Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | Деформируемое внимание с большим ядром (D-LKA Attention), большое ядро свертки улучшает механизм внимания восприимчивых полей с различными функциями
💡💡💡Эта статья является результатом самостоятельного исследования и инновационного улучшения: Деформируемое большое внимание ядра (D-LKA) Внимание) эффективно сочетает SPPF для вторичных инноваций, а большие ядра свертки улучшают механизм внимания в восприимчивых полях различных функций.

1.SPP &SPPFпредставлять
YOLOv5 изначально принял структуру SPP и начал использовать SPPF после версии v6.0 (репозиторий). Основная цель — интеграция более масштабной (глобальной) информации. YOLOV8 использует SPPF Автор сравнивает SPP и SPPF, SPPF может достигать более высоких скоростей и меньшего количества FLOP, не влияя на mAP.
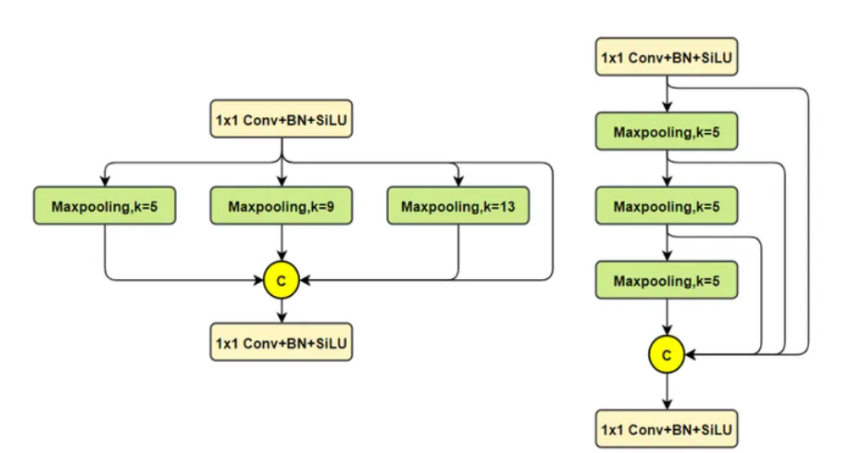
2. Введение в принципы улучшения
бумага:arxiv.org/pdf/2309.00121.pdf
Чтобы решить эти проблемы, мы представляем концепцию деформируемого большого внимания ядра (D-LKA Attention), упрощенного механизма внимания, который использует большие ядра свертки для полного понимания объемного контекста.
Этот механизм действует в рецептивном поле, аналогичном полю самовнимания, избегая при этом дополнительных вычислительных затрат. Кроме того, предлагаемый нами механизм внимания использует деформируемые свертки, позволяющие гибко искажать сетку выборки, позволяя модели соответствующим образом адаптироваться к различным шаблонам данных. Мы разработали 2D- и 3D-адаптацию D-LKA Attention, последняя из которых хорошо справляется с глубоким пониманием данных.
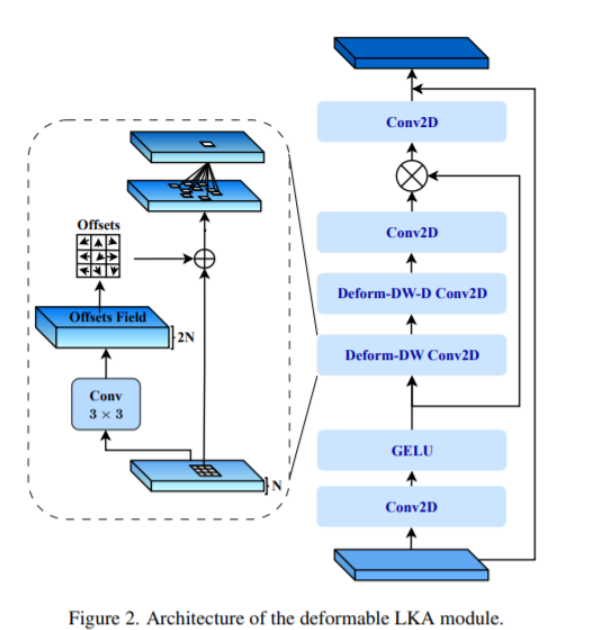
3. Принципиальная схема инноваций SPPF
Воляdeformable_LKAиSPPFЭффективное сочетание,вводить новшества
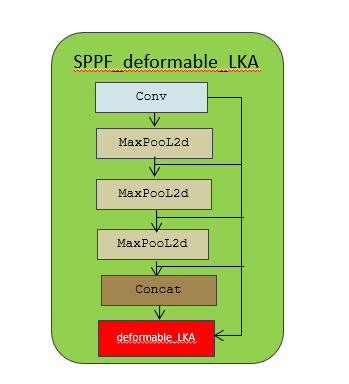
3.1 Инновация SPPF присоединяется к YOLOv5
3.1.1 SPPF_deformable_LKAприсоединитьсяmodels/sppf/SPPF_deformable_LKA.py
Основной исходный код:
class DeformConv_experimental(nn.Module):
def __init__(self, in_channels, groups, kernel_size=(3,3), padding=1, stride=1, dilation=1, bias=True):
super(DeformConv_experimental, self).__init__()
self.conv_channel_adjust = nn.Conv2d(in_channels=in_channels, out_channels=2 * kernel_size[0] * kernel_size[1], kernel_size=(1,1))
self.offset_net = nn.Conv2d(in_channels=2 * kernel_size[0] * kernel_size[1],
out_channels=2 * kernel_size[0] * kernel_size[1],
kernel_size=3,
padding=1,
stride=1,
groups=2 * kernel_size[0] * kernel_size[1],
bias=True)
self.deform_conv = torchvision.ops.DeformConv2d(in_channels=in_channels,
out_channels=in_channels,
kernel_size=kernel_size,
padding=padding,
groups=groups,
stride=stride,
dilation=dilation,
bias=False)
def forward(self, x):
x_chan = self.conv_channel_adjust(x)
offsets = self.offset_net(x_chan)
out = self.deform_conv(x, offsets)
return out
class deformable_LKA(nn.Module):
def __init__(self, dim):
super().__init__()
self.conv0 = DeformConv(dim, kernel_size=(5,5), padding=2, groups=dim)
self.conv_spatial = DeformConv(dim, kernel_size=(7,7), stride=1, padding=9, groups=dim, dilation=3)
self.conv1 = nn.Conv2d(dim, dim, 1)
def forward(self, x):
u = x.clone()
attn = self.conv0(x)
attn = self.conv_spatial(attn)
attn = self.conv1(attn)
return u * attnот CSDN AI, маленький монстр
https://blog.csdn.net/m0_63774211/category_12511737.html?spm=1001.2014.3001.5482

