eBPF, технология, которая подрывает мониторинг контейнеров
Привет, ребята, я Луга. Сегодня мы поговорим о теме «мониторинга», в основном о мониторинге контейнеров в облачной экосистеме. Здесь мы в основном обсуждаем «технический» уровень.
С момента разработки технологий, связанных с контейнерами, таких как Docker и Kubernetes, почти десять лет назад, контейнеры изменили всеобщее понимание управления и контроля ресурсов. Контейнеры основаны на общем базовом ядре ОС и изолируют среды выполнения приложений друг от друга. При этом он обычно измеряется в мегабайтах, использует гораздо меньше ресурсов, чем виртуальная машина, и запускается быстрее. Кроме того, на основе контейнеров можно добиться более плотной упаковки на том же оборудовании, не затрачивая слишком много усилий и накладных расходов, тем самым достигая эффекта «снижения затрат и повышения эффективности».
Действительно, контейнерная технология имеет множество преимуществ. Однако одним из ее самых больших недостатков является то, что трудно «мониторить» эффективность всей ее системы, особенно «эфемерную природу» контейнеров в сочетании с их абстракцией от серверов, на которых размещены. их, что затрудняет эффективный и действенный сбор данных мониторинга из контейнеров.
К счастью, по мере развития технологий и появления новых технологий появилась многообещающая новая технология, которая может обеспечить решение проблемы мониторинга контейнеров. Она называется eBPF, и на основе этой технологии мы вносим революционные инновации в традиционные идеи и методы мониторинга рабочих нагрузок Docker и Kubernetes.
На основе традиционной модели
В традиционной концепции разработчики, персонал по эксплуатации и техническому обслуживанию или инженеры DevOps сталкиваются со следующими общими проблемами, если они хотят иметь возможность эффективно контролировать контейнеры «всесторонним способом»:
1. В зависимости от различных бизнес-сценариев определенное приложение может содержать десятки или даже сотни отдельных развертываний контейнеров. При этом каждый контейнер необходимо отслеживать индивидуально, что увеличивает стоимость усилий, необходимых для развертывания агентов мониторинга и сбора необходимых данных из каждого контейнера.
2. В зависимости от статуса жизненного цикла контейнера, когда контейнер закрывается по разным причинам, данные, хранящиеся в контейнере, исчезают, и обычно невозможно точно предсказать, когда контейнер может быть закрыт. Поэтому мы не можем регулярно получать данные мониторинга. Это не соответствует нашему первоначальному намерению собирать данные из каждого контейнера в режиме реального времени.
3. Кроме того, поскольку контейнеры абстрагированы от операционной системы сервера, на котором они размещены, и основаны на разных средах, их может потребоваться перемещать по разным узлам, поэтому метод мониторинга на основе хоста часто оказывается менее эффективным, чем ожидалось. . Это делает невозможным простой запуск агента на каждом сервере и использование его для мониторинга всех контейнеров.
На самом деле, по сути, на рынке существует множество вариантов решения вышеописанных задач, но наиболее популярной и распространенной стратегией является использование так называемого паттерна Sidecar для развертывания агентов мониторинга контейнеров. В дополнительном режиме агенты мониторинга могут работать в специальных контейнерах, которые работают рядом с контейнерами, которые они отслеживают. Этот подход более эффективен, чем попытка развернуть агент мониторинга на хосте. Это также устраняет необходимость предоставлять данные мониторинга непосредственно из логики приложения, что требует сложных изменений в исходном коде.
В модели сайдкара инструменты наблюдения или безопасности внедряются в каждый под в качестве контейнера сайдкара. Следует отметить, что Sidecar также является контейнером. Все контейнеры в Pod могут совместно использовать сетевое пространство имен и информацию о томе, поэтому Sidecar может видеть, что происходит в других контейнерах в Pod. Чтобы развернуть Sidecar в поде, его необходимо настроить в YAML. Эту операцию можно выполнить вручную или автоматически. Конечно, определения дополнительных компонентов можно внедрить в YAML приложения для автоматизации развертывания.
Однако модель на основе коляски имеет неотъемлемый недостаток: чувствительность к ресурсам, то есть она не может использовать ресурсы полностью и эффективно. Дополнительный контейнер должен быть развернут рядом с каждым контейнером, в котором размещается фактическая рабочая нагрузка, а это означает, что в реальной производственной среде нам придется запускать больше контейнеров. Поскольку все эти дополнительные контейнеры требуют ресурсов ЦП и памяти, они резервируют меньше ресурсов для кластера контейнеров, который мы создаем.
