Фабрика данных против сетки данных
концепция
недавно,В сфере управления данными тоже много горячих слов.,Пришедшие из-за границы изпереплетение данных (Data Fabric) и искладка данных (Data Mesh) — это две новые темы, которые часто упоминаются. Чтобы идти в ногу с темпами развития новых технологий,,Я также провел небольшое исследование этих двух концепций.,и Давайте обсудим вместе.
GartnerДаватьпереплетение данных(Data Fabric) определяется следующим образом: Data Fabric is a design concept that serves as an integrated layer of data and connecting processes. переплетение данныхэто дизайнконцепция,выражатьданныеипроцесс подключенияиз Уровень интеграции。
ForresterДаватьвнесетка данных (Data Mesh) определяется следующим образом: Data Mesh is a decentralized sociotechnical approach to share, access and manage analytical data in complex and large-scale environments within or across organizations. сетка данныхэто своего рода дисперсияизсоциотехнический подход,Используется в различных сложных и крупномасштабных средах внутри или между организациями.,Совместное использование, доступ и анализ данных управления.
переплетение данных
Forrester аналитик Noel Yuhanna является самым ранним в 200 Год среднего поколения определение переплетение Один из данныхиз людей. Из концепции, большое переплетение данные по сути являются мета-данными Машинный способ объединить различные наборы инструментов, которые решают ключевые проблемы в крупных проектах обработки данных единым способом с самообслуживанием. В частности, данные Fabric Решения предоставляют возможности в таких областях, как доступ к данным, обнаружение, преобразование, интеграция, безопасность, управление, происхождение и оркестровка. Graph Также часто используется для связи активов данных и пользователей.
Momentum Строительное переплетение Концепция данных, как способ упростить доступ к данным и управление ими во все более разнообразной среде, включает в себя хранилище данных транзакций и операций, хранилище данных, озеро данных и дом у озера. Организации создают больше разрозненных структур, а не меньше, и по мере развития облачных вычислений проблемы, связанные с многообразием, становятся более серьезными, чем когда-либо.
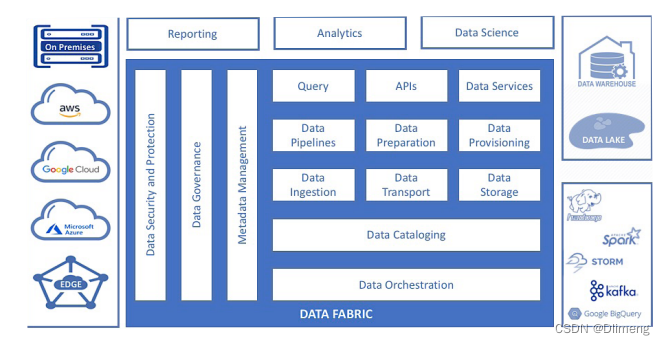
A data fabric consists of multiple data management layers (Image source: Eckerson Group)
С помощью единого переплетения, практически наложенного на различные хранилища данных. данных,Организации могут обеспечить своего рода единое управление для различных изданных источников и последующих потребителей (включающие администраторы, инженеры по данным, специалисты по аналитике данных). Но следует отметить, что из,Управление – это единство из,Вместо фактического из хранилища,Он до сих пор распространяется.
включать Informatica и Talend Некоторые поставщики инструментов предлагают полезные переплетения, которые содержат многие из вышеперечисленных функций. данные, в то время как другие поставщики инструментов, такие как Ataccama и Denodo) обеспечивает специфическое изпереплетение данныхчасть。 Google Cloud также через свой новый Dataplex Поддержка продуктапереплетение данныхметод。переплетение Интеграция между различными компонентами данных обычно осуществляется посредством API универсальная JSON Формат данных обрабатывается.
