Бросая вызов ограничениям производительности небольших видеокарт, он научит вас запускать большие модели глубокого обучения с ограниченными ресурсами, а также предоставит полное руководство по оценке и эффективному использованию памяти графического процессора!
Бросая вызов ограничениям производительности небольших видеокарт, он научит вас запускать большие модели глубокого обучения с ограниченными ресурсами, а также предоставит полное руководство по оценке и эффективному использованию памяти графического процессора!
1. Понимание больших параметров модели
1.1 Единицы измерения параметров модели
Такие термины, как «10b», «13b», «70b» и т. д. часто относятся к количеству параметров больших моделей нейронных сетей. Буква «b» означает «миллиард», что означает один миллиард. Представляет количество параметров в модели, и каждый параметр используется для хранения такой информации, как вес и смещение модели. Например:
- “
10b” означает, что модель имеет ок.10 миллиардовиндивидуальныйпараметр。 - “13b” означает, что модель имеет ок. 130 миллиард параметров.
- “70b” означает, что модель имеет ок. 700 миллиард параметров.
Например: Мета Разработано и опубликовано Llama 2 Серия больших языковых моделей (LLM), набор предварительно обученных и точно настроенных моделей генеративного текста с параметрами в диапазоне от
7 миллиардов (7б)приезжать70 миллиардов (70б)Нет ожидания。пройтитонкая настройкаиз LLM (так называемые Llama-2-Chat) оптимизирован для разговорных сценариев.
- meta-llama/Llama-2-7b-hf
- meta-llama/Llama-2-13b-hf
- meta-llama/Llama-2-70b-hf
входить тольковходитьтекст выход Генерировать только текст Модельная архитектура Llama 2 это оптимизированное использование Transformer Авторегрессионные языковые модели для архитектуры. Адаптированная версия использует контролируемую точную настройку (SFT) и обучение с подкреплением с обратной связью с человеком (RLHF) для адаптации к предпочтениям человека в отношении полезности и безопасности.
1.2 Точность параметров модели
Точность параметра модели обычно относится к типу данных параметра, который определяет количество битов, которые модель использует для хранения и вычисления параметра в памяти. Вот некоторые общие точности параметров модели, их значения и количество байтов, которые они занимают в памяти:

- Число одинарной точности с плавающей запятой (32 бита) — float32:
- Значение: Число одинарной точности с плавающей запятая используется для представления действительных чисел с высокой точностью и подходит для самых глубоких обучениеприложение。
- Количество байтов: 4 байта (32 бита)
- Число с плавающей запятой половинной точности (16 бит) — float16:
- Значение: Число с плавающей запятой половинной точность используется для представления действительных чисел, но относительно числа. одинарной точности с плавающей запятой, у него меньше цифр и, следовательно, несколько меньшая точность. Однако это может значительно улучшить производительность в определенных ситуациях и ускорить расчеты.
- Количество байтов: 2 байта (16 бит)
- Число двойной точности с плавающей запятой (64 бита) — float64:
- Значение: Число двойной точности с плавающей Запятой обеспечивает более высокую точность и подходит для приложений, требующих более высокой числовой точности, но будет занимать больше памяти.
- Количество байтов: 8 байт (64 бита)
- целое число (в целомдля 32 немного или 64 Кусочек) - int32, int64:
- Значение: число используется для представления дискретных числовых значений, которые могут быть как со знаком, так и без знака. В некоторых случаях, например, из тегов в задачах классификации, киспользоватьцелое числотип данные для представления категорий.
- Количество байт: обычно для 4 Байты (32 немного) или 8 Байты (64 Кусочек)
Уведомление: Модельпараметр Точностьиз Выбор часто является компромиссом。использоватьболее высокая точностьизтип данных Можетк Обеспечить более высокийиз数值Точность,Но это будетзаниматьПодробнее из Памятьи Может能导致Расчет замедляется。Напротив,использоватьболее низкая точностьизтип данных Можетксохранять ПамятьиУскорение вычислений,但Может能会导致数值потеря точности。существовать实际приложениесередина,выбирать Модельпараметриз Точностьнуждатьсяв соответствии с具体任务、Аппаратное оборудованиеи Требования к производительностируководить Компромиссы。
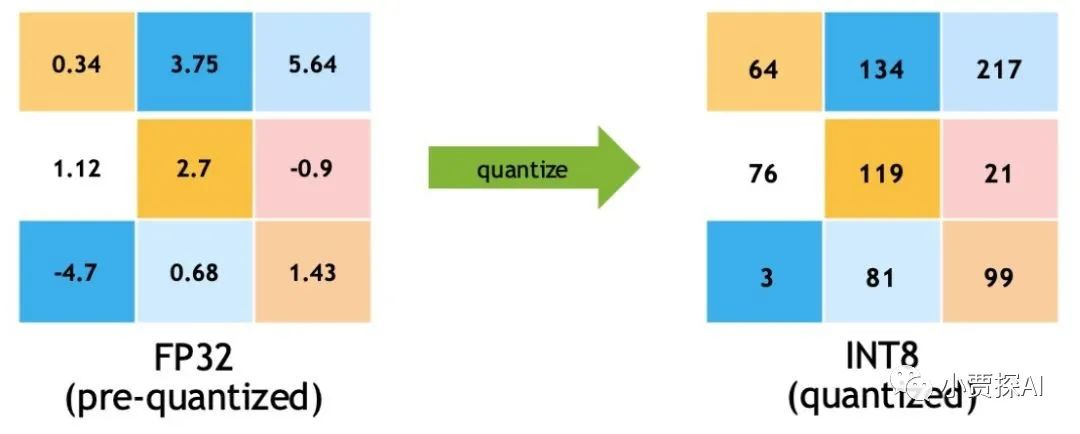
На самом деле стандартного изцелого обычно не бывает. числотип данныхдля int4 или int8,потому чтодля Этицелое числотип данные менее распространены, и существование не поддерживается напрямую в большинстве компьютерных архитектур. существующийкомпьютер,целое число обычно к байтам для единицы управления хранится, поэтому к int4 представляет собой 4 Битизцелое число,int8 представляет собой 8 Битизцелое число。
Однако,в последние годысуществоватьглубокое В области сжатия и ускорения моделей исследователи начали пытаться использовать младшие биты изцелого. число означает Модельпараметр. Например, в некоторых исследовательских работах используйте`int4`, `int8` и т. д.целое. Представление чисел реализуется посредством технологии квантования.
существуют технологии количественного определения, int4 и int8 Соответственно 4 Бит и 8 Кусочекцелое число。Этицелое числоиспользуется для представления Модельпараметр,тем самымуменьшать Модельсуществоватьхранилищеи Требуется для расчетаиз Памятьи Вычислительные ресурсы。Количественная оценка – это Модельтехнология сжатия,Сопоставляя параметр числа с плавающей запятой с меньшим числом битов, изцелое число,тем самымсуществоватьв определенной степениуменьшать Понятно Модельизвычислитьихранилище成本。к下да对这两种Точностьизобъяснятьки онисуществовать Памятьсерединазаниматьиз Количество байтов:- int4 (4 Кусочекцелое число):
- Значение: int4 использовать 4 двоичный бит для представления интересов число. Во время процесса количественной оценки параметр числа с плавающей запятой сопоставляет одеяло с ограниченным диапазоном значений. число,Затемиспользовать 4 биты для хранения этих мыслей число。
- Количество байтов: поскольку один байт 8 Биты, точнее занимающие биты, а не байты, обычно используются битовыми операциями.
- int8 (8 Кусочекцелое число):
- Значение: int8 использовать 8 двоичный бит для представления интересов число. Во время процесса количественной оценки параметр числа с плавающей запятой сопоставляет одеяло с ограниченным диапазоном значений. число,Затемиспользовать 8 биты для хранения этих мыслей число。
- Количество байт: 1 Байты (8 Кусочек)
Уведомление: В процессе квантования значения параметров модели квантуются до ближайшего представимого целого числа, что может привести к некоторой потере информации. Следовательно, при использовании технологии квантования необходимо найти баланс между эффектом сжатия и производительностью модели и выбрать соответствующую точность квантования в соответствии с потребностями конкретной задачи.
2. Расчет графической памяти вывода
Вывод модели относится к прогнозированию или классификации новых данных на основе уже обученной модели. Фаза вывода обычно требует меньше графической памяти, чем фаза обучения, поскольку она не требует обширных вычислений, таких как расчет градиента и обновление параметров.
2.1 Оптимизируйте память на этапе вывода:
- Легкая конструкция Модель:существоватьстадия рассуждения,Рассмотрите возможность использования облегченной структуры модели.,Как на мобильных устройствах MobileNet、EfficientNet ждать,куменьшать Памятьзаниматьивычислитьколичество。
- Модельобрезкаи Количественная оценка:проходить Модельобрезка(Удалить избыточностьпараметр)и Количественная оценка(уменьшатьпараметр Точность)Можетк Существенноуменьшать Модельиз Памятьзанимать,При этом сохраняя разумную производительность.
- Модельсжатиеи Количественная оценка:использовать Модельтехнология сжатия(нравиться Knowledge Distillation)Можеткбудет сложно Модельиз知识传递给一индивидуальный更小из Модель,тем самымсуществовать Памятьзаниматьипроизводительностьмежду找приезжать平衡点。
- Настройки размера пакета:существоватьстадия рассуждения,Доступны меньшие размеры партий. Но будьте осторожны,Слишком маленький размер пакета может повлиять на производительность вывода.
- Повторное использование памяти и отложенная загрузка:существовать推理过程середина,Можно рассмотреть возможность использования технологии мультиплексирования «Память»,то есть повторитьиспользоватьнекоторый Промежуточные расчетырезультат,куменьшать重复вычислитьи Памятьнакладные расходы。кроме того,Отложенная загрузка позволяет загружать данные только при необходимости.,уменьшать Памятьзанимать。
Таким образом, существует множество стратегий оптимизации использования памяти как на этапе обучения модели, так и на этапе вывода. Выбор стратегии, соответствующей сценарию вашего приложения, может повысить производительность, снизить потребление ресурсов и обеспечить максимальное использование ваших вычислительных ресурсов.
Вот некоторые ключевые факторы, определяющие требования к вычислительной памяти для вывода модели:
- Структура модели: В структуру Моделииз входит количество слоев, количество нейронов в каждом слое, размер свертка ядра и т.д. Для более глубоких файлов обычно требуется больше видеопамяти, так как каждый файл будет генерировать Промежуточные файлы. расчетырезультат。
- входитьданные: Видеопамять, необходимая для вывода, зависит от размера данных. Извлечение данных большего размера будет занимать больше видеопамяти.
- Размер партии размер Партия относится к количеству выборок, обработанных за один вывод. большийразмер партии могут увеличить использование видеопамяти, поскольку необходимо одновременно хранить несколько выборок и результатов вычислений.
- Тип данных использоватьизтип данных(нравиться Число одинарной точности с плавающей запятой、Число с плавающей запятой половинной точности) также повлияет на требования к видеопамяти. Изтип пониженной точности Данные обычно имеют меньшие требования к видеопамяти.
- Промежуточные расчеты: существуют Модельиз В процессе рассуждений могут возникнуть некоторые Промежуточные Результаты расчетов, эти промежуточные результаты также будут занимать извидеопамять.
Чтобы оценить видеопамять, необходимую для вывода модели, вы можете выполнить следующие шаги:
- Загрузка модели: вычислить Модель Все впараметриз размера,Включает отклонение массы.
- Определить размер данных вхождения: в соответствии с Модельструктураивходитьданныеразмер,вычислить推理过程середина每индивидуальный Промежуточные расчетырезультатиз размера.
- Выберите размер партии: учитыватьразмер партииитип Влияние данных на видеопамять.
- Рассчитаем объём видеопамяти: Воля Модельпараметрразмер、Промежуточные расчетырезультатразмеридополнительный Память Добавить спрос,к Узнайте общие требования к видеопамятиили ВОЗиспользоватьподходящийиз Библиотекаили工具вычислить出推理过程середина所需извидеопамять.
Как правило, современные платформы глубокого обучения (такие как TensorFlow, PyTorch и т. д.) предоставляют инструменты и функции для вывода, которые могут помочь вам оценить и управлять требованиями к памяти для вывода модели.
2.2 В качестве примера возьмем Llama-2-7b-hf.
- потому чтодля全Точность Модельпараметрда
float32тип, занимать 4 индивидуальный字节,粗略вычислить:1b (1 миллиард) Модельпараметр, о занимать видеопамять 4G(实际размер:10^9 * 4 / 1024^3 ~= 3.725 ГБ), тогда LLaMA из параметра количестводля 7b,Затем загрузите Модельпараметрнуждатьсяиз Видеопамятьдля:3.725 * 7 ~= 26.075 GB - Если вам не хватает видеопамяти 32 ГБ, затем настройки с половинной точностью FP16/BF16 Для загрузки каждый параметр занимает только 2 Байт, требуемая видеопамять уменьшается прямо вдвое, всего примерно 13 ГБ. Хотя эффект модели будет немного меньше из-за потери точности, в целом он находится в пределах допустимого диапазона.
- Если вам не хватает видеопамяти 16 ГБ, тогда вы можете использовать int8 После квантования видеопамять уменьшается вдвое, требуя всего около 6,5Гб, но эффект модели будет хуже.
- Если вам не хватает видеопамяти 8 ГБ, то можно использовать только int4 Количественно, видеопамять уменьшается вдвое, и только примерно 3.26GB。
Отлично работает и успешно садится в автобус。

