Единая архитектура и технология выбора портретных платформ
Функции портретной платформы аналогичны, и ее техническая архитектура также может абстрагировать унифицированную модель. В этом разделе в основном представлена общая техническая архитектура портретной платформы. Чтобы улучшить понимание читателями выбора технологий, в этом разделе также будут представлены планы выбора технологий нескольких интернет-компаний на портретных платформах.
Общая архитектура портретных платформ
Общая схема технической архитектуры портретной платформы показана на рисунке 2-13 и в основном включает в себя уровень данных, уровень хранения, уровень обслуживания и уровень приложений.
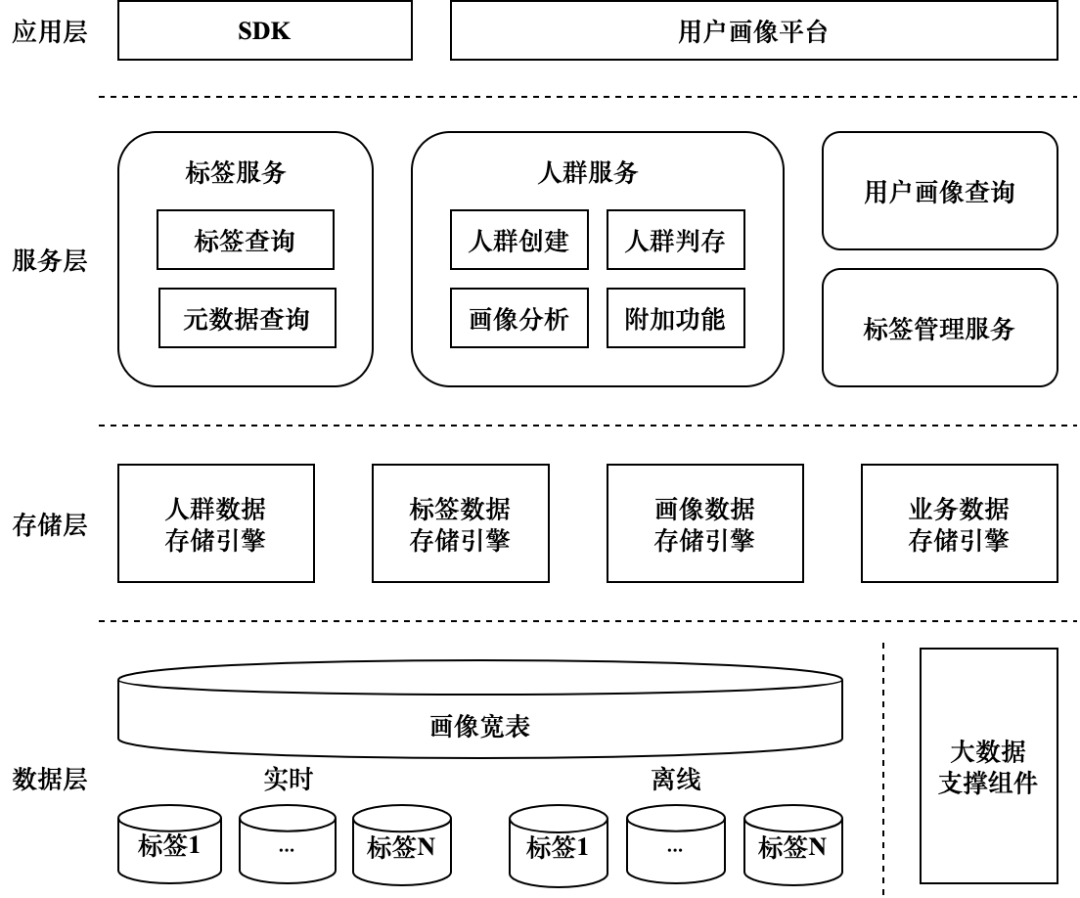
Уровень данных:Функциональная конструкция портретной платформы опирается на существующиебольшие данныекомпоненты,нравитьсябольшие данныехранилище、большие данныевычислить、большие планирование задач по данным и т. д. с помощью больших данныекомпоненты可以实现标签的生产、хранилище和维护。Источник данных тега — это данные самого низкого уровня, на которых основана портретная платформа.,Различные теги часто разбросаны по разным таблицам бизнес-библиотеки. Для удобства использования в бизнесе,Платформа портретной ориентации суммирует все теги в широкую портретную таблицу. Данные этикетки разделены на две категории: офлайн и в режиме реального времени.,Теги реального времени — это в основном теги, созданные на основе данных в реальном времени.,Офлайн-ярлыки рассчитываются и генерируются на основе офлайн-данных.,Метки майнинга, создаваемые алгоритмом, также относятся к категории автономных меток.
Уровень хранения:画像平台业务代码直接访问的都是хранилище层数据,В основном он содержит 4 типа хранения контента. Механизм хранения данных о толпе в основном используется для хранения данных о толпе.,Различные группы людей, созданные портретной платформой, требуют постоянного хранения.,Для облегчения последующего использования внешних сервисов. Механизм хранения данных тегов в основном используется для служб запроса тегов.,Для повышения производительности сервиса обычно используются высокопроизводительные кэшированные базы данных. Механизм хранения портретных данных предназначен для повышения скорости выбора толпы.,Производительность массового отбора, основанного непосредственно на базовой исходной таблице больших данных, низкая.,Для повышения продуктивности толпы необходимо использовать механизм хранения портретных данных. Механизм хранения бизнес-данных в основном хранит бизнес-данные.,нравиться人群基本信息、Условия отбора толпы、Отметьте основную информацию、Информация о выводе этикетки и т. д.
