DINOv2: не требует тонкой настройки, заполняет пробелы в SAM, поддерживает множество последующих задач

Эта статья была выбрана как выдающаяся итоговая работа [Тренировочного лагеря по техническому письму], автор: Ван Юэтянь.
Некоторое время назад компания Meta AI выпустила Segment Anything (SAM) с высоким профилем, который быстро генерирует маски в интерактивном режиме и может точно сегментировать изображения, которые никогда не подвергались обучению. Он может обводить сегменты изображения на основе текстовых подсказок или кликов пользователя. . Конкретные объекты, его гибкость является первой в своем роде в области сегментации изображений.
Однако, в конечном счете, SAM представляет собой систему оперативной сегментации, которая в основном используется для различных задач сегментации. Она не так уж полезна для других визуальных задач (например, классификации, поиска, VQA...).
Итак, после [Divide Everything] Мета AI Переиздание тяжелых проектов с открытым исходным кодом - DINOv2, DINOv2. Может извлечь мощные функции изображения,исуществоватьпо последующим задачамНе требуется тонкая настройка,Это делает его подходящим для множества различных приложений в новом BackBone.
По сравнению с ранее выпущенным Segment Anything, DINOv2 имеет более широкий спектр приложений и сферу применения. Эксперименты в этой статье также охватывают классические последующие задачи в нескольких CV.

Paper:
https://arxiv.org/abs/2304.07193
Code:
https://github.com/facebookresearch/dinov2
Demo:
https://dinov2.metademolab.com/
MMPreTrain уже поддерживает магистральные рассуждения DINOv2, добро пожаловать к использованию:
https://github.com/open-mmlab/mmpretrain/tree/main/configs/dinov2
Основные особенности
В официальном блоге Meta AI особенности DINOv2 резюмируются следующим образом:
- DINOv2 — это новый метод обучения компьютерному зрению высокого уровня. Модельиз.
- DINOv2 Обеспечивает мощную изпроизводительность, и Не требуется тонкая настройка。
- Поскольку это самоконтроль, DINOv2 может учиться на любой коллекции изображений. В то же время он также может изучить определенные функции, которые не могут быть изучены существующими методами, например, оценку глубины.
DINOv2 — это новый высокопроизводительный метод обучения модели компьютерного зрения, который использует обучение с самоконтролем для достижения результатов, которые соответствуют или превосходят стандартные методы, используемые в этой области. Как и другие системы с самоконтролем, модели, использующие подход DINOv2, можно обучать на любой коллекции изображений, не требуя каких-либо связанных метаданных. Это означает, что он может учиться на всех получаемых изображениях, а не только на тех, которые содержат определенный набор тегов, замещающий текст или подписи. DINOv2 предоставляет высокопроизводительные функции, которые можно использовать непосредственно в качестве входных данных для простого линейного классификатора. Такая гибкость означает, что DINOv2 можно использовать для создания универсальной магистрали для решения множества различных задач компьютерного зрения.
Эксперименты в этой статье демонстрируют отличные возможности DINOv2 для решения последующих задач, таких как классификация, сегментация и поиск изображений. Среди них самым удивительным является то, что с точки зрения оценки глубины результаты DINOv2 значительно лучше, чем внутридоменные и внедоменные конвейеры SOTA. Авторы полагают, что такая высокая производительность вне предметной области является результатом сочетания самоконтролируемого обучения функциям и легких модулей для конкретных задач, таких как линейные классификаторы.
Наконец, поскольку точная настройка не используется, магистральная сеть остается универсальной, и одну и ту же функцию можно использовать для множества различных задач одновременно.
Содержание исследования
Здесь мы не будем вдаваться в подробности алгоритма DINOv2, а лишь кратко представим, что в основном делает DINOv2 (личное мнение, добро пожаловать к обсуждению).
Создан новый высококачественный набор данных.
Building a large, curated, and diverse dataset to train the models
В современную эпоху больших моделей для дальнейшего повышения производительности более крупным моделям часто требуется больше данных для обучения. Поскольку не существует высококачественных наборов данных, достаточно больших, чтобы удовлетворить потребности обучения DINOv2, Meta AI собрала новый набор данных, извлекая изображения из большого неорганизованного пула данных, которые были похожи на изображения в нескольких организованных наборах данных. Конкретный процесс заключается в следующем:
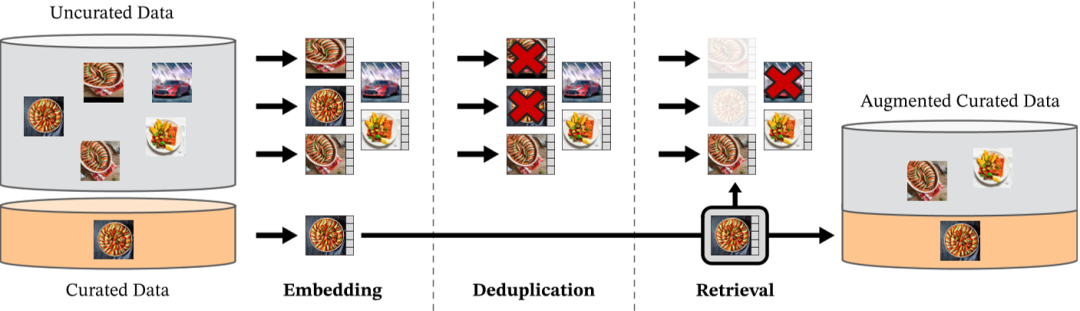
This approach enabled us to produce a pretraining dataset totaling 142 million images out of the 1.2 billion source images.
Давайте подробнее рассмотрим конвейер построения набора данных, который в основном состоит из трех частей: источники данных, дедупликация и самоконтролируемое извлечение изображений.
▶ Источник данных (Данные sources.)
Прежде всего, источник набора данных LVD-142M состоит из двух частей: общедоступных наборов данных и наборов сетевых данных.
Публичный набор данных
Как показано в таблице ниже, обучающие разделения содержат ImageNet-22k, ImageNet-1k, Google Landmarks и несколько мелкозернистых наборов данных:

