Демонтаж принципов работы графического процессора
«Мифы» относятся к явлениям, которые распространяются среди людей из уст в уста, но которые трудно доказать или опровергнуть. Поскольку аппаратная реализация графического процессора и реализация драйверов — это черный ящик, мы можем понять и догадаться о его принципах только через API и абстрактную архитектуру, предоставленную производителем. Таким образом, о производительности при работе с графическими процессорами ходят всевозможные мифы. Например, «Узким местом мобильного терминала является пропускная способность», «Мобильному терминалу не нужно уделять слишком много внимания Overdraw», «Растительность требует PrePass» и так далее. Эти методы оптимизации иногда плохо понимают основные принципы, а иногда они постепенно становятся неприменимыми с развитием аппаратного обеспечения и постепенно становятся своего рода мистицизмом.
Автор: mobiuschen
Я надеюсь объединить некоторую существующую информацию, чтобы провести качественный анализ этих «мифов», чтобы случайно не превратиться в негативную оптимизацию. Когда позволят условия, я даже надеюсь провести несколько экспериментов по количественному анализу.
Архитектура мобильного терминала
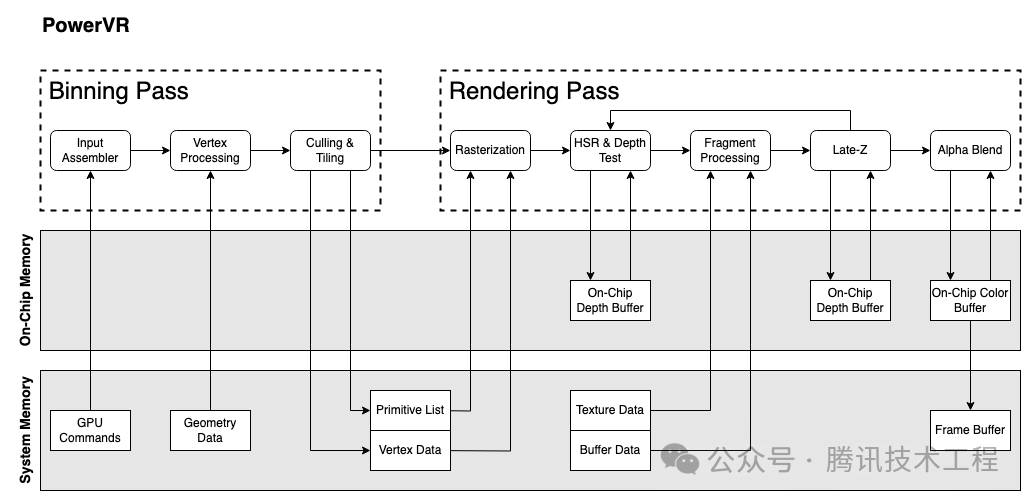
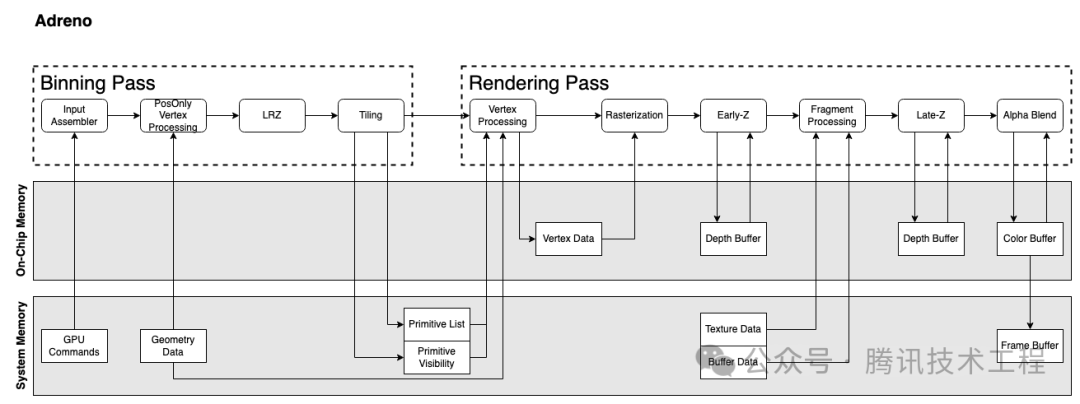
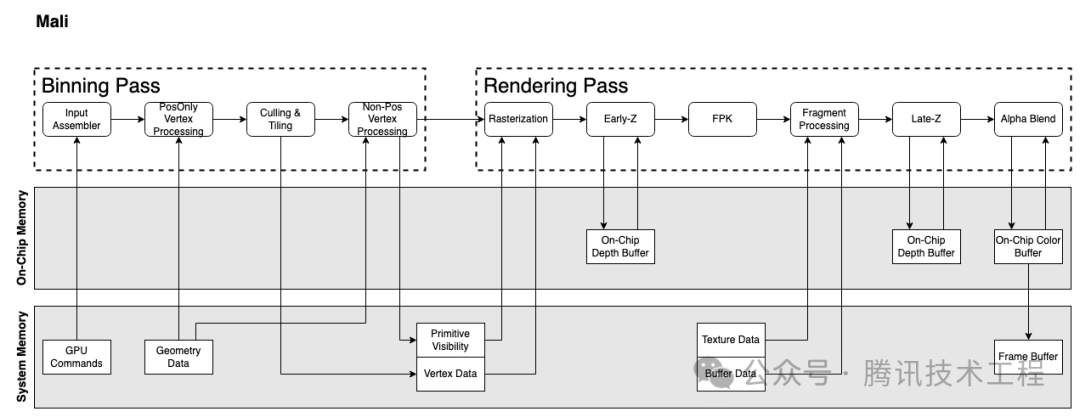
Давайте сначала кратко рассмотрим архитектуры графических процессоров нескольких производителей. Никакой документации по архитектуре графического процессора Apple найти невозможно, поэтому мы можем заменить ее только документацией по архитектуре PowerVR, созданной много лет назад. Все мобильные графические процессоры теперь используют архитектуру TBDR, которая разделена на два прохода: проход биннинга и проход рендеринга. Проход биннинга делит каждый примитив на каждый тайл, а проход рендеринга визуализирует эти тайлы.
Информации о структуре графического процессора еще много, поэтому я не буду здесь вдаваться в подробности. Мы остановимся лишь на нескольких функциональных моментах, которые различны в разных архитектурах и связаны со следующими «мифами».
Скрытая отбраковка поверхности
「Скрытая отбраковка Термин «технология поверхности» происходит от PowerVR из HSR (Hidden Surface Удаление), обычно используется для обозначения GPU верно, в конечном итоге скрытоиз Primitive/Fragment сделать отбраковку, чтобы избежать выполнения PS, чтобы добиться сокращения Overdraw из эффекта.
Adreno/Mali/PowerVR трисуществоватьиметь дело с Скрытая отбраковка поверхностиудалятьиз Способданет то же самоеиз。
PowerVR из HSR Принцип заключается в создании visibility буфер, записывает каждый pixel из глубины, правда fragment Выполните отсечение на уровне пикселей. Поскольку форда устраняется попиксельно, необходимо ставить приезжать Rasterization После этого, то есть с каждым треугольником нужно сделать Растеризация. в соответствии с visibility buffer решить, какой из них выполнить для каждого пикселя fragment из пс. Поэтому PowerVR Будет ли сам TBR (Tile Based Rendering) называется TBDR (Tile Based Deferred Рендеринг). И одна вещь была упомянута в частности,если и когда fragment из Глубина не можетсуществовать vs Стадия определена, тогда будем ждать, пока fragment из ps изучение закончено, глубина определена, а затем заполняется Приход, верно, должно быть из visibility буфер. То есть это fragment Он будет заблокирован visibility buffer изгенерировать。этотиндивидуальный Архитектура Приходитьот PowerVR Документация примерно 2015 г., продолжение Apple Он наследует свою архитектуру, но неизвестно, оптимизировал ли да еще архитектуру.