Сервисный уровень:Уровень обслуживания — это уровень реализации основных функций портретной платформы.。Служба тегов в основном используется для реализации службы запроса тегов и службы запроса метаданных.,Он опирается на механизм хранения данных тегов и механизм хранения бизнес-данных уровня хранения. Крауд-сервисы в основном включают в себя услуги по созданию толпы и портретному анализу.,Создание толпы поддерживает различные методы создания.,Служба анализа профилирования поддерживает несколько сценариев анализа профилирования.,Крауд-сервисы также включают в себя идентификацию толпы и дополнительные функциональные модули толпы. Крауд-сервисы в основном полагаются на механизмы хранения данных толпы и механизмы хранения портретных данных. Служба управления тегами обеспечивает функции добавления, удаления, изменения и запроса тегов.,Он опирается на механизм хранения бизнес-данных и некоторые компоненты поддержки больших данных. Служба запроса портретов пользователей в основном предоставляет функцию запроса портретов отдельных пользователей.,Его данные поступают из механизма хранения данных тегов.
Прикладной уровень:Уровень приложения — это уровень представления внешних сервисов портретной платформы.。SDKВ основном предоставляет внешние сервисные интерфейсы,Например, интерфейс запроса тегов, интерфейс запроса метаданных, интерфейс создания толпы, интерфейс оценки и хранения и т. д.,Третьи стороны используют сервисы портретной платформы и получают портретные данные с помощью SDK. Портретная платформа отображает функции платформы через визуальные страницы.,Пользователи могут использовать различные функции портретной платформы посредством простой настройки.,Повышена эффективность использования портретных данных.
Примеры выбора технологии платформы визуализации
В предыдущем разделе была представлена общая техническая архитектура портретной платформы. В этом разделе будет представлен конкретный план технического выбора каждого модуля. В главе 7 этой книги будет представлен практический пример построения портретной платформы от 0 до 1. Чтобы гарантировать, что читатели смогут успешно воспроизводить содержание книги, все технологии, выбранные в этой книге, используют технологии с открытым исходным кодом или облачные сервисы. Принимая во внимание тенденцию развития отраслевых портретных платформ и популярность технологии, выбор конкретной технологии показан на рисунке 2-14. В этом разделе представлено только общее описание связанных технологий. Подробные сведения о характеристиках и конфигурации каждой технологии см. пожалуйста, обратитесь к главе 2-14.
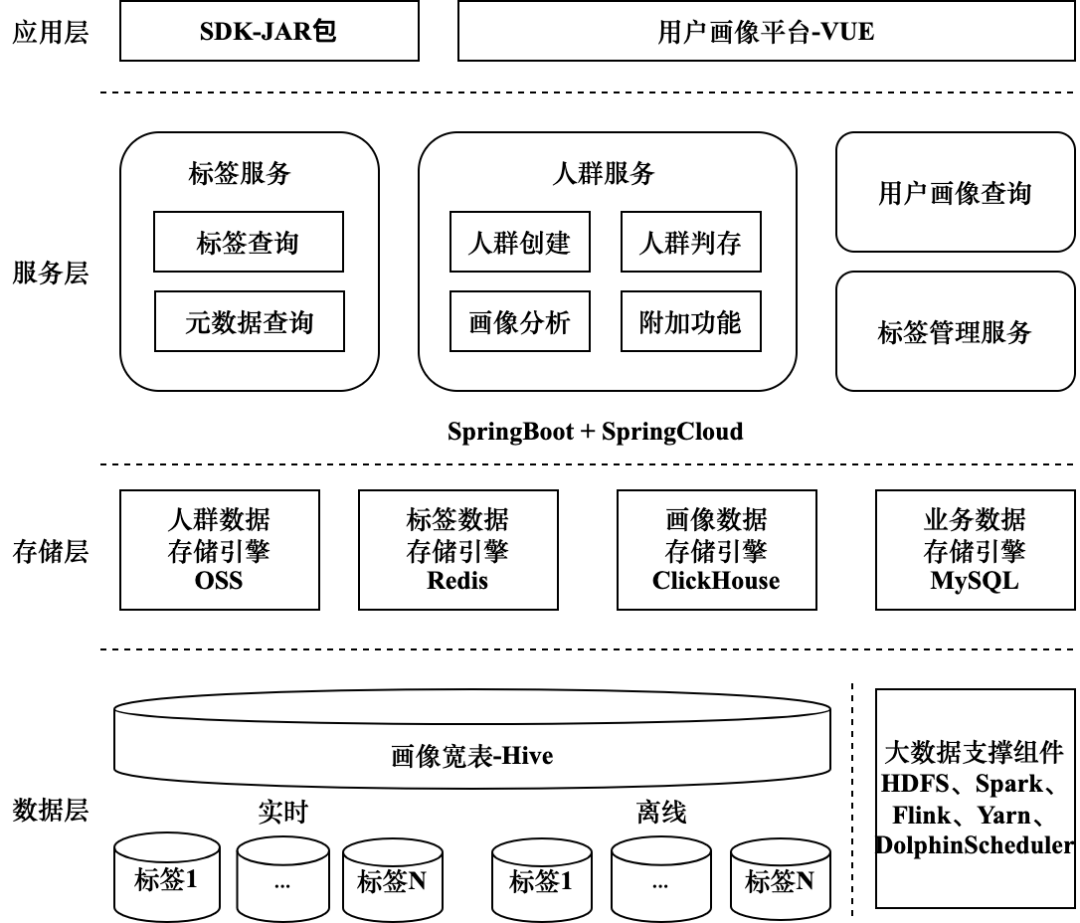
