Большие данные: введение в Trino и решения для сценариев ETL
Введение
Первоначально Presto был создан в Facebook, чтобы заполнить пробел между запросами в реальном времени и обработкой ETL в Facebook в то время. Основная цель Presto — предоставление интерактивных запросов, которые мы часто называем специальными запросами. Многие компании используют его в качестве механизма вычислений OLAP. Однако, поскольку в последние годы бизнес-сценарии становятся все более и более сложными, в дополнение к сценариям интерактивных запросов многим компаниям также требуется пакетная обработка, однако Presto, как вычислительный механизм MPP, использует базу данных архитектуры MPP для обработки больших объемов данных; наборы данных. Это очень сложная проблема, поэтому общий подход заключается в написании адаптера во внешнем интерфейсе для предварительной обработки SQL. Если это мгновенный запрос, используйте Presto, в противном случае используйте Spark. Эта обработка может в определенной степени решить нашу проблему, но два вычислительных механизма и предыдущая предварительная обработка SQL значительно увеличивают сложность нашей системы.
Чтобы решить эту проблему, PrestoDB запустила такие проекты, как Presto Unlimited и Presto on Spark. О них можно узнать в статьях Presto on Spark: поддержка мгновенных запросов и пакетной обработки и Presto on Spark: расширение Presto. Детали Искры. Сегодня мы поговорим о дороге ETL Trino (PrestoSQL), еще одной ветки Presto. В течение последних шести месяцев сообщество Trino разрабатывало поддержку ETL под кодовым названием Tardigrade, модифицируя код Trino для поддержки ETL.
Что такое проект Тихоходка