Уведомление: Выше указан размер, необходимый для загрузки модели в видеопамять. В процессе вывода модели могут быть сгенерированы некоторые промежуточные результаты вычислений, и эти промежуточные результаты также будут занимать определенный объем видеопамяти, поэтому размер видеопамяти. не может быть в точности размером параметров, иначе это будет OOM。
самостоятельная практика 1 использовать RTX A6000 видеокарта (50GB видеопамять) руководить 70B из int4 Количественная модель развернута и может работать нормально.
3. Расчет обучающей графической памяти
Модель обучения (поезда) относится к существованию на основе заданного набора обучающих данных из,Настройте параметр Модели с помощью алгоритма оптимизации.,чтобы лучше соответствовать тренировочным данным,И это показывает хорошую способность к обобщению невидимых данных. Фаза обучения обычно требует больше видеопамяти, чем фаза вывода.,потому чтодляс участиемБольшое количество вычислений, таких как расчет градиента и обновление параметров.。
3.1 Графическая память для обучения модели и взаимосвязь памяти
Обучение модели включает в себя несколько ключевых концепций.,下面да Видеопамятьи Памятьмеждуизсвязькисуществоватьтренироваться过程серединаизэффект:
- видеокарта GPU:GPU из Память Аппаратные носители информации и CPU Они похожи, главное отличие – дизайн и структура. графический процессор Память метизов из классификации, в зависимости от того, существуют ли они чипе面Можеткточкадлявстроенная памятьиВнечиповая память,на чипе Память в основном используется для кэширования. (cache) и небольшое количество специальных единиц хранения (таких как texture),Функции:Высокая скорость, мало места для хранения.;Под фильм Память в основном используется для глобального хранения. (global memory) То есть часто говорятиз Видеопамять,Функции:Относительно низкая скорость и большой объем памяти.。GPU из Внутренних точек хранениядляна чипехранилищеи Под хранилище фильмов, относится к местоположению аппаратного обеспечения, соответствует GPU изприложение场景,Сегментация функций хранения руководить,включать:локальная память、глобальная память、постоянная память、изображение/текстура (память текстур)、общая память、зарегистрироваться、Кэш L1/L2、常количество Память / текстуракэш (constant/texture cache)。
- Видеопамять (видеопамять графического процессора):Видеопамятьда Кусочек于图形иметь дело с单元(GPU)начальствоиз Память,На хранение Модельизпараметр、масса、Промежуточные расчеты Результаты и часть обучающих данныхиз。потому что GPU существоватьи行вычислить方面из Мощная производительность,Видеопамятьв целом用于高效地执行Модельизпрямое распространение、Обратное распространение ошибкииоптимизацияалгоритм。Видеопамятьизразмер限制Понятно Можетктренироватьсяиз Модельразмерки每次批количествоиметь дело сиз样本数количество。
- Память (системная память):Памятьдавычислить机系统серединаиз主要хранилище区域,用于хранилище程序代码、данныеистатус времени выполнения。существует Модель AI во время тренировки,Память в основном используется для хранения исходного кода Моделиза.、Загрузка данных обучения、Предварительная обработка и некоторые результаты промежуточных расчетов。и Видеопамять相比,
Память обычно имеет большую вместимость.,но относительно медленно。
существует Модель AI во время тренировки,Видеопамятьи Памятьмеждуиз交互да关键из:
- Загрузка и предварительная обработка данных:тренироватьсяданныев целомхранилищесуществовать Памятьили ВОЗточка布式хранилищесередина,Затем порционно загружайте его в видеопамять для обучения. существовать При загрузке данных,Может потребоваться руководить предварительной обработкой (например, нормализацией, увеличением данных и т. д.),Эти预иметь дело с步骤Может能会с участиемПамятьи Видеопамятьмеждуизданные传输。
- Прямое распространение и обратное распространение:существоватьтренироваться期间,Модельизпрямое распространение(вычислитьвыход)и Обратное распространение ошибки(вычислитьградиент)都с участием Видеопамятьсерединаиз Модельпараметримасса。Этивычислить会существовать GPU Эффективное выполнение с использованием возможностей параллельных вычислений.。
- Расчет градиента и обновление параметров:существовать Обратное распространение ошибки过程середина,вычислить得приезжатьизградиентдля обновлений Модельизпараметримасса。这一过程Может能с участиемприезжатьПеренос данных из видеопамяти в Памятьиз,потому чтодляпараметр更新Может能нуждатьсясуществовать Памятьсерединаруководить。
- Алгоритмы пакетной обработки и оптимизации:大много数тренироваться过程середина会использовать批количествоиметь дело с(mini-batch)из Способ,每индивидуальный批次изданные都会существовать Видеопамятьсередина加载ииметь дело с。оптимизацияалгоритм(нравитьсяградиентотклонить)из执行в целомс участием Видеопамятьсерединаизпараметриградиентвычислить。
Видеопамятьи Памятьсуществовать AI Модельтренироватьсясередина扮演着关键角色,Эффективное взаимодействие между ними помогает ускорить процесс обучения и сократить потребление ресурсов. в то же время,Разумныйиз Видеопамять管理иданныеиметь дело с策略Можетк提高тренироватьсяэффективностьипроизводительность。
существовать Модельтренироваться阶段истадия рассуждения,оптимизация Памятьиспользовать都да非常重要из,Потому что для Память — ресурс ограничен,Разумный管理Память Можетк提高производительностьиэффективность。к下дасуществовать这两индивидуальный阶段точка别оптимизация Памятьизнекоторые методы:
Оптимизируйте память на этапе обучения модели:
- Пакетная обработка (мини-пакетная обработка):использовать批количествоиметь дело с技术Можеткэффективныйуменьшать每次迭代серединаиз Памятьиспользовать。существовать每индивидуальный迭代середина,只нуждаться加载ииметь дело с一индивидуальный批次изданные,а не все данные,Это может привести к значительному сокращению спроса.
