Этот вычислительный кластер, выпущенный Goose Factory, может обучать большие модели с триллионами параметров за самые быстрые 4 дня.

Для успеха больших моделей ключевое значение имеет вычислительная мощность.
Вот параметры производительности нового поколения высокопроизводительных вычислительных кластеров HCC, выпущенных Tencent Cloud для сценариев обучения больших моделей:
«Показатели вычислительной мощности улучшены в три раза по сравнению с предыдущим поколением, а пропускная способность доступа к серверу увеличена с 1,6 Т до 3,2 Т».
В этом поколении высокопроизводительного кластера HCC используется последнее поколение серверов Tencent Cloud Xinghai собственной разработки и оснащено графическим процессором NVIDIA H800 Tensor Core. Одна карта графического процессора поддерживает вычислительную мощность до 1979 терафлопс.
В чем заключается конкретная сила?
последний октябрь,Tencent финиширует первойиндивидуальныйтриллионы параметровAIбольшой Модель——Обучение крупных моделей Hunyuan НЛП。В том же наборе данных,Сократите время обучения с 50 до 11 дней. Если на базе кластера нового поколения,Время обучения будет сокращено до 4 дней.
01
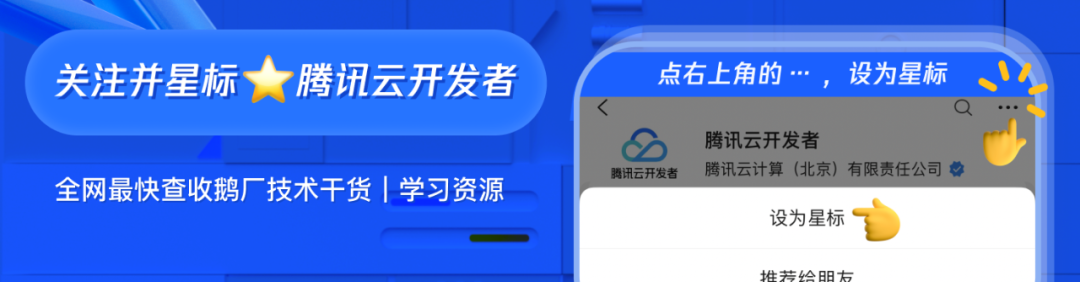
Просто складывая карты друг в друга, вычислительная мощность не может увеличиваться линейно.
Популярность моделей продолжает расти, но для обучения успешной большой модели необходимы вычислительные мощности, алгоритмы и данные.
Чем мощнее большая модель, тем больше вычислительной мощности потребуется для завершения обучения. Наличие мощной вычислительной мощности является ключом к успеху крупных моделей ИИ.
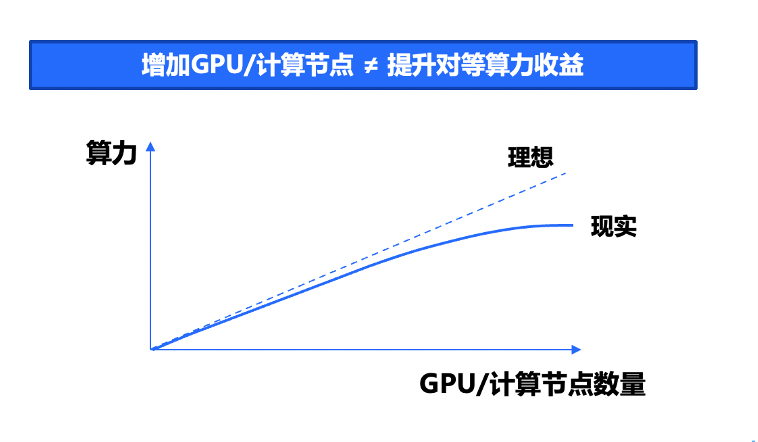
Когда один сервер имеет ограниченную вычислительную мощность, необходимо подключить тысячи серверов для создания крупномасштабного распределенного высокопроизводительного вычислительного кластера. Большие модели, являющиеся отраслевыми эталонами, обычно требуют очень высокой вычислительной мощности для обучения с использованием тысяч графических карт.
При таком огромном масштабе параметров одна вычислительная карта с графическим процессором не может выполнить даже самую базовую нагрузку. Это также требует от нас использования сети для соединения тысяч серверов для формирования крупномасштабного вычислительного кластера, обеспечивающего необходимую вычислительную мощность для больших моделей. .
Кластер высокопроизводительных вычислений HCC родился под таким спросом. Однако для последовательного «соединения» такого количества карт требуются мощные технические возможности.
Потому что, согласно эффекту бочки, простое штабелирование карт не может привести к линейному увеличению вычислительной мощности. Для этого требуется комплексная координация вычислений, хранения, сети и структуры верхнего уровня для создания высокопроизводительной платформы интеллектуальных вычислений с высокой пропускной способностью и малой задержкой.
02
За самой мощной вычислительной мощностью стоит прорыв в базовой технологии собственной разработки.
