Crowd LookALike и идеи для создания крауд-майнинга
Crowd LookALike — это заданная исходная популяция, а затем используются технические средства для поиска групп пользователей, похожих на исходную популяцию. Crowd LookALike часто используется в рекламе. Например, если клиент предоставляет ценную группу людей, с помощью рекламной платформы LookALike можно найти больше потенциальных ценных пользователей для рекламы. Ниже представлены несколько распространенных решений реализации LookALike.
Расчет сходства выполняется на основе пользовательских векторов. Используйте портретные данные, данные о поведении, данные о потреблении и т. д. для построения вектора признаков для каждого пользователя. Процесс построения основан на кодировании данных, нормализации данных и других средствах. Предполагая, что у пользователя есть 1000 тегов, можно построить массив длиной 1000. Значение каждого бита в массиве представляет значение соответствующего тега. Массив можно рассматривать как вектор пользователя. Вычислив векторное расстояние между каждым пользователем в исходной популяции и другими пользователями, не являющимися исходной популяцией, можно построить целевую популяцию, найдя ТОП-пользователей, ближайших к каждому пользователю. Методы расчета расстояний между векторами включают евклидово расстояние, расстояние Чебышева, расстояние Манхэттена и т. д., которые можно выбирать в соответствии с характеристиками бизнеса. Вектор пользователя также может быть реализован посредством встраивания в глубокое обучение. На рис. 5-26 показан основной процесс поиска толп LookALike на основе векторов.
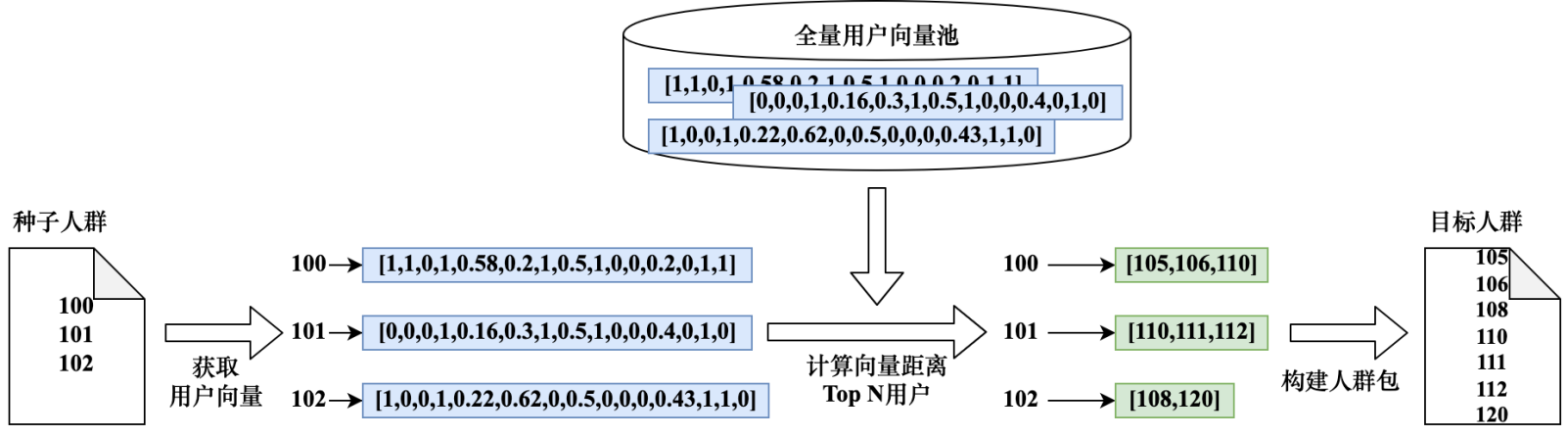
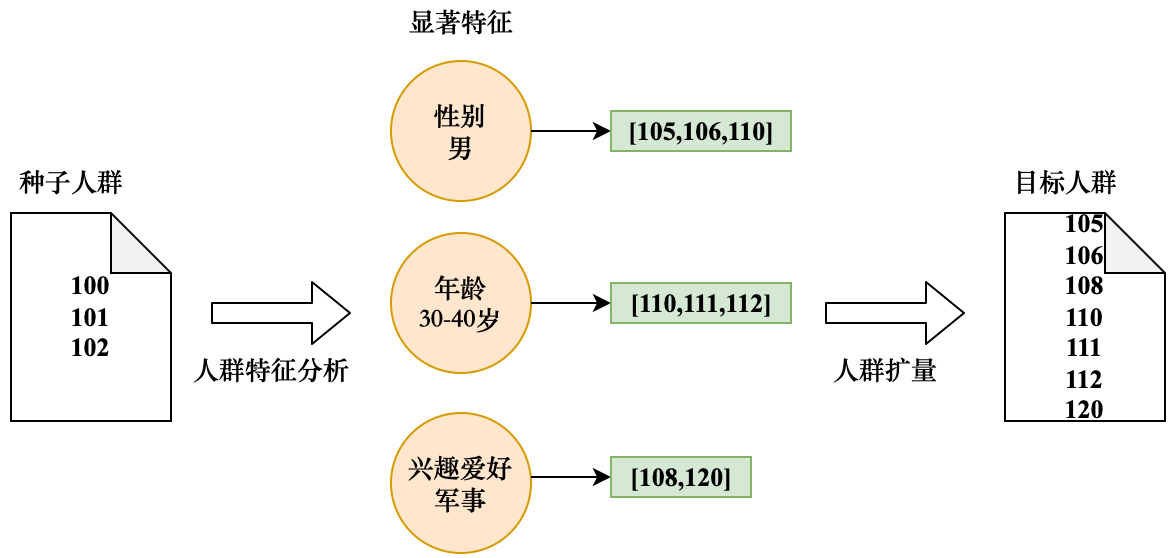
Рассчитайте аналогичные популяции на основе распределения признаков популяции семян. Используйте портретные данные для анализа характеристик семенной популяции и выясните ее основные характеристики этикетки. Например, этикеточные характеристики семенной популяции, как правило, следующие: мужской пол, возраст от 30 до 40 лет, хобби – военное. В качестве целевой группы были выбраны дети в возрасте от 40 лет, не относящиеся к группе семян. Целью этого метода является анализ профиля популяции семян и выяснение основных характеристик. Здесь основные характеристики распределения популяции семян можно найти путем сравнения TGI с крупномасштабными пользователями (активными ежедневно или ежемесячно). ). Процесс расчета похожих групп на основе распределения признаков показан на рисунке 5-27.
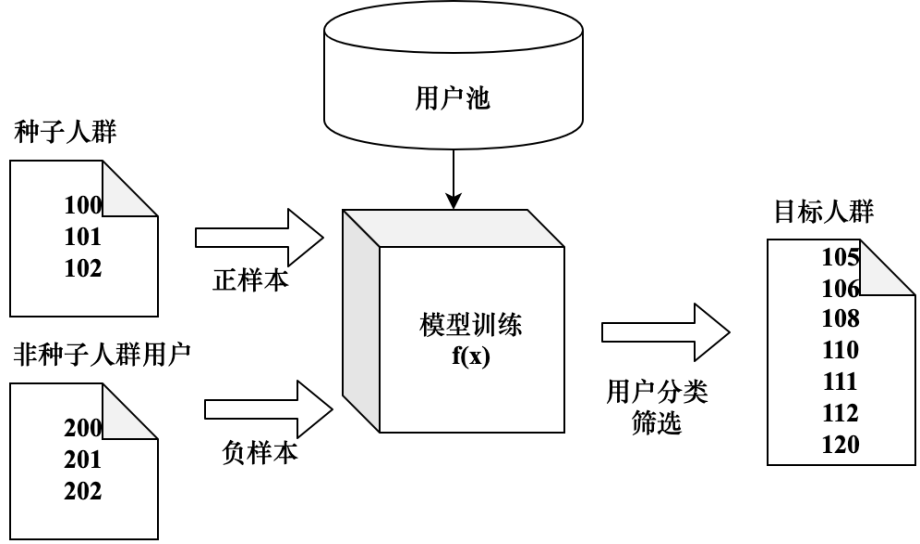
Вычислите похожие группы людей на основе алгоритмов классификации. Рассматривайте исходную популяцию как положительные образцы, а другие популяции, не являющиеся семенами (или другие популяции), как отрицательные выборки. Используйте модель обучающей классификации для расчета пользователей, соответствующих условиям, и создания целевой популяции. Вычисление похожих групп с помощью алгоритмов классификации также является распространенным решением реализации CrowdLookALike в отрасли. На рис. 5-28 показан основной процесс реализации. Модель классификации может использовать традиционные методы машинного обучения или глубокого обучения. В настоящее время также существуют практические решения для использования социальных сетей для проведения LookALike среди групп, использования дружеских отношений для поиска друзей нескольких степеней всех пользователей в исходной группе и построения целевой группы.
