DeepSpeed Руководство по глубокому обучению по фреймворку распределенного обучения
введение
По мере увеличения размера моделей глубокого обучения также увеличиваются вычислительные ресурсы и временные затраты, необходимые для обучения этих моделей. Традиционный метод обучения на одной машине больше не может удовлетворить потребности в обучении крупномасштабных моделей. В качестве эффективного решения распределенное обучение реализует параллельные вычисления путем распределения модели и данных по множеству вычислительных узлов, тем самым значительно увеличивая скорость обучения. DeepSpeed — это библиотека оптимизации обучения глубокому обучению с открытым исходным кодом, разработанная Microsoft. Она специально разработана для сценариев распределенного обучения и направлена на повышение эффективности и масштабируемости обучения крупномасштабных моделей. В этой статье мы углубимся в базовые знания DeepSpeed, бизнес-сценарии, функциональные моменты и решенные технические трудности, а также продемонстрируем его практическое применение на распределенных примерах Python.
1. Базовые знания
1.1 Проблемы масштабирования моделей глубокого обучения
В последние годы модели глубокого обучения достигли замечательных результатов в различных областях, но размер и сложность моделей также увеличиваются. От крупномасштабных предварительно обученных моделей для обработки естественного языка до глубоких нейронных сетей в компьютерном зрении — обучение этих моделей требует огромных вычислительных ресурсов и ресурсов памяти. Однако скорость разработки аппаратного обеспечения намного меньше, чем скорость роста размера модели, в результате чего процесс обучения становится чрезвычайно медленным и дорогим.
1.2 Основные принципы распределенного обучения
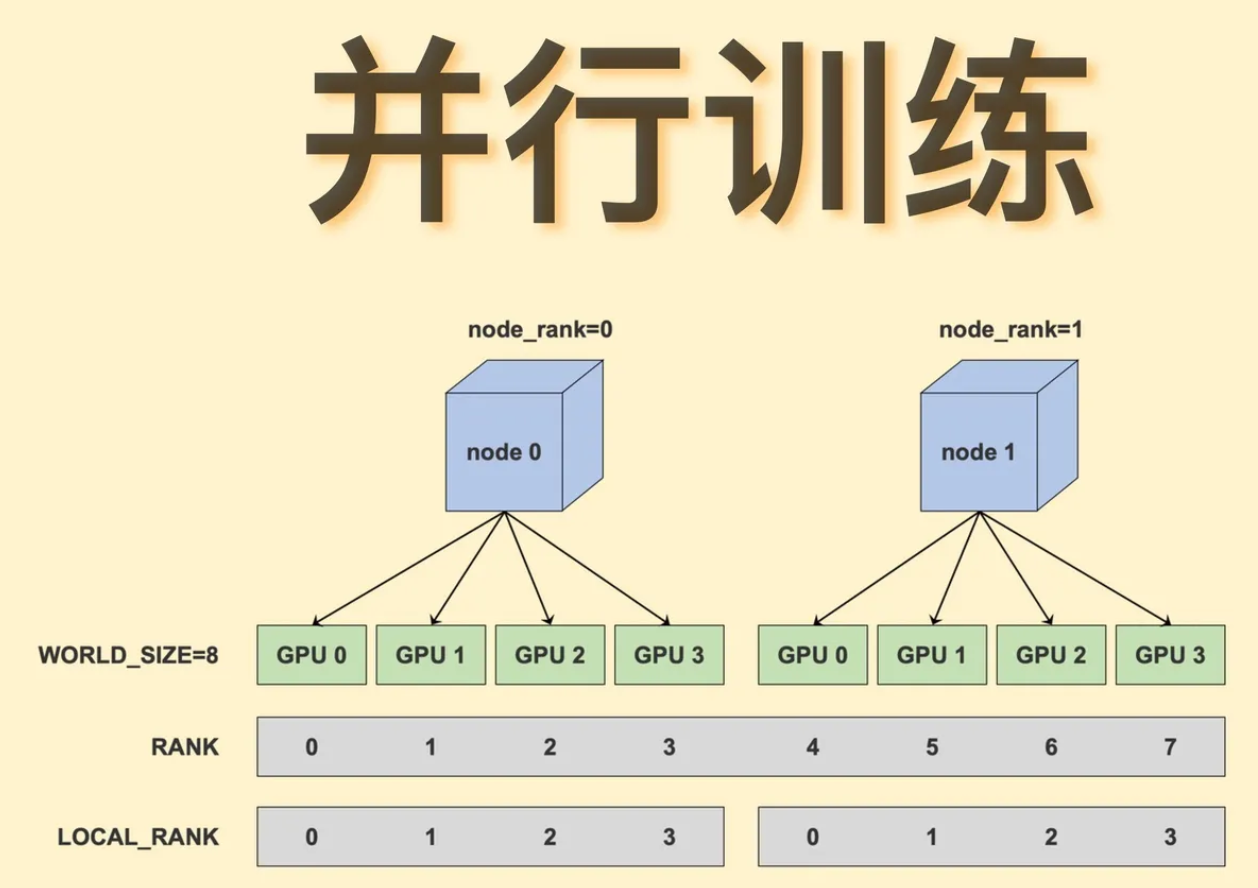
Распределенное обучение реализует параллельные вычисления путем распределения моделей и данных по нескольким вычислительным узлам. Каждый узел самостоятельно обрабатывает подмножество данных и синхронизирует параметры во время обучения, тем самым ускоряя процесс обучения. Распределенное обучение в основном включает в себя три метода: параллелизм данных, параллелизм моделей и параллелизм конвейеров.
- параллелизм данных:Разделите набор данных на небольшие фрагменты,Каждый узел обрабатывает подмножество данных,И выполнять синхронизацию параметров в процессе обучения.
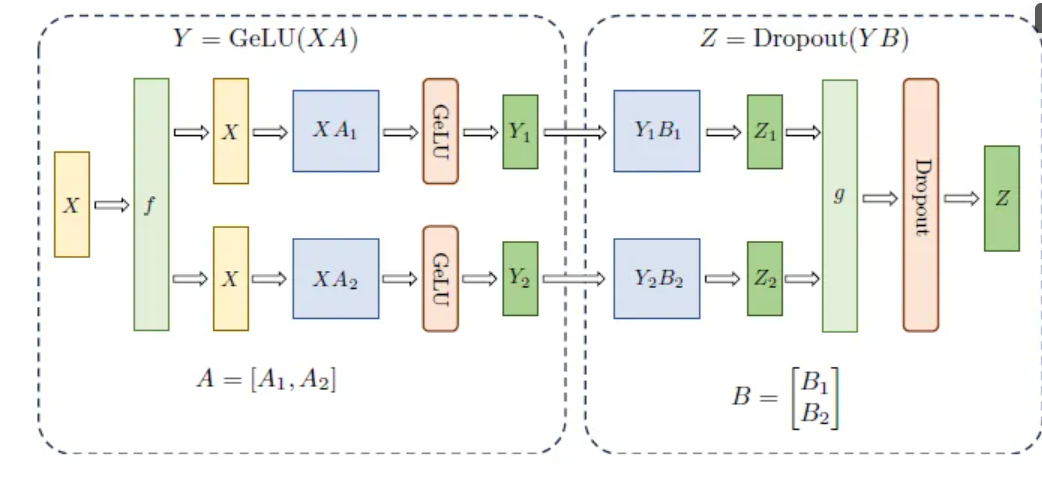
