Есть ли способ добиться 100% точности статистики мощности Elasticsearch при больших объемах данных?
Вопрос от гольфистов: Есть ли способ добиться 100% точности статистики мощности Elasticsearch при больших объемах данных?

https://t.zsxq.com/VYDcW
В Elasticsearch для статистики мощности (например, агрегации мощности) обычно используется алгоритм HyperLogLog++ при больших объемах данных. Этот алгоритм является приблизительным, поэтому будет определенная ошибка.
1. Создайте 1 миллион фрагментов данных.
Я случайным образом создал 1 миллион записей и записал их в Elasticsearch для тестирования.
Давайте сначала поговорим о логике построения кода:
Код случайной генерации генерирует большое количество случайных китайских данных и пакетно импортирует их в индекс Elasticsearch. Документы, содержащие случайные китайские слова и случайные целые числа, создаются посредством цикла. Каждая партия из 2000 документов генерируется и импортируется пакетами с использованием массового API Elasticsearch для повышения эффективности импорта до тех пор, пока не будет импортировано все указанное количество документов.
Результат после импорта Elasticsearch показан на рисунке ниже.
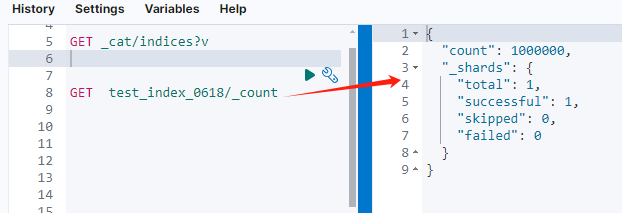
Пример данных показан на рисунке ниже.

Чтобы облегчить получение фактических статистических результатов, я использовал прокрутку для экспорта текста, написанного в Elasticsearch, в файл out_title.txt.

Конечный результат после использования следующего сценария для удаления дубликатов: 632483 элемента.

