Быстрое обучение с помощью одной статьи - Практическая практика построения графа знаний с нуля: Практика построения структуры графа знаний - извлечение информации
Предисловие
Согласно предыдущей статье серии, мы уже поняли основные концепции графов знаний, а также текущий статус развития графов знаний и направление интеграции с передовым искусственным интеллектом. Теперь единственный шаг — это построить граф знаний. По сути, вы получите более четкое представление о продукте графа знаний.
Поэтому, если вы хотите хорошо выполнять свою работу, вам необходимо сначала отточить свои инструменты. Как и в случае с нашим знанием языков программирования, более продвинутое использование и навыки могут еще больше улучшить качество наших проектных продуктов. В этой статье мы будем использовать их с самого начала. среда разработки Напишите о практике построения базового графа знаний и завершите процесс построения графа знаний с нуля.
1. Архитектура построения графа знаний
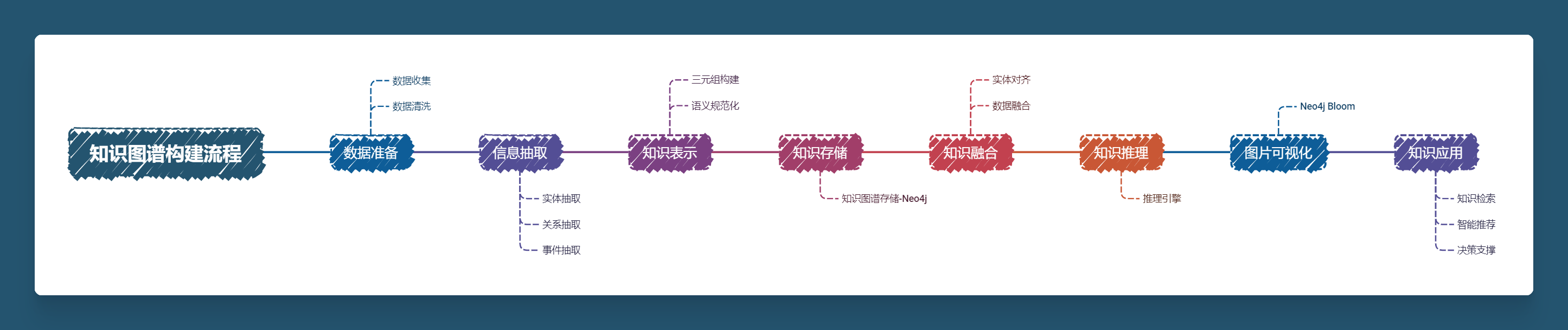
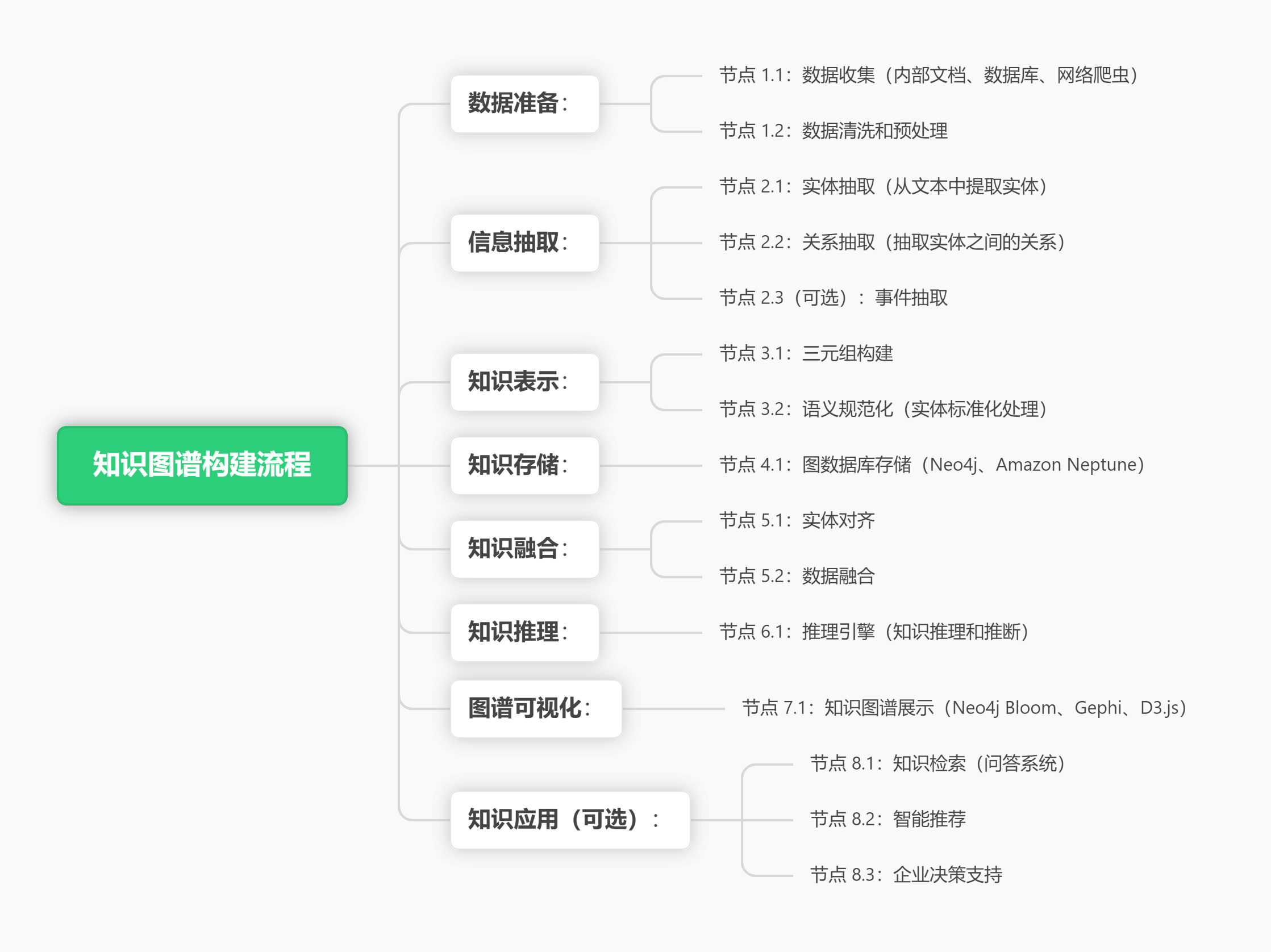
2. Практика графа знаний
1. Извлечение информации
Извлечение информации Экстракция, короче IE) — это сборка График Одним из основных шагов в области знаний является автоматическое извлечение значимой структурированной информации из неструктурированных текстовых данных, включая сущности, отношения и события. извлечение информации В основном он разделен на следующие этапы:Извлечение сущности、Извлечение отношений、Извлечение атрибутовиизвлечение событий,На каждом этапе используются разные методы и инструменты.
Что касается инструмента извлечения информации, я использую модель UIE PaddleNLP. Яоджи Лу и др. предложили единую структуру для общего извлечения информации UIE в ACL-2022. Эта среда реализует унифицированное моделирование таких задач, как извлечение сущностей, извлечение отношений, извлечение событий и анализ настроений, а также обеспечивает хорошие возможности переноса и обобщения между различными задачами.
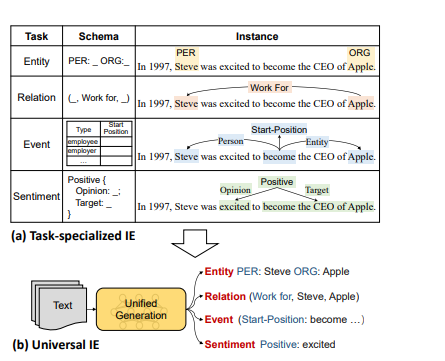
Что касается инструмента извлечения информации, я использую модель UIE PaddleNLP. Яоджи Лу и др. предложили единую структуру для общего извлечения информации UIE в ACL-2022. Эта среда реализует унифицированное моделирование таких задач, как извлечение сущностей, извлечение отношений, извлечение событий и анализ настроений, а также обеспечивает хорошие возможности переноса и обобщения между различными задачами.Вот краткое введениеUIE。
UIE
UIE (Universal Information Extraction) — это технология обработки естественного языка, основанная на глубоком обучении, предназначенная для автоматического извлечения ценной информации из неструктурированного текста. Он объединяет различные задачи извлечения информации, включая распознавание сущностей, извлечение взаимосвязей, извлечение событий и т. д., чтобы сформировать единую структуру.
Основные понятия UIE
