CVPR 2024 | Обзор направлений улучшения диффузионной модели на основе 6 статей
1、Accelerating Diffusion Sampling with Optimized Time Steps

Диффузионно-вероятностные модели (DPM) показали замечательную эффективность при создании изображений с высоким разрешением, но их эффективность выборки все еще нуждается в повышении, поскольку обычно требуется большое количество шагов выборки. Последние достижения в применении решателей ОДУ более высокого порядка к DPM позволяют генерировать высококачественные изображения с меньшим количеством шагов выборки. Однако большинство методов выборки по-прежнему используют одинаковые временные шаги, что неоптимально при использовании небольшого количества шагов.
Чтобы решить эту проблему, предлагается общая структура для разработки задачи оптимизации, которая ищет более подходящий временной шаг для конкретного численного решателя ОДУ в DPM. Цель этой задачи оптимизации — минимизировать расстояние между фундаментальным решением и соответствующим численным решением. Эффективное решение этой задачи оптимизации занимает не более 15 секунд.
Обширные эксперименты с DPM в пиксельном и скрытом пространстве, безусловной и условной выборке показывают, что в сочетании с современным методом выборки UniPC в сочетании с равномерным временным шагом для таких данных, как CIFAR-10. и ImageNet Set, согласно оценке FID, оптимизация временного шага значительно повышает производительность генерации изображений.
2、DistriFusion: Distributed Parallel Inference for High-Resolution Diffusion Models