- Модельный параллелизм:Назначьте разные части модели разным узлам,Каждый узел отвечает за часть вычислений модели.
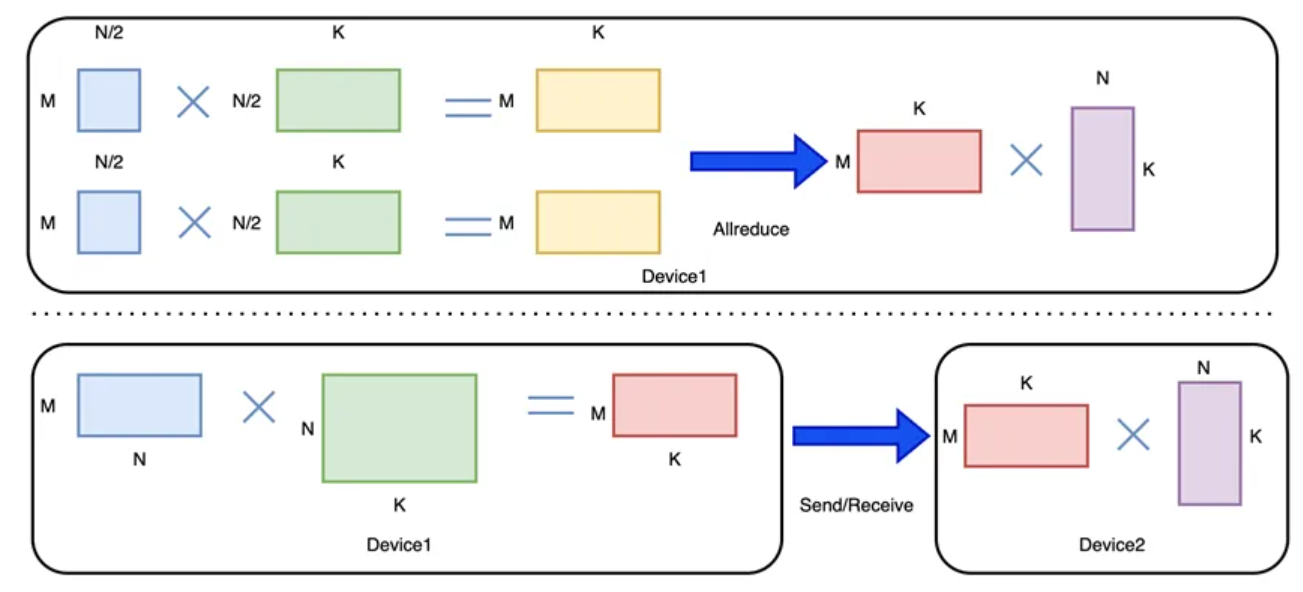
- Параллелизм трубопроводов:Назначьте разные слои модели разным узлам.,Сформируйте упрощенный процесс расчета.
2. Бизнес-сценарий
DeepSpeed широко используется в различных бизнес-сценариях, требующих крупномасштабного обучения моделей, включая, помимо прочего:
- обработка естественного языка:например обучениеBERT、Большие языковые модели, такие как GPT.
- компьютерное зрение:например обучениеResNet、Большие сверточные нейронные сети, такие как VGG.
- Система рекомендаций:например обучение基于深度学习из推荐算法。
Общими характеристиками этих бизнес-сценариев являются большой масштаб модели, большие объемы обучающих данных и высокие требования к вычислительным ресурсам. DeepSpeed значительно повышает скорость обучения и использование ресурсов в этих сценариях благодаря своей эффективной технологии распределенного обучения и оптимизации.
3. Функциональные точки
DeepSpeed предоставляет множество функциональных возможностей для удовлетворения потребностей в обучении в различных сценариях. Ниже приведены основные функциональные моменты DeepSpeed:
3.1 Zero Redundancy Optimizer (ZeRO)
ZeRO — это основная технология оптимизации DeepSpeed, разработанная для уменьшения объема памяти за счет устранения избыточных затрат памяти при параллельном обучении данных. ZeRO сегментирует параметры, градиенты и статус оптимизатора модели и распределяет их по нескольким вычислительным узлам для достижения эффективного использования памяти. ZeRO разделен на несколько этапов, каждый из которых дополнительно снижает объем памяти и накладные расходы на связь.
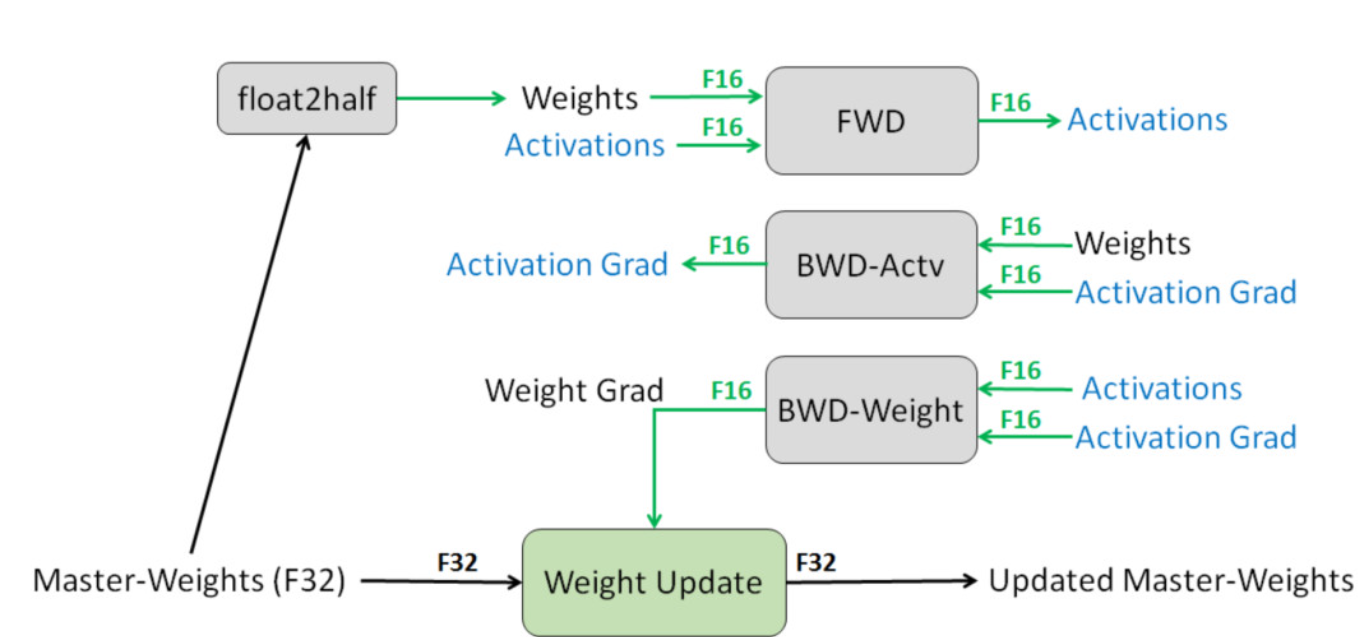
3.2 Обучение смешанной точности
DeepSpeed поддерживает обучение смешанной точности, при котором для обучения используются числа с плавающей запятой как одинарной, так и половинной точности. Этот метод может сократить использование памяти, время вычислений и энергопотребление, сохраняя при этом производительность модели.
3.3 Оптимизация связи
DeepSpeed уменьшает объем передачи данных и задержку между узлами за счет оптимизации механизма связи. Он поддерживает несколько стратегий связи, таких как NCCL, Gloo и т. д., и выбирает подходящую библиотеку связи в соответствии с конкретной ситуацией. Кроме того, DeepSpeed еще больше снижает накладные расходы на связь за счет динамического планирования связи.