Анализ толпы заключается в определении целей оптимизации, использовании возможностей алгоритмов для поиска пользователей, соответствующих требованиям, и создании толпы. Группа правил находит пользователей, которые соответствуют требованиям, посредством «описанных» условий фильтрации, в то время как группа майнеров использует алгоритмы, чтобы лучше соответствовать характеристикам пользователей и более точно находить целевых пользователей на основе целей оптимизации бизнеса.
В сценарии игрового бизнеса, чтобы продвигать определенную игру-стрелялку, необходимо найти группу пользователей, которые готовы загрузить игру. Ориентация на эту группу во время продвижения игры может увеличить количество показов игры и охват сообщений. В ходе определенного мероприятия по раздаче подарков для пополнения баланса, чтобы увеличить количество пользователей пополнения баланса, участвующих в этом мероприятии, можно обнаружить группы пользователей с сильным желанием пополнить счет и использовать их в качестве ключевых целей рекламы при продвижении мероприятия. Некоторому большому V автору, чтобы помочь ему быстро увеличить количество поклонников, необходимо найти потенциальных пользователей, которым интересен пользователь и его произведения. Все приведенные выше примеры имеют конкретные цели оптимизации для крауд-майнинга: объем загрузки игры, количество пополнений и количество следующих пользователей. Инженер-алгоритмист выбирает подходящую модель для крауд-майнинга на основе этой цели.
Идея крауд-майнинга заключается в том, чтобы сначала найти обучающие образцы (начальную толпу), а затем расширить сид-толпу с помощью идеи LookALike. Разница между этим методом и толпой LookALike заключается в том, что результаты крауд-майнинга могут включать пользовательские данные в начальную толпу. Если взять в качестве примера вышеупомянутую деятельность по раздаче подарков для пополнения счета, то для того, чтобы определить группу пользователей с сильным желанием пополнить счет, первым шагом является поиск начальной группы пользователей, которые недавно пополнили счет, и пользователей, которые недавно сделали это. покупки в приложении можно рассматривать как начальную толпу; второй шаг — расширение на основе начальной толпы. Идея реализации аналогична толпе LookALike. Целевую толпу можно рассчитать через векторное расстояние между пользователями, извлекая ключевые характеристики. исходную толпу и использование алгоритмов классификации.
Эта статья взята из книги «Портреты пользователей: построение платформ и бизнес-практика». При перепечатке указывайте источник.