Создание изображений высокого разрешения с использованием диффузионных моделей требует больших вычислительных затрат, что приводит к неприемлемой задержке для интерактивных приложений. DistriFusion предлагается решить эту проблему, используя параллелизм между несколькими графическими процессорами. Метод разделяет входные данные модели на несколько патчей и назначает каждый графическому процессору. Однако простая реализация этого алгоритма нарушит взаимодействие между патчами и приведет к потере точности, а учет этого взаимодействия приведет к огромным накладным расходам на связь.
Чтобы решить эту дилемму, наблюдается большое сходство между входными данными соседних этапов диффузии и предлагается параллелизм участков смещения, который использует последовательный характер процесса диффузии путем повторного использования предварительно вычисленной карты признаков предыдущего временного шага, поскольку текущий шаг обеспечивает контекст . Таким образом, методы поддерживают асинхронную связь и могут передаваться по конвейеру посредством вычислений. Обширные эксперименты показывают, что этот метод можно применить к последнему Stable Diffusion XL без потери качества и добиться ускорения до 6,1 раз по сравнению с устройством NVIDIA A100. Исходный код уже открыт по адресу: https://github.com/mit-han-lab/distrifuser.
3、Balancing Act: Distribution-Guided Debiasing in Diffusion Models
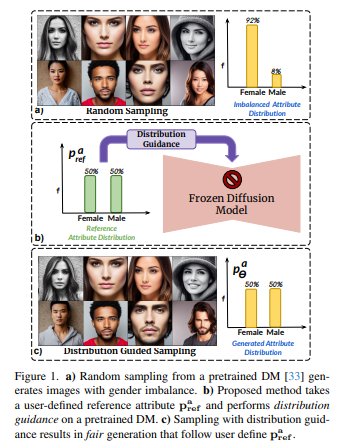
Модели диффузии (DM) отражают смещение, присутствующее в наборе обучающих данных. Особое беспокойство вызывает случай с лицами, когда DM отдают предпочтение определенным демографическим группам перед другими (например, женщины перед мужчинами). В этой работе предлагается метод устранения смещения DM, не полагаясь на дополнительные данные или переобучение модели.
В частности, предлагается метод Distribution Guidance, который заставляет сгенерированное изображение следовать заданному распределению атрибутов. Для достижения этой цели скрытые функции шумоподавления UNet созданы с использованием богатой семантики групп населения, и эти функции можно использовать для управления созданием debias. Обучите предиктор распределения атрибутов (ADP), небольшой многоуровневый персептрон, который сопоставляет скрытые функции с распределениями атрибутов. ADP обучается с использованием псевдометок, созданных существующими классификаторами атрибутов. Введенные Руководство по распределению и ADP обеспечивают справедливое производство.
Этот метод уменьшает смещение по одному/множеству атрибутов и обеспечивает значительно лучшую базовую производительность, чем предыдущие методы, с точки зрения моделей безусловного и текстового распространения. Кроме того, предлагается следующая задача по обучению классификатора справедливых атрибутов путем генерации данных, которые перебалансируют обучающий набор.
4、Few-shot Learner Parameterization by Diffusion Time-steps
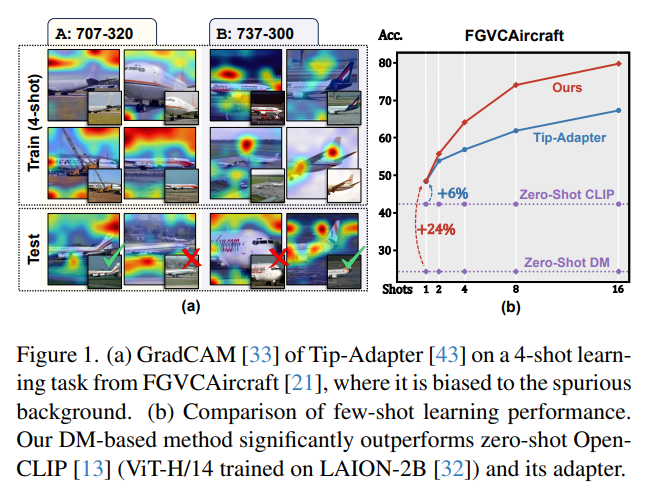
Даже при использовании больших мультимодальных базовых моделей обучение в несколько этапов остается сложной задачей. Без соответствующего индуктивного смещения трудно сохранить тонкие атрибуты класса, удаляя при этом заметные визуальные атрибуты, не имеющие отношения к метке класса.
Было обнаружено, что временные шаги модели диффузии (DM) могут изолировать тонкие атрибуты класса, т. Е. Поскольку прямая диффузия добавляет шум к изображению на каждом временном шаге, тонкие атрибуты часто теряются на более ранних временных шагах, чем существенные атрибуты. На основании этого предлагается обучающийся алгоритм с несколькими шагами по времени (TiF). Адаптеры низкого ранга для конкретного класса обучены для DM с текстовым условием, чтобы компенсировать недостающие атрибуты, позволяя точно реконструировать исходное изображение из зашумленного изображения с учетом подсказок. Таким образом, на меньших временных шагах адаптеры и подсказки по сути представляют собой параметризации с лишь тонкими свойствами класса. Для тестового изображения эту параметризацию можно использовать для извлечения только тонких атрибутов класса для классификации. При выполнении различных мелкодетализированных и настраиваемых задач обучения, состоящих из нескольких шагов, учащийся TiF значительно превосходит OpenCLIP и его адаптеры по производительности.
5、Structure-Guided Adversarial Training of Diffusion Models

Модели диффузии продемонстрировали превосходную эффективность в различных генеративных приложениях. Существующие модели в основном сосредоточены на моделировании распределения данных посредством минимизации взвешенных потерь, но их обучение в основном делает упор на оптимизацию на уровне экземпляра, игнорируя ценную структурную информацию в каждом мини-пакете данных.
Чтобы устранить это ограничение, введен метод состязательного обучения диффузионных моделей (SADM), ориентированный на структуру. Заставляет модель изучать структуру многообразия между выборками в каждом обучающем пакете. Чтобы гарантировать, что модель отражает реальную структуру многообразия в распределении данных, предлагается новый дискриминатор структуры, позволяющий различать реальную структуру многообразия и сгенерированную структуру многообразия, играя в игру с генератором диффузии посредством состязательного обучения.
SADM значительно улучшает существующие диффузионные преобразователи, превосходя существующие методы на 12 наборах данных в задачах генерации изображений и междоменной точной настройки для генерации изображений с учетом классов с разрешениями 256×256 и 512×512. Новые записи FID составляют 1,58 и 2,11 соответственно. .
6、Tackling the Singularities at the Endpoints of Time Intervals in Diffusion Models