Уровень данных:所有底层数据хранилище在基于HiveВ хранилище данных построено,Все они существуют в виде таблиц Hive. HDFS обеспечивает большие возможности распределенного хранения файлов данных; Yarn используется для планирования ресурсов, создания этикеток, обработки данных в реальном времени и других задач, все из которых основаны на больших объемах данных; Планирование ресурсов данных; DolphinScheduler в основном используется для планирования задач и в основном отвечает за импорт толп в таблицы Hive, регулярное обновление меток, запланированный вывод толп и т. д. Работа по планированию данных; Spark как механизм расчета данных в автономном режиме в основном используется для расчета некоторых автономных задач; Flink в основном используется для обработки данных в реальном времени, например, для использования данных в реальном времени для анализа поведения пользователей. Вышеуказанные технологии обеспечивают стабильный вывод базовых данных портретной платформы.
Уровень хранения:В целях повышения скорости досмотра толпы,Представлен расчетный механизм ClickHouse,Его производительность превосходна в сценариях OLAP.,Он больше подходит для реализации функций выбора и анализа толпы портретной платформы с помощью кэша Redis, он может удовлетворить высокие требования к параллелизму службы запросов тегов и службы оценки толпы, чтобы облегчить внешний вывод данных о толпе;,生成的人群会хранилище在阿里云OSS(Object Storage Сервис, служба хранения объектов), данные толпы также будут храниться в таблицах Hive для резервного копирования; бизнес-данные на платформе хранятся в базе данных MySQL, включая информацию о конфигурации толпы, метаинформацию тегов, данные результатов портретного анализа и т. д. На основе этих механизмов хранения можно создать высокодоступные службы профилирования.
Сервисный уровень:服务层主要поставлять用于构建画像平台页面的接口服务以及支持分布式高并发场景下的微服务。В этой книге используютсяSpringBootСоздание проекта сервера портретной платформы,Предоставление интерфейсных сервисов в стиле RESTful для внешнего интерфейса платформы. Использование Spring Cloud для создания набора микросервисов;,Он может удовлетворить потребности сервисов с высоким уровнем параллелизма, таких как запрос и оценка тегов.
Прикладной уровень:Можно использовать передовые исследования и разработкиVueСоздавайте интерфейсные проекты и разрабатывайте функции платформы визуального портрета.;平台对外поставлять的服务均可以封装到SDKсередина,Эта книга в основном основана на языке Java.,Поэтому SDK в основном использует JAR (Java Архив, Java-архив) существует.
Вышеупомянутый план выбора технологии является осуществимым. Читатели также могут выбирать различные технические решения или языки реализации в соответствии со своими бизнес-характеристиками, но общая архитектура и логика бизнес-реализации в основном аналогичны.
Выбор технологии функции отраслевой визуализации
