CVPR 2024 | AVID: Раскрашивание видео произвольной длины на основе модели диффузии
Ссылка на статью:https://arxiv.org/abs/2312.03816 автор:Zhixing Zhang, Bichen Wu ждать Адрес проекта:https://github.com/zhang-zx/AVID Организация контента:Ван Хан В этой статье предлагается новая технология под названием AVID (любая длина). Video Inpainting with Diffusion Model)извидео Исправить。AVID能够处理不同长度извидео,И хорошо справляйтесь с различными задачами по редактированию видео. видео ремонт,Также известно как видеозаполнение (inpainting),означает в пределах заданной области маски видео,Следуйте текстовым подсказкам или инструкциям по редактированию.,Создавайте новый видеоконтент,Сохраняя исходное содержимое немаскированных областей нетронутым. автор проверил эффективность AVID Model с помощью широкого спектра экспериментов,и по сравнению с некоторыми существующими методами,Продемонстрировал свое превосходство в различных восстановительных задачах по производительности. также,В статье также представлены некоторые качественные результаты, показывающие,и чтобы Модельиз效率、Область применения、сравнительный анализ、абляционное исследование、Обсуждение ограничений и потенциальных направлений улучшения.
Введение
В этой статье представлен метод восстановления видео, который является универсальным для любой длительности видео и диапазона задач. В этой статье считается, что наиболее прямой метод редактирования видео для пользователей — это задать маску в первом кадре и отредактировать текст. Учитывая видео, область маски начального кадра и приглашение к редактированию, задача требует, чтобы модель заполняла рекомендации по редактированию в каждом кадре, сохраняя при этом целостность области вне маски. Есть три трудности: 1) Временная согласованность 2) Поддержка разных типов восстановления на разных уровнях структурной точности 3) Обработка видео произвольной длины
Эта статья предназначена для редактирования видео фиксированной длины. Наша модель оснащена эффективными модулями движения и регулируемыми структурными направляющими. Основываясь на этом, в данной статье предлагается конвейер выборки Temporal MultiDiffusion с механизмом управления вниманием промежуточного кадра для создания видео любой желаемой продолжительности.
Детали модели
AVID разработан на основе системы врисовки изображений с текстовым управлением. Модуль движения объединен для обеспечения согласованности времени в области редактирования. Модуль структурного руководства адаптирует модель к различной структурной точности. И конвейер генерации нулевых кадров, который использует механизм управления вниманием в середине кадра для улучшения управления видео любой длины.
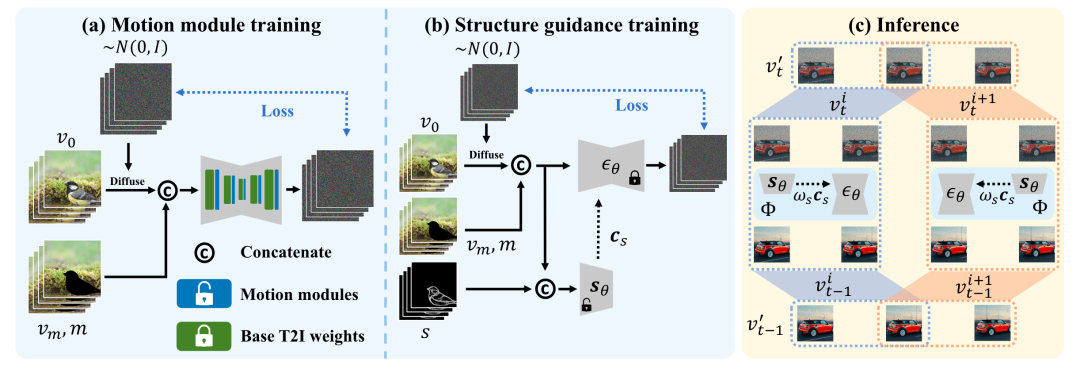
Рисунок 1
Видеозавершение текстового руководства
Для задач точного редактирования с учетом маски первого кадра в этой статье эта маска сначала расширяется на каждый кадр видео, чтобы получить последовательность масок. Для задачи обрезки для всех кадров предусмотрена одна и та же маска. Чтобы решить проблему временной непрерывности, мы обращаемся к AnimateDiff, чтобы расширить 2D-слой свертки до псевдо-3D, и добавляем модуль движения, чтобы изучить взаимосвязь между кадрами:
К условиям относятся области, не закрытые маской, маской и встраиванием текста. В процессе обучения оптимизируется только модуль движения, чтобы сохранить способность генерации исходной модели текстового изображения.
Структурное руководство по восстановлению видео
Учитывая, что задача покраски включает в себя различные типы подзадач, требования к точности поддержания конструкции различаются. Одним из распространенных типов ремонта является замена объектов, например «Заменить автомобиль на MINI Cooper»; другой тип — наложение текстуры (например, «Изменить цвет листа с красного на желтый» и существуют типы обрезки (например, «Заполнение областей выше»); и ниже") также популярны. Различные типы ремонта подразумевают разную структурную надежность. Например, если речь идет о преобразовании объекта, например, операции редактирования, заключающейся в превращении человека в статую, движения и структура исходного персонажа в области маски должны быть сохранены. Напротив, раскройка видео требует заполнения пустых областей для увеличения поля зрения без сигналов указания из области маски.

