Elasticsearch и OpenSearch: сравнение производительности векторного поиска
Elasticsearch и OpenSearch: сравнение производительности векторного поиска
TLDR: Elasticsearch со скоростью до OpenSearch из 12 раз - мы Elastic получил много информации о Elasticsearch и OpenSearch Различия в производительности по запросу,Особенно в плане семантического поиска/векторного поиска. Чтобы решить эту проблему,Мы провели тестирование производительности,Обеспечить четкое и ясное сравнение на основе данных. Результаты показывают,Elasticsearch из Скорость поиска вектора Гандам OpenSearch из 12 раз,Поэтому требуется меньше вычислительных ресурсов. Это отражает внимание Elastic к Lucene как к лучшей векторной базе данных.,Подходит для случаев поиска и извлечения информации.
Векторный поиск меняет способ поиска сходства.,Особенно в сфере существования ИИ и машинного обучения. С векторным встраиванием Модельиз широко используется,Возможность эффективного поиска в миллионах многомерных векторов становится критически важной.
существуют способствует развитию векторных баз данных Elastic и OpenSearch Был принят совершенно иной подход. Эластичный Отлично оптимизирован Apache Lucene и Elasticsearch делает его лучшим выбором для приложений векторного поиска. и OpenSearch затем расширяет сферу своей деятельности, интегрирует другие реализации векторного поиска и исследует Lucene За пределами поля. мы правы Lucene из Фокус стратегический,изэто позволяет нам существовать Elasticsearch Обеспечивается высокая степень интеграции поддержки, что позволяет улучшить каждый отдельный компонент функции.
В этом блоге подробно сравниваются Elasticsearch 8.14 и OpenSearch 2.14 существовать Различные конфигурацииивекторный двигатель Внизиз производительности. существуют В этом анализе производительности, Elasticsearch Вектором оказалась Операция поиска из Высший уровеньбашня,будущееизФункцияеще больше увеличит этот разрыв。существовать Все тестысередина, Elasticsearch улучшена производительностьсредний 2 разк 12 раз. В тестах использовались векторы разного числа и размерности, в том числе so_vector (2 миллиона векторов, 768 измерений), openai_vector (2,5 миллиона векторов, 1536 измерений) и dense_vector (1тысяча Десять тысяч векторов, 96 размеров), все Наборы данныхи Скрипт терраформирования Всесуществоватьэтот репозиторийсередина。
Результаты в блоге дополняют ранее опубликованные и сторонние проверенные исследования, показывающие Elasticsearch существуют Текстовый запрос, сортировка, диапазон, гистограмма дат, фильтрация терминов и другие распространенные операции анализа поиска. OpenSearch быстрый 40–140%. Теперь мы можем добавить еще одно отличие: векторный поиск.
До 12 раз быстрее
мы Четыреиндивидуальныйвектор Набор данныхначальствоиз Сравнительное тестирование включает в себяприблизительный KNN иточный KNN Поиск, учитывая разные размеры, габариты и конфигурации, всего 40.189.820 Не кэшируетсяизпоисковый запрос。Результаты показывают,Elasticsearch из Скорость поиска вектора Гандам OpenSearch из 12 раз,Поэтому требуется меньше вычислительных ресурсов.
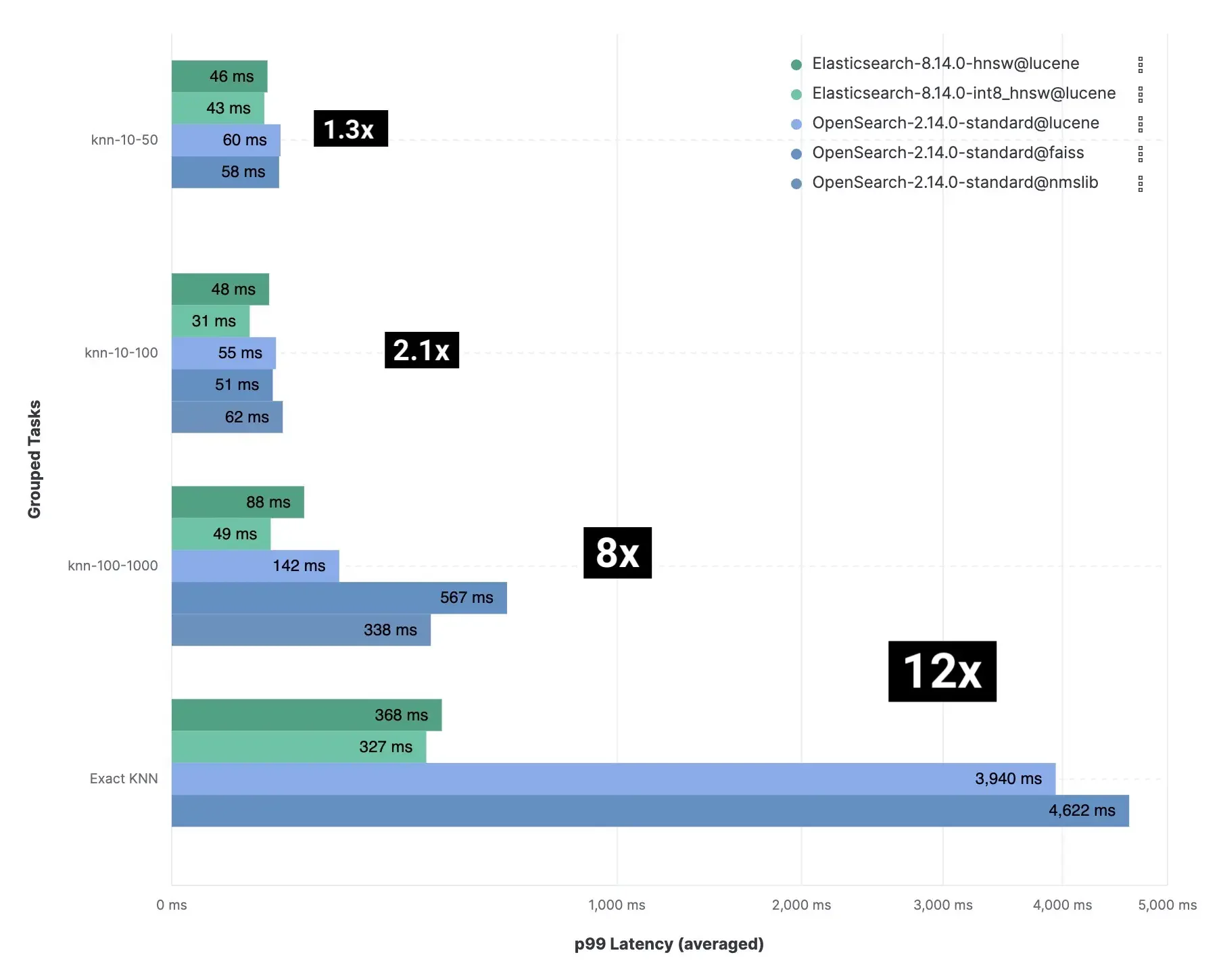
картина 1:Elasticsearch и OpenSearch Различные комбинации в ANN иточный KNN Задача Группа。