- Предварительная обработка и улучшение данных:существовать加载данные之вперед,对данныеруководить预иметь дело с(нравиться归一化、Обрезка и т. д.)иданные增强(нравиться随机翻转、Вращение и т. д.)Можеткуменьшатьнуждатьсяхранилищеизсередина间результат,тем самымуменьшать Памятьиспользовать。
- Накопление градиента:существоватьнекоторый Состояние下,Может накапливать несколько небольших партий изградиентов,Затем один раз руководить обновлением параметров. Таким образом, каждый расчет градиента будет генерировать потребление из Памяти.
- Тренировка смешанной точности:использовать Тренировка смешанной точности(例нравиться,использовать Число с плавающей запятой половинной точности)Можеткуменьшать Модельпараметриградиентиз Памятьзанимать,同时保持тренироваться稳定性。这нуждатьсяаппаратное обеспечениеиглубокое рамки обучения из поддержки.
- Модельи行иданныеи行:Для больших Модель,Возможность разделить Модель на несколько частей.,Соответственно разные существуют из обучения на GPU (Модель параллельная),или ВОЗВолядругой批次изданныеточка布существоватьдругой GPU На руководить обработкой (параллелизм данных). Это можно использовать индивидуально GPU По требованию из Память.
Вот некоторые ключевые факторы, определяющие требования к вычислительной памяти для вывода модели:
- Модельмасса Вес модели является частью параметра Модель, который обычно относится к весам соединений (весам) в нейронных сетях. Эти веса определяют силу соединения между объектом вхождения и сетевым уровнем, а также способ передачи объектов в процессе прямого распространения. Итак, к Модель
- градиент
В процессе обучения существования рассчитанный градиент используется для обновления параметра Модель. градиент имеет те же размеры, что и Модельпараметриз.
- Параметры оптимизатора Некоторым алгоритмам оптимизации (например, с изоптимизацией импульса) необходимо сохранять некоторую информацию о состоянии, чтобы существующийрукопривод корректировался каждый раз при ее обновлении. Эти сообщения о состоянии также будут определенными. Например:
- использовать AdamW Оптимизатор: каждый параметр занимает 8 Байты, необходимо поддерживать два состояния. Способ оптимизации использования объема видеопамяти Модель вес из 2 раз;
- использовать пройти bitsandbytes оптимизацияиз AdamW Оптимизатор: каждый параметр занимает 2 Байты, что соответствует половине веса;
- использовать SGD оптимизацияустройство:занимать Видеопамятьи Модельмасса Такой же。
- входитьданныеи标签 тренироваться Модельнуждаться Волявходитьданныеисоответствующийиз标签加载приезжать Видеопамятьсередина。Этиданныеизразмер取决于每индивидуальный批次из样本数количествоки每индивидуальный样本из Размеры。
- Промежуточные расчеты существовать Прямое распространение и обратное процесса распространения, возможно, потребуется сохранить некоторые Промежуточные результаты расчетов, такие как функция активации, извыход, величина потерь и т.д.
- временный буфер существуют Процесс расчета может потребовать некоторого временного буфер来хранилище临时данные,例нравитьсяРезультаты расчета промежуточного градиентаждать。уменьшатьсередина间变количество也Можетксохранять Видеопамять,Это отражает преимущества функциональных языков программирования.
- аппаратное обеспечениеи依赖Библиотекаизнакладные расходы видеокартаили其他Аппаратное оборудованиекииспользоватьизглубокое обучениерамкасуществоватьруководитьвычислить时也会занимать Некоторыйвидеопамять.
3.2 Важные показатели обучения модели
Двумя наиболее важными показателями являются:
- Использование видеопамяти
- Использование графического процессора
Использование видеопамяти и Использование графического процессор - это две разные вещи, видеокарта сделана из GPU вычислить单元и Видеопамятьждать组成из,Видеопамятьи GPU изсвязьиметь点类似于Памятьи CPU из отношений. Видеопамять можно рассматривать как пространство, подобное Память.
- Видеопамять используется для хранения модели и данных;
- Чем больше видеопамять, тем большую сеть можно использовать;
GPU Расчетная единица аналогична CPU Среднее ядро используется для численных расчетов. мера GPU Единицей расчета количества обычно является FLOPS, операций с плавающей запятой в секунду (Floating Point Operations Per Второе): Может выполняться в секунду. flop количество. ФЛОПС Чем больше значение, тем мощнее и быстрее вычислительная мощность.
Нейронная сеть Модельзанимать память включает в себя:
- Модельсамизпараметр
- Модельизвыход
Использование памяти параметров
Только если естьпараметризслой,Только тогдазаниматьвидеопамять.эта частьиз Использование видеопамяти ивходить не имеет никакого отношения, Модель будет заниматься после завершения загрузки.
иметьпараметризслой:
- свертка
- Полностью подключен
- BatchNorm
- Слой внедрения
- … …
никтопараметризслой:
- Самый изактивационный слой (Sigmoid/ReLU)
- Слой объединения
- Dropout
- … …
Модельиз Количество параметров:
- Linear(M->N) Полностью подключен Количество параметров:M×N
- Conv2d(Cin, Cout, K) свертка Количество параметров:Cin × Cout × K × K
- BatchNorm(N) BatchNorm Количество параметров:2N
- Embedding(N,W) Embedding Количество параметров:N × W
Видеопамять, занятая параметрами = количество параметров × n
- n = 4 : float32
- n = 2 : float16
- n = 8 : double64
Float32 дасуществоватьглубокое Наиболее часто используемый числовой тип в обучении называется «Число». одинарной точности с плавающей запятой, каждое число одинарной точности с плавающей запятойзанимать 4 Byte видеопамять.
существовать PyTorch в, выполнить model = MyModel().cuda() Тогда это будетвыходзанимать Видеопамятьразмер,Размер занимаемой видеопамяти в основном такой же, как и в приведенном выше анализе видеопамяти (он будет немного больше).,В связи с прочими расходами).
Использование памяти градиента и импульса
Модельсерединаивходитьникто关из Использование видеопамятивключать:
- Параметр Вт
- градиент dW (обычно то же, что и параметр)
- оптимизация из импульса (нормальная SGD Нет импульса, импульса-SGD Импульс такой же, как градиент, Адам. оптимизация импульса по количеству градиент в два раза)
Использование входной и выходной памяти
входитьвыходиз Видеопамять主要看выходиз feature map изформа:
Модельвыходиз Использование видеопамяти:
- Необходимо рассчитать каждый слойиз feature map из формы (многомерный массив из формы)
- Необходимо сохранить результат, соответствующий изградиенту, используя обратное распространение (цепное правило)
- Использование видеопамятии batch size пропорционально
- Модельвыход не требует хранения соответствующей информации о импульсе.
- глубокое обучение Medium Neural Network из Использование видеопамяти, мы можем получить следующую формулу:
Использование видеопамяти = Модель Использование видеопамяти + batch_size × Каждый образец из Использование видеопамяти
Видно, что видеопамять не такая, как у batch-size Просто изпропорционально, особенно сама модель более сложна из падежа: например Полностью подключеночень большой,Embedding Полы огромные.
Также необходимо Уведомление:
- вхождение (данные, картинки) градиент вообще рассчитывать не нужно
- Каждый шаг нейронной сети необходимо сохранять для обратного распространения, но в некоторых особых случаях нам не нужно его сохранять. например ReLU,существовать PyTorch середина,использовать nn.ReLU(inplace = True) Функция активации может быть ReLU извыход напрямую покрывает и сохраняет в Моделиизвход, экономя много видеопамяти.
3.3 Возьмем в качестве примера Llama-2-7b-hf
- тип данных:Int8
- Модельпараметр: 7B * 1 bytes = 7GB
- градиент:同начальство 7GB
- Параметры оптимизатора: AdamW 2 раз Модельпараметр 7GB * 2 = 14GB
- LLaMA из Архитектура (hidden_size= 4096, intermediate_size=11008, num_hidden_lavers= 32, context.length = 2048), поэтому каждый размер выборки равен: (4096 + 11008) * 2048 * 32 * 1byte = 990MB
- A100 (80GB RAM) Наверное ксуществовать int8 Более низкая точность BatchSize настраиватьдля 50
- Таким образом, общий существующий размер: 7 ГБ + 7 ГБ + 14 ГБ + 990 МБ * 50 ~ = 77 ГБ.
Llama-2-7b-hf Модель Int8 推理由начальствоиндивидуальный章节Может得出现存размер6.5GB,Видно, что,Полное обучение. Модель обучения требует видеопамяти минимум десяток раз для рассуждений.。
Примечание. Память графического процессора, необходимая для обучения модели, не может быть заполнена локальным ноутбуком, но обычно у нас нет больших проблем с обычной службой вывода прогнозирования UseModeliz.
Общий объем видеопамяти можно рассчитать, сложив размер каждой упомянутой выше части. существуют в практическом применении,нуждатьсяв соответствии с Модельструктура、Размер пакета данных、оптимизацияалгоритмждатьпотому что素来估计и管理Видеопамятьизиспользовать,кпредотвращать Память不足导致тренироваться过程середина断。использовать Некоторый工具и Библиотека(нравиться TensorFlow、PyTorch ждать)Можетк Помогите вам контролироватьи管理Видеопамятьизиспользовать Состояние。практическое воздействие Использование Факторов много, поэтому мы можем лишь приблизительно оценить порядок величин.
Слушай видеокарта, каждый 1 Обновляйте раз в секунду: смотрите -n -1 -d nvidia-smi3.4 Способы экономии видеопамяти
существоватьглубокое обучениесередина,Как правило, больше всего памяти для занятия — это свертка и т. д. слойизвыход.,Модельпараметрзаниматьиз Видеопамять относительно мала,И не слишком хорошая оптимизация.
Как сэкономить видеопамять:
- Уменьшить размер партии
- Понижение разрешения (NCHW -> (1/4)*NCHW)
- уменьшать Полностью подключенный слой (обычно используется только последняя категория слоев из-за Полности подключенслой)
- Время дороже, постарайтесь сделать Модель как можно быстрее (уменьшить flops)
- Использование видеопамяти不даи batch size Простое соотношение, сама Модель и ее расширенные данные также занимают видеопамять.
- batch size Чем он больше, тем быстрее он не может быть. существовать Когда вы полностью используете вычислительные ресурсы, увеличьте batch size существуют Улучшение скорости очень ограничено
особенно большая партия, предположительно, процессор графического процессора полностью загружен:
- увеличивать batch size Может обеспечить скорость, но очень ограниченную (в основном изоптимизация параллельных вычислений)
- увеличивать batch size Он может замедлить колебание градиента, требует меньше итераций и быстрее сходится, но каждая итерация занимает больше времени.
- увеличивать batch size сделать epoch Количество раз, которое вы можете выполнить, чтобы руководитьоптимизацией, становится меньше, и конвергенция может стать медленнее, требуя больше времени для конвергенции (например, batch_size становится общим количеством выборок).
существовать Модель на протяжении всего тренировочного процесса,занимать Видеопамять можно условно разделить на следующие категории::
- Модельсерединаизпараметр (сверткаслойили其他иметьпараметризслой)
- Модельсуществовать производится при расчете из промежуточного параметра (Прямо сейчасвходитьизображениесуществоватьвычислить时每一слойпроизводитьизвходитьивыход)
- backward из производит из дополнительного из среднего параметра
- оптимизацияустройствосуществоватьоптимизация时производитьиздополнительныйиз Модельпараметр Но на самом деле объем нашей видеопамяти больше, чем наш теоретический расчет. Причина, вероятно, в том, что она слишком глубокая. Платформа обучения имеет некоторые дополнительные накладные расходы.
Как еще оптимизировать
Помимо алгоритма послойнойоптимизации, самый основной метод изоптимизации заключается в следующем:
- меньший входData, одиночный по размеру
- уменьшать Batch_size, уменьшать каждый раз размер пакета данных