Рисунок 2. Различные типы рисования.
Наложение текстур требует сохранения структуры исходного видео, например, преобразование материала пальто человека в кожу (как показано), в то время как задачи по обрезке не должны быть такими точными. Поэтому автор разработал модуль структурного руководства, ссылаясь на конструкцию ControlNet, и зафиксировал параметры сети шумоподавления для обучения структурного модуля (на рисунке). Экстрактор структуры S используется для извлечения структурных признаков для каждого кадра. Извлеченные структурные признаки Cs содержат 13 карт признаков в 4 разрешениях, которые интегрируются в пропускное соединение сети шумоподавления и вход промежуточного слоя. В процессе вывода характеристики промежуточного слоя экстрактора будут иметь коэффициент для управления прочностью структурных особенностей.
Вывод нулевого кадра для длинных видео
Temporal MultiDiffusion
Теоретически модуль движения может генерировать видеоролики любой длины, но при создании видеороликов, длиннее обучающих, произойдет серьезное ухудшение качества. Temporal MultiDiffusion был разработан на основе MultiDiffusion. Сначала длинное видео разбивается на фрагменты с использованием псевдонимов. Конечный результат каждого кадра представляет собой среднее значение результатов шумоподавления, полученных для каждого фрагмента, содержащего этот кадр.
Middle-frame attention guidance
Хотя Multi Diffusion может сгладить вывод длинных видеороликов, автор обнаружил, что тема видео будет постепенно меняться, как показано на рисунке ниже.