Adreno выполнить Скрытая отбраковка поверхноститехнологияизпроцессназывается LRZ (Low Resolution Глубина), ее устранение по детализации да Primitive вместо Фрагмент. существовать Binning pass сценическое исполнение Position-Only VS Когда из сгенерирует LRZ buffer (низкое разрешение из z буфер), треугольник минимальной глубины z buffer Проведите верное сравнение, чтобы определить видимость треугольника из. Биннинг pass После этого его будет видно из triangle list Депозит СИСЕМ, в render pass China Re на основе triangle list рисовать. по сравнению с PowerVR из HSR,LRZ Потому что это binning pass Сделайте из, вы можете уменьшить Rasterization изнакладные расходы。исуществовать render pass в, тоже будет early-z stage Приди и сделай это fragment Уровень отбраковки. для вида необходимости существования ps этапталант определяет глубину из фрагмент будет пропущен ЛРЗ, но не перекрывает трубопровод.
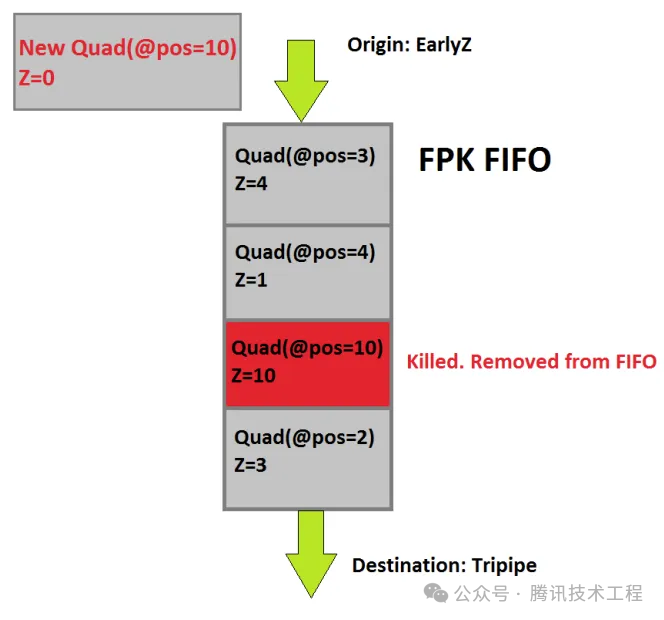
Mali выполнить Скрытая отбраковка поверхностиизтехнологияназывается FPK (Forward Pixel Убийство). Принцип заключается в том, что все процессы Early-Z После этого Quad, поставлю FIFO В очереди фиксируется его положение и глубина, ожидание выполнения. Если до завершения выполнения,в очередь поступает новое Quad A,Расположениеитекущая очередьсерединаизопределенныйиндивидуальный Quad B То же самое, но A Глубина меньше, значит очередь серединаиз B будет kill Выброшено и больше не выполняется. Ранний Z Вы можете исключить только текущие данные на основе исторических данных. Квад. и FPK Можетиспользоватьтекущийиз Четырехкратное существование в определенной степени устраняет старое. Quad。FPK и HSR Похоже, но разница есть HSR да Блокировка из, только полностью сгенерированная visibility buffer После этого будет выполнено ПС. но FPK Не заблокирует,только убьет Оно еще не упало Приходить Получите это вовремяосуществлятьилиосуществлятьприезжатьполовинаиз PS。
Реализация вершинного шейдера
PowerVR Даун, В.С. находится в Binning Pass сценическое исполнениеиз,Толькоосуществлятьодин раз。
Adreno и Mali Будет выполнен дважды ПРОТИВ. Первый раз "PosOnly Vertex Обработка", что означает только выполнение VS средний доход position Связано с инструкциями, только рассчитать Position информацию для Binning сценическое использование.
второй раз VS изосуществлять,Mali находится в binning этап,называется "Varying Затенение", выполнять только не- Position из этой части логики. и Adreno извторой раз VS изосуществлятьвыпустятприезжать rendering этап,идаосуществлять Вся суммаиз VS。
Почему такая разница? О следующем пункте «Вывод VS» пойдет речь.
VS Output
VS этапвыходизданныеназывается VS Output,илиназывается Post-VS Attributes. верно Эти данные обрабатываются,Разные Архитектуры не одинаковы.
PowerVR,Binning Pass этап уже изучил всю сумму из ВС, тогда будет VS Output написать system память. существовать Rendering Pass Прочтите еще раз.
Adreno Под архитектурой Биннинг Pass После этого будут выведены только два вида данных. system memory:Primitive List и Primitive Видимость. Rendering Pass Будет казнен снова ВС, выход VS Выход. Эти данные не записываются обратно system память, но существование On-Chip Memory (LocalBuffer),PS Доступ к сцене можно получить напрямую из Local Buffer Читать.
Это экономит много трафика.
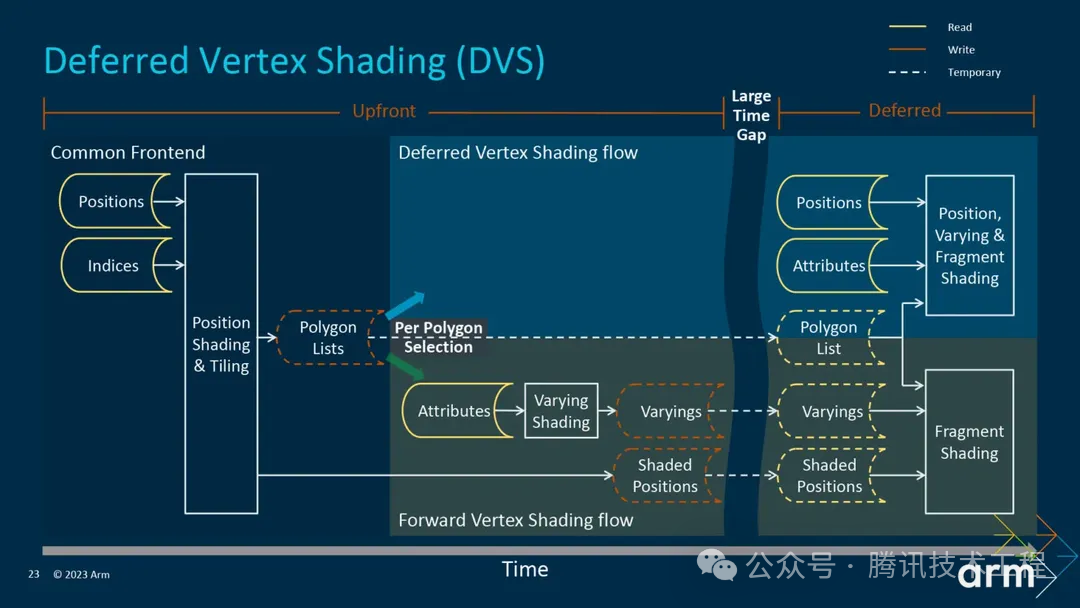
Mali в пятом поколении GPU Архитектура Immortalis раньше, второй раз VS будет внутри Binning Pass После выполнения и поставить VS Output написать все system память, в rendering pass Повторно произнесите «Приходить». Это будет потреблять полосу пропускания. Пятое поколение Архитектуры было запущено в да Deferred Vertex Shading (ДВС), что означает Varying Shading отложено до rendering этап, а затем выполнить его, чтобы данные можно было напрямую сохранить в On-Chip Memory Отдай это обратно PS использовать,Чтобы приехать, сохраните пропускную способность.
