Elasticsearch Проверка использования индексного диска
хорошие вещи случаются
приятно упомянуть сегодня вещи случаются Статья посвящена Tencent Cloud.webСтатьи о брандмауэре приложений,Название статьи [Развлечение с пробной версией брандмауэра веб-приложений Tencent Cloud],Ссылка на статью:https://cloud.tencent.com/developer/article/2472571 В этой статье представлены функции и типы межсетевого экрана веб-приложений Tencent Cloud (WAF), его роль в защите безопасности веб-сайтов и бизнеса, а также подробно описаны его функции, такие как физическая проверка трафика, сортировка конфигурации и анализ трафика BOT.
Начнём сегодняшний контент...
Учитывая, что данные обычно хранятся в ES (Elasticsearch), а объем данных зачастую довольно велик, надо опасаться возможных проблем с дисками при выполнении масштабных операций по изменению данных. Например, когда вам нужно перенести или скопировать индекс, содержащий более десяти ГБ данных, это значительно увеличит использование диска. В этом случае особенно важно заранее понять использование диска.
Проверьте использование диска
Введите следующую команду на панели инструментов Kibana, чтобы получить подробный список всех индексов в кластере.
GET /_cat/indices?vПараметр ?v здесь является необязательным и используется для добавления заголовков (имен столбцов) к выходным данным, чтобы облегчить чтение результатов. После выполнения команды возвращается результат, показанный ниже.
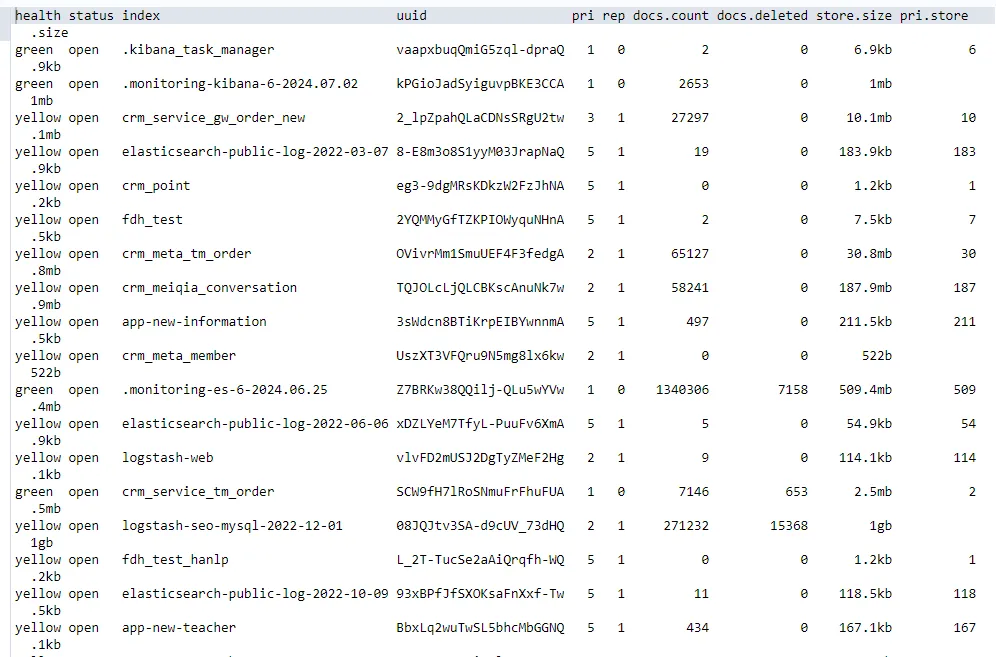
Среди них каждый столбец информации поясняется следующим образом:
Состояние здоровья (здоровья):
Состояние индекса обычно тесно связано с состоянием всего кластера и является важным индикатором того, нормально ли работает индекс.
Статус:
Текущее состояние индекса, например «открыто» или «закрыто», которое определяет, можно ли запрашивать и изменять индекс.
Имя индекса (индекс):
Имя, которое идентифицирует конкретный индекс и используется для уникальной идентификации индекса в Elasticsearch.
Уникальный идентификатор (uuid):
Каждый индекс снабжен уникальным идентификатором для точной идентификации при управлении и операциях кластера.
Количество первичных шардов (pri):
Количество первичных шардов, включенных в индекс. Первичные шарды отвечают за хранение данных и обработку запросов на чтение и запись.
Количество осколков реплики (rep):
Количество сегментов реплик для индекса. Осколки реплик обеспечивают избыточное резервное копирование данных и могут распределять нагрузку по запросам.
Количество документов (docs.count):
Общее количество документов, хранящихся в индексе, отражает размер данных индекса.
Количество удаленных документов (docs.deleted):
Количество документов в индексе, помеченных для удаления, но еще не полностью удаленных из сегмента диска.
Размер хранилища (store.size):
Общее дисковое пространство, занимаемое индексом, включая данные и метаданные всех шардов.
Размер основного хранилища шарда (pri.store.size):
Объем дискового пространства, занимаемого только основным сегментом, может помочь понять стоимость и эффективность фактического хранения данных.
Если вы хотите получить подробную информацию о распределении шардов в кластере. Вы можете сделать следующий запрос, который поможет вам понять, как сегменты кластера распределяются по различным узлам, а также использование памяти и диска каждым узлом.
GET /_cat/allocation?vРезультат вывода такой, как показано на рисунке