Простое понимание наборов сетевых данных заключается в сборе исходных нефильтрованных наборов данных изображений из общедоступных хранилищ сетевых данных, а затем очистке этих данных в три этапа:
- Сначала для каждой интересующей веб-страницы из тега извлекается URL-ссылка на изображение;
- Во-вторых, исключите URL-ссылки, которые имеют проблемы с безопасностью или ограничены доменными именами;
- Наконец, загруженные изображения были подвергнуты постобработке, включая хеширование PCA для дедупликации, фильтрацию NSFW и размытие опознаваемых лиц.
Результат — 120 миллионов уникальных изображений.
▶ Дедупликация.
Чтобы еще больше уменьшить избыточность и увеличить разнообразие изображений, DINOv2 использует конвейер обнаружения копирования, предложенный в статье «Дескриптор с самоконтролем для обнаружения копий изображений», для выполнения проверки дублирования изображений. Этот метод вычисляет сходство между изображениями на основе глубокого обучения.
Ссылка на документ: https://arxiv.org/abs/2202.10261.
Кроме того, DINOv2 удаляет дубликаты изображений, содержащиеся в тестовых или проверочных наборах, используя любой тест, чтобы гарантировать чистоту набора данных.
▶ Самоконтролируемый поиск изображений (Самоконтролируемый image retrieval.)
Далее следует процесс самостоятельного поиска изображений. Чтобы получить изображения, которые очень похожи на тщательно организованный набор данных, из большого объема немаркированных данных, эти нефильтрованные изображения необходимо сначала кластеризовать, чтобы изображения, похожие на изображение запроса, можно было быстро найти во время поиска. Алгоритмы кластеризации группируют визуально очень похожие изображения в одну группу.
Чтобы процесс кластеризации прошел гладко, сначала необходимо вычислить вложения каждого изображения. DINOv2 использует нейронную сеть с самоконтролем ViT-H/16, предварительно обученную на ImageNet-22k, для расчета встраивания каждого изображения.
После вычисления вектора внедрения каждого изображения DINOv2 использует алгоритм кластеризации k-средних для помещения изображений с похожими векторами внедрения в один и тот же кластер. Затем, учитывая изображение запроса, DINOv2 извлекает N (обычно 4) наиболее похожих изображений из того же кластера, что и изображение запроса. Если изображение запроса находится в слишком маленьком кластере, DINOv2 выбирает M изображений из кластера (M определяется после визуальной проверки результатов). Наконец, эти похожие изображения используются для предварительного обучения вместе с изображением запроса, чтобы получить более качественный, тщательно отфильтрованный, крупномасштабный набор данных для предварительного обучения.
▶ LVD-142M
С помощью описанного выше процесса Meta AI получил организованные 142 миллиона изображений из 1,2 миллиарда изображений, названные набором данных LVD-142M. В этом процессе, благодаря использованию технологии поиска изображений с самоконтролем, качество и разнообразие набора данных значительно улучшаются, обеспечивая более богатые ресурсы данных для последующего обучения DINOv2.
Улучшения в методах и техниках обучения
▶ Метод обучения: Дискриминационный Self-supervised Pre-training
DINOv2 использует дискриминационный метод предварительного обучения с самоконтролем для изучения функций, который можно рассматривать как комбинацию потерь DINO и iBOT и централизации SwAV).
Проще говоря, DINOv2 использует две целевые функции для обучения сети. Первая — это целевая функция уровня изображения, которая использует функции токена cls ViT для расчета потерь перекрестной энтропии путем сравнения выходных данных токена cls сети ученика и сети учителя, полученных из разных частей одного и того же изображения. Вторая — это целевая функция уровня патча, которая случайным образом маскирует некоторые патчи, введенные сетью учеников (а не сетью учителей), и вычисляет потери перекрестной энтропии для функций каждого замаскированного патча. Веса этих двух целевых функций необходимо корректировать отдельно, чтобы получить лучшую производительность в разных масштабах.