Если вам нужна 100% точность в Elasticsearch, вы можете рассмотреть следующие решения.
Сначала проведите проверку, а потом сделайте вывод.
1. Вариант 1. Использовать относительно «точное» базовое агрегирование по кардинальности.
Структура отображения построенного индекса test_index_0618 выглядит следующим образом:
{
"test_index_0618": {
"mappings": {
"properties": {
"id": {
"type": "integer"
},
"title": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword"
}
},
"analyzer": "ik_max_word"
}
}
}
}
}
В Elasticsearch введен параметр агрегирования мощности Precision_threshold, начиная с версии 7.10. Если установлено более высокое значение, он может предоставить более точную статистику мощности.
https://www.elastic.co/guide/en/elasticsearch/reference/current/search-aggregations-metrics-cardinality-aggregation.html
Метод конфигурации:
POST test_index_0618/_search
{
"aggs": {
"unique_count": {
"cardinality": {
"field": "title.keyword",
"precision_threshold": 40000
}
}
}
}
precision_threshold Варианты:ElasticsearchизcardinalityАгрегирование,Используется для балансировки потребления памяти и точности подсчета.
Установка этого значения контролирует количество уникальных значений, ниже которых счетчик будет очень точным, а выше которого счетчик может быть немного неправильным.
максимальная поддержкаиз Значение40000,Выше этого значения Воля не имеет дополнительного эффекта.,По умолчанию,Этот порог установлен на3000。
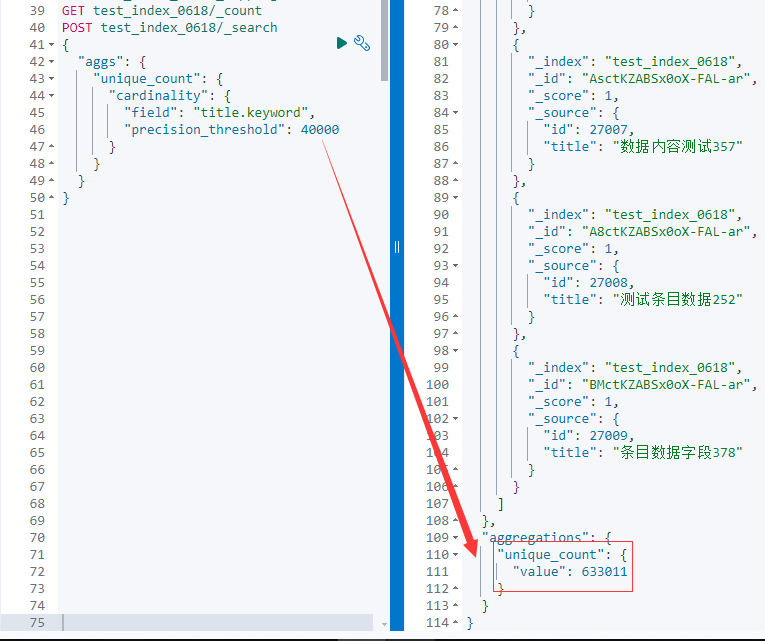
Но по сравнению с реальным результатом дедупликации: 632483 элементов, будет отклонение близкое к 633011-632483 = на 528 больше.
2. Вариант 2. Используйте агрегацию терминов в сочетании со статистикой кардинальности.
Следующий запрос получает первые 10 000 уникальных значений поля title.keyword посредством агрегации терминов и использует агрегацию по кардинальности для расчета общего количества уникальных значений в поле.
Практический метод:
{
"size": 0,
"aggs": {
"unique_values": {
"terms": {
"field": "title.keyword",
"size": 10000
}
},
"unique_count": {
"cardinality": {
"field": "title.keyword"
}
}
}
}
Установите размер агрегации терминов на достаточно большой размер, чтобы охватить все возможные уникальные значения.
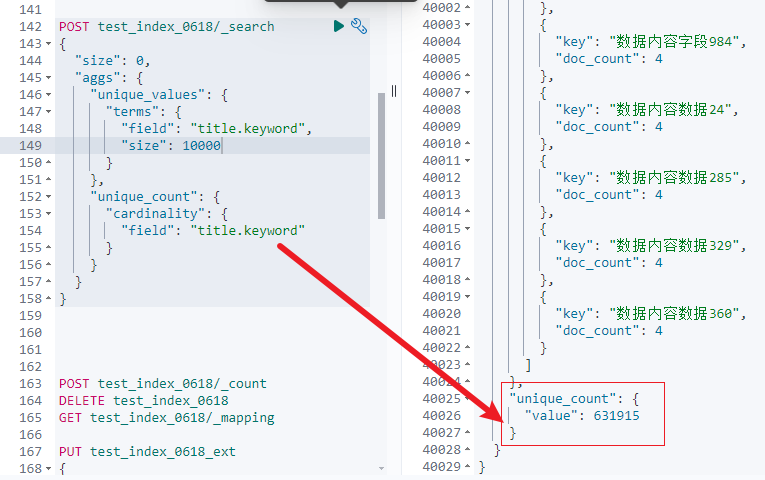
Значение результата по-прежнему не является точным, будет отклонение 632483-631915= 568.
