Эксперты ICML 2023|CMU подробно резюмируют шесть основных задач «Мультимодального машинного обучения»: 36 страниц длинной статьи + 120 страниц PPT, вся практическая информация!
Новый отчет мудрости
Редактор: ЛРС
【Шин Джиген Введение】мультимодальныймашинное Шесть больших проблем в сфере образования: Представительство、Выровнять、рассуждение、генерировать、Перенос и количественная оценка.
Поскольку производительность различных крупных моделей, таких как язык, зрение, видео и аудио, продолжает расти, мультимодальное машинное обучение также начало расти. Интегрируя данные из разных модальностей, исследователи начали разрабатывать более сложные компьютерные агенты, которые могут лучше понимать. , рассуждать и учиться на реальном мире.
В процессе разработки исследования в области мультимодального машинного обучения также вызвали вычислительные и теоретические проблемы. В таких сценариях применения, как интеграция мультимодальности, автономия агентов и объединение нескольких датчиков, все еще существуют разнородные источники данных и т. д. Появляются новые источники данных. методы обнаружения закономерностей данных.

Недавно исследователи из Университета Карнеги-Меллона опубликовали подробный обзор мультимодального машинного обучения и провели учебное пособие на конференции ICML 2023. Обзор областей применения и теоретических основ мультимодального машинного обучения. Обзор вычислительных и теоретических основ машинного обучения.

Ссылка на документ: https://arxiv.org/pdf/2209.03430.pdf.
Презентация: https://drive.google.com/file/d/1qIYBuYrSW2-e95DL7LndfLFqGkIWFG21.
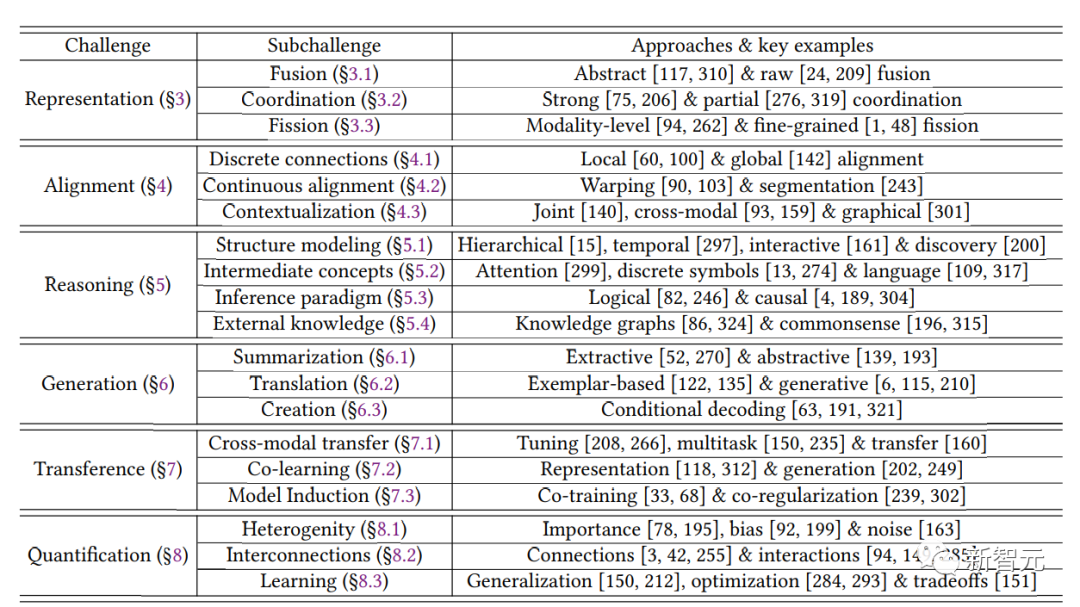
Исследователи сначала определили три ключевых принципа модальной неоднородности, связности и взаимодействия, которые определяют последующие инновации, и предложили классификацию шести основных технических проблем: характеристика, согласование, вывод, генерация, передача и количественная оценка. последние тенденции в модальном машинном обучении.