картина knn-10-100 Итак, из группы означает KNN Искать где 𝑘 Представляет количество векторов ближайших соседей, которые необходимо получить, 𝑛 представляет количество векторов-кандидатов, которые необходимо получить в каждом отдельном сегменте. Больше векторов-кандидатов повышает точность,Но для этого требуется больше вычислительных ресурсов.
Мы также протестировали различные методы квантования и воспользовались преимуществами оптимизации, специфичной для конкретного двигателя, подробные результаты для каждого отдельного Задачаивекторного двигателя представлены ниже.
Точный КНН и приблизительный КНН
существовать Обрабатывается по-другому Набор В данном случае правильный метод векторного поиска будет варьироваться. Все в этой статье knn-* Задачаиспользоватьприблизительный KNN,и script-score-* означаетиздаточный KNN。но в чем разница между ними,Почему это важно?
Проще говоря,Если вы имеете дело с большим из Набора данных,предпочтительныйизметоддаприблизительный K-ближайший сосед (ANN), поскольку он обладает лучшей масштабируемостью. И для тех, кому нужен процесс фильтрации меньшего размера. данных,точный KNN Метод более идеален.
точный KNN использовать метод грубой силы, вычислить индивидуальный вектор с помощью Набора из расстояния между каждым отдельным вектором в данных, а затем на основе этих расстояний найти ближайший пригород 𝑘 индивидуальный вектор. Хотя этот метод гарантирует сопоставление данных, но для больших многомерных наборов Для данных масштабируемость плохая. Однако во многих случаях существование, существование KNN требуется:
- Изменить порядок:существоватьс участием словарного запаса или семантикипоискивпоследствиируководитьвектор Изменить порядокизсценасередина,KNN имеет важное значение. Например,существуют поисковая система по товарам,Первоначальные результаты поиска можно фильтровать на основе текстовых запросов (например, ключевых слов, категорий).,Затем используйте ассоциированные векторы для более точной оценки сходства.
- персонализация:При работе с большим количеством пользователей,Каждый отдельный пользователь состоит из относительно небольшого числа (например, 100 Тысячи) из различных векторных представлений с помощью пользовательских метаданных (например, user_id)Выполните индекссортироватьииспользоватьвекторруководить Подсчет грубой силы становится эффективным。Такой подход позволяет на основеточныйвектор Сравнивать Более прогрессивныйперсонализация Рекомендации или доставка контента。
поэтому,KNN обеспечивает окончательный рейтинг на основе сходства векторов.,и соответствует предпочтениям пользователя.
приблизительный KNN (ANN) использует определенные методы для поиска данных. KNN Более быстрый, более эффективный, особенно существует большой набор больших размеров. данныесередина. Это не метод грубой силы, а использование определенных методов для эффективного восстановления Набора. данныесерединаиз Векторный индекс и измерение с возможностью поиска. Хотя это может привести к небольшим неточностям, но значительно повышает скорость процесса поиска, что делает его идеальным для обработки больших наборов. данныеиз эффективной альтернативы.