Чтобы обеспечить максимальную вычислительную мощность, высокопроизводительный кластер Tencent Cloud HCC внедрил различные технологические инновации — от базовой инфраструктуры до структуры обучения верхнего уровня.
2.1 Вычисления: ведущая в отрасли сверхвысокая плотность повышает производительность одноточечных вычислений до более высокого уровня.
Автономная производительность сервера является основой вычислительной мощности кластера. В случае неразреженных спецификаций кластерная карта нового поколения с одним графическим процессором поддерживает вычислительную мощность до 495 терафлопс (TF32), 989 терафлопс (FP16/BF16) и 1979 терафлопс (FP8).
Для сценариев обучения больших моделей сервер Tencent Cloud Xinghai использует конструкцию высотой 6U со сверхвысокой плотностью, что на 30% выше, чем поддерживаемая промышленностью плотность полок;
Используя концепцию параллельных вычислений и интеграцию конструкции узлов ЦП и ГП, производительность одноточечных вычислений повышается до более высокого уровня;
Комплексное обновление до расширенного процессора Intel Xeon четвертого поколения, пропускная способность сервера PCIe и пропускная способность памяти увеличены до 100%.
2.2 Сеть: высокопроизводительная вычислительная сеть Xingmai собственной разработки увеличивает вычислительную мощность кластера еще на 20%.
Мы знаем, что чем больше количество параметров модели, тем выше требования к пропускной способности. Тысячи графических карт работают вместе неделями или даже дольше, и существуют огромные требования к внутреннему обмену данными между графическими процессорами, а также между серверами и серверными узлами.
Традиционное обучение моделей малого и среднего размера часто требует участия лишь небольшого количества серверов графических процессоров. Требования к межсерверной связи относительно невелики, и можно использовать общую полосу пропускания 100 Гбит/с. Обучение больших моделей с триллионами параметров представляет собой вычислительную услугу, чувствительную к пропускной способности, которая часто представляет собой режим связи «все со всеми».
В сценарии с большой моделью, по сравнению с единичным сбоем графического процессора, который затрагивает лишь несколько тысячных вычислительной мощности кластера, неравномерная нагрузка на один канал приводит к перегрузке сети, что становится недостатком и влияет на соединения десятков или даже более графических процессоров. .
В то же время кластерное обучение также приведет к дополнительным издержкам связи, в результате чего вычислительная мощность N графических процессоров будет менее чем в N раз превышать вычислительную мощность одного графического процессора. Промышленная библиотека коллективной связи графических процессоров с открытым исходным кодом (например, NCCL) не может максимизировать производительность связи в сети.
Если последнее поколение графических процессоров в отрасли — это спортивный автомобиль, то нам нужен профессиональный трек, чтобы максимизировать потенциал большого кластера обучения модели, состоящего из N графических процессоров.
