ByteDance DevMind: подробное объяснение построения и эволюции платформы измерения производительности для десятков тысяч людей.

Автор | Чэн Синь
В сегодняшних условиях, когда предприятия сокращают затраты и повышают эффективность, уменьшая количество жира и увеличивая вес, измерение эффективности НИОКР на платформе больших данных стало важным ключом к повышению эффективности НИОКР предприятия и качества продукции. В этой статье представлен полный процесс эволюции платформы измерения производительности исследований и разработок Byte от 0 до 1. Объясняя различные противоречия, возникающие в процессе инженерной реализации, в простой и понятной форме, она помогает читателям лучше применять технические решения и углублять их понимание. -глубокое мышление в этой области.
Что такое Дев Майнд?
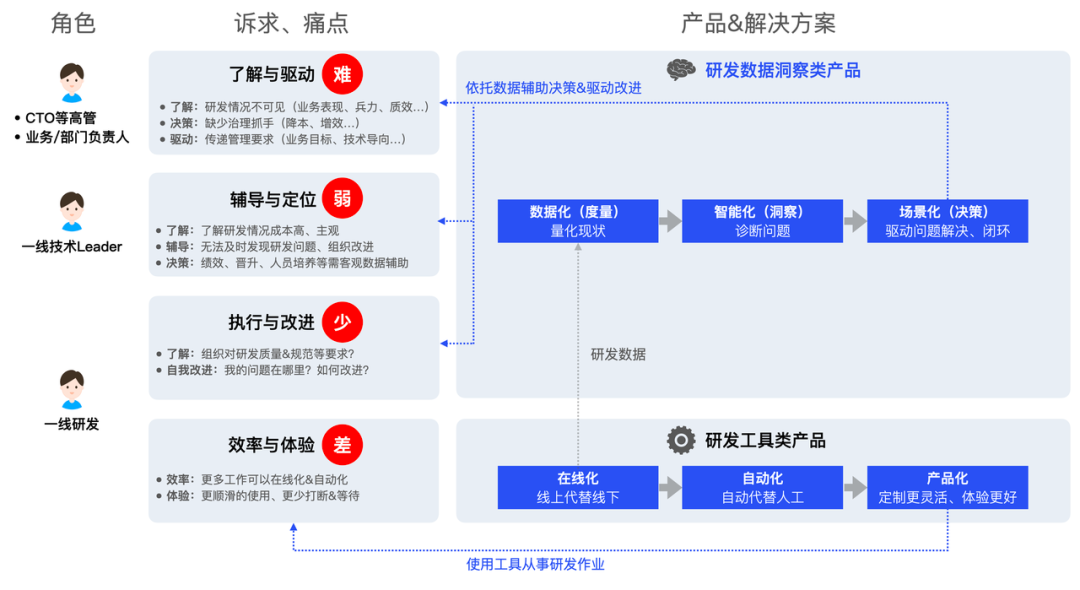
DevMind Это цифровые продукты и решения ByteDance, занимающиеся исследованиями и разработками, целью которых является улучшение текущей ситуации на всех уровнях исследований и разработок. & Проблемы можно визуализировать, оценить и диагностировать, чтобы помочь в принятии решений и улучшении, достигая «повышения эффективности НИОКР на основе данных». Что включает в себя 3 ключевые компетенции:
- Измерьте, дайте количественную оценку текущей ситуации:все Он объединяет все большие данные, а эксперты в этой области преобразуют свой опыт в индексы и модели анализа.
- Понимание, диагностика проблем:верно НИОКРИндикаторы автоматическиданные Понимание,Сформируйте объективные и точные выводы анализа.
- Принятие решений способствует решению проблем:Помощник бизнес-менеджера、TL、Во фронтовом НИОКР понимают объективную ситуацию、вопрос、Решение, принятие научных решений в каждой Работасцене (сцена в основном включает в себя: улучшения НИОКР、Управление командой、НИОКР процесс идентификации рисков и т.д.).
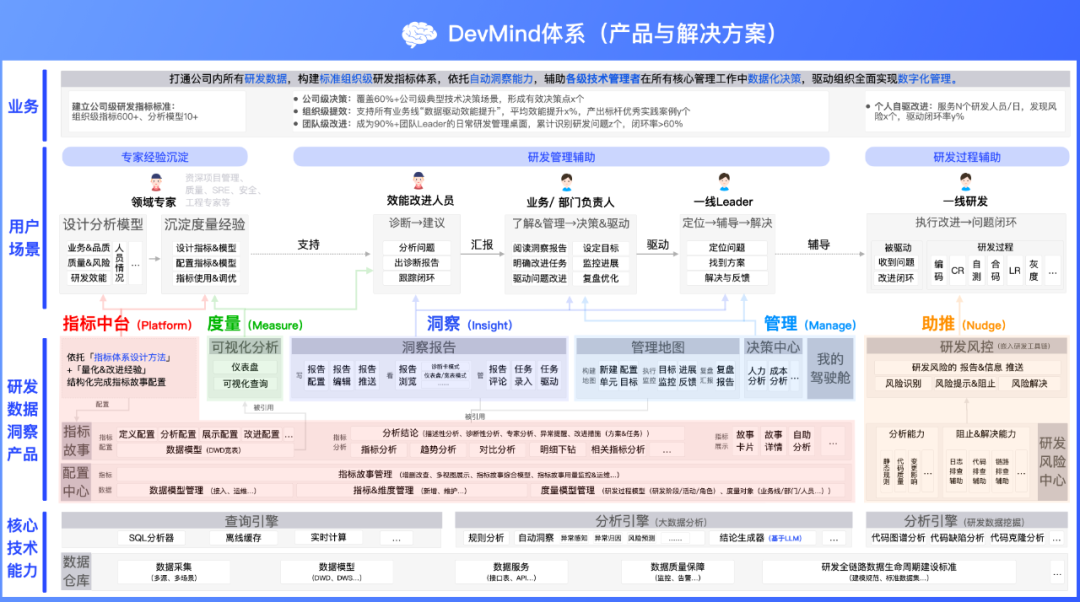
Узнать больше DevMind система:Создайте «навигатор» и «движок» для повышения эффективности и реализации перехода от данных к ценности.
Техническая архитектура DevMind показана на рисунке ниже:


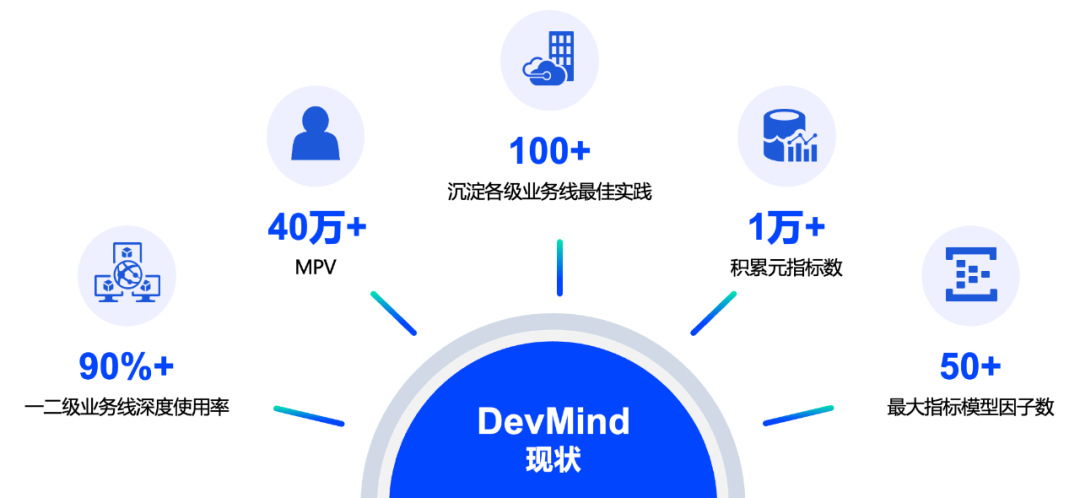
В этой статье будут обсуждаться соответствующие аспекты бизнес-инжиниринга и обработки данных. 3 большой“противоречие”Расширять,Объясните подробно,Как создать платформу измерения эффективности для десятков тысяч людей,существовать“Оба хотят, хотят и хотят”под невыполнимыми требованиями,Проектирование и реализация инженерных возможностей,Для достижения бизнес-целей в условиях ограниченного времени и ограниченной рабочей силы.
Подробное объяснение бизнес-инжиниринга
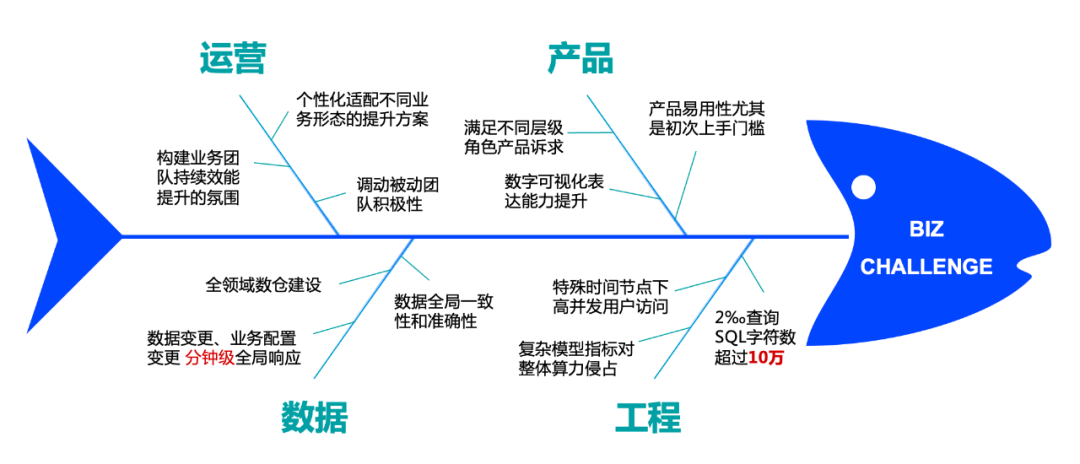
В области бизнес-инжиниринга существуют три основных противоречия:
- Противоречие 1:данныеполе、противоречие диверсификации ролей и эффективности совместной работы пользователей.
- Противоречие 2:платформаполе Профессионализми用户非Профессионализм的противоречие。
- Противоречие 3:сценасложность(данныешкала,структура данных, сложность алгоритма,Частота изменения), а также стабильность и производительность системы.
Поэтому нам нужно иметь 3 набора планов, чтобы победить их одного за другим.
2.1 Стимулирование производительности
Противоречие 1. Противоречие между предметной областью, диверсификацией ролей и эффективностью совместной работы пользователей.
Связь между эффективностью НИОКР длинная и охватывает множество областей. Каждое поле имеет свой собственный уникальный порог знаний предметной области. Чтобы лучше сгладить эти барьеры при анализе визуализации данных, необходимо построить полноценную систему данных, и Involve играет ключевую роль в канале передачи данных. Трудности в процессе внедрения отражаются в основном в трех аспектах:
1. Множество полей данных:
2. Множество пользовательских ролей:
3. Роли пользователей имеют разные возможности и существуют препятствия для сотрудничества:

