Двадцать строк кода! Я использовал Spark для реализации алгоритма рекомендации фильмов.
Предисловие
давным-давно,Кто-то спросил меня, как его сделатьxxСистемные решения, основанные на технологии больших данных。В то время по этому вопросу,Это действительно ставит меня в тупик,Потому что в то время я знал только одногосовместная фильтрация,Другие не были изучены слишком глубоко.
Недавно кто-то задал мне этот вопрос в личном сообщении. Итак, я воспользовался этой возможностью, чтобы записать весь процесс построения системы рекомендаций с нуля, будучи новичком.
Алгоритм рекомендаций
Поискал некоторую информацию в Интернете,Откройте для себя рекомендации «Алгоритм», и их много.,Напримерсовместная фильтрация(Collaborative Фильтрация), фильтрация контента (Content-Based фильтрация), рекомендации на основе модели (Model-Based Рекомендации), гибридная система рекомендаций (Hybrid Recommendation системы) и рекомендации, основанные на обучении с подкреплением.
В итоге я выбрал совместную алгоритм фильтрации, причина в том, что вопрос требует использования технологии больших данных, а Spark интегрирует современные фильтрация, а Spark может лучше связываться с другими технологиями больших данных, поэтому в конечном итоге он основан на совместной технологии Spark. фильтрация для реализации системы рекомендаций。
совместная фильтрация
Давайте сначала разберемся, что такое совместная фильтрацияалгоритм。совместная фильтрацияалгоритмизпринципНа основе поведения и предпочтений пользователей даются рекомендации путем анализа данных взаимодействия между пользователями и предметами (например, рейтингов, записей о покупках и т. д.).。Его основная идея заключается в“Похожие пользователи любят похожие товары”。
совместная Существует два основных типа фильтрации: Пользовательская совместная фильтрация. фильтрацияи предметысовместная фильтрация。
пользовательсовместная фильтрация
на основепользовательизсовместная фильтрацияалгоритм(user-based collaboratIve фильтрация): рекомендовать пользователю продукты, которые нравятся другим пользователям со схожими интересами, сортировать прогнозируемые оценки товаров, купленных всеми похожими пользователями, по пользователю u и рекомендовать пользователю u товары-кандидаты из TopN.
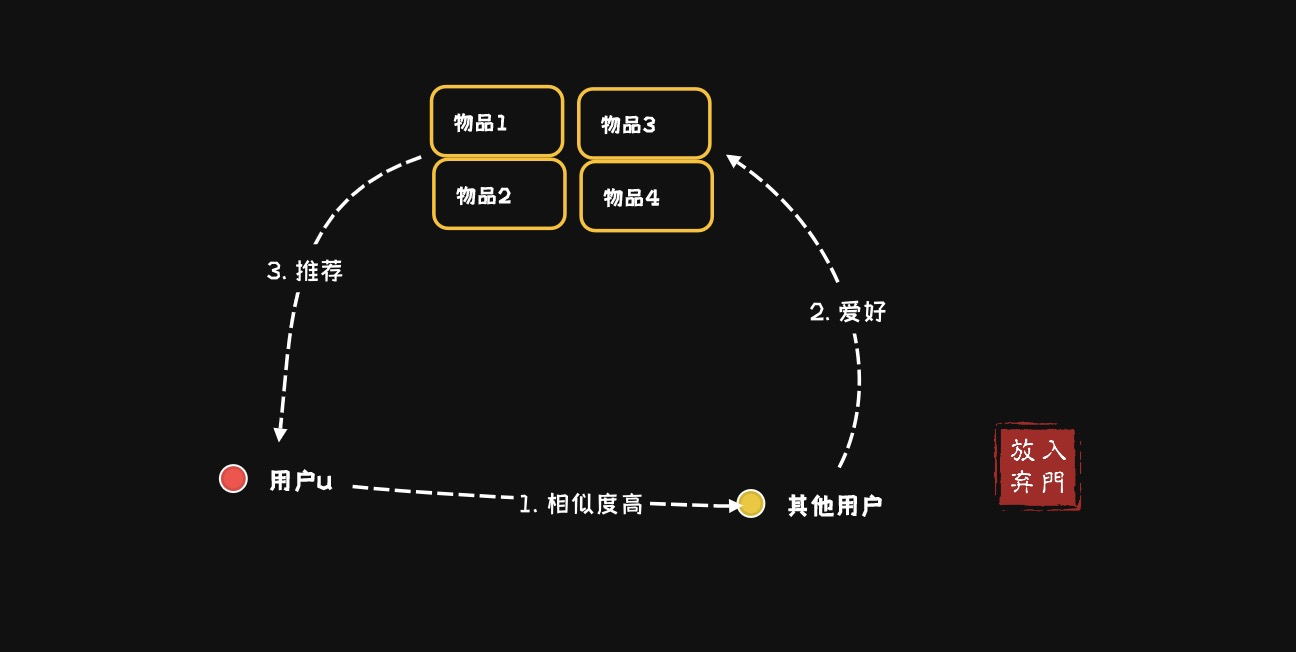
Этот метод работает путем поиска других пользователей с такими же интересами, как у целевого пользователя, чтобы рекомендовать товары, которые нравятся этим похожим пользователям.
- Рассчитайте сходство между пользователями (например, используя коэффициент корреляции Пирсона, косинусное сходство и т. д.).
- Найдите K пользователей, наиболее похожих на целевого пользователя.
- На основе оценок этих похожих пользователей порекомендуйте предметы, которые им нравятся, но с которыми целевой пользователь еще не сталкивался.