Высокопроизводительная вычислительная сеть Xingmai, разработанная Tencent, является профессиональным направлением. Этот трек глубоко настраивает сеть кластера графических процессоров. Пропускная способность сетевого узла увеличена, что обеспечивает высокопроизводительную сеть 3.2T ETH RDMA для вычислительных узлов, что значительно снижает долю затрат времени на связь.
Это эквивалентно использованию той же карты графического процессора, использующей сверхширокополосную сеть для повышения вычислительной мощности кластера до более высокого уровня. Фактические результаты измерений показывают, что новейшая сеть Xingmai 3,2T, оснащенная тем же графическим процессором, увеличивает общую вычислительную мощность кластера на 20% по сравнению с сетью 1,6T.
На этой трассе также были оптимизированы «правила дорожного движения». В крупномасштабных обучающих кластерах связь между графическими процессорами фактически осуществляется с помощью различных форм сетей, включая межорганические сети и внутриорганические сети.
Традиционные коммуникационные решения включают в себя большой объем межмашинного сетевого взаимодействия, что приводит к большим затратам на связь между кластерами. Высокопроизводительная вычислительная сеть Xingmai использует обе сети одновременно, объединяя небольшие потоки в большие потоки и уменьшая количество потоков для повышения производительности передачи всей сети. Фактические измерения показывают, что в крупномасштабных сценариях «всем всем» высокопроизводительная вычислительная сеть Синмай может помочь улучшить производительность передачи данных на 30%.
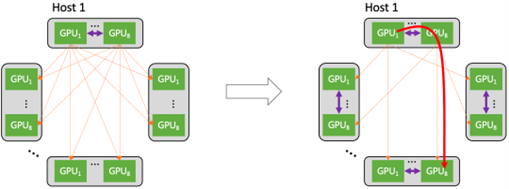
Основанный на неблокирующей сетевой архитектуре многоканальной агрегации, активном контроле перегрузки и настраиваемой библиотеке ускорения связи, кластер нового поколения в настоящее время может предоставлять лучшие в отрасли возможности построения кластеров и поддерживать масштаб сети до 100 000 карт для одного кластера. .
Высокопроизводительная библиотека коллективной связи TCCL, разработанная Tencent, основана на глубокой оптимизации сетевой аппаратной платформы Xingmai и включает в себя специально разработанные решения для глобального планирования маршрутов, планирования сходства с учетом топологии, а также сигнализации и самовосстановления в реальном времени. сетевых неисправностей. По сравнению с отраслевой библиотекой коллективного общения с открытым исходным кодом она оптимизирует производительность нагрузки на 40 % для обучения больших моделей и устраняет проблемы с прерыванием обучения, вызванные многочисленными сетевыми причинами.
В сценариях с чрезвычайно большими кластерами он по-прежнему может поддерживать превосходный коэффициент накладных расходов на связь и производительность пропускной способности, отвечая горизонтальному расширению бизнеса по обучению больших моделей и выводам.
2.3 Хранилище: пропускная способность на уровне ТБ и десятки миллионов операций ввода-вывода в секунду, сокращающие время ожидания вычислительных узлов.