- извлечение информации:Относится к извлечению структурированной информации из текста.,Например, именованные объекты, связь, события между объектами. и их атрибуты и т.д. извлечение информации способен преобразовывать неструктурированные данные (например, статьи、отчеты и т. д.) в структурированные данные, которые можно использовать для анализа и принятия решений.
- единство:UIE Будут разнообразные извлечения информации Задачи интегрированы в одну модель,Возможность одновременного выполнения нескольких задач по извлечению,Улучшена универсальность и применимость модели.
Основные задачи UIE
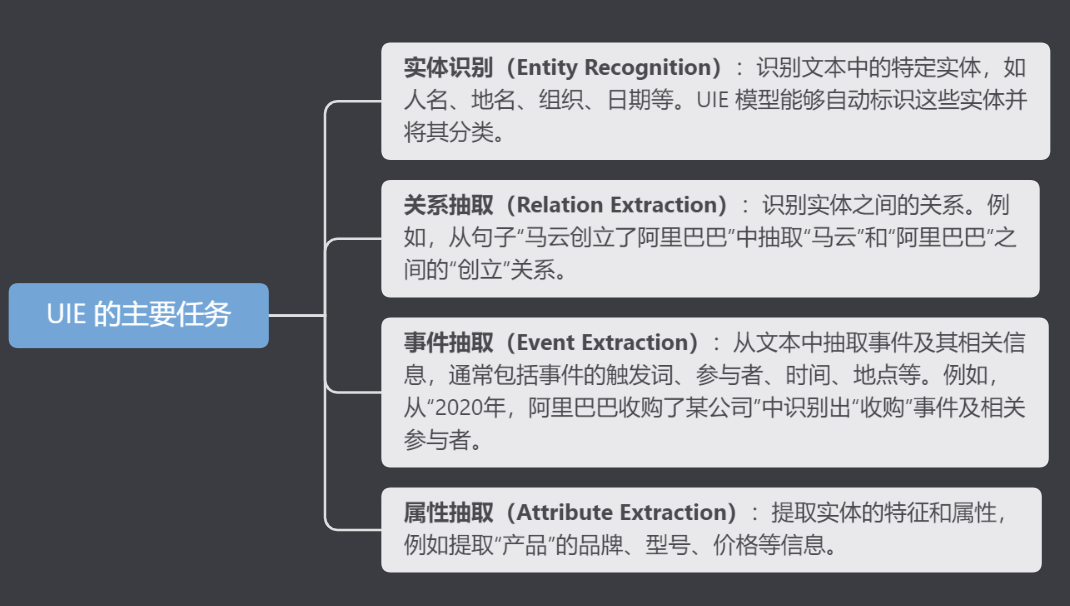
UIE в основном включает в себя следующие подзадачи:
- Распознавание объектов:Выявление конкретных объектов в тексте,Например, имя человека、название места、организовать、Дата и т. д. ИЮП Модель может автоматически идентифицировать и классифицировать эти объекты.
- Связь Extraction):идентифицировать сущностисвязь。Например,из предложения“Джек Ма основал Alibaba”Рисовать из“Джек Ма”и“Алибаба”между“Основан”связь。
- извлечение событий(Event Extraction):из текста Рисовать из События и сопутствующая информация,Обычно включает триггерные слова события, участников, времени, места и т. д. Например,Из «2020,Алибабаприобретениекомпания”идентифицировано в“приобретение”События и связанные с нимиучастники。
- Извлечение атрибутов(Attribute Extraction):извлекать Характеристики сущностиисвойство,Например извлекает марку «продукта», модель, цену. и другая информация.
Внедрить модуль извлечения информации из графа знаний на основе модели PaddleNLP-UIE:
! pip install --upgrade paddlenlp
! pip show paddlenlp1.1 Извлечение объекта
Извлечение объектов, также известное как распознавание именованных объектов (NER, Named Entity Recognition), предназначено для идентификации конкретных типов именных фраз из текста, обычно слов с реальным значением, таких как имена людей, географические названия, организации, даты, продукты и технические данные. существительные подождите. Целью извлечения сущностей является структурирование важных информационных точек в тексте для последующего анализа и хранения.
- Тип объекта:
- Человек: например, «Джек Ма».
- Местоположение: например, «Ханчжоу».
- Организация: типа «Алибаба»
- Время: например «Август 2024 года».
- Другие (Продукт, Event, Деньги и др.)
В качестве примера возьмем текстовые данные:
schema = ['время', 'Город'] # Define the schema for entity extraction
ie = Taskflow('information_extraction', schema=schema, model='uie-base')
ie_en = Taskflow('information_extraction', schema=schema, model='uie-base-en')
pprint(ie("Все строительные конкурсы, по которым проекты жилищного строительства и муниципальной инфраструктуры инвестировались за счет государственных средств в нашем городе (включая уезды (районы) и зоны застройки (новые районы)) с 3 июня 2017 года выдали тендерную документацию, должен Положения «Уведомления Главного управления муниципального народного правительства Наньчана о выпуске системы обеспечения ежегодных тендерных заявок (испытательной) для торгов по инвестиционно-строительному проекту государственного фонда Наньчана» (Hongfu Tingfa [2016] № 74) » )). # Better print results using pprint[{'Город': [{'end': 71,