Непосредственной причиной этого противоречия является профессиональный порог анализа данных, что приводит к недостаточному набору инженеров данных и аналитиков, при этом бессильны студенты-бизнесмены, не получившие профессиональной подготовки.

Основная причина заключается в том, что профессионализм информационных продуктов является высокомерным, и нет реального сочувствия потребностям обычных пользователей.

2.1.1 Решите цель
Понизьте порог пользователя, чтобы все роли, такие как продукт, операция, контроль качества и т. д., могли беспрепятственно использовать его.
2.1.2 Решение
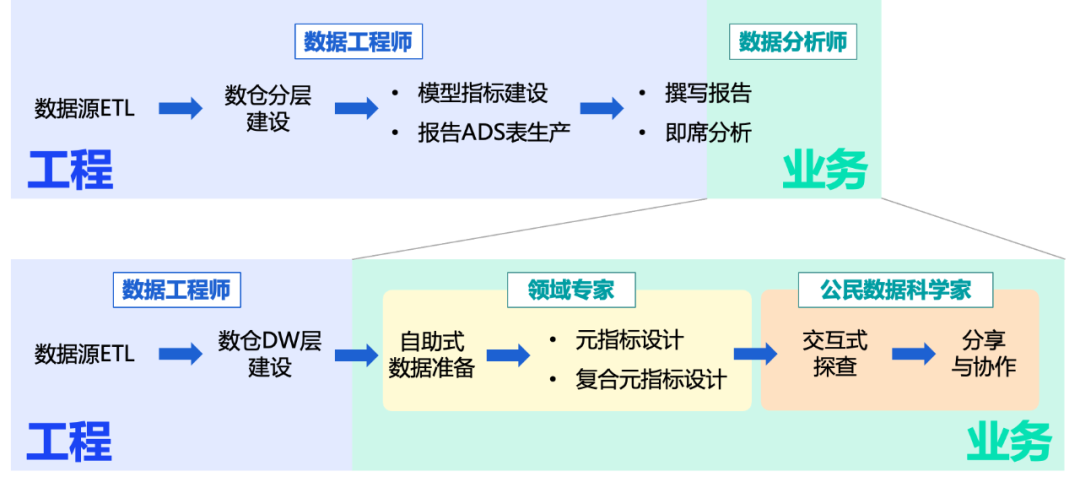
2.1.2.1 Процесс изменения формы
DevMind перепроектирует метод взаимодействия анализа визуализации данных, заменяя традиционный «выбор источников данных в качестве отправной точки» на «взятие индикаторов в качестве ядра». Позвольте опытным аналитикам данных и экспертам в предметной области сосредоточиться на разработке основных показателей и моделей анализа данных. Позвольте большему количеству участников бизнеса завершить исследование данных по индикаторам или воспроизвести производные индикаторы.
Такое изменение формы взаимодействия не только повышает продуктивность экспертов в предметной области, но, что более важно, взаимодействие, ориентированное на показатели, значительно снижает порог понимания и использования для непрофессиональных пользователей. Кроме того, изменения в форме производства означают, что индикаторная платформа DevMind больше не является обходным инструментом управления метаинформацией, а может активно участвовать во всем производственном звене. Таким образом, это изменение эффективно позволяет избежать проблемы, когда активы данных, первоначально размещенные на платформе индикаторов, постепенно повреждаются и истекают из-за отделения от последующей бизнес-деятельности.
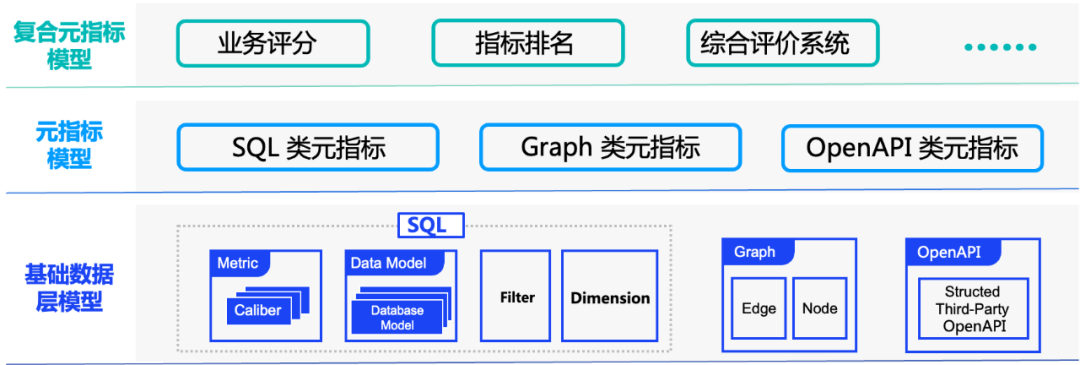
2.1.2.2 Абстрактные средства производства — модель метаиндекса
Основная идея:к“Метаметрический + Объект измерения”двоичная формаверно Базаданные Высокоинкапсулированный слой,Сделайте так, чтобы он имел полное деловое значение и был независимо исполняемым.
модель метаиндикатора:из материального мираприезжатьматематическое преобразование。Воляданные Визуальная конфигурация разлагается на разработку логики бизнес-запросов и настройку визуальных выражений.。
сложныймодель метаиндикатора:Алгебраические матрицы с богатыми бизнес-принципами。вспомогательныйк Арифметические операторы и логические операторы для получения бизнес-выражений более высокого уровня.。
2.2 Повышение производительности
Противоречие 2 — Противоречие между профессионализмом в платформенной сфере и непрофессионализмом среди пользователей.
Даже будучи официальной платформой измерения производительности, DevMind Он также не может справиться с почти неограниченными потребностями бизнеса при ограниченной рабочей силе. Если мы хотим продвигать концепцию повышения эффективности во всем коллективе компании НИОКР, нам необходимо вовлечь в работу каждого студента, связанного с бизнес-направлением. Легче найти идеи, соответствующие реальному бизнесу, когда их анализируют студенты, которые лучше всего разбираются в бизнесе. Гражданский представлен здесь специалист по даннымконцепция。Гражданский специалист по данным (Citizen Data Ученый) относится к работникам умственного труда без формального обучения в области высшей математики и статистики, которые могут извлекать ценную информацию из данных с помощью адаптированных прикладных продуктов.
DevMind стремится постоянно снижать пороговые значения для анализа данных и помогать гражданским ученым, работающим с данными, создавать более качественные аналитические отчеты.
2.2.1 Решите цель
Пополняйте библиотеку инструментов алгоритмов автоматического анализа, оптимизируйте эффективность пользовательского анализа и узнавайте, что происходит и почему.
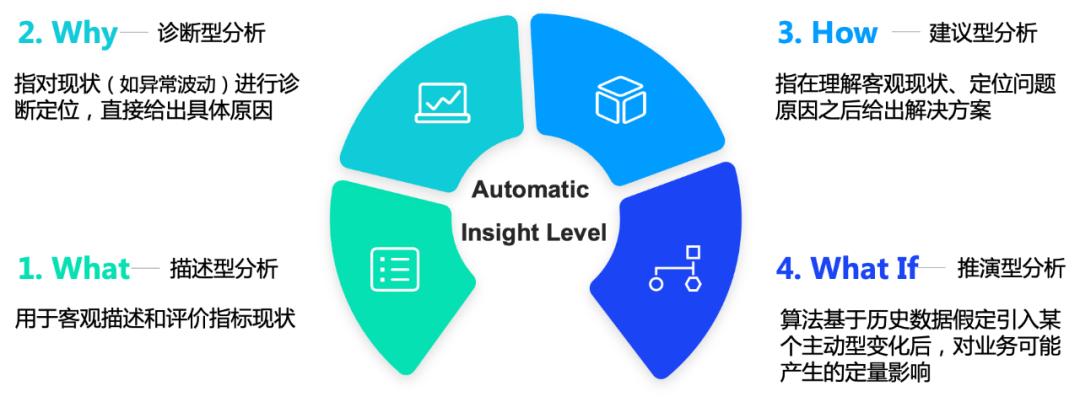
2.2.2 Решение
2.2.2.1 Почему – анализ колебаний (показатель соотношения)
Трудности с показателями соотношения:
Математически: показатели соотношения неаддитивны и не могут быть непосредственно разложены на измерения, поэтому классические методы анализа, такие как вклад, не могут быть применены.
Бизнес-уровень: Размеры числителя и знаменателя показателя соотношения не совпадают строго, и необходимо учитывать как минимум три сценария, что также увеличивает сложность анализа.
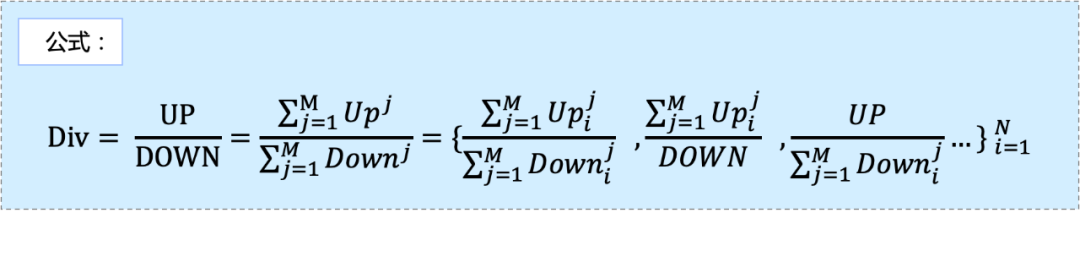
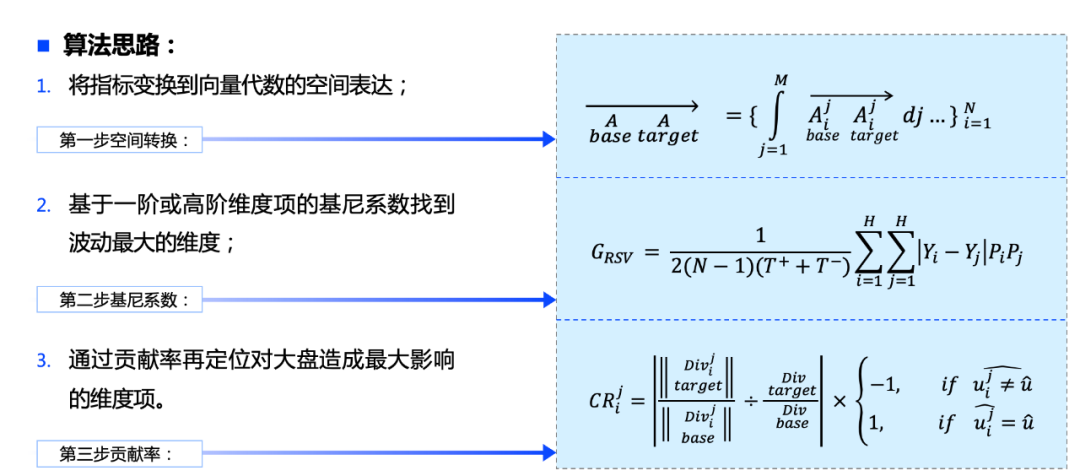
2.2.2.2 Как — анализ потенциала
Требования:
На основе анализа колебаний можно эффективно определить первопричину измерения, вызывающую аномальные колебания, но иногда это не то направление оптимизации, которое может быть непосредственно принято бизнесом. Следовательно, необходимы более совершенные алгоритмы, чтобы сообщить бизнес-стороне, какое направление имеет наибольший потенциал оптимизации.
Основная идея:
Регрессия среднего: предполагается, что значения компонентов измерения будут колебаться вокруг среднего значения измерения, и вероятность колебаний, приближающихся к среднему значению, выше, чем вероятность отклонения от среднего значения.
Отдайте приоритет элементам с высокой долей: если каждый элемент измерения в указанном измерении изменяется с одинаковым фиксированным соотношением, элемент измерения с высокой долей будет иметь большее влияние на рынок.
Разреженность измерений: на основе обработки разреженности измерения с меньшим количеством элементов измерения не могут влиять на общий рынок, тем самым решая проблему влияния количества элементов измерения на общий рынок.