вещьсовместная фильтрация
на основевещьизсовместная фильтрацияалгоритм(item-based collaborative фильтрация): пользователь рекомендует предметы, похожие на предметы, которые ему нравились раньше. Из набора предметов, купленных пользователем u, выберите TopN предметов, похожих на каждый предмет, и используйте средневзвешенное значение для оценки оценки пользователя u для каждого кандидата. элемент.
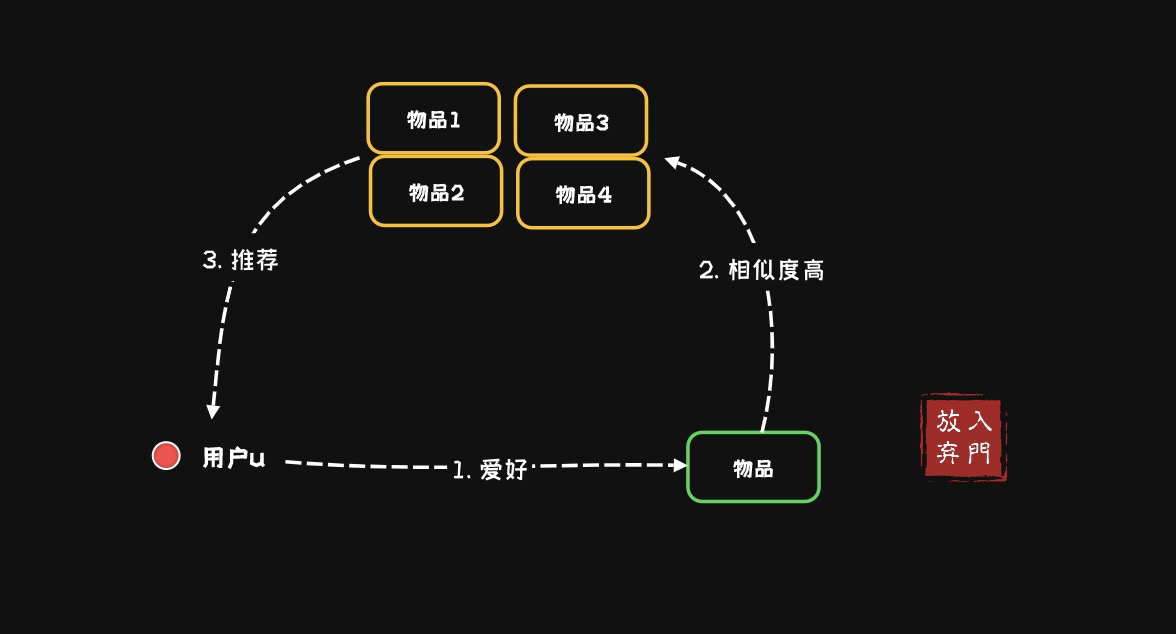
При обнаружении других элементов, похожих на целевой элемент, пользователю рекомендуются элементы, аналогичные целевому элементу.
- Вычислить сходство между предметами (также можно использовать косинусное сходство и другие методы)
- Найдите элементы, которые оценили пользователи, и определите другие элементы, похожие на эти элементы.
- Рекомендовать эти похожие товары
В итоге,независимо от типа,Нам всем нужно знать, насколько пользователям нравятся товары,Для оценки должна быть количественная ценность (например, лайки, рейтинги и т. д.).。Что касаетсясовместная фильтрация Алгоритм рекомендаций Два типа задействованыРасчет сходства, коэффициентждать,Никаких углубленных исследований здесь проводиться не будет. После понимания вышеуказанных основных понятий,Как реализовать алгоритм совместной фильтрации?
Sparkизсовместная фильтрация
Млибмашинное в Спарке библиотека обучения предоставляет совместную Осуществление фильтрации.
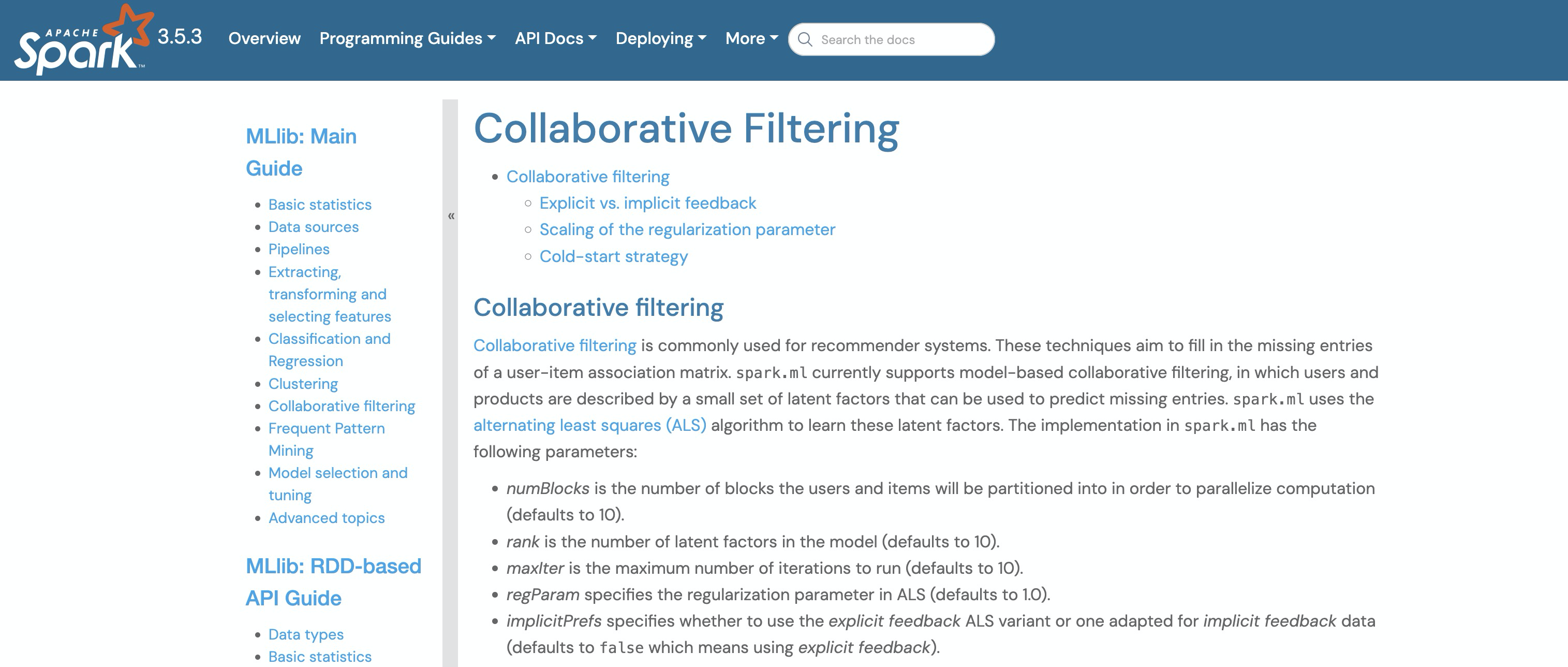
Sparkосовместная фильтрацияизвыполнитьда Опишите это такиз:Spark.ml в настоящее время поддерживает совместные файлы на основе моделей. фильтрация, где пользователи и продукты описываются набором скрытых факторов, которые можно использовать для прогнозирования отсутствующих записей. Spark.ml использует алгоритм попеременных наименьших квадратов (ALS) для изучения этих скрытых факторов.
ALS (чередующиеся наименьшие квадраты)
Прибытие в Искру, совместная фильтрация И сновамашинное обучение связано. БАС (переменный Least Squares)дасовместная Конкретная реализация фильтрации, в основном используемая для оптимизации разложения матрицы рейтингов пользовательских элементов.
Разреженность матрицы «пользователь-элемент» является распространенной проблемой в рекомендательных системах. В основном это связано с тем, что в этой матрице отсутствует взаимодействие между большинством пользователей и элементами (например, рейтинги, покупки и т. д.), в результате чего. большинство элементов в матрице пусты или отсутствуют, поэтому не хватает данных для учета предпочтений пользователя.
ALS — это широко используемый метод матричной факторизации.,Обычно используется для обработки крупномасштабных разреженных матриц.,Изучите скрытые характеристики пользователей и предметов с помощью обучающих моделей.,кгенерироватьперсонализацияизрекомендовать。Подводя итог в одном предложениида:Spark использует ALS для достижения более точных алгоритмических рекомендаций.。