Power Query: автоматическое суммирование ежемесячных данных с обновлением одним щелчком мыши.
установка Ubuntu в среде npm

3 Бесплатные системы управления складом (WMS) .NET с открытым исходным кодом

Глубокое погружение в библиотеку Python Lassie: мощный инструмент для автоматизации извлечения метаданных
Объяснение прослушивателя серии Activiti7 последней версии 2023 года

API-интерфейс Jitu Express для электронных счетов-Express Bird [просто для понимания]

Каковы архитектуры микросервисов Java. Серверная часть плавающей области обслуживания

Описание трех режимов жизненного цикла службы внедрения зависимостей Asp.net Core.

Java реализует пользовательские аннотации для доступа к интерфейсу без проверки токена.

Серверная часть Unity добавляет поддержку .net 8. Я еще думал об этом два дня назад, и это сбылось.
Проект с открытым исходным кодом | Самый элегантный метод подписки на публичные аккаунты WeChat на данный момент
Разрешения роли пользователя Gitlab Гость, Репортер, Разработчик, Мастер, Владелец

Spring Security 6.x подробно объясняет механизм управления аутентификацией сеанса в этой статье.

[Основные знания ASP.NET] — Аутентификация и авторизация — Использование удостоверений для аутентификации.

Соединение JDBC с базой данных MySQL в jsp [легко понять]

[Уровень няни] Полный процесс развертывания проекта Python (веб-страницы Flask) в Docker.
6 способов чтения файлов свойств, рекомендуем собрать!
Графическое объяснение этапа строительства проекта IDEA 2021 Spring Cloud (базовая версия)

Подробное объяснение технологии междоменного запроса данных JSONP.

Учебное пособие по SpringBoot (14) | SpringBoot интегрирует Redis (наиболее полный во всей сети)
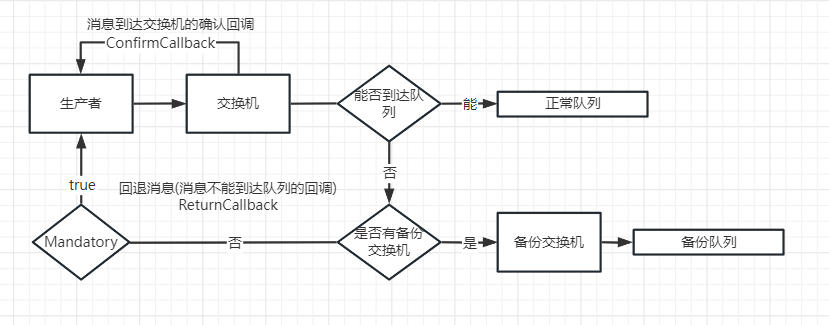
Подробное объяснение механизма подтверждения выпуска сообщений RabbitMQ.

На этот раз полностью поймите протокол ZooKeeper.
Реализуйте загрузку файлов с использованием минимального WEB API.

Демо1 Laravel5.2 — генерация и хранение URL-адресов
Spring boot интегрирует Kafka и реализует отправку и потребление информации (действительно при личном тестировании)
Мысли о решениях по внутренней реализации сортировки методом перетаскивания

Междоменный доступ к конфигурации nginx не может вступить в силу. Междоменный доступ к странице_Page

Как написать текстовый контент на php

PHP добавляет текстовый водяной знак или водяной знак изображения к изображениям – метод инкапсуляции