За последние пять лет количество параметров модели выросло в 100 000 раз, тогда как память графического процессора увеличилась всего в 4 раза. Теоретически объединение ресурсов в облаке может решить эту проблему.
Однако в сценарии обучения тысячи вычислительных узлов будут одновременно считывать пакет наборов данных, а сегмент хранения также сталкивается с проблемами высокого параллелизма. Наборы данных больших моделей в основном представляют собой большие файлы размером в ГБ. От загрузки модели до запуска требуется несколько минут. Если ресурсы графического процессора простаивают, это также снижает общую эффективность обучения.
Если говорить о сети в большой модели вычислительной мощности, то она построена на профессиональном уровне для графических процессоров. Высокопроизводительное хранилище — это ремонтная станция, способная «сменить шины за секунды». Она заранее подготавливает данные, минимизирует ожидание вычислительных узлов и приближает производительность кластера к оптимальной.
Кластер нового поколения представляет новейшую архитектуру хранения данных собственной разработки Tencent Cloud с пропускной способностью на уровне ТБ и десятками миллионов операций ввода-вывода в секунду, обеспечивая потребности в хранении данных в различных сценариях.
Решение COS+GooseFS обеспечивает ускорение многоуровневого кэша на основе объектного хранилища, значительно повышает производительность сквозного чтения данных и обеспечивает масштабное, чрезвычайно быстрое и экономичное решение для хранения данных для сценариев с большими моделями, которые оно будет публиковать; наборы данных, данные обучения и результаты моделей. Унифицированное хранилище в объектное хранилище COS для достижения унифицированного хранения и эффективной передачи данных. GooseFS кэширует горячие данные в память графического процессора и на локальный диск по требованию, обеспечивая возможности локализованного доступа с малой задержкой для обучения больших моделей, ускоряя процесс обучения и повышая эффективность обучения.
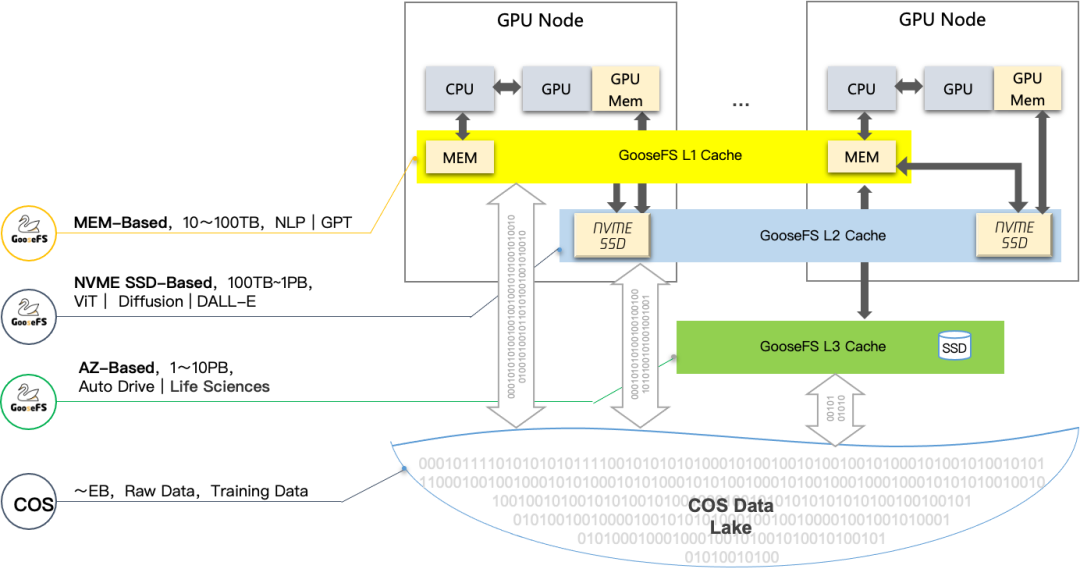
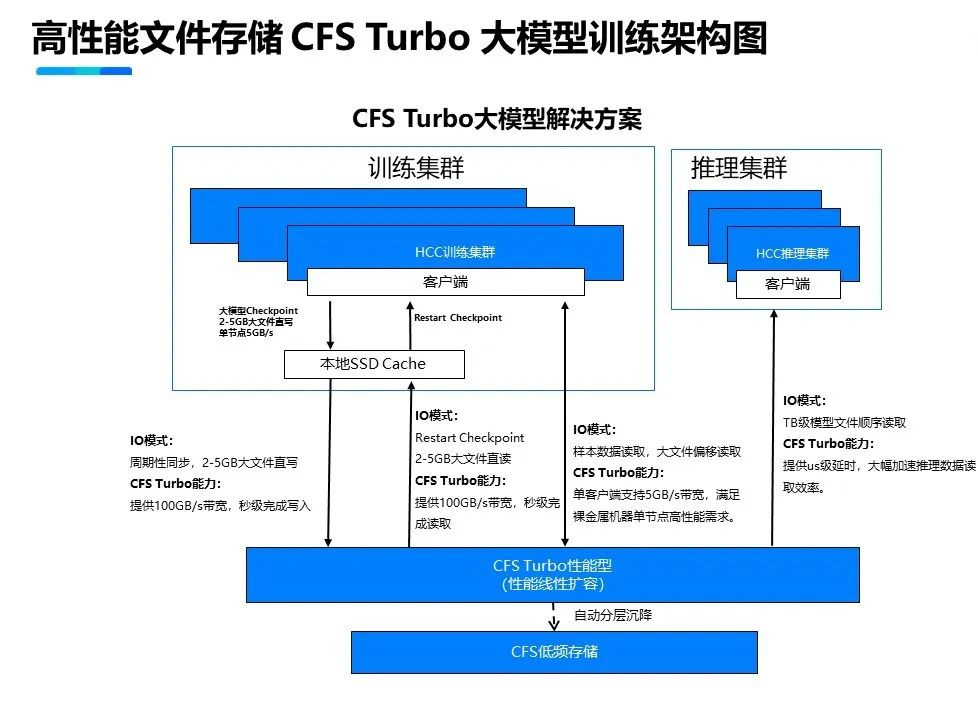
Высокопроизводительное параллельное хранилище файлов CFS Turbo использует решение для многоуровневого ускорения кэша. Основанный на полностью распределенной архитектуре, он обеспечивает максимальную производительность: пропускную способность 100 ГБ/с и 10 миллионов операций ввода-вывода в секунду. А благодаря технологии постоянного клиентского кэширования локальный твердотельный накопитель NVMe и файловая система Turbo голого сервера образуют единое пространство имен для достижения задержки на уровне микросекунд и удовлетворения требований большого объема данных, высокой пропускной способности и низкой задержки в сценариях с большими моделями. В то же время благодаря интеллектуальной технологии многоуровневого хранения «горячие» и «холодные» данные автоматически распределяются по уровням, что экономит 80 % затрат на хранение и обеспечивает максимальную экономическую эффективность.