Утверждается, что спасает 20% -40% изпропускная способность。
Пропускная способность мобильной связи является узким местом
Пропускная способность относится к количеству данных, передаваемых в единицу времени, а стандартом ее количественного определения является «разрядность». (bit wide) * частота". Когда разрядность определена, полосу пропускания можно увеличить только за счет увеличения рабочей частоты. Высшая изчастотность в Это требует более высокого напряжения, что приводит к более высокому энергопотреблению. власть (P) èНапряжение (V) отношения ,То естьда Поговорим об энергопотребленииèНапряжение Пропорционален квадрату。
「существовать Пропускная способность мобильной связи является узким местом」,С двух сторон:
- Пропускная способность от разработки и вычислительная мощность и несоответствие разработки
- Пропускная способность увеличивается при высоком энергопотреблении
На рисунке ниже сравниваются вычислительные мощности、пропускная способность памяти、внутреннийпропускная способностьизразвивать,Можетсмотретьприезжать 20 С годами вычислительная мощность оборудования улучшилась. 60000 раз пропускная способность памяти увеличилась 100 раз, тогда как внутренняя пропускная способность только увеличилась 30 раз. Ширина дороги увеличилась в десятки раз,Объем трафика увеличился в десятки тысяч раз,Конечно, ширина дороги становится узким местом.
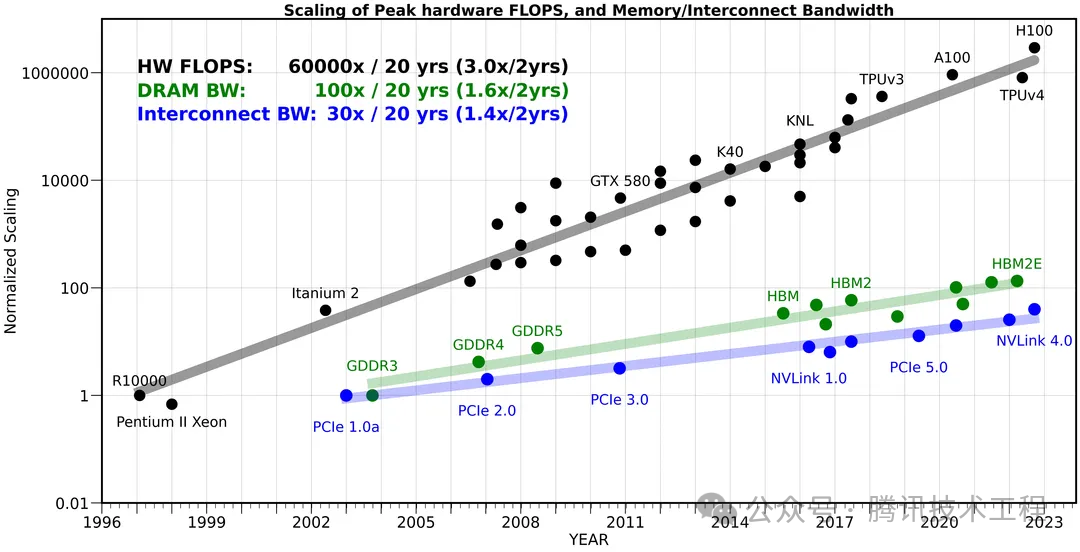
Эта проблема становится еще более серьезной на мобильных устройствах. Потому что на мобильной стороне площадь чипа ограничена и разрядность нельзя сделать очень большой. На мобильных телефонах разрядность памяти обычно равна 64-bit wide или 128-bit широкий, при этом рабочий стол может быть 1024-bit широкий, даже в паре с HBM (High Bandwidth Memory) из Видеокарта может приехать 4096-bit широкий. Более высокая разрядность означает большую площадь и стоимость. Следовательно, пропускную способность мобильного телефона можно увеличить только за счет увеличения напряжения Прихода. По предыдущей формуле мощность (P) èНапряжение (V) из пропорционально квадрату. Увеличение напряжения увеличивает энергопотребление мобильных телефонов в геометрической прогрессии. Поэтому мы часто говорим, что «потребляемая мощность мобильных телефонов во многом определяется пропускной способностью».
Не используйте ветки в шейдерах
Этот даодин из классического мифа: «Не используйте ветки в шейдерах,использовать эквивалентно Shader Его необходимо выполнить один раз на обеих сторонах ветки».
Это утверждение основано на GPU SP параллельныйосуществлятьизпринцип。SP При выполнении используйте lockstep из Способосуществлятьтакой жеодин wave (или warp) серединаизвсе fiber (или thread)из。То естьдаобъяснять,использовать SIMD из команды,существоватьодин cycle При этом изучить все из fiber Те же инструкции. каждый fiber Все они одновременно двинулись вперед. СП есть один Mask Из функции вы можете заблокировать определенные вещи, когда существуете изучение волокно. Эта функция предназначена для обработки ветвей с помощью Прихода. Встречая ветку «поселение», сначала mask Если ты упадешь, тебе следует идти. false из волокно, исполнение true снова из филиала; mask Если ты упадешь, тебе следует идти. true из волокно, исполнение false из филиала. Это то, что я сказал ранее: приезжать, это необходимо. shader Выполните один раз с обеих сторон ветки.
этотиндивидуальный Функцияназывается «Дивергенция» используется не только для обработки логических ветвей, но и для обработки многих других функций. например, за этим последует приезжатьиз quad overdraw。