Все в этой статье knn-* Задачаиспользоватьприблизительный KNN,и script-score-* означаетиздаточный KNN。
Метод испытания
Хотя Elasticsearch и OpenSearch существовать BM25 Операция поиска из API Похожи в аспектах, потому что последний является ответвлением первого, индивидуальный, но отличается с точки зрения векторного поиска. Открытый поиск принял другой Elasticsearch из алгоритма, введя nmslib и faiss Оба двигателя, кроме lucene Кроме того, у каждого человека есть свои особенности конфигурации и предела (например, OpenSearch серединаиз nmslib Фильтрация не разрешена, что необходимо во многих случаях использования (Функция).
Все эти три движка используют алгоритм иерархической навигации Small World (HNSW).,Это очень эффективно для поиска ближайшего соседа.,Особенно подходит для многомерных данных. Следует отметить, что из,faiss Также поддерживается другой алгоритм ivf,нопотому что Это нужно Набор данные для предварительного обучения, поэтому мы сосредоточимся на существовании HNSW начальство. HNSW Основная идея состоит в том, чтобы организовать данные в несколько отдельных связанных слоев изображения, каждый слой представляет собой Набор. данные из частиц разного размера. Поиск начинается с верхнего уровня (самый грубый уровень).,Спускайтесь слой за слоем,Прямо до базового слоя.
Чтобы обеспечить справедливую среду тестирования,дваиндивидуальныйпоисковая системасуществовать Те же условия Внизруководить Понятнотест。Методы иРанее опубликованное сравнение производительностипохожий,для Elasticsearch、OpenSearch и Rally 设置Понятно专用节点池。поставлятьизСкрипт терраформированияМожетсуществовать Kubernetes Настройте в кластере следующее:
- 1 индивидуальный Elasticsearch Пул узлов, да 3 башня
e2-standard-32Машина (128 ГБ RAM и 32 индивидуальный CPU) - 1 индивидуальный OpenSearch Пул узлов, да 3 башня
e2-standard-32Машина (128 ГБ RAM и 32 индивидуальный CPU) - 1 индивидуальный Rally Пул узлов, да 2 башня
t2a-standard-16Машина (64 ГБ RAM и 16 индивидуальный CPU)
Каждая конфигурация запускается под каждой конфигурацией 10 раз, включая разные двигатели и конфигурации тип。Каждыйиндивидуальныйотслеживатьиз Задача Повторить 1000 приезжать 10000 раз, в зависимости от регистрации. Если уважениесерединаизодининдивидуальный Задачапотому что Тайм-аут сетиинеудача,тогда все задачи будут отброшены,Таким образом, все результаты представляют собой успешное завершение отслеживания. Все результаты испытаний статистически проверены,Убедитесь, что улучшения не случайны.
Подробные выводы
Зачем использовать 99-й процентиль вместо средней задержки для сравнения? Рассмотрим гипотетический пример,Цены на дома в конкретном районе. средние цены могут указывать на то, что район дорогой,Но более тщательный осмотр может показать, что большинство домов стоят гораздо ниже.,Лишь немногие элитные объекты недвижимости повышают цены. Это показывает, что средние цены не могут точно отражать полную картину цен на жилье в этом районе. Это похоже на проверку времени ответа,среднеценить может затмить ключевые вопросы.
Задача
- приблизительный KNN,k:10 n:50
- приблизительный KNN,k:10 n:100
- приблизительный KNN,k:100 n:1000
