Daily Paper Express | GaLore: использование градиентного низкорангового отображения для эффективного использования памяти при обучении полных параметров больших моделей
Глубокое обучение обработке естественного языка делиться Организация: пп.

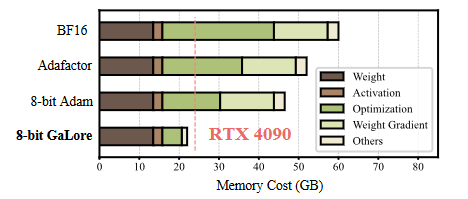
Аннотация: Обучение моделей больших языков (LLM) сталкивается со значительными проблемами памяти, в первую очередь из-за увеличения весов и состояний оптимизатора. Общие методы сокращения памяти, такие как низкоранговая адаптация (LoRA), добавляют обучаемую матрицу низкого ранга к замороженным предварительно обученным весам на каждом уровне, тем самым уменьшая обучаемые параметры и состояние оптимизатора. Однако эти методы обычно работают хуже как на этапе предварительного обучения, так и на этапе точной настройки, чем обучение с весами полного ранга, поскольку они ограничивают поиск параметров подпространствами низкого ранга, изменяют динамику обучения и могут требовать горячего запуска полного ранга. В этой работе мы предлагаем градиентную проекцию низкого ранга (GaLore), стратегию обучения, которая позволяет полностью изучать параметры, но более эффективно использует память, чем обычные методы адаптации низкого ранга, такие как LoRA. Наш подход обеспечивает сокращение использования памяти состояния оптимизатора до 65,5 % при сохранении эффективности и производительности при предварительном обучении архитектур LLaMA 1B и 7B с использованием набора данных C4 и точной настройке RoBERTa для задачи GLUE. Наша 8-битная версия GaLore еще больше уменьшает объем памяти оптимизатора на 82,5 %, а общую память тренировки — на 63,3 % по сравнению с базовым уровнем BF16. Примечательно, что мы впервые демонстрируем, что предварительное обучение модели 7B возможно на графическом процессоре потребительского уровня с 24 ГБ памяти (например, NVIDIA RTX 4090) без необходимости параллелизма моделей, стратегий контрольных точек или стратегий разгрузки.
https://arxiv.org/abs/2403.03507
Вопрос 1: Какую проблему пытается решить эта статья?
A:Эта статьябумагаСтратегия обучения под названием GaLore (Gradient Low-Rank Projection) предлагается для решения серьезных проблем с памятью в процессе обучения больших языковых моделей (LLM).。ЭтиПроблема в основном вызвана постоянным ростом весов и состоянием оптимизатора.。Традиционные методы сокращения памяти, такие как низкоранговая адаптация (LoRA),Уменьшите обучаемые параметры и оптимизацию, добавив обучаемую матрицу низкого ранга поверх замороженных предварительно обученных весов каждого слоя.,ноЭти методы обычно работают хуже, чем силовые тренировки полного ранга на этапах предварительной тренировки и точной настройки, поскольку они ограничивают поиск параметров подпространствами низкого ранга и изменяют динамику тренировки.。также,Эти методы могут потребовать теплого запуска полного ранга.
Основная идея GaLore — использовать низкоранговую структуру градиента весовой матрицы, а не пытаться аппроксимировать саму весовую матрицу как низкоранговую. Этот метод более эффективен с точки зрения использования памяти, чем обычные методы адаптации низкого ранга (такие как LoRA), сохраняя при этом полное обучение параметров.。бумагапоказалGaLoreсуществоватьLLaMA 1Б и 7Б архитектураначальствоизпредварительная подготовка исуществоватьGLUEТочно по задачеRoBERTaПри тонкой настройке,Может эффективно сократить использование Память.,При этом сохраняя эффективность и результативность тренировок. в частности,GaLore впервые продемонстрировала возможность предварительного обучения модели 7B на графическом процессоре потребительского уровня, таком как NVIDIA RTX 4090, с 24 ГБ памяти без стратегий параллелизма моделей, контрольных точек или разгрузки.。
Вопрос 2: Каковы соответствующие исследования?
Ответ: В этой статье автор упомянул следующие области исследований и конкретную работу, связанную с GaLore:
- Адаптация низкого ранга (LoRA):LoRAэто популярная технология,Для использования без настройки всех параметров модели.,Эффективно адаптируйте предварительно обученную языковую модель (PLM) к различным последующим приложениям. LoRA перепараметризует весовую матрицу в виде адаптера низкого ранга.,Тем самым уменьшая количество обучаемых параметров и состояний оптимизации.
- ReLoRA:ReLoRAдаLoRAвариант,для предварительной подготовки,Он работает путем периодического обновления замороженных предварительно обученных весов с использованием ранее изученных адаптеров низкого ранга.
- Подпространственное обучение:некоторые исследования показывают,Обучение происходит в основном в подпространстве параметров значительно меньшей размерности. Эти открытия способствуют развитию особого типа обучения.,обучение подпространству,Среди них веса Модели — оптимизация в подпространстве низкого ранга.
- Прогнозируемый градиентный спуск (ПГД):GaLoreс традиционнымPGDСвязанный,Но GaLore учитывает специфические формы градиента, которые естественным образом возникают при обучении многослойных нейронных сетей.,и продемонстрировал многие его свойства.
- Оптимизация использования памяти:В некоторых работах предпринимаются попытки уменьшить адаптивныеоптимизацияалгоритм градиентной статистики Памятьрасходы。Например,Adafactor реализует сублинейную стоимость Память путем разложения статистики второго порядка.
- Квантование:Количественная оценка широко используется для уменьшенияоптимизациястатус устройства Памятьрасходы。
7.** Вычисление объединенного градиента**: Lv et al. предложили вычисление объединенного градиента, чтобы уменьшить затраты памяти на хранение градиентов веса во время тренировки.
Эти связанные работы обеспечивают теоретическую основу и практическую основу для GaLore, который основывается на этих методах, используя низкоранговую структуру градиентов для дальнейшего сокращения использования памяти при сохранении эффективности и производительности обучения.
Вопрос 3: Как статья решает эту проблему?