3.4 Оптимизация памяти
Помимо технологии ZeRO, DeepSpeed также предоставляет другие технологии оптимизации памяти, такие как контрольные точки активации, накопление градиента и т. д. Эти методы могут еще больше сократить использование памяти и повысить эффективность обучения.
3.5 Пользовательский оптимизатор
DeepSpeed позволяет пользователям интегрировать собственные оптимизаторы для удовлетворения особых потребностей. Пользователи могут выбрать подходящий оптимизатор на основе характеристик своей модели и целей обучения, а также выполнить эффективное распределенное обучение с помощью DeepSpeed.
4. Технические трудности, которые необходимо решить
DeepSpeed решает множество технических проблем в процессе распределенного обучения, включая узкие места памяти, накладные расходы на связь и низкое использование вычислительных ресурсов. Ниже приведены основные технические трудности, решаемые DeepSpeed:
4.1 Узкое место памяти
Узкие места в памяти — распространенная проблема при обучении крупномасштабных моделей. Традиционные подходы к параллельному использованию данных сохраняют полные параметры модели, градиенты и состояние оптимизатора на каждом узле, что приводит к огромному потреблению памяти. DeepSpeed устраняет эти избыточные затраты памяти с помощью технологии ZeRO, снижая требования к памяти до уровня, который может себе позволить один узел.
4.2 Накладные расходы на связь
Накладные расходы на связь во время распределенного обучения также являются важной проблемой. DeepSpeed снижает накладные расходы на связь за счет оптимизации механизмов связи, уменьшения объема связи и использования эффективных коммуникационных библиотек. Кроме того, DeepSpeed еще больше снижает задержки и накладные расходы на связь за счет динамического планирования связи.
4.3 Низкая загрузка вычислительных ресурсов
Низкое использование вычислительных ресурсов также является распространенной проблемой при распределенном обучении. DeepSpeed улучшает использование вычислительных ресурсов за счет эффективных параллельных вычислений и технологии оптимизации, позволяя использовать больше вычислительных ресурсов для реального процесса обучения.
5. Функциональные возможности и использование DeepSpeed
5.1 Функциональные возможности DeepSpeed