При этом, чтобы лучше обучать сеть, автор также использует некоторые приемы. Например, отмена привязки весов между двумя целевыми функциями для решения проблемы недостаточного и чрезмерного подбора модели в разных масштабах. Кроме того, авторы использовали центрирование Синкхорна-Кноппа для нормализации данных и регуляризатор KoLeo для обеспечения равномерного распределения функций внутри пакетов. Наконец, чтобы повысить точность последующих задач на уровне пикселей, таких как сегментация или обнаружение, авторы применили метод постепенного увеличения разрешения изображения, что еще больше улучшило производительность модели.
В частности, авторы реализовали следующие методы:
- Image-level Цель: использовать функцию перекрестной энтропийной потери для извлечения характеристик учащихся и учителей. Эти функции взяты из ViTizcls. token,Получено путем извлечения различных обрезанных изображений одного и того же изображения. Авторы использовали метод экспоненциального скользящего среднего (EMA) для построения модели учителя.,Параметры Модельиз студента получаются посредством обучения.
- Patch-level Цель: Случайным образом охватить несколько входных участков, а затем охватить сети учеников и учителей сетьсуществовать из Характеристики патча сравниваются с потерей перекрестной энтропии. Это уровень функции потери изображения из функции потери в сочетании.
- Untying head weights between both цели: авторы обнаружили, что объединение двух объективных весов привело к получению модели существовать. Patch-level Недооснащение, в Image-level Переобучение. Разделение этих весов решает эту проблему и улучшает обе шкалы.
- Центрирование Синкхорна-Кноппа: этот метод является улучшением некоторых этапов методов DINO и iBOT. Подробности см. в этой статье: Неконтролируемое обучение визуальных функций путем сопоставления кластерных назначений (arxiv.org).
- Регуляризатор KoLeo: регуляризатор KoLeo — это метод регуляризации, который обеспечивает равномерное распределение объектов внутри пакета путем расчета разницы между векторами признаков. Он получен на основе дифференциальной оценки энтропии Козаченко-Леоненко и обеспечивает равномерное изменение признаков внутри пакета. Подробности см.: Распространение векторов для поиска по сходству (arxiv.org).
- Адаптация разрешения. Этот шаг в основном включает увеличение разрешения изображения до 518×518 в течение последнего периода предварительного обучения, чтобы можно было лучше обрабатывать информацию на уровне пикселей в последующих задачах, таких как задачи сегментации или обнаружения. Изображения с высоким разрешением обычно требуют больше вычислительных ресурсов и места для хранения, поэтому этот метод используется только на заключительном этапе предварительного обучения, чтобы сократить затраты времени и ресурсов.
▶ Инженерные улучшения в технологии обучения
В то же время DINOv2 также использует ряд инженерных улучшений для обучения моделей в более крупных масштабах. Благодаря использованию новейших технологий параллелизма данных Pytorch 2.0, распределенного обучения, обучения смешанной точности и эффективного использования памяти переменной длины новый код работает примерно в два раза быстрее, чем раньше, на том же оборудовании, используя при этом меньше памяти. -треть оригинала, что может помочь DINOv2 более эффективно масштабироваться с точки зрения данных, размера модели и аппаратного обеспечения.
▶ Дистилляция для получения хороших легких моделей
Также следует отметить, что хотя большие модели хороши, их требования к оборудованию и вычислительной мощности слишком высоки. Мы всегда надеемся на появление мощных, легких моделей с более низкими порогами.
Таким образом, Meta AI сжимает знания большой модели в меньшую модель посредством дистилляции модели, так что последующие исследователи могут значительно снизить стоимость умозаключений с минимальными затратами на точность. В то же время полученные модели ViT-Small, ViT-Base и ViT-Large также показывают хорошие результаты обобщения на последующих задачах, как показано в следующих экспериментальных результатах.
Результаты оценки предварительно обученных моделей
Первый — необходимый результат на ImageNet-1k. Видно, что DINOv2 имеет очень очевидное улучшение (+4,2%) в линейной оценке по сравнению с предыдущим SOTA (iBOT ViT-L/16, обученным на ImageNet-22k).

