DIN, POSO, SENet рассказывают о внимании, обычно используемом в рекомендательных моделях
1. Предисловие
Говоря о структуре модели, я часто слышу, как студенты, дающие рекомендации, говорят:
«Здесь добавлено внимание к себе» "похоже на SENet" «Магически модифицированный ПОСО» «DIN – это внимание» ...
Прослушав эти распространенные модули и модели, я все еще немного их понимаю. Прочитав несколько статей Zhihu о моделях, я почувствовал, что все они выглядят одинаково. Чтобы четко понять эти модели, я развернул их. бумаги и прочитайте их еще раз. В этой статье в качестве примера будет использован выбор функций в системе рекомендаций, чтобы поговорить о том, как использовать эти модели в модульном порядке, и добавить некоторые из моих личных знаний. Если есть какие-либо ошибки, пожалуйста, поправьте меня. зона комментариев!
2. Пример рекомендательной системы
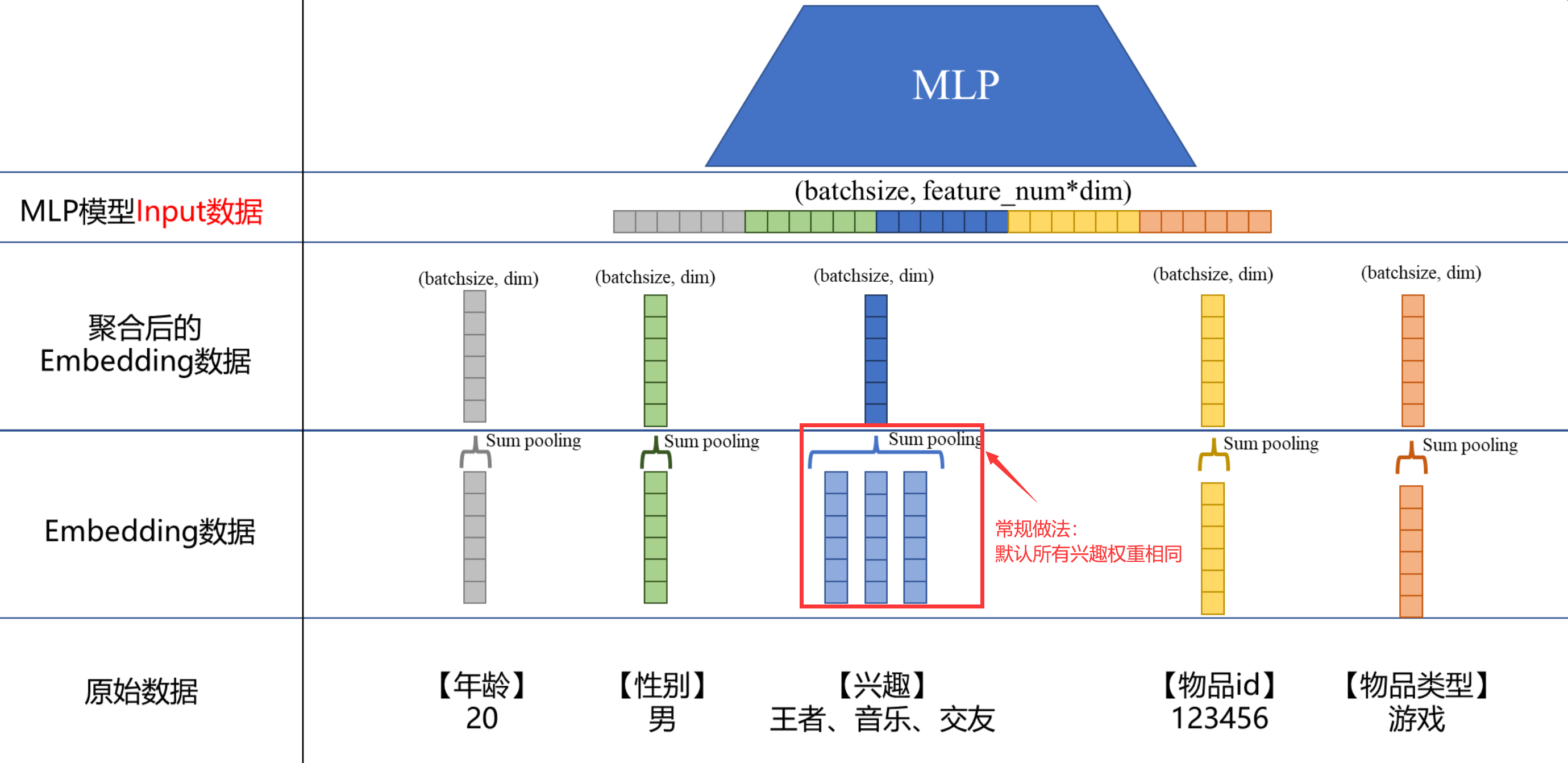
Давайте возьмем общий пример рекомендаций. Каждый, кто создает модели рекомендаций, должен быть знаком с ним. Самые простые данные обычно включают в себя два аспекта: характеристики пользователя и характеристики элемента. На следующем рисунке показан основной процесс. просто с точки зрения данных. Давайте поговорим о картинке ниже, которая в основном разделена на 4 части:
- Исходные данные. Вот наши самые оригинальные данные в строковой форме.
- Встраивание данных: путем хеширования исходных данных в ключи.,Создайте еще один словарь,одинkeyпереписыватьсяодининициализацияиз
dimвектор размерностей。Обратите внимание в это время,Такие характеристики, как [интерес],Так как есть 3 типа пользователей,Это необходимо встроить в 3 независимых вектора.,То есть «король», «музыка», По одному вектору для «Друзей». - Агрегированные данные внедрения: при агрегировании обычно используется сумма Объединение (добавление соответствующих элементов), вы также можете использовать avg pooling(Возьмите среднее значение соответствующих элементов)。сделай этоПо умолчанию каждая функция одинаково важна.,Например, в [Интерес],«Музыка» и «Друзья» имеют одинаковый вес. Если в объекте есть только один ключ,Например, [возраст], [пол],После агрегирования изменений не происходит, если имеется несколько ключей;,Например [интерес],Это объединит вложения нескольких ключей.
- Входные данные MLPМодель: 5 векторов, полученных на предыдущем шаге, собираются в длинный вектор по принципу «голова к торцу».