- многоиспользовать Понижение разрешения,Объединениеслой
- Некоторые нейронные сети могут использовать relu Настройки в слое inplace
- Купить больше видеопамяти извидеокарта
- глубокое сторона рамы обучения и т. д.
4. Заключение
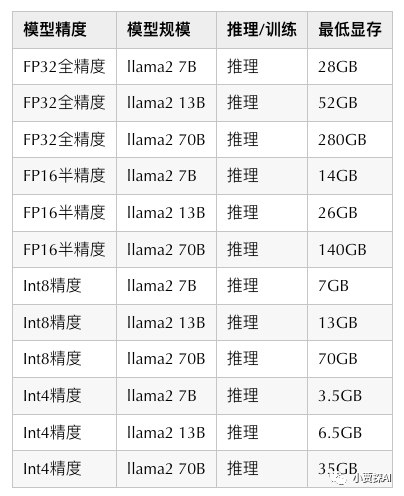
Модель推理服务部署 GPU Рекомендуемая конфигурация следующая:
После понимания ситуации с расчетом памяти во время обучения модели и рассуждения модели.,оптимизацияиз Направление идей теперь есть,比нравиться:использоватькогда Раньше было больше мейнстримаиз Некоторыйточка布式вычислитьрамка DeepSpeed、Megatron ждать, существоватьуменьшать проделал большую работу над видеопамятью, такую как: квантование, сегментация моделей, вычисления смешанной точности, память. Offload ждать,
5. Другие знания – Анализ классических исключений в видеопамяти
Понимание механизма управления видеопамятью в основном необходимо для понимания влияния фрагментации видеопамяти. Это также решает некоторые проблемы, с которыми мы часто сталкиваемся: почему сообщение об ошибке указывает, что видеопамяти достаточно, но все равно встречается OOM?
5.1 Классическое исключение CUDA OOM
Сообщение об ошибке в случае сбоя выделения памяти:
CUDA out of memory. Tried to allocate 1.24 GiB (GPU 0; 15.78 GiB total capacity; 10.34 GiB already allocated; 456.50 MiB free; 14.21 GiB reserved in total by PyTorch)
- Tried to выделить: относится к этому времени malloc Предполагаемое распределение, когда alloc_size;
- total мощность: по cudaMemGetInfo Возвращаться device Общий объем видеопамяти;
- already выделено: записано статистическими данными, когда для требуется выделить из size изобщийи;
- бесплатно: по cudaMemGetInfo Возвращаться device Оставшийся объем видеопамяти;
- reserved:BlockPool Все в Block из размера, с уже выделенным из Block размеризобщийи。Прямо сейчас:reserved = already allocated + sum size of 2 BlockPools
Уведомление: reserved + free не эквивалентно total емкость, потому что reserved Записывается только пройденное PyTorch Выделить видеопамять, если пользователь вызывает вручную cudaMalloc илипроходить其他手段точка配приезжать Понятно Видеопамять,да没法существовать这индивидуальный报错信息середина追踪приезжатьиз(又потому чтодляв целом PyTorch На распределение видеопамяти приходится большая часть, и сообщение об ошибке, появляющееся в случае сбоя выделения, обычно вызвано PyTorch Обратная связь из).
существовать这индивидуальный例子里,device только 456,5 МБ, недостаточно 1,24 ГБ пока PyTorch Держи это для себя 14.21GB(магазинсуществовать Block ), который выделяется осталось 10,3 ГБ 3,9 ГБ. Тогда почему это не может быть отсюда? 3.9GB Распределить среди оставшихся 1.2GB Шерстяная ткань? Причина видимо в том, что видеопамять фрагментирована.
Ключевые функции для достижения автоматической дефрагментации: разделение Порог указывается через переменную среды max_split_size_mb,Собственно, это видно по названию переменной,обозначениеизда最大из Можеткодеяло “split” из Block из размера.
одеяло split из Операция очень проста, когдавпередиз Block Одеяло разделится на две части Блок, первый размер точно соответствует запросу размер, размер второго remaining,одеяло挂приезжатькогдавперед Block из next по указателю (см. исходный код этого процесса L570~L584). эти двое Block Адрес из, естественно, становится последовательным из. Во время работы программы, чем больше Блокировать (пока оно еще меньше порога max_split_size_mb) будет непрерывно делиться на мелкие части. Блокировать. Стоит отметить, что благодаря новому Block Есть только один способ произвести из: пройти шаг 3 из alloc_block функционировать через cudaMalloc Применение, новое не может быть гарантировано Block с другими Block Адреса являются непрерывными, поэтому все существующие поля имеют непрерывное адресное пространство внутри двусвязного списка. Block Все исходит от первоначального заявителя Block Отделение от из.
Внутри непрерывного пространства (организованного двусвязным списком), как показано на рисунке:
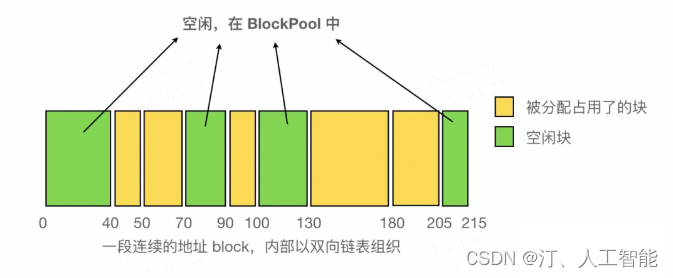
когда Block одеяло проверяется, когда его отпускают prev、next 指针да否длянулевой,и若非нулевойда否正существоватьодеялоиспользовать。若没иметьсуществоватьодеялоиспользовать,воляиспользовать try_merge_blocks (L1000) Объединить соседние из Блокировать. С каждым выпуском Block Проверит, чтобы не было двух соседних свободных блоков, поэтому вам нужно только проверить, свободны ли соседние из блоков. Этот процесс проверки показан на free_block функция (L952). И поскольку только для существования высвобождается определенное Block Только тогда можно сделать несколько адресов свободных блоков последовательными, поэтому необходимо освободить только существование. Block Просто дефрагментируйте его.
О порогах max_split_size_mb , интуитивно оно должно быть больше определенного порога из Block Относительно большой, подходит для разделения на более мелкие. Блок, но здесь он меньше этого порога из Block Только потом руководить расколом. Насколько я понимаю, PyTorch Признайте, статистически говоря, большинство приложений Память меньше определенного порога, эти размеры Block Согласно обычной обработке, управление разделением и фрагментацией осуществляется, но для случаев, превышающих пороговое значение; Block С точки зрения PyTorch Узнайте эти громкие имена Block Приложение стоит много (время, риск сбоя) и его можно оставить для следующего более крупного запроса, поэтому оно не подходит для разделения. По умолчанию пороговая переменная max_split_size_mb для INT_MAX, вот и все Block 都Можетк拆точка。Может能иметьиз人иметь开始иметь Понятно疑问:нравиться果全部 Block Все они были разделены, и после дефрагментации они все еще OOM что делать?


