Большое обновление! ! ! Могу ли я запустить SDXL с 4G видеопамяти? SD1.7 может объединиться с оптимизацией F8
Экология SDXL еще не полностью стабильна, но следует отметить огромное улучшение SDXL в трех основных компонентах: VAE, CLIP и UNET. Его 10,1 миллиарда параметров в N раз больше, чем у исходного SD. экология SDXL Введение повторяем еще раз. 4G видеопамяти может работать с SDXL, а это означает, что размер большой модели Lora в будущем будет уменьшен, и давление на алхимическую печь будет меньше ~
Почему SDXL силен?
0,1 Объем обучения параметров составляет 10,1 миллиарда, в том числе 3,5 миллиарда для модели BASE и 6,6 миллиарда для модели REFINER, что в 8 раз превышает SD? ? ?
В версии 0.2 внесены улучшения в исходную U-Net от Stable Diffusion (всего XL Base U-Net имеет 14 модулей), VAE и текстовый кодировщик CLIP. Может значительно сократить использование видеопамяти и объем вычислений.
В версии 0.3 добавлена отдельная модель Refiner на основе скрытых данных для улучшения детализации изображения. [Новое: Уточнение скрытых особенностей изображения, созданного базовой моделью, что, по сути, представляет собой работу по созданию изображения из изображения. 】
В версии 0.4 разработано множество приемов обучения (эти приемы обладают хорошей универсальностью и переносимостью и могут принести пользу другим генеративным моделям), включая стратегии определения размера изображения, согласование параметров обрезки изображения, многомасштабное обучение и т. д.
0.5 сначала выпустит тестовую версию Stable Diffusion XL 0.9. Основываясь на опыте пользователей и созданных изображениях, официальная версия Stable Diffusion XL 1.0 будет запускаться итеративно путем увеличения набора данных и использования технологии RLHF для его оптимизации.
Метод выборки 0.6 отключает DDIM (зарезервировано, а не абсолютно) и не требует включения CN. При поддержке CN можно включить версию XL CN. Все экологические потребности — это экология XL
0,7 Непосредственный вывод изображений с разрешением 1024, начиная с 1024*1024.

При этом идет занятость большой видеопамяти, но с предложенным новым PR его можно протестировать на видеопамяти 4G и решить при определенном занятии памяти! ! !
A big improvement for dtype casting system with fp8
storage type and manual castБольшое улучшение памяти FP8 и ручного преобразования.
После pytorch 2.1.0 в pytorch добавлены 2 новых типа данных в качестве типов хранения: float8_e5m2, float8_e4m3fn. [1][2] На основе статьи, в которой обсуждается использование fp8 в качестве параметра/градиента для обучения/использования моделей NN. Думаю стоит провести оптимизацию под формат fp8. [3][4] Кроме того, некоторые расширения уже поддерживают эту функцию[5].
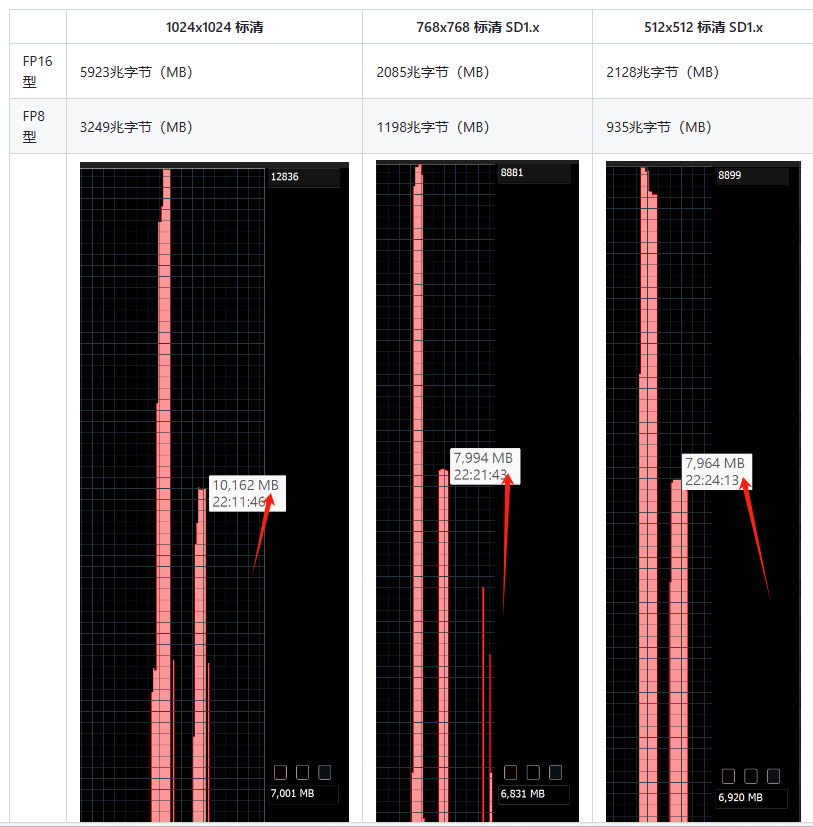
увеличение скорости
Поскольку FP8 используется с FP16, для расчета требуются некоторые дополнительные операции по приведению dtype. Это будет замедляться (особенно для небольших партий)
размер партии | 768x768 SD 1.x fp16 | 768x768 SD 1.x fp8 | 1024x1024 SDXL fp16 | 1024x1024 SDXL fp8 |
|---|---|---|---|---|
1 | 8,27 секунды/секунду | 7,85 секунды/секунду | 3,84 секунды/секунду | 3,67 секунды/секунду |
4 | 3,19 секунды/секунду | 3,08 секунды/секунду | 1,51 секунды/секунду | 1,45 секунды/секунду |
Снизит ли это качество? Почти никогда