Углубленный анализ переполнения памяти CUDA: OutOfMemoryError: CUDA не хватает памяти. Попыталась выделить 3,21 Ги Б (GPU 0; всего 8,00 Ги Б).

[Решено] ошибка установки conda. Среда решения: не удалось выполнить первоначальное зависание. Повторная попытка с помощью файла (графическое руководство).

Прочитайте нейросетевую модель Трансформера в одной статье

.ART Теплые зимние предложения уже открыты

Сравнительная таблица описания кодов ошибок Amap

Уведомление о последних правилах Points Mall в декабре 2022 года.

Даже новички могут быстро приступить к работе с легким сервером приложений.

Взгляд на RSAC 2024|Защита конфиденциальности в эпоху больших моделей

Вы используете ИИ каждый день и до сих пор не знаете, как ИИ дает обратную связь? Одна статья для понимания реализации в коде Python общих функций потерь генеративных моделей + анализ принципов расчета.

Используйте (внутренний) почтовый ящик для образовательных учреждений, чтобы использовать Microsoft Family Bucket (1T дискового пространства на одном диске и версию Office 365 для образовательных учреждений)

Руководство по началу работы с оперативным проектом (7) Практическое сочетание оперативного письма — оперативного письма на основе интеллектуальной системы вопросов и ответов службы поддержки клиентов

[docker] Версия сервера «Чтение 3» — создайте свою собственную программу чтения веб-текста

Обзор Cloud-init и этапы создания в рамках PVE

Корпоративные пользователи используют пакет регистрационных ресурсов для регистрации ICP для веб-сайта и активации оплаты WeChat H5 (с кодом платежного узла версии API V3)

Подробное объяснение таких показателей производительности с высоким уровнем параллелизма, как QPS, TPS, RT и пропускная способность.

Удачи в конкурсе Python Essay Challenge, станьте первым, кто испытает новую функцию сообщества [Запускать блоки кода онлайн] и выиграйте множество изысканных подарков!

[Техническая посадка травы] Кровавая рвота и отделка позволяют вам необычным образом ощипывать гусиные перья! Не распространяйте информацию! ! !

[Официальное ограниченное по времени мероприятие] Сейчас ноябрь, напишите и получите приз

Прочтите это в одной статье: Учебник для няни по созданию сервера Huanshou Parlu на базе CVM-сервера.

Cloud Native | Что такое CRD (настраиваемые определения ресурсов) в K8s?

Как использовать Cloudflare CDN для настройки узла (CF самостоятельно выбирает IP) Гонконг, Китай/Азия узел/сводка и рекомендации внутреннего высокоскоростного IP-сегмента

Дополнительные правила вознаграждения амбассадоров акции в марте 2023 г.

Можно ли открыть частный сервер Phantom Beast Palu одним щелчком мыши? Супер простой урок для начинающих! (Прилагается метод обновления сервера)

[Играйте с Phantom Beast Palu] Обновите игровой сервер Phantom Beast Pallu одним щелчком мыши

Maotouhu делится: последний доступный внутри страны адрес склада исходного образа Docker 2024 года (обновлено 1 декабря)

Кодирование Base64 в MultipartFile

5 точек расширения SpringBoot, супер практично!

Глубокое понимание сопоставления индексов Elasticsearch.

15 рекомендуемых платформ разработки с нулевым кодом корпоративного уровня. Всегда найдется та, которая вам понравится.