Рисунок 3
Чтобы решить эту проблему, в этой статье вводится управление вниманием к промежуточному кадру, чтобы гарантировать, что сгенерированные объекты в каждом срезе являются непрерывными. Во-первых, 2D-самообслуживание расширяется до псевдо-3D-самообслуживания, а средний кадр в срезе используется в качестве ориентира на каждом уровне самообслуживания, как показано на рисунке ниже. Сила управления контролируется параметрами.
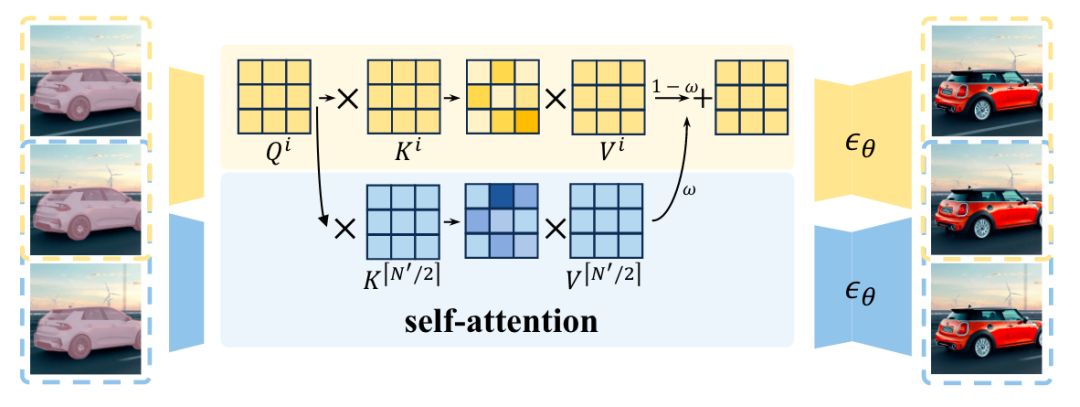
Рисунок 4
эксперимент
деталь
На основе предварительно обученной модели LDM. Используемый набор данных — это набор видеоданных Shutterstock после удаления водяных знаков. Обучение модуля движения настроено на 16 кадров случайной маски с разрешением 512x512. Кроме того, в качестве модуля управления используется энкодер Unet, который обучается с использованием того же набора данных. Используя HED в области синтеза в качестве направляющей информации для модуля управления, все параметры модуля управления участвуют в оптимизации.
Качественные результаты
Модель AVID была протестирована при различных типах монтажа видео разной продолжительности.,Включая замену объектов, обновление текстур и раскройку. Результаты эксперимента показывают, что,AVID способен обрабатывать изображения, не меняя окружающий контент.,Точно измените указанную область,И поддерживайте согласованность идентичности (например, цвета, структуры) сгенерированного контента в видеокадре.

Рисунок 5
AVID сравнивается с несколькими другими методами прорисовки видео на основе диффузионной модели, включая методы покадровой прорисовки. inpainting) и VideoComposer. показаны результаты эксперимента,AVIDПо предварительному заказудеталь、Превосходит другие методы с точки зрения сохранения фона и временной согласованности.。
Количественные результаты
Производительность модели оценивалась количественно с использованием трех автоматических показателей оценки: сохранение фона, выравнивание текста и видео и временная согласованность. AVID продемонстрировал отличные показатели по этим показателям.
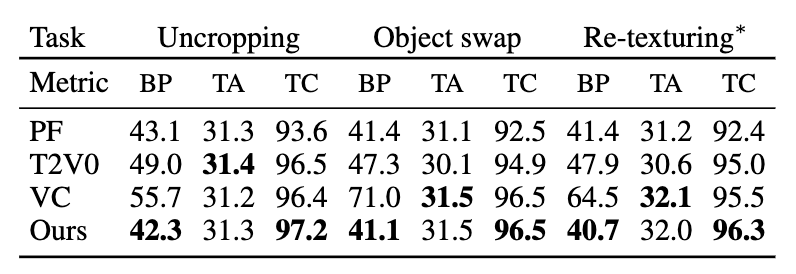
Рисунок 6
пользовательэксперимент
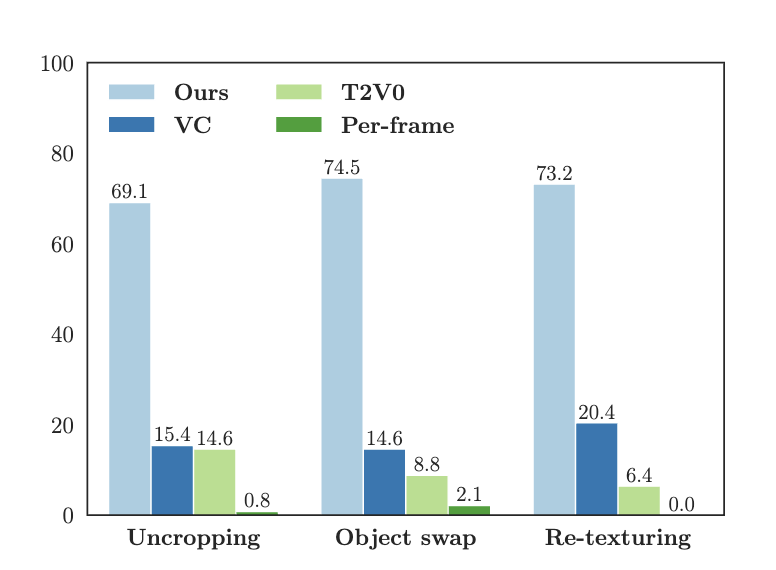
Рисунок 7
удалятьэксперимент
структурное руководство
показалструктурное Влияние коэффициента руководства на результаты редактирования видео, указывая на то, что разные подзадачи редактирования требуют разной структуры. руководство Пропорция。