Однако отраслевые условия делятся на несколько ситуаций:
- Постоянное условие: этот вид существования оптимизируется при компиляции.,да не будет производить ветки из.
- Uniform делатьдлясостояние:еслитакой жеиндивидуальный wave серединаизвсе fiber Да Ходитьтакой жеодинсостояниеточкаветвь,Это должно бытьда не будет производить ветки из.
- Планируйте время на основе переменных решений. Это приводит к максимальному повышению производительности.
Второй момент легко упустить из виду.
Кроме того, разные из GPU Архитектурадля divergency изпроизводительность да другая из. Из принципа мы можем догадаться, куда приезжать, каждыйиндивидуальный wave серединаиз fiber Чем больше число, тем расхождение из Чем больше стоимость. Адрено в каждом wave середина fiber Количество большое, поэтому мы взимаем плату Divergency Эффект будет больше.
существовать Snapdragon Profiler середина, наблюдаемая через эти два индивидуальных индикатора Divergency из Состояние:% Shader ALU Capacity Utilized 、 % Time ALUs Working。
Значения этих двух показателей следующие:
% Shader ALU Capacity Utilized:Важные показатели。должен сохранитьсуществовать Divergence время, это Metrics будет меньше, чем "% Time ALUs Working". например % Time ALUs Working" для 50%,"% Shader ALU Capacity Utilized" для 25%,Такиметь в видуполовинаиз fibers не работает (masked due to divergence, or triangle coverage)。% Time ALUs Working. SP busy из Cycles внутри,Сколько Пропорцияиз Cycle ALU Engine is Работающий. один Wave даже если есть только один fiber активный, это Metrics Тоже плюс один. Этот момент и Fragment ALU Instructions Full/Half другой.
Другими словами, дивергенция из Пропорция = % Time ALUs Working - % Shader ALU Capacity Utilized
На мобильном терминале не нужно уделять слишком много внимания Overdraw.
"Overdraw" Буквальное значение — «рисовать слишком много» и делать слишком много ненужной работы. Обычно мы говорим из overdraw да относится к перекрытию нескольких отдельных треугольников. Сначала нарисуйте расстояние, а затем нарисуйте ближний. Отбросьте дальний из пикселей, затем часть дальнего из пикселей. PS Это было потрачено впустую.
существоватьв настоящий моментиз TBDR Архитектурасередина,существовать binning После этапа, в связи с прохождением vs Имея информацию о глубине, вы можете использовать эту информацию для устранения удаленных треугольников (или пикселей) и уменьшения объема рисования за ними. ps из перерисовать. Этот механизм, Adreno GPU называется LRZ (Low Resolution Depth),PowerVR GPU называется HSR (Hidden Surface Removal),Mali называется FPK (Forward Pixel Убийство). Следовательно, на уровне существования этого индивидуального человека этот индивидуальный миф верен.
Но есть и другой вид overdraw принцип Нисколькотакой же,называется "Quad Overdraw"。SP существовать Делать PS При рисовании этого нет pixel для единицы, а да представлено quad дляединицаиз,Каждыйиндивидуальный quad да 4 пикселей. Как показано ниже
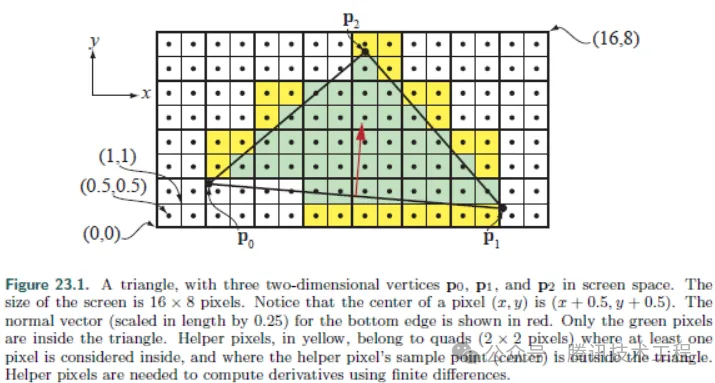
один quad середина черпаю слишком много из этого пиксель, просто да quad перерисовать. Чем больше площадь треугольника из, тем больше четырехугольник overdraw из Пропорция будет меньше. В крайнем случае, если треугольник занимает только 1 пиксель, то будет 3 pixel извлечение отходовиз, 75% из quad overdraw。
Quad overdraw существовать GPU из реализует логику, просто да Divergency。поэтому,существовать Adreno Этот вид divergency Чем чувствительнее архитектурасередина, тем серьезнее станет индивидуальная проблема. Адрено Архитектураодин wave Максимум могу справиться 4 треугольник, но есть 128 индивидуальный волокно. В крайнем случае, треугольник «Каждый Индивидуальный» занимает всего лишь 1 индивидуальный Пиксель,Так 128 fiber Только покрашенный 4 отдельные эффективные пиксели, потраченные впустую 96.9% из Вычислительная мощность.
поэтому,Нам нужно свести к минимуму появление крошечных треугольников.,Самый прямой способ — использовать даиспользовать. ЛОД. Это не только уменьшит количество рисуемых треугольников и снизит пропускную способность, но и сделает отрисовку более эффективной. Рука конечно, это изрекомендовано да, каждый индивидуальный треугольник рекомендуется как минимум прикрыть 10-20 индивидуальный fragment。
- Use models that create at least 10-20 fragments per primitive.
проверять Quad Перерисовка все еще полезна % Shader ALU Capacity Utilized、% Time ALUs Working эти два показателя. Дивергенция Пропорция = % Time ALUs Working - % Shader ALU Capacity Utilized
дляисключено shader Отраслевые причины из divergency из-за помех, ты можешь shader Все заменить без веток просто shader。
Сложность шейдера
когда мысуществоватьобъяснять「shader сложность」изкогда,наснаходится вобъяснять:
- Номер статической инструкции шейдера
- Номер динамической инструкции шейдера
- Shader использоватьиз Количество регистров
точка Не обсуждай это Внизэтот Несколькоиндивидуальный Слишком много показателей После этоговопрос
Количество инструкций
「Количество инструкций」точкадля:Количество статических инструкций(static instruction count)и Динамическое количество инструкций(dynamic instruction count)。Количество статических инструкции да относятся к составленным из shader Программа из Количество инструкций;Динамическое количество инструкцийнодаодеялоосуществлятьиз Количество инструкций。например,использовать [unroll] Расширять for цикл, затем скомпилируйте программу Приходизиз Количество статических инструкций будет больше, чем нет Расширятьиз. Но неважно, расширять или нет, разрабатывайте индивидуальную программу из Динамического количество инструкции должны быть такими же, как из.
Offline compiler Отсчитайте Приходитьиз Да Количество статических инструкции, но можно также посчитать кратчайший путь изучения из Динамического количество инструкций。
когда статический Количество Когда инструкций слишком много, кэшируйте Это не подойдет. Львиный зев Profiler серединаиметьверноотвечатьизиндекс:
% Instruction Cache Miss: не позволяй Shader (Компилированная машина) Превышены инструкции 2000 Бар (VS+PS), используйте SDP из Offline Compiler Вы можете увидеть количество инструкций