2.3 Количественная оценка производительности
Противоречие 3. Противоречие между сложностью сценария (масштабом данных, структурой данных, сложностью алгоритма, частотой изменений) и стабильностью и производительностью системы.
Вычислительная мощность DevMind как продукта данных является наиболее важным фактором в области исследований и разработок. Поэтому мы надеемся создать комплексную систему оценки вычислительной мощности, которая сможет точно и количественно описать текущую ситуацию DevMind. Эта система оценки вычислительной мощности будет использоваться в различных сценариях, таких как управление эксплуатацией и техническим обслуживанием, проверка доступа к новым потребностям и количественная оценка технологических преобразований.
2.3.1 Решите цель
Разрушьте черный ящик и получите точное количественное описание общего текущего состояния платформы, создав комплексную систему оценки вычислительной мощности. В настоящее время у нас есть полный черный ящик в отношении ситуации с вычислительной мощностью, и у нас даже нет точного определения «вычислительной мощности».
Конкретный бизнес-сценарий: полугодовой сезон производительности. Сезон производительности — это пиковый период посещения DevMind пользователями. На основе исторических данных мы можем узнать количество посещений пользователей и уровень проникновения. Но какой новый спрос на «вычислительную мощность» будет стоять за этим объемом трафика и какой спрос на «вычислительную мощность» может выдержать текущая база данных? Эти вопросы неизвестны.
Все, что мы делаем, это готовимся как можно лучше и молимся, чтобы ничего не пошло не так. Вы не можете управлять тем, что не измеряете. Что нам действительно нужно сделать, так это точно описать текущую ситуацию и количественно описать спрос и запас «вычислительных мощностей».
2.3.2 Решение
2.3.2.1 Уточнение сценариев применения
- Стабильность работы и обслуживания:на на основе Полной сцены мониторинга энергопотребления компьютеров для ежедневной эксплуатации и обслуживания Работа. И обеспечить поддержку данных для ресурсных приложений, таких как операционная деятельность.
- Проверка поступления новых требований:
- Метод расчета: {Стоимость вычислительной мощности} = {Стоимость вычислительной мощности за доступ к функциональной точке} × {Уровень проникновения пользователей функциональных точек}
- Бизнес-ограничения: {Общая вычислительная мощность платформы} ≥ {Накладные расходы на вычислительную мощность инвентаризации} + {Новая требуемая стоимость вычислительной мощности}
- Количественная оценка преимуществ технологических инноваций:Создание эталонного уровня вычислительной мощности платформы,Это обеспечивает справедливую основу для количественного выигрыша после оптимизации производительности технологии.
2.3.2.2 Разработка модели оценки вычислительной мощности
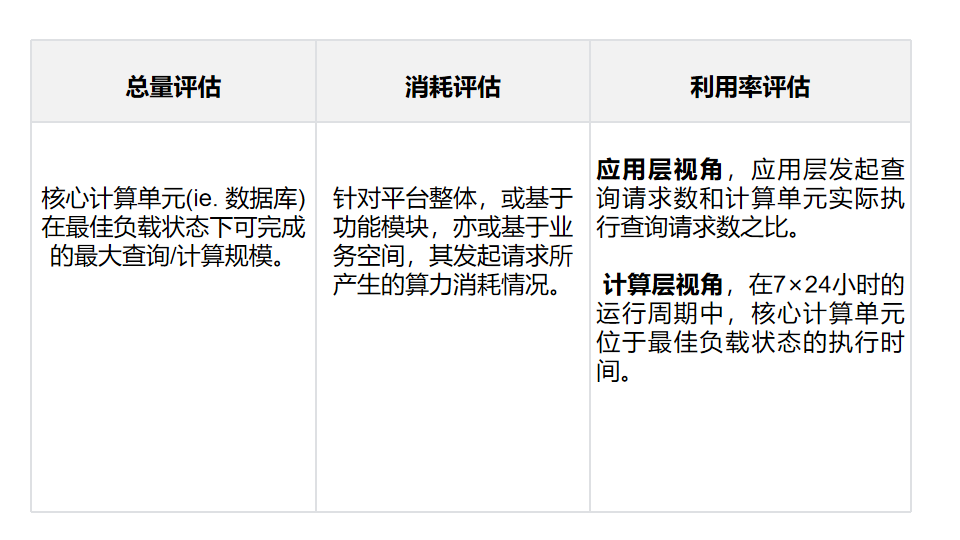
Измерение «вычислительной мощности» происходит с двух аспектов. Первый — это производитель, то есть база данных. Для базы данных вычислительная мощность означает максимальное количество запросов, которые могут быть выполнены в единицу времени. Второй — потребитель, которым является платформа DevMind. Вычислительная мощность, потребляемая потребителями, представляет собой количество запросов данных, генерируемых каждой функциональной точкой, умноженное на единицу времени PV каждой функциональной точки. Когда вычислительная мощность, производимая базой данных, превышает или равна вычислительной мощности, потребляемой платформой DevMind, мы можем считать общий доход разумным.
В приведенном выше обсуждении «вычислительная мощность» является абстрактным понятием, поэтому сначала нам нужно материализовать «вычислительную мощность».
2.3.2.2.1 Классификация оценки вычислительной мощности

