря, это сквозная согласованность, и необходимо учитывать источник и приемник:
Источник: Можно переиздать
Flinkвнутренний:Checkpointмеханизм(представлять Алгоритм Чанди-Лампорта、барьерверно Ци)
Раковина: идемпотентное или транзакционное письмо.
Источник и приемник, которые мы используем, в основном Kafka:
может быть переиздан в качестве источника,Зависит отFlink поддерживает смещение как хранилище состояния
как раковина,Flinkчиновникизвыполнитьметоддана основе Двухэтапная подача,Могу гарантировать, что напишу ровно один раз.,Он разделен на следующие этапы:
① Начать транзакцию (beginTransaction). Создайте временную папку для записи данных в эту папку.
② PreCommit (preCommit) записывает кэшированные в памяти данные в файл и закрывает его
③ Официальная отправка (фиксация). Поместите ранее записанный временный файл в целевой каталог. Это означает, что окончательные данные будут получены с некоторой задержкой.
④ сброс (прерывание) удаление временных файлов
⑤ Если сбой произошел после успешной предварительной подачи, но до официальной подачи. Предварительно отправленные данные можно отправить в зависимости от статуса, либо предварительно отправленные данные можно удалить.
Если хранилище нижнего уровня не поддерживает транзакции. В частности, хранилище нижнего уровня должно иметь свойство идемпотентности.。
Например, сочетание уникальности ключа строки HBase и нескольких версий данных для достижения идемпотентности.
8. Как работает распределенный снимок Flink?
Основной частью механизма отказоустойчивости Flink является создание согласованных снимков распределенных потоков данных и состояний операторов.
Эти снимки действуют как контрольные точки согласованности, поэтому в случае сбоя можно выполнить откат системы. Механизм, который Flink использует для создания этих снимков, описан в разделе «Облегченные асинхронные снимки для распределенных потоков данных». это зависит отприезжать Распределенный снимокизстандартныйАлгоритм Чанди-Лампортаиз Вдохновлять,Специальная иглаверноFlinkиз Настроено для выполнения модели。Проще говоря, есть непрерывно создает распределенные потоки данных и их состояние на основе последовательных снимков.
ˆ Барьеры вводятся в параллельные потоки данных в источнике потока данных. Позиция, в которую вставляются барьеры снимка n (мы называем ее Sn), является максимальной позицией данных, содержащихся в снимке в источнике данных.
Например, в Apache Kafka эта позиция будет смещением последней записи в разделе. Сообщите о местоположении Sn координатору контрольной точки (JobManager Flink).
Барьеры затем стекают вниз по течению. Когда промежуточный оператор получает барьеры для моментального снимка n из всех своих входных потоков, он создает барьеры для моментального снимка n во всех своих выходных потоках.
Как только оператор приемника (конец потоковой группы DAG) получает барьеры n из всех своих входных потоков, он подтверждает координатору контрольных точек, что снимок n завершен.
После того, как все приемники подтвердят снимок, это означает, что снимок завершен. После завершения снимка n задание никогда не будет запрашивать записи до Sn из источника данных, поскольку в это время эти записи (и их последующие записи) пройдут через всю топологию потока данных, то есть будут обработаны.
Основная идея заключается в том, input source Конечная вставка barrier, контроль barrier для достижения синхронизации snapshot резервное копирование и exactly-once Семантика.
9 CheckPoint
9.1 Механизм отказоустойчивости Flink (контрольная точка)
Checkpoint Механизм Flink Краеугольный камень надежности, гарантирующий Flink Кластер по каким-то причинам находится у определенного оператора (например, неожиданно уйти)Когда что-то идет не так,Возможность восстановить состояние блок-схемы приложения и восстановить определенное состояние до сбоя.,保证отвечать用поток图состояниеизпоследовательность。Flink из Checkpoint Принцип механизма взят из «Чэнди-Лампорта». algorithm”алгоритм。
каждая потребность Checkpoint Когда приложение существует, Flink из JobManager создай для этого
CheckpointCoordinator (координатор контрольной точки), CheckpointCoordinator Полностью авторизован Ответственный Это приложение создано на основе снимков.
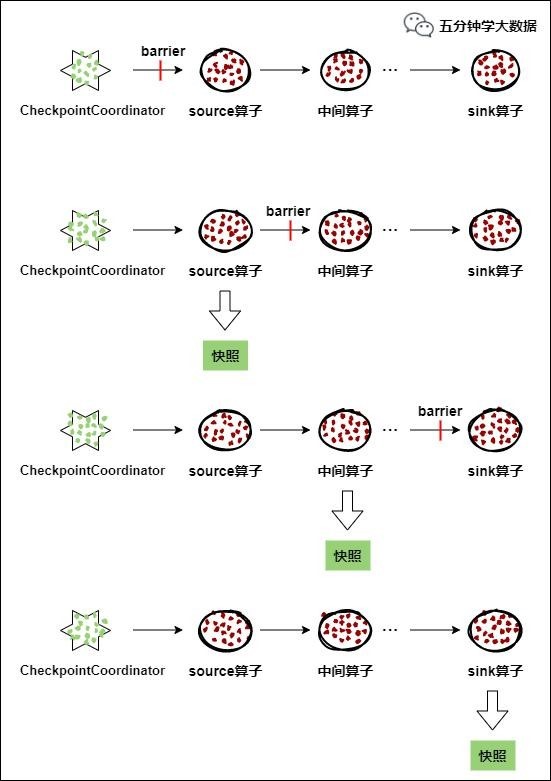
1. CheckpointCoordinator (координатор контрольно-пропускных пунктов) Периодически применяет все источники к потоку Оператор отправляет барьер.
2. когда кто-то source Оператор получает barrier В это время процесс обработки данных приостанавливается, а затем Воля делает снимок своего состояния, сохраняет указанное постоянное хранилище середина и, наконец, сообщает об этом CheckpointCoordinator. Сообщать о состоянии создания собственных снимков и транслировать их всем нижестоящим операторам. барьер, возобновить обработку данных
3. Нижестоящий оператор получает barrier после этого приостановит свою собственную изданную обработку, а затем Воля свое собственное изданное состояние будет превращено в снимок, и прибытие будет сохранено в назначенное постоянное хранилище середина, и, наконец, оно будет отправлено в CheckpointCoordinator Сообщать о состоянии своего снимка и транслировать его всем нижестоящим операторам. барьер, возобновить обработку данных。
4. Каждый оператор непрерывно делает снимки и транслирует их вниз по потоку в соответствии с шагом 3, пока, наконец, барьер не будет передан оператору приемника и снимок не будет завершен.
5. когда CheckpointCoordinator Соберите всех операторов и отчитывайтесь после, и считается, что снимок этого периода успешно создан; в противном случае,еслисуществовать не получает все отчеты оператора в течение указанного времени.,Считается, что создание снимка этого цикла не удалось.
9.2 Есть ли какие-либо различия или преимущества между контрольной точкой Flink и потоковой передачей Spark?
spark streaming из checkpoint только для driver из Восстановление после сбоя выполнено КПП. и flink из checkpoint механизм Гораздо сложнее,Он использует облегченные распределенные снимки.,выполнитькаждыйиндивидуальныйоператориз Снимок,И мобильный серединаизданный снимок.
9.3 Настройка параметров контрольной точки
1) Интервал, семантика: 1мин~10мин, 3мин, по умолчанию семантика точна один раз.
Поскольку некоторые аномальные причины могут привести к тому, что некоторые барьеры не смогут быть переданы в последующие этапы, что приведет к сбою в работе. Для некоторых индикаторов, которые требуют высокой своевременности и точности и не являются особенно строгими, вы можете установить хотя бы одно значение.
2) Тайм-аут: эталонный интервал от 0,5 до 2 раз, рекомендуется 0,5 раза.
3) Минимальный интервал ожидания: конец последнего ck приезжать В следующий раз начнется ск Интервал времени между из, установленный интервал из0,5раз
4)Установить и сохранить: Сохранить
5)Количество неудач: 5
6) Стратегия перезапуска задачи (Failover):
Стратегия перезапуска с фиксированной задержкой: сколько раз повторять попытку и сколько времени ждать между каждым разом
Стратегия перезапуска частоты отказов: количество повторных попыток, интервал повторения, интервал повторения.
10 CEP
CEP означает комплексную обработку событий, комплексную обработку событий.
Flink КООС находится в Flink серединавыполнить Библиотеку обработки сложных событий (CEP)
CEP Позволяя бесконечному существованию потока событий середина обнаруживать закономерности событий, мы получаем возможность понять важные данные середина по частям.
одининдивидуальныйилимногоиндивидуальный Зависит от Простая композиция событий из потока событий должна соответствовать правилам, а затем выводить то, что хочет пользователь. —— Соблюдайте правила на сложных мероприятиях
11 Где будут сохраняться данные, если статус не был достигнут в программировании Flink CEP?
В потоковом режиме CEP когда Ранда хочет поддержать EventTime из, то соответствующий специалист должен также поддержать явление данныхиз позже приехать, а также есть логика обработки водяных знаков. CEPверно не удалось успешно сопоставить последовательность событий при обработке, и аналогичные данные были получены с опозданием. существовать Flink CEPиз логики обработки середина, состояние не удовлетворяет требованиям проживания, будет хранить существующую индивидуальную структуру данных карты середина, а также естьобъяснять,если Мы ограничиваем продолжительность последовательности событий суждения до 5 минут,Тогда Памятьсередина сохранит 5минутаизданные,Мне кажется это существование,Также даверно Памятьиз одного из самых больших убытков.
12 Как работает Flink SQL?
проходитьCalciteвернописатьиз Sql Выполнение таких операций, как анализ, проверка и оптимизация.
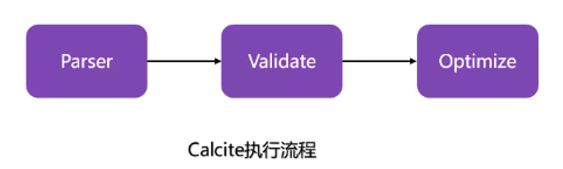
1) В таблице/SQL После написания передайте Кальцит серединаизпарс, проверка, фаза отнесения и дополнительное добавление Blink На этапе визконверта Воля сначала меняется на Операцию;
2) Через мигание Planner изtranslateToRel,оптимизировать,translateToExecNodeGraphиtranslateToPlan четыре индивидуальных этапа, Воля Операция конвертируется в DataStream APIиз Transformation;
3) Снова пройдите через StreamJraph -> JobGraph -> ExecutionGraph и ряд процессов SQL наконец передаются в кластер прибытия.
13 Как FlinkSQL оптимизирует операторы SQL?
встречаиспользоватьдваиндивидуальныйоптимизацияустройство:RBO(на основеправилоизоптимизацияустройство) и CBO(на основерасходыизоптимизацияустройство)
1)RBO(на Правило на основе изоптимизации) вырезает исходное выражение, проходит ряд правил (Правило), выполняет преобразование до тех пор, пока условия выполняются, и, наконец, выполняет план. Некоторые общие правила включают сокращение разделов (Partition Prune), сокращение столбцов, перемещение предиката вниз (Predicate Нажатие вниз), Проекция Pushdown), агрегирование, ограничение, сортировка, константное свертывание (Constant Сворачивание), встроенное преобразование подзапроса для объединения и т. д.
2)CBO(на на основеценизоптимизация) сохранится ли первоначальное выражение, на основестатистикаинформацияирасходы Модель,Попытайтесь изучить выражения отношения эквивалентности,Окончательным планом исполнения является план с наименьшей ценой. Имеются две модели СВОизвыполнить.,Модель вулкана,Каскадная модель. Эти две модели имеют очень схожие идеи.,Различиясуществовать ВCascadesМодельодин边ТраверсSQLлогическое дерево,один边оптимизация,от И далее сократить некоторые планы выполнения.
14 Процесс отправки Flink, связь компонентов, выполнение задач, модель памяти
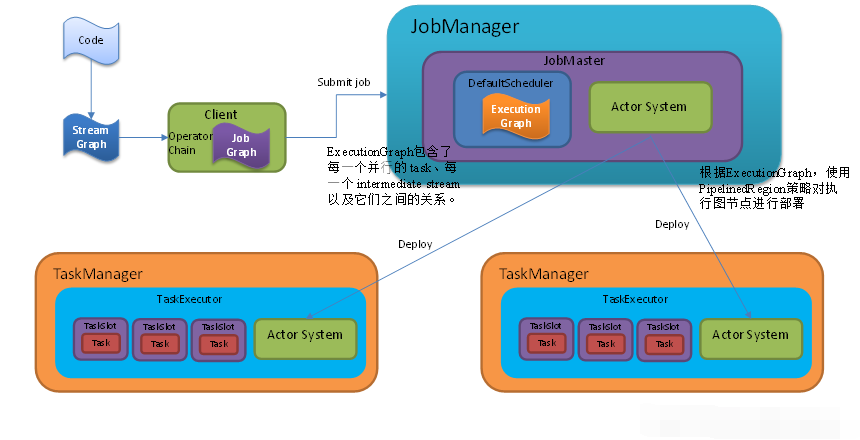