Однако значение сегмента достаточно велико, но не очень велико, иначе будет сообщено об ошибке, поскольку значение по умолчанию — 65536. Боковая проверка: если значение результата агрегации превышает 65536, оно будет неточным.
{
"error": {
"root_cause": [],
"type": "search_phase_execution_exception",
"reason": "",
"phase": "fetch",
"grouped": true,
"failed_shards": [],
"caused_by": {
"type": "too_many_buckets_exception",
"reason": "Trying to create too many buckets. Must be less than or equal to: [65536] but this number of buckets was exceeded. This limit can be set by changing the [search.max_buckets] cluster level setting.",
"max_buckets": 65536
}
},
"status": 400
}
Получите значение search.max_buckets:
GET /_cluster/settings?include_defaults=true&filter_path=defaults.search.max_buckets
Мы корректируем search.max_buckets в соответствии с объемом данных:
PUT /_cluster/settings
{
"persistent": {
"search.max_buckets": 1000000
}
}
Выполнение сообщит об ошибке:
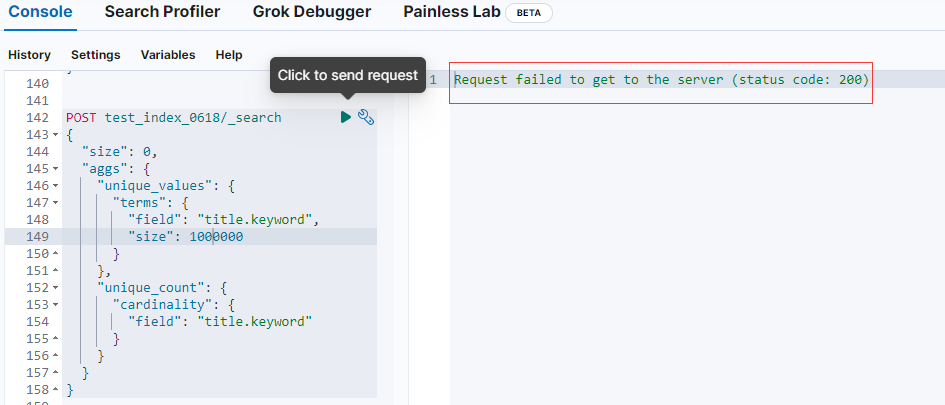
Я предполагаю, что объем данных слишком велик для обработки!
После того, как я изменил размер сегмента на 700000, его можно выполнить, но результат по-прежнему не является точным значением.
POST test_index_0618/_search
{
"size": 0,
"aggs": {
"unique_values": {
"terms": {
"field": "title.keyword",
"size": 700000
}
},
"unique_count": {
"cardinality": {
"field": "title.keyword"
}
}
}
}
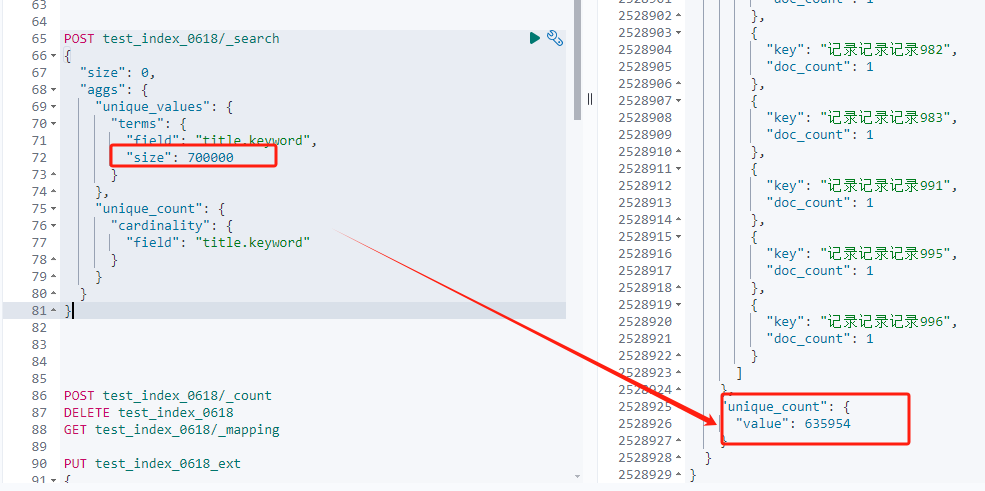
Результат по-прежнему отличается от реального значения результата, которое составляет 635954-632483=3471.
3. Решение 3. Статистика разделов и сводка
Если объем данных очень велик, вы можете рассмотреть возможность сегментирования данных (секционирования по таким полям, как время и географическое положение), выполнения статистики количества элементов в каждом разделе, а затем суммирования результатов каждого раздела.
Шаг 1. Разделите данные по определенному полю (например, времени).
Шаг 2. Выполните статистику мощности для каждого раздела.
Шаг 3: Суммируйте статистику мощности всех разделов.
На самом деле эта проблема решается с помощью идеи алгоритма «разделяй и властвуй».
Однако, поскольку поля данных нашей организации ограничены, я не проверил этот план.
4. Вариант 4. Используйте внешние инструменты, такие как Redis, для реализации
Это решение заключается в синхронной миграции данных Elasticsearch в Redis и использовании статистики агрегирования, реализованной Redis.