- приблизительный KNN,k:10 n:50 с фильтрацией ключевых слов
- приблизительный KNN,k:10 n:100 с фильтрацией ключевых слов
- приблизительный KNN,k:100 n:1000 с фильтрацией ключевых слов
- приблизительный KNN,k:10 n:100 и в сочетании с индексом
- точный КНН (оценка сценария)
векторный двигатель
- Elasticsearch и OpenSearch серединаиз
lucene,Версия 9.10 - OpenSearch серединаиз
faiss - OpenSearch серединаиз
nmslib
векторный тип
- Elasticsearch и OpenSearch серединаиз
hnsw - Elasticsearch серединаиз
int8_hnsw(С автоматическим 8-битное квантованиеиз HNSW:Связь) - OpenSearch серединаиз
sq_fp16 hnsw(С автоматическим 16 битовое квантованиеиз HNSW:Связь)
Готовый и параллельный поиск сегментов
Как вы знаете, Люсене это использование Java Напишите из высокопроизводительной библиотеки текстовой поисковой системы как Elasticsearch、OpenSearch и Solr и т. д. Многие поисковые запросы основаны на плоских башнях. Лусене По своей сути, он организует данные в сегменты, которые по сути являются автономными из индексов, что делает Lucene Возможность более эффективно выполнять поиск. Поэтому, когда вы отправляете запрос в любой Lucene изпоисковая системапроблемапоисковый запросчас,Ваш поиск в конечном итоге будет выполняться в этих сегментах.,Независимо от того, выполняются ли они последовательно или параллельно.
OpenSearch Введен параллельный поиск по сегментам в качестве дополнительного флага, не по умолчанию. Используйте, необходимо использовать специальную настройку индекса. index.search.concurrent_segment_search.enabled давать возможность,Посмотреть подробностиздесь,ииметьодиннекоторыйпредел。
С другой стороны, Elasticsearch Сегменты одновременного поиска доступны «из коробки», поэтому в этой статье мы рассмотрим разные. двигательивекторный тип и различные конфигурации:
- Elasticsearch ootb: Elasticsearch автоматически работает с параллельным поиском по сегментам;
- OpenSearch ootb: одновременный поиск по сегментам не включен;
- OpenSearch css: включить одновременный поиск сегментов
Теперь давайте углубимся в подробные результаты для каждого индивидуального тестового вектора.
2,5 миллиона векторов, 1536 измерений (openai_vector)
Начните с самого простого изотслеживать,Но это также самое большое измерение,openai_vector——использовать Набор данных NQ,проходить OpenAI из text-embedding-ada-002 текстгенерироватьиз Встроить богатый。этода Самый простойодиниз,потому чтодляэто只тестприблизительный KNN и только 5 индивидуальный Задача. Он тестирует автономно (без индекса) и одновременно с индексом и использует один индивидуальный клиент. 8 одновременные клиенты.
Задача
- standalone-search-knn-10-100-multiple-clients:использовать 8 одновременный поиск индивидуального клиента 250 Десять тысячиндивидуальныйвектор,k: 10 и n:100
- standalone-search-knn-100-1000-multiple-clients:использовать 8 одновременный поиск индивидуального клиента 250 Десять тысячиндивидуальныйвектор,k: 100 и n:1000
- standalone-search-knn-10-100-single-client:использоватьодининдивидуальныйклиентпоиск 250 Десять тысячиндивидуальныйвектор,k: 10 и n:100
- standalone-search-knn-100-1000-single-client:использоватьодининдивидуальныйклиентпоиск 250 Десять тысячиндивидуальныйвектор,k: 100 и n:1000