Среди них каждый столбец информации поясняется следующим образом:
Общее количество шардов (осколков):
Отображает текущее количество шардов в кластере, отражающее степень уточнения распределения данных.
Использование индексного диска (disk.indices):
Подсчитайте общий объем дискового пространства, занимаемый всеми индексными данными.
Используемое дисковое пространство (disk.used):
Отображает объем дискового пространства, использованного на каждом узле.
Доступное дисковое пространство (disk.avail):
Указывает объем дискового пространства, оставшегося доступным на каждом узле.
Общая емкость диска (disk.total):
Показывает общую емкость диска каждого узла.
IP-адрес (ip):
Идентифицирует сетевой адрес каждого узла.
Имя узла (узла):
Укажите уникальное имя для каждого узла.
Проверить использование диска по указанному индексу
Помимо просмотра общего использования диска es, вы также можете просмотреть использование диска по определенному индексу.
GET /_cat/indices/crm_meiqia_conversation?vРезультаты запроса показаны на рисунке.

Среди них информация столбца объясняется следующим образом:
health: Состояние здоровья индекса, обычно с зеленый, желтый и Существует три состояния красного цвета (красный), обозначающие, что все первичные сегменты и реплики доступны, все первичные сегменты доступны, но некоторые реплики недоступны, а некоторые первичные сегменты недоступны.
status: Статус индекса, например открыть или закрывать.
index: Имя индекса.
uuid: Уникальный идентификатор индекса.
pri: Число первичных шардов для индекса.
rep: Количество осколков реплик для индекса.
docs.count: Общее количество документов в индексе.
docs.deleted: Количество документов в индексе, помеченных для удаления, но еще не полностью удаленных из сегмента диска.
store.size: Объем дискового пространства, занимаемого индексом.
pri.store.size: Объем дискового пространства, занимаемый основным сегментом.
Проверьте состояние потока узла
Иногда вам нужно проверить состояние потоков узла, вы можете использовать следующую команду
GET /_cat/thread_pool?vРезультаты запроса показаны на рисунке.