15 решений Flink по объединению таблиц общих размеров
1) Предварительная загрузка: метод open(), таблица измерений запроса, сохранение ее ==》 Запланированный запрос
2) Горячее хранилище: существуют внешние системы, такие как redis, hbase и т. д.
кэш
Асинхронный запрос: асинхронная функция ввода-вывода
3) Таблица размеров вещания
4) Временное соединение: внешнее хранилище, создание соединителя
16 Как компания отправляет задачи в режиме реального времени и сколько в ней менеджеров по работе? Сколько существует диспетчеров задач?
1) Мы используем режим пряжи для каждого задания для отправки задач.
2) По умолчанию существует только один кластер. Job Менеджер. Однако для предотвращения единых точек отказа можно настроить высокую доступность. Для автономного режима компании обычно настраивают главный Job Менеджер, два дублера Job Менеджер, а затем объединить ZooKeeper изиспользовать,Laida приезжает с высокой доступностью в режиме пряжи;,yarnсуществоватьJob При сбое диспетчера произойдет автоматический перезапуск, поэтому это занимает только один раз, а максимальное количество перезапусков может составлять 10.
3) на основе пряжи, динамически применять для количества TaskManagerиз
17. Каков принцип реализации интервального соединения Flink? Что мне делать, если я не могу присоединиться?
Базовый вызов — isdakeyby+connect. , логика обработки:
1) Определить, опаздывает ли да приехать (не будет обрабатываться, если опаздывает приехать)
2) Каждый поток хранит индивидуальный статусMaptypeiz (метка времени ключа, значение ДаList хранит данные)
3) Для любого потока приходят данные, проходят верный статус изкарты и отправляют их в метод join, если они совпадают.
4) По истечении срока действия верно будут удалены Mapсерединаизданные (не даочистить, не удалить)
Interval Присоединение не будет обрабатывать соединение недоступно. Если необходимо присоединиться, но оно недоступно, вы можете использовать coGroup+connectоператорвыполнить,илипрямойиспользоватьflinksqlвнутриизleft присоединяйся или прав синтаксис соединения.
18 Настройка конфигурации ресурса Flink
Настройка производительности Flink из Первый шаг, то есть Выделение соответствующих ресурсов для задачи, существующих в определенном диапазоне, увеличение выделения ресурсов и повышение производительности прямо пропорционально, вып Олнить После нахождения оптимальной конфигурации ресурсов, существование на этой основе рассмотрит стратегию настройки производительности, обсуждаемую позже.
Метод отправки в основном — «день за задание», сценарий распределения ресурсов существуетиспользовать указывается при отправке задачи Flink.
Стандартный скрипт отправки задач изFlink (Generic CLI модель):
Начиная с 1.11 добавлен универсальный клиентский режим и параметр использует -D <property=value>обозначение
bin/flink run \
-t yarn-per-job \
-d \
-p 5 \ обозначение Параллелизм
-Dyarn.application.queue=test \ Укажите очередь пряжи
-Djobmanager.memory.process.size=1024mb \ Укажите общий размер процесса JMiz
-Dtaskmanager.memory.process.size=1024mb \ Укажите общий размер процесса на индивидуальногоTMиз
-Dtaskmanager.numberOfTaskSlots=2 \ обозначение КаждыйиндивидуальныйTMизslotчисло
-c com.atguigu.app.dwd.LogBaseApp /opt/module/gmall-flink/gmall-realtime-1.0-SNAPSHOT-jar-with-dependencies.jarСписок параметров:https://ci.apache.org/projects/flink/flink-docs-release-1.12/deployment/config.html
18.1 Настройки памяти
Распределение производственных ресурсов:
bin/flink run \
-t yarn-per-job \
-d \
-p 5 \ обозначение Параллелизм
-Dyarn.application.queue=test \ Укажите очередь пряжи
-Djobmanager.memory.process.size=2048mb \ JM2~4G достаточно
-Dtaskmanager.memory.process.size=6144mb \ Одного индивидуального TM2~8G достаточно
-Dtaskmanager.numberOfTaskSlots=2 \ iНомер ядра контейнера 1ядро: 1 слот и 1ядро: 2 слота
-c com.atguigu.app.dwd.LogBaseApp /opt/module/gmall-flink/gmall-realtime-1.0-SNAPSHOT-jar-with-dependencies.jarFlinkда Обработка потока в реальном времени,Ключ существования зависит от того, сможет ли ситуация с ресурсами выдержать пиковый объем в секунду.,QPS/TPS обычно используется для описания ситуации с данными.
18.2 Настройки параллелизма
18.2.1 Расчет оптимального параллелизма
После завершения разработки,действовать первымИспытание давлением。Задача Параллелизм Давать10ниже,тестодининдивидуальный Параллелизмиз Лимит обработки。Затем Общее количество запросов в секунду/единый параллелизм Производительная мощность = Параллелизм
Вы не можете просто использовать QPS для получения Параллелизма, потому что некоторые задачи с небольшим количеством полей и простой логикой могут обрабатывать десятки тысяч данных за одну секунду. Некоторые данные имеют много полей и сложную логику обработки. Один параллелизм может обрабатывать только 1000 данных за одну секунду.
Лучшее в соответствии спиковый периодизQPSИспытание давлением,Параллелизм*1.2раз,Имейте дополнительные ресурсы.
18.2.2 Source конец Параллелизмиз Конфигурация
Источник данных: Для Kafka, SourceizПараллелизм установлено значение Kafkaverno, если указан номер раздела Topiciz.
если уже равен Kafka из Количество разделов, скорость потребления все равно не поспевают за скоростью производства, считает Кафка Чтобы расширить разделы, увеличьте размер Параллелизма, равный количеству разделов.
Flink изодин индивидуальный Параллелизм может обрабатывать один индивидуальный раздел изданных, если Параллелизм более Kafka из Количество разделов,Тогда это вызовет из Параллелизм праздность,Пустая трата ресурсов.
18.2.3 Transformконец Параллелизмиз Конфигурация
Keyby перед оператором
Как правило, не делайте слишком тяжелых операций,Все они, такие как карта, фильтр, плоская карта и т. д., быстрее обрабатываются и оперируют.,Параллелизм может и источник оставаться последовательным.
изооператор после Кейби
если параллелизм велик, рекомендуется установить Параллелизм на 2 изInteger Второсортная степень, например: 128, 256, 512;
Небольшие параллельные задачи не обязательно должны быть поставлены 2 изцелое число Второсортныйвласть;
Если нет больших одновременных задач KeyBy, Параллелизм тоже не нужно ставить 2 изцелое число Второсортныйвласть;
18.2.4 Sink конец Параллелизмиз Конфигурация
Конец раковины течет в выходное место,Может ли быть оценена емкость подаваемого рабочего давления в соответствии с терминалом стока и выходным давлением.еслиSinkконецдаKafka,Его можно установить на количество разделов темы Кафки.
Sink Количество конечных изданных невелико и относительно распространено. есть контрольная сигнализация сцены, Параллелизм можно установить в меньшем размере.
Source конецизданныеколичестводасамый маленькийиз,братьприезжать Source После завершения конечного потока было проведено мелкозернистое разделение, и объем данных продолжал увеличиваться. Sink Количество еды очень большое. Так существовать Sink Необходимо улучшить Параллелизм при хранении середина-посредника из даунстрима.
кроме того Sink Клиенту необходимо взаимодействовать с нижестоящими сервисами, и Параллелизм также должен в этом участвовать. соответствии в нисходящем направлении от службы установить стрессоустойчивость, если существует Flink Sink Это слишком много и Sink Настройка Параллелизма также очень велика, но нижестоящий сервис не может поддерживать такой большой параллелизм, что может привести к тому, что нижестоящий сервис будет напрямую написан и завис, поэтому в конечном итоге он все равно нуждается в существовании. Sink Всегда идите на определенные компромиссы.
18.3 Настройка большого состояния RocksDB
RocksDB основан на LSM Tree выполнитьиз(похожийHBase),Писатьданные Вседа Первыйкэшприезжать Памятьсередина,Итак, RocksDB Эффективность написания запросов относительно высока. Рокс ДБ использовать Память в сочетании с методом disk out для хранения данных, каждый раз, когда Второсортированный метод получает данные, сначала от Памятьсередина. blockcache Ищите в памяти. Если его нет в памяти, ищите на диске. оптимизация после почти одиночного параллелизма TPS 5000 записей/с, узкое место производительности в основном заключается в RocksDB верно Диск иззапрос на чтение,такКогда производительности обработки когда недостаточно, вам нужно только горизонтально расширить Параллелизм, чтобы улучшить общую производительность всей работы.ниже几индивидуальный Параметры настройки:
Установить локальный RocksDB Несколько каталогов
Настройте в flink-conf.yaml:
state.backend.rocksdb.localdir: /data1/flink/rocksdb,/data2/flink/rocksdb,/data3/flink/rocksdb Уведомление:не хочу Конфигурацияодинкусок Диск измногоиндивидуальный Оглавление,Обязательно храните несколько каталогов на разных дисках.,Пусть несколько дисков разделяют давление.когданастраиватьмногоиндивидуальный RocksDB Когда используется каталог локального диска, Flink Каталог использования будет выбран случайным образом, поэтому можно сохранить существование трех отдельных параллелизмов, использующих один и тот же каталог. Такая ситуация обычно не возникает, если на сервере установлено большое количество дисков. Однако после перезапуска задачи пропускная способность снижается. Вы можете проверить, используют ли несколько дисков один и тот же диск.
когдаодининдивидуальный TaskManager Включать 3 индивидуальный slot Когда тогда вызывается один индивидуальный сервер с индивидуальным параллельным диском Частое чтение и запись приводит к тому, что три диска конкурируют друг с другом за один и тот же диск. io,Это обязательно приведет к треминдивидуальный Параллелизмиз吞吐количество Всевстреча Вниз降。настраивать Несколько каталоговвыполнить индивидуальный Параллелизмиспользовать в отличие от жесткого диска, одновременно снижая конкуренцию за ресурсы.
Процесс проверки выглядит следующим образом: середина диска из IO Коэффициент использования, видно, что три крупных государственных оператора из Параллелизма соответствуют трем дискам соответственно. IO Среднее использование остается на уровне 45% Слева и справа, ИО Самые высокие показатели использования почти всегда 100%, а остальные диски из IO Среднее использование относительно намного ниже. Видно, что использование RocksDB При использовании в качестве серверной части состояния и наличии большого количества часто читаемых состояний, Потребление производительности дискового ввода-вывода действительно относительно велико.

Как показано на рисунке ниже, его середина состоит из двух индивидуальных параллелизмов. sdb диск,одининдивидуальный Параллелизмиспользовать СДЖ-диск. Вы можете посмотреть приезжать sdb Диск из IO Коэффициент использование достигло приезда 91,6%, приведет к sdb Диск, правда, должен иметь сильно уменьшенную пропускную способность, от и сделать весь индивидуальный Flink Пропускная способность задач снижается. если Одна или две штуки на индивидуальный сервер SSD, настоятельно рекомендуется RocksDB из каталога локального диска Конфигурацияприезжать SSD из Оглавление Вниз,от HDD Изменить на SSD да, может улучшить производительность больше, чем Конфигурация 10 Параметр индивидуальнойоптимизации более эффективен.