С помощью вышеуказанной операции вы можете изменить: Возраст: 20.,пол:……данные конвертируются в Модельнеобходимыйtensor。В это время обычно(batchsize, feature_num, dim)форма:
batchsizeразмер партии,Например 512;feature_numэто количество функций,На картинке выше это 5;dimэто каждыйодинособенностьиз Размеры,Например 16.
Почему мы должны так ясно объяснять ввод основных данных, потому что выбор функций POSO, SENet и DIN, которые будут обсуждаться позже, существенно изменен на этой основе. Эти модели (модули) описаны ниже.
3. SENet
Давайте сначала поговорим о SENet. Первоначально он был предложен в области CV. По оригинальным словам автора, цель модели:
Наша цель — обеспечить, чтобы сеть могла повысить свою чувствительность к информативным функциям, чтобы их можно было использовать при последующих преобразованиях, а также подавлять менее полезные функции и подавлять менее полезные функции.

Поэтому была предложена приведенная выше модель. Если ее поместить в рекомендательную систему, некоторые понятия на картинке выше следует заменить:
- Н (высокий)、W(Ширина)следует заменить на
dim - C(Channel)следует заменить на
feature_num
В приведенном выше примере весь процесс выглядит следующим образом:
1. SENetТо есть исходные данные(batchsize, feature_num, dim)Характеристики сначала сжимаются в(batchsize, feature_num, 1)Тогда возьмите это сжатиеизособенность过одиндва этажаMLP,Наконец, используйте сигмоид для вывода,получатьодин(batchsize, feature_num, 1)вес формы。

2. Затем умножьте этот вес обратно на каждое агрегированное внедрение, чтобы получить новые агрегированные данные внедрения.