Рисунок 8
Temporal MultiDiffusion
Исследуется эффективность временного конвейера мультидиффузионной выборки при обработке видео различной длины.

Рисунок 9
Механизм управления вниманием промежуточного кадра
Исследуется роль механизмов управления вниманием в поддержании согласованности идентичности между видеокадрами.

Рисунок 10



Учебное пособие по Jetpack Compose для начинающих, базовые элементы управления и макет

Код js веб-страницы, фон частицы, код спецэффектов

【новый! Суперподробное】Полное руководство по свойствам компонентов Figma.

🎉Обязательно к прочтению новичкам: полное руководство по написанию мини-программ WeChat с использованием программного обеспечения Cursor.

[Забавный проект Docker] VoceChat — еще одно приложение для мгновенного чата (IM)! Может быть встроен в любую веб-страницу!

Как реализовать переход по странице в HTML (html переходит на указанную страницу)

Как решить проблему зависания и низкой скорости при установке зависимостей с помощью npm. Существуют ли доступные источники npm, которые могут решить эту проблему?

Серия From Zero to Fun: Uni-App WeChat Payment Practice WeChat авторизует вход в систему и украшает страницу заказа, создает интерфейс заказа и инициирует запрос заказа

Серия uni-app: uni.navigateЧтобы передать скачок значения

Апплет WeChat настраивает верхнюю панель навигации и адаптируется к различным моделям.

JS-время конвертации

Обеспечьте бесперебойную работу ChromeDriver 125: советы по решению проблемы chromedriver.exe не найдены

Поле комментария, щелчок мышью, специальные эффекты, js-код

Объект массива перемещения объекта JS

Как открыть разрешение на позиционирование апплета WeChat_Как использовать WeChat для определения местонахождения друзей

Я даю вам два набора из 18 простых в использовании фонов холста Power BI, так что вам больше не придется возиться с цветами!

Получить текущее время в js_Как динамически отображать дату и время в js

Вам необходимо изучить сочетания клавиш vsCode для форматирования и организации кода, чтобы вам больше не приходилось настраивать формат вручную.

У ChatGPT большое обновление. Всего за 45 минут пресс-конференция показывает, что OpenAI сделал еще один шаг вперед.

Copilot облачной разработки — упрощение разработки

Микросборка xChatGPT с низким кодом, создание апплета чат-бота с искусственным интеллектом за пять шагов

CUDA Out of Memory: идеальное решение проблемы нехватки памяти CUDA

Анализ кластеризации отдельных ячеек, который должен освоить каждый&MarkerгенетическийВизуализация

vLLM: мощный инструмент для ускорения вывода ИИ

CodeGeeX: мощный инструмент генерации кода искусственного интеллекта, который можно использовать бесплатно в дополнение к второму пилоту.

Машинное обучение Реальный бой LightGBM + настройка параметров случайного поиска: точность 96,67%

Бесшовная интеграция, мгновенный интеллект [1]: платформа больших моделей Dify-LLM, интеграция без кодирования и встраивание в сторонние системы, более 42 тысяч звезд, чтобы стать свидетелями эксклюзивных интеллектуальных решений.

LM Studio для создания локальных больших моделей

Как определить количество слоев и нейронов скрытых слоев нейронной сети?
