ByteDance Seed-TTS: революция в технологии синтеза речи искусственного интеллекта
Привет, друзья, сегодняшняя тема — изучение TTS. Недавняя работа связана с микшированием и обрезкой видео с помощью искусственного интеллекта, что требует синтеза тембра. Давайте посмотрим на относительно зрелые технологии на рынке, которые являются эффективными и экономически выгодными!
Весь сегодняшний контент связан с TTS. Если у вас есть дополнительные рекомендации, оставьте сообщение ~.
На волне развития искусственного интеллекта технология преобразования текста в речь (TTS) становится все более важной. Он не только позволяет умным помощникам «говорить», но и обеспечивает дубляж видео и игр и даже помогает слабовидящим людям «читать» текст. Команда Seed компании ByteDance вывела эту технологию на новый уровень благодаря своей модели Seed-TTS.
Что такое Сид-ТТС?
Seed-TTS — это серия моделей TTS, разработанная Bytedance Seed Team. Они не только могут синтезировать высококачественную речь, неотличимую от человеческой речи, но также могут генерировать управляемую, высококачественную синтетическую речь на основе короткой записи с нулевыми выборками.

Технические характеристики
- Естественность и выразительность:Seed-TTSсинтетическийголос Достижение человеческого уровня естественности и выразительности。
- Обучение речевому контексту с нулевым выстрелом:Нет необходимости в больших выборках,Вы можете учиться и имитировать определенные характеристики голоса.
- Тонкая настройка динамиков и контроль эмоций:путем тонкой настройки,Модель способна лучше имитировать голос конкретного говорящего.,и контролировать эмоциональное выражение.
Техническая архитектура
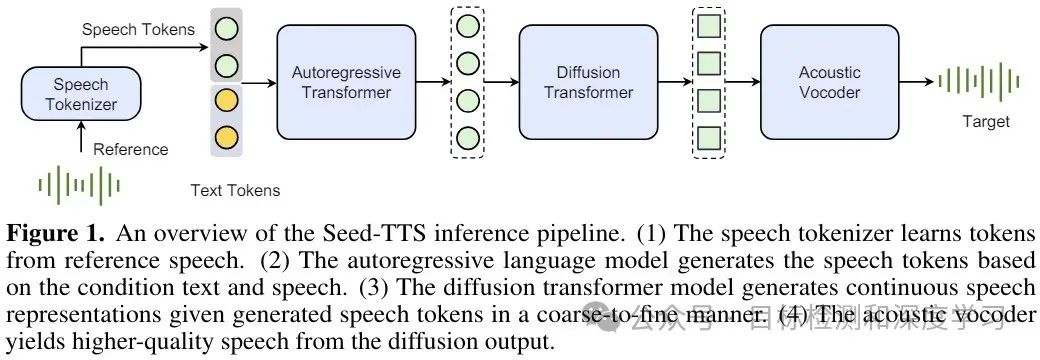
Seed-TTS основан на модели авторегрессионного трансформатора и включает в себя четыре основных модуля: речевой токенизатор, модель языка токенов, модель диффузии токенов и акустический вокодер. Эта архитектура делает Seed-TTS более эффективным и точным при обработке синтеза речи.
Экспериментирование и оценка
Seed-TTS оценивается при выполнении нескольких задач, включая изучение речевого контекста с нулевым выстрелом, тонкую настройку говорящего и контроль эмоций. Результаты экспериментов показывают, что Seed-TTS обладает хорошими показателями естественности, стабильности и управляемости.
- Контекстное обучение с нулевого выстрела:В объективном и субъективном тестировании,Производительность Seed-TTS аналогична работе реальных людей.,Даже сложно заметить разницу.
- Тонкая настройка динамиков:путем тонкой настройки,Seed-TTS способен более точно имитировать вокальные характеристики конкретного говорящего.
Сценарии применения
Seed-TTS предлагает широкий спектр сценариев применения, включая, помимо прочего, персональных умных помощников.、саундтрек к видеоигре、производство аудиокниг、Межъязыковой TTS、преобразование голоса и многое другое.
прогноз на будущее
Ожидается, что благодаря постоянному развитию технологий Seed-TTS будет играть важную роль во многих областях и предоставлять людям более богатый и естественный опыт голосового взаимодействия.



Учебное пособие по Jetpack Compose для начинающих, базовые элементы управления и макет

Код js веб-страницы, фон частицы, код спецэффектов

【новый! Суперподробное】Полное руководство по свойствам компонентов Figma.

🎉Обязательно к прочтению новичкам: полное руководство по написанию мини-программ WeChat с использованием программного обеспечения Cursor.

[Забавный проект Docker] VoceChat — еще одно приложение для мгновенного чата (IM)! Может быть встроен в любую веб-страницу!

Как реализовать переход по странице в HTML (html переходит на указанную страницу)

Как решить проблему зависания и низкой скорости при установке зависимостей с помощью npm. Существуют ли доступные источники npm, которые могут решить эту проблему?

Серия From Zero to Fun: Uni-App WeChat Payment Practice WeChat авторизует вход в систему и украшает страницу заказа, создает интерфейс заказа и инициирует запрос заказа

Серия uni-app: uni.navigateЧтобы передать скачок значения

Апплет WeChat настраивает верхнюю панель навигации и адаптируется к различным моделям.

JS-время конвертации

Обеспечьте бесперебойную работу ChromeDriver 125: советы по решению проблемы chromedriver.exe не найдены

Поле комментария, щелчок мышью, специальные эффекты, js-код

Объект массива перемещения объекта JS

Как открыть разрешение на позиционирование апплета WeChat_Как использовать WeChat для определения местонахождения друзей

Я даю вам два набора из 18 простых в использовании фонов холста Power BI, так что вам больше не придется возиться с цветами!

Получить текущее время в js_Как динамически отображать дату и время в js

Вам необходимо изучить сочетания клавиш vsCode для форматирования и организации кода, чтобы вам больше не приходилось настраивать формат вручную.

У ChatGPT большое обновление. Всего за 45 минут пресс-конференция показывает, что OpenAI сделал еще один шаг вперед.

Copilot облачной разработки — упрощение разработки

Микросборка xChatGPT с низким кодом, создание апплета чат-бота с искусственным интеллектом за пять шагов

CUDA Out of Memory: идеальное решение проблемы нехватки памяти CUDA

Анализ кластеризации отдельных ячеек, который должен освоить каждый&MarkerгенетическийВизуализация

vLLM: мощный инструмент для ускорения вывода ИИ

CodeGeeX: мощный инструмент генерации кода искусственного интеллекта, который можно использовать бесплатно в дополнение к второму пилоту.

Машинное обучение Реальный бой LightGBM + настройка параметров случайного поиска: точность 96,67%

Бесшовная интеграция, мгновенный интеллект [1]: платформа больших моделей Dify-LLM, интеграция без кодирования и встраивание в сторонние системы, более 42 тысяч звезд, чтобы стать свидетелями эксклюзивных интеллектуальных решений.

LM Studio для создания локальных больших моделей

Как определить количество слоев и нейронов скрытых слоев нейронной сети?