Автор статьи Пол Пу Лян — аспирант кафедры машинного обучения Университета Карнеги-Меллон. Его научные руководители — Луи-Филипп Моренси и Руслан Салахутдинов. Его основным направлением исследований являются основы мультимодального машинного обучения. его применение в искусственном интеллекте социального интеллекта, обработке естественного языка, приложениях в здравоохранении и образовании.
Задача 1: Характеристика Representation
Как изучить представления, отражающие кросс-модальные взаимодействия между отдельными элементами в разных модальностях, является проблемой. Эту задачу можно рассматривать как изучение локальных представлений между элементами или представлений с использованием глобальных функций.
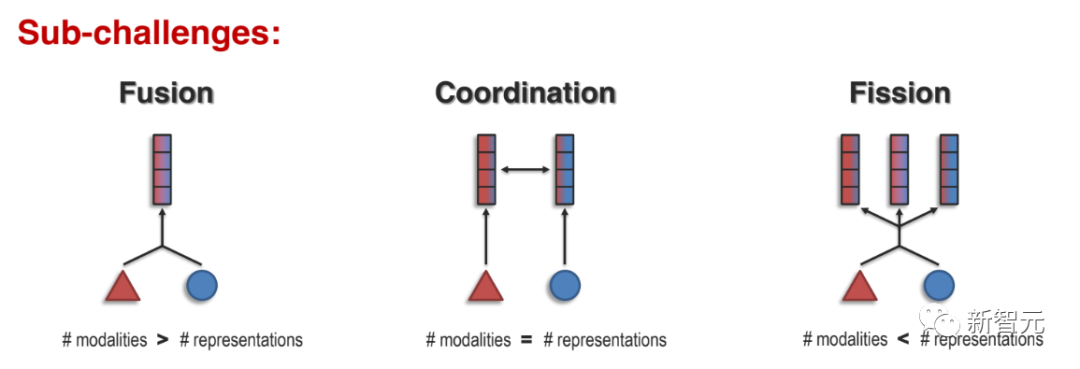
В статье в основном представлены три подзадачи:
1. Слияние представлений
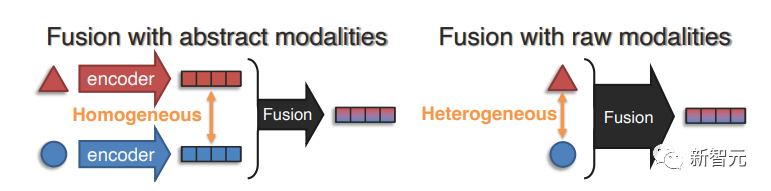
Цель объединения представлений — изучить совместное представление, которое может моделировать кросс-модальные взаимодействия между элементами в разных модальностях, тем самым эффективно сокращая количество независимых представлений.
Исследователи разделили эти методы на две категории:
(1) Абстрактное модальное слияние: сначала примените подходящий одномодальный кодер для захвата общего представления каждого элемента (или всех модальностей), а затем используйте несколько компонентов слияния представлений для изучения совместного представления, то есть слияние происходит в абстракция Репрезентативный уровень.
(2) Исходное модальное объединение представлений выполняется на ранней стадии, требующей лишь простой предварительной обработки, и даже сами исходные модальные данные могут быть введены напрямую.
2. Координация представительства
Цель состоит в том, чтобы изучить мультимодальные контекстуализированные представления, которые скоординированы друг с другом посредством корреляции; в отличие от слияния представлений, координация сохраняет количество представлений постоянным, но улучшает мультимодальную контекстуализацию;
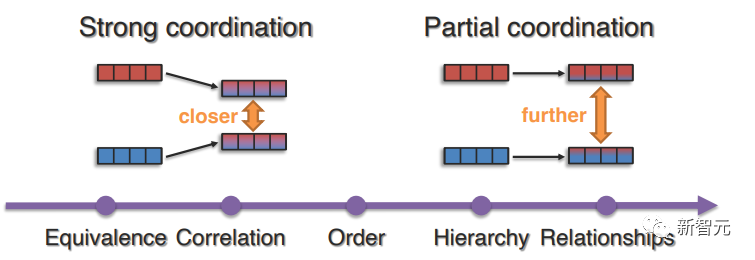
В статье сначала обсуждается сильная координация, которая обеспечивает строгую эквивалентность между модальными элементами, а затем переходит к частичной координации, которая может охватывать более общие связи, такие как корреляция, порядок, иерархия или отношения, выходящие за рамки сходства.
3. Деление представления
Цель состоит в том, чтобы создать новый набор разделенных представлений (обычно больший, чем набор входных представлений), которые отражают знания о внутренних мультимодальных структурах, таких как кластеризация данных, независимые факторы вариации или информация, специфичная для модальности.
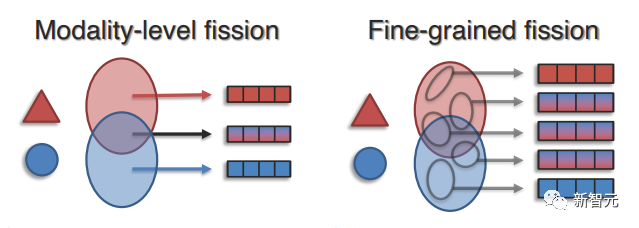
По сравнению с совместной характеристикой и скоординированной характеристикой, характеризирующее деление обеспечивает детальную интерпретацию и детальную управляемость. В зависимости от детализации факторов развязки методы можно разделить на деление модального уровня и мелкозернистое деление.