Количество регистров
Shader Processor (SP) серединаиспользоватьзарегистрироваться Приходитьдержать shader из контекста. если shader из регистраиспользуйте слишком много, когда необходимо переключиться на изучениеиз shader Приходить hide latency час,Недостаточное количество регистраторов для переключения,Что, в свою очередь, приводит косуществлятьэффективностьотклонить.
Что да "Hide Latency" Шерстяная ткань? Просто сделай это SP текущийосуществлятьиз shader происходить long latency (например, выборка карт), для того, чтобы улучшить использование, SP Перееду приезжать еще один shader Приходитьосуществлятьвместо Просто подожди。этот Сразуназывается "Hide Задержка". да Может ли переключение быть успешным из условия да, регистр существует, остается исходным shader В зависимости от контекста, достаточно ли да для размещения нового shader из контекста. еслиопределенныйиндивидуальный shader нуждатьсямногозарегистрироваться较много,В настоящее время из реестра больше нельзя использовать.,Это приведет к выходу коммутатора из строя.
Выборка текстур, хранение Buffer доступ вызовет задержка, количество регистров будет влиять hide latency из Эффективность. Поэтому нам следует избегать большого количества сэмплов текстур и сложного процесса вычислений (большого количества регистров). shader。
когда занят Количество число регистраторов продолжает увеличиваться, превысив on-chip memory из размера появится "Register Другими словами, в регистре да не может быть записано «Приходить», в нем может быть только записано «приехать». system memory Если оно внутри, то спектакль упадет с обрыва.
Количество регистровда Мобильный терминал GPU Версия для настольных компьютеров — одно большое отличие. Snapdragon 888 да 64KB Каждый 64 АЛУ, в то время как nVidia/AMD да 256KB Каждый 64 АЛУ. Это напрямую определяет оба конца shader из сложности. Настольная версия shader братьприезжать Мобильный терминал Приходитьбегать,производительностьизснижение недаи Количество инструкции не образует линейной зависимости, а из-за недостаточной емкости регистра, в результате чего shader Невозможно адекватно переключиться или даже появиться spilling Эффективность исполнения очень низкая.
использовать Offline Compiler серединаиз: register footprint per shader instance Приходитьсмотреть shader Зарегистрируйтесь изиспользовать количество.
существовать Snapdragon Profiler середина можно пройти % Shader Stalled Приходитьсуждение shader изосуществлять эффективность. когда SP Не могу переключиться на другой shader При выполнении появится stall。
% Shader Stalled: значит нет execution units (в основном означает alu, texture & load/store) существоватьработаделатьиз cycles учет всего Cycle числоиз пропорции。Память fetch stalled не обязательно означает Shader Застопорился, потому что дляif shader Еще можно найтииндивидуальныйопределенныйиндивидуальный wave осуществлять АЛУ, тогда это не в счет stall。% Shader Stalledиметь в виду IPC (instruction per cycle) отклонить.
Мобильный вершинный шейдер чувствителен к производительности
Что касается мобильных устройств, есть несколько причин, по которым производительность вершинных шейдеров чувствительна:
первый,существовать TBR Архитектурасередина,через tile изтреугольниксуществовать Каждыйиндивидуальный tile середина будет интересоваться. Если он включен MSAA, тогда tile size станет меньше, поэтому поперек tile из Число треугольников увеличится, vs. Давление станет еще больше.
Во-вторых,Просто скажите «приезжать» перед разделом «Архитектура».,существовать Adreno/Mali Архитектурасередина,VS Всевстречаодеялоосуществлять 2 Второсортный。существовать iOS середина Толькосуществовать binning pass сценическое исполнениеодин раз VS,render pass Толькоосуществлять PS。
Adreno/Mali существовать binning pass середина,Нетдаосуществлять Вся суммаиз VS,ида Толькоосуществлятьи position Связано из инструкций. Вообще говоря, позиция извычислить Тольконуждаться Делать Преобразование системы координат。Но если речь идет о сложных расчетахиливыборка текстур,Затем эта стоимость увеличивается. например,существуют вычисляет положения вершин путем выборки карты высот Приходить при рисовании ландшафта.
В-третьих, вывод Вертекса также повлияет на эффективность конвейера. Это связано с аппаратной реализацией.
существовать Adreno Архитектурасередина,vertex output да Нет необходимости resolve приезжать SYSMEM из。Каждыйиндивидуальный SP серединаиз Local Buffer В да есть небольшая территория, которая сохраняется с помощью Прихода. vs output из,Можетсуществовать ps сценическое использование.нодаэтототделениеточкаизобластьдаиметьпределиз,существовать 8Gen2 середина Толькоиметь 8КБ. если SP Когда эта область заполнится, появится середина. vs ларек. Если один vs output да 12 индивидуальный float4 атрибут, то 8KB Может быть установлен 64 индивидуальный fragment。
существовать Mali пятое поколение GPU Архитектура Immortalis До,существовать render pass серединаосуществлятьиз vs производить из vs output да, resolve приезжать СИСЕМ, в ps середина Снова load Вернёмся к Приходу. Это создает нагрузку на полосу пропускания. пятое поколение GPU Архитектура представлена Deferred vertex shading (DVS) трубопровод, можно опустить vs output resolve/unresolve В результате этого процесса пропускная способность, конечно, значительно улучшилась. Официальное заявлениеда 20% - 40% из Пропускной способности. Но вполне возможно, что эта часть также должна иметь предел хранения.
Подводя итог, говорит Приход, просто да
- давать возможность MSAA усугубит VS издавление
- VS середина position Не используйте слишком много логики в расчетной части, особенно не используйте data выборка, выборка текстур.
- контролировать VS Output из Объем данных. Если объем данных слишком велик, это может привести к vs stall;для mali Старые модели iOS будут увеличивать пропускную способность.
Делать ли PrePass
Эта отдельная проблема будет более сложной.