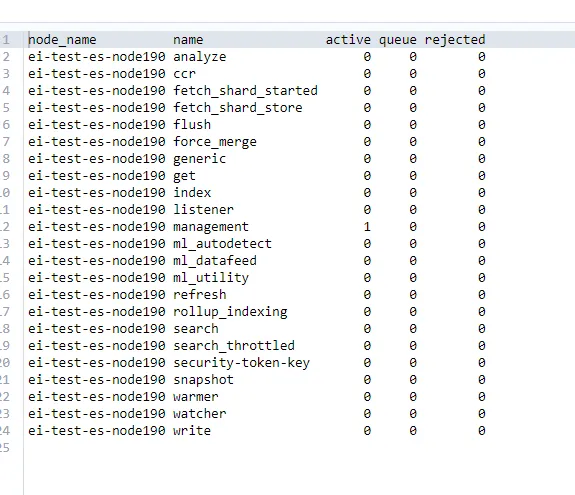
Среди них информация столбца объясняется следующим образом:
node_name: Имя узла.
name: Имя пула потоков, например search、write、management и т. д., указывая назначение пула потоков.
active: Количество активных в данный момент потоков, то есть количество потоков, выполняющих задачи.
queue: Количество задач, находящихся в настоящее время в очереди, указывает количество задач, ожидающих выполнения.
rejected: Количество отклоненных задач, что обычно происходит, когда очередь заполнена и больше не может обрабатывать задачи.
Запрос статуса выполнения асинхронных задач
Иногда вам может потребоваться использовать асинхронные задачи при работе с es, тогда вам нужно запросить статус выполнения асинхронных задач и выполнить команду
GET /_tasks/cbwVMU6UTACFPxKW0zkOcw:453897345Когда выполнение асинхронной задачи завершается, вы передаете идентификатор асинхронной задачи. Запрос статуса выполнения асинхронных задач Будет дана следующая подсказка
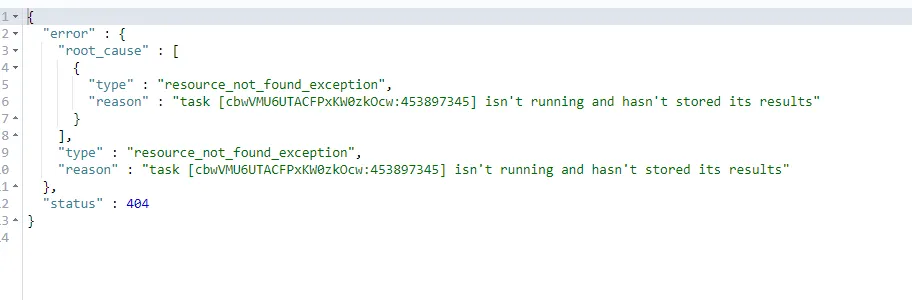
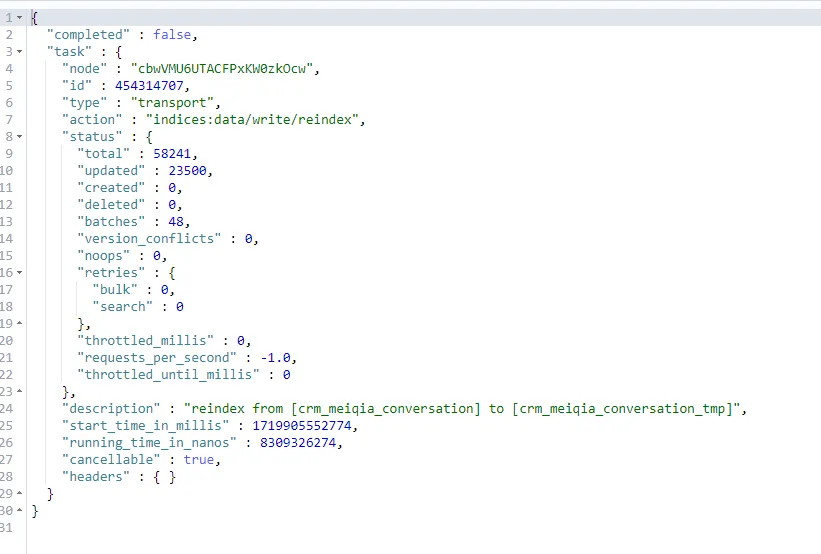
При запросе выполняемой асинхронной задачи будет возвращен следующий контент
Прочие операции
В дополнение к вышеуказанным операциям команды es существует также операция принудительного обновления es.
# Принудительное обновление
POST /_flush/synced?pretty
POST /_refreshв
POST /_flush/synced?pretty
Используется для сброса данных из памяти на диск и обеспечения синхронизации данных между несколькими копиями сегментов. Это важно для обеспечения долговечности и согласованности данных, особенно в случае сбоя или перезагрузки.
POST /_refresh
Используется для обновления индекса, чтобы новые добавленные или обновленные документы были видны для поиска. В Elasticsearch запись документов и обновление индексов асинхронны, а это означает, что вновь написанные документы могут не сразу отображаться для поиска.
Эти два запроса служат разным целям в Elasticsearch, и соответствующую операцию следует выбирать в зависимости от ваших конкретных потребностей.