Кроме того, еще одним недостатком модели Sidecar является «соответствие конфигурации». Если Sidecar настроен неправильно, он не сможет нормально работать в Pod. Это еще одна уязвимость сайдкара. Если злоумышленнику удастся запустить под, избежав внедрения сайдкара, он не сможет видеть, что происходит в поде.
На основе модели eBPF
eBPF позволяет решить эту проблему, отслеживая каждый контейнер без потребления большого количества ресурсов. eBPF обеспечивает программируемость ядра Linux. Благодаря своей безопасности, гибкости и невторжению в приложения он привнес множество креативных приложений в облачные сети, безопасность и наблюдаемость.
Представленный в 2015 году eBPF — это функция Linux, которая позволяет запускать программы непосредственно в ядре Linux, а не в «пользовательском пространстве», где нет прямого доступа к ресурсам ядра.
eBPF является производным от BPF и, по сути, представляет собой эффективный и гибкий компонент виртуальной машины виртуального класса в ядре, который безопасно выполняет байт-код во многих точках перехвата ядра. Первоначальной целью BPF была эффективная фильтрация сетевых пакетов. После редизайна eBPF больше не ограничивается стеком сетевых протоколов. Он стал подсистемой верхнего уровня ядра и превратился в общий механизм выполнения. Разработчики могут разрабатывать инструменты анализа производительности, программно-определяемые сети, безопасность и многие другие сценарии на основе eBPF.
Принципы архитектуры eBPF
В целом eBPF разделен на две части: программа User Space (пространство пользователя) и программа Kernel Space (ядро):
1. Программа User Space отвечает за загрузку байт-кода BPF в ядро. При необходимости она также будет отвечать за чтение статистики или сведений о событиях, возвращаемых Kernel Space;
2. Байт-код BPF в пространстве ядра отвечает за выполнение определенных событий в пространстве ядра. При необходимости результаты выполнения также будут отправлены в пространство пользователя через карты или события perf-event.
Программа User Space и программа байт-кода BPF в пространстве ядра могут использовать структуру карты для достижения двусторонней связи, что обеспечивает более гибкое управление программой байт-кода BPF, работающей в пространстве ядра.
Что касается архитектурной ссылки eBPF, как показано на рисунке ниже:
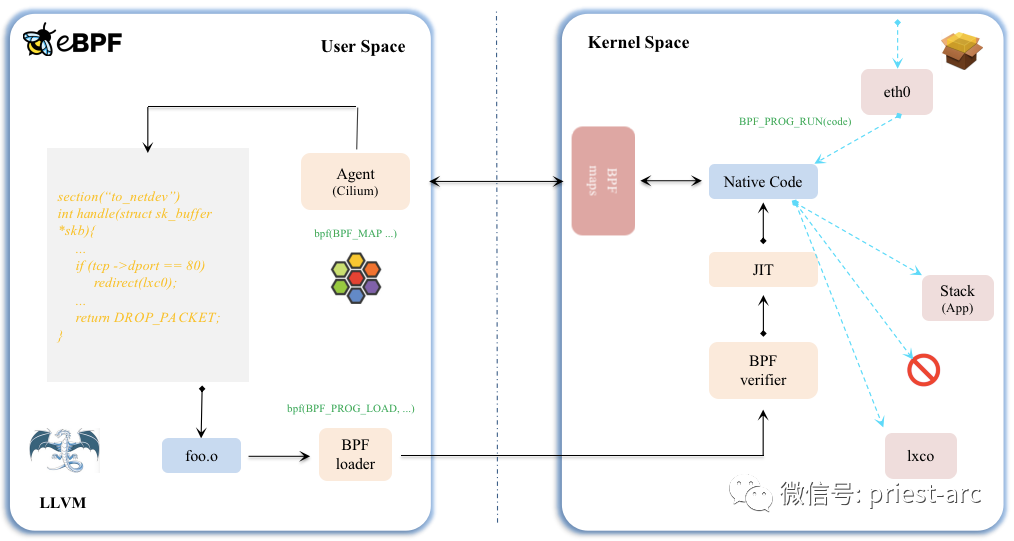
Основываясь на приведенной выше схеме архитектуры, мы видим, что весь принцип работы включает в себя следующее:
1. Программа eBPF управляется событиями и привязана к пути кода. Путь кода содержит определенные триггеры (называемые перехватчиками), которые при передаче выполняют любые подключенные программы eBPF. Некоторые примеры перехватчиков включают сетевые события, системные вызовы, записи функций и точки трассировки ядра.
2. При срабатывании код сначала компилируется в байт-код BPF. В свою очередь, байт-код проверяется перед запуском, чтобы гарантировать отсутствие циклов. Этот шаг предотвращает случайное или намеренное повреждение программами ядра Linux.
3. После того, как Hook запускает программу, она выполняет вызов Helper, предопределенный ядром. Обычно эти вызовы в первую очередь снабжают eBPF различными функциями доступа к функциям ядра.
eBPF изначально использовался как способ улучшить наблюдаемость и безопасность при фильтрации сетевых пакетов. Однако со временем это стало способом сделать реализации пользовательского кода более безопасными, удобными и производительными. Поскольку программы eBPF выполняются в ядре, они, как правило, потребляют меньше ресурсов, и более того, они могут получить доступ к данным, созданным любым процессом, запущенным на сервере, на котором они работают.
Основные преимущества eBPF
По сути, преимущество eBPF отражено в двух уровнях «наблюдения» и «безопасности», которые в основном используются для «отслеживания» процесса пользовательского пространства. Исходя из вышеизложенного, его преимущества в основном заключаются в следующем:
1. Высокая производительность
eBPF может переместить обработку пакетов из пространства ядра в пространство пользователя. Аналогично, eBPF — это JIT-компилятор. После компиляции байт-кода будет вызываться eBPF вместо выполнения новой интерпретации байт-кода для каждого метода. Благодаря этому механизму эффективность значительно повышается.