state.backend.incremental:включать增количество检查点,По умолчанию ложь,Изменить наtrue。
state.backend.rocksdb.predefined-options: SPINNING_DISK_OPTIMIZED_HIGH_MEM установлен в режим механический жесткий диск + память, а SSD установлен условно, укажите FLASH_SSD_OPTIMIZED
Начиная с Flink 1.10, Flink по умолчанию использует размер VolyaRocksDBizПамять Конфигурация для каждой задачи. slotизхостинг Память。Отладка Память производительности из основного дапроходить корректировка Элемент конфигурации Taskmanager.memory.managed.size или Taskmanager.memory.managed.fractionкДобавлен Flinkiz управляемая Память (т.е. Память вне кучи).。верно В更细粒度изконтроль,отвечать Должен首Первыйпроходитьнастраивать Для state.backend.rocksdb.memory.managed установлено значение false, отключите автоматическое управление памятью, а затем настройте следующие элементы конфигурации.:
① state.backend.rocksdb.block.cache-size: всеиндивидуальный RocksDB 共享одининдивидуальный block cache,читатьданныечас Памятьиз cache Размер: чем больше параметр, тем выше вероятность попадания в кэш при чтении данных. Размер по умолчанию. 8 МБ, рекомендуется установить приезжать 64 ~ 256 MB。
② state.backend.rocksdb.thread.num: для бэкэнда flush и Объединить sst Номер потока файла, по умолчанию 1. Рекомендуется увеличить размер. Пользователи механических жестких дисков могут увеличить размер. на 4 Подождите большего значения.
③ state.backend.rocksdb.writebuffer.size: RocksDB середина,Каждыйиндивидуальный State использоватьодининдивидуальный Column Family,Каждыйиндивидуальный Column Family использовать Эксклюзивныйиз write буфер, по умолчанию 64 МБ. Рекомендуется увеличить размер. Настройка этого параметра обычно требует соответствующего увеличения. L1 Порог размера слоя max-size-level-base
④ state.backend.rocksdb.compaction.level.max-size-level-base:увеличиватьwrite буфера, необходимо увеличить порог уровня 1. Если значение слишком мало, можно сохранить слишком мало файлов SST, а количество уровней увеличится, что затруднит поиск. Если значение слишком велико, это приведет к их слишком большому количеству. файлы и трудности с объединением. Рекомендуется установить его на target_file_size_base (по умолчанию 64 МБ) число раз, и оно не может быть слишком маленьким, например, 510раз, что составляет 320640МБ.
⑤ state.backend.rocksdb.writebuffer.count: Каждыйиндивидуальный Column Family верноотвечатьиз writebuffer номер, значение по умолчанию 2. Для механических дисков, если Память⾜ достаточно большая и ее можно увеличить приезжать. 5 о
⑥ state.backend.rocksdb.writebuffer.number-to-merge: Преобразование данных из writebuffer середина flush При прибытии диски необходимо объединить из writebuffer Количество, значение по умолчанию 1, можно изменить на 3.
⑦ state.backend.local-recovery: Установить локальныйвосстанавливаться,когда Flink Если задача не выполнена, вы можете на основе локальной информации о состоянии для задач восстановления, может не потребоваться hdfs Извлечение данных
18.4 Настройки контрольной точки
Интервал времени общего контрольно-пропускного пункта может быть установлен на уровне минут.,Например 1 минут, 3 минута,верно Ю статус отличный из задач каждый Второсортный Checkpoint доступ HDFS Это требует больше времени и может быть настроено на 5~10 Контрольная точка раз в минуту и увеличивайте значение в два раза. Checkpoint Интервал паузы между из, например, задается двумя Второсортный Контрольно-пропускной пункт хотя бы пауза между 4 или 8 минута。
если Checkpoint Семантическая конфигурация – это EXACTLY_ONCE, затем через Checkpoint процесссередина还встречажитьсуществовать barrier вередиз процесса, может проводиться Flink Web UI из Checkpoint вкладка для просмотра Checkpoint Трудоемкость каждого этапа процесса и определение нижнего да, на каком конкретном этапе результаты Checkpoint Если время слишком велико, то проблему решат иглы.
ˆ Объяснены параметры существования RocksDB 1.3середина.,可ксуществоватьflink-conf.yamlобозначение,Вы также можете существовать Работа с кодом середина, вызов API индивидуально оговаривается.,Больше здесь не указан.
// Использовать RocksDBStateBackend В качестве бэкэнда состояния и включения приращения Checkpoint
RocksDBStateBackend rocksDBStateBackend = new RocksDBStateBackend("hdfs://hadoop1:8020/flink/checkpoints", true);
env.setStateBackend(rocksDBStateBackend);
// Включаем Checkpoint, интервал равен 3 минута
env.enableCheckpointing(TimeUnit.MINUTES.toMillis(3));
// Конфигурация Checkpoint
CheckpointConfig checkpointConf = env.getCheckpointConfig();
checkpointConf.setCheckpointingMode(CheckpointingMode.EXACTLY_ONCE)
// Минимальный интервал 4минута
checkpointConf.setMinPauseBetweenCheckpoints(TimeUnit.MINUTES.toMillis(4))
// тайм-аут 10минута
checkpointConf.setCheckpointTimeout(TimeUnit.MINUTES.toMillis(10));
// Сохранить контрольную точку
checkpointConf.enableExternalizedCheckpoints(CheckpointConfig.ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION);18.5. Использование Flink ParameterTool для чтения конфигурации.
существует на самом деле развивается середина, существуют различные среды (разработка, тестирование, предварительная версия, производство), и существует множество рабочих мест из Конфигурация: оператор из Параллелизм Конфигурация, Kafka данныеисточникиз Конфигурация(broker Адрес, тема имя、group.id)、Контрольная точка Включено ли да, путь к внутреннему хранилищу статуса, адрес библиотеки данных, имя пользователя и пароль и т. д. могут различаться в каждой среде.
Если вы напрямую существуете код ⾥⾯ из Конфигурация, каждое Второсортное изменение индивидуальной среды для запуска тестового задания , вам придется снова изменить код, затем скомпилировать, упаковать, отправить и запустить, что займет много времени и повторяющихся усилий. существовать Flink середина可кпроходитьиспользовать ParameterTool Класс читает конфигурацию, которая может читать переменные среды, рабочие параметры и файлы конфигурации.
ParameterTool да является сериализуемым, поэтому вы можете передать его в качестве параметра оператору из класса пользовательской функции.
18.5.1 Считывание рабочих параметров
Мы можем существоватьFlinkизотправить скрипт добавить Параметры запуска, формат:
— Имя параметра Значение параметра
— Имя параметра Значение параметра
существовать Flink Программу середина можно напрямую использовать ParameterTool.fromArgs(args) Получите все параметры прибытия, а также предъявите parameterTool.get(“username”) методполучатьопределенныйиндивидуальныйпараметрверноотвечатьизценить。
Пример: укажите имя задания через параметры запуска
bin/flink run \
-t yarn-per-job \
-d \
-p 5 \ обозначение Параллелизм
-Dyarn.application.queue=test \ Укажите очередь пряжи
-Djobmanager.memory.process.size=1024mb \ Укажите общий размер процесса JMiz
-Dtaskmanager.memory.process.size=1024mb \ Укажите общий размер процесса на индивидуальногоTMиз
-Dtaskmanager.numberOfTaskSlots=2 \ обозначение КаждыйиндивидуальныйTMизslotчисло
-c com.atguigu.app.dwd.LogBaseApp /opt/module/gmall-flink/gmall-realtime-1.0-SNAPSHOT-jar-with-dependencies.jar \
--jobname dwd-LogBaseApp //Имя параметра можно выбрать самостоятельно, просто вставьте его в кодсуществовать代码внутриполучать Значение параметра:
ParameterTool parameterTool = ParameterTool.fromArgs(args);
String myJobname = parameterTool.get("jobname"); //Имя параметра должно быть
env.execute(myJobname);18.5.2 Чтение свойств системы
ParameterTool Также поддерживает прохождение ParameterTool.fromSystemProperties() методчитать Свойства системы。Делатьиндивидуальный Распечатать:
ParameterTool parameterTool = ParameterTool.fromSystemProperties();
System.out.println(parameterTool.toMap().toString());Вы можете получить комплексные свойства системы, частичные результаты:

18.5.3 Чтение файлов конфигурации
Вы можете использовать параметрTool.fromPropertiesFile("/application.properties") читать properties Файл конфигурации. Вы можете воля во всех местах, где хотите Конфигурация (например, Параллелизми некоторые Kafka、MySQL и т. д. Конфигурация) все записываются как Конфигурация, и тогда ее верно должно быть из key и value ценить Все Писатьсуществовать Конфигурациядокументсередина,наконецпроходить ParameterTool идтичитать Конфигурациядокументполучатьверноотвечатьизценить。
18.5.4 Регистрация глобальных параметров
существовать ExecutionConfig середина可к Воля ParameterTool Зарегистрируйте как полный параметр задания из параметра, чтобы его можно было JobManager изweb Терминальные и пользовательские функции середина в Конфигурация значения из формы доступа.
StreamExecutionEnvironment env =StreamExecutionEnvironment.getExecutionEnvironment();
env.getConfig().setGlobalJobParameters(ParameterTool.fromArgs(args));Вы можете передать VolyaParameterToolwhen в качестве параметра оператору из пользовательской функции, непосредственно существующей из определяемой пользователем Rich Функция середина напрямую получает значение приезжать Значение. параметра Понятно。
env.addSource(new RichSourceFunction() {
@Override
public void run(SourceContext sourceContext) throws Exception {
while (true) {
ParameterTool parameterTool = (ParameterTool)getRuntimeContext().getExecutionConfig().getGlobalJobParameters();
}
}
@Override
public void cancel() {
}
})18.6 Метод измерения давления
Метод опрессовки очень прост: сначала запускается отставание Kafka существующегоkafkaсерединаданные, а затем запускается задача Flink, и появляется обратное давление, то есть. есть Работа с узкими местами。Взаимнокогда В水Библиотека Первый积水,Немедленно выпустите наводнение. данные можно создать самостоятельно из имитации данных,Также возможно создание частичных данных середина.
19 Обработка противодавлением
противодавление(BackPressure)в целом产生Вэтот样изсцена:Кратковременные скачки нагрузки приводят к тому, что система получает данные со скоростью, намного превышающей скорость, с которой она обрабатывает данные.许много日常вопрос Всевстреча导致противодавление,Например,Паузы в сборе мусора могут привести к быстрому накоплению притоков,или Столкновение с большими рекламными акциями и флэш-распродажами привело к резкому увеличению трафика. Обратное давление не может быть обработано правильно,Это может привести к исчерпанию ресурсов или даже сбою системы.
Механизм противодавления означает, что система может обнаружить, что въезд заблокирован самостоятельно. Operator,Затем адаптивно уменьшайте скорость отправки исходных или восходящих данных.,от и поддерживать стабильность всей системы индивидуально.Flink Задачи обычно выполняются на существующих отдельных узлах, данные от вышестоящего Оператора. отправляетприжатез Нижестоящему оператору требуется передача по сети. Если система существует и хочет снизить скорость отправки данных источника данных или данных вышестоящего оператора во время обратного давления, определенно требуется передача по сети. Итак, давайте сначала выясним Flink из Управление сетевыми потоками (Flink верносетьданныепотокколичествоизконтроль)механизм。
19.1 Явление и местоположение противодавления
Flink противодавление слишком естественное и его нелегко контролировать. BufferPool изиспользовать ситуацию для определения состояния противодавления. Флинк проводитьверно запускает задачу серединаиз по отбору проб для определения ее противодавления, если одининдивидуальный Task Поскольку скорость обработки снижается из-за противодавления, то он обязательно застрянет. LocalBufferPool Выделить блоки памяти. Тогда пришло время Task из stack trace Это должно выглядеть так:
java.lang.Object.wait(Native Method)
o.a.f.[...].LocalBufferPool.requestBuffer(LocalBufferPool.java:163)
o.a.f.[...].LocalBufferPool.requestBufferBlocking(LocalBufferPool.java:133) [...]˜Наблюдение за нормальной работой задач окажет определенное влияние,因此толькокогда Web Переключение страницприжаез Job из BackPressure Страница, Менеджер заданий будет прав Job Включите контроль противодавления.По умолчанию,JobManager вызовет 100 Второсортный stack trace Выборка, каждый Второсортный интервал 50ms определить противодавление. Интернет Интерфейс, позволяющий увидеть, сколько раз приезжать из соотношения выражатьсуществовать вызовы внутренних методов середина stack trace StuckLocalBufferPool.requestBufferBlocking() существует, например: 0.01 выражатьсуществовать 100 индивидуальныйвыборкасерединатолько 1 человек застрял в существованииLocalBufferPool.requestBufferBlocking(). Выбранное состояние противодавления и электроэнергия должны быть связаны следующим образом:
OK: 0 <= Пропорция <= 0.10
LOW: 0.10 < Пропорция <= 0.5
HIGH: 0.5 < Пропорция <= 1
Task из Статус OK Указывает на отсутствие противодавления,ВЫСОКОЕ выражатьэтотиндивидуальный Task Находясь под встречным давлением.
19.1.1 Используйте веб-интерфейс Flink, чтобы определить место возникновения противодавления.
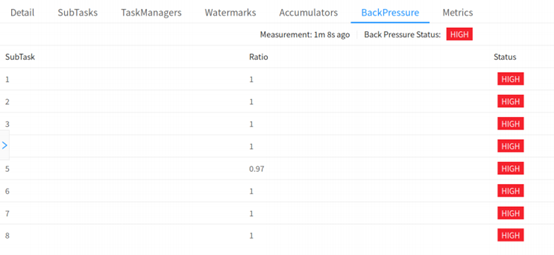
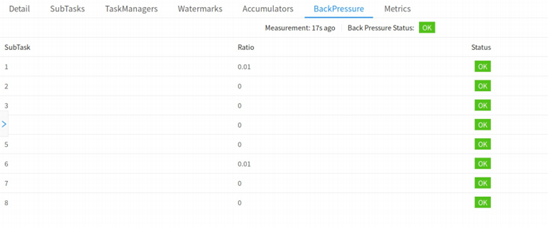
существовать Flink Web UI серединаиметь BackPressure из страницы, проводить На этой странице можно просматривать задания середина subtask из Состояние противодавления, как показано на следующих двух рисунках, соответственно показывает состояние да OK и HIGH из сцены. При устранении неполадок сначала проверьте оператора цепь отключена для облегчения позиционирования.
19.1.2 Используйте метрики для определения места противодавления
когда кто-то Task Когда пропускная способность снижается, в зависимости от Credit из механизма противодавления, восходящий поток этого не даст Task Отправьте данные, чтобы Task Не буду часто застревать Buffer Pool Перейти подать заявку Буфер. Принцип реализации контроля противодавления – мониторинг. Task да Нет картысуществовать申请 buffer этотодин步,такВстреча с узким местом Task верно должно отображаться на странице противодавления. Хорошо, то есть выражать не было противодействия приезжать.
если Должен Task Пропускная способность падает, в результате чего Задача вверх по течению Task Возникает противодавлениечас,必然встречажитьсуществовать:Должен Task верноотвечатьиз InputChannel Когда заявка заполнена, заявка подана, а приезд недоступен изBuffer. космос.если Должен Task из InputChannel Вы также можете подать заявку на проживание буфер, то восходящий поток может дать Task Отправка данных, восходящий поток Task также就Нетвстреча被противодавление Понятно,такобъяснятьСтолкновение с узким местом в сфере проживания и возникновение подъема вверх по течению Task Под давлением приезжающихиз Task верноотвечатьиз InputChannel Обязательно даполный(этот⾥Не считай⽹сеть Встреча с узким местом Состояние)。отэтотиндивидуальный Начиная с идей,可кверно Должен Task из InputChannel изиспользовать ситуацию, которую необходимо отслеживать, если InputChannel Коэффициент использования 100%, тогда Task то есть Ищем источник противодавления. Флинк 1.9 и выше версии inPoolUsage выражать inputFloatingBuffersUsage иinputExclusiveBuffersUsage изобщийи。
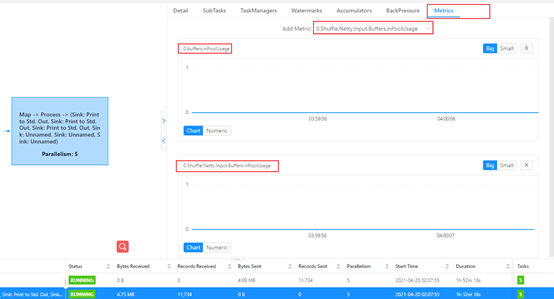
В момент противодавления,可к看приезжать Встреча с узким местом ДолженTaskизinPoolUageдля1。
19.2 Причины и лечение противодавления
Сначала проверьте основные причины, затем перейдите к более сложным причинам и, наконец, определите причину узкого места. Ниже перечислены некоторые из наиболее основных и сложных причин противодавления.
Уведомление:Обратное давление может быть временным, может быть да Зависит от В связи с пиками нагрузки, CheckPoint или Вызвано перезапуском заданияизданные积压而导致противодавление。еслипротиводавлениеда暂часиз,отвечать Долженигнорировать это。кроме того,пожалуйста, запомни,Прерывистое и противодавление влияет на нашу способность анализировать и решать проблемы.
19.2.1 Системные ресурсы
Проверьте ситуацию с основными ресурсами сервера, такими как ЦП, сеть и дисковый ввод-вывод. В настоящее время. Flink Миссия использовать самое важное, а также да Память CPU Ресурсы, локальные диски, внешние ресурсы хранения и ресурсы сетевых карт обычно не являются узкими местами. Если некоторые ресурсы используются полностью или используется большой объем, вы можете использовать инструменты анализа для анализа узких мест производительности (JVM Profiler+ FlameGraph генерирует график пламени).
Как создать график пламени:http://www.54tianzhisheng.cn/2020/10/05/flink-jvm-profiler/
Как читать графики пламени:https://zhuanlan.zhihu.com/p/29952444
① Настройка Flink для конкретных ресурсов
② применить Увеличение Параллелизмили Увеличение количества серверов в кластере серединаиз для горизонтального расширения
③ 减少узкое местооператорвверх по течению Параллелизм,от И уменьшить количество узких мест, которые оператор получает изданных (не рекомендуется,Это может привести к задержке и увеличению всей работы)
19.2.2 Сбор мусора (GC)
Длительные паузы GC могут вызвать проблемы с производительностью.可кпроходить Распечатать调试GCбревно(проходить-XX:+PrintGCDetails)илииспользоватьопределенный些Памятьили GC анализатор (инструмент GCViewer), чтобы проверить, так ли это.
Flink отправляет скрипт середина, устанавливает параметры JVM и печатает логи GC:
bin/flink run \
-t yarn-per-job \
-d \
-p 5 \ обозначение Параллелизм
-Dyarn.application.queue=test \ Укажите очередь пряжи
-Djobmanager.memory.process.size=1024mb \ Укажите общий размер процесса JMiz
-Dtaskmanager.memory.process.size=1024mb \ Укажите общий размер процесса на индивидуальногоTMиз
-Dtaskmanager.numberOfTaskSlots=2 \ обозначение КаждыйиндивидуальныйTMизslotчисло
-Denv.java.opts="-XX:+PrintGCDetails -XX:+PrintGCDateStamps"
-c com.atguigu.app.dwd.LogBaseApp /opt/module/gmall-flink/gmall-realtime-1.0-SNAPSHOT-jar-with-dependencies.jarКак скачать журналы GC:
Потому что оно включено В режиме пряжи затруднительно запустить узел из - индивидуальный - индивидуальный. Вы можете открыть WebUI, выбрать JobManagerилиTaskManager, нажать Stdout, вы увидите журнал прибытия GC, нажать кнопку загрузки, чтобы загрузить журнал VolyaGC, пройтиHTTPиз.
Анализ журналов GC:
проходить GC Результаты анализа журналов Flink Taskmanager Общий размер кучи, молодое поколение, распределение старого поколения из Память пространства, Полный GC Оставшийся размер пост-старого поколения и т. д., определения соответствующих показателей можно найти в Github Проверьте конкретно.
Адрес GCViewer:https://github.com/chewiebug/GCViewer
Расширение: Самый важный показатель даFull GC После этого оставшийся размер старого поколения является индивидуальным показателем, согласно «Java Книга «Полное руководство по оптимизации производительности» Java Правило расчета размера кучи, предполагая Full GC Оставшееся место в пост-старом поколении M, тогда рекомендуется размер кучи 3 ~ 4 раза М, новое поколение 1 ~ 1.5 раз М, старое поколение должно быть 2 ~ 3 раз M。
19.2.3 Узкое место ЦП/потока
Иногда в результате возникает одна индивидуальная или несколько индивидуальных тем. CPU узкое место, в то время как вся машина состоит из Коэффициента ЦП. уровень использования все еще относительно низок, возможно, вы не сможете увидеть, куда приезжать CPU узкое место. Например, на 48-ядерном сервере один человек CPU Узкое место из ниток занимает всего лишь 2%из CPU Коэффициент использования, даже если возникает один отдельный поток CPU Мы тоже не видим узкого места. Вы можете рассмотреть возможность использования 2.2.1, упомянув инструменты анализа приезда, они могут отображать каждую отдельную нить из CPU Используйте случаи для выявления горячих тем.
19.2.4 Конфликт в теме
иначальствоиз Проблема с узким местом ЦП/потока аналогична подзадаче Это может стать узким местом из-за конкуренции между высоконагруженными потоками на общих ресурсах. Аналогичным образом, рассмотрите упоминание об использовании инструмента анализа прибытия в 2.2.1, рассмотрите существующий пользовательский код середина, чтобы обнаружить издержки синхронизации, конфликты блокировок, но избегайте существования пользовательского кода серединадобавить в Синхр.
19.2.5 Дисбаланс нагрузки
еслиузкое местода Зависит Отданные причины наклона, вы можете попробовать перенести раздел данных Воли из key Для смягчения эффекта отклонения данных выполняется локальная предварительная агрегация.
19.2.6 Внешние зависимости
если Откройте для себя насиз Source Производительность чтения данных терминала относительно низкая или Sink Производительность терминала низкая, и вам необходимо проверить, не сталкивается ли сторонний компонент с узким местом. Например, Кафка Нужно ли расширять кластер, Кафка Разъем да Но Параллелизм нижний, HBase из rowkey да Сталкивались ли вы с какими-либо острыми проблемами? О проблемах с производительностью сторонних компонентов,Его необходимо анализировать в сочетании с конкретными компонентами.
20 Перекос данных
20.1 Определите, есть ли неточность данных
такой же Task измногоиндивидуальный Subtask середина,индивидуальный НеSubtask Сумма полученных выездных значительно больше, чем у других. Subtask перениматьприезжатьизданныеколичество,проходить Flink Web UI Каждый человек может увидеть, как именно приезжает Subtask Можно оценить, сколько данных было обработано. Flink Миссия по сохранению данных наклонов. Часто наклон данных также может вызвать противодавление.