2.3.2.2.2 Упрощенная модель преобразования вычислительной мощности

- Определение вычислительной мощности:верно Вданныепродукт,Вычислительная мощность — это физические затраты, необходимые для достижения бизнес-целей.
- Преобразование вычислительной мощности:проходить「Контрольный «запрос», как среда и базовая единица, связывающая производственную и потребительскую стороны, материализует абстрактное понятие «вычислительная мощность».
- Контрольный запрос:Выбирать Форма Самый универсальный и легко обобщаемый продукт. Кейс может быть эквивалентно преобразован в различные бизнес-сценарии или получен в результате стресс-тестирования вычислительного блока.
- Моделирование потребительской вычислительной мощности:
- Объект анализа модели — это запрос запроса, сгенерированный пользователем во время использования функции продукта в течение заданного временного окна.
- Со стороны пользователя необходимо учитывать масштаб различных типов пользователей, а также частоту и глубину доступа.
- продуктсторона,Учитывается потребление вычислительной мощности каждой функциональной точки продукта.,а также глубина и масштаб продукта в различных пользовательских пространствах.
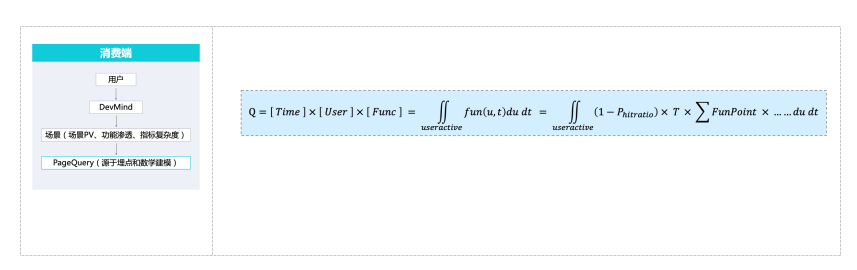
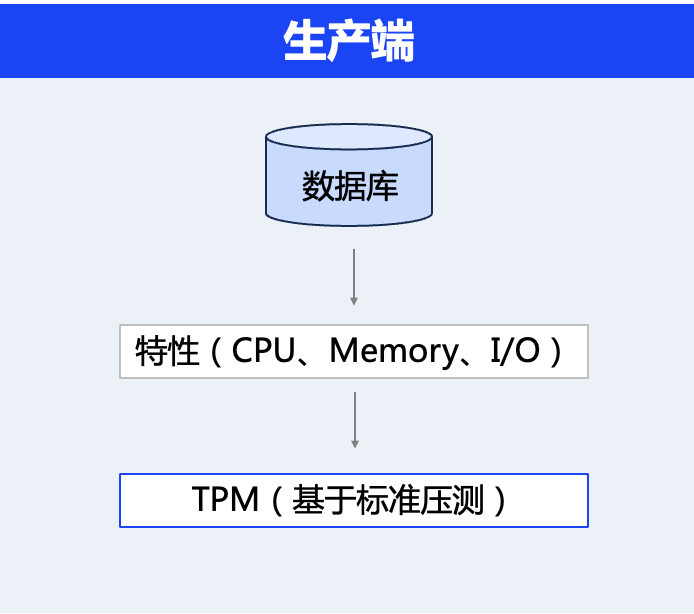
2.3.2.2.3 Моделирование вычислительной мощности на производственной стороне
- определение:Общий объем вычислительной мощности определяется вычислительным уровнем самой сервисной архитектуры.физические Решения в области интеллектуальной собственности и инженерной реализации принимаются совместно. Стандарт стратегии для общего объема вычислительной мощности основан на библиотеке данных. TPM(transactions per minute) Концепция принята: «1 Максимум минут исполняемый Контрольный запросчисло」。
- физические свойства:CPU、I/O、Memory、Емкость диска、Компьютерный зал и т. д.
- Технические характеристики:данные Тип и версия библиотеки,Выбор индекса, оптимизация реализовать、Настройка алгоритма и т. д.
2.3.2.2.4 Идеи по оптимизации вычислительной энергетики
Анализ оптимизации вычислительной мощности на основе принципа MECE:

- Повышенная вычислительная мощность:
- Замена механизма запросов: OLAP HSAP
- Обновление режима запроса: самостоятельное создание SQL оптимизация器
- 算力利用率提升:
- Использование уровня приложения: усовершенствованное кэширование, дедупликация запросов.
- Использование вычислительного уровня: переключение между передними и задними задачами на основе мультиплексирования с временным разделением
- Распределение вычислительной мощностиоптимизация:
- данныестадия производства:предварительная обработка && Предварительные вычисления
- этап потребления данных: динамическое планирование между кластерами
- ссылка на данные: автономная интегрированная система хранения и вычислений.
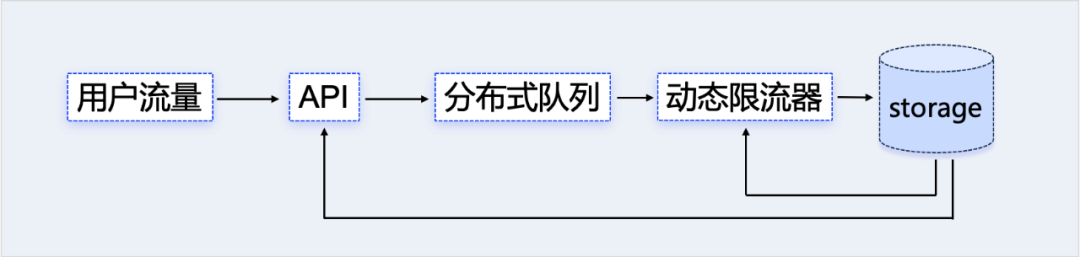
2.3.2.2.5 Динамическая регулировка вычислительной мощности: режим противодавления
В системе вызова данных участвуют три стороны: производитель генерирует запросы и передает их потребителю через конвейер. Когда темп производства производителя превышает пропускную способность потребителя, можно вывести три стратегии:
- Буфер:Воля Временное хранение лишнего трафикасуществоватьвнутри трубы,Затем потребители выполняют их один за другим.
- Отказаться:Когда восходящий поток превышает пропускную способность нисходящего потока,Когда длина очереди также превышена,Лишний трафик необходимо перенаправить.
- Контроль Контроль:Снизить скорость потребительского производства,Уменьшите трафик непосредственно из источника.
Вышеупомянутые три стратегии на самом деле не изолированы в инженерной практике. DevMind обеспечивает динамическое управление общим циклом данных с помощью адаптивной системы противодавления.
- Обратное Давление:проходить Датчик нагрузки определяет давление нагрузки потребителя。Когда нагрузка превышает порог,Сообщите о давлении обратно в восходящий поток,Дать возможность добывающим компаниям и трубопроводам чувствовать противодавление и реализовывать соответствующие стратегии.,Для достижения цели адаптивной регулировки скорости потока.
- Динамический ограничитель тока:проходить Измерение противодавления и динамическая регулировка ограничения общего тока。Когда срабатывает ограничение тока,на Конфигурация «основаOnline» позволяет освобождать запросы в соответствии с приоритетом.
- распределенная очередь:проходить Синхронная асинхронизация вызовов,Пиковое ограничение может быть достигнуто,Также можно выполнять уточнение запросов в окне очереди.
Подробное объяснение инженерии данных
Есть также три основных противоречия в области инженерии данных:
- Противоречие 1:разные предприятияданныемежду дифференцированными и стандартизированными мерамипротиворечие(данныеуправлять)。
- Противоречие 2:Запросшкала、противоречие (данные заявки) по своевременности и пределам физической работоспособности двигателя.
- Противоречие 3:данныеразнообразие источников、противоречие (данные хранилища) с унифицированным управлением фрагментацией и платформой.
Поэтому мы по-прежнему используем 3 набора планов, чтобы победить их один за другим.
3.1 Управление данными
Противоречие 1 – Противоречие между дифференцированными и стандартизированными измерениями различных бизнес-данных (управление данными).
Будь то небольшая команда или большой отдел, разные инструменты НИОКР или разные способы использования одного и того же инструмента НИОКР привели к совершенно разным данным.
3.1.1 Решите цель
разрушение с традицией Внутренние свойства пространственной изоляции платформ BI,поставлятьГибкое управление данными,Максимизируйте ценность добычи и повторного использования.
Мы можем предложить следующие сценарии практического применения, чтобы подумать о решениях этих проблем. В первом сценарии сначала найдите источник данных, свяжитесь с платформой спроса для получения данных, а затем найдите платформу BI для реализации. Для второго сценария вам необходимо повторить шаги первого вопроса, и тогда вы столкнетесь с новыми проблемами. Стандарты данных в каждом бизнесе различны. Нет проблем с использованием каждого «маленького менеджера», но в качестве «большого менеджера». , как вы можете посмотреть на общую ситуацию? В третьем сценарии сценарии и объем измерений постоянно расширяются. Как решить подобные проблемы?