'probability': 0.9465240012183784,
'start': 68,
'text': «Город Наньчан»},
{'end': 85,
'probability': 0.9736215907851147,
'start': 82,
'text': «Город Наньчан»}],
'время': [{'end': 48,
'probability': 0.5193512646392762,
'start': 39,
'text': '3 июня 2017'}]}]1.2 Извлечение отношений
Связь Экстракция, корочеRE),Это относится к идентификации сущностей из текста и извлечению семантических связей между сущностями.,Затем получите информацию о тройке,Прямо сейчас<основная часть,предикат,объект>。Извлечение отношенийцельсуществовать Идентифицировать два или более объекта в текстемеждусвязь。например,Определите «основательные» отношения в «Alibaba была основана Джеком Ма».,Ссылка «Джек Ма» и «Алибаба».
- Тип отношений:
- Например «Творение», «принадлежность», «сотрудничество» и т. д.
schema = {'Отдел':['Руководство','Название деятельности']}
ie.set_schema(schema)
txt_file='Отдел развития и реформ Государственного совета направляет и координирует национальные торги и конкурсную работу, а также контролирует и проверяет инженерные торги и тендерную деятельность по крупным национальным строительным проектам. '
pprint(ie(txt_file))[{'отделение': [{'end': 9,
'probability': 0.9600018973785609,
'relations': {'гид': [{'end': 22,
'probability': 0.9368320465242093,
'start': 14,
'text': «Национальные торги и тендеры»}]},
'start': 0,
'text': «Департамент развития и реформ Госсовета»}]}]
1.3 Извлечение атрибутов
Извлечение атрибутов заключается в идентификации и извлечении соответствующих значений атрибутов сущностей. Например, укажите дату основания компании, характеристики продукции, участников мероприятия и т. д.
schema = {'Компания':['Основатель','Время основания','Место']}
ie.set_schema(schema)
txt_file='Alibaba Group Holdings Co., Ltd. (аббревиатура: Alibaba Group) — компания, основанная в 1999 году в Ханчжоу, провинция Чжэцзян, 18 основателями под руководством Джека Ма. '
pprint(ie(txt_file))[{'компания': [{'end': 12,
'probability': 0.8997031190817637,
'relations': {'Основатель': [{'end': 26,
'probability': 0.7737946618519764,
'start': 24,
'text': 'Джек Ма'}],
'Место': [{'end': 49,
'probability': 0.3552619337063625,
'start': 43,
'text': 'Город Ханчжоу, провинция Чжэцзян'}],
«Время установления»: [{'end': 42,
'probability': 0.8343506849196594,
'start': 37,
'text': '1999'}]},
'start': 0,
'text': 'Alibaba Group Holdings Limited'}]}]
1.4 Извлечение событий
Извлечение событий — это идентификация и извлечение сложных структур событий из текста. Например, «Alibaba» идентифицируется как субъект из «В 2020 году Alibaba объявила о запуске нового плана розничной торговли», событие — «начало», время — «2020», а объект — «новый план розничной торговли». ".
schema = {'Начало':['время','Объект']}
ie.set_schema(schema)
txt_file='В 2020 году Alibaba объявила о запуске нового розничного плана'
pprint(ie(txt_file))[{'запускать': [{'end': 19,