2. Программируемость
Использование eBPF помогает расширить возможности вашей среды без добавления дополнительных уровней. Кроме того, поскольку код выполняется непосредственно в ядре, данные могут сохраняться между событиями eBPF, а не сбрасываться, как в других трекерах.
3. Безопасность
Программа фактически находится в песочнице, что означает, что исходный код ядра остается защищенным и неизмененным. Этап проверки программ eBPF гарантирует, что ресурсы не блокируются программами, выполняющими бесконечные циклы.
4. Низкая инвазивность
Создание кода для функций ядра Hook требует меньше усилий, чем создание и поддержка модулей ядра. При использовании в качестве отладчика eBPF не требует остановки программы для наблюдения за ее состоянием.
Вышеупомянутое является основными преимуществами. Конечно, помимо вышеперечисленного, есть и другие преимущества: например, единая, мощная и доступная структура процесса отслеживания и т. д.
Сценарии применения eBPF
Одной из сильных сторон eBPF является его низкая интрузивность, что означает, что программа может работать в ядре без изменений, что позволяет ей наблюдать за тем, что происходит во всех контейнерах и подах, не изменяя нигде YAML. Нет необходимости добавлять скрипты в файл. приложение. Это одна из причин, почему появляется много новых проектов на основе eBPF и почему эта технология интересна.
eBPF уже завоевал широкое внимание и признание в облачной экосистеме. Исходя из этого, если используется технология eBPF, сценарии ее применения в основном включают следующее:
1. Наблюдаемость на уровне ядра
В этом сценарии eBPF может включаться быстрее и точнее, без влияния на производительность, вызванного переключением контекста. Кроме того, программа eBPF основана на событиях, поэтому нет никаких конкретных триггеров, никаких дополнительных событий выполняться не будет;
2. Традиционный мониторинг неадекватен
В распределенных и контейнерных средах eBPF может в полной мере реализовать возможности «мониторинга», особенно в некоторых сценариях визуализации процессов. eBPF имеет доступ к информации о процессах и программах, запущенных в этих процессах, а также к информации о сетевом трафике. Если мы объединим эту информацию и интегрируем ее, мы получим такую информацию: мы сможем увидеть, какой именно процесс, на каком узле, в каком поде, в каком пространстве имен и какой исполняемый файл выполняется, какое конкретное сетевое соединение обрабатывается и т. д. . В конце концов, в этих средах eBPF может закрыть пробелы в видимости и обеспечить видимость HTTP-трафика.
Следовательно, исходя из вышесказанного, если вы хотите отслеживать контейнеры, то вы можете написать программу eBPF, которая будет перехватывать процессы, относящиеся к каждому контейнеру, и собирать данные мониторинга. Результатом является решение для мониторинга, которое требует меньше ресурсов, чем традиционные контейнеры с коляской.
В то же время нет необходимости идти на компромисс в отношении объема данных, собираемых для целей мониторинга. Практически вся необходимая информация о состоянии и производительности каждого контейнера доступна через ядро.
Даже развертывание и управление становятся проще благодаря подходу мониторинга на основе eBPF. Вместо того, чтобы развертывать и организовывать кучу дополнительных контейнеров, нам нужно всего лишь запустить программу eBPF на каждом узле в кластере K8s. Вы можете спросить: если eBPF — отличное решение для мониторинга контейнеров, почему не все его используют?
«Откуда вы знаете, что другие не используют ее?» Здесь задействовано множество факторов, возможно, из-за зрелости технологии, может быть, из-за лени людей, но это не может предотвратить внедрение новых технологий и внедрение новых технологий. Вероятно, большинство существующих инструментов мониторинга контейнеров основаны на шаблоне Sidecar, а не на использовании eBPF. Но это явление постепенно меняется. Такие инструменты, как Cilium, уже используют eBPF для повышения эффективности и прозрачности. Многие поставщики средств наблюдения, такие как VMware, Splunk и New Relic и многие другие, также изучают потенциал eBPF для инкапсулированной интеграции.
Поэтому, если вы чувствуете, что традиционные методы мониторинга контейнеров неэффективны и слишком неэффективны, особенно с точки зрения снижения затрат и повышения эффективности. Эта стратегия потребляет наши приложения или ресурсы и ею трудно управлять, возможно, вы захотите попробовать eBPF. принесу вам другой сюрприз~
Adiós !