Что такое ФП8 FP16?
Fp16: означает, что модель хранится с 16-битными числами с плавающей запятой, что меньше и быстрее, чем Fp32, но не может использоваться в ЦП, поскольку некоторые операции с точностью до половины плавающей запятой не поддерживаются ЦП. Обычно для более быстрых вычислений мы также конвертируем Fp32 в Fp16 на графическом процессоре. Это можно настроить в настройках. Тогда следующие параметры составляют 8 байт, FP32 — 4 байта, FP8 — один байт, FP или BF16 имеют относительно хорошее качество изображения.
Следующие результаты теста предоставлены автором оригинального PR Эмбер Аоба. Если вы хотите попробовать, просто включите этот PR в исходный код.
Прежде всего, в SD1 FP16 сохраняется на уровне 2G. В SDXL, поскольку параметров больше, FP16 также нуждается в 5G, поэтому многие видеокарты не могут его удержать. Поэтому Qingye что-то сделал: использовал FP8 для помещения его в видеопамять при загрузке, чтобы SDXL, хранящийся в видеопамяти, составлял 2,5 ГБ. Однако соответствующий FP8 преобразуется в FP16 на каждом уровне расчета, поэтому весь процесс расчета выглядит последовательным. В то же время сокращается использование памяти всем процессом.