сетка данных
Хотясетка данные предназначены для решения многих проблем, связанных с данными. данных — это та же проблема, то есть сложность управления данными в гетерогенной среде данных, но она решает проблему совершенно другим способом. Короче говоря, хоть и переплетение данных пытались построить единый уровень виртуального управления поверх распределенных данных, но сетка Данные поощряют распределенные группы команд управлять данными по своему усмотрению, хотя существуют некоторые положения о совместном управлении.
сетка данныхконцепцияпервоначально автором Zhamak Dehghani Написано, что он сейчас Thoughtworks North America Директор инкубатора технологий следующего поколения. Dehghani в ней 2019 Год 5 Ежемесячный отчет «Как выйти за рамки монолитного озера данных к распределенной сетке» данных”разработано всетка данныеизм, многие принципы иконцепции, она впоследствии 2020 Год 12 Месячная публикация под названием «сетка принцип данных и логическая структура» и «отчет».
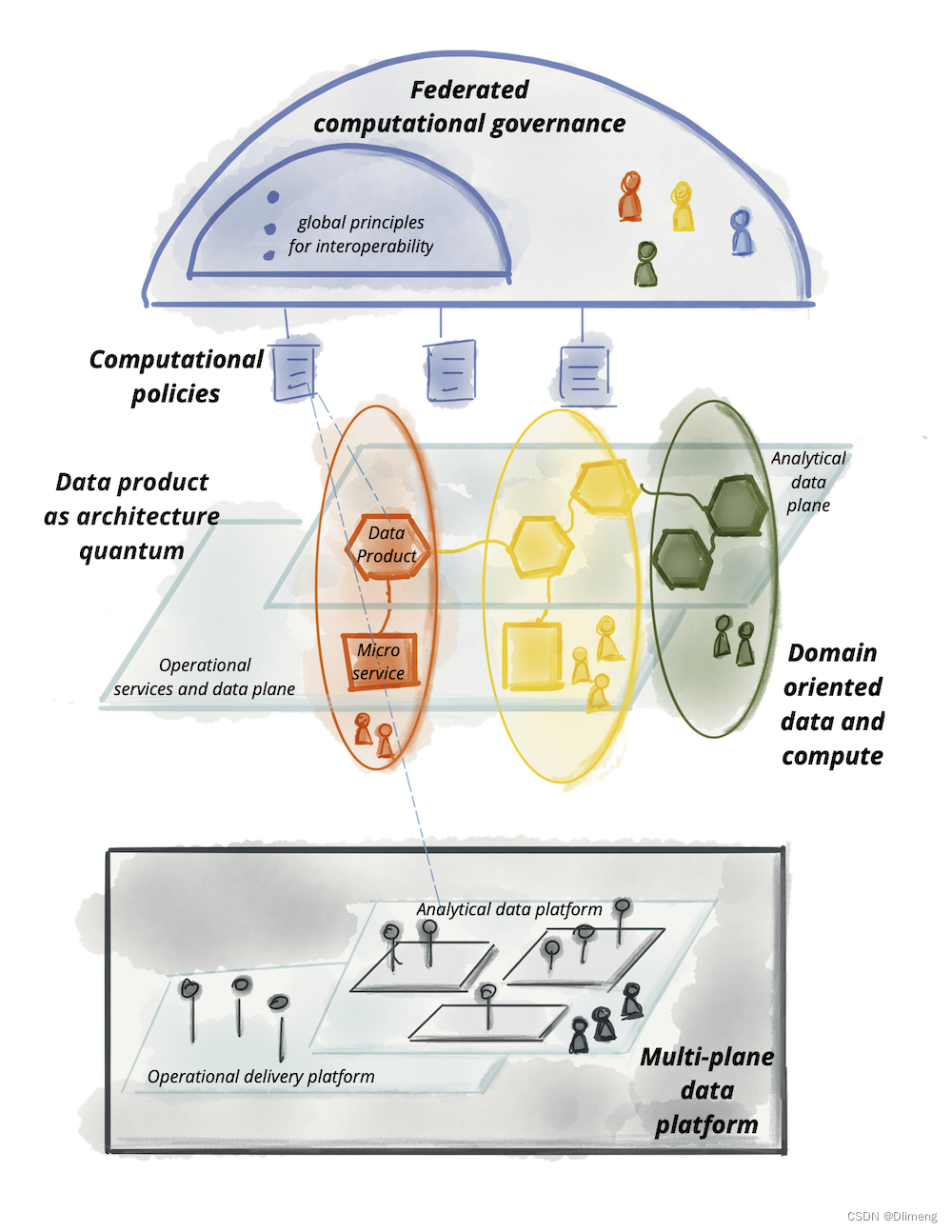
Как мы уже писали сегодня, водить машинусетка Основной принцип данных состоит в исправлении несоответствий озера данных и данных между хранилищами. Хранилище данных первого поколения было разработано для хранения больших объемов структурированных данных, что позволяет аналитикам использовать их для обратного отслеживания. SQL аналитика, в то время как озера данных второго поколения в основном используются для хранения больших объемов неструктурированных моделей данных, которые специалисты по данным используют для построения прогнозного машинного обучения. Dehghani Написал систему третьего поколения с потоковой передачей в реальном времени и облачными сервисами. (Каппа), но не устраняет потенциальный разрыв в удобстве использования между системами первого и второго поколения.
Многие организации строяти Комплекс в обслуживаниииз ETL Конвейер данных, позволяющий синхронизировать данные. Это также вызывает потребность в «сверхспециализированных инженерах по обработке данных», которым поручено поддерживать византийские системы.
Dehghani Ключевой вывод, связанный с этим вопросом, заключается в том, что преобразование данных не может быть жестко встроено в данные инженерами, а должно представлять собой фильтр, применяемый к общему набору данных, доступному всем пользователям. Поэтому вместо создания сложного набора ETL Конвейер для перемещения данных в различные сообщества мог бы анализировать данные из специальных репозиториев, а не оставлять данные примерно в их исходной форме, и ряд групп, специализирующихся на конкретных областях, будут владеть этими данными по мере того, как они преобразуют данные в продукт. Dehghani израспределеннаясетка данных решает эту проблему посредством новой архитектуры с четырьмя основными функциями:
- Доменно-ориентированный с децентрализованным владением данными и архитектурой;
- данные как продукт;
- В качестве платформы инфраструктуры данных самообслуживания;