Рекомендуемые фильмы
Так,Как использовать ALS Spark для реализации рекомендаций Алгоритма? Код рекомендации фильма приведен в документации официального сайта Spark.,Давайте использовать этот пример,Вы можете учиться наоборот.
Код доступен в версиях Python, Java, Scala и R. В качестве примера мы рассмотрим Spark. Как Mlib реализует совместную систему на базе ALS фильтрацияиз Алгоритм рекомендаций。
1. Подготовка данных
Сначала давайте посмотрим на часть подготовки данных.
import org.apache.spark.ml.evaluation.RegressionEvaluator
import org.apache.spark.ml.recommendation.ALS
case class Rating(userId: Int, movieId: Int, rating: Float, timestamp: Long)
def parseRating(str: String): Rating = {
val fields = str.split("::")
assert(fields.size == 4)
Rating(fields(0).toInt, fields(1).toInt, fields(2).toFloat, fields(3).toLong)
}
val ratings = spark.read.textFile("data/mllib/als/sample_movielens_ratings.txt")
.map(parseRating)
.toDF()Код очень простой,Загрузите сначалаsample_movielens_ratings.txt,Этот файл используется для данных рекомендаций.
0::2::3::1424380312
0::3::1::1424380312
0::5::2::1424380312
1::94::2::1424380312
1::96::1::1424380312
1::97::1::1424380312
2::4::3::1424380312
2::6::1::1424380312НастроитьparseRatingФункция разбивает каждую строку данных,Затем сопоставьте его с объектом рейтинга.,генерироватьDataFrameПроизвести расчеты。в ВключатьпользовательID、номер фильма、Рейтинг и временная метка в четырех полях。Поле рейтинга в данных,Это количественная оценка интереса пользователя к фильмам.
2. ALS
Следующим шагом является обучение обработанных данных рейтинга фильмов с помощью ALS для построения модели рекомендаций.
// 80% данных — это данные обучения, а 20% — данные тестирования.
val Array(training, test) = ratings.randomSplit(Array(0.8, 0.2))
// Build the recommendation model using ALS on the training data
val als = new ALS()
.setMaxIter(5)
.setRegParam(0.01)
.setUserCol("userId")
.setItemCol("movieId")
.setRatingCol("rating")
val model = als.fit(training)setMaxIterУстановить максимум Итерироватьчастота,В алгоритме АЛС,Итерироватьосновнойдаобратитесь кМатрица функций пользователяиМатрица характеристик товараиз Процесс обновления。в Матрица функций пользователяиспользуется для описанияпользовательиз Предпочтение,Матрица свойств предмета используется для описания характеристик предмета.
В процессе Итерировать,Повторите следующий процесс поочередно,До тех пор, пока не будет достигнуто максимальное количество Итерировать или не будет выполнено определенное условие сходимости.
- Матрица фиксированных элементов, обновленная матрица пользователей: используйте текущие характеристики элемента для расчета характеристик пользователя.