Задача 2: Согласование
Роль выравнивания заключается в выявлении кросс-модальных связей и взаимодействий между несколькими модальными элементами. Например, при анализе речи и жестов человека, как можно согласовать конкретный жест с произнесенным словом или высказыванием?
Согласование между модальностями может иметь зависимости на больших расстояниях или включать нечеткие сегментации (например, слова или предложения) и может быть один-к-одному, многие-ко-многим или вообще не иметь согласования, поэтому это очень сложная задача.
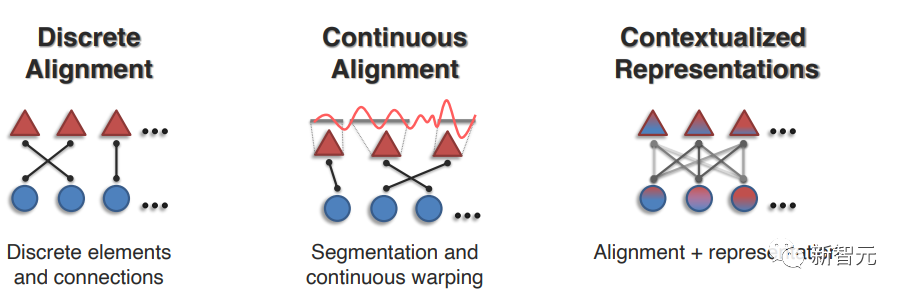
1. Дискретное выравнивание
Цель состоит в том, чтобы выявить связи между дискретными элементами нескольких модальностей. Недавние работы в основном включают два метода: локальное выравнивание находит связи между заданной парой совпадающих модальных элементов, которое должно выполняться глобально. Выравнивание, чтобы научиться соединяться и сопоставляться.
2. Непрерывное выравнивание
Предыдущие методы основаны на важном предположении, что модальные элементы сегментированы и дискретизированы.
Хотя для некоторых модальностей существуют четкие сегментации (например, слова/фразы в предложениях или области объектов на изображениях), во многих случаях границы сегментации найти непросто, например, непрерывные сигналы (например, финансовые или медицинские временные ряды), пространственно-временные данные ( такие как спутниковые или метеорологические изображения) или данные без четких семантических границ (например, изображения МРТ).
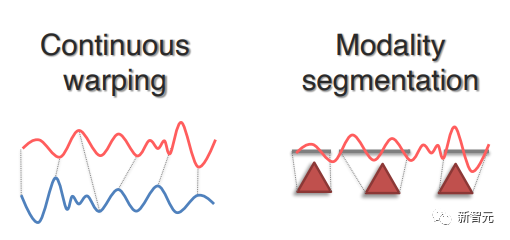
В некоторых недавних работах были предложены методы, основанные на непрерывной деформации и модальной сегментации, которые сегментируют непрерывные сигналы на дискретные элементы с соответствующей степенью детализации.
3. Контекстуализированные представления
Его цель — смоделировать все модальные связи и взаимодействия для изучения лучших представлений, что можно рассматривать как промежуточный шаг (потенциальный шаг) и использовать в ряде последующих задач, таких как распознавание речи, машинный перевод, описание мультимедиа и визуальный вопрос. отвечая, добиться лучшей производительности.
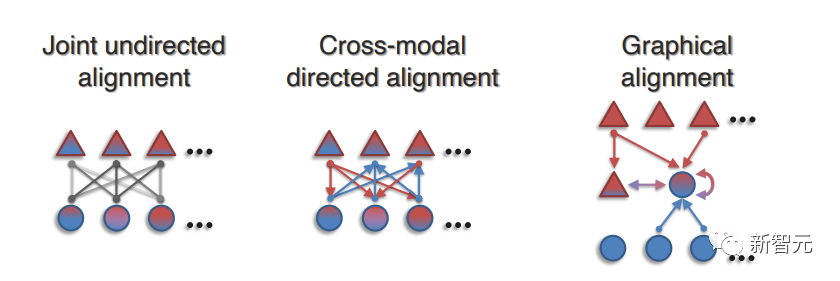
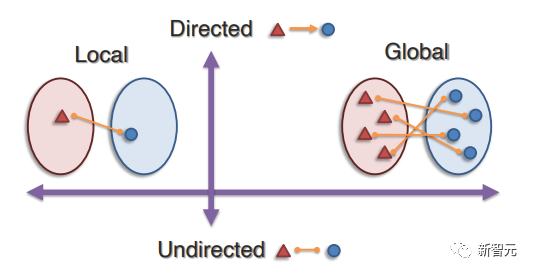
В этой статье работа над представлением контекста разделена на:
(1) Совместное ненаправленное выравнивание, которое может фиксировать ненаправленные соединения кросс-модальных пар, симметричных в любом направлении;
(2) Кросс-модальное направленное выравнивание, которое направленно соединяет элементы исходной модальности с целевой модальностью и может установить асимметричную модель связи;
(3) Графическое выравнивание, которое обобщает последовательные шаблоны в ненаправленном или направленном выравнивании по любой структуре графа между элементами.