Если вы понимаете это по оригинальному тексту SENet,Вот как это должно быть обработано,Это нетрудно увидеть,Фактически, это датьfeature_numРазный вес для каждой функции。Потому что в Система рекомендацийсередина,feature_numможно сравнить сCVвнутриChannel。На самом деле, у меня здесь есть несколько вопросов.:
- Почему SENet сжимает в статье два измерения (В, Ш)?,Вышеописанный процесс сжимает только
dim? Ответ: Потому что картинка имеет длину и ширину по сравнению с системой. У рекомендации есть еще одно измерение, поэтому родной SENet необходимо сжимать два измерения. А поскольку это двухмерное исходное сжатие текста, используется avg. В общем, в рекомендации есть только одно измерение, которое можно заменить плотным слоем. - Зачем давать
feature_numРазный вес для каждой функции,вместоdim?Нельзя ли придать разным весам разные элементы?? Ответ: Целью собственной SENet является «решение проблемы, заключающейся в том, что сверточные нейронные сети имеют плохие возможности моделирования функций, связанных с каналами, при обработке изображений».,Поэтому, если вы скопируете его, это дастfeature_numразные веса。Если его нужно разбить на разные элементыразные веса,То есть сжатый в(batchsize, 1, dim)форма,Сделайте взвешивание еще раз,Лично я считаю, что никакой проблемы нет. Это эквивалентно присвоению разного веса разным элементам. Конечно, если вы хотите придать ему форму сетки ворот, вы также можете,Это поколение(batchsize, feature_num, dim)изtensorСделайте взвешивание еще раз。 - Поскольку она только взвешивается, а не суммируется, теоретически возможно ли узнать эту информацию в MLP. Будет ли это лишним? Ответ: Теоретически эту информацию о весе действительно можно узнать в MLP. Как и в случае с теоремой об универсальной аппроксимации, нельзя сказать, что MLP теоретически может все, поэтому я просто использую MLP и ничего больше. В конце концов, в случае ограниченных данных искусственное добавление некоторых сложных структур Модели к предыдущей может помочь Модели лучше подойти. Так что не лишним будет это сделать. Надо попробовать, чтобы посмотреть, есть ли эффект. Не исключено, что в некоторых сценариях разницы между добавлением и не добавлением (головы собаки) не будет.
наконецПодвести итогодин раз,Стили SENet можно добавить в любую сеть.,Если вы хотите присвоить разный вес разным элементам в определенном измерении.。стоит отметитьиз Это здесьТолько взвешивание, без суммирования。А какой размер выбрать?(feature_numвсе ещеdim)Внизиз Элементам присваивается разный вес,Выбирайте, исходя из конкретного понимания бизнеса.
4. DIN
DIN — это модель, построенная Alibaba на основе характеристик поведения пользователей. То есть, когда последовательность действий пользователя (например, последовательность кликов) имеет несколько идентификаторов элементов, если для агрегирования используется объединение сумм напрямую, веса этих нажатых элементов будут одинаковыми по умолчанию. По аналогии с рисунком в главе 2 мы можем видеть, что когда область объектов (например, [Интерес]) имеет несколько функций, традиционным подходом является объединение сумм или объединение средних значений. Таким образом, веса этих функций по умолчанию будут одинаковыми. DIN нацелен на решение этой проблемы и считает, что разные функции должны иметь разные веса, и этот вес является интересом пользователя.
Поэтому, применяя DIN к нашему примеру, процесс выглядит следующим образом:
- Выберите домен объекта с несколькими функциями,Например [интерес],Выберите объект, который соответствует ему или связан с ним.,например【Тип элемента】。Тогда воспользуйтесь игройизembedding
(batchsize, 1, dim),и каждыйодининтересизembedding(batchsize, 3, dim)Входить“блок активации”получатьодинвесовое значение(batchsize, 3, 1),Представляет вес внимания. А что такое «блок активации»?,Вы можете обратиться к документам DIN,Это небольшая закрытая сеть,Конечно, здесь идея открыта. Вы можете попробовать различные способы реализации блока активации.,Структура статьи также не определена.

2. Затем замените предыдущую сумму полученным весом. Объединение в пул заменяется взвешенным суммированием для создания агрегированного внедрения, которое возвращается во всю структуру, как показано на рисунке ниже. Если выразить это в терминах арифметики, это, вероятно, будет так: a+b+cповышен до(0.7×a)+(0.05×b)+(0.25×c) Напротив, последний, очевидно, более элегантен, и эти веса автоматически рассчитываются моделью.

наконецПодвести итогодин раз,Кратко поговорив о структуре DIN, можно найти,По сравнению с SENet,Внимание DIN действует на слое «Внедрение данных».,На картинке это второй слой снизу вверх. Итак, с точки зрения понимания бизнеса,Внимание DIN не занимается «выбором функций».,Это небольшое обновление для объединения сумм.,让особенность表达изболее точный。вотвзвешивание, суммированиеиз。
5. POSO
Наконец, давайте поговорим о структуре POSO. По сравнению с двумя предыдущими, POSO, возможно, менее известна. «ПОСО: Personalized Cold Start Modules for Large-scale Recommender Systems》,Это документ, предложенный Куайшоу в 2021 году.,В основном это улучшение, предложенное на уровне модели для решения проблемы переполнения функций при холодном запуске. Возьмите MLP в качестве примера.,нравитьсяMLPиз Размеры512 * 256 * 256из。Мгновенный выбородин Люди думают, что это важнееизособенностьx^{pc}генерировать512、256、256три разныхиз Умножить на вес ВходитьMLPвнутри сети。

Если в нашем примере,Примерно так, как показано ниже,нравитьсяMLPиз Размеры512 * 256 * 128из。Выбиратьодин Я думаю, это важнееизособенность,Например [интерес]какx^{pc},Затем используйте 3 вентильные сети для создания 3 тензоров.,Они есть(batchsize, 512, 1)、(batchsize, 256, 1)、(batchsize, 128, 1)。здесьиз Закрытая сеть может бытьMLP+sigmoidформа。Конечно, вы также можете использовать свои собственные магические модификации.。наконец将получатьизтриtensorпутем умноженияформабрать ВходитьMLPВнутри сети,Добиться внимания на разных нейронах.