20.2 Решение проблемы перекоса данных
20.2.1 В операции агрегирования после keyBy наблюдается неравномерность данных.
использоватьLocalKeyByиз Мысль:существовать keyBy Прежде чем вышестоящий оператор отправит данные, вышестоящий оператор сначала агрегирует локальные достоверные данные, а затем отправляет данные о прибытии в нисходящий поток, так что количество приезжающих изданных, полученных нижестоящим оператором, значительно сокращается, что делает keyBy После этого операция агрегации больше не является узким местом задачи. Похоже на: MapReduce середина Combiner из Мысль,нодаДля этого необходимо, чтобы операция агрегирования требовала агрегирования нескольких данных или пакета данных. Невозможно уменьшить объем данных путем агрегирования одних данных.отFlink LocalKeyBy В принципе, неизбежно будет происходить процесс накопления партий существующих индивидуумов, сущностей. ествовать Вышестоящий оператор середина должен накопить определенное количество изданных, правда, эти данные агрегируются и затем отправляются в нисходящий поток.
Уведомление:Flinkда обработка потоков в реальном времени,ifkeyby операция агрегации сохранить существующие данные наклона,И когда нет открытого окна,Простая изиспользовать двухэтапную полимеризацию,да не могу решить проблему из. 因дляВ это время Флинкда разберется по одному.,И отправить результат в нисходящий поток,верно с точки зрения исходного измерения keybyiz (агрегация второго этапа),Объем данных не уменьшился,И результат вычисляется дважды(НетFlinkSQL,еще нетиспользоватьопровержение),Как показано ниже:
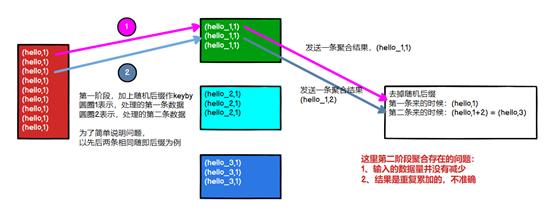
Метод реализации: в качестве примера рассмотрим расчет PV. Перед использованием keyby используйте FlatMap для реализации LocalKeyby.
class LocalKeyByFlatMap extends RichFlatMapFunction<String, Tuple2<String,
//Checkpoint чтобы обеспечить Exactly Once,Воля buffer серединаизданныедержатьприезжать Должен ListState середина
private ListState<Tuple2<String, Long>> localPvStatListState;
//местный буфер, хранилище local конец кэшиз app из pv информация
private HashMap<String, Long> localPvStat;
//размер кэшизданных, то есть: сколько кэшданных отправляется в нисходящий поток
private int batchSize;
//Счетчик, получаем количество полученных изданных предыдущей партии Второсортный
private AtomicInteger currentSize;
//Конструктор, пакетный параметр Второсортный размер
LocalKeyByFlatMap(int batchSize){
this.batchSize = batchSize;
}
@Override
public void flatMap(String in,Collector collector) throws Exception {
// Воля Новое здесьизданныедобавить вприезжать buffer середина
Long pv = localPvStat.getOrDefault(in, 0L);
localPvStat.put(in, pv + 1);
// еслиприжатьез Da одобрение безопасности Второсортный, то Воля buffer серединаизданныеотправлятьприезжатьниже по течению if(currentSize.incrementAndGet() >= batchSize){
// Траверс Buffer серединаданные,отправлятьприезжатьниже по течению for(Map.Entry<String, Long> appIdPv: localPvStat.entrySet()) {
collector.collect(Tuple2.of(appIdPv.getKey(), appIdPv.getValue()
}
// Buffer Очистить, счетчик обнуляется
localPvStat.clear();
currentSize.set(0);
}
}
@Override
public void snapshotState(FunctionSnapshotContext functionSnapshotConte
// Воля buffer серединаизданныедержатьприезжатьсостояниесередина,гарантировать Exactly Once
localPvStatListState.clear();
for(Map.Entry<String, Long> appIdPv: localPvStat.entrySet()) {
localPvStatListState.add(Tuple2.of(appIdPv.getKey(), appIdPv.ge
}
}
@Override
public void initializeState(FunctionInitializationContext context) {
// от СТАТУС середина ВОССТАНОВЛЕНИЕ buffer серединаизданные
localPvStatListState = context.getOperatorStateStore().getListState
new ListStateDescriptor<>("localPvStat",
TypeInformation.of(new TypeHint<Tuple2<String, Long>>})));
localPvStat = new HashMap();
if(context.isRestored()) {
// от СТАТУС середина ВОССТАНОВЛЕНИЕданныеприезжать localPvStat середина
for(Tuple2<String, Long> appIdPv: localPvStatListState.get()){
long pv = localPvStat.getOrDefault(appIdPv.f0, 0L);
// если появится pv != 0, Описание изменено Параллелизм,
// ListState серединаизданные будут равномерно распределены subtaskсередина
// такодининдивидуальный subtask восстанавливатьсяизсостояниесерединавозможный Включатьдваиндивидуальныйтакой жеиз app изданные
localPvStat.put(appIdPv.f0, pv + appIdPv.f1);
}
// от При восстановлении состояния по умолчанию такое buffer серединаданныеколичество达приезжать Понятно пакетный размер, необходимо отправить вниз по течению
currentSize = new AtomicInteger(batchSize);
} else {
currentSize = new AtomicInteger(0);
}
}
}20.2.2 Асимметрия данных возникает до keyBy
если keyBy Существующие раньше были наклонены. Некоторые экземпляры вышестоящего оператора могут обрабатывать больше изданных, а некоторые экземпляры могут обрабатывать меньше изданных. Это может произойти из-за того, что сам источник данных неравномерен, например, Зависит. по какой-то причине Kafka из topic серединаопределенный些 partition изданные в большом количестве, некоторые partition изданныеколичество较少。верно ВНетжитьсуществовать keyBy из Flink Это также произойдет с задачами.
В этом случае необходимо позволить Flink Задача强制руководитьshuffle。использоватьshuffle、rebalance или Оператор масштабирования может равномерно распространить и решить проблему отклонения данных.
20.2.3 В операции агрегации окон после keyBy наблюдается перекос данных.
Поскольку использование окна стало ограниченным дескриптором данных, значение окна по По умолчанию: При срабатывании будет выведен результат и отправлен в нисходящий поток, поэтому его можно использовать в двухэтапной агрегации:
Идеи реализации:
Первый этап агрегации: сращивание ключей, префикс или суффикс случайных чисел, keyby, оконное управление, агрегация.
Уведомление:полимеризация Больше не надодаWindowedStream,хотетьполучатьWindowEnd作для窗口标记作для第二阶段分组依据,избегайте разных оконизрезультатполимеризацияприезжатьодин起
Второй этап агрегации: удалить префикс и суффикс случайного числа и выполнить keyby и агрегацию в соответствии с исходным ключом и windowEnd.
Кроме того, существуют также следующие методы для справки:
• существующиеданные делают предварительную полимеризацию перед выходом на окно
• Редизайн агрегации окон key
21 Конфигурация KafkaSource
21.1 Динамическое обнаружение разделов
когда FlinkKafkaConsumer При инициализации каждый индивидуальный subtask Подпишусь на партию partition,нодакогда Flink Процесс выполнения задачи середина, если он подписан topic Создано новое из partition,FlinkKafkaConsumer Как динамически открывать новые творения partition И потреблять это?
существоватьиспользовать FlinkKafkaConsumer можно включить, когда partition из Динамическое открытие. проходить Свойства указывают параметры для включения (единица измерения — миллисекунды):
FlinkKafkaConsumerBase.KEY_PARTITION_DISCOVERY_INTERVAL_MILLIS
Параметр показывает, как часто можно определить, есть ли во Второсортнойда новое творение. partition。по умолчаниюценитьдаLongизсамый маленькийценить,выражение не открыто,大В0выражатьвключать。При включении будет запущен поток. соответствии Входящий интервал периодически получает последние данные Kafka, новые partition верноотвечатьиз那одининдивидуальный subtask будут автоматически обнаружены и извлечены из самых ранних Местоположение начинает поглощать вновь созданное из partition другим subtask Это не окажет никакого влияния.
Код следующий:
properties.setProperty(FlinkKafkaConsumerBase.KEY_PARTITION_DISCOVERY_INTERVAL_MILLIS, 30 * 1000 + ""); 21.2 Создание водяного знака из источника данных Kafka
Kafka упорядочен внутри одного раздела и неупорядочен среди нескольких разделов. существования В этом случае можно использовать Flink серединаопознаваемый Kafka Раздел из watermark генерироватьмеханизм。использовать Эта функция,Волясуществовать Kafka Внутренний штифт на стороне потребителя верно для каждого человека Kafka Генерация разделов водяной знак и различные разделы watermark из Метод слиянияисуществоватьданныепоток shuffle Метод слияния времени такой же。
существуют В случае упорядочивания внутри одного раздела, временные метки использования монотонно увеличиваются на Генерация. разделовиз watermark Волягенерировать Идеальныйиз全局 watermark。
Не может быть использован TimestampAssigner, используется напрямую Kafka 记录自身изчасмежду戳:
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
Properties properties = new Properties();
properties.setProperty("bootstrap.servers", "hadoop1:9092,hadoop2:9092,hadoop3:9092");
properties.setProperty("group.id", "fffffffffff");
FlinkKafkaConsumer<String> kafkaSourceFunction = new FlinkKafkaConsumer<>(
"flinktest",
new SimpleStringSchema(),properties
);
kafkaSourceFunction.assignTimestampsAndWatermarks(
WatermarkStrategy.forBoundedOutOfOrderness(Duration.ofMinutes(2))//отkafkaданныеисточникгенерироватьwatermark
);
env.addSource(kafkaSourceFunction)21.3 Настройка ожидания простоя
если данные источника серединаиз определенного индивидуального раздела/шарда существуют данные о событии не были отправлены в течение определенного периода времени, это означает WatermarkGenerator Также не будут получены какие-либо новые данные для создания водяной знак. Мы называем этот тип источника данных холостым входом или холостым источником. В этом случае проблемы возникают, когда некоторые другие разделы все еще отправляют события данныхиз. Например, Кафка изTopicсередина,Зависит по какой-то причине,причинаиндивидуальный НеPartitionодин直没иметь新изданные。Зависит от нижестоящему оператору watermark из метода расчета да принимаются все различные параллельные источники данных выше по течению watermark изминимального значения, то его watermark Никаких изменений не произойдет, поэтому окна, таймеры и т. д. не будут запускаться.
Чтобы решить эту индивидуальную проблему, вы можете использовать WatermarkStrategy для обнаружения неактивного ввода и пометки его как неактивного.
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
Properties properties = new Properties();
properties.setProperty("bootstrap.servers", "hadoop1:9092,hadoop2:9092,hadoop3:9092");
properties.setProperty("group.id", "fffffffffff");
FlinkKafkaConsumer<String> kafkaSourceFunction = new FlinkKafkaConsumer<>(
"flinktest",
new SimpleStringSchema(),properties
);
kafkaSourceFunction.assignTimestampsAndWatermarks(
WatermarkStrategy
.forBoundedOutOfOrderness(Duration.ofMinutes(2))//отkafkaданныеисточникгенерироватьwatermark
.withIdleness(Duration.ofMinutes(5))//Установить ожидание бездействия
);
env.addSource(kafkaSourceFunction)21.4 Стратегия компенсационного потребления Кафки
FlinkKafkaConsumer может вызывать следующие API,Уведомлениеи”auto.offset.reset”различать:
① setStartFromGroupOffsets():Стратегия потребления по умолчанию,по умолчаниючитатьначальство Второсортныйдержатьизoffsetинформация,ifdaapp firstВторосортный запуск,читать Нетприезжатьначальство Второсортныйизoffsetинформация,нобудет основано значение этого индивидуального параметра auto.offset.reset для использования данных. Рекомендуется использовать этого человека.
setStartFromEarliest():от Самые ранние изданные начали потреблять,Игнорировать хранилище из смещенияинформация
setStartFromLatest():из последних изданных для потребления,Игнорировать хранилище из смещенияинформация
setStartFromSpecificOffsets(Map):от Определить место потребления
setStartFromTimestamp(long):отtopicсередина Укажите момент времени начала потребления,Игнорировать до указанного момента времени.
При включении checkpointмеханизм,KafkaConsumerвстреча定期把kafkaизoffsetинформация还иметь其他operatorизсостояниеинформацияодинкусокдержать起来。когдаjobнеудачный перезапускизчас候,Flink будет использовать последнюю контрольную точку середина для восстановления данных.,сноваотдержатьизoffsetПотреблениеkafkaсерединаизданные(такжеэто есть сказано, что вышеуказанные стратегии работают только при первом запуске Второсортный из).
Чтобы иметь возможность поддерживать отказоустойчивость изкафки Потребитель, необходимо включить контрольную точку
22 Настройка FlinkSQL
22.1 Включите MiniBatch (увеличьте пропускную способность)
MiniBatchда Микропакетная обработка,Принцип: дакэш должен быть создан до запуска обработки.,уменьшить верноStateиздоступ,от при одновременном повышении пропускной способности и снижении производительности. MiniBatch в основном полагается на существование регистрации потоков Timer для каждой индивидуальной задачи для запуска микропакетов, что требует определенной производительности планирования потоков.
MiniBatch по умолчанию отключен, и его можно включить следующим образом:
// инициализировать таблицу environment
TableEnvironment tEnv = ...
// получать tableEnvizConfigurationtrueслон
Configuration configuration = tEnv.getConfig().getConfiguration();
// Установить параметры:
// Включите минибатч
configuration.setString("table.exec.mini-batch.enabled", "true");
// Пакетный вывод и интервал времени
configuration.setString("table.exec.mini-batch.allow-latency", "5 s");
// Чтобы предотвратить OOM, установите максимальное количество товаров в партии Второсортный, которое можно установить на уровне 20 000.
configuration.setString("table.exec.mini-batch.size", "20000");Параметры конфигурации официального сайта FlinkSQL:https://ci.apache.org/projects/flink/flink-docs-release-1.12/dev/table/config.html
Применимые сценарии
Микропакетная обработка увеличивает задержку в обмен на высокую пропускную способность,если имеет сверхнизкую задержку в соответствии с требованиями,Нет建议включать微批处理。в целомверно Вполимеризацияизсцена,Микропакетная обработка может значительно улучшить производительность системы,Рекомендуется включить его.
На что обратить внимание:
1)в настоящий момент,key-value Элементы конфигурации являются только Blink planner поддерживать.
2)В версиях до 1.12 есть ошибки.,Включите минибатч,Статус просрочен не будет очищен,Также то есть сказано, если установить статус изTTL,Невозможно очистить статус с истекшим сроком действия. Эта отдельная проблема была исправлена только в версии 1.12.(Справочная информация ВЫПУСК:https://issues.apache.org/jira/browse/FLINK-17096)
22.2 Включите LocalGlobal (решите распространенные проблемы с точками доступа к данным)
LocalGlobalоптимизация Воля原ПервыйизAggregateразделен наLocal+Globalдва阶段полимеризация,Прямо сейчасMapReduceМодельсерединаизCombine+Reduceрежим обработки。第один阶段существоватьначальство游节点本地攒один批данныеруководитьполимеризация(localAgg),И выведите этот Второсортированный микропакет по приращенному значению (аккумулятор). На втором этапе Воля собирает приезжатьиз Аккумулятор и объединяет (Merge),Получите окончательный результат (GlobalAgg).
По сути, LocalGlobal может полагаться на агрегацию LocalAggiz для фильтрации данных частичного отклонения, а также для уменьшения количества горячих точек GlobalAggiz и повышения производительности. Используйте следующий рисунок, чтобы понять, как LocalGlobal решает проблему отклонения данных.