Задача 3: Рассуждение
Рассуждение определяется как объединение знаний, часто посредством нескольких этапов рассуждения, с использованием мультимодальных механизмов и структур вопросов.
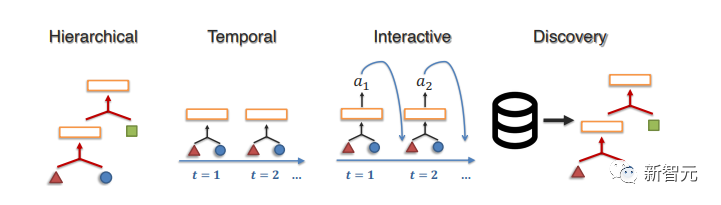
1. Моделирование структуры
Цель этого шага — фиксировать иерархические отношения композиции, обычно через структуры данных, которые параметризуют атомы, отношения и процессы рассуждения.
Обычно используемые структуры данных включают деревья, графы или нейронные модули, и мы представляем недавнюю работу по моделированию скрытых иерархий, временных структур и структур взаимодействия, а также обнаружению структур, когда базовая структура неизвестна.
2. Промежуточные понятия
Этот вопрос исследует, как можно параметризовать одну мультимодальную концепцию во время вывода.
Хотя в стандартных нейронных архитектурах промежуточные понятия часто представляют собой плотные векторные представления, существует также большое количество связанных работ по интерпретируемым картам внимания, дискретным символам и языку как промежуточным средствам рассуждения.
3. Парадигмы вывода
В этой части в основном рассматривается, как выводить все более абстрактные концепции из одного мультимодального доказательства.
Хотя достижения в слиянии локальных представлений (например, аддитивное, мультипликативное, тензорное, основанное на внимании и последовательное слияние) также в целом применимы и здесь, цель вывода состоит в том, чтобы улучшить процесс вывода посредством знаний предметной области о мультимодальных проблемах. эта статья в основном иллюстрирует новейшее направление явного моделирования процессов рассуждения с помощью логических и причинных операторов.
4. Внешние знания
Знания получаются в результате исследований, определяющих состав и структуру, где знания часто поступают из предметных знаний в наборах данных для конкретных задач.
В качестве альтернативы использованию знаний предметной области для предварительного определения композиционной структуры недавние исследовательские усилия также изучали автоматический вывод с использованием подходов, основанных на данных, таких как данные, широко доступные, но слабо контролируемые за пределами области непосредственной задачи.
Задача 4: Генерировать
Модель должна изучить процесс генерации посредством обобщения, перевода и создания, чтобы генерировать оригинальные модальности, отражающие кросс-модальное взаимодействие, структуру и связность. Эти три категории соответствуют методу классификации генерации текста в соответствии с модальностью ввода и вывода. модальность дифференциации в зависимости от изменений в информации.
1. Резюме
Целью обобщения является сжатие данных и создание резюме, которое представляет наиболее важную или релевантную информацию в исходном контенте. Помимо текстовых форматов, оно также включает резюме в изображениях, видео, аудио и других модальностях.