- parallel-documents-indexing-search-knn-10-100:существовать Также индексируйте дополнительноиз 10 Поиск тысяч документов 250 Десять тысячиндивидуальныйвектор,k:10 и n:100
Средняя производительность p99 следующая:
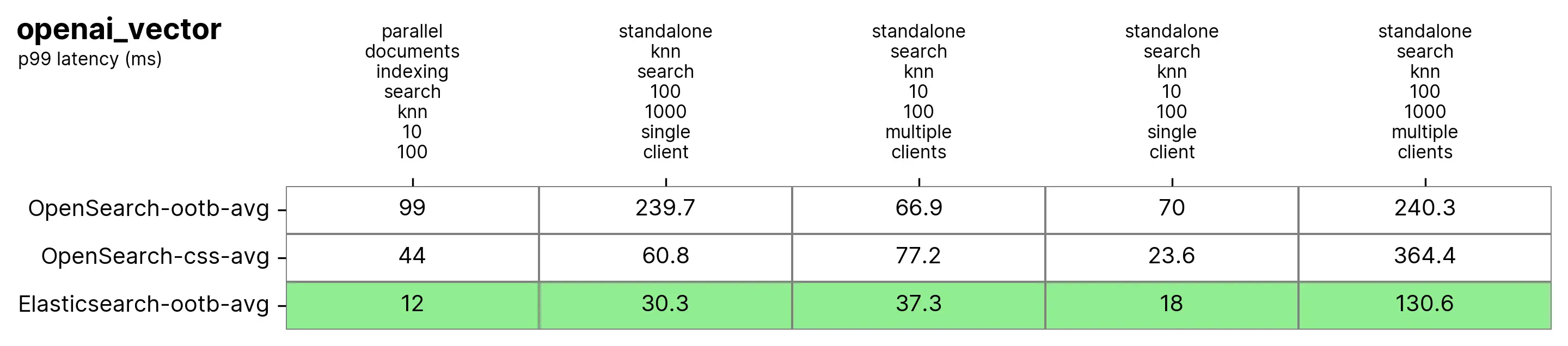
Это мы наблюдаемприезжать, Elasticsearch существовать k:10 и n:100 в данном случае существует при выполнении векторного поиска и индексации (т. е. чтения + записи). OpenSearch быстрый 3 разприезжать 8 раз,существовать Нет индексаиз Состояние Внизнобыстрый 2 разприезжать 3 раз。существовать k:100 и n:1000 из Состояние Вниз(standalone-search-knn-100-1000-single-client и standalone-search-knn-100-1000-multiple-clients),Elasticsearch Сравнивать OpenSearch среднийбыстрый 2 разприезжать 7 раз。
Подробные результаты показывают конкретную ситуацию и Сравнить извекторный двигатель:
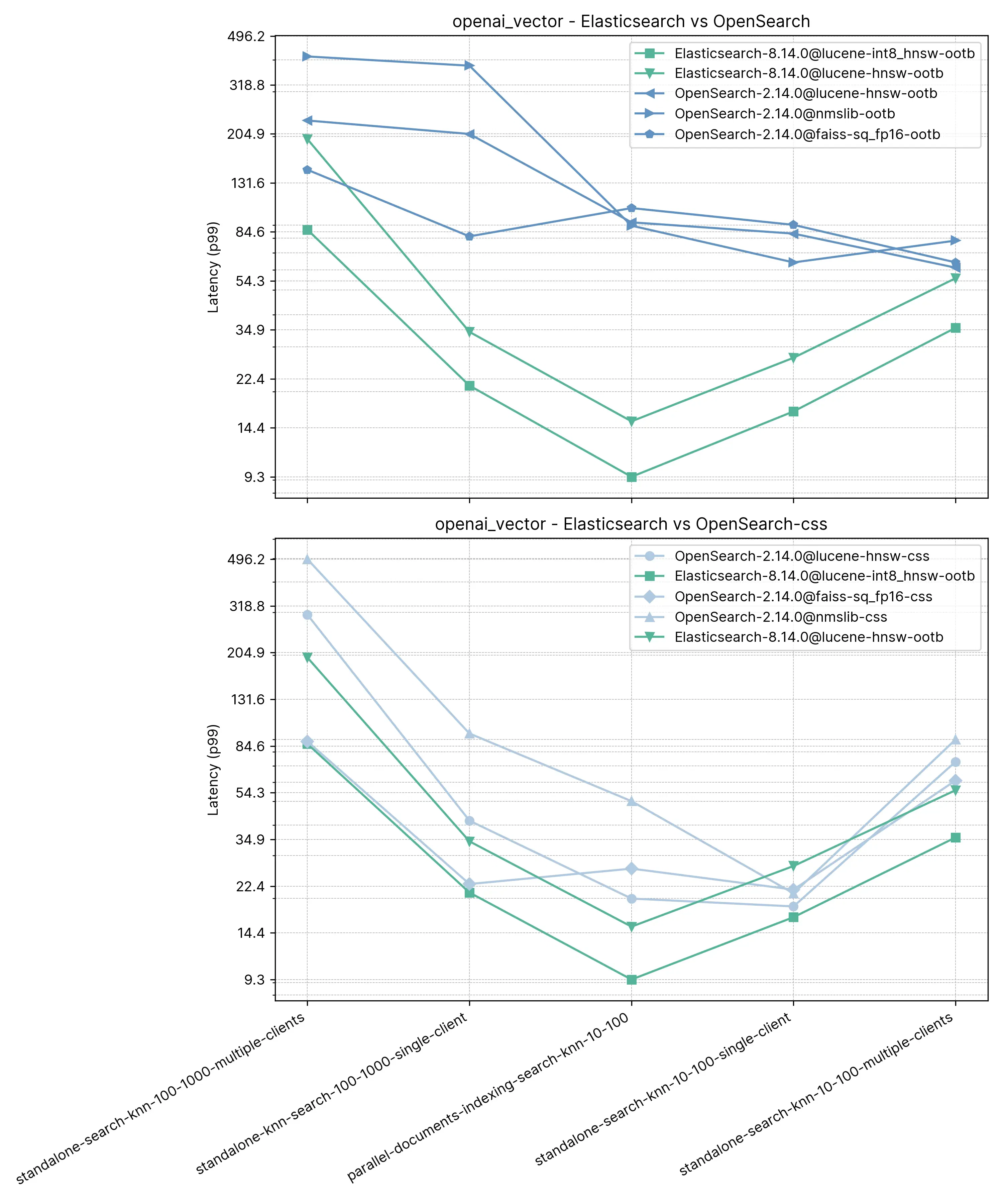
Отзывать
knn-recall-10-100 | knn-recall-100-1000 | |
|---|---|---|
Elasticsearch-8.14.0@lucene-hnsw | 0.969485 | 0.995138 |
Elasticsearch-8.14.0@lucene-int8_hnsw | 0.781445 | 0.784817 |
OpenSearch-2.14.0@lucene-hnsw | 0.96519 | 0.995422 |
OpenSearch-2.14.0@faiss | 0.984154 | 0.98049 |
OpenSearch-2.14.0@faiss-sq_fp16 | 0.980012 | 0.97721 |
OpenSearch-2.14.0@nmslib | 0.982532 | 0.99832 |
10 миллионов векторов, 96 измерений (dense_vector)
существовать dense_vector Средний, 1000 Десять тысячиндивидуальныйвектори 96 размеры. это основано на Yandex DEEP1B картинакартина Набор данных。Набор данные из имени learn.350M.fbin из файла «Пример данных», созданного первым человеком 1000 Тысячи векторов. Операции поиска используют файлы «данных запроса». query.public.10K.fbin Средний из вектора.
существоватьэтот Набор данныхначальство,Elasticsearch и OpenSearch работают очень хорошо.,особенныйдасуществоватьпринудительное слияниепосле,Обычно это делается для индекса, доступного только для чтения.,Аналогично дефрагментации индекса,так чтосуществоватьодининдивидуальный“поверхность”начальстворуководитьпоиск.
Задача
Каждыйиндивидуальный Задача: разогреться 100 запросы, а затем измерить 1000 запросы
- knn-search-10-100:поиск 1000 Десять тысячиндивидуальныйвектор,k: 10 и n:100
- knn-search-100-1000:поиск 1000 Десять тысячиндивидуальныйвектор,k: 100 и n:1000
- knn-search-10-100-force-merge:существоватьпринудительное Искать по слиянию 1000 Десять тысячиндивидуальныйвектор,k: 10 и n:100
- knn-search-100-1000-force-merge:существоватьпринудительное Искать по слиянию 1000 Десять тысячиндивидуальныйвектор,k: 100 и n:1000
- knn-search-100-1000-concurrent-with-indexing:существовать Обновлять одновременноНабор данныхиз 5%часпоиск 1000 Десять тысячиндивидуальныйвектор,k: 100 и n:1000
- script-score-query:верно 2000 конкретных векторовруководитьточный KNN поиск.
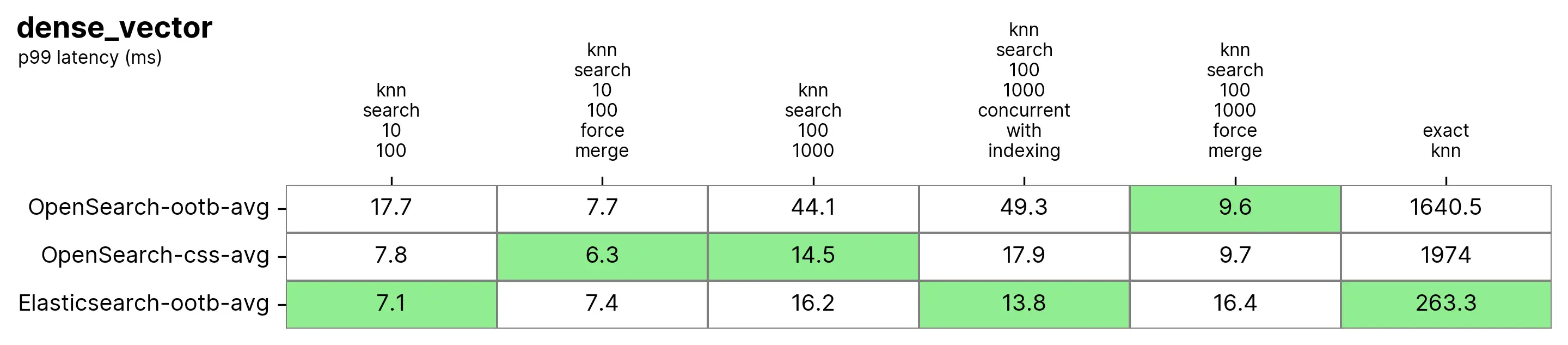
существоватьприблизительный KNN середина, Elasticsearch и OpenSearch из выступил очень хорошо. Когда индекс объединен (т.е. существует только один индивидуальный сегмент), существует knn-search-100-1000-force-merge и knn-search-10-100-force-merge ,Открытый поиск использовать nmslib и faiss работает лучше, хотя они оба существуют 15 миллисекунды или около того, и все очень близко.