- Фиксированная матрица пользователей, обновленная матрица элементов: используйте текущие характеристики пользователя для расчета характеристик элемента.
Параметры АЛС задаются в коде:
- setRegParam(0.01): установите параметр регуляризации на 0.01,предотвратитьпереоснащение
- setUserCol("userId"): указывает имя столбца идентификатора пользователя, который представляет собой уникальный идентификатор пользовательских данных.
- setItemCol("movieId"): указывает имя столбца идентификатора элемента, который представляет уникальный идентификатор элемента (например, фильма).
- setRatingCol("rating"): указывает имя столбца рейтинга, указывающее пользовательский рейтинг элемента.
Здесь появляется существительное:Итерироватьипереоснащение。
Итерировать
setMaxIter(5) контролирует количество раз, когда алгоритм ALS ищет лучшую рекомендательную модель. Число раз определяет количество шагов, необходимых алгоритму для достижения сходимости (то есть ошибка больше не уменьшается значительно).
Обычно,Увеличение количества Итерировать может повысить точность модели.,Но это также увеличит вычислительные затраты и время. Слишком большое количество итераций может привести к тому, что модель не будет соответствовать обучающим данным.,Это приводит к снижению производительности при работе с новыми данными.
5 раз Итерировать обычно считается разумной отправной точкой.,Это может обеспечить определенную эффективность вычислений, в то время как,Обеспечьте лучшую производительность модели. Однако оптимальное значение может варьироваться в зависимости от конкретного набора данных и сценария применения. Рекомендуется корректировать, исходя из следующих факторов:
- Размер данных: для сходимости больших наборов данных может потребоваться больше итераций.
- Метрики оценки: определите количество итераций, необходимое для достижения оптимальной производительности посредством перекрестной проверки или других методов оценки.
- Вычислительные ресурсы: рассмотрите доступные вычислительные ресурсы и бюджет времени, чтобы определить подходящее количество Итерировать.
переоснащение
переоснащение (Overfitting) означает «машинное обучение» и «глубокое обучение».,Модель слишком хорошо работает на обучающих данных.,Изучение деталей в обучающих данных,Включает шум и аномалии в данных.,Однако он плохо работает с тестовыми данными или новыми данными.
Например, если данные совпадаютy = x^2изсвязь,Результат в обучающих данныхиз Некоторые аномальные данные согласуются сy=sinx,Эти аномальные данные также влияют на взаимосвязь между xy,Следовательно, окончательная формула не очень точна применительно к тестовому набору.,Это переоснащение данных.
Итак, чтобы решить проблему переоснащения, вводятся функция потерь и регуляризация:
$$
Общие потери = функция потерь (L) + λ\ * член регуляризации (J)
$$
Среди них функция потерь (функция потерь) используется для измерения разницы между выходными данными модели и реальными y и указывает направление оптимизации модели. J — это термин регуляризации, который используется для. ограничить сложность модели; λ — коэффициент регуляризации, используемый для регулирования компромисса между функцией потерь и членом регуляризации.
В ALS Spark у нас есть возможность выбрать только λ, поэтому здесь используется setRegParam, чтобы установить λ равным 0,01. Что касается того, почему оно равно 0,01, это может быть комплексное решение (полученное из сети), основанное на опыте, характеристиках данных, сложности модели и результатах экспериментов.
Наконец, вызовите fit, чтобы начать обучение модели.
3. Модельное предсказание
Как определить, является ли рекомендованная мной модель переоснащением? Вы можете рассчитать RMSE модели на обучающем наборе и проверочном наборе соответственно?
В обычных обстоятельствах,Если обучающий набор RMSE и набор проверки RMSE аналогичны,Это показывает, что модель обладает хорошей способностью к обобщению. Если RMSE обучающего набора значительно ниже, чем RMSE проверочного набора,Это может быть признаком переоснащения. Это показывает, что модель очень хорошо работает на обучающем наборе.,Но он хуже работает с новыми данными (набор проверки).
model.setColdStartStrategy("drop")
val predictions = model.transform(test)
val evaluator = new RegressionEvaluator()
.setMetricName("rmse")
.setLabelCol("rating")
.setPredictionCol("prediction")
val rmse = evaluator.evaluate(predictions)
println(s"Root-mean-square error = $rmse")- setColdStartStrategy устанавливает стратегию холодного запуска на «отбрасывание», то есть во время прогнозирования, если у пользователя или элемента нет никаких исторических данных, результаты прогнозирования пользователя или элемента будут отброшены.
- преобразование использует обученную модель для прогнозирования набора тестовых данных
- ReгрессияEvaluator создает оценщик Объект регрессии, используемый для оценки прогнозирующей эффективности регрессионной модели.
оценщик регрессии
ReгрессияEvaluator использует RMSE(среднеквадратическая ошибка)измерить регрессию Прогноз производительность модели, это значит Прогноз Отклонение между значением модели и фактическим значением.
setLabelCol указывает имя столбца метки как «рейтинг», которое является именем столбца рейтинга фильма в приведенном выше наборе данных, а setPredictionCol указывает имя столбца прогнозирования как «прогноз», которое является именем столбца модели. значение прогноза.
Наконец, оценщик используется для оценки результата прогнозирования DataFrame и расчета среднеквадратической ошибки (RMSE) прогноза модели.