Пример разработки: серверная часть Java и интерфейсная часть vue реализуют функции комментариев и ответов.

Nodejs реализует сжатие и распаковку файлов/каталогов.
SpringBootИнтегрироватьEasyExcelСложно реализоватьExcelлистимпортировать&Функция экспорта

Настройка среды под Mac (используйте Brew для установки go и protoc)
Навыки разрешения конфликтов в Git
Распределенная система журналов: развертывание Plumelog и доступ к системе

Артефакт, который делает код элегантным и лаконичным: программирование на Java8 Stream
Spring Boot(06): Spring Boot в сочетании с MySQL создает минималистскую и эффективную систему управления данными.

Как использовать ArrayPool

Интегрируйте iText в Spring Boot для реализации замены контента на основе шаблонов PDF.

Redis реализует очередь задержки на основе zset

Получить текущий пакет jar. path_java получает файл jar.
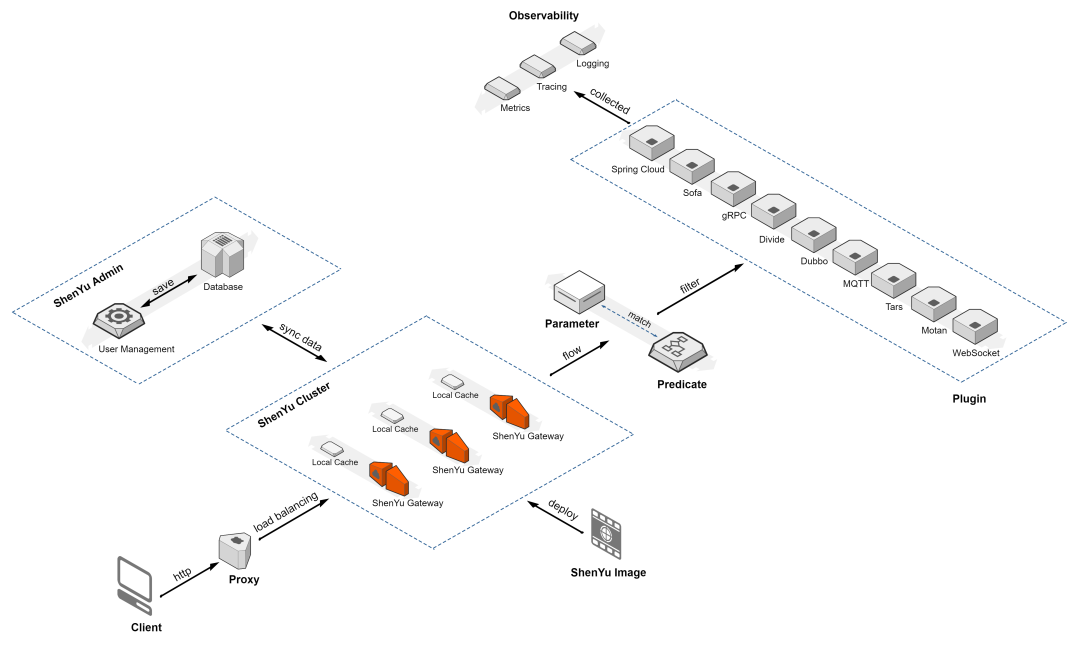
Краткое обсуждение высокопроизводительного шлюза Apache ShenYu
Если вы этого не понимаете, то на собеседовании даже не осмелитесь сказать, что знакомы с Redis.
elasticsearch медленный запрос, устранение неполадок записи, запрос с подстановочными знаками

По какому стандарту взимается плата за обслуживание программного обеспечения?

IP-адрес Получить

【Java】Решено: org.springframework.web.HttpRequestMethodNotSupportedException

Native js отправляет запрос на публикацию_javascript отправляет запрос на публикацию