DeepSpeed — это библиотека оптимизации глубокого обучения, разработанная Microsoft и предназначенная для ускорения обучения и вывода крупномасштабных моделей. Он предоставляет ряд мощных функций для повышения эффективности обучения, уменьшения объема памяти и оптимизации коммуникации. Ниже приведены основные функциональные моменты DeepSpeed:
5.2ZeRO(Zero Redundancy Optimizer)- ZeRO — это основная технология DeepSpeed.,Это достигается за счет устранения избыточного объема памяти при обучении параллелизму данных.,Значительно снижает использование памяти во время тренировки.
- ZeRO разделен на несколько этапов (Stage 0-3), каждый этап дополнительно оптимизирует использование памяти и эффективность связи. Например, ZeRO-3 распределяет параметры модели, градиенты и состояние оптимизатора на каждый графический процессор, обеспечивая чрезвычайно высокую экономию памяти.
5.3Тренировка смешанной точности- DeepSpeed поддерживает FP16 и FP32Тренировка смешанной точности,для уменьшения использования памяти и ускорения вычислений,при сохранении точности модели.
- Тренировка смешанной точность обеспечивается технологией автоматической смешанной точности (AMP), которая динамически выбирает лучшую числовую точность для достижения баланса между точностью и производительностью.
5.4накопление градиента- накопление градиента позволяет накапливать градиенты по нескольким мини-пакетам данных.,Затем выполните обновление оптимизатора,Это помогает обучать более крупные модели с ограниченной памятью.
5.5Оптимизация памяти- DeepSpeed предлагает разнообразные оптимизации технологии памяти, такие как контрольные точки активации, накопление градиента и сегментирование параметров для уменьшения использования памяти и повышения эффективности обучения.
5.6Оптимизация связи- DeepSpeed повышает скорость обучения за счет оптимизации механизма связи для уменьшения объема передачи данных и задержки между узлами.
- Он поддерживает несколько стратегий связи, таких как All-Reduce, уменьшить-разброс и т. д., и выбирает соответствующую библиотеку связи (например, NCCL) в соответствии с конкретной ситуацией.
5.7Пользовательский оптимизатор- DeepSpeed позволяет пользователям интегрировать собственные оптимизаторы для удовлетворения потребностей конкретных моделей или задач обучения.
5.8Модельный параллелизми Параллелизм трубопроводов- Кроме параллелизма данныхснаружи,DeepSpeed также поддерживает Модельный параллелизми Параллелизм трубопроводов для адаптации к различным типам моделей и потребностям обучения.