'probability': 0.975417622363075,
'relations': {'время': [{'end': 5,
'probability': 0.9598323070613546,
'start': 0,
'text': '2020'}]},
'start': 14,
'text': «Новый розничный план»}]}]
Итак, мы понимаем метод извлечения, а затем нам нужно составить общий пакет для наших данных:
import paddlehub as hub
import json
from collections import defaultdict
from docx import Document
import jieba.posseg as pseg
from paddlenlp import Taskflow
def extract_text_from_docx(docx_path):
document = Document(docx_path)
return [paragraph.text.strip() for paragraph in document.paragraphs if paragraph.text.strip()]
def split_paragraphs_into_sections(paragraphs):
sections = defaultdict(list)
current_section = "другой"
for paragraph in paragraphs:
if «Тендерный тип» in paragraph:
current_section = «Тендерный тип»
elif «Метод организации тендеров» in paragraph:
current_section = «Метод организации тендеров»
elif «Требования к проекту» in paragraph:
current_section = «Требования к проекту»
sections[current_section].append(paragraph)
return sections
def generate_schema_from_sections(sections):
section_schemas = {}
for section, paragraphs in sections.items():
entity_candidates = defaultdict(int)
relation_candidates = defaultdict(int)
for paragraph in paragraphs:
words = pseg.cut(paragraph)
for word, flag in words:
if flag in ['n', 'nr', 'ns', 'nt', 'nz']:
entity_candidates[word] += 1
elif flag in ['v']:
relation_candidates[word] += 1
top_relations = sorted(relation_candidates, key=relation_candidates.get, reverse=True)[:10]
schema = {}
for entity in entity_candidates:
schema[entity] = top_relations
section_schemas[section] = schema
return section_schemas
def process_text_with_uie_by_sections(sections, ie_model, section_schemas):
extracted_info = {}
for section, paragraphs in sections.items():
schema = section_schemas.get(section, {})
ie_model.set_schema(schema)
section_info = []
for paragraph in paragraphs:
extraction_result = ie_model(paragraph)
section_info.append(extraction_result)
extracted_info[section] = section_info
return extracted_info
def save_extracted_info_to_json(extracted_info, output_path):
with open(output_path, 'w', encoding='utf-8') as f:
json.dump(extracted_info, f, ensure_ascii=False, indent=4)
def main():
docx_path = 'данные/Базовые знания в области торгов и закупок.docx' # Replace with your actual file path
output_json_path = 'data/extracted_info.json' # Replace with your output path
paragraphs = extract_text_from_docx(docx_path)
sections = split_paragraphs_into_sections(paragraphs)
section_schemas = generate_schema_from_sections(sections)
print(f"Generated Schemas: {section_schemas}")
ie_model = Taskflow('information_extraction', model='uie-base') # Load PaddleHub UIE model
extracted_info = process_text_with_uie_by_sections(sections, ie_model, section_schemas)
save_extracted_info_to_json(extracted_info, output_json_path)
print(f"Extracted information and saved to {output_json_path}")
if __name__ == "__main__":
main()
Получите соответствующий json-файл:

Небольшие выборки улучшают эффект UIE
Мы обучаем базовую версию UIE в Taskflow с помощью большого количества помеченных образцов, но эффект извлечения UIE в некоторых подполях не является удовлетворительным. UIE может быстро улучшить эффект с помощью небольших выборок. Почему UIE может улучшить результаты за счет небольших выборок? Метод моделирования UIE в основном заключается в Prompt способ моделирования, Prompt Точная настройка на небольших выборках очень эффективна. Ниже рассмотрим конкретный случай. Чтобы продемонстрировать эффект тонкой настройки UIE.
Сначала нам нужно установить:
pip3 install setuptools_scm -i https://pypi.tuna.tsinghua.edu.cn/simpleПоскольку этот плагин может сообщать об ошибке, если он не установлен отдельно, установите doccano позже:
pip3 install doccano -i https://pypi.tuna.tsinghua.edu.cn/simpleИнициализировать базу данных и учетную запись(имя пользователяи Пароль можно заменитьдляпользовательское значение)
$ doccano init
$ doccano createuser --username fanstuck --password xwt353008Начать документацию
- Веб-сервер в окне Начать документацию, оставить окно
$ doccano webserver --port 8000- Очередь задач Начать документацию в другом окне
$ doccano taskШаг 4. Запустите doccano для аннотирования объектов и связей.
Откройте браузер (рекомендуется Chrome),существоватьв адресной строкевходитьhttp://127.0.0.1:8000/Затем нажмите EnterПрямо сейчас Получите следующий интерфейс。
Вход в аккаунт。Нажмите на правый верхний уголLOGIN,входитьStep 2中设置的имя пользователяи Пароль для входа。
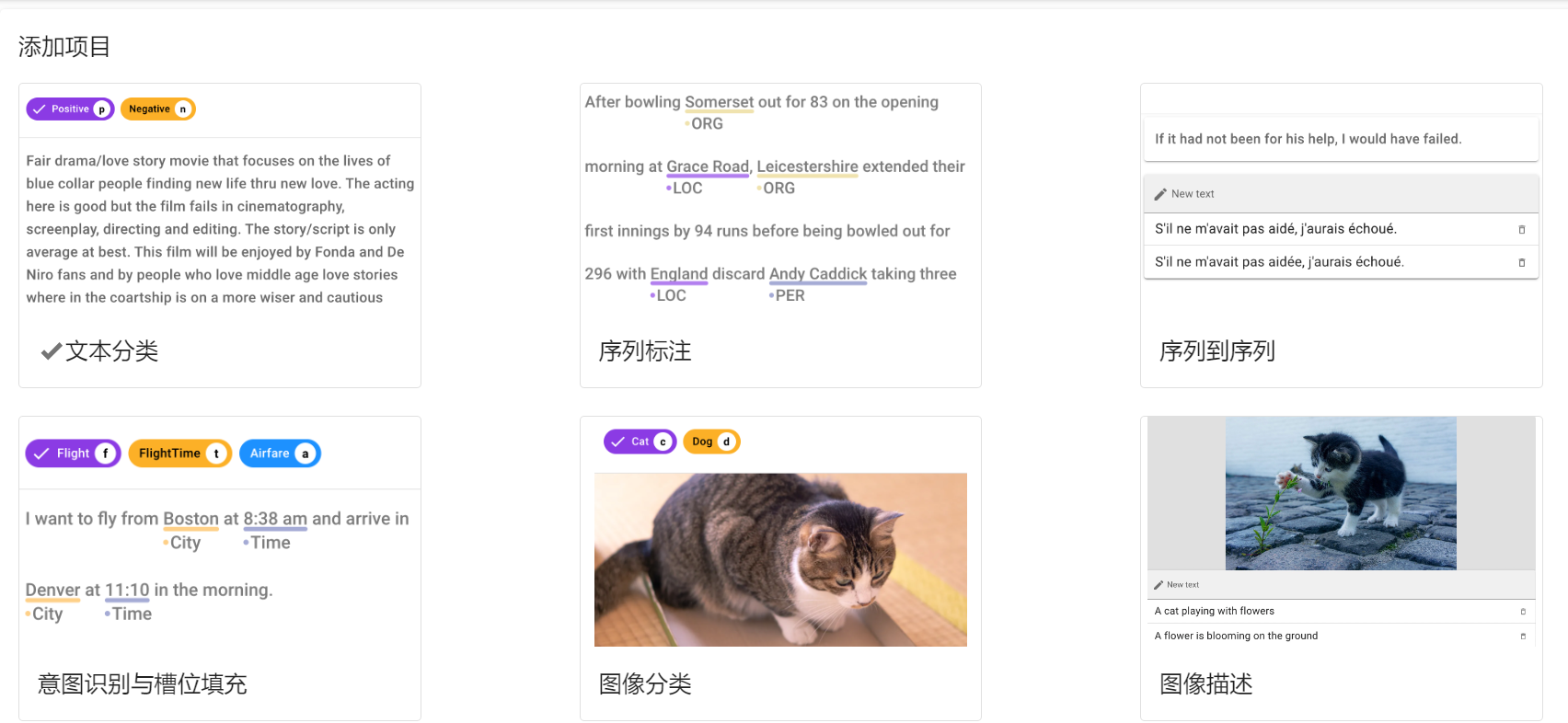