В этом разделе в основном представлены отраслевые решения по техническому выбору функций, связанных с портретной съемкой. В настоящее время построение уровня данных в отрасли опирается на инструменты и компоненты больших данных в системе Hadoop. Разница в уровне обслуживания в основном заключается на уровне языковой структуры, и окончательный метод предоставления услуг тот же. Выбор технологии, упомянутый в этом разделе, в основном сосредоточен на механизме профилирования и технических решениях, связанных с анализом профилирования, задействованных на уровне хранения, что соответствует функциям массового выбора и анализа профилирования на функциональном уровне.
Alibaba Damopan — это рекламная платформа Alimama, которую можно использовать для отбора толпы и последующей рекламы. Решение Alibaba по реализации в основном основано на собственных облачных сервисах MaxComputer и AnalyticDB. MaxComputer в основном используется для автономных вычислений и майнинга, а AnalyticDB используется для анализа больших данных в реальном времени.
Планы реализации Meituan и Didi относительно схожи. Они в основном используют механизмы Elasticsearch и Spark для массового отбора. Elasticsearch может быстро находить толпы с помощью относительно простой логики отбора. При использовании сложной логики отбора его можно напрямую понизить до механизма Spark. Получите данные из базовой таблицы Hive.
Apache Doris произошел от Baidu и широко используется в Baidu. Внутренний отбор и анализ портретов пользователей Baidu в основном реализован на основе Doris. Чжиху также полагается на Дорис при выборе портретов и использует Spark в качестве вычислительной машины для выбора толпы в некоторых особых бизнес-сценариях.
ClickHouse стал более популярным в последние годы. Toutiao DMP и CDP реализуют массовый выбор через ClickHouse и используют ClickHouse BitMap для ускорения массового выбора; Kuaishou DMP также использует ClickHouse BitMap для реализации связанных функций в сценариях массового выбора.
Наконец, давайте поговорим о коммерческих платформах анализа данных. И Shence, и GrowingIO были основаны в 2015 году. Однако из-за разных технических стилей команд-основателей их выбор технологий совершенно разный. Shence в основном реализован на основе Impala и Kudu и сделал множество оптимизаций на Impala. GrowingIO реализован с помощью Elasticsearch и HBase, а некоторые функции рассчитываются с использованием движка Spark;
В выборе технологии нет преимуществ или недостатков. Главное – соответствовать характеристикам вашего бизнеса. С помощью этого раздела читатели смогут получить общее представление о выборе технологий в отрасли и выбрать наиболее подходящее для них техническое решение в процессе построения портретной платформы.
Совет: Вышеуказанные технические подборки взяты из общедоступных материалов в Интернете. Если есть ошибки, вы можете их покритиковать и исправить.