Помимо базовой архитектуры, для сценариев обучения больших моделей кластер нового поколения интегрирует самостоятельно разработанный Tencent Cloud механизм ускорения обучения TACO Train, который выполняет большое количество оптимизаций на системном уровне для сетевых протоколов, коммуникационных стратегий, инфраструктур искусственного интеллекта и составление модели, существенно экономя корректировки обучения. Оптимизировать и рассчитать стоимость.
AngelPTM, система обучения, лежащая в основе большой модели Tencent Hunyuan, также предоставляет внешние услуги через Tencent Cloud, чтобы помочь предприятиям ускорить внедрение крупных моделей. В Tencent Cloud предприятия могут использовать возможности крупных моделей и набор инструментов платформы TI для проведения точного обучения на основе данных промышленных сценариев, повышения эффективности производства, а также быстрого создания и развертывания приложений искусственного интеллекта.
03
Многоуровневый доступ упрощает получение вычислительной мощности
Поскольку размер большой модели требует очень большого количества узлов в одном кластере, начинающие компании обычно сталкиваются с проблемой: насколько большим должен быть один узел кластера, чтобы адаптироваться к масштабу вычислительной мощности ИИ?
Столкнувшись с этим спросом на уровне вычислительной мощности, Tencent Cloud предлагает подходящие решения и продукты для сценариев обучения, вывода, тестирования и оптимизации.
в,Высокопроизводительный вычислительный кластер нового поколения HCC,Для крупномасштабного обучения ИИ. Предоставление услуг извне в выделенном кластере,Тенсент ОблакоОблачный сервер «голого металла»как узел,Полностью оснащен графическим процессором последнего поколения.,В сочетании с собственной архитектурой хранения узлы соединяются между собой посредством собственной разработки Xingmai RDMAсеть.,Обеспечьте интегрированные высокопроизводительные вычисления с высокой производительностью, высокой пропускной способностью и низкой задержкой для крупных сервисов обучения.
Впоследствии, чтобы удовлетворить высокие вычислительные потребности клиентов в таких сценариях, как обучение автономному вождению, обработка естественного языка, обучение большим моделям AIGC и вычисления для научных исследований, возможности многоформового и многоуровневого доступа Tencent Cloud, такие как «голое железо», облачные серверы, контейнеры и облачные функции будут использоваться для удовлетворения высоких вычислительных потребностей клиентов. Могут быть получены быстро.
Более крупные модели приближаются к границам вычислительной мощности. Tencent Cloud, отмеченная новым поколением кластеров, создает высокопроизводительную интеллектуальную вычислительную сеть для AIGC путем интеграции программного и аппаратного обеспечения на основе чипов собственной разработки, серверов собственной разработки Xingxinghai и распределенных облачных операционных систем и продолжает ускоряться. развитие всего общества. Инновации в облаке.