Создать проект。Нажмите на верхний левый уголCREATE,Перейдите к следующему интерфейсу.
- Проверьте аннотацию последовательности(
Sequence Labeling) - Введите название проекта(
Project name)等必要信息 - 勾选允许实体重叠(
Allow overlapping entity)、использоватьсвязьотметка(Use relation labeling) - После создания видео на главной странице проекта содержит подробные инструкции по семи шагам от импорта данных до экспорта.
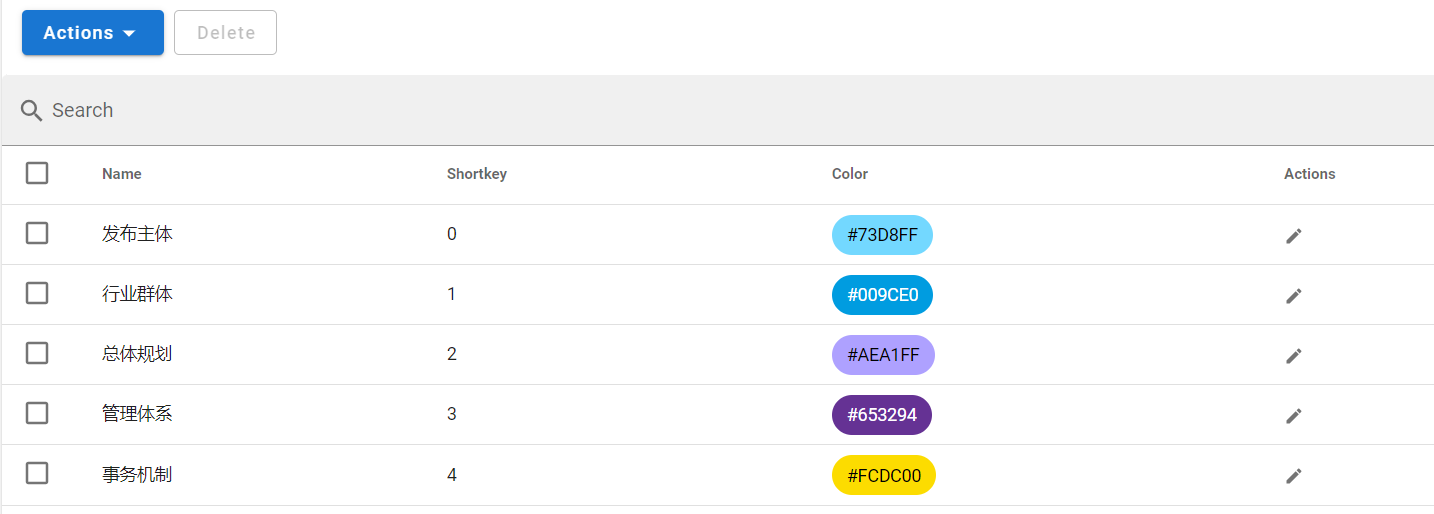
Установить ярлык。существоватьLabelsНажмите на столбецActions,Create LabelУстановить вручную илиImport Labelsимпорт из файла。
- Верхний диапазон представляет собой метку объекта, а связь представляет метку связи, которую необходимо установить отдельно.
Импортировать данные。существоватьDatasetsНажмите на столбецActions、Import Datasetимпорт из файлатекстовые данные。
- В соответствии с примером, приведенным в разделе «Формат файла», выберите соответствующий формат для импорта файла пользовательских данных.
- После успешного импорта произойдет переход к списку данных.
- отметкаданные。Нажмите на крайнюю правую часть каждого фрагмента данных.
Annotateкнопка начала тега。Тип тега в правой части страницы тегов(Label Типы) для переключения между тегами сущностей и тегами отношений.- Маркировка объектов. Вы можете маркировать объекты, выделив текст непосредственно с помощью мыши.
- Аннотация связи: сначала щелкните метку связи, которую нужно аннотировать, а затем последовательно щелкните соответствующие начальные и хвостовые объекты, чтобы завершить аннотацию связи.
Экспортировать данные。существоватьDatasetsНажмите на столбецActions、Export DatasetЭкспортированоотметка的данные。