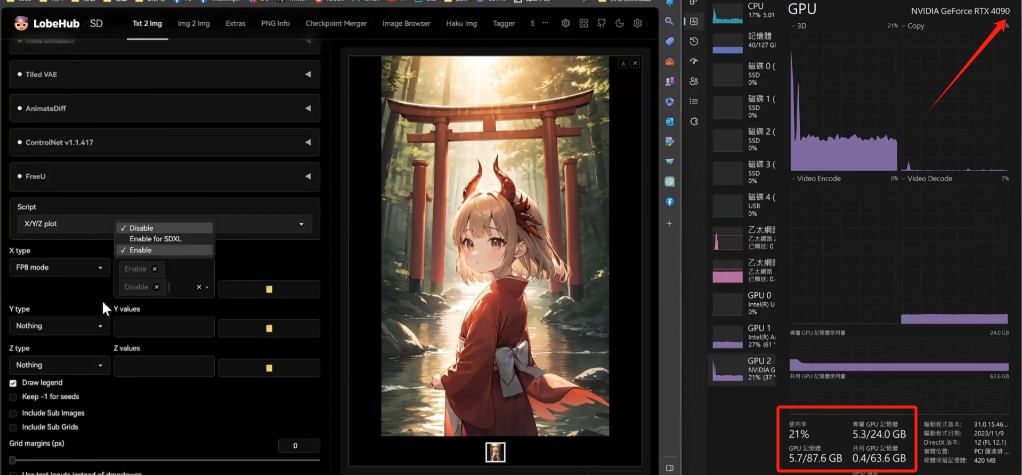
Обычный тест запуска
Включите FP8 и включите оптимизацию кэша памяти.
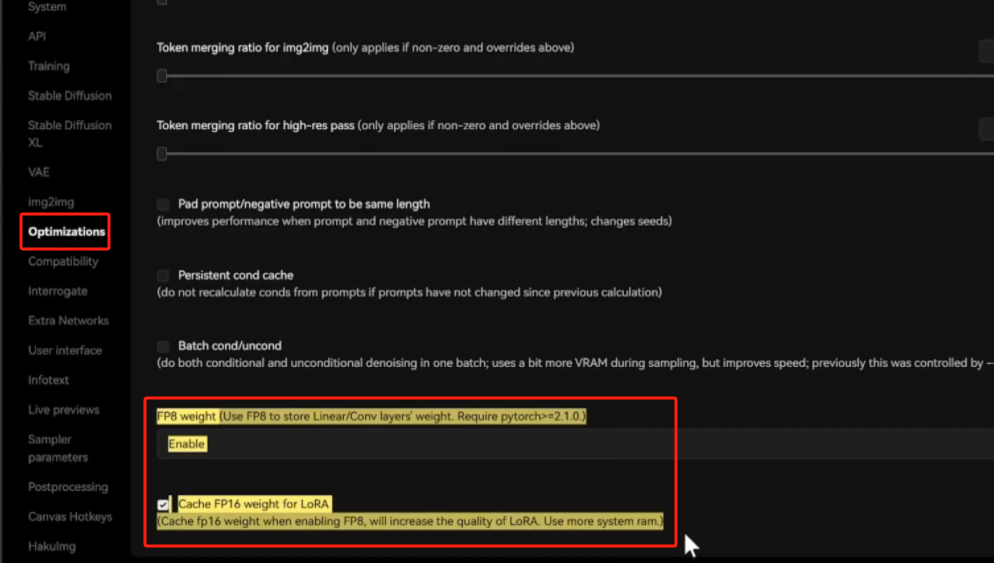
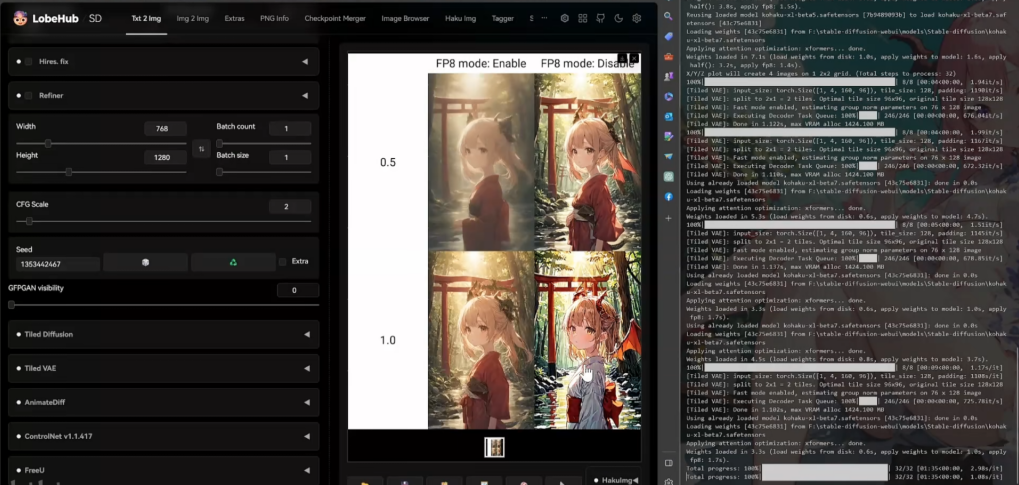
Сравнение до и после отключения теста XYZ
Первоначальный объем статической памяти составлял 5,3.
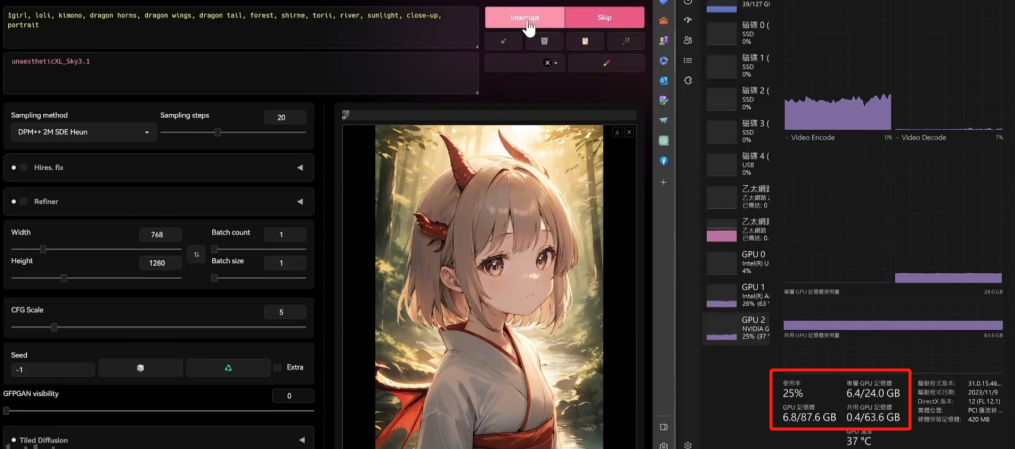
После запуска стабилизировалось на отметке 6,4.
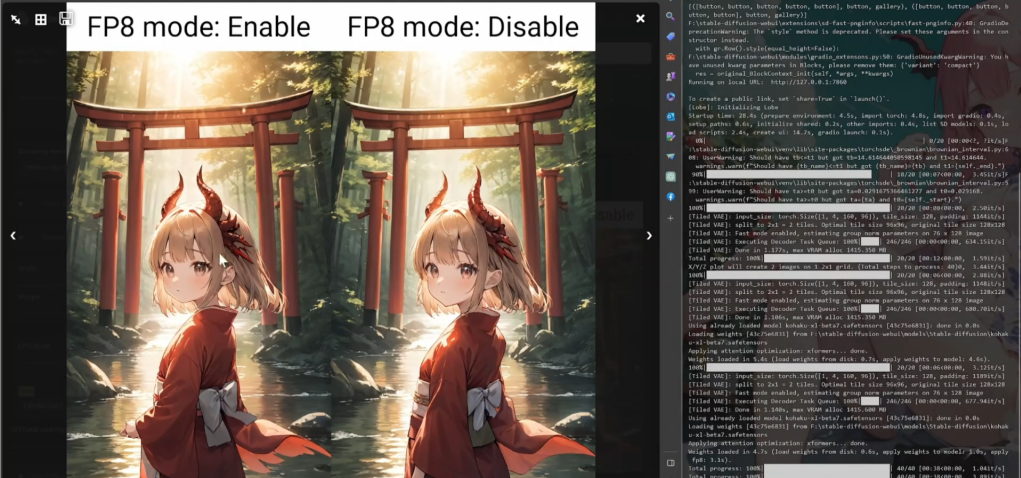
На прямое соединение изображений до и после включения влияние незначительное, есть небольшие различия в деталях.
Тест с LCM
Все PR-обзоры пройдены, либо официальная версия будет запущена в 1.7 после тестирования.
Многие коллекции искусственного интеллекта были организованы по адресу https://yv4kfv1n3j.feishu.cn/docx/MRyxdaqz8ow5RjxyL1ucrvOYnnH.