3.1.2 Ключевые проблемы
- Возможности межотраслевого повторного использования и упрощенные «расходы на связь» часто являются наиболее дорогостоящими.
- данные Точное изображение,«Квази» общее и «универсальное» — парадокс.,Необходимо взвесить стоимость и цену, необходимую для «точности».
- Платформа инструментов BI не будет поддерживать эту функциональную концепцию.,Традиционная практика заключается в том, чтобы затопить сами приезжающие.,Для достижения этой цели положитесь на отношения данных.
Что касается ввода сцены, давайте посмотрим на разницу между «раньше» и «сейчас» с инженерной точки зрения.
прошлое:
- доступ к данным:Ищем потребностиданныеисточник,Зависит от возможностей открытия данных платформы,Комплексная ЭТЛ Работа
- индексопределение:от 0-1 Обсудить калибр индикатора, логику расчета
- Рисовать диаграммы:традиционный визуальный рисунок Работа,После формата с момента определения,Тривиальные повторы типа набора текста,Окончательная панель вывода,сводный отчет,на на основе Диаграммы, объединенные в отчеты с разными стилями
Сейчас:
суммировано в одном предложении:“Встаньте на плечи гигантов”。нам просто нужно выбратьиндексистория生成属В自己的Аналитический отчет Вот и все,Больше ничего делать не нужно. даже,Нет необходимости выбирать индикаторные истории,Переключайтесь по желаниюОбъект измерения,Вы можете динамически просматривать Аналитический отчет, принадлежащий этому объекту, в режиме реального времени.
- доступ к данным:Нет необходимости понимать“OpenAPI”,«Несколько складов»,Не нужно учитывать инженерные возможности,Выполните базовую настройку сопоставления,Вот и все
- индексопределение:представлять“эксперт”Роль,«Эксперт» может быть ролью эксперта по анализу данных.,Это может быть основано на опыте других
- отчет о розыгрыше:индексистория、Аналитический Платформа оптимальной формы отчета была автоматически закреплена
Как добиться такого эффекта? Заключительный анализ заключается в установлении подходящих «отношений сопоставления».
Отвечать:данныеуправлятькарта + Дерево сопоставления объектов метрик
3.1.3 Решение
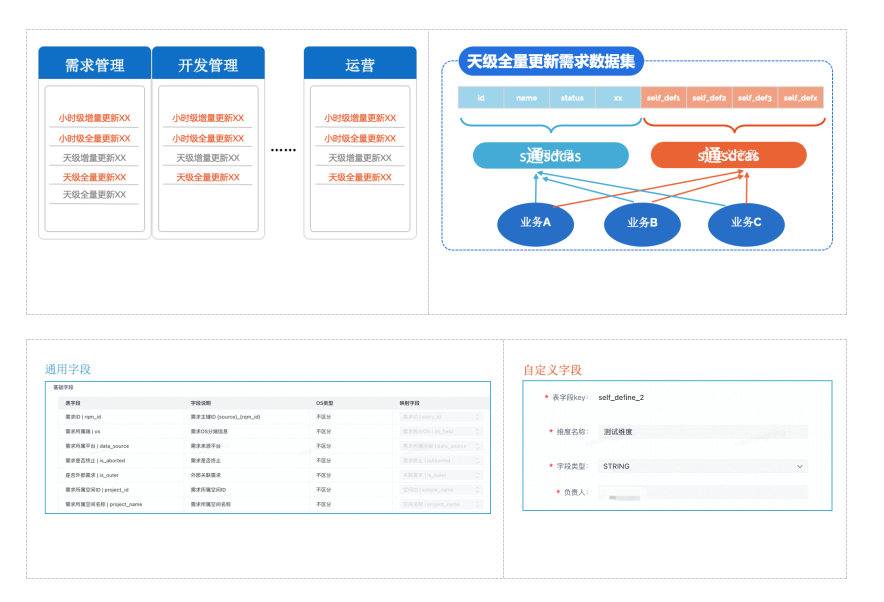
3.1.3.1 Создание карты управления данными
Создайте картографию данных и бизнеса первого уровня с точки зрения производителей.
- Метод реализации:то же ядроданные Модель,Поделиться базовой таблицей,Два требования,Учитывайте общие черты и различия в бизнесе.
- Общие поля:не означает то же самое“состояние”поля,Все деловые стороны имеют одно и то же название,полуавтономныйопределение,Деловые значения поля универсальны.
- Поскольку поле определения:Все изопределение,Деловое значение поля полностью вытекает из определения.
- Эффект:отданныев производстве,Насколько это возможно, поместите разные предприятия в одну и ту же сцену в одну модель данных.
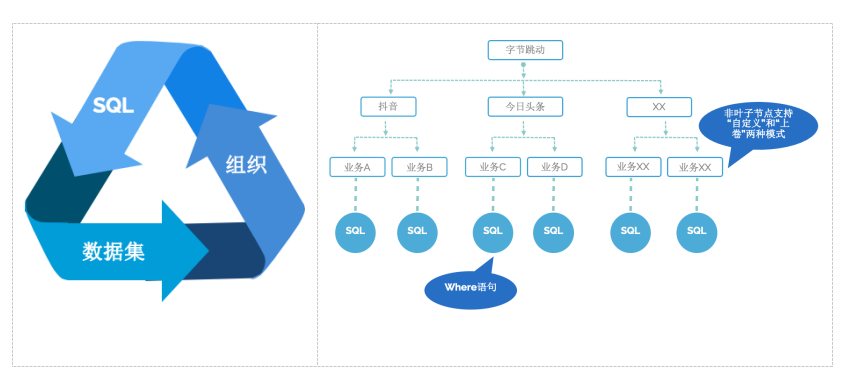
3.1.3.2 Учреждать Дерево сопоставления объектов метрик
Создайте второй уровень сопоставления данных и бизнеса с точки зрения пользователя.
С помощью пользовательского фрагмента «SQL» отношения сопоставления между одним бизнесом, несколькими бизнесами и родительскими и дочерними бизнесами решаются на основе одного и того же набора данных. Проще говоря, для фильтрации данных необходимо правило фильтрации. Это предполагает взаимозависимость между SQL, наборами данных и организациями:
- отдельные данные набор yObject Отношения между измерениями
- специализация бизнеса SQL определениеи Объект Отношения между измерениями
- Объект Отношения между измерениями
3.2 Применение данных
Противоречие 2. Противоречие между масштабом запроса, своевременностью и ограничениями физической производительности механизма (приложение данных).
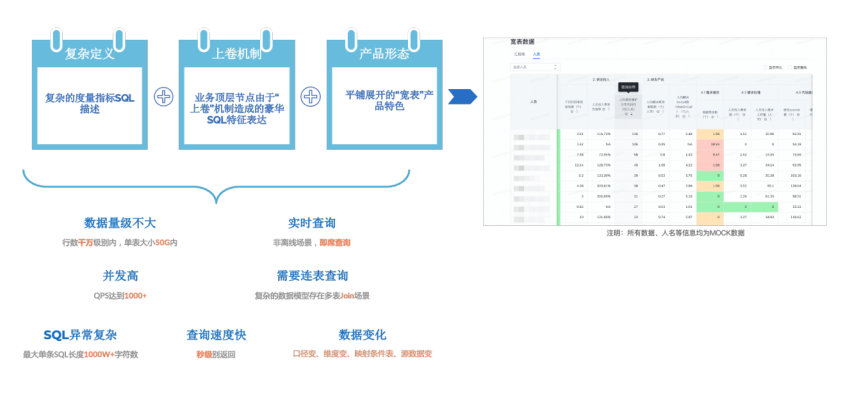
Длина самого длинного и сложного SQL, который вы когда-либо видели, преувеличена. Например, в нашем проекте длина одного SQL, то есть количество символов, может достигать 1000W+. Что делать, если добавить высокие требования к QPS. к этой сложности. Формирование такого сложного сценария запроса можно объяснить тремя основными элементами, которые составляют аналитический отчет с точки зрения функций продукта: история индикатора + аналитический отчет + объект измерения. Давайте посмотрим на источник сложного сценария с трех сторон:
- определение:Приведите пример,Сложная агрегатная функция + слогические выражения
- механизм:верно В接近顶层节点的“свернуть”механизмпринести роскошь SQL
- Форма продукта:одиночная сетка,Функция базового уровня (глобальный базовый уровень, общий исторический базовый уровень);,Формат продукта, поддерживающий расширение иерархического дерева.
3.2.1 Решить цель - «Теория суперкара»
Для сложных запросов к текущим бизнес-узлам верхнего уровня не будет преувеличением сказать, что удаление одного индикатора представляет собой автономный расчет на уровне задачи. Давайте проведем аналогию: наша нынешняя система запросов теперь представляет собой автобус, который перевозит много пассажиров, но недостаточно быстр, чтобы добраться до пункта назначения. Далее, например, мы используем роскошную систему запросов, которая представляет собой чрезвычайно быстрый суперкар. , но пассажиров мало, суперкар, тянувший сотню человек, чуть не перевернулся. Один из способов заключается в том, что мы можем получить еще несколько суперкаров для их перевозки одновременно. Тогда нам еще нужно решить эту проблему. Мы должны сказать пассажирам, что нереально, чтобы 10 000 человек прибыли на станцию одновременно. время в три секунды. При нынешних технологиях такого средства передвижения не существует.
- идеальный:мы надеемся найтиприезжатьидеальный двигатель,Он может удовлетворить все характеристики и требования текущего запроса платформы.