Далее следуют результаты классификации изображений и видео, а также детальной классификации:

В качестве классической задачи Downsteam сегментация имеет важное значение:

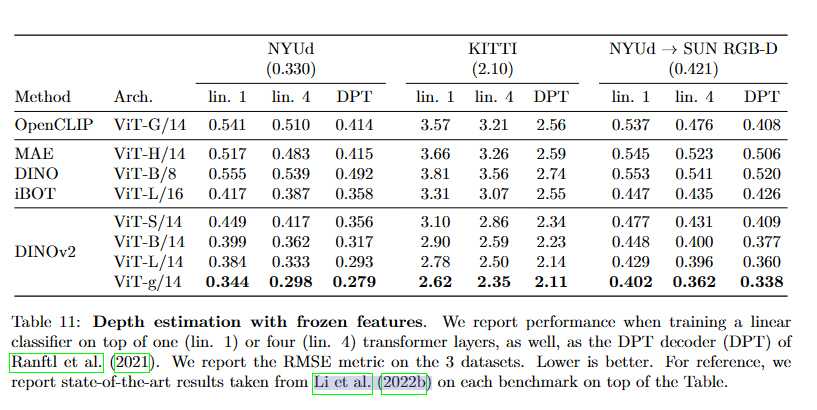
Есть и менее распространенные результаты монокулярной оценки глубины:
Выпущена серия высокопроизводительных предварительно обученных моделей.
Releasing a family of high-performance pretrained models
Прочитав результаты экспериментов, показанные выше, хочет ли кто-нибудь из студентов опробовать DINOv2 в качестве основы в своих собственных задачах? Meta AI также выпустила для сообщества серию предварительно обученных моделей DINOv2.
DINOv2 можно использовать «из коробки» в качестве средства извлечения признаков и добиться очень хороших результатов при выполнении множества последующих задач без тонкой настройки (в ImageNet-1k линейная оценка всего на 2% лучше, чем точная настройка), как показано на рисунке. ниже Показать:

Играйте с демо
В то же время Meta опубликовала на своем официальном сайте веб-демо оценки глубины, семантической сегментации и поиска экземпляров. Вы можете попробовать это напрямую без регистрации (это «Открытый» AI).
Ссылка: https://dinov2.metademolab.com/
Здесь я также поделюсь результатами своих испытаний:
Оценка глубины
Как правило, лишь немногие предварительно обученные модели демонстрируют свои возможности в оценке глубины, что также показывает, что модель DINOv2 демонстрирует высокую производительность вне распределения.
Здесь я намеренно выбрал в качестве теста ночную сцену в условиях неестественного освещения, и результаты оказались потрясающими!