5.9Улучшение ввода-вывода- DeepSpeed оптимизирует скорость загрузки и хранения данных с помощью таких технологий, как кэширование и распределенные файловые системы, сокращая время передачи данных и использование полосы пропускания сети.
5.10Оптимизация вывода- DeepSpeed также предлагает Оптимизацию выводатехнология,Такие как Модельный параллелизм и индивидуальные ядра вывода.,для уменьшения задержки и увеличения пропускной способности.
5.11Интеграция и совместимость- DeepSpeed поддерживает несколько фреймворков глубокого обучения, таких как PyTorch, TensorFlow и Horovod, для простой интеграции с существующими системами.
- Обнимать Face Основные библиотеки моделей, такие как библиотека Transformers, тесно интегрированы, что обеспечивает готовые возможности оптимизации.
6. Как использовать DeepSpeed
Чтобы использовать DeepSpeed для распределенного обучения, вам необходимо выполнить следующие шаги:
6.1УстановитьDeepSpeed- Установить DeepSpeed можно через pip:
башкопировать код
pip установить DeepSpeedбашкопировать код
git clone https://github.com/microsoft/DeepSpeed.git
cd DeepSpeed
pip install -r requirements.txt6.2Подготовьте набор данных- Используйте загрузчик данных PyTorch или собственный загрузчик данных для загрузки набора данных.
6.3Написать сценарий обучения- В своем сценарии обучения используйте API распределенного обучения, предоставляемый DeepSpeed.
- Создайте экземпляр движка DeepSpeed и передайте ему модель, оптимизатор и загрузчик данных.
- Используйте механизм DeepSpeed для прямого распространения, обратного распространения и обновлений оптимизатора.
6.4Настроить Дип Спид- Через файл конфигурации JSON или непосредственно в коде. Дип Параметры Спид, такие как ступень Зе РО, Тренировка смешанной варианты точности, стратегии связи и т. д.
6.5Начать обучение- Используйте mpirun или другие распределенные инструменты запуска для загрузки. скрипт обучения и укажите желаемое количество графических процессоров и другие параметры распределенного обучения.
Вот простой пример использования DeepSpeed:
pythonкопировать代码
import torch
import torch.nn as nn
import torch.optim as optim
from deepspeed import DeepSpeedEngine, Hparams
# Определить модель
class SimpleModel(nn.Module):
def __init__(self):
super(SimpleModel, self).__init__()
self.fc = nn.Linear(10, 1)
def forward(self, x):
return self.fc(x)