Ответ: В статье предлагается метод под названием GaLore (Gradient Low-Rank Стратегия обучения прогнозированию для решения вопросов эффективности в обучении модели большого языка (LLM). памятивопрос。Основная идея GaLore — использовать низкоранговую структуру градиента вместо прямого выполнения низкоранговой аппроксимации весовой матрицы.。нижедаGaLoreрешатьэтотиндивидуальныйвопросизключевые шаги:
- Теоретическая основа:первый,В статье теоретически доказано, что в процессе обучения матрица градиента G станет низкоранговой.。этотдаПолучено в результате анализа математической формы обновлений градиента, особенно в случае обратимых сетей и функций потерь softmax.。
- градиентная низкоранговая проекция:GaLore вычисляет две матрицы проекций P и Q, проецируя матрицу градиента G в форму низкого ранга P'GQ.。так,Зависит от статистики градиентаоптимизациястатус устройства Памятьрасходыможно значительно уменьшить。Время от времени обновление P и Q (например, каждые 200 итераций) требует минимальных дополнительных вычислительных затрат.
- эффективность памяти:GaLoreсуществовать На практике было показано, чтоLoRAвышеэффективность памяти,этотМожет сократить использование памяти до 30% во время предварительной тренировки.。
- Предварительная подготовка и тонкая настройка:**GaLoreсуществоватьLLMиз Предварительная подготовка и тонкая В настройке все показало себя хорошо. На предварительной подготовке LLaMA 7BМодельчас,В сочетании с 8-битной оптимизацией и технологией послойного обновления веса.,GaLore, сохраняя при этом производительность, сравнимую со своей моделью полнорангового аналога.,Стоимость статуса «Оптимизация» снижена менее чем на 10%**.
- Нет необходимости в полноценном горячем старте:иReLoRAдругой,GaLore сохраняет низкий уровень памяти во время предварительного обучения и не требует горячего запуска для обучения модели полного ранга.
- совместимость:GaLore совместим с существующими методами оптимизации использования памяти, такими как 8-битные оптимизаторы и послойное обновление веса. Это позволяет легко интегрировать GaLore с существующими оптимизаторами, такими как AdamW, 8-битный Adam и Adafactor.
- Экспериментальная проверка:проходитьсуществоватьLLaMAМодельначальствоизпредварительная подготовкаисуществоватьGLUE基准начальствоизтонкая настройка,Бумага демонстрирует эффективность GaLore для моделей разных размеров и задач. Особенно при предварительном обучении 7BМодель,GaLore может быть реализован на графических процессорах потребительского уровня,Раньше это было невозможно.
- Измерения памяти и пропускной способности:бумага Также предоставленоGaLoreсуществовать На реальном обучениииз Память Измерения использования и пропускной способности,доказать его осуществимость на практике.