Семантическая сегментация
Замороженные функции DINOv2 можно легко использовать для задач семантической сегментации.

Вот простая семантическая сегментация, в которую не так удобно играть, как в SAM, при решении задач сегментации.
Получение экземпляра
Это демо, которое я считаю очень интересным. Это поиск произведений искусства, похожих на данную картину, из большой коллекции художественных изображений. Здесь я загрузил изображение Башни Желтого Журавля в качестве запроса:

Это результат, полученный от Dinov2. Он очень близок по смыслу (оба имеют высокую башню или здание😂).

будущее направление
Meta AI также определяет будущие направления исследований команды. Как правило, он сочетается с большими языковыми моделями (LLM, Large Language Models) для перехода к общему искусственному интеллекту и сложным системам искусственного интеллекта (сложным системам искусственного интеллекта).
Заключение
DINOv2 представляет собой метод с самоконтролем и без тонкой настройки, который хорошо справляется с извлечением особенностей изображения и подходит для множества различных задач по зрению. Его открытый исходный код также предоставляет новый выбор для исследователей и инженеров и, как ожидается, принесет новые прорывы в области компьютерного зрения. Вы можете рассчитывать на дальнейшие исследования на основе DINOv2.
MMPreTrain
Если вас интересуют базовые модели предварительного обучения, связанные с DINOv2, рекомендуется обратить внимание на набор инструментов для предварительного обучения OpenMMLab с открытым исходным кодом MMPreTrain. В настоящее время MMPreTrain уже поддерживает вывод магистрали DINOv2.

Ссылка на гитхаб:
https://github.com/open-mmlab/mmpretrain
(Добро пожаловать)
MMPreTrain охватывает множество магистральных сетей и моделей предварительного обучения и поддерживает различные стратегии обучения (обучение с учителем, обучение без учителя и т. д.). Включены следующие алгоритмы с самоконтролем, все из которых являются новейшими классическими методами. последние два года😊.

ссылка
- https://www.facebook.com/login/?next=https%3A%2F%2Fwww.facebook.com%2Fzuck%2Fposts%2Fpfbid02f3chCYQphfYnzRaDXeJxsT5EmyhbrFsjqLaU31KuTG63Ca4yMXFcDXQcukYPbWUMl
- https://ai.facebook.com/blog/dino-v2-computer-vision-self-supervised-learning/


На этот раз полностью поймите протокол ZooKeeper.

Реализуйте загрузку файлов с использованием минимального WEB API.

Демо1 Laravel5.2 — генерация и хранение URL-адресов
Spring boot интегрирует Kafka и реализует отправку и потребление информации (действительно при личном тестировании)
Мысли о решениях по внутренней реализации сортировки методом перетаскивания

Междоменный доступ к конфигурации nginx не может вступить в силу. Междоменный доступ к странице_Page