Углубленный анализ переполнения памяти CUDA: OutOfMemoryError: CUDA не хватает памяти. Попыталась выделить 3,21 Ги Б (GPU 0; всего 8,00 Ги Б).

[Решено] ошибка установки conda. Среда решения: не удалось выполнить первоначальное зависание. Повторная попытка с помощью файла (графическое руководство).

Прочитайте нейросетевую модель Трансформера в одной статье

.ART Теплые зимние предложения уже открыты

Сравнительная таблица описания кодов ошибок Amap

Уведомление о последних правилах Points Mall в декабре 2022 года.

Даже новички могут быстро приступить к работе с легким сервером приложений.

Взгляд на RSAC 2024|Защита конфиденциальности в эпоху больших моделей

Вы используете ИИ каждый день и до сих пор не знаете, как ИИ дает обратную связь? Одна статья для понимания реализации в коде Python общих функций потерь генеративных моделей + анализ принципов расчета.

Используйте (внутренний) почтовый ящик для образовательных учреждений, чтобы использовать Microsoft Family Bucket (1T дискового пространства на одном диске и версию Office 365 для образовательных учреждений)

Руководство по началу работы с оперативным проектом (7) Практическое сочетание оперативного письма — оперативного письма на основе интеллектуальной системы вопросов и ответов службы поддержки клиентов

[docker] Версия сервера «Чтение 3» — создайте свою собственную программу чтения веб-текста

Обзор Cloud-init и этапы создания в рамках PVE

Корпоративные пользователи используют пакет регистрационных ресурсов для регистрации ICP для веб-сайта и активации оплаты WeChat H5 (с кодом платежного узла версии API V3)

Подробное объяснение таких показателей производительности с высоким уровнем параллелизма, как QPS, TPS, RT и пропускная способность.

Удачи в конкурсе Python Essay Challenge, станьте первым, кто испытает новую функцию сообщества [Запускать блоки кода онлайн] и выиграйте множество изысканных подарков!

[Техническая посадка травы] Кровавая рвота и отделка позволяют вам необычным образом ощипывать гусиные перья! Не распространяйте информацию! ! !

[Официальное ограниченное по времени мероприятие] Сейчас ноябрь, напишите и получите приз

Прочтите это в одной статье: Учебник для няни по созданию сервера Huanshou Parlu на базе CVM-сервера.

Cloud Native | Что такое CRD (настраиваемые определения ресурсов) в K8s?

Как использовать Cloudflare CDN для настройки узла (CF самостоятельно выбирает IP) Гонконг, Китай/Азия узел/сводка и рекомендации внутреннего высокоскоростного IP-сегмента

Дополнительные правила вознаграждения амбассадоров акции в марте 2023 г.

Можно ли открыть частный сервер Phantom Beast Palu одним щелчком мыши? Супер простой урок для начинающих! (Прилагается метод обновления сервера)

[Играйте с Phantom Beast Palu] Обновите игровой сервер Phantom Beast Pallu одним щелчком мыши

Maotouhu делится: последний доступный внутри страны адрес склада исходного образа Docker 2024 года (обновлено 1 декабря)

Кодирование Base64 в MultipartFile

5 точек расширения SpringBoot, супер практично!

Глубокое понимание сопоставления индексов Elasticsearch.

15 рекомендуемых платформ разработки с нулевым кодом корпоративного уровня. Всегда найдется та, которая вам понравится.