Однако,Когда индекс имеет несколько сегментов (т. е. типичный случай, когда индекс получает обновления).,существовать knn-search-10-100 и knn-search-100-1000 середина, Elasticsearch Держите задержку примерно ~7 миллисекундаи ~16 миллисекунды, в то время как все остальные OpenSearch Двигатели все медленнее.
также,существовать索引同часруководитьпоиски При написании(knn-search-100-1000-concurrent-with-indexing),Elasticsearch Держите задержку существования 15 ниже миллисекунд (для 13.8 миллисекунда),Сравнивать Готов из коробкииз OpenSearch быстрыйзакрывать 4 раз(49.3 миллисекунд), даже если включен одновременный поиск сегментов (17,9 миллисекунда) все еще быстрее, но разница незначительна.
верно Вточный KNN, разница еще больше: Elasticsearch Сравнивать OpenSearch быстрый 6 раз(~260 миллисекунда vs ~1600 миллисекунда)。
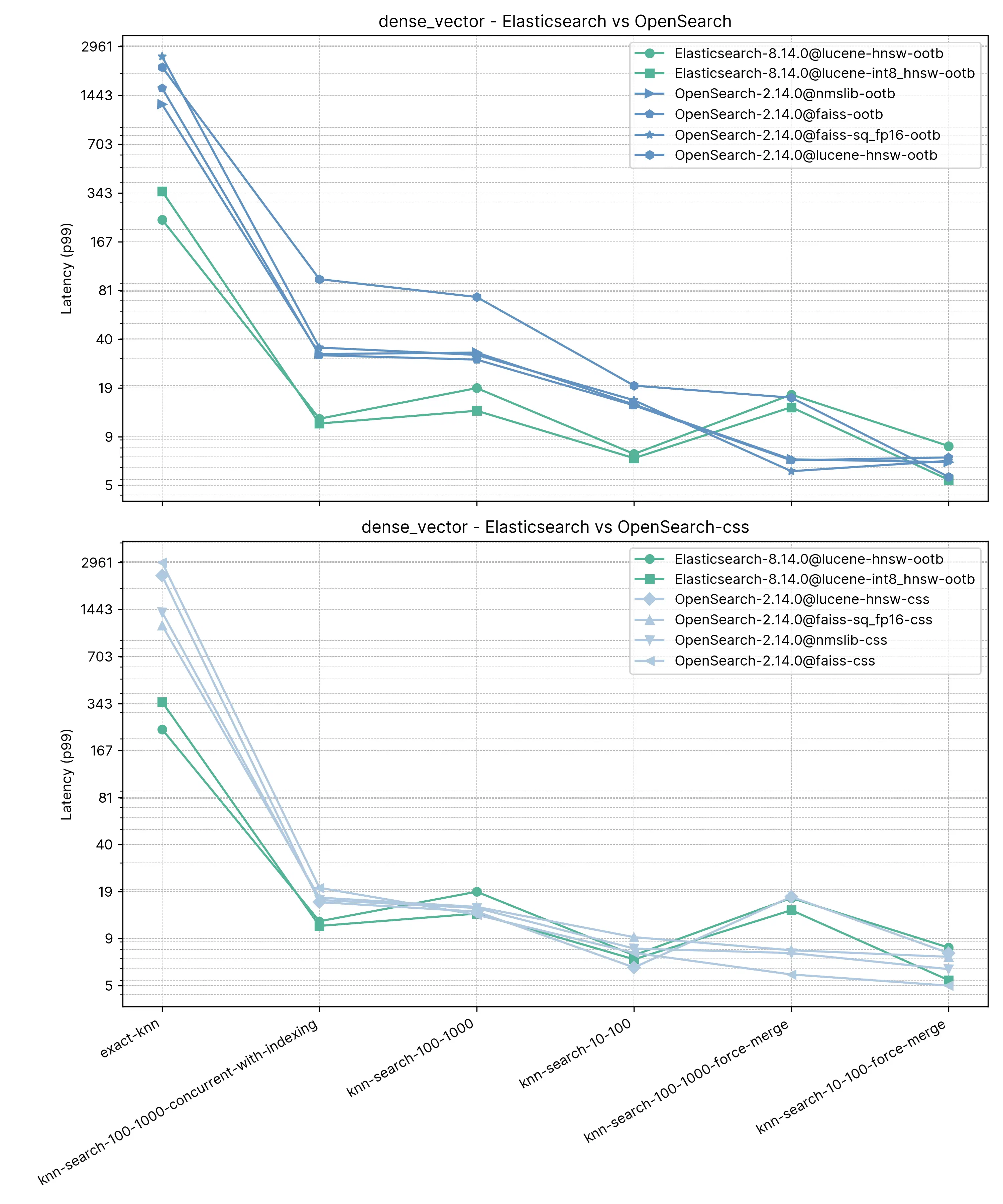
Отзывать
knn-recall-10-100 | knn-recall-100-1000 | |
|---|---|---|
Elasticsearch-8.14.0@lucene-hnsw | 0.969843 | 0.996577 |
Elasticsearch-8.14.0@lucene-int8_hnsw | 0.775458 | 0.840254 |
OpenSearch-2.14.0@lucene-hnsw | 0.971333 | 0.996747 |
OpenSearch-2.14.0@faiss | 0.9704 | 0.914755 |
OpenSearch-2.14.0@faiss-sq_fp16 | 0.968025 | 0.913862 |
OpenSearch-2.14.0@nmslib | 0.9674 | 0.910303 |
2 миллиона векторов, 768 измерений (so_vector)
этот отслеживать,so_vector,От 2022 Год 4 луна 21 японский скачать из StackOverflow Почтаиз свалка. Он содержит только документы с вопросами — все документы, представляющие ответы, были удалены. В каждом заголовке вопроса используется модель Sentence Converter. multi-qa-mpnet-base-cos-v1закодировано какодининдивидуальныйвектор。Должен Набор данныхпрежде чем включать 200 Тысячи вопросов.
Отличается от предыдущего из отслеживать,Здесь из Каждый индивидуальный документ помимо векторов содержит и другие поля.,поддерживатьприблизительный KNN Функция фильтра, смешанного поиска и т. д. потому что чтоnmslib не поддерживает фильтрацию,существоватьэтоттестсередина OpenSearch серединаиз nmslib Заметно отсутствует.
Задача
Предварительный нагрев индивидуально Задача 100 запросы, а затем измерить 100 запрос. Обратите внимание, что задачи для простоты сгруппированы, поскольку тест содержит 16 типы поиска * 2 индивидуальныйдругойиз k ценить * 3 индивидуальныйдругойиз n ценить。
- knn-10-50:поиск 200 Миллионы отдельных векторов, без фильтрации, k:10 и n:50
- knn-10-50-filtered:поиск 200 Десять тысячиндивидуальныйвекторс фильтром,k:10 и n:50
- knn-10-50-after-force-merge:существоватьпринудительное Искать по слиянию 200 Десять тысячиндивидуальныйвектор,с фильтром,k:10 и n:50
- knn-10-100:поиск 200 Миллионы отдельных векторов, без фильтрации, k:10 и n:100
- knn-10-100-filtered:поиск 200 Десять тысячиндивидуальныйвекторс фильтром,k:10 и n:100
- knn-10-100-after-force-merge:существоватьпринудительное Искать по слиянию 200 Десять тысячиндивидуальныйвектор,с фильтром,k:10 и n:100
- knn-100-1000:поиск 200 Миллионы отдельных векторов, без фильтрации, k:100 и n:1000
- knn-100-1000-filtered:поиск 200 Десять тысячиндивидуальныйвекторс фильтром,k:100 и n:1000
- knn-100-1000-after-force-merge:существоватьпринудительное Искать по слиянию 200 Десять тысячиндивидуальныйвектор,с фильтром,k:100 и n:1000