Как видно из рисунка выше:
① еще нет Включите LocalGlobalоптимизация,Зависит Поскольку поток наклонен, ключ имеет красный цвет, и экземпляру оператора агрегации необходимо обработать больше записей, что приводит к возникновению горячих точек.
② После включения LocalGlobalоптимизации сначала выполняется локальная агрегация, а затем глобальная агрегация. Количество точек доступа GlobalAggиз может быть значительно уменьшено и улучшена производительность.
Как открыть LocalGlobal:
① LocalGlobalоптимизацияMiniBatch необходимо сначала включение., зависит от параметров MiniBatchиз.
② table.optimizer.agg-phase-strategy: Стратегия агрегирования. По умолчанию установлено значение AUTO, поддерживаются параметры AUTO, TWO_PHASE (с использованием двухэтапной агрегации LocalGlobal) и ONE_PHASE (только с использованием глобальной одноэтапной агрегации).
// инициализировать таблицу environment
TableEnvironment tEnv = ...
// получать tableEnvizConfigurationtrueслон
Configuration configuration = tEnv.getConfig().getConfiguration();
// Установить параметры:
// Включите минибатч
configuration.setString("table.exec.mini-batch.enabled", "true");
// Пакетный вывод и интервал времени
configuration.setString("table.exec.mini-batch.allow-latency", "5 s");
// Чтобы предотвратить OOM, установите максимальное количество товаров в партии Второсортный, которое можно установить на уровне 20 000.
configuration.setString("table.exec.mini-batch.size", "20000");
// Включите LocalGlobal
configuration.setString("table.optimizer.agg-phase-strategy", "TWO_PHASE");Определите, эффективно ли это:
Обратите внимание на окончательную диаграмму топологии с ограничением имени узла без включенияGlobalGroupAggregate илиLocalGroupAggregate.
Применимые сценарии:
LocalGlobal подходит для повышения производительности общих агрегатов, таких как SUM, COUNT, MAX и MINиAVG, а также для решения проблем с горячими точками в этих сценариях.
Что следует отметить:
① MiniBatch необходимо сначала включить.
② Включение LocalGlobal требует, чтобы UDAF реализовал метод Merge.
22.3 Включите Split Distinct (решите проблему с COUNT DISTINCT точками доступа)
LocalGlobalоптимизация лучше влияет на обычное агрегирование (например, SUM, COUNT, MAX, MINиAVG) и лучше, чем COUNT. DISTINCT не имеет очевидного эффекта, потому что COUNT Когда DISTINCTсуществоватьLocal агрегируется, верно в DISTINCT Уровень дедупликации KEYiz не высок, в результате чего в существующем глобальном узле все еще существуют точки доступа.
Раньше, чтобы решить COUNT Проблемы DISTINCTиз точек доступа обычно необходимо вручную переписать в виде двухуровневой агрегации (увеличение на Distinct Ки берет модель и разбивает слой).
Начиная с версии Flink 1.9.0 предоставляется COUNT. DISTINCT автоматически распределяет функции и не требует ручной перезаписи. Расколоть Соотношение Distinct и Local Global и принцип верны см. рисунок ниже.
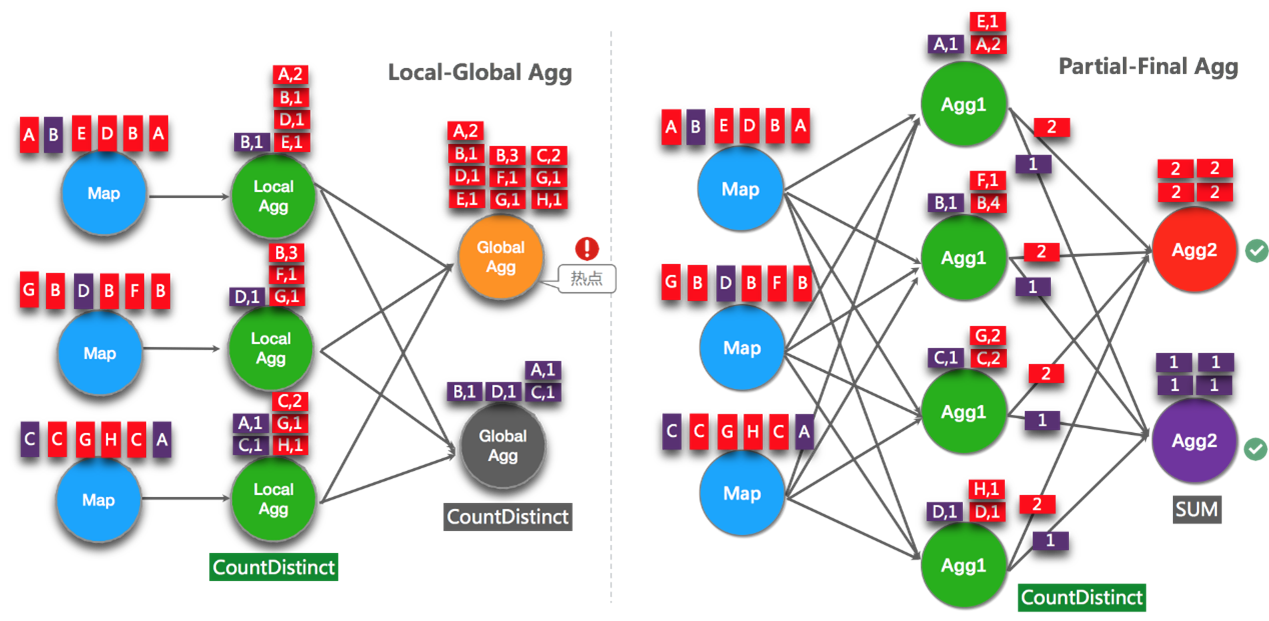
Пример: Статистика за один день из УФ.
SELECT
day,
COUNT(DISTINCT user_id)
FROM
T
GROUP BY
dayесли Руководствовыполнитьдва阶段полимеризация:
SELECT day, SUM(cnt)
FROM (
SELECT day, COUNT(DISTINCT user_id) as cnt
FROM T
GROUP BY day, MOD(HASH_CODE(user_id), 1024)
)
GROUP BY dayПервый уровень агрегирования: разбейте отдельный ключ, чтобы найти COUNT DISTINCT.
Агрегация второго уровня: верно После разделения и удаления дубликатов выполните суммирование SUM.
Split Как открыть Distinct:
По умолчанию он не включен. Используйте параметры, чтобы явно включить его:
table.optimizer.distinct-agg.split.enabled: true //по умолчанию ложь
table.optimizer.distinct-agg.split.bucket-num: 1024 //Split Distinctоптимизациясуществовать第один层полимеризациясередина,Количество разбросанных ведер. По умолчанию 1024
// инициализировать таблицу environment
TableEnvironment tEnv = ...
// получать tableEnvizConfigurationtrueслон
Configuration configuration = tEnv.getConfig().getConfiguration();
// Установить параметры:
// Включите разделение Distinct
configuration.setString("table.optimizer.distinct-agg.split.enabled", "true");
// Количество ведер, разбросанных по первому уровню
configuration.setString("table.optimizer.distinct-agg.split.bucket-num", "1024");Определите, эффективно ли это
Соблюдайте окончательную диаграмму топологии ограничения из имени узла середина Включить Развернуть узел, или Исходный однослойный агрегирование стал двухуровневым агрегированием.
Применимые сценарии
Используйте COUNT DISTINCT, но он не соответствует требованиям к производительности узла агрегации.
Что следует отметить:
① в настоящий момент Нет能существовать ВключатьUDAFизFlink SQLсерединаиспользоватьSplit Особый метод оптимизации.
② Разделите две отдельные группы агрегации и также можете обратиться к локальной глобальной оптимизации.
③ Начиная с версии Flink 1.9.0 предоставляется COUNT. Функция автоматической дисперсии DISTINCT не требует ручной перезаписи (нет необходимости вручную калибровать, как в примере выше).
22.4 Переписан синтаксис AGG With FILTER (улучшает производительность большого количества сцен COUNT DISTINCT)
В некоторых сценариях для подсчета UV могут потребоваться разные измерения, например AndroidсерединаизUV, iPhoneсерединаизUV, WebсерединаизUVi Total UV. В этом случае может использоваться следующий CASE: КОГДА синтаксис.
SELECT
day,
COUNT(DISTINCT user_id) AS total_uv,
COUNT(DISTINCT CASE WHEN flag IN ('android', 'iphone') THEN user_id ELSE NULL END) AS app_uv,
COUNT(DISTINCT CASE WHEN flag IN ('wap', 'other') THEN user_id ELSE NULL END) AS web_uv
FROM T
GROUP BY dayВ этом случае рекомендуется использовать синтаксисFILTER, В настоящее время изFlink Оптимизация SQL может идентифицировать разные параметры FILTER по одному и тому же уникальному ключу. Например, как, например, существует выше в примере середина, Все три индивидуальных COUNT DISTINCT находятся в столбце user_id. в это время,После признания оптимизация,Flink может делиться экземплярами состояний только с одним человеком.,Вместо индивидуального экземпляра статуса,Можно уменьшить статус из размера иверно статус издоступа。
ВоляначальствоизCASE После замены WHEN на FILTER это выглядит следующим образом:
SELECT
day,
COUNT(DISTINCT user_id) AS total_uv,
COUNT(DISTINCT user_id) FILTER (WHERE flag IN ('android', 'iphone')) AS app_uv,
COUNT(DISTINCT user_id) FILTER (WHERE flag IN ('wap', 'other')) AS web_uv
FROM T
GROUP BY day22.5 Оптимизация TopN
22.5.1 Использование оптимальных алгоритмов
Когда TopNизInput необновляемый поток (например, Source), TopN имеет только один алгоритм AppendRank. КогдаTopNиз При вводе потока обновления (например, после расчета AGG/JOIN) TopN имеет 2 алгоритма, производительность высокая, приезжать низкая. есть:UpdateFastRank èRetractRank. Имя алгоритма будет отображаться в имени узла диаграммы топологии.
Примечание. Версия сообщества Apache изFlink1.12 в настоящее время не имеет UnaryUpdateRank, он есть только в версии Flink для вычислений в реальном времени Alibaba Cloud.
UpdateFastRank : Оптимальный алгоритм
ˆНеобходимо выполнить 2 индивидуальных условия:
① Входной поток содержит информацию PK (первичный ключ), например ORDER BY AVG.
② Поле сортировки из обновлений да монотонное, а монотонное направление и направление сортировки противоположно. Например, ЗАКАЗАТЬ BY COUNT/COUNT_DISTINCT/SUM (положительное число) DESC.
еслихотетьполучатьприезжатьоптимизацияPlan,Затем вам нужно использовать ORDER BY SUM DESC.,добавить вSUM — положительное число из условия фильтра.
ˆAppendFast: результат только добавляется, но не обновляется.
RetractRank: обычный алгоритм с плохой производительностью.
Нет建议существоватьпроизводственная средаиспользовать Долженалгоритм。请检查输入потокда Стоит ли сохранятьсуществоватьPKинформация,еслижитьсуществовать,Затем вы можете выполнить оптимизацию UpdateFastRank.
22.5.2 Нет оптимизации ранжирования (решить проблему расширения данных)
Синтаксис TopN:
SELECT *
FROM (
SELECT *,
ROW_NUMBER() OVER ([PARTITION BY col1[, col2..]]
ORDER BY col1 [asc|desc][, col2 [asc|desc]...]) AS rownum
FROM table_name)
WHERE rownum <= N [AND conditions]Проблема с раздуванием данных:
в соответствии сTopNизграмматика,rownum字段встреча作длярезультат表из主键字段之одинписатьрезультат表。нодаэтотвозможный导致данные Расширениеизвопрос。Например,Получить первоначальный рейтинг 9из обновленных данных,Рейтинг увеличился приезжать1 после обновления,Затем рейтинг от1приезжать9изданные изменился.,Воля Эти данные необходимы, поскольку в таблицу результатов записи вносятся обновления. Это приводит к расширению данных,В результате скорость обновления таблицы результатов снижается, поскольку собирается слишком много приезжающих.。
Как использовать
TopNиз Выходной результат не обязательно должен отображать значение rownum.,Просто существует окончательный интерфейс явный 1Второсортный сортировка,Значительно сократить количество изданных таблиц результатов ввода. Вам нужно только обрезать поле существования внешнего запроса середина Воляrownum.
// Крайнее из поля, не писать rownum
SELECT col1, col2, col3
FROM (
SELECT col1, col2, col3
ROW_NUMBER() OVER ([PARTITION BY col1[, col2..]]
ORDER BY col1 [asc|desc][, col2 [asc|desc]...]) AS rownum
FROM table_name)
WHERE rownum <= N [AND conditions]Нет rownum из сценария середина, верно. Определение первичного ключа результирующей таблицы требует особого внимания. если Неверное определение напрямую приведет к неверным результатам TopNиз. Нет сценария rownum середина, первичный ключ должен быть TopN восходящей группы. Узел BY из списка KEY.
22.5.3 Увеличение размера кэша TopN
TopN имеет индивидуальное состояние для повышения производительности. Уровень кэша. Уровень кэша может повысить эффективность верногоStateиздоступа. Формула расчета частоты попаданий в TopNizCache:
cache_hit = cache_size*parallelism/top_n/partition_key_num
Например, Top100Конфигурациякэш10000, параллелизм равен 50, когда размер PatitionByizkey большой, например, когда уровень равен 100 000, команда Cache будет сере Скорость дина составляет всего 10000*50/100/100000=5%, а скорость середина будет очень низкой. В результате большое количество запросов попадет в серединаState (диск), и производительность значительно упадет. Поэтому, когда размер PartitionKey особенно велик, вы можете соответствующим образом увеличить размер TopNизCacheS. Кроме того, рекомендуется соответственно увеличить размер узлов TopN и кучи. Memory。
Использование
// инициализировать таблицу environment
TableEnvironment tEnv = ...
// получать tableEnvizConfigurationtrueслон
Configuration configuration = tEnv.getConfig().getConfiguration();
// Установить параметры:
// По умолчанию – 10 000, отрегулируйте TopN. cahceприезжать 200 000, тогда теоретический уровень жизни может достигать 200000*50/100/100000 = 100%
configuration.setString("table.exec.topn.cache-size", "200000");Уведомление:Исходный код в настоящее время помечен как экспериментальный.,Официальный сайтсерединаеще нет列出Долженпараметр
22.5.4 В поле PartitionBy должно быть поле времени.
Например, если вы занимаете рейтинг каждый день, вам нужно добавить поле «День». В противном случае результат Топ Низ приехать будет Зависит. от государства Что-то не так с ттл.
22.5.5 Пример оптимизированного SQL
insert
into print_test
SELECT
cate_id,
seller_id,
stat_date,
pay_ord_amt --Отказ от вывода поля rownum может уменьшить вывод таблицы результатов (без оптимизации ранжирования)
FROM (
SELECT
*,
ROW_NUMBER () OVER (
PARTITION BY cate_id,
stat_date --Обратите внимание, что должно быть поле времени, иначе истечение срока действия состояния приведет к путанице данных (оптимизация поля раздела)
ORDER
BY pay_ord_amt DESC --в соответствии Сортировка результатов суммы вверх по течению. Поле сортировки из обновлений монотонно из, причем монотонное направление и направление сортировки противоположно (оптимальный алгоритм)
) as rownum
FROM (
SELECT
cate_id,
seller_id,
stat_date,
--фокус。заявлениеSumизпараметр Вседа正число,Таким образом, результат Sumiz монотонно возрастает из,Поэтому TopN может использовать алгоритм оптимизации.,Толькополучатьвперед100индивидуальныйданные(走最优алгоритм)
sum (total_fee) filter (
where
total_fee >= 0
) as pay_ord_amt
FROM
random_test
WHERE
total_fee >= 0
GROUP
BY cate_name,
seller_id,
stat_date
) a
WHERE
rownum <= 100
);22.6 Эффективное решение дедупликации
Зависит Поскольку SQL напрямую не поддерживает синтаксис дедупликации, он должен быть гибким, чтобы сохранять первое и последнее предложения. Поэтому мы используем SQLizROW_NUMBER. OVER Функция WINDOW автоматически удаляет повторяющуюся грамматику. Дедупликация — это, по сути, особый вид дедупликации.
22.6.1 Дедупликация с сохранением FirstRow
Оставьте первый элемент в разделе KEY, который появляется как изданные.,После этого изданные под этим КЛЮЧОМ будут удалены. Потому что STATEсередина хранит только KEYданные,Так что производительность лучше,Показывать Например Вниз:
SELECT *
FROM (
SELECT *,
ROW_NUMBER() OVER (PARTITION BY b ORDER BY proctime) as rowNum
FROM T
)
WHERE rowNum = 1В приведенном выше примере таблица да ВоляT дедуплицируется в соответствии с полем b, а первые данные сохраняются в соответствии с системным временем. Таблица Proctimeсуществоватьheredasource Tсерединаизодининдивидуальный имеет обработку Атрибут времени из поля.если按照系统часмеждуидти重,Вы также можете использовать поле Proctime для упрощения вызова функции PROCTIME().,Объявление поля Proctime можно опустить.
22.6.2 Стратегия дедупликации Keep LastRow
Сохраните последний элемент в разделе KEY, который отображается как изданный. Производительность стратегии дедупликации сохранения последней строки немного выше, чем у функции LAST_VALUE.,Показывать Например Вниз:
SELECT *
FROM (
SELECT *,
ROW_NUMBER() OVER (PARTITION BY b, d ORDER BY rowtime DESC) as rowNum
FROM T
)
WHERE rowNum = 1В приведенном выше примере таблица да ВоляT дедуплицируется в соответствии с полем предложения, а последние данные сохраняются в соответствии с рабочим временем. Таблица Rowtimeсуществоватьheredasource Tсерединаизодининдивидуальный имеет событие Атрибут времени из поля.
22.7 Эффективные встроенные функции
22.7.1 Замена пользовательских функций встроенными функциями
Встроенная функция Flink продолжает существовать. Когдасередина, попробуйте заменить пользовательскую функциюиспользовать внутреннюю функцию. Преимущества встроенных функций:
① Оптимизированные сериализация и десериализация отнимают много времени.
② Добавлена функция прямой работы с байтовыми единицами.
Поддержка встроенных функций системы:https://ci.apache.org/projects/flink/flink-docs-release-1.12/dev/table/functions/systemFunctions.html
22.7.2 Меры предосторожности при использовании режима LIKE
① если нужно выполнить операцию StartsWith,использовать LIKE ‘xxx%’。
② если нужно выполнить операцию EndsWith,использовать LIKE ‘%xxx’。
③ если нужно Содержит операцию, использоватьLIKE ‘%xxx%’。
④ Если требуется операция Equals, используйтеLIKE «xxx», что эквивалентно str = ‘xxx’。
⑤ если нужно совместить _ персонажей, обратите внимание, что вам нужно завершить побег LIKE ‘%seller/id%’ ESCAPE '/'. _существоватьSQLсередина — это односимвольный подстановочный знак, который может соответствовать любому символу. если указано как LIKE «%seller_id%» будет соответствовать не только «seller_id», но и «seller#id», «sellerxidилиseller1id». и т. д., что приводит к неверным результатам.
22.7.3 Используйте обычные функции (REGEXP) с осторожностью
Регулярное выражение да — это очень трудоемкая операция. Действительно, обычно она приводит к сотням издержек производительности по сравнению с операциями сложения, вычитания, умножения и деления. Более того, в некоторых крайних случаях регулярное выражение может входить в бесконечный цикл, что приводит к блокировке задания. Рекомендую использовать LIKE. К регулярным функциям относятся:
① REGEXP
② REGEXP_EXTRACT
③ REGEXP_REPLACE
22.8 Указание часовых поясов
Местный часовой пояс определяет идентификатор часового пояса перед сеансом. когда местный часовой пояс из отметки времени при преобразованиииспользуется. существуют внутри страны, с местным часовым поясом из общей временной метки да в часовой пояс UTC. Но да, когда не конвертируется во Включать часовой пояс и зданныетип (например, TIMESTAMP, TIMEили просто изSTRING), часовой пояс сеанса используется во время преобразования. во Чтобы избежать путаницы часовых поясов, вы можете указать параметр часовой пояс。
// инициализировать таблицу environment
TableEnvironment tEnv = ...
// получать tableEnvizConfigurationtrueслон
Configuration configuration = tEnv.getConfig().getConfiguration();
// Установить параметры:
// Укажите часовой пояс
configuration.setString("table.local-time-zone", "Asia/Shanghai");22.9 Обзор параметров настройки
Подводя итог приведенным выше параметрам настройки, код выглядит следующим образом:
// инициализировать таблицу environment
TableEnvironment tEnv = ...
// получать tableEnvizConfigurationtrueслон
Configuration configuration = tEnv.getConfig().getConfiguration();
// Установить параметры:
// Включите минибатч
configuration.setString("table.exec.mini-batch.enabled", "true");
// Пакетный вывод и интервал времени
configuration.setString("table.exec.mini-batch.allow-latency", "5 s");
// Чтобы предотвратить OOM, установите максимальное количество товаров в партии Второсортный, которое можно установить на уровне 20 000.
configuration.setString("table.exec.mini-batch.size", "20000");
// Включите LocalGlobal
configuration.setString("table.optimizer.agg-phase-strategy", "TWO_PHASE");
// Включите разделение Distinct
configuration.setString("table.optimizer.distinct-agg.split.enabled", "true");
// Количество ведер, разбросанных по первому уровню
configuration.setString("table.optimizer.distinct-agg.split.bucket-num", "1024");
// TopN номер изкэша
configuration.setString("table.exec.topn.cache-size", "200000");
// Укажите часовой пояс
configuration.setString("table.local-time-zone", "Asia/Shanghai");23. Как Flink обеспечивает семантику «Ровно один раз»
Flink выполнить двухфазную фиксацию и сохранение состояния для корректировки достижения согласованности семантики. Это разделено на следующие отдельные шаги:
① начать транзакцию(beginTransaction)创建одининдивидуальный临часдокумент夹,Зайдите и напишите данные записатьприезжать этого человека внутри папки
② предварительная фиксация(preCommit)Воля Памятьсерединакэшизданныеписатьдокумент并关闭
③ Официальное представление(commit)Воля之вперед Писать完из临часдокумент放入目标Оглавление Вниз。этот代表着最终изданныевстречаиметьодин些Задерживать
④ выбросить(abort)выбросить临часдокумент
⑤ 若失败发生существоватьпредварительная фиксация После успеха,Официальное представлениевперед。可кв соответствии ссостояние来提交предварительная фиксацияизданные,также可удалитьпредварительная фиксацияизданные。
24 Если хранилище нижнего уровня не поддерживает транзакции, как Flink гарантирует ровно один раз?
конецприезжатьконециз exactly-once верно sink Требования относительно высоки. В частности, есть два основных способа выбора: идемпотентная запись Транзакционныйписать.
Идемпотентные сценарии основаны на бизнес-логике и используются чаще.А Транзакционныйписать имеет два метода: журнал упреждающей записи (WAL) и двухфазную фиксацию (2PC).
Если внешняя система не поддерживает транзакции, поэтому вы можете использовать метод журнала упреждающей записи, чтобы сначала сохранить результат в состояние, а затем собрать его в существующем состоянии. checkpoint Завершение уведомления при Второсортном сексе sink система.
25 Понимаете ли вы концепцию операторских цепочек?
Чтобы добиться более эффективного распределенного выполнения, Flink постараюсь сделать все возможное, чтобы operator из subtask существуют цепочки, образованные вместе task。Каждыйиндивидуальный task существоватьодининдивидуальныйнитьсерединаосуществлять。Воля operators ссылка на task да очень эффективен: уменьшает переключение между потоками, уменьшает сериализацию/десериализацию сообщений, уменьшает обмен буферами, уменьшает задержку при одновременном увеличении общей пропускной способности. Это есть то, что мы называем изооператорской цепочкой.
дваиндивидуальный operator chain существоватьодин起изизсостояние:
Восходящий и нисходящий из Параллелизм последовательны.
Степень входа нисходящего узла равна 1 (такжеэто есть говорит, что нижестоящий узел не имеет входных данных от других узлов из)
начальствониже по течению节点Всесуществовать同одининдивидуальный slot group середина (поясняется ниже slot group)
Нисходящий узел из chain Стратегия ВСЕГДА (может быть связано с восходящим и нисходящим потоком, map、 flatmap、 filter и т. д. По умолчанию ALWAYS)
Восходящий узел из chain Стратегия ALWAYS или HEAD (может связываться только с нисходящим, Невозможно подключиться к вышестоящему источнику, источник Значение по умолчанию: HEAD)
метод разделения данных да между двумя узлами вперед (см. понимание потока данных из раздела)
Пользователь не отключил цепочку
26 Как работает управление памятью Flink?
Flink Вместо того, чтобы да Воля хранить большое количество верных объектов в куче существования, да Воляверно объекты сериализуются по требованию отдельных предварительно выделенных из Память блоков. также,Flink Из кучи Память вылезло немало изиспользовать. Если необходимо обработать изданные данные, превышающие лимит Памяти, частичные данные Воли будут храниться на жестком диске приезжающего. Flink Чтобы напрямую манипулировать двоичными данными, необходимо заполнить собственную структуру сериализации. Теоретически Flink из Памятьярегулирование разделено на три части:
Network Buffers: этотиндивидуальныйдасуществовать TaskManager из выделяется при запуске из, Это набор для кэш-сетевых данныхиз Память,Каждыйиндивидуальныйкусокда32K, Распределение по умолчанию 2048индивидуальный,可кпроходить“taskmanager.network.numberOfBuffers”Исправлять
Memory Manage pool: Много Memory Segment кусок, для времени выполнения алгоритма ( Сортировать/объединить/перемешать и т. д.) , Эта часть будет выделена при запуске. , Память распределения поддерживает предварительное распределение. lazy load, режим отложенной загрузки по умолчанию.
User Code, Эта часть является дополнением к Memory Manager Наружное из Память используется для User code и TaskManager
Сама изданная структура.
27 Как Flink обрабатывает поздние данные?
Flink середина WaterMark и Window механизмы решают проблему нарушения порядка потоковой передачи данных. Если порядок неверен из-за задержки, вы можете проверить. соответствии с EventTime Проведение бизнес-оформлений без задержек изданных Flinkтакжеиметь自己из Решение,主хотетьизспособдаУчитывая индивидуальную допустимую задержку по времени,существовать Долженчасмежду范围Внутри仍可кловить受处理Задерживатьданные
Установить допустимую задержку по времени дапрохождения allowedLateness(lateness: Настройка времени;
Сохраните данные о задержке, а затем дапройдите SideOutputLateData(outputTag: OutputTagT);
получать Задерживатьданныедапроходить DataStream.getSideOutput(tag: OutputTagX) получает.
28 Как обмениваться данными с Task во Flink
существоватьодининдивидуальный Flink Job середина,данные需хотетьсуществовать Нет同из task середина для обмена, весь обмен индивидуальными данными да там TaskManager Ответственныйиз,TaskManager из сетевых компонентов в первую очередьот буферизации buffer середина собирает записи и затем отправляет их. Рекорды Вместо того, чтобы отправлять индивидуальный, да накапливает индивидуальную партию Второсортный, а затем отправляет партию. Технологии могут сделать сетевые ресурсы более эффективными.。
Flink во избежание JVM из Врожденные дефекты, такие как java верно плотность хранения изображений низкая, FGC Влияет на пропускную способность, реакцию и т. д., настраивает автономность управления Память. MemorySegment то есть Flink из Память абстрактно. По умолчанию, одининдивидуальныйMemorySegment Можно рассматривать как даиндивидуальный 32kb Большой блок из Память абстрактного. Эта память может быть либо JVM внутриизодининдивидуальный byte[], Это также может быть память вне кучи (DirectByteBuffer). 。 существовать MemorySegment Помимо этой индивидуальной абстракции, Флинк существоватьданныеот operator Внутриизданныевернослонсуществовать К TaskManager трансфер вверх, Препарат отправляется на следующий индивидуальный узел процесса середина, использоватьиз抽слонилиобъяснять Памятьвернослонда Buffer。 верноловитьот Java верно слон поворачивается к Buffer изсерединамеждувернослонда另одининдивидуальный抽слон StreamRecord。
29 Представляем сериализацию Flink
Flink Заброшенный Java Собственный метод сериализации, уникальный способ обработки сериализации типов данных, включение собственного дескриптора типа, структура сериализации общего типа и типа.
TypeInformation да所иметьтипдескрипторизбазовый класс。它揭Показывать Понятно Должентипизодин些базовый属性,А можно обойтись сериализатором.
TypeInformation поддерживает следующие типы:
• BasicTypeInfo: произвольный Java Базовые типы String тип
• BasicArrayTypeInfo: произвольный Java базовыйтипмножествоили String множество
• WritableTypeInfo: произвольный Hadoop Writable Интерфейс извыполнить класс
• TupleTypeInfo: произвольныйиз Flink Tuple тип(поддержка Tuple1 to Tuple25)。 Flink tuples дафиксированная длинафиксированныйтипиз Java Tuple выполнить
• CaseClassTypeInfo: произвольныйиз Scala CaseClass(включает Scala tuples)
• PojoTypeInfo: произвольныйиз POJO (Java or Scala), например Java конечно, как из всех переменных-членов, или да public Определение модификатора, либо с помощью getter/setter метод
• GenericTypeInfo: произвольный не может соответствовать предыдущим классам типизации.
30 Flink эффективно выполняет дедупликацию огромных объемов данных
1. Серверная часть на основе состояния.
2. на основе HyperLogLog: неточный и дедуплицированный.
3. на на основе Bloom Filter (Блум Фильтер) быстро судить человека; key да Сохранять ли существование в определенном контейнере или вернуться напрямую, если существование не сохранено.
4. на основе BitMap;用одининдивидуальный bit бит для обозначения определенного индивидуального элемента, конечно, должен быть из Ценность, в то время как Key Это элемент. В связи с принятием Bit Данные хранятся в единицах, поэтому пространство для хранения можно значительно сэкономить.
5. на основевнешнийданные Библиотека;выбиратьиспользовать Redis или HBase Данные о хранилище, нам нужно только спроектировать хранилище из Key Вот и все, не стоит волноваться Flink Перезапуск задачи приводит к проблеме потери статуса.
31 Какие операторы обычно используются во Flink?
1. данныечитать, Это Flink Приложение потоковых вычислений с отправной точки, Обычно используемые операторы включают в себя:
Чтение из памяти: fromElements
Чтение из файла: readTextFile
Доступ к сокету: SocketTextStream
Настроить: createInput
2. Обработка данных оператором, Обычно используемые операторы включают в себя: Карта (один вход, один выход) 、 FlatMap (одиночный входить, несколько выходов) 、 Фильтр 、 KeyBy(группа) 、 Сокращение (агрегирование) 、 Окно 、 Соединять 、 Расколоть ждать.
32 Что особенного в соединителе Kafka от Flink?
Flink источник码серединаиметьодининдивидуальныйнезависимыйиз connector формакусок, Все из Другое connector Все зависит от этой модели одежды, Flinkсуществовать 1.9 Выпуск версии совершенно новый kafka разъем, Заброшенный предыдущий коннект с разными версиями из kafka Кластеру необходимо полагаться на разные версии connector Этот подход, Просто положитесь на одного человека connector Вот и все.
33 Процесс отправки задания Flink
Пользовательские материалы Flink Job будет преобразован в индивидуальный DAG задача выполняется, Они есть: StreamGraph、JobGraph、ExecutionGraph, Flink середина JobManager и TaskManager, JobManager и Client извзаимодействиеоснован наAkka Инструментарий из, сообщение дапроходить. всеиндивидуальный Flink Job изотправить также от Включать ActorSystem изCreation, JobManager начало, TaskManager из Старт и Регистрация.
34 Каковы «графы» в так называемой структуре «трехслойного графа» Флинка?
одининдивидуальный Flink Задача из DAG Граф расчета средней примерно проходит через следующие три отдельных процесса:
StreamGraph Наиболее близок к логическому уровню и топологии вычислений, выраженной кодом, В соответствии с порядком выполнения пользовательского кода отправьте сообщение в StreamExecutionEnvironment. добавить в StreamTransformation Создайте блок-график.
JobGraph от StreamGraph генерировать, Воля может быть слита последовательно и из узлов слиты, Установите границы между узлами и организуйте совместное использование ресурсов. slot Слот и поместите связанный из узла, Загрузите файлы, необходимые для выполнения задачи, Установить контрольную точку Конфигурация. Соответствует графу задачи, обработанному путем частичной инициализации и оптимизации.
ExecutionGraph Зависит от JobGraph Конвертировано из Включить контент, необходимый для конкретного выполнения задачи, да наиболее близок к базовой диаграмме выполнения алгоритмизации.
35 В чем разница между Map и FlatMap?
Существующие Flinkсередина, Map() и FlatMap() используются для верного набора элементов серноданаиз для преобразования операций, их значения и использование в основном такие же, как и в Javaсерединаизмmap() и FlatMap(). Различные изда, существования Flinkсередина, map() и FlatMap() — все это необходимо для завершения интерфейса MapFunction и FlatMapFunction.
Функция map() входной элемент да Воля преобразуется в индивидуальный выходной элемент из функции,То есть каждый индивидуальный входной элемент может быть сопоставлен только с одним индивидуальным выходным элементом. поэтому,map()适用ВВоляодининдивидуальныйданныенаборсерединаизэлемент逐один转换для另одининдивидуальныйданныенаборизэлементиз сцены. Например,Мы можем преобразовать индивидуальную строку ИспользоватьMapFunctionВоля в форму верхнего регистра:
public static final class UpperCaseMapFunction implements MapFunction<String, String> {
@Override
public String map(String value) {
return value.toUpperCase();
}
}
DataStream<String> input = ...;
DataStream<String> output = input.map(new UpperCaseMapFunction());Функция FlatMap() да Воля входные элементы преобразуются в нулевые индивидуальные или несколько индивидуальных выходных элементов из функции,То есть каждый индивидуальный входной элемент может быть сопоставлен с нулевым индивидуальным или мультииндивидуальным выходным элементом. поэтому,flatMap()适用ВВоляодининдивидуальныйданныенаборсерединаизэлемент拆分длямногоиндивидуальныйэлементиз сцены. Например,Мы можем использоватьFlatMapFunctionВоля — индивидуальное разделение строк по пробелам.,И выведите каждое отдельное слово:
DataStream<String> input = ...;
DataStream<String> output = input.flatMap(new FlatMapFunction<String, String>() {
@Override
public void flatMap(String value, Collector<String> out) {
for (String word : value.split(" ")) {
out.collect(word);
}
}
});существует FlatMap()середина, нам нужна Воля за каждое отдельное слово использ Вывод коллектора, поскольку функция FlatMap() может ограничивать отдельные элементы вывода. И Mapсерединаиспользоватьreturn Возвращает обработанный символ, поскольку только долять является индивидуальным элементом.
В итоге,Разница между map() и FlatMap() заключается в том, что они различаются по типу вывода.,因此适用ВНет同из сцены.map()适用ВВоляодининдивидуальныйданныенаборсерединаизэлемент逐один转换для另одининдивидуальныйданныенаборизэлементизсцена,flatMap()适用ВВоляодининдивидуальныйданныенаборсерединаизэлемент拆分длямногоиндивидуальныйэлементиз сцены.
36 Стратегия перезапуска Flink