Преобразуйте данные аннотаций в данные, необходимые для обучения UIE.
Запустите следующий код, чтобы преобразовать данные аннотации в данные, необходимые для обучения UIE.
! python preprocess.py --input_file ./data/test.jsonl --save_dir ./data/ --negative_ratio 5 --splits 0.2 0.8 0.0 --seed 1000Обучить модель UIE
- Используйте аннотированные данные для обучения небольшой выборки,Сохранить параметры моделисуществовать
./checkpoint/Оглавление。
tips: рекомендоватьиспользоватьGPUсреда,В противном случае может произойти переполнение памяти. В среде ЦП,Может быть измененmodelдляuie-tiny,Отрегулируйте пакетный_размер соответствующим образом.
! python finetune.py --train_path ./data/train.txt --dev_path ./data/dev.txt --save_dir ./checkpoint --model uie-base --learning_rate 1e-5 --batch_size 16 --max_seq_len 512 --num_epochs 50 --seed 1000 --logging_steps 10 --valid_steps 10Теперь мы в основном завершили небольшую часть обучения кейсу. В следующей главе мы отобразим граф знаний в базе данных.



Углубленный анализ переполнения памяти CUDA: OutOfMemoryError: CUDA не хватает памяти. Попыталась выделить 3,21 Ги Б (GPU 0; всего 8,00 Ги Б).