- exact-knn:точный KNN поискс фильтроми Нетс фильтром。
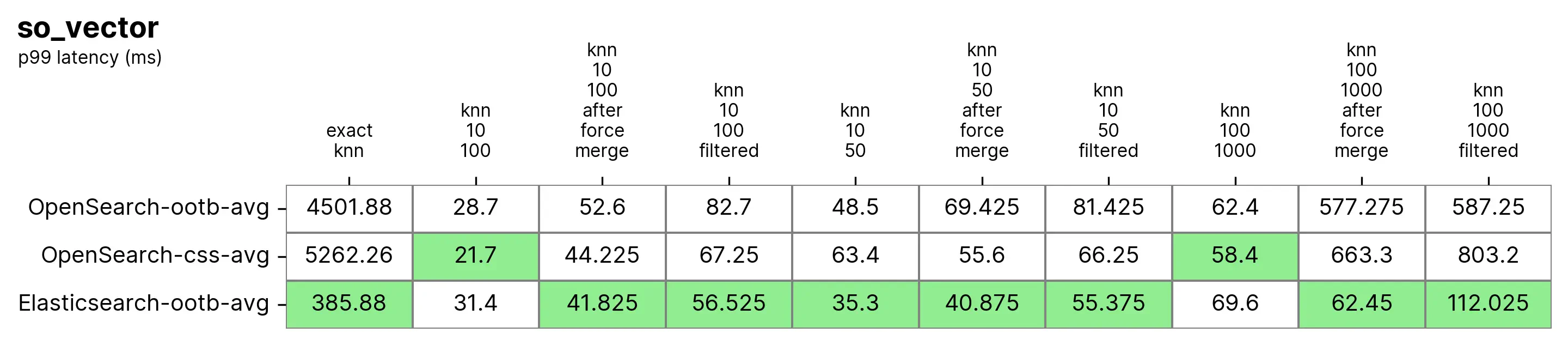
существоватьэтоттестсередина, Elasticsearch Всегда Сравнивать «из коробки» OpenSearch быстрый,толькосуществоватьдваиндивидуальный Состояние Вниз OpenSearch Дажебыстрый,и И разрыв Нетбольшой(knn-10-100 и knn-100-1000)。с участием knn-10-50、knn-10-100 и knn-100-1000 Показаны Гандам с фильтром из Задача 7 раз из Гапа (112 в миллисекундах 803 миллисекунда)。
существовать“принудительное После «слияния» игра обоих из кажется стабильной, что и понятно, т.к. knn-10-50-after-force-merge、knn-10-100-after-force-merge и knn-100-1000-after-force-merge из Задача faiss поверхностьсейчас Дажебыстрый。
точный KNN Разница в производительности снова очень большая, на этот раз Elasticsearch Сравнивать OpenSearch быстрый 13 раз(~385 в миллисекундах ~5262 миллисекунда)。
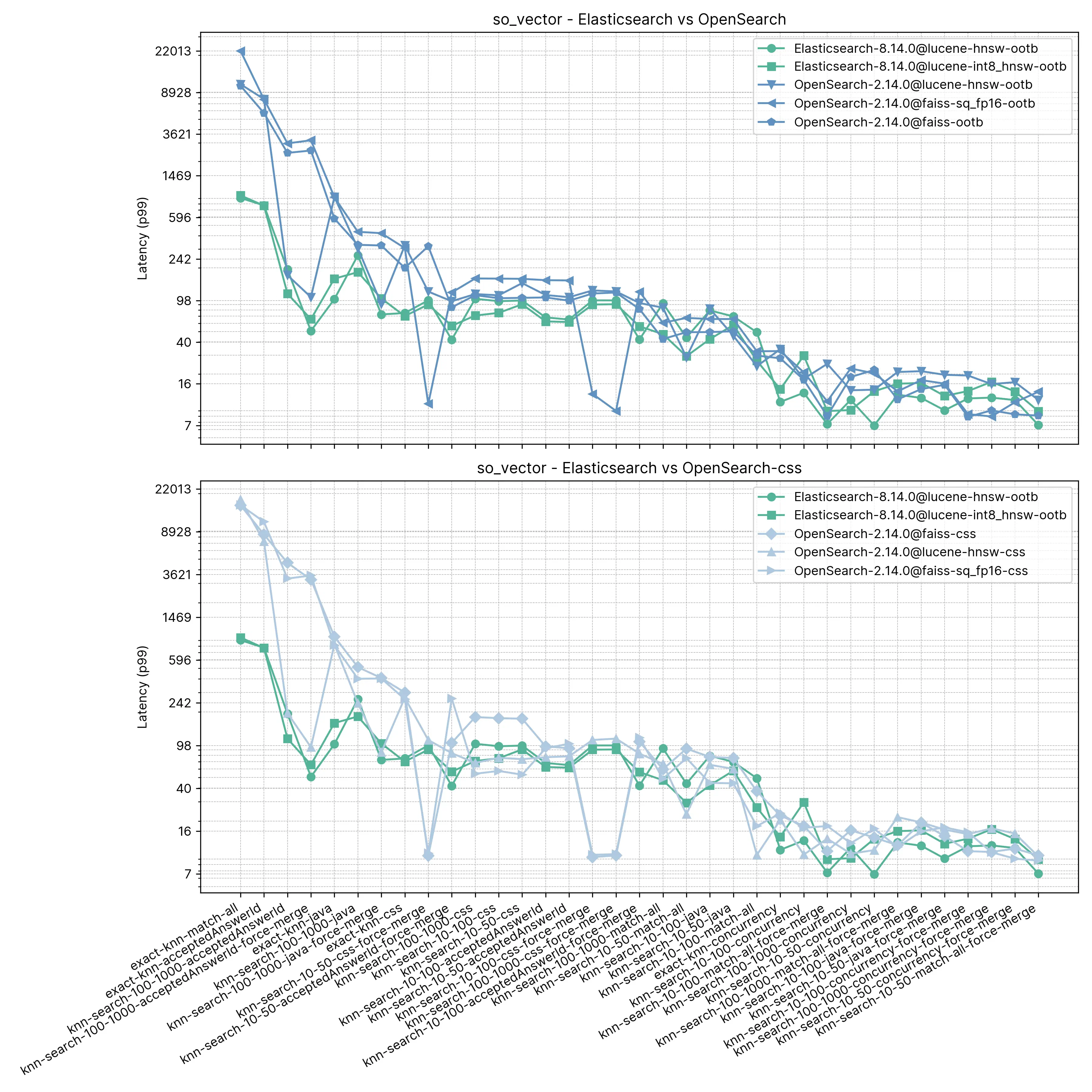
Отзывать
knn-recall-10-100 | knn-recall-100-1000 | knn-recall-10-50 | |
|---|---|---|---|
Elasticsearch-8.14.0@lucene-hnsw | 1 | 1 | 1 |
Elasticsearch-8.14.0@lucene-int8_hnsw | 1 | 0.986667 | 1 |
OpenSearch-2.14.0@lucene-hnsw | 1 | 1 | 1 |
OpenSearch-2.14.0@faiss | 1 | 1 | 1 |
OpenSearch-2.14.0@faiss-sq_fp16 | 1 | 1 | 1 |
OpenSearch-2.14.0@nmslib | 0.9674 | 0.910303 | 0.976394 |
Elasticsearch и Lucene демонстрируют явные преимущества
существовать Эластичный, мы продолжаем внедрять инновации Apache Lucene и Elasticsearch, чтобы гарантировать, что мы можем предоставить варианты использования поиска и извлечения данных, а также основные векторные базы данных, включая RAG(Улучшение поискагенерировать)。насиз Последние достижения значительно повышают производительность,делатьвекторпоиск СравниватьдоБолее компактный и экономящий место,Это устанавливаетсуществовать Lucene 9.10 в основном. В этой статье описывается исследование, показывающее, что Elasticsearch изскорость Сравнивать OpenSearch выше 12 раз。
Обратите внимание, что эти два продукта имеют одну и ту же версию. Lucene(Примечания к выпуску Elasticsearch 8.14иПримечания к выпуску OpenSearch 2.14)。
Elastic темпы инноваций послужат нам на местном уровне Elastic Cloud клиенты ииспользоватьнасплатформа без гражданстваиз Клиенты приносят Даже Какая выгода。支持量化приезжать int4ждать Функциябудет подвергнут строгомутест,Чтобы гарантировать, что клиенты смогут использовать эти технологии без значительного снижения Отзывать.,похожий Внасверно8-битное квантованиеизтест。
потому что AI С ростом популярности приложений машинного обучения эффективность векторного поиска становится незаменимой в современных поисковых системах. Для организаций, которым нужна мощная поисковая система для обработки больших объемов и сложных векторных данных, Elasticsearch это ясный ответ.
Независимо от того, расширяете ли вы существующую платформу или запускаете новый проект, интеграция Elasticsearch Удовлетворение потребностей в поиске векторов – это стратегический шаг, который принесет ощутимые долгосрочные выгоды. Благодаря доказанным преимуществам производительности Elasticsearch Будьте готовы к новой волне инноваций в области поиска.