Окончательное рассчитанное среднеквадратическое отклонение равно 1,7, что означает, что разница между выходным значением и истинным значением в тестовых данных составляет 1,7. Для большинства систем рекомендаций по контенту приемлемым считается RMSE от 1 до 3.
4. Рекомендации по модели
Затем начните давать рекомендации на основе модели, обученной выше.
val userRecs = model.recommendForAllUsers(10)
// Generate top 10 user recommendations for each movie
val movieRecs = model.recommendForAllItems(10)
// Generate top 10 movie recommendations for a specified set of users
val users = ratings.select(als.getUserCol).distinct().limit(3)
val userSubsetRecs = model.recommendForUserSubset(users, 10)
// Generate top 10 user recommendations for a specified set of movies
val movies = ratings.select(als.getItemCol).distinct().limit(3)
val movieSubSetRecs = model.recommendForItemSubset(movies, 10)рекомендацияForAllUsers создает список рекомендаций из 10 лучших фильмов для каждого пользователя. Модель представляет собой модель рекомендаций, обученную с помощью алгоритма ALS, описанного выше. Затем генерируются два списка рекомендаций:
- Создайте для каждого фильма список рекомендаций из 10 лучших пользователей, которым он может понравиться.
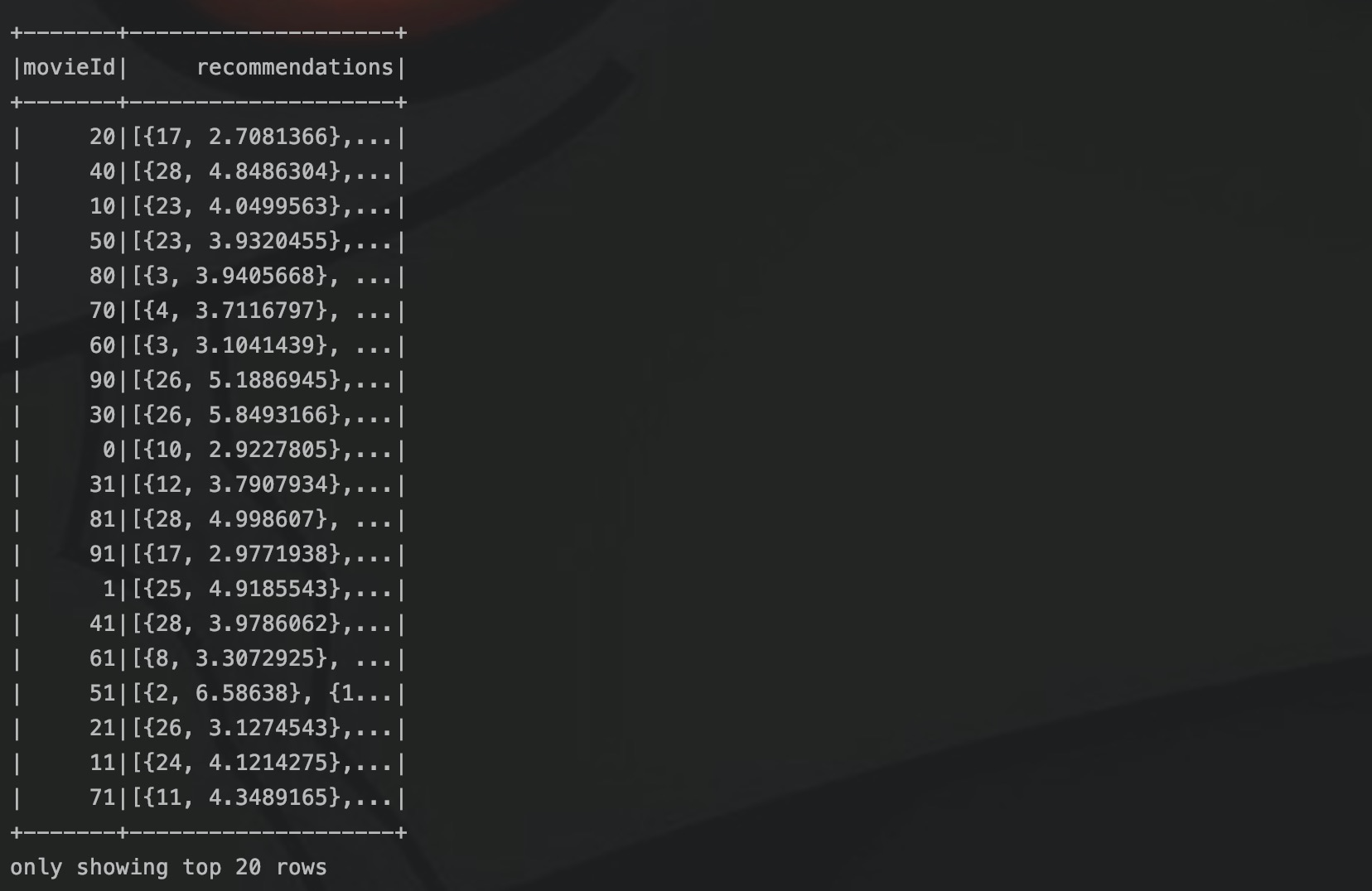
- Создайте список рекомендаций из 10 лучших фильмов для этих 3 пользователей.
Таким образом, с использованием алгоритма ALS Spark завершается подготовка фоновых рекомендательных данных системы рекомендаций фильмов. Если мы хотим создать систему рекомендаций, у нас должна быть клиентская страница, поэтому нам нужно поместить эту часть данных во внутреннюю базу данных.
Аналогично, в наборе данных пользователи и фильмы представлены идентификаторами, поэтому в базе данных также будет таблица сопоставления между идентификаторами пользователей и пользователями, идентификаторами фильмов и названиями фильмов.
Заключение
Реализация совместной с использованием ASL от Spark фильтрациярекомендоватьиз Наблюдайте за всем процессом,Меньше кода и простые шаги. От подготовки данных до обучения и проверки моделей,и, наконец, сгенерируйте рекомендуемый контент,Все предоставляют стандартные интерфейсы,Поэтому дополнительная работа заключается в подготовке данных.
После создания данных рекомендаций и помещения их в базу данных вы можете разработать интерфейсную страницу для рекомендаций. Что касается дизайна, вы можете начать с двух аспектов: практичности и отображения.