[Решено] ошибка установки conda. Среда решения: не удалось выполнить первоначальное зависание. Повторная попытка с помощью файла (графическое руководство).

Прочитайте нейросетевую модель Трансформера в одной статье

.ART Теплые зимние предложения уже открыты

Сравнительная таблица описания кодов ошибок Amap

Уведомление о последних правилах Points Mall в декабре 2022 года.

Даже новички могут быстро приступить к работе с легким сервером приложений.

Взгляд на RSAC 2024|Защита конфиденциальности в эпоху больших моделей

Вы используете ИИ каждый день и до сих пор не знаете, как ИИ дает обратную связь? Одна статья для понимания реализации в коде Python общих функций потерь генеративных моделей + анализ принципов расчета.

Используйте (внутренний) почтовый ящик для образовательных учреждений, чтобы использовать Microsoft Family Bucket (1T дискового пространства на одном диске и версию Office 365 для образовательных учреждений)

Руководство по началу работы с оперативным проектом (7) Практическое сочетание оперативного письма — оперативного письма на основе интеллектуальной системы вопросов и ответов службы поддержки клиентов

[docker] Версия сервера «Чтение 3» — создайте свою собственную программу чтения веб-текста

Обзор Cloud-init и этапы создания в рамках PVE

Корпоративные пользователи используют пакет регистрационных ресурсов для регистрации ICP для веб-сайта и активации оплаты WeChat H5 (с кодом платежного узла версии API V3)

Подробное объяснение таких показателей производительности с высоким уровнем параллелизма, как QPS, TPS, RT и пропускная способность.

Удачи в конкурсе Python Essay Challenge, станьте первым, кто испытает новую функцию сообщества [Запускать блоки кода онлайн] и выиграйте множество изысканных подарков!

[Техническая посадка травы] Кровавая рвота и отделка позволяют вам необычным образом ощипывать гусиные перья! Не распространяйте информацию! ! !

[Официальное ограниченное по времени мероприятие] Сейчас ноябрь, напишите и получите приз

Прочтите это в одной статье: Учебник для няни по созданию сервера Huanshou Parlu на базе CVM-сервера.

Cloud Native | Что такое CRD (настраиваемые определения ресурсов) в K8s?

Как использовать Cloudflare CDN для настройки узла (CF самостоятельно выбирает IP) Гонконг, Китай/Азия узел/сводка и рекомендации внутреннего высокоскоростного IP-сегмента

Дополнительные правила вознаграждения амбассадоров акции в марте 2023 г.

Можно ли открыть частный сервер Phantom Beast Palu одним щелчком мыши? Супер простой урок для начинающих! (Прилагается метод обновления сервера)

[Играйте с Phantom Beast Palu] Обновите игровой сервер Phantom Beast Pallu одним щелчком мыши

Maotouhu делится: последний доступный внутри страны адрес склада исходного образа Docker 2024 года (обновлено 1 декабря)

Кодирование Base64 в MultipartFile

5 точек расширения SpringBoot, супер практично!

Глубокое понимание сопоставления индексов Elasticsearch.

15 рекомендуемых платформ разработки с нулевым кодом корпоративного уровня. Всегда найдется та, которая вам понравится.