Хотя большинство методов направлены только на создание текстовых сводок из мультимодальных данных, в некоторых направлениях рассматривается создание сводных изображений в дополнение к сгенерированным текстовым сводкам.
2. Перевод
Цель перевода — сопоставить одну модальность с другой, сохраняя при этом семантические связи и информационное содержание. Например, создание описательных подписей к изображениям может помочь улучшить доступность визуального контента для слепых людей.
Мультимодальный перевод также создает новые трудности, такие как генерация многомерных структурированных данных и их оценка. Основные методы можно разделить на методы, основанные на примерах, и методы генеративной модели. Первые ограничиваются извлечением из обучающих экземпляров для выполнения различных задач. различные модели переводят между модальностями, но с гарантированной точностью перевода; последний может быть переведен в произвольные интерполированные примеры вне данных, но сталкивается с проблемами качества, разнообразия и оценки.
Несмотря на эти проблемы, в последнее время был достигнут прогресс в широкомасштабных моделях перевода текста в изображение, текста в видео, аудио в изображение, текста в речь, речи в жесты, речи в жесты, речи в жесты, речи в жесты. слушатель, язык-жест, генерация речи и музыки и т. д. создают впечатляюще высококачественный контент.
3. Создание
Целью создания является создание новых многомерных данных (которые могут охватывать текст, изображения, аудио, видео и другие параметры) из небольших исходных примеров или потенциальных условных переменных. Этот процесс условного декодирования чрезвычайно сложен и требует от модели. иметь:
(1) Условно: сохранить семантическое отображение исходного семени на ряд параллельных модальностей на большом расстоянии;
(2) Синхронизация: семантическая согласованность всех модальностей;
(3) Случайный: поймать множество возможных потомков в определенном состоянии;
(4) Автоматический возврат на возможное большое расстояние.
Задача 5: Трансфер (Перенос)
Его цель — передать знания между модальностями и их представлениями. В основном он исследует, как знания, полученные из второй модальности (например, предсказанные метки или представления), помогают модели, обученной на первой модальности.
Решение этой проблемы особенно важно, когда основная модальность имеет ограниченные ресурсы (например, отсутствие аннотированных данных, зашумленный ввод или ненадежные метки), поскольку передача информации вторичной модальности может привести к новому поведению, никогда не наблюдавшемуся в основной модальности.
1. Кросс-модальный трансфер