# Создание моделей и оптимизаторов
model = SimpleModel()
optimizer = optim.SGD(model.parameters(), lr=0.01)
# Определить конфигурацию DeepSpeed
hparams = Hparams(
zero_optimization={
"stage": 3, # Оптимизируйте с помощью ZeRO-3
},
fp16={
"enabled": True,# 启用Тренировка смешанной точности
},
gradient_accumulation_steps=4 # накопление градиентаколичество шагов
)
# Инициализируйте движок DeepSpeed
model_engine, optimizer, _, _ = DeepSpeedEngine(
model=model,
optimizer=optimizer,
config=hparams
)
# Моделирование циклов загрузки и обучения данных
for epoch in range(10): # Тренироваться 10 эпох
for batch in range(100): # Предположим, имеется 100 пакетов.
# Сгенерируйте данные моделирования
inputs = torch.randn(32, 10) # Предположим, партия размер — 32, а размерность входного объекта — 10.
labels = torch.randn(32, 1) # Предположим, что выходная размерность равна 1.
# прямое распространение
outputs = model_engine(inputs)
loss = nn.MSELoss()(outputs, labels)
# Обратное распространение ошибки и оптимизация
model_engine.backward(loss)
model_engine.step()
print(f'Epoch {epoch+1} complete')В приведенном выше примере мы создали простую модель линейной регрессии и обучили ее с помощью движка DeepSpeed. Мы оптимизируем использование памяти и скорость вычислений, настроив ZeRO-3 с обучением смешанной точности. Затем мы смоделировали цикл обучения, который включал загрузку данных, прямое распространение, обратное распространение и обновления оптимизатора.
пожалуйста, обрати внимание,Это всего лишь очень простой пример. в практическом применении,你可能需要根据你из模型и训练需求进行更复杂из配置и优化。Рекомендуется прочитатьDeepSpeedизОфициальная документация,для получения более подробной информации и расширенного использования.
Ниже приведен пример распределенного обучения на Python с использованием DeepSpeed. В этом примере показано, как параллельно обучать простую модель глубокого обучения на нескольких вычислительных узлах.
pythonкопировать代码
import torch
import torch.nn as nn
import torch.optim as optim
from deepspeed import DeepSpeedEngine, Hparams
# Определите простую модель нейронной сети
class SimpleModel(nn.Module):
def __init__(self):
super(SimpleModel, self).__init__()
self.fc = nn.Linear(10, 1)
def forward(self, x):
return self.fc(x)
# Определить функцию потерь и оптимизатор
model = SimpleModel()
criterion = nn.MSELoss()
optimizer = optim.SGD(model.parameters(), lr=0.01)
# Определите параметры конфигурации для DeepSpeed
hparams = Hparams(