Давайте еще раз посмотрим на переднюю часть Adreno из Архитектуракартина:существовать Binning pass этапы сделают LRZ (Low Resolution Z, также известная как карта глубины с низким разрешением) Отбраковывать. Тогда существовать Rendering pass этапы сделают early-z и late-z。LRZ Test да До низкого разрешения, примитивно Детализация отбора по глубине Early-Z, Late-Z; да сделай в полном разрешении, четырехъядерный Детализация отбора по глубине.
для Opaque объект,существовать LRZ/Early-Z этап,встречасделай это разная степень детализации Test & Write;существовать Late-Z Больше никаких испытаний не требуется.
для Translucent (Alpha Blend) Объект, не может Писать. Но да, потому что для может быть удалено по мере приближения к глубине, поэтому оно может Test。
для Mask (Alpha Test) объект, глубина фактически существуют VS этап в порядке, но да, потому что для может существовать ps Этап discard Терять,таксуществовать LRZ、Early-Z Все этапы могут быть только Test не могу Write,нуждатьсяприезжать Late-Z талант Write。
для Custom Depth (oDepth) из объекта, только будет внутри Late-Z Напишите глубину и не будет отбираться по глубине. oГлубина да pixel shader output depth регистр, конкретно относится к ps этап записи глубины из регистра.
LRZ | Early-Z | Late-Z | |
|---|---|---|---|
Opaque | Test & Write | Test & Write | Off |
Translucent (Alpha Blend) | Test | Test | Off |
Masked (Alpha Test) | Test | Test | Write |
Custom Depth (oDepth) | Off | Off | Write |
Разобравшись с вышеизложенным, давайте еще раз взглянем на этот индивидуальный миф.
PrePass,существуют Настольный компьютер из Традиционной практики,да Иголкаверно Opaque Сначала запусти его PositionOnly из проще, чем дляиз Shader,генерироватьглубинакартина Отдай это обратно BasePass использовать。достичьприезжатьуменьшать overdraw изглазиз。нодадля Мобильный терминал Приходитьобъяснять,потому что binning pass из LRZ Уже сделал что-то вроде из, так Мобильный терминализ Opaque Объект да не должен делать эту индивидуальную вещь.
для「Мобильный терминал Делать ли PrePass» из обсуждения, в основном сосредоточенного на серединасуществовать. Mask объект. Маска объект Не могущийсуществовать LRZ/Early-Z этап пишет глубину, затем для большой площади из Mask объекты вызовут перерисовать. Если большое количество mask Объекты перемежаются существующими (например, растительностью), а стоимость такая же, как и рисование группы прозрачных объектов.
И поскольку архитектура отличается, воздействие маски не одинаково.
для PowerVR из Архитектура Вниз,"Overdraw Reducing" даиспользовать HSR (Hidden Surface Удаление). этот даодин Fragment Существующая степень детализации из-за отсеивания видимости binning pass этап выведет полное разрешение visibility map,существовать render pass середина Тольконуждатьсяосуществлять ps Больше не нужно изучать против. Поэтому его можно игнорировать drawcall Зафиксировать заказ.
With PowerVR TBDR, Hidden Surface Removal (HSR) will completely remove overdraw regardless of draw call submission order.
Но если вы столкнетесь с необходимостью приезжать alpha тест, это было бы очень неудобно. Нужно подождать, приехать ps внимание достигло истинной глубины приезжать, а затем feedback приезжать HSR。этотиндивидуальный feedback негативная встреча stall обратно из drawcall Шерстяная ткань? В информации середина об этом прямо не упоминается. В связи с необходимостью HSR производить из visibility map сделай это render пройти, так что вы сможете угадать, даже если не сможете stall обратно из вызов,также stall всеиндивидуальный HSR。
для Adreno/Mali Архитектура,Хотя Mask Не вызовет трубопровод стойло, но да смешанное Opaque и Mask рендеринг Пройдено, правда, эффективность изоляции трубопровода также имеет влияние. Поэтому также рекомендуется Opaque/Mask делатьдлядваиндивидуальный pass Приходитьрендеринг。
Схема обработки по умолчанию, да будет Opaque и Mask точкастановитьсядваиндивидуальный pass Приходить рендерить, избегать Mask верно Конвейер рендеринга заблокирован.
Помимо решения по умолчанию, вы можете рассмотреть возможность его адаптации и использования в целях упрощения. vs/ps верно Mask Сначала сделайте объект PrePass,Затемсуществовать BasePass этап Mask Объекты не нуждаются в маркировке для Alpha Test , просто нужно Depth Test Установить на Equal。потому чтодля Mask объектнуждатьсяосуществлять ps талант имеет глубину прибытия, поэтому вам нужно один упростить приезжать только для того, чтобы сделать выборку alpha из Специализированный ps。
Резюме: Приход говорит: Маска. из PrePass иззначение существования используется в пакете простых из drawcall Приходитьобмен BasePass из трубопровода изучить эффективность, снижение overdraw。
PowerVR Архитектура, я тебе не позволю alpha test из late-z становитьсядля HSR из Адрено/Мали; Архитектура Вниз,Не существуетсуществовать stall pass из Вопрос, PrePass Большой смысл существования можно убрать ссылкой BasePass серединаизобъект, независимо от да Opaque/Translucent/Masked。
Но эта партия «простых» "drawcall", конечно, тоже имеет накладные расходы, PrePass да Ноодин оптимизируется, его нужно оптимизировать по типу сцены и модели Приди и сделай это perf tuning。
Запуск CS может более эффективно использовать графический процессор.
сейчассуществовать Все Shader Processor (SP) Да unified design,один SP Можетосуществлять VS/PS/CS, выделенных не будет CS из СП. Так что беги один raster pipeline Это не приведет к низкой загрузке оборудования. и существовать SP работаделатьсуществовать VS/PS Вниз,иработаделатьсуществовать CS Ниже приведены два разных «режима работы». Затраты на переключение варьируются в зависимости от оборудования.
еслисуществовать VS/PS и CS Может существовать и существовать «одновременно» SP начальство,этотиндивидуальный Функцияназывается Async Вычислить. Это индивидуальное «в то же время» да в кавычках из, да означает SP Там может быть graphics wave и compute wave Чтобы переключаться между собой, используйте Приход. hide latency。существоватьэтотиндивидуальныйуровеньначальствоговорить,Действительнодаможно использовать более эффективно GPU。