Большинство моделей диффузии предполагают, что обратный процесс подчиняется распределению Гаусса. Однако это приближение не было строго проверено в особых точках (t=0 и t=1), особенно в сингулярностях. Неправильное обращение с этими точками может вызвать проблемы со средней яркостью в приложениях и ограничить создание изображений с чрезмерной яркостью или глубокой темнотой.
В данной статье рассматривается этот вопрос с теоретической и практической точки зрения. Во-первых, устанавливается граница погрешности аппроксимации обратного процесса и демонстрируются его гауссовы характеристики на сингулярных шагах по времени. На основе этого теоретического понимания подтверждается, что особая точка при t=1 может быть устранена условно, тогда как особая точка при t=0 является внутренним свойством. На основе этих важных выводов предлагается новый метод plug-and-play SingDiffusion для обработки выборки начальных сингулярных временных шагов, который может не только эффективно решить проблему средней яркости без дополнительного обучения, но и улучшить возможности их генерации, тем самым достигая значительно более низкий показатель FID. https://github.com/PangzeCheung/SingDiffusion



Учебное пособие по Jetpack Compose для начинающих, базовые элементы управления и макет

Код js веб-страницы, фон частицы, код спецэффектов

【новый! Суперподробное】Полное руководство по свойствам компонентов Figma.

🎉Обязательно к прочтению новичкам: полное руководство по написанию мини-программ WeChat с использованием программного обеспечения Cursor.

[Забавный проект Docker] VoceChat — еще одно приложение для мгновенного чата (IM)! Может быть встроен в любую веб-страницу!

Как реализовать переход по странице в HTML (html переходит на указанную страницу)

Как решить проблему зависания и низкой скорости при установке зависимостей с помощью npm. Существуют ли доступные источники npm, которые могут решить эту проблему?

Серия From Zero to Fun: Uni-App WeChat Payment Practice WeChat авторизует вход в систему и украшает страницу заказа, создает интерфейс заказа и инициирует запрос заказа

Серия uni-app: uni.navigateЧтобы передать скачок значения

Апплет WeChat настраивает верхнюю панель навигации и адаптируется к различным моделям.

JS-время конвертации

Обеспечьте бесперебойную работу ChromeDriver 125: советы по решению проблемы chromedriver.exe не найдены

Поле комментария, щелчок мышью, специальные эффекты, js-код

Объект массива перемещения объекта JS

Как открыть разрешение на позиционирование апплета WeChat_Как использовать WeChat для определения местонахождения друзей

Я даю вам два набора из 18 простых в использовании фонов холста Power BI, так что вам больше не придется возиться с цветами!

Получить текущее время в js_Как динамически отображать дату и время в js

Вам необходимо изучить сочетания клавиш vsCode для форматирования и организации кода, чтобы вам больше не приходилось настраивать формат вручную.

У ChatGPT большое обновление. Всего за 45 минут пресс-конференция показывает, что OpenAI сделал еще один шаг вперед.

Copilot облачной разработки — упрощение разработки

Микросборка xChatGPT с низким кодом, создание апплета чат-бота с искусственным интеллектом за пять шагов

CUDA Out of Memory: идеальное решение проблемы нехватки памяти CUDA

Анализ кластеризации отдельных ячеек, который должен освоить каждый&MarkerгенетическийВизуализация

vLLM: мощный инструмент для ускорения вывода ИИ

CodeGeeX: мощный инструмент генерации кода искусственного интеллекта, который можно использовать бесплатно в дополнение к второму пилоту.

Машинное обучение Реальный бой LightGBM + настройка параметров случайного поиска: точность 96,67%

Бесшовная интеграция, мгновенный интеллект [1]: платформа больших моделей Dify-LLM, интеграция без кодирования и встраивание в сторонние системы, более 42 тысяч звезд, чтобы стать свидетелями эксклюзивных интеллектуальных решений.

LM Studio для создания локальных больших моделей

Как определить количество слоев и нейронов скрытых слоев нейронной сети?