- Федеративное управление вычислениями.
Собственно, сетка Подход к данным признает, что только Data Lake обладает масштабируемостью для удовлетворения сегодняшних потребностей аналитики, но попытки организаций навязать нисходящий стиль управления Data Lake потерпели неудачу. сетка данных Пытаюсь использовать снизу вверхиз Способы переосмысления структур собственности,Предоставьте каждой команде возможность построить систему, отвечающую их собственным потребностям.,Хотя требуется некоторое межкомандное управление.
Сетка против переплетения
Как мы видим,Между методами сетки данныхипереплетения данных есть сходство. но,Есть и некоторые различия, которые следует учитывать.
в соответствии с Forrester из Yuhanna из заявления,сетка данныхипереплетение Основное различие между методами обработки данных заключается в том, что API изAccess метод.
"и [данные] косадругой,сетка данные в основном предназначены для разработчиков из API водить машину [Решение]», Юханна объяснять. “[Data Fabric] исетка данных Вместо этого вы делаете API Напишите код для интерфейса. С другой стороны, переплетение данные являются low-code, без кода, что означает API Интеграция происходит внутри структуры, а не с ее непосредственным использованием, а не сеткой. данных。”
James Serra Это Эрнст энд Янг (Earnst and Young) изданные Менеджер по архитектуре платформы,Ранее работал архитектором складских решений в Microsoft изданныеиданные.,Разница между этими двумя методами заключается в том, где пользователь получает к ним доступ.
“переплетение данныхисетка оба данных обеспечивают доступ к архитектуре данных на нескольких технологиях и платформах, но переплетение данные ориентированы на технологии, а сетка данных ориентированы на организационные изменения», — сказал Серра в 6 Юэ из написал в своем блоге. “[A] сетка данные больше связаны с людьми и процессами, чем с архитектурой, а переплетение Данные — это архитектурный подход, который обрабатывает метасложность данных таким образом, чтобы они хорошо работали вместе и разумно. "
в соответствии с Eckerson Group аналитик David Wells скажем, вы можете использовать обе сетки данныхипереплетение данных,Даже хаб данных
"первый,Это концепция,а не вещи,”Wells В недавнем сообщении в блоге «Архитектура: комплекс ) и Complex (Сложный.)» — написал. «Быть архитектурным концептуально-изданным хабом — это не то же самое, что быть библиотекой данных и зданными хабами. Во-вторых, они являются компонентами, а не заменителями. Архитектура содержит в себе и переплетение. данныхисетка данные практичны из. Они не являются взаимоисключающими. В конце концов, это архитектурные рамки, а не архитектуры. в рамке соответствии Ваши потребности, процессы и терминология корректируются и настраиваются до того, как у вас появится архитектура. "
сетка данныхипереплетение данных — все они имеют место в большом списке данных. При поиске архитектуры для поддержки вашего крупного проекта все сводится к поиску подхода, который лучше всего соответствует вашим конкретным потребностям.
ссылка https://www.datanami.com/2021/10/25/data-mesh-vs-data-fabric-understanding-the-differences/