Роман по адресу видео: https://kkget.jeff1992.com/



Учебное пособие по Jetpack Compose для начинающих, базовые элементы управления и макет

Код js веб-страницы, фон частицы, код спецэффектов

【новый! Суперподробное】Полное руководство по свойствам компонентов Figma.

🎉Обязательно к прочтению новичкам: полное руководство по написанию мини-программ WeChat с использованием программного обеспечения Cursor.

[Забавный проект Docker] VoceChat — еще одно приложение для мгновенного чата (IM)! Может быть встроен в любую веб-страницу!

Как реализовать переход по странице в HTML (html переходит на указанную страницу)

Как решить проблему зависания и низкой скорости при установке зависимостей с помощью npm. Существуют ли доступные источники npm, которые могут решить эту проблему?

Серия From Zero to Fun: Uni-App WeChat Payment Practice WeChat авторизует вход в систему и украшает страницу заказа, создает интерфейс заказа и инициирует запрос заказа

Серия uni-app: uni.navigateЧтобы передать скачок значения

Апплет WeChat настраивает верхнюю панель навигации и адаптируется к различным моделям.

JS-время конвертации

Обеспечьте бесперебойную работу ChromeDriver 125: советы по решению проблемы chromedriver.exe не найдены

Поле комментария, щелчок мышью, специальные эффекты, js-код

Объект массива перемещения объекта JS

Как открыть разрешение на позиционирование апплета WeChat_Как использовать WeChat для определения местонахождения друзей

Я даю вам два набора из 18 простых в использовании фонов холста Power BI, так что вам больше не придется возиться с цветами!

Получить текущее время в js_Как динамически отображать дату и время в js

Вам необходимо изучить сочетания клавиш vsCode для форматирования и организации кода, чтобы вам больше не приходилось настраивать формат вручную.

У ChatGPT большое обновление. Всего за 45 минут пресс-конференция показывает, что OpenAI сделал еще один шаг вперед.

Copilot облачной разработки — упрощение разработки

Микросборка xChatGPT с низким кодом, создание апплета чат-бота с искусственным интеллектом за пять шагов

CUDA Out of Memory: идеальное решение проблемы нехватки памяти CUDA

Анализ кластеризации отдельных ячеек, который должен освоить каждый&MarkerгенетическийВизуализация

vLLM: мощный инструмент для ускорения вывода ИИ

CodeGeeX: мощный инструмент генерации кода искусственного интеллекта, который можно использовать бесплатно в дополнение к второму пилоту.

Машинное обучение Реальный бой LightGBM + настройка параметров случайного поиска: точность 96,67%

Бесшовная интеграция, мгновенный интеллект [1]: платформа больших моделей Dify-LLM, интеграция без кодирования и встраивание в сторонние системы, более 42 тысяч звезд, чтобы стать свидетелями эксклюзивных интеллектуальных решений.

LM Studio для создания локальных больших моделей

Как определить количество слоев и нейронов скрытых слоев нейронной сети?