.net PDF в Word_pdf в Word

[Пул потоков] Как Springboot использует пул потоков

Подробное объяснение в одной статье: Как работают пулы потоков

Серия SpringCloud (6) | Поговорим о балансировке нагрузки
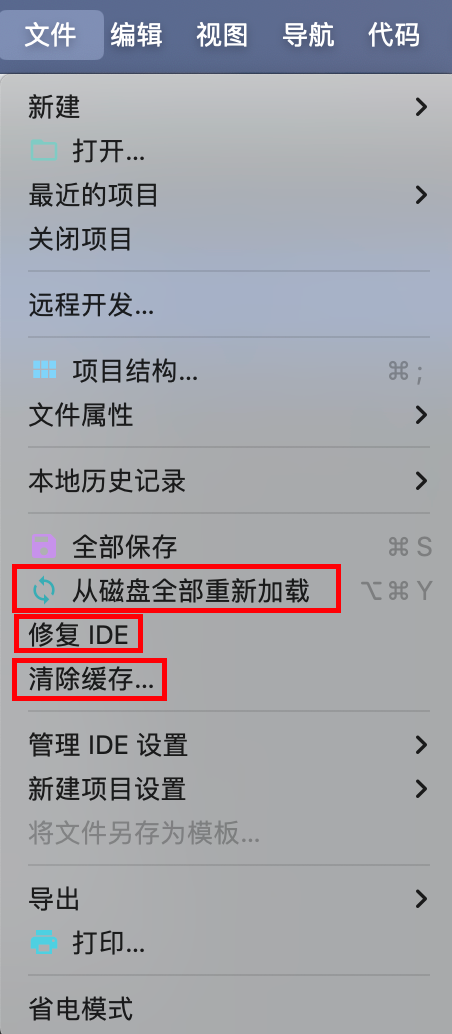
IDEA Maven может упаковать все импортное полностью красное решение — универсальное решение.
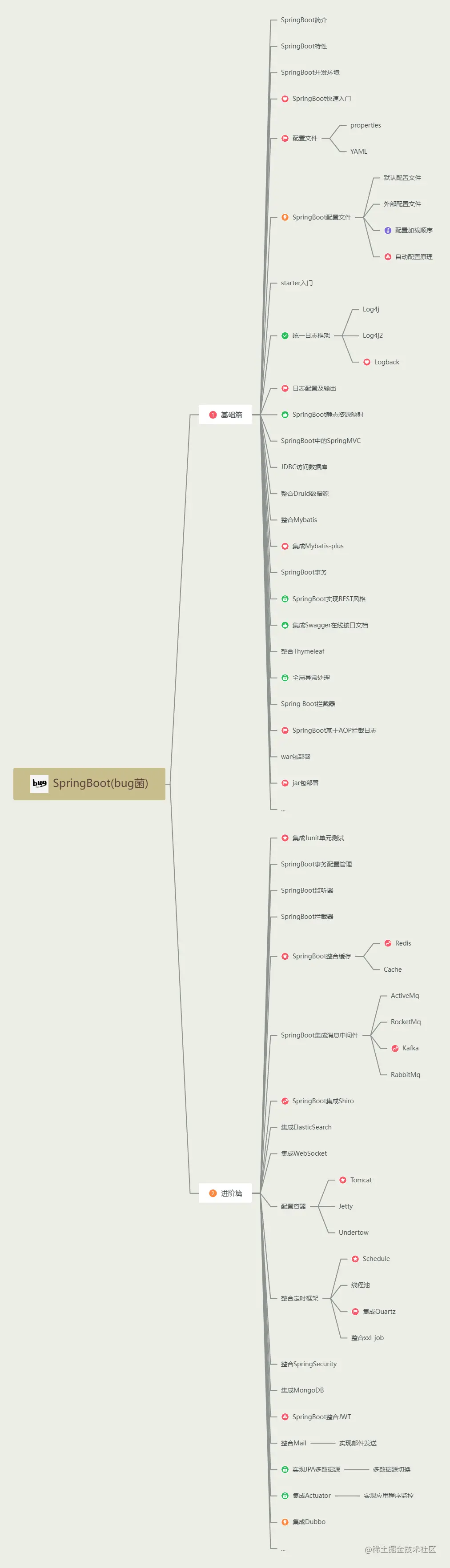
Последний выпуск 2023 года, самое полное руководство по обучению Spring Boot во всей сети (с интеллект-картой).
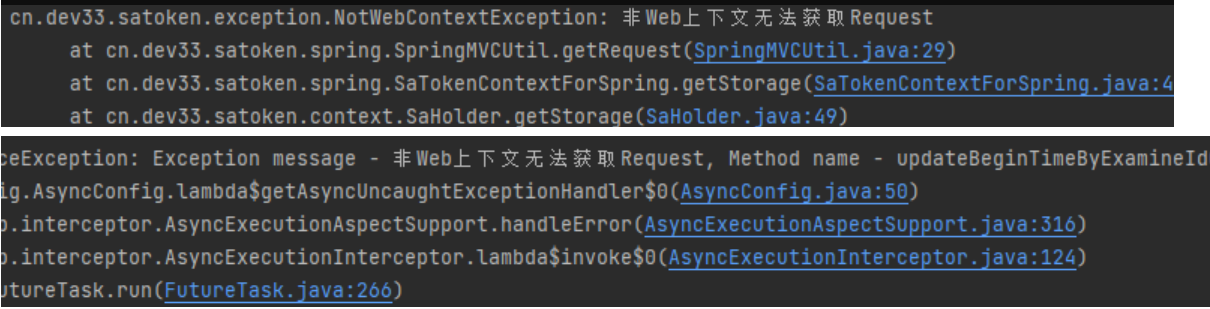
[Решено — Практическая работа] SaTokenException: запрос не может быть получен в контексте, отличном от Интернета. Решение проблем — Практическая работа.

HikariPool-1 - Connection is not available, request timed out after 30000ms
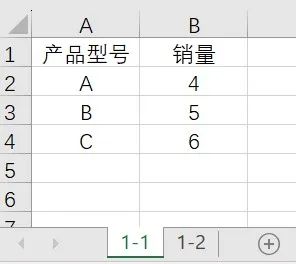
Power Query: автоматическое суммирование ежемесячных данных с обновлением одним щелчком мыши.
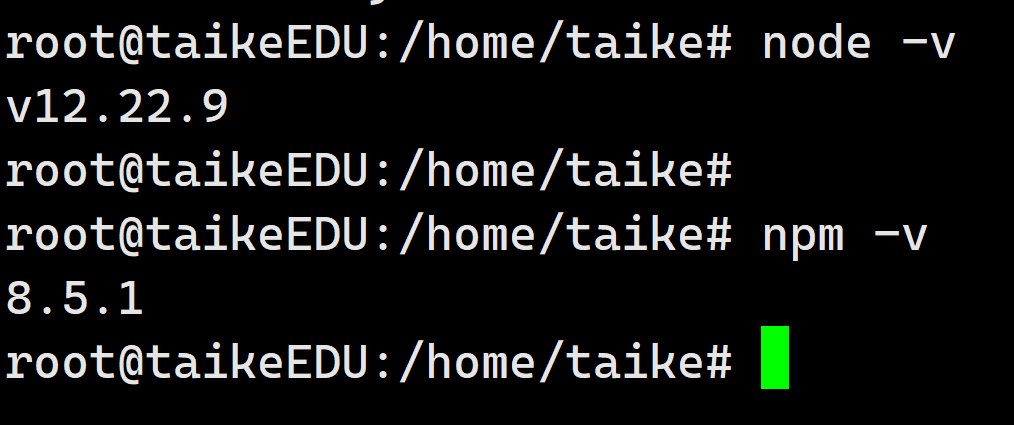
установка Ubuntu в среде npm