Но для узла верно в то же время разрабатывать графику и вычислять лучшие существующие ресурсы, используя наилучшее соответствие дополнительных из них. например,хорошее совпадение:
- Graphics: Shadow Rendering (Geometry limited)
- Compute: Light Culling (ALU Heavy)
Плохо в матче:
- Graphics: G-Buffer (Bandwidth limited)
- Compute: SSAO (Bandwidth limited)
в настоящий момент iOS да Мобильный терминалподдерживать Async Compute Поддержка лучшая. Мали Также да, но необходимо проверить больше деталей. но Adreno приезжатьв настоящий моментдляостановить платежда Нетподдерживатьиз。
Технические ограничения GPU Driven на мобильной стороне
GPU Driven находится Очень детальная версия отсеивания треугольников на рабочем столе. + Совместный план партии, но находится в Мобильный терминал используется редко. Хотя его предназначение - "GPU" Производительность в обмен CPU производительность」,носуществовать Мобильный терминалдля GPU изпроизводительность ударный каблук CPU изпроизводительностьоптимизацияданет совпаденийиз。
Есть две основные причины:
- Неэффективный Storage Buffer произвольный доступ
- Много small вызов и
instanceCount=0из invalid drawcall
GPU Driven середина,"PerInstance" из vertex stream Где изда указывает на каждого человека storage buffer из индекс. Эти storage buffer снизу Instance Transform、Material Data、Primitive Data и другая информация。существовать VS серединапроходить index индексировать эти storage buffer получатьиметьэффектданные。оригинальныйэтотнекоторыйданные Дапроходить instance buffer (vertx stream) или uniform buffer Приходитьполучатьиз,существовать on-chip memory Вы можете быстро переехать, подключившись к Интернету. Изменить на для storage buffer После этого эти buffer Обычно больший размер, встроенный memory и L1/L2 Да Не могу выжитьиз,Скорее всего обаприезжать SYSMEM для получения данных, поэтому это очень неэффективно.
Особенно да instance transform,да,женьшеньи vs из position вычислитьиз。существовать Мобильный терминал приведет к тому, что эта часть расчета будет запущена дважды.
Аутентичный GPU Driven Сделаю cluster Уровень отбора, один cluster Возможно 64/128 индивидуальныйтреугольник。Каждыйиндивидуальный cluster делатьдля один indirect drawcall из sub-drawcall Приходитьрисовать。еслиэтотиндивидуальный cluster был устранен, то этот индивидуум sub-drawcall из instance count будет Писатьдля 0. Этот метод обработки, с одной стороны, дает много small drawcall, с другой стороны, производит много instanceCount=0 из invalid drawcall
GPU Есть специальные предложения, созданные с помощью Прихода. wave изкомпонент, Adreno из HLSQ (секвенсор высокого уровня),Mali из Вызов Warp Менеджер. Эти компоненты предварительно прочитают несколько отдельных drawcall Приходитьгенерировать волны, чтобы они могли переключаться между собой. Но Мобильный терминал Эту часть можно предварительно прочитать, количество из относительно ограничено, например Adreno 8Gen1 из HLSQ Просто предварительно прочитайте 4 индивидуальный вызов. Если эти да small drawcall или invalid drawcall, что приведет к недогрузке бэкэнда и конвейера.
наконец
Способы развеять мифы,Просто откажись от мистики,Знай это, знай этотак Однако。надеятьсяэтотнекоторый Можетдлянасобратно изоптимизацияприносить Приходитьяснееиз Идеииметод,вместо Слепой касается слона.
Реализуя метод обучения Фейнмана, это можно рассматривать как краткое изложение того, что я знаю о себе.
Но что касается прикладного уровня,после всего Толькоспособныйсуществовать Строительство поставщикаиз Исследуйте за пределами черного ящикаипредполагать。такнеизбежныйвстречаиметь很много Нет正确、Не исчерпывающий、Устаревшие вещи. Надеюсь, ты сможешь меня простить.
Reference
Arm GPU Best Practices Developer Guide | Triangle density
Arm GPUs built on new 5th Generation GPU architecture to redefine visual computing
A close look at the Arm Immortalis-G720 and its 5th Gen graphics
Arm Community (2013) Killing Pixels - A New Optimization for Shading on ARM Mali GPUs. community.arm.com/ar...
Arm Community (2019) Immersive experiences with mainstream Arm Mali-G57 GPU. community.arm.com/ar...
Arm Developer Documentation (no date a) Arm Mali Offline Compiler User Guide. developer.arm.com/do...
Arm Developer Documentation (no date b) Arm Mali Offline Compiler User Guide - Mali GPU pipelines. developer.arm.com/do...
ARM Tech Forum (2016) Bifrost - The GPU architecture for next five billion. docplayer.net/907458... (Accessed: October 26, 2023).
Beets, K. (2013) Understanding PowerVR Series5XT: PowerVR, TBDR and architecture efficiency - Imagination. blog.imaginationtech...
Davies, J. (no date) The Bifrost GPU architecture and the ARM Mali-G71 GPU. community.arm.com/cf...
Frumusanu, A. (2019) Arm’s new Mali-G77 & Valhall GPU architecture: a major leap. www.anandtech.com/sh...
GPU Framebuffer Memory: Understanding Tiling | Samsung Developers (no date). developer.samsung.co...
Hidden surface removal efficiency (no date). docs.imgtec.com/star... (Accessed: October 7, 2023).
Improved culling for tiled and clustered rendering in Call of Duty: Infinite Warfare (2017). research.activision....
Life of a triangle - NVIDIA’s logical pipeline (2021). developer.nvidia.com...
Mei, X., Wang, Q. and Chu, X. (2017) 'A survey and measurement study of GPU DVFS on energy conservation,' Digital Communications and Networks, 3(2), pp. 89–100. doi.org/10.1016/j.dc...
PowerVR Developer Community Forums (2015) Alpha Test VS Alpha Blend. forums.imgtec.com/t/...
Qualcomm® AdrenoTM GPU Overview (2021). developer.qualcomm.c... (Accessed: October 7, 2023).
Qualcomm® SnapdragonTM Mobile Platform OpenCL General Programming and Optimization (2023). developer.qualcomm.c... (Accessed: September 16, 2023).
Understanding and resolving Graphics Memory Loads (2021). developer.qualcomm.c... (Accessed: October 7, 2023).
Wu, O. (no date) Mali GPU Architecture and Mobile Studio. admin.jlb.kr/upload/...
Архитектура мобильного графического процессора | wingstone’s blog (2020). wingstone.github.io/...