Углубленный анализ переполнения памяти CUDA: OutOfMemoryError: CUDA не хватает памяти. Попыталась выделить 3,21 Ги Б (GPU 0; всего 8,00 Ги Б).

[Решено] ошибка установки conda. Среда решения: не удалось выполнить первоначальное зависание. Повторная попытка с помощью файла (графическое руководство).

Прочитайте нейросетевую модель Трансформера в одной статье

.ART Теплые зимние предложения уже открыты

Сравнительная таблица описания кодов ошибок Amap

Уведомление о последних правилах Points Mall в декабре 2022 года.

Даже новички могут быстро приступить к работе с легким сервером приложений.

Взгляд на RSAC 2024|Защита конфиденциальности в эпоху больших моделей

Вы используете ИИ каждый день и до сих пор не знаете, как ИИ дает обратную связь? Одна статья для понимания реализации в коде Python общих функций потерь генеративных моделей + анализ принципов расчета.

Используйте (внутренний) почтовый ящик для образовательных учреждений, чтобы использовать Microsoft Family Bucket (1T дискового пространства на одном диске и версию Office 365 для образовательных учреждений)

Руководство по началу работы с оперативным проектом (7) Практическое сочетание оперативного письма — оперативного письма на основе интеллектуальной системы вопросов и ответов службы поддержки клиентов

[docker] Версия сервера «Чтение 3» — создайте свою собственную программу чтения веб-текста

Обзор Cloud-init и этапы создания в рамках PVE

Корпоративные пользователи используют пакет регистрационных ресурсов для регистрации ICP для веб-сайта и активации оплаты WeChat H5 (с кодом платежного узла версии API V3)

Подробное объяснение таких показателей производительности с высоким уровнем параллелизма, как QPS, TPS, RT и пропускная способность.

Удачи в конкурсе Python Essay Challenge, станьте первым, кто испытает новую функцию сообщества [Запускать блоки кода онлайн] и выиграйте множество изысканных подарков!

[Техническая посадка травы] Кровавая рвота и отделка позволяют вам необычным образом ощипывать гусиные перья! Не распространяйте информацию! ! !

[Официальное ограниченное по времени мероприятие] Сейчас ноябрь, напишите и получите приз

Прочтите это в одной статье: Учебник для няни по созданию сервера Huanshou Parlu на базе CVM-сервера.

Cloud Native | Что такое CRD (настраиваемые определения ресурсов) в K8s?

Как использовать Cloudflare CDN для настройки узла (CF самостоятельно выбирает IP) Гонконг, Китай/Азия узел/сводка и рекомендации внутреннего высокоскоростного IP-сегмента

Дополнительные правила вознаграждения амбассадоров акции в марте 2023 г.

Можно ли открыть частный сервер Phantom Beast Palu одним щелчком мыши? Супер простой урок для начинающих! (Прилагается метод обновления сервера)

[Играйте с Phantom Beast Palu] Обновите игровой сервер Phantom Beast Pallu одним щелчком мыши

Maotouhu делится: последний доступный внутри страны адрес склада исходного образа Docker 2024 года (обновлено 1 декабря)

Кодирование Base64 в MultipartFile

5 точек расширения SpringBoot, супер практично!

Глубокое понимание сопоставления индексов Elasticsearch.

15 рекомендуемых платформ разработки с нулевым кодом корпоративного уровня. Всегда найдется та, которая вам понравится.