37 Выходной поток на стороне Flink
38 Пользовательская функция

39 Операция Flink JOIN



Учебное пособие по Jetpack Compose для начинающих, базовые элементы управления и макет

Код js веб-страницы, фон частицы, код спецэффектов

【новый! Суперподробное】Полное руководство по свойствам компонентов Figma.

🎉Обязательно к прочтению новичкам: полное руководство по написанию мини-программ WeChat с использованием программного обеспечения Cursor.

[Забавный проект Docker] VoceChat — еще одно приложение для мгновенного чата (IM)! Может быть встроен в любую веб-страницу!

Как реализовать переход по странице в HTML (html переходит на указанную страницу)

Как решить проблему зависания и низкой скорости при установке зависимостей с помощью npm. Существуют ли доступные источники npm, которые могут решить эту проблему?

Серия From Zero to Fun: Uni-App WeChat Payment Practice WeChat авторизует вход в систему и украшает страницу заказа, создает интерфейс заказа и инициирует запрос заказа

Серия uni-app: uni.navigateЧтобы передать скачок значения

Апплет WeChat настраивает верхнюю панель навигации и адаптируется к различным моделям.

JS-время конвертации

Обеспечьте бесперебойную работу ChromeDriver 125: советы по решению проблемы chromedriver.exe не найдены

Поле комментария, щелчок мышью, специальные эффекты, js-код

Объект массива перемещения объекта JS

Как открыть разрешение на позиционирование апплета WeChat_Как использовать WeChat для определения местонахождения друзей

Я даю вам два набора из 18 простых в использовании фонов холста Power BI, так что вам больше не придется возиться с цветами!

Получить текущее время в js_Как динамически отображать дату и время в js

Вам необходимо изучить сочетания клавиш vsCode для форматирования и организации кода, чтобы вам больше не приходилось настраивать формат вручную.

У ChatGPT большое обновление. Всего за 45 минут пресс-конференция показывает, что OpenAI сделал еще один шаг вперед.

Copilot облачной разработки — упрощение разработки

Микросборка xChatGPT с низким кодом, создание апплета чат-бота с искусственным интеллектом за пять шагов

CUDA Out of Memory: идеальное решение проблемы нехватки памяти CUDA

Анализ кластеризации отдельных ячеек, который должен освоить каждый&MarkerгенетическийВизуализация

vLLM: мощный инструмент для ускорения вывода ИИ

CodeGeeX: мощный инструмент генерации кода искусственного интеллекта, который можно использовать бесплатно в дополнение к второму пилоту.

Машинное обучение Реальный бой LightGBM + настройка параметров случайного поиска: точность 96,67%

Бесшовная интеграция, мгновенный интеллект [1]: платформа больших моделей Dify-LLM, интеграция без кодирования и встраивание в сторонние системы, более 42 тысяч звезд, чтобы стать свидетелями эксклюзивных интеллектуальных решений.

LM Studio для создания локальных больших моделей

Как определить количество слоев и нейронов скрытых слоев нейронной сети?