В большинстве случаев может быть проще собрать размеченные или неразмеченные данные для вторичной модальности и обучить надежные контролируемые или предварительно обученные модели, которые затем можно настроить или уточнить для последующих задач, включающих первичную модальность, тем самым интегрируя одномодальные модели. передача и точная настройка распространяются на кросс-модальные среды.
2. Мультимодальное совместное обучение
Мультимодальное совместное обучение направлено на перенос информации, полученной посредством субмодальности, на целевую задачу, включая основную модальность, путем разделения промежуточного пространства представления между двумя модальностями. Суть этих методов заключается в построении единой совместной модели. .
3. Модельная индукция
В отличие от совместного обучения, методы индукции модели разделяют одномодальные модели на первичные и вторичные режимы, но направлены на обобщение поведения обеих моделей.
Совместное обучение является примером индукции модели: при совместном обучении два алгоритма обучения обучаются отдельно для каждого представления данных, а затем прогнозы каждого алгоритма используются для псевдомаркировки новых немаркированных примеров для дополнения других. представления, то есть информация передается между несколькими представлениями посредством прогнозов модели, а не через общее пространство представления.
Задача 6: Количественная оценка
Целью количественной оценки является проведение более глубоких эмпирических и теоретических исследований мультимодальных моделей, чтобы получить представление и повысить их надежность, интерпретируемость и надежность в практических приложениях.
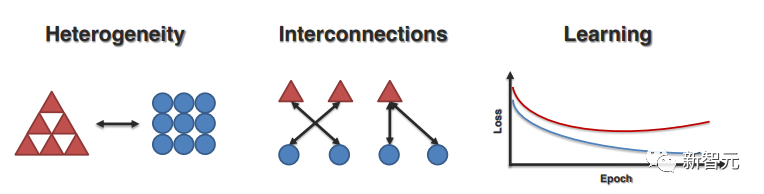
1. Размеры неоднородности
Эта часть посвящена пониманию общих аспектов неоднородности в мультимодальных исследованиях и того, как они впоследствии влияют на моделирование и обучение.
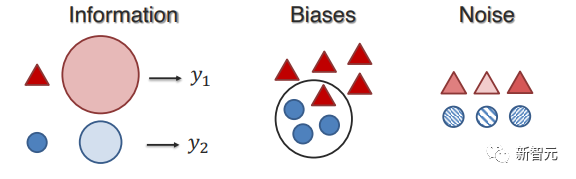
2. Взаимосвязь модальностей
Связи и взаимодействия между модальностями являются важными компонентами мультимодальных моделей, мотивирующими соответствующую работу по визуализации и пониманию природы модальных взаимосвязей в наборах данных и обученных моделях.
Исследователи разделяют недавнюю работу на следующие два аспекта количественной оценки:
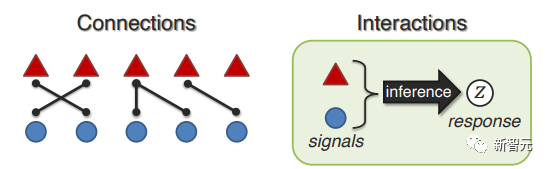
(1) Связь: как способы связаны между собой и имеют общие черты;
(2) Взаимодействие: как модальные элементы взаимодействуют в процессе рассуждения.
3. Мультимодальный процесс обучения
Последний вопрос в основном касается проблем обучения и оптимизации, с которыми сталкиваются модели при обучении на разнородных данных. В этой статье в основном представлены соответствующие работы с трех аспектов:
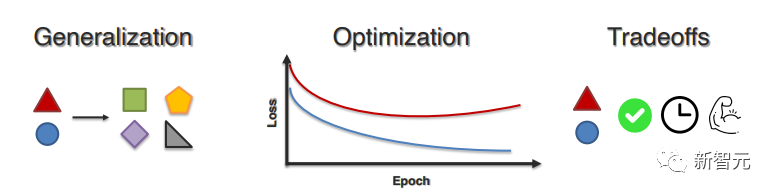
(1) Обобщение по модальностям и задачам;
(2) Лучшая оптимизация для достижения сбалансированного и эффективного обучения;
(3) Компромиссы между производительностью, надежностью и сложностью в реальных условиях.
Ссылки:
https://cmu-multicomp-lab.github.io/mmml-tutorial/icml2023/