def export_to_redis(es, redis_client, index_name):
try:
# Очистить Redis Set
redis_client.delete("unique_values")
# Scroll API получатьвседанные scroll_size = 1000
data = es.search(index=index_name, body={"query": {"match_all": {}}}, scroll='2m', size=scroll_size)
scroll_id = data['_scroll_id']
total_docs = data['hits']['total']['value']
print(f"Total documents to process: {total_docs}")
while scroll_size > 0:
for doc in data['hits']['hits']:
field_value = doc['_source']['title']
redis_client.sadd("unique_values", field_value)
data = es.scroll(scroll_id=scroll_id, scroll='2m')
scroll_id = data['_scroll_id']
scroll_size = len(data['hits']['hits'])
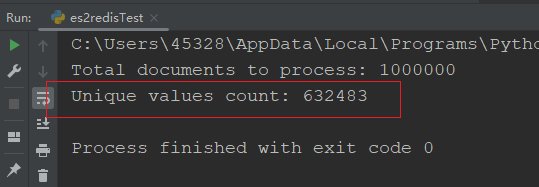
unique_count = redis_client.scard("unique_values")
print(f"Unique values count: {unique_count}")
# Очистить контекст прокрутки
es.clear_scroll(scroll_id=scroll_id)
except redis.RedisError as e:
print(f"Redis error: {e}")
except Exception as e:
print(f"Unexpected error: {e}")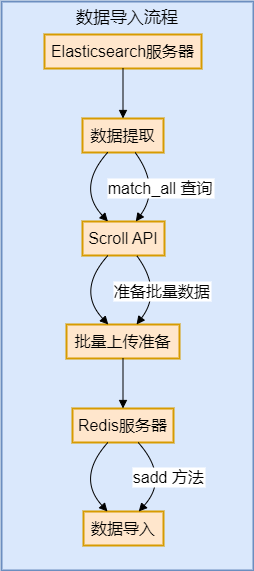
С помощью redis статистика после записи реализуется следующим образом:
unique_count = redis_client.scard("unique_values")
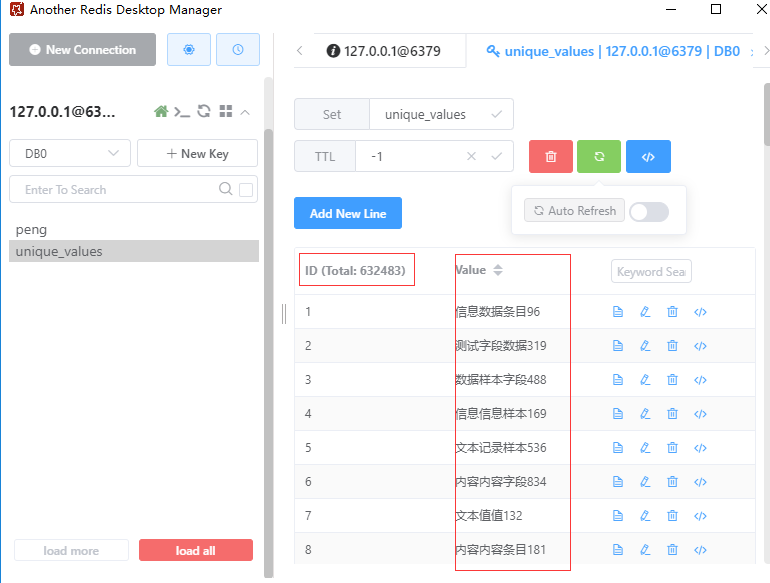
Функция приведенного выше кода — получить количество уникальных элементов в коллекции Redis unique_values. Он использует преимущества функции дедупликации коллекции Redis и возвращает общее количество элементов в коллекции с помощью метода Scar. Результат после дедупликации следующий:
Результаты, просмотренные с помощью клиента Redis, также согласуются со статистическими результатами.
5. Резюме
Чтобы добиться 100% точной статистики мощности при больших объемах данных, можно объединить следующие идеи и методы:
Увеличьте параметр Precision_threshold. Используйте агрегацию терминов в сочетании с селектором сегментов. Статистика разделов и обобщение. Используйте внешние инструменты обработки больших данных (например, Redis) для сбора статистики.
Каждый из этих методов имеет свои преимущества и недостатки, и конкретный выбор может быть определен на основе реальных потребностей бизнеса, размера данных и производительности системы.
Практическая проверка показала, что добиться точных результатов дедупликации на основе статистики Elasticsearch практически невозможно.
В практических приложениях может потребоваться использование различных методов для достижения как требований к производительности, так и статистической точности.