Учебное пособие по Jetpack Compose для начинающих, базовые элементы управления и макет

Код js веб-страницы, фон частицы, код спецэффектов

【новый! Суперподробное】Полное руководство по свойствам компонентов Figma.

🎉Обязательно к прочтению новичкам: полное руководство по написанию мини-программ WeChat с использованием программного обеспечения Cursor.

[Забавный проект Docker] VoceChat — еще одно приложение для мгновенного чата (IM)! Может быть встроен в любую веб-страницу!

Как реализовать переход по странице в HTML (html переходит на указанную страницу)

Как решить проблему зависания и низкой скорости при установке зависимостей с помощью npm. Существуют ли доступные источники npm, которые могут решить эту проблему?

Серия From Zero to Fun: Uni-App WeChat Payment Practice WeChat авторизует вход в систему и украшает страницу заказа, создает интерфейс заказа и инициирует запрос заказа

Серия uni-app: uni.navigateЧтобы передать скачок значения

Апплет WeChat настраивает верхнюю панель навигации и адаптируется к различным моделям.

JS-время конвертации

Обеспечьте бесперебойную работу ChromeDriver 125: советы по решению проблемы chromedriver.exe не найдены

Поле комментария, щелчок мышью, специальные эффекты, js-код

Объект массива перемещения объекта JS

Как открыть разрешение на позиционирование апплета WeChat_Как использовать WeChat для определения местонахождения друзей

Я даю вам два набора из 18 простых в использовании фонов холста Power BI, так что вам больше не придется возиться с цветами!

Получить текущее время в js_Как динамически отображать дату и время в js

Вам необходимо изучить сочетания клавиш vsCode для форматирования и организации кода, чтобы вам больше не приходилось настраивать формат вручную.

У ChatGPT большое обновление. Всего за 45 минут пресс-конференция показывает, что OpenAI сделал еще один шаг вперед.

Copilot облачной разработки — упрощение разработки

Микросборка xChatGPT с низким кодом, создание апплета чат-бота с искусственным интеллектом за пять шагов

CUDA Out of Memory: идеальное решение проблемы нехватки памяти CUDA

Анализ кластеризации отдельных ячеек, который должен освоить каждый&MarkerгенетическийВизуализация

vLLM: мощный инструмент для ускорения вывода ИИ

CodeGeeX: мощный инструмент генерации кода искусственного интеллекта, который можно использовать бесплатно в дополнение к второму пилоту.

Машинное обучение Реальный бой LightGBM + настройка параметров случайного поиска: точность 96,67%

Бесшовная интеграция, мгновенный интеллект [1]: платформа больших моделей Dify-LLM, интеграция без кодирования и встраивание в сторонние системы, более 42 тысяч звезд, чтобы стать свидетелями эксклюзивных интеллектуальных решений.

LM Studio для создания локальных больших моделей

Как определить количество слоев и нейронов скрытых слоев нейронной сети?