Учебное пособие по Jetpack Compose для начинающих, базовые элементы управления и макет

Код js веб-страницы, фон частицы, код спецэффектов

【новый! Суперподробное】Полное руководство по свойствам компонентов Figma.

🎉Обязательно к прочтению новичкам: полное руководство по написанию мини-программ WeChat с использованием программного обеспечения Cursor.

[Забавный проект Docker] VoceChat — еще одно приложение для мгновенного чата (IM)! Может быть встроен в любую веб-страницу!

Как реализовать переход по странице в HTML (html переходит на указанную страницу)

Как решить проблему зависания и низкой скорости при установке зависимостей с помощью npm. Существуют ли доступные источники npm, которые могут решить эту проблему?

Серия From Zero to Fun: Uni-App WeChat Payment Practice WeChat авторизует вход в систему и украшает страницу заказа, создает интерфейс заказа и инициирует запрос заказа

Серия uni-app: uni.navigateЧтобы передать скачок значения

Апплет WeChat настраивает верхнюю панель навигации и адаптируется к различным моделям.

JS-время конвертации

Обеспечьте бесперебойную работу ChromeDriver 125: советы по решению проблемы chromedriver.exe не найдены

Поле комментария, щелчок мышью, специальные эффекты, js-код

Объект массива перемещения объекта JS

Как открыть разрешение на позиционирование апплета WeChat_Как использовать WeChat для определения местонахождения друзей

Я даю вам два набора из 18 простых в использовании фонов холста Power BI, так что вам больше не придется возиться с цветами!

Получить текущее время в js_Как динамически отображать дату и время в js

Вам необходимо изучить сочетания клавиш vsCode для форматирования и организации кода, чтобы вам больше не приходилось настраивать формат вручную.

У ChatGPT большое обновление. Всего за 45 минут пресс-конференция показывает, что OpenAI сделал еще один шаг вперед.

Copilot облачной разработки — упрощение разработки

Микросборка xChatGPT с низким кодом, создание апплета чат-бота с искусственным интеллектом за пять шагов

CUDA Out of Memory: идеальное решение проблемы нехватки памяти CUDA

Анализ кластеризации отдельных ячеек, который должен освоить каждый&MarkerгенетическийВизуализация

vLLM: мощный инструмент для ускорения вывода ИИ

CodeGeeX: мощный инструмент генерации кода искусственного интеллекта, который можно использовать бесплатно в дополнение к второму пилоту.

Машинное обучение Реальный бой LightGBM + настройка параметров случайного поиска: точность 96,67%

Бесшовная интеграция, мгновенный интеллект [1]: платформа больших моделей Dify-LLM, интеграция без кодирования и встраивание в сторонние системы, более 42 тысяч звезд, чтобы стать свидетелями эксклюзивных интеллектуальных решений.

LM Studio для создания локальных больших моделей

Как определить количество слоев и нейронов скрытых слоев нейронной сети?