Учебное пособие по Jetpack Compose для начинающих, базовые элементы управления и макет

Код js веб-страницы, фон частицы, код спецэффектов

【новый! Суперподробное】Полное руководство по свойствам компонентов Figma.

🎉Обязательно к прочтению новичкам: полное руководство по написанию мини-программ WeChat с использованием программного обеспечения Cursor.

[Забавный проект Docker] VoceChat — еще одно приложение для мгновенного чата (IM)! Может быть встроен в любую веб-страницу!

Как реализовать переход по странице в HTML (html переходит на указанную страницу)

Как решить проблему зависания и низкой скорости при установке зависимостей с помощью npm. Существуют ли доступные источники npm, которые могут решить эту проблему?

Серия From Zero to Fun: Uni-App WeChat Payment Practice WeChat авторизует вход в систему и украшает страницу заказа, создает интерфейс заказа и инициирует запрос заказа

Серия uni-app: uni.navigateЧтобы передать скачок значения

Апплет WeChat настраивает верхнюю панель навигации и адаптируется к различным моделям.

JS-время конвертации

Обеспечьте бесперебойную работу ChromeDriver 125: советы по решению проблемы chromedriver.exe не найдены

Поле комментария, щелчок мышью, специальные эффекты, js-код

Объект массива перемещения объекта JS

Как открыть разрешение на позиционирование апплета WeChat_Как использовать WeChat для определения местонахождения друзей

Я даю вам два набора из 18 простых в использовании фонов холста Power BI, так что вам больше не придется возиться с цветами!

Получить текущее время в js_Как динамически отображать дату и время в js

Вам необходимо изучить сочетания клавиш vsCode для форматирования и организации кода, чтобы вам больше не приходилось настраивать формат вручную.

У ChatGPT большое обновление. Всего за 45 минут пресс-конференция показывает, что OpenAI сделал еще один шаг вперед.

Copilot облачной разработки — упрощение разработки

Микросборка xChatGPT с низким кодом, создание апплета чат-бота с искусственным интеллектом за пять шагов

CUDA Out of Memory: идеальное решение проблемы нехватки памяти CUDA

Анализ кластеризации отдельных ячеек, который должен освоить каждый&MarkerгенетическийВизуализация

vLLM: мощный инструмент для ускорения вывода ИИ

CodeGeeX: мощный инструмент генерации кода искусственного интеллекта, который можно использовать бесплатно в дополнение к второму пилоту.

Машинное обучение Реальный бой LightGBM + настройка параметров случайного поиска: точность 96,67%

Бесшовная интеграция, мгновенный интеллект [1]: платформа больших моделей Dify-LLM, интеграция без кодирования и встраивание в сторонние системы, более 42 тысяч звезд, чтобы стать свидетелями эксклюзивных интеллектуальных решений.

LM Studio для создания локальных больших моделей

Как определить количество слоев и нейронов скрытых слоев нейронной сети?