Эта статья взята из книги «Портреты пользователей: построение платформ и бизнес-практика». При перепечатке указывайте источник.




Учебное пособие по Jetpack Compose для начинающих, базовые элементы управления и макет

Код js веб-страницы, фон частицы, код спецэффектов

【новый! Суперподробное】Полное руководство по свойствам компонентов Figma.

🎉Обязательно к прочтению новичкам: полное руководство по написанию мини-программ WeChat с использованием программного обеспечения Cursor.

[Забавный проект Docker] VoceChat — еще одно приложение для мгновенного чата (IM)! Может быть встроен в любую веб-страницу!

Как реализовать переход по странице в HTML (html переходит на указанную страницу)

Как решить проблему зависания и низкой скорости при установке зависимостей с помощью npm. Существуют ли доступные источники npm, которые могут решить эту проблему?

Серия From Zero to Fun: Uni-App WeChat Payment Practice WeChat авторизует вход в систему и украшает страницу заказа, создает интерфейс заказа и инициирует запрос заказа

Серия uni-app: uni.navigateЧтобы передать скачок значения

Апплет WeChat настраивает верхнюю панель навигации и адаптируется к различным моделям.

JS-время конвертации

Обеспечьте бесперебойную работу ChromeDriver 125: советы по решению проблемы chromedriver.exe не найдены

Поле комментария, щелчок мышью, специальные эффекты, js-код

Объект массива перемещения объекта JS

Как открыть разрешение на позиционирование апплета WeChat_Как использовать WeChat для определения местонахождения друзей

Я даю вам два набора из 18 простых в использовании фонов холста Power BI, так что вам больше не придется возиться с цветами!

Получить текущее время в js_Как динамически отображать дату и время в js

Вам необходимо изучить сочетания клавиш vsCode для форматирования и организации кода, чтобы вам больше не приходилось настраивать формат вручную.

У ChatGPT большое обновление. Всего за 45 минут пресс-конференция показывает, что OpenAI сделал еще один шаг вперед.

Copilot облачной разработки — упрощение разработки

Микросборка xChatGPT с низким кодом, создание апплета чат-бота с искусственным интеллектом за пять шагов

CUDA Out of Memory: идеальное решение проблемы нехватки памяти CUDA

Анализ кластеризации отдельных ячеек, который должен освоить каждый&MarkerгенетическийВизуализация

vLLM: мощный инструмент для ускорения вывода ИИ

CodeGeeX: мощный инструмент генерации кода искусственного интеллекта, который можно использовать бесплатно в дополнение к второму пилоту.

Машинное обучение Реальный бой LightGBM + настройка параметров случайного поиска: точность 96,67%

Бесшовная интеграция, мгновенный интеллект [1]: платформа больших моделей Dify-LLM, интеграция без кодирования и встраивание в сторонние системы, более 42 тысяч звезд, чтобы стать свидетелями эксклюзивных интеллектуальных решений.

LM Studio для создания локальных больших моделей

Как определить количество слоев и нейронов скрытых слоев нейронной сети?