- Реальность:Жаль,Абсолютно идеального двигателя не существует,Различные двигатели должны быть усовершенствованы в каком-то аспекте.
- результат:
3.2.2 Решение
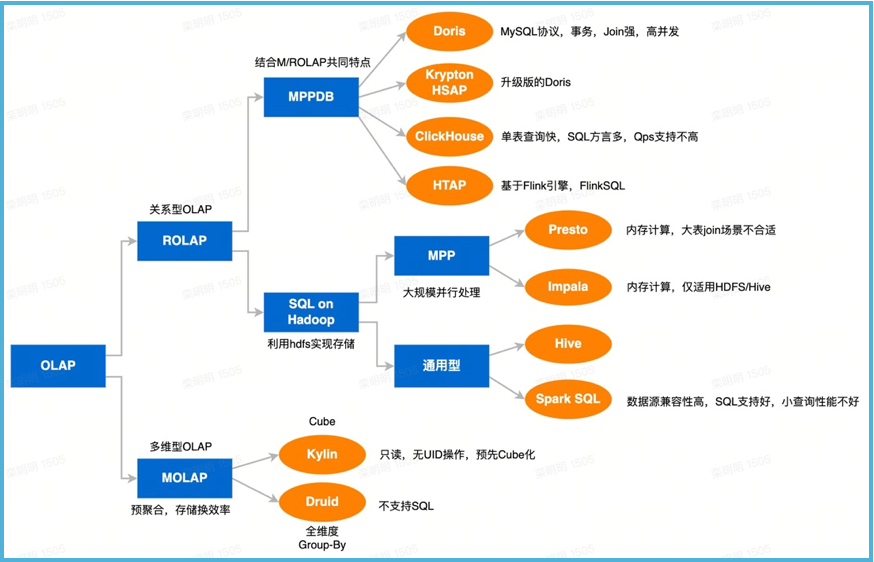
Мы пытались и раньше, надеясь найти серебряную пулю для решения насущной потребности. Реальность такова, что просто полагаться на «двигатель» суперкара не может помочь нам быстро и надежно доставлять тысячи пользователей к местам назначения. После углубленного исследования популярных в отрасли вычислительных механизмов и логики выбора технологий мы можем свести их к трем основным идеям:
- технология МПП,массово-параллельная обработка,Распределенная и параллельная технология, зрелая,Ожидается, что он достигнет «100 миллионов уровней, открывающихся за секунды».
- Вычисления в памяти,данные Том слишком велик и не может быть загружен.
- предварительная обработка,Qube изация, хранение на время
Сравнительный анализ двигателя:
Логика выбора двигателя:
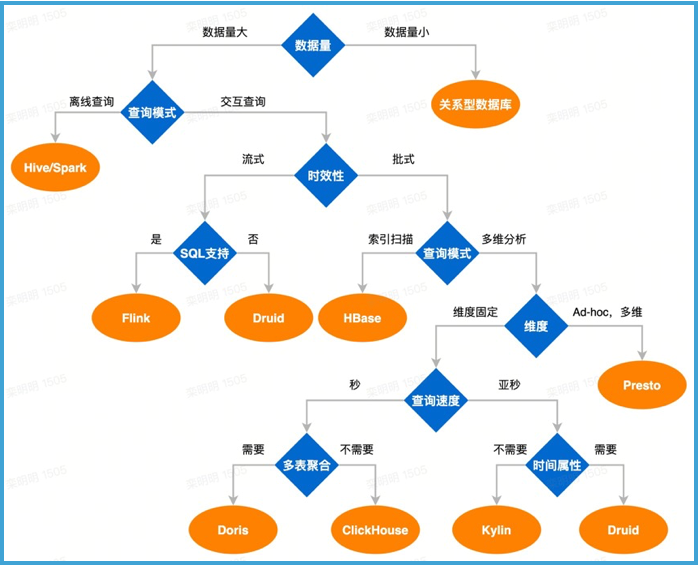
исторические причины:наск Реляционный MySQL В качестве основного двигателя, вспомогательного ClickHouse Решайте сценарии использования больших данных в одной таблице. Стоимость внедрения нового движка: стоимость адаптации синтаксиса, миграции и преобразования, а также позиционирование сценария платформы. AD-Hoc Запрос, существуют сотни тысяч измерений пользовательских индикаторов, потому что MySQL Он слишком мощный и бесплатный, поэтому переход на любой другой механизм запросов становится очень дорогим или даже невозможным.
3.2.2.1 Замена двигателя (аппаратная возможность)
Ищете универсальный механизм запросов, соответствующий сценариям запросов
Универсального двигателя не существует, поэтому мы попытались его совместить. Здесь я должен упомянуть Krypton, вычислительный механизм реального времени в рамках звездообразной архитектуры HSAP компании Byte. Это нормально, что механизм OLAP работает более чем в сто раз быстрее, чем MySQL, но сценариев, в которых мы бы это сделали, почти нет. приходится иметь дело с таким сложным SQL. Просто совместимость синтаксиса уже победила множество компонентов. И по совпадению, совместимость синтаксиса MySQL — одна из особенностей Krypton:
- облачный родной:Архитектура разделения хранения и вычислений,Эластичное расширение
- Простота использования:Совместимость синтаксиса
- высокая производительность:Хранение строк и строк、механизм векторизации、MPP、Материализованное представление в реальном времени、Асинхронное выполнение
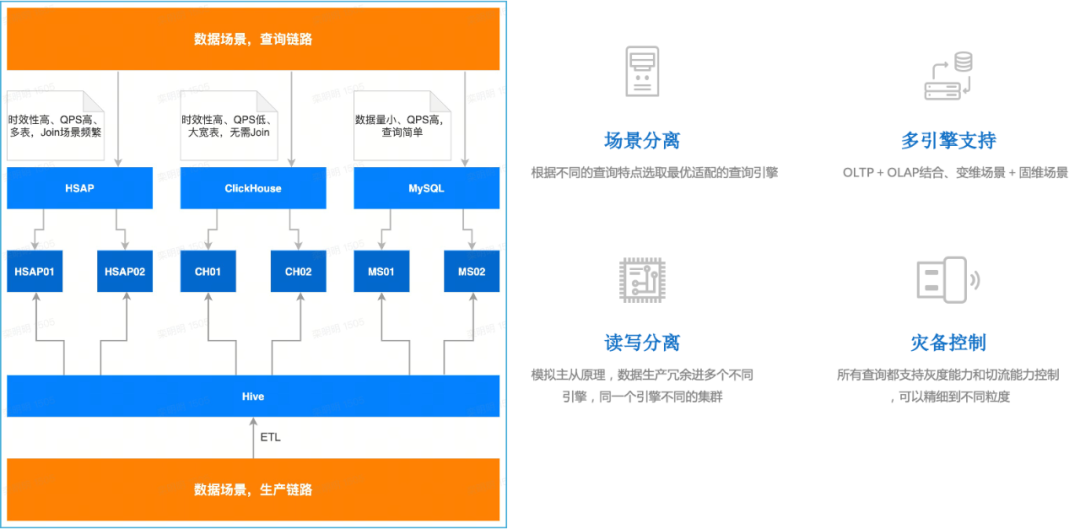
Исходя из этих соображений, мы наконец построили достойный «универсальный движок» на основе MySQL + ClickHouse + Krypton.
3.2.2.2 Стратегия изменения (возможности программного обеспечения)
Найдите лучшую комбинацию стратегий в условиях ограниченного оборудования.
Можно сказать, что в нашей платформе есть все стратегии и методы оптимизации, связанные с повышением производительности запросов к данным. На движке: различные модели данных (обоснованность детальных таблиц, декартовых таблиц, кубических таблиц), механизмы целевого индексирования (например, характеристики запроса для оптимизации порядка совместного индекса), операции с подбазой данных и подтаблицей с точки зрения стратегии: преобразование; большое разделение запросов, асинхронное ограничение тока и снятие пиков, а также идеи предварительной обработки данных с точки зрения кэширования: сочетание длинных и коротких кэшей под разные сценарии и функциональные модули с точки зрения функций: посредством предварительной очистки (запускается симулированными людьми); блокировка (рассчитывается заранее) Сохранение результатов) и другие эксплуатационные ограничения для истощения вычислительной мощности двигателя.
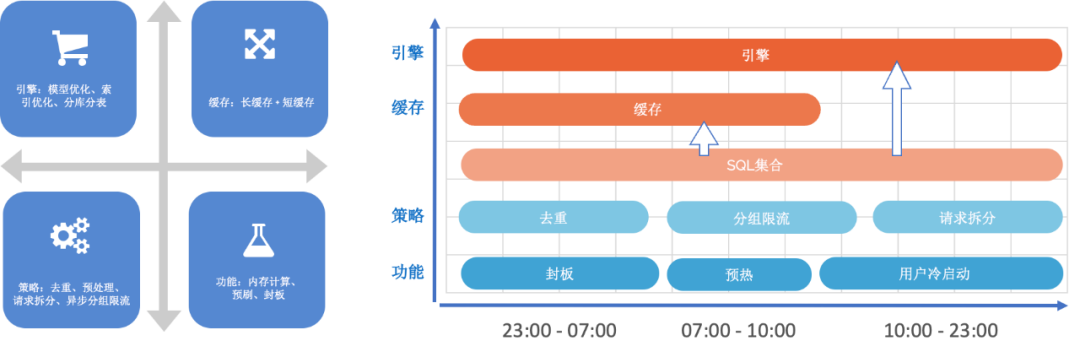
3.2.2.3 Добавить ограничения к ожиданиям (возможности управления)
Сдерживать необоснованное поведение (злоупотребление, чрезмерную настройку) + корректировать неверные ожидания (изменения происходят за секунды)
Иногда, независимо от того, насколько сильно вы занимаетесь оптимизацией, вы не можете удовлетворить возможности пользователя «творить», поэтому вам необходимо усилить возможности доступа и выхода.
- ограничения отчетности
Например, при написании кода многие люди пишут тысячи строк в одном методе, что является типичным плохим случаем. По аналогии с отчетами, некоторые студенты-бизнесмены стремятся запихнуть все показатели в одну панель, не говоря уже о проблемах с производительностью запросов. Например, если вы руководитель или пользователь и видите полный экран различных цифр, охватывающих разные темы. вы почувствуете в своем сердце, вероятно, рухнуло. Есть также некоторые особые сценарии, такие как история составных индикаторов. Составной индикатор представляет собой комбинацию десятков метаиндикаторов, что эквивалентно экспоненциальному расширению.
- Вложение данных
У некоторых пользователей выработалась привычка присоединяться, если отсутствует отсутствующее поле, что приводит к увеличению уровня объединений в базовой модели данных. Или некоторые наборы данных типа журнала содержат чрезвычайно большой объем данных. Если цикл запроса слишком длинный, это приведет к слишком большому количеству сканирований базы данных.
- спецификация SQL
Вы можете контролировать длину. При нажатии кнопки «Сохранить» будут предложены некоторые предложения. Например, для решения проблемы можно использовать другие, более подходящие механизмы. Оптимизируйте и обнаруживайте синтаксис, подскажите неправильный синтаксис и даже дайте предложения по сокращению слияний, а также выполняйте некоторые базовые проверки внедрения уязвимостей SQL и другие внедрения правил.
