Brother OCR, библиотека с открытым исходным кодом для Python, которая распознает коды проверки.
OCR (оптическое распознавание символов) — это технология, используемая для преобразования печатного или рукописного текста в редактируемые и доступные для поиска электронные документы. Он анализирует формы и структуры символов на изображениях и преобразует их в машиночитаемые текстовые данные. Технология оптического распознавания символов играет важную роль во многих областях, включая управление документами, автоматизированный офис, оцифровку библиотек, распознавание номерных знаков и т. д.
Для извлечения текста OCR ранее также был представлен Umi-OCR. Этот инструмент, и то, чем мы собираемся поделиться сегодня, в основном представляет собой инструмент с открытым исходным кодом, используемый для решения проблем, связанных с кодами проверки. ддддокр адрес проекта автора на github следующий:https://github.com/sml2h3/ddddocr?tab=readme-ov-file
Когда мы выполняем некоторые ежедневные операции, связанные с автоматическим тестированием, нам иногда необходимо вводить коды проверки. Сейчас на рынке представлено множество типов кодов проверки. Основные из них следующие:
- Перетащите ползунок в указанное положение
- Нажмите на указанный текст последовательно
- Введите комбинацию букв+цифр на картинке
- Посчитайте числа на картинке, сложите, вычтите, умножьте и разделите результаты.
- сотовый телефон Проверочный кодиз
- Есть также некоторые нечеловеческие объекты распознавания (тип эмо).
ddddorc в основном используется для решения таких сценариев, как идентификация текстового содержимого изображения, такого как буквы и китайские иероглифы, а также скользящие ползунки.
Итак, давайте установим и воспользуемся им, чтобы опробовать эффект ddddocr. Требуемая среда – это Python<=3.9Версия。window,linux,Mac поддерживает,Но он не поддерживаетсяM1。Просто введите в терминале
pip install ddddocrПодождите установки и затем используйте его.。 Ниже приведен пример использования: - Распознавание текста на изображениях: подходит для ввода определенных букв или цифр на изображениях и т. д.
import ddddocr
ocr = ddddocr.DdddOcr()
#Путь к изображению
with open("img.png", 'rb') as f:
image = f.read()
res = ocr.classification(image)
print(res)2. Обнаружение цели. Подходит для щелчков по тексту и значков. Проще говоря, для кодов подтверждения, вводимых щелчком мыши, текст или значки на изображении могут быть быстро обнаружены.
import ddddocr
import cv2
det = ddddocr.DdddOcr(det=True)
with open("test.jpg", 'rb') as f:
image = f.read()
poses = det.detection(image)
print(poses)
im = cv2.imread("test.jpg")
for box in poses:
x1, y1, x2, y2 = box
im = cv2.rectangle(im, (x1, y1), (x2, y2), color=(0, 0, 255), thickness=2)
cv2.imwrite("result.jpg", im)Творить непросто. Если вы считаете, что эта статья вам полезна, поставьте мне лайк. Это будет моей мотивацией продолжать делиться высококачественным контентом.


Поиграйтесь с интеграцией Spring Boot (платформа запланированных задач Quartz)

Несколько популярных режимов интерфейса API: RESTful, GraphQL, gRPC, WebSocket, Webhook.

Redis: практика публикации (pub) и подписки (sub)

Подробное объяснение пакета Golang Context
Краткое руководство: создайте свое первое приложение .NET Aspire

Краткое обсуждение метода пакетной вставки MyBatis: обработка 100 000 фрагментов данных занимает всего 2 секунды.

[Инструмент] Используйте nvm для управления переключением версий nodejs, это так здорово!

HTML можно преобразовать в word_html для отображения текстовых документов.
Статья Spring Security 6.x для быстрого понимания принципов настройки
Не забудьте изменить имя каждого модуля RUOYI один раз, чтобы избежать мошенничества ~~~
Научите вас шаг за шагом, как интегрировать систему обслуживания клиентов Hunyuan AI Q&A от 0 до 1.

Подробное объяснение Gzip: принципы и применение алгоритмов сжатия.

Скачать Tomcat - ссылка для скачивания на официальном сайте tomcat7, tomcat8, tomcat9
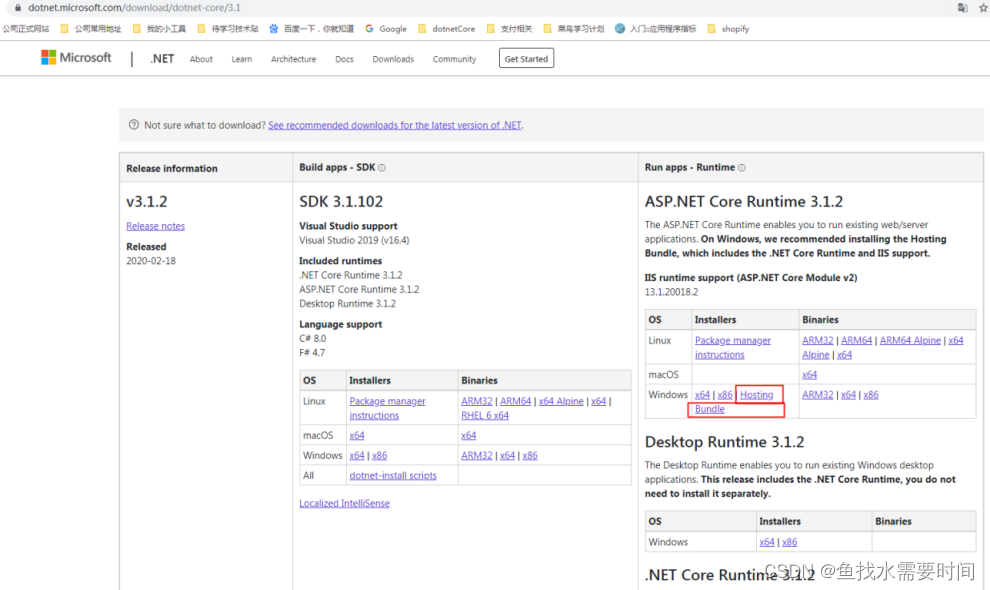
Развертывание IIS.NetCore
[Оптимизация памяти Android] Общие функции инструмента Android Profiler (мониторинг памяти | снимок памяти)

Встроенная в Springboot пользовательская конфигурация временного каталога, связанного с Tomcat.

Краткое руководство по началу работы с Element-UI
Руководство пользователя ГОРМ
Одна статья для понимания артефакта развязки внутренних компонентов Spring Event (событие Spring)

Java перехватывает строку после определенного символа_java, как перехватить строку

Давайте кратко поговорим о технологии копирования на записи.

Выполнение собственных условий SQL-запроса в MyBatis Plus

Напоминание о выпуске общедоступной учетной записи WeChat (интерфейс сообщения шаблона общедоступной учетной записи WeChat)
5 шагов для установки среды протокола

Наиболее полные коды состояния HTTP
На основе языка Go мы шаг за шагом научим вас внедрять структуру системы управления серверной частью.
Эффективное управление журналами с помощью Spring Boot и Log4j2: подробное объяснение конфигурации

Что делать, если telnet не является внутренней или внешней командой [легко понять]

php-объект для анализа json_php json