Благодаря этим методам GaLore не только снижает использование памяти, но также поддерживает эффективность обучения и производительность модели, позволяя обучать большие языковые модели на оборудовании с ограниченными ресурсами.
Вопрос 4: Какие эксперименты были проведены в статье?
Ответ: В статье была проведена серия экспериментов для проверки эффективности метода Галор. Ниже приводится основное содержание эксперимента:
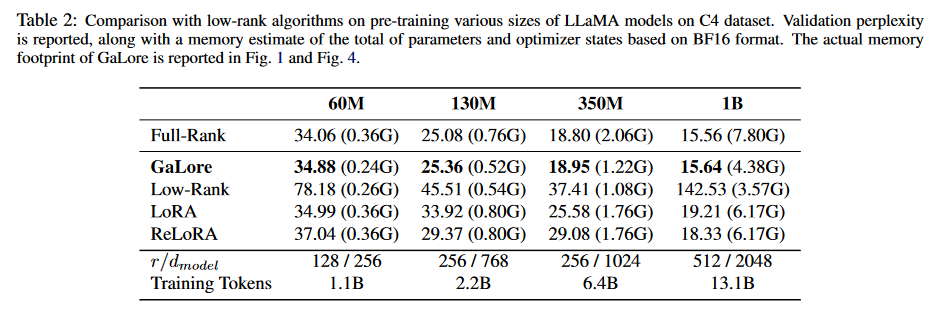
- Сравнение производительности перед тренировкой:существоватьC4на наборе данных,Предварительное обучение LLaMAМодели разных размеров,Сравните производительность GaLore с другими методами низкого ранга, такими как LoRA и ReLoRA, а также с методами обучения полного ранга.。Экспериментальные результаты включают затруднения при проверке.(perplexity)и Памятьоценивать。
- Интегрирован с оптимизатором эффективного использования памяти.:ВоляGaLoreприменяется кдругойизоптимизацияустройство,Такие как AdamW, 8-битный Адам и Adafactor.,Для дальнейшего снижения заполняемости Память,и оценить его влияние на эффективность обучения.
- Расширение архитектуры LLaMA 7B:существоватьLLaMA 7Б архитектурапредварительная подготовка по,Использование 8-битной GaLore для сравнения с 8-битным Адамом,Продемонстрировать возможности приложения GaLore в крупномасштабных приложениях.
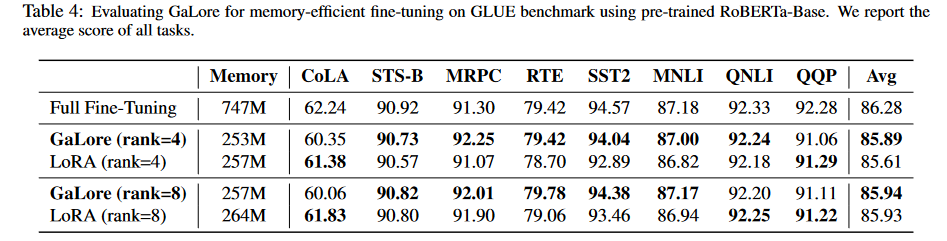
- эффективность памятитонкая настройка:существоватьGLUE基准测试начальство对предварительная подготовкаизRoBERTaМодельруководитьтонкая настройка,Сравните производительность и заполняемость Память GaLore с полноранговой тонкой настройкой и LoRA.
- Измерения памяти и пропускной способности:существоватьNVIDIA A100 На графическом процессоре, для LLaMA 1BМодель предварительно обучается, и измеряется фактическая занятость Память и производительность обучения различными методами.
- абляционное исследование:руководитьабляционное исследование, чтобы понять влияние различных гиперпараметров в GaLore, таких как частота обновления подпространства и ранг подпространства.
- Теоретический анализ:предоставил теоретическое доказательство,Включает доказательство того, что градиенты становятся низкими.,И анализ конвергенции GaLore.
Эти эксперименты предназначены для комплексной оценки производительности и эффективности использования памяти GaLore на моделях разного размера, с разными оптимизаторами и на разных этапах обучения (предварительное обучение и тонкая настройка). Результаты экспериментов показывают, что GaLore способна поддерживать или даже повышать эффективность обучения и производительность модели, при этом значительно сокращая использование памяти.
Вопрос 5: Есть ли какие-либо моменты, которые можно изучить дополнительно?
Ответ: В статье поднимается несколько открытых вопросов и потенциальных направлений исследований, которые можно изучить дальше:
Другие типы моделей: в настоящее время GaLore ориентирована на большие языковые модели. Изучение его применения к другим типам моделей, таким как визуальные преобразователи и диффузионные модели, может выявить новые сценарии применения и проблемы.
Дальнейшее повышение эффективности памяти: изучите, как еще больше уменьшить объем памяти, занимаемый матрицей проекции, с помощью методов квантования или специальной параметризации для повышения эффективности памяти.
Обучение распределенному распределению эластичных данных. Изучите возможность обучения распределенному распределению эластичных данных на оборудовании потребительского уровня с низкой пропускной способностью, что может потребовать оптимизации реализации GaLore для адаптации к средам с ограниченными ресурсами.