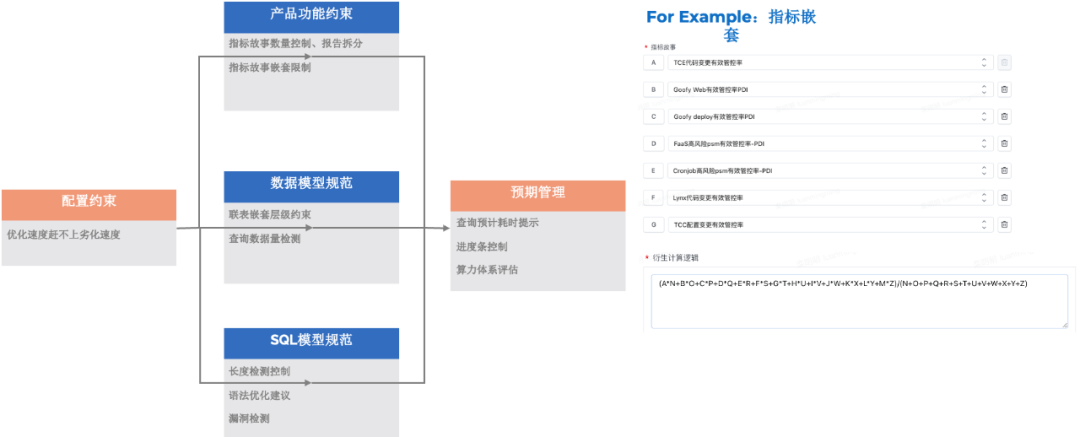
Что касается ожиданий, в ходе общения с пользователями и интервью была обнаружена интересная проблема. Дело не в том, что пользователи не могут смириться с медлительностью, а в том, что им необходимо дать психологическую подсказку или подробное объяснение. Например, индикаторы выполнения, круги или более прямое и грубое «расчетное время запроса». Поскольку никаких ожиданий не дано, вся информация, воспринимаемая пользователем, по умолчанию «возвращается за секунды». В результате после ожидания в течение 10 минут он обязательно выйдет из строя.
3.3 Хранение данных
Противоречие 3 – противоречие между разнообразием и фрагментацией источников данных и единым управлением платформой (хранилищем данных).
Мы не производим данные, мы просто переносим данные. Этот вопрос, вероятно, разделяют студенты, которые работают над построением данных. Сама работа не сложна, но стандартизировать управление сложно.
3.3.1 Решите цель
Статус бизнеса. Возможности открытости бизнес-данных различаются, и каждое предприятие в той или иной степени выполнило сбор данных.
Статус технологии: зрелая теория моделирования хранилищ данных и, как правило, компании оснащены полными возможностями среднего уровня данных.
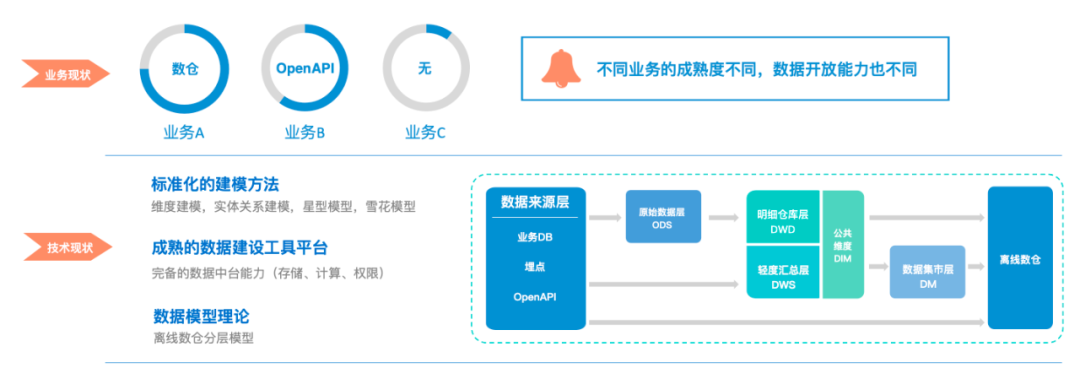
Для производителей данных осведомленность бизнеса относительно низкая, в сочетании с частыми перебоями, информация не передается между пользователями, а предельные выгоды для потребителей данных очень малы, затраты на связь и стыковку высоки; Поэтому им приходится сталкиваться с общими проблемами, такими как плохие методы управления данными, отсутствие возможностей совместного строительства и совместного использования, а также высокие затраты на стыковку.
3.3.2 Решение
3.3.2.1 Создание портала хранилища данных
Переход от поиска людей к поиску систем
Определение портала данных. Используйте интерфейсную платформу самообслуживания для создания веб-сайтов, чтобы упорядоченно управлять сложными функциональными URL-адресами и документами и предоставлять пользователям единый вход.
- Сторона производства: спецификация, стандартизированная конструкция.,Благодаря чистому надежному обучению (спецификация хранилища данных, именование, разрешения, качество, пользовательская документация),Затем проверьте созданную таблицу активов и положите ее на полку.,Подведите итоги прибытия в теме большого хранилища данных.
- Потребительская сторона: Портал есть.、Иметь базу пользователей、Иметь понятную пользовательскую документацию、Вопросы и ответы распространенымеханизм,Пользователям не нужно искать разные платформы для потребления.,Зато прямой единый вход.
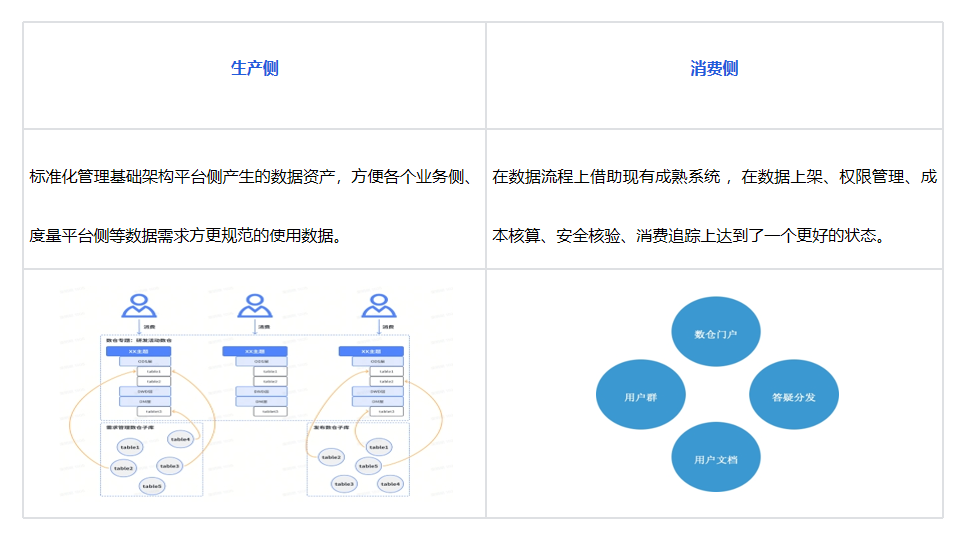
После использования этого набора появится эффект снежного кома. Во-первых, это заставит инструментальную платформу практиковаться в соответствии с этим стандартом. Во-вторых, они также смогут стать производителями и делиться агрегированными таблицами с другими потребителями.
3.3.2.2 Создание каналов передачи данных
Стандартизируйте таблицы данных в соответствии с пригодными для использования моделями данных.
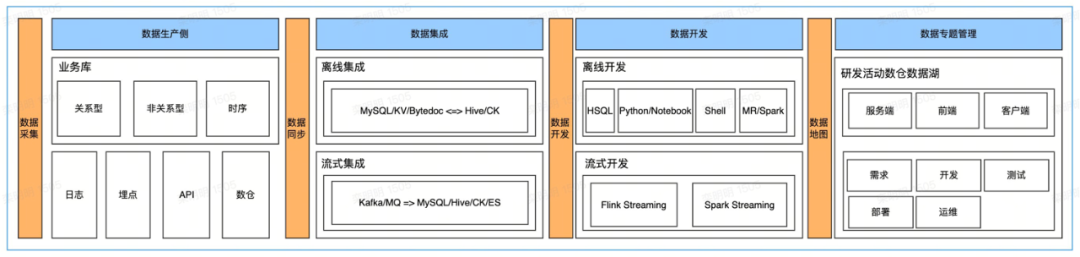
Общая сводка представляет собой данные «ETL», которые становятся реальным списком активов данных платформы DevMind посредством интеграции пакетного потока и разработки пакетного потока. Основой интеграции данных является преобразование между различными типами хранилищ. Суть разработки данных заключается в написании логики агрегирования и обработке данных в целевых широких таблицах.
Сами возможности инструмента будут охватываться зрелыми промежуточными платформами данных. В наших собственных проектах мы больше уделяем внимание управлению и механизму процесса приложения. Эффективное использование возможностей промежуточной платформы данных представляет собой трудность. Только выполнив следующие пункты, мы можем назвать это преобразованием «данных в пригодную для использования модель».
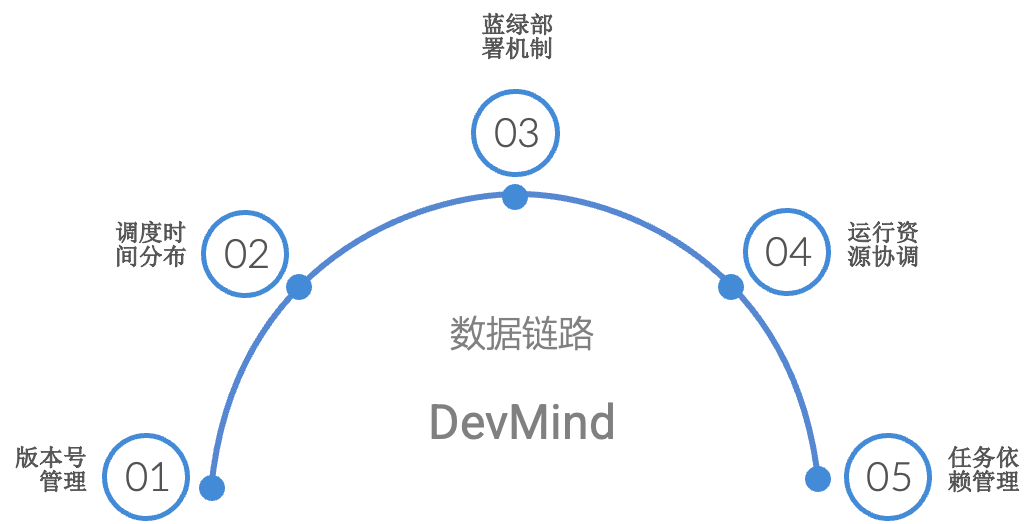
- номер версии:решатьданныепоследовательностьки снимоквопрос
- Планирование времени:идеальный Ситуация устраивает T+1,У нас есть сотни эпизодов данных,Необходимо учитывать факторы приоритета очереди и приоритета задачи.
- Сине-зеленое развертывание:решать Синхронизация задач“открытый люк”вопрос,Например, период окна запрещенных данных, вызванный задачей очистки записи.
- Координация ресурсов:капиталисточникне бесконечный,такой же Необходимо учитывать факторы приоритета очереди и приоритета задачи.
- Зависимости задач:Разумная схема топологии и настройки канала
Средне- и долгосрочное направление развития
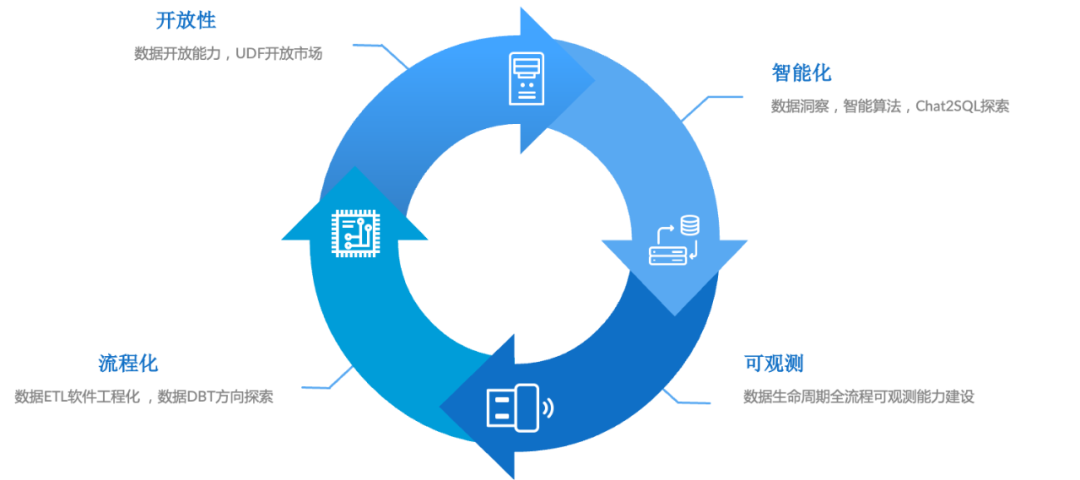
4.1 Более открытый и умный
- открытость:похожий HiveUDF экология
- Оптимизированный:DBT,Решите ETL в T сцене
- Разумный:сейчас жарко AIGC Тренд, можем ли мы сделать какую-то практическую реализацию в конкретных проектах?
- наблюдаемый:данные Визуализация полного жизненного циклауправлять,Данные очень полезны при эксплуатации, обслуживании и устранении неполадок.
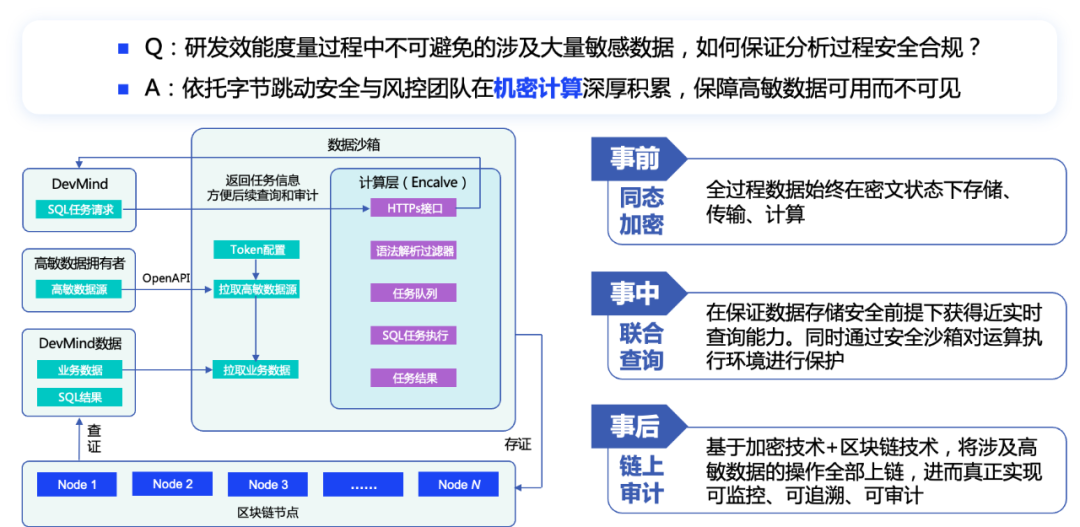
4.2 Конфиденциальность и безопасность гарантированы.
Дальнейшее чтение
- DevMind система:Создайте «навигатор» и «движок» для повышения эффективности и реализации перехода от данных к ценности.
- DevMind технология:Охватывая десятки тысяч сотрудников, занимающихся исследованиями и разработками, ByteDance впервые раскрывает основную технологию измерения производительности!
Об авторе
Ченг Синь,Байт Данс DevMind менеджер по исследованиям и разработкам
Цзян Лэй,Байт Данс DevMind Бизнес-инжиниринг Ответственное техническое лицо
Луан Минмин,Байт Данс DevMind инженерия данных Ответственное техническое лицо