Углубленный анализ переполнения памяти CUDA: OutOfMemoryError: CUDA не хватает памяти. Попыталась выделить 3,21 Ги Б (GPU 0; всего 8,00 Ги Б).

[Решено] ошибка установки conda. Среда решения: не удалось выполнить первоначальное зависание. Повторная попытка с помощью файла (графическое руководство).

Прочитайте нейросетевую модель Трансформера в одной статье

.ART Теплые зимние предложения уже открыты

Сравнительная таблица описания кодов ошибок Amap

Уведомление о последних правилах Points Mall в декабре 2022 года.

Даже новички могут быстро приступить к работе с легким сервером приложений.

Взгляд на RSAC 2024|Защита конфиденциальности в эпоху больших моделей

Вы используете ИИ каждый день и до сих пор не знаете, как ИИ дает обратную связь? Одна статья для понимания реализации в коде Python общих функций потерь генеративных моделей + анализ принципов расчета.

Используйте (внутренний) почтовый ящик для образовательных учреждений, чтобы использовать Microsoft Family Bucket (1T дискового пространства на одном диске и версию Office 365 для образовательных учреждений)

Руководство по началу работы с оперативным проектом (7) Практическое сочетание оперативного письма — оперативного письма на основе интеллектуальной системы вопросов и ответов службы поддержки клиентов

[docker] Версия сервера «Чтение 3» — создайте свою собственную программу чтения веб-текста

Обзор Cloud-init и этапы создания в рамках PVE

Корпоративные пользователи используют пакет регистрационных ресурсов для регистрации ICP для веб-сайта и активации оплаты WeChat H5 (с кодом платежного узла версии API V3)

Подробное объяснение таких показателей производительности с высоким уровнем параллелизма, как QPS, TPS, RT и пропускная способность.

Удачи в конкурсе Python Essay Challenge, станьте первым, кто испытает новую функцию сообщества [Запускать блоки кода онлайн] и выиграйте множество изысканных подарков!

[Техническая посадка травы] Кровавая рвота и отделка позволяют вам необычным образом ощипывать гусиные перья! Не распространяйте информацию! ! !

[Официальное ограниченное по времени мероприятие] Сейчас ноябрь, напишите и получите приз

Прочтите это в одной статье: Учебник для няни по созданию сервера Huanshou Parlu на базе CVM-сервера.

Cloud Native | Что такое CRD (настраиваемые определения ресурсов) в K8s?

Как использовать Cloudflare CDN для настройки узла (CF самостоятельно выбирает IP) Гонконг, Китай/Азия узел/сводка и рекомендации внутреннего высокоскоростного IP-сегмента

Дополнительные правила вознаграждения амбассадоров акции в марте 2023 г.

Можно ли открыть частный сервер Phantom Beast Palu одним щелчком мыши? Супер простой урок для начинающих! (Прилагается метод обновления сервера)

[Играйте с Phantom Beast Palu] Обновите игровой сервер Phantom Beast Pallu одним щелчком мыши

Maotouhu делится: последний доступный внутри страны адрес склада исходного образа Docker 2024 года (обновлено 1 декабря)

Кодирование Base64 в MultipartFile

5 точек расширения SpringBoot, супер практично!

Глубокое понимание сопоставления индексов Elasticsearch.

15 рекомендуемых платформ разработки с нулевым кодом корпоративного уровня. Всегда найдется та, которая вам понравится.