Как написать текстовый контент на php

PHP добавляет текстовый водяной знак или водяной знак изображения к изображениям – метод инкапсуляции
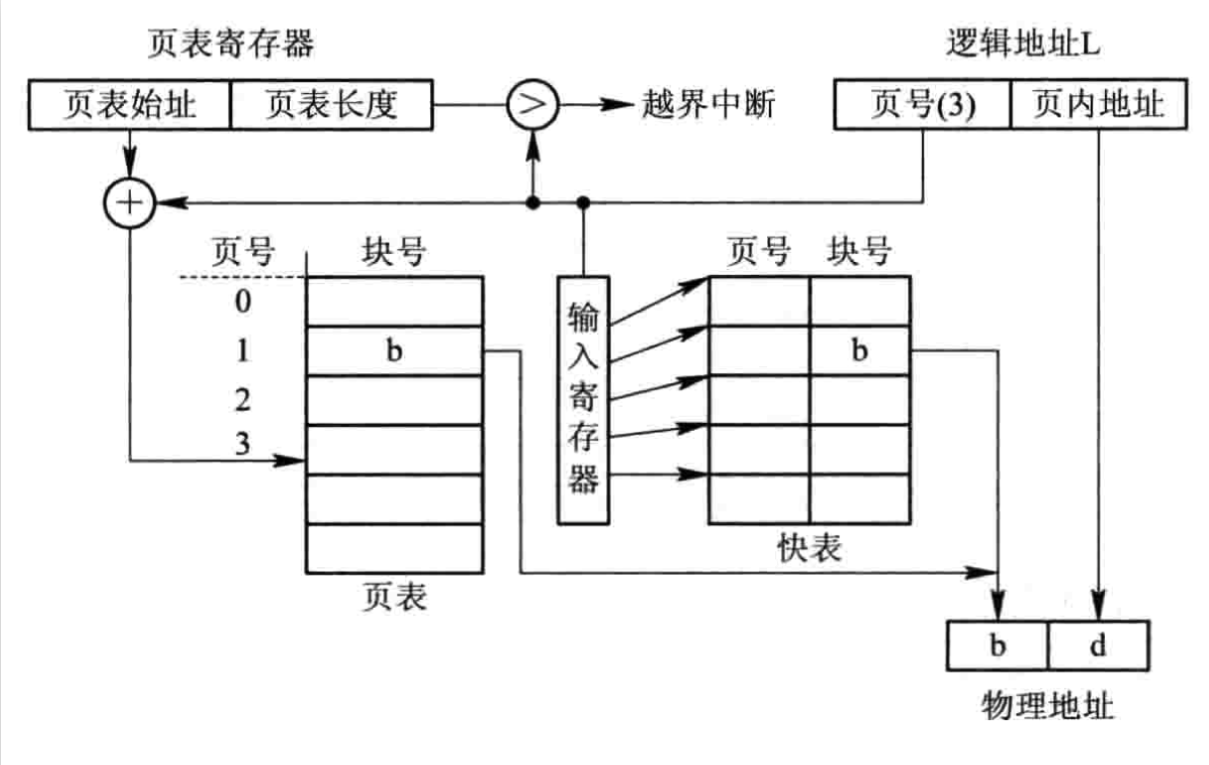
Интерпретация быстрой таблицы (TLB)

Интерфейс WeChat API (полный) — оплата WeChat/красный конверт WeChat/купон WeChat/магазин WeChat/JSAPI