наконецПодвести итогодин раз,Хотя ПОСО вроде как уделяет внимание,Но он действует на нейроны,Он отличается от двух предыдущих. POSO — это не просто выбор функций.,Это стратегия улучшения функций. Итак, пока вы считаете, что определенная функция важна,Просто вытащите его и выровняйте.,Возможно, будет улучшение~
6. Резюме
Все три вышеупомянутые модельные структуры используют идеи, схожие с вниманием, так что же такое внимание? Цитируем исходный текст SENet:
В широком смысле внимание можно рассматривать как инструмент смещения распределения доступных ресурсов обработки в сторону наиболее информативных компонентов входного сигнала. Распределение смещено в сторону компонента с наибольшим объемом информации входного сигнала).
Моё личное понимание — «использовать всё наилучшим образом». В Интернете можно найти множество поговорок. Например, распространена поговорка, что «внимание» — это на профессиональном жаргоне слово «взвешенная сумма». Неплохо понимать это именно так. Что касается того, как это сказать и как это сделать, и научные круги, и промышленность, как правило, ориентированы на результат, а хорошие результаты – это путь к достижению!
Ссылки
SENet:http://dx.doi.org/10.1109/tpami.2019.2913372



Углубленный анализ переполнения памяти CUDA: OutOfMemoryError: CUDA не хватает памяти. Попыталась выделить 3,21 Ги Б (GPU 0; всего 8,00 Ги Б).

[Решено] ошибка установки conda. Среда решения: не удалось выполнить первоначальное зависание. Повторная попытка с помощью файла (графическое руководство).

Прочитайте нейросетевую модель Трансформера в одной статье

.ART Теплые зимние предложения уже открыты

Сравнительная таблица описания кодов ошибок Amap

Уведомление о последних правилах Points Mall в декабре 2022 года.

Даже новички могут быстро приступить к работе с легким сервером приложений.

Взгляд на RSAC 2024|Защита конфиденциальности в эпоху больших моделей

Вы используете ИИ каждый день и до сих пор не знаете, как ИИ дает обратную связь? Одна статья для понимания реализации в коде Python общих функций потерь генеративных моделей + анализ принципов расчета.

Используйте (внутренний) почтовый ящик для образовательных учреждений, чтобы использовать Microsoft Family Bucket (1T дискового пространства на одном диске и версию Office 365 для образовательных учреждений)

Руководство по началу работы с оперативным проектом (7) Практическое сочетание оперативного письма — оперативного письма на основе интеллектуальной системы вопросов и ответов службы поддержки клиентов

[docker] Версия сервера «Чтение 3» — создайте свою собственную программу чтения веб-текста

Обзор Cloud-init и этапы создания в рамках PVE

Корпоративные пользователи используют пакет регистрационных ресурсов для регистрации ICP для веб-сайта и активации оплаты WeChat H5 (с кодом платежного узла версии API V3)

Подробное объяснение таких показателей производительности с высоким уровнем параллелизма, как QPS, TPS, RT и пропускная способность.

Удачи в конкурсе Python Essay Challenge, станьте первым, кто испытает новую функцию сообщества [Запускать блоки кода онлайн] и выиграйте множество изысканных подарков!

[Техническая посадка травы] Кровавая рвота и отделка позволяют вам необычным образом ощипывать гусиные перья! Не распространяйте информацию! ! !

[Официальное ограниченное по времени мероприятие] Сейчас ноябрь, напишите и получите приз

Прочтите это в одной статье: Учебник для няни по созданию сервера Huanshou Parlu на базе CVM-сервера.

Cloud Native | Что такое CRD (настраиваемые определения ресурсов) в K8s?

Как использовать Cloudflare CDN для настройки узла (CF самостоятельно выбирает IP) Гонконг, Китай/Азия узел/сводка и рекомендации внутреннего высокоскоростного IP-сегмента

Дополнительные правила вознаграждения амбассадоров акции в марте 2023 г.

Можно ли открыть частный сервер Phantom Beast Palu одним щелчком мыши? Супер простой урок для начинающих! (Прилагается метод обновления сервера)

[Играйте с Phantom Beast Palu] Обновите игровой сервер Phantom Beast Pallu одним щелчком мыши

Maotouhu делится: последний доступный внутри страны адрес склада исходного образа Docker 2024 года (обновлено 1 декабря)

Кодирование Base64 в MultipartFile

5 точек расширения SpringBoot, супер практично!

Глубокое понимание сопоставления индексов Elasticsearch.

15 рекомендуемых платформ разработки с нулевым кодом корпоративного уровня. Всегда найдется та, которая вам понравится.