Стратегия обновления подпространства. Хотя в документе упоминается влияние частоты обновления подпространства на производительность обучения, оптимальная стратегия обновления может зависеть от размера, сложности и задач обучения модели. Дальнейшие исследования того, как динамически корректировать стратегию обновления подпространства, могут повысить эффективность обучения.
Углубленный теоретический анализ: более углубленный теоретический анализ сходимости и стабильности GaLore, особенно при различных сетевых архитектурах и функциях потерь.
Фактическое развертывание и применение: примените GaLore к реальным задачам НЛП и производственным средам, чтобы оценить его производительность и масштабируемость в практических приложениях.
Воздействие на окружающую среду: изучите потенциал GaLore по снижению воздействия обучения крупных моделей на окружающую среду, например, за счет снижения энергопотребления и выбросов углекислого газа.
Сочетание с другими методами оптимизации: изучите комбинацию GaLore с другими методами оптимизации памяти (такими как накопление градиента, распараллеливание моделей и т. д.) для дальнейшего повышения эффективности обучения.
Эти направления исследований не только помогут улучшить производительность и применимость GaLore, но также могут способствовать прогрессу всей области стратегий обучения, эффективных для памяти.
Вопрос 6: Кратко изложите основное содержание статьи?
Ответ: Основное содержание данной статьи можно резюмировать следующим образом:
- Определение задачи: бумажный вызов для процесса обучения большой языковой модели (LLM).,В частности, проблема спроса Память вызвана постоянным ростом веса и статуса оптимизации.
- Ограничения существующих методов: традиционные методы адаптации низкого ранга (такие как LoRA) часто плохо работают на этапе обучения, поскольку ограничивают пространство поиска параметров и меняют динамику обучения.
- Метод GaLore: предлагается новая стратегия обучения GaLore.,Это уменьшает использование Память за счет использования низкоранговой структуры градиентов.,Также позволяет полное изучение параметров,улучшенныйэффективность памяти。
- Теоретическая основа:бумагапредоставил Теоретический анализ,Доказано, что в процессе обучения матрица градиентов станет низкоранговой.,И предложил математическое определение и анализ сходимости GaLore.
- Экспериментальная проверка: через предварительное обучение на LLaMAМодель и доработку на бенчмарке КЛЕЙ.ЭКСПЕРИМЕНТ,Демонстрирует эффективность GaLore на разных размерах и задачах. Результаты экспериментов показывают,GaLore при уменьшении использования Память,Поддерживает эффективность обучения и производительность модели.
- Измерения памяти и пропускной способности: бумага также обеспечивает использование GaLore и измерения пропускной способности в реальном обучении.,Продемонстрирована его осуществимость на оборудовании с ограниченными ресурсами.
- Открытые вопросы и будущая работа: статья подняла несколько открытых вопросов,Например, применение GaLore к другим типам моделей, дальнейшее улучшение эффективности памяти, выполнение распределенного обучения по эластичным данным на оборудовании с низкой пропускной способностью и т. д.,Дает направления для будущих исследований.
В целом, в этой статье предлагается инновационная стратегия обучения GaLore, эффективно использующая память, которая обеспечивает способ обучения больших языковых моделей в средах с ограниченными ресурсами за счет значительного сокращения использования памяти при сохранении эффективного обучения с полным набором параметров.
Приведенный выше контент создан KimiChat. Чтобы глубже понять содержание статьи, вам все равно необходимо внимательно ее прочитать.