Преобразование Java-объекта в json string_complex json-строки в объект

Примените сегментацию слов jieba (версия Java) и предоставьте пакет jar

matinal: Самый подробный анализ управления разрешениями во всей сети SAP. Все управление разрешениями находится здесь.
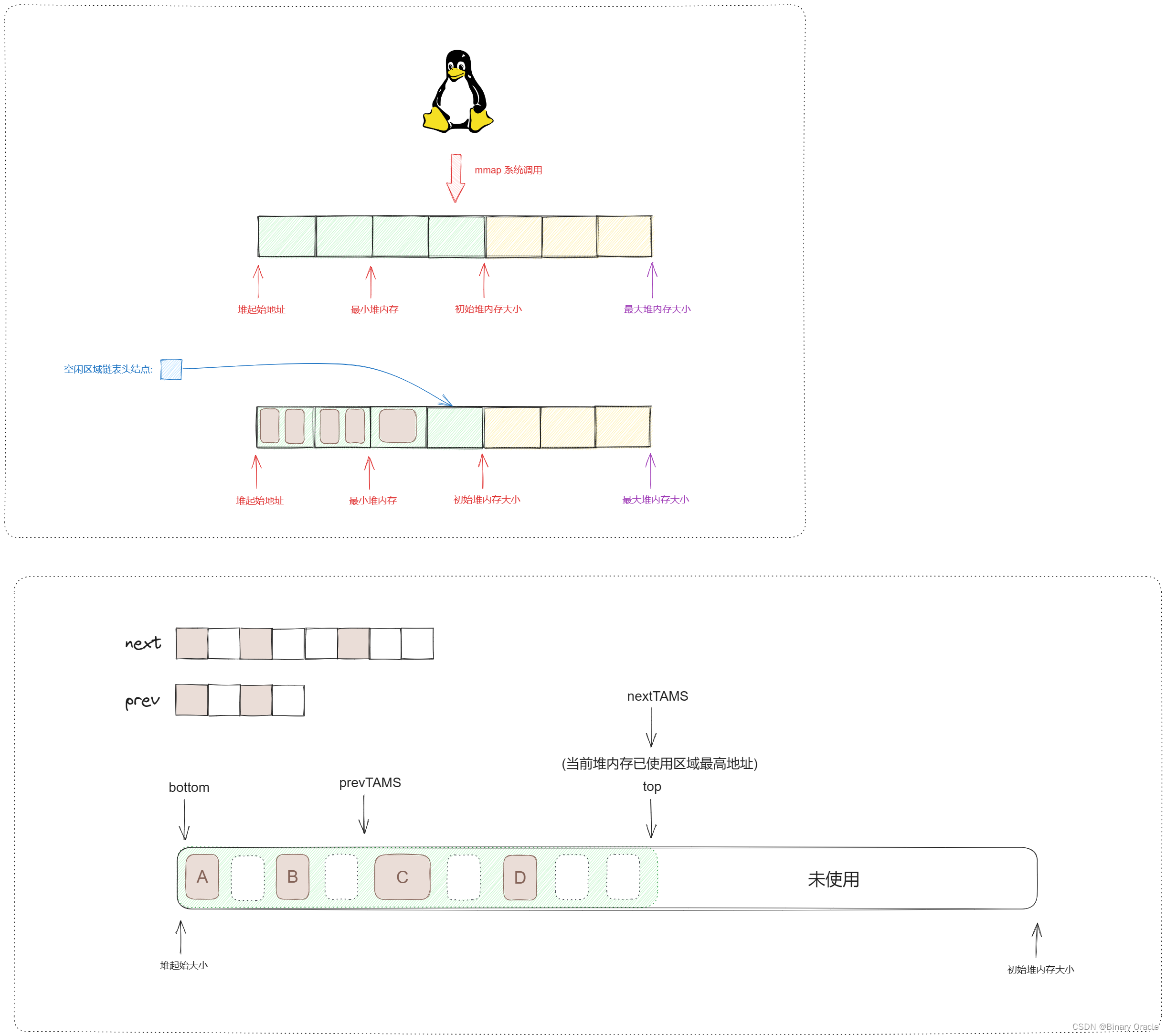
Коротко расскажу обо всем процессе работы алгоритма сборки мусора G1 --- Теоретическая часть -- Часть 1
[Спецификация] Результаты и исключения возврата интерфейса SpringBoot обрабатываются единообразно, поэтому инкапсуляция является элегантной.

Интерпретация каталога веб-проекта Flask

Что такое подробное объяснение файла WSDL_wsdl

Как запустить большую модель ИИ локально
Подведение итогов десяти самых популярных веб-фреймворков для Go
5 рекомендуемых проектов CMS с открытым исходным кодом на базе .Net Core

Java использует httpclient для отправки запросов HttpPost (отправка формы, загрузка файлов и передача данных Json)

Руководство по развертыванию Nginx в Linux (Centos)

Интервью с Alibaba по Java: можно ли использовать @Transactional и @Async вместе?

Облачный шлюз Spring реализует примеры балансировки нагрузки и проверки входа в систему.

Используйте Nginx для решения междоменных проблем

Произошла ошибка, когда сервер веб-сайта установил соединение с базой данных. WordPress предложил решение проблемы с установкой соединения с базой данных... [Легко понять]

Новый адрес java-библиотеки_16 топовых Java-проектов с открытым исходным кодом, достойных вашего внимания! Обязательно к просмотру новичкам

Лучшие практики Kubernetes для устранения несоответствий часовых поясов внутри контейнеров
Введение в проект удаления водяных знаков из коротких видео на GitHub Douyin_TikTok_Download_API