zero_optimization={
"stage": 3,
"offload_optimizer": {
"device": "cpu"
},
"overlap_comm": True,
"contiguous_gradients": True,
"reduce_scatter": True,
"reduce_bucket_size": 5e8,
"allgather_bucket_size": 5e8,
"partition_activations": True,
"cpu_offload": True,
"min_num_size": 1e8,
"load_from_fp32_weights": True,
"stage3_gather_fp16_weights_on_model_save": True,
"stage3_prefetch_bucket_size": 5e8,
"stage3_param_persistence_threshold": 1e8,
"stage3_max_live_parameters": 1e9,
"stage3_max_reuse_distance": 1e9,
"stage3_gather_fp16_weights_during_training": True,
"offload_param": True,
"pin_memory": True,
"fast_init": True,
"sync_bn_in_backward": True,
"reduce_bucket_size": 5e8,
"allgather_bucket_size": 5e8,
"reduce_scatter": True,
"contiguous_gradients": True,
"overlap_comm": True
},
fp16={
"enabled": True,
"loss_scale": 0,
"initial_scale_power": 16,
"scale_window": 1000
},
gradient_clipping={
"enabled": True,
"clip_value": 1.0
},
train_batch_size=32,
gradient_accumulation_steps=4,
steps_per_print=10
)
# Инициализируйте движок DeepSpeed
model_engine, optimizer, dataloader, _ = DeepSpeedEngine(
model=model,
optimizer=optimizer,
config=hparams,
dataloader=..., # Здесь вам нужно передать свой загрузчик данных
)
# Определить цикл обучения
for epoch in range(num_epochs):
for batch in dataloader:
inputs, labels = batch
# прямое распространение
outputs = model_engine(inputs)
loss = criterion(outputs, labels)
# Обратное распространение ошибки и оптимизация
model_engine.backward(loss)
model_engine.step()
print(f'Epoch {epoch+1} complete')
# Сохранить модель
model_engine.save_checkpoint('model_checkpoint.pt')Подвести итог
DeepSpeed — это эффективная среда распределенного обучения, которая значительно повышает эффективность и масштабируемость обучения крупномасштабных моделей за счет ряда технологий и функций оптимизации. DeepSpeed широко используется в таких бизнес-сценариях, как обработка естественного языка, компьютерное зрение и системы рекомендаций, предоставляя мощный инструмент обучения для исследователей и инженеров. Изучая эту статью, вы сможете получить более глубокое понимание базовых знаний DeepSpeed, бизнес-сценариев, функциональных моментов, решенных технических трудностей и освоить его практическое применение с помощью распределенных примеров Python. Я надеюсь, что эта статья поможет вам изучить и использовать DeepSpeed.