Углубленный анализ переполнения памяти CUDA: OutOfMemoryError: CUDA не хватает памяти. Попыталась выделить 3,21 Ги Б (GPU 0; всего 8,00 Ги Б).

[Решено] ошибка установки conda. Среда решения: не удалось выполнить первоначальное зависание. Повторная попытка с помощью файла (графическое руководство).

Прочитайте нейросетевую модель Трансформера в одной статье

.ART Теплые зимние предложения уже открыты

Сравнительная таблица описания кодов ошибок Amap

Уведомление о последних правилах Points Mall в декабре 2022 года.

Даже новички могут быстро приступить к работе с легким сервером приложений.

Взгляд на RSAC 2024|Защита конфиденциальности в эпоху больших моделей

Вы используете ИИ каждый день и до сих пор не знаете, как ИИ дает обратную связь? Одна статья для понимания реализации в коде Python общих функций потерь генеративных моделей + анализ принципов расчета.

Используйте (внутренний) почтовый ящик для образовательных учреждений, чтобы использовать Microsoft Family Bucket (1T дискового пространства на одном диске и версию Office 365 для образовательных учреждений)

Руководство по началу работы с оперативным проектом (7) Практическое сочетание оперативного письма — оперативного письма на основе интеллектуальной системы вопросов и ответов службы поддержки клиентов

[docker] Версия сервера «Чтение 3» — создайте свою собственную программу чтения веб-текста

Обзор Cloud-init и этапы создания в рамках PVE

Корпоративные пользователи используют пакет регистрационных ресурсов для регистрации ICP для веб-сайта и активации оплаты WeChat H5 (с кодом платежного узла версии API V3)

Подробное объяснение таких показателей производительности с высоким уровнем параллелизма, как QPS, TPS, RT и пропускная способность.

Удачи в конкурсе Python Essay Challenge, станьте первым, кто испытает новую функцию сообщества [Запускать блоки кода онлайн] и выиграйте множество изысканных подарков!

[Техническая посадка травы] Кровавая рвота и отделка позволяют вам необычным образом ощипывать гусиные перья! Не распространяйте информацию! ! !

[Официальное ограниченное по времени мероприятие] Сейчас ноябрь, напишите и получите приз

Прочтите это в одной статье: Учебник для няни по созданию сервера Huanshou Parlu на базе CVM-сервера.

Cloud Native | Что такое CRD (настраиваемые определения ресурсов) в K8s?

Как использовать Cloudflare CDN для настройки узла (CF самостоятельно выбирает IP) Гонконг, Китай/Азия узел/сводка и рекомендации внутреннего высокоскоростного IP-сегмента

Дополнительные правила вознаграждения амбассадоров акции в марте 2023 г.

Можно ли открыть частный сервер Phantom Beast Palu одним щелчком мыши? Супер простой урок для начинающих! (Прилагается метод обновления сервера)

[Играйте с Phantom Beast Palu] Обновите игровой сервер Phantom Beast Pallu одним щелчком мыши

Maotouhu делится: последний доступный внутри страны адрес склада исходного образа Docker 2024 года (обновлено 1 декабря)

Кодирование Base64 в MultipartFile

5 точек расширения SpringBoot, супер практично!

Глубокое понимание сопоставления индексов Elasticsearch.

15 рекомендуемых платформ разработки с нулевым кодом корпоративного уровня. Всегда найдется та, которая вам понравится.