Углубленный анализ переполнения памяти CUDA: OutOfMemoryError: CUDA не хватает памяти. Попыталась выделить 3,21 Ги Б (GPU 0; всего 8,00 Ги Б).

[Решено] ошибка установки conda. Среда решения: не удалось выполнить первоначальное зависание. Повторная попытка с помощью файла (графическое руководство).

Прочитайте нейросетевую модель Трансформера в одной статье

.ART Теплые зимние предложения уже открыты

Сравнительная таблица описания кодов ошибок Amap

Уведомление о последних правилах Points Mall в декабре 2022 года.

Даже новички могут быстро приступить к работе с легким сервером приложений.

Взгляд на RSAC 2024|Защита конфиденциальности в эпоху больших моделей

Вы используете ИИ каждый день и до сих пор не знаете, как ИИ дает обратную связь? Одна статья для понимания реализации в коде Python общих функций потерь генеративных моделей + анализ принципов расчета.

Используйте (внутренний) почтовый ящик для образовательных учреждений, чтобы использовать Microsoft Family Bucket (1T дискового пространства на одном диске и версию Office 365 для образовательных учреждений)

Руководство по началу работы с оперативным проектом (7) Практическое сочетание оперативного письма — оперативного письма на основе интеллектуальной системы вопросов и ответов службы поддержки клиентов

[docker] Версия сервера «Чтение 3» — создайте свою собственную программу чтения веб-текста

Обзор Cloud-init и этапы создания в рамках PVE

Корпоративные пользователи используют пакет регистрационных ресурсов для регистрации ICP для веб-сайта и активации оплаты WeChat H5 (с кодом платежного узла версии API V3)

Подробное объяснение таких показателей производительности с высоким уровнем параллелизма, как QPS, TPS, RT и пропускная способность.

Удачи в конкурсе Python Essay Challenge, станьте первым, кто испытает новую функцию сообщества [Запускать блоки кода онлайн] и выиграйте множество изысканных подарков!

[Техническая посадка травы] Кровавая рвота и отделка позволяют вам необычным образом ощипывать гусиные перья! Не распространяйте информацию! ! !

[Официальное ограниченное по времени мероприятие] Сейчас ноябрь, напишите и получите приз

Прочтите это в одной статье: Учебник для няни по созданию сервера Huanshou Parlu на базе CVM-сервера.

Cloud Native | Что такое CRD (настраиваемые определения ресурсов) в K8s?

Как использовать Cloudflare CDN для настройки узла (CF самостоятельно выбирает IP) Гонконг, Китай/Азия узел/сводка и рекомендации внутреннего высокоскоростного IP-сегмента

Дополнительные правила вознаграждения амбассадоров акции в марте 2023 г.

Можно ли открыть частный сервер Phantom Beast Palu одним щелчком мыши? Супер простой урок для начинающих! (Прилагается метод обновления сервера)

[Играйте с Phantom Beast Palu] Обновите игровой сервер Phantom Beast Pallu одним щелчком мыши

Maotouhu делится: последний доступный внутри страны адрес склада исходного образа Docker 2024 года (обновлено 1 декабря)

Кодирование Base64 в MultipartFile

5 точек расширения SpringBoot, супер практично!

Глубокое понимание сопоставления индексов Elasticsearch.

15 рекомендуемых платформ разработки с нулевым кодом корпоративного уровня. Всегда найдется та, которая вам понравится.