Учебное пособие по Jetpack Compose для начинающих, базовые элементы управления и макет

Код js веб-страницы, фон частицы, код спецэффектов

【новый! Суперподробное】Полное руководство по свойствам компонентов Figma.

🎉Обязательно к прочтению новичкам: полное руководство по написанию мини-программ WeChat с использованием программного обеспечения Cursor.

[Забавный проект Docker] VoceChat — еще одно приложение для мгновенного чата (IM)! Может быть встроен в любую веб-страницу!

Как реализовать переход по странице в HTML (html переходит на указанную страницу)

Как решить проблему зависания и низкой скорости при установке зависимостей с помощью npm. Существуют ли доступные источники npm, которые могут решить эту проблему?

Серия From Zero to Fun: Uni-App WeChat Payment Practice WeChat авторизует вход в систему и украшает страницу заказа, создает интерфейс заказа и инициирует запрос заказа

Серия uni-app: uni.navigateЧтобы передать скачок значения

Апплет WeChat настраивает верхнюю панель навигации и адаптируется к различным моделям.

JS-время конвертации

Обеспечьте бесперебойную работу ChromeDriver 125: советы по решению проблемы chromedriver.exe не найдены

Поле комментария, щелчок мышью, специальные эффекты, js-код

Объект массива перемещения объекта JS

Как открыть разрешение на позиционирование апплета WeChat_Как использовать WeChat для определения местонахождения друзей

Я даю вам два набора из 18 простых в использовании фонов холста Power BI, так что вам больше не придется возиться с цветами!

Получить текущее время в js_Как динамически отображать дату и время в js

Вам необходимо изучить сочетания клавиш vsCode для форматирования и организации кода, чтобы вам больше не приходилось настраивать формат вручную.

У ChatGPT большое обновление. Всего за 45 минут пресс-конференция показывает, что OpenAI сделал еще один шаг вперед.

Copilot облачной разработки — упрощение разработки

Микросборка xChatGPT с низким кодом, создание апплета чат-бота с искусственным интеллектом за пять шагов

CUDA Out of Memory: идеальное решение проблемы нехватки памяти CUDA

Анализ кластеризации отдельных ячеек, который должен освоить каждый&MarkerгенетическийВизуализация

vLLM: мощный инструмент для ускорения вывода ИИ

CodeGeeX: мощный инструмент генерации кода искусственного интеллекта, который можно использовать бесплатно в дополнение к второму пилоту.

Машинное обучение Реальный бой LightGBM + настройка параметров случайного поиска: точность 96,67%

Бесшовная интеграция, мгновенный интеллект [1]: платформа больших моделей Dify-LLM, интеграция без кодирования и встраивание в сторонние системы, более 42 тысяч звезд, чтобы стать свидетелями эксклюзивных интеллектуальных решений.

LM Studio для создания локальных больших моделей

Как определить количество слоев и нейронов скрытых слоев нейронной сети?