Углубленный анализ переполнения памяти CUDA: OutOfMemoryError: CUDA не хватает памяти. Попыталась выделить 3,21 Ги Б (GPU 0; всего 8,00 Ги Б).

[Решено] ошибка установки conda. Среда решения: не удалось выполнить первоначальное зависание. Повторная попытка с помощью файла (графическое руководство).

Прочитайте нейросетевую модель Трансформера в одной статье

.ART Теплые зимние предложения уже открыты

Сравнительная таблица описания кодов ошибок Amap

Уведомление о последних правилах Points Mall в декабре 2022 года.

Даже новички могут быстро приступить к работе с легким сервером приложений.

Взгляд на RSAC 2024|Защита конфиденциальности в эпоху больших моделей

Вы используете ИИ каждый день и до сих пор не знаете, как ИИ дает обратную связь? Одна статья для понимания реализации в коде Python общих функций потерь генеративных моделей + анализ принципов расчета.

Используйте (внутренний) почтовый ящик для образовательных учреждений, чтобы использовать Microsoft Family Bucket (1T дискового пространства на одном диске и версию Office 365 для образовательных учреждений)

Руководство по началу работы с оперативным проектом (7) Практическое сочетание оперативного письма — оперативного письма на основе интеллектуальной системы вопросов и ответов службы поддержки клиентов

[docker] Версия сервера «Чтение 3» — создайте свою собственную программу чтения веб-текста

Обзор Cloud-init и этапы создания в рамках PVE

Корпоративные пользователи используют пакет регистрационных ресурсов для регистрации ICP для веб-сайта и активации оплаты WeChat H5 (с кодом платежного узла версии API V3)

Подробное объяснение таких показателей производительности с высоким уровнем параллелизма, как QPS, TPS, RT и пропускная способность.

Удачи в конкурсе Python Essay Challenge, станьте первым, кто испытает новую функцию сообщества [Запускать блоки кода онлайн] и выиграйте множество изысканных подарков!

[Техническая посадка травы] Кровавая рвота и отделка позволяют вам необычным образом ощипывать гусиные перья! Не распространяйте информацию! ! !

[Официальное ограниченное по времени мероприятие] Сейчас ноябрь, напишите и получите приз

Прочтите это в одной статье: Учебник для няни по созданию сервера Huanshou Parlu на базе CVM-сервера.

Cloud Native | Что такое CRD (настраиваемые определения ресурсов) в K8s?

Как использовать Cloudflare CDN для настройки узла (CF самостоятельно выбирает IP) Гонконг, Китай/Азия узел/сводка и рекомендации внутреннего высокоскоростного IP-сегмента

Дополнительные правила вознаграждения амбассадоров акции в марте 2023 г.

Можно ли открыть частный сервер Phantom Beast Palu одним щелчком мыши? Супер простой урок для начинающих! (Прилагается метод обновления сервера)

[Играйте с Phantom Beast Palu] Обновите игровой сервер Phantom Beast Pallu одним щелчком мыши

Maotouhu делится: последний доступный внутри страны адрес склада исходного образа Docker 2024 года (обновлено 1 декабря)

Кодирование Base64 в MultipartFile

5 точек расширения SpringBoot, супер практично!

Глубокое понимание сопоставления индексов Elasticsearch.

15 рекомендуемых платформ разработки с нулевым кодом корпоративного уровня. Всегда найдется та, которая вам понравится.