Следуйте и отмечайте меня
Чтобы подать заявку на внутреннее тестирование, ответьте «вычислительная мощность».



Учебное пособие по Jetpack Compose для начинающих, базовые элементы управления и макет

Код js веб-страницы, фон частицы, код спецэффектов

【новый! Суперподробное】Полное руководство по свойствам компонентов Figma.

🎉Обязательно к прочтению новичкам: полное руководство по написанию мини-программ WeChat с использованием программного обеспечения Cursor.

[Забавный проект Docker] VoceChat — еще одно приложение для мгновенного чата (IM)! Может быть встроен в любую веб-страницу!

Как реализовать переход по странице в HTML (html переходит на указанную страницу)

Как решить проблему зависания и низкой скорости при установке зависимостей с помощью npm. Существуют ли доступные источники npm, которые могут решить эту проблему?

Серия From Zero to Fun: Uni-App WeChat Payment Practice WeChat авторизует вход в систему и украшает страницу заказа, создает интерфейс заказа и инициирует запрос заказа

Серия uni-app: uni.navigateЧтобы передать скачок значения

Апплет WeChat настраивает верхнюю панель навигации и адаптируется к различным моделям.

JS-время конвертации

Обеспечьте бесперебойную работу ChromeDriver 125: советы по решению проблемы chromedriver.exe не найдены

Поле комментария, щелчок мышью, специальные эффекты, js-код

Объект массива перемещения объекта JS

Как открыть разрешение на позиционирование апплета WeChat_Как использовать WeChat для определения местонахождения друзей

Я даю вам два набора из 18 простых в использовании фонов холста Power BI, так что вам больше не придется возиться с цветами!

Получить текущее время в js_Как динамически отображать дату и время в js

Вам необходимо изучить сочетания клавиш vsCode для форматирования и организации кода, чтобы вам больше не приходилось настраивать формат вручную.

У ChatGPT большое обновление. Всего за 45 минут пресс-конференция показывает, что OpenAI сделал еще один шаг вперед.

Copilot облачной разработки — упрощение разработки

Микросборка xChatGPT с низким кодом, создание апплета чат-бота с искусственным интеллектом за пять шагов

CUDA Out of Memory: идеальное решение проблемы нехватки памяти CUDA

Анализ кластеризации отдельных ячеек, который должен освоить каждый&MarkerгенетическийВизуализация

vLLM: мощный инструмент для ускорения вывода ИИ

CodeGeeX: мощный инструмент генерации кода искусственного интеллекта, который можно использовать бесплатно в дополнение к второму пилоту.

Машинное обучение Реальный бой LightGBM + настройка параметров случайного поиска: точность 96,67%

Бесшовная интеграция, мгновенный интеллект [1]: платформа больших моделей Dify-LLM, интеграция без кодирования и встраивание в сторонние системы, более 42 тысяч звезд, чтобы стать свидетелями эксклюзивных интеллектуальных решений.

LM Studio для создания локальных больших моделей

Как определить количество слоев и нейронов скрытых слоев нейронной сети?