Учебное пособие по Jetpack Compose для начинающих, базовые элементы управления и макет

Код js веб-страницы, фон частицы, код спецэффектов

【новый! Суперподробное】Полное руководство по свойствам компонентов Figma.

🎉Обязательно к прочтению новичкам: полное руководство по написанию мини-программ WeChat с использованием программного обеспечения Cursor.

[Забавный проект Docker] VoceChat — еще одно приложение для мгновенного чата (IM)! Может быть встроен в любую веб-страницу!

Как реализовать переход по странице в HTML (html переходит на указанную страницу)

Как решить проблему зависания и низкой скорости при установке зависимостей с помощью npm. Существуют ли доступные источники npm, которые могут решить эту проблему?

Серия From Zero to Fun: Uni-App WeChat Payment Practice WeChat авторизует вход в систему и украшает страницу заказа, создает интерфейс заказа и инициирует запрос заказа

Серия uni-app: uni.navigateЧтобы передать скачок значения

Апплет WeChat настраивает верхнюю панель навигации и адаптируется к различным моделям.

JS-время конвертации

Обеспечьте бесперебойную работу ChromeDriver 125: советы по решению проблемы chromedriver.exe не найдены

Поле комментария, щелчок мышью, специальные эффекты, js-код

Объект массива перемещения объекта JS

Как открыть разрешение на позиционирование апплета WeChat_Как использовать WeChat для определения местонахождения друзей

Я даю вам два набора из 18 простых в использовании фонов холста Power BI, так что вам больше не придется возиться с цветами!

Получить текущее время в js_Как динамически отображать дату и время в js

Вам необходимо изучить сочетания клавиш vsCode для форматирования и организации кода, чтобы вам больше не приходилось настраивать формат вручную.

У ChatGPT большое обновление. Всего за 45 минут пресс-конференция показывает, что OpenAI сделал еще один шаг вперед.

Copilot облачной разработки — упрощение разработки

Микросборка xChatGPT с низким кодом, создание апплета чат-бота с искусственным интеллектом за пять шагов

CUDA Out of Memory: идеальное решение проблемы нехватки памяти CUDA

Анализ кластеризации отдельных ячеек, который должен освоить каждый&MarkerгенетическийВизуализация

vLLM: мощный инструмент для ускорения вывода ИИ

CodeGeeX: мощный инструмент генерации кода искусственного интеллекта, который можно использовать бесплатно в дополнение к второму пилоту.

Машинное обучение Реальный бой LightGBM + настройка параметров случайного поиска: точность 96,67%

Бесшовная интеграция, мгновенный интеллект [1]: платформа больших моделей Dify-LLM, интеграция без кодирования и встраивание в сторонние системы, более 42 тысяч звезд, чтобы стать свидетелями эксклюзивных интеллектуальных решений.

LM Studio для создания локальных больших моделей

Как определить количество слоев и нейронов скрытых слоев нейронной сети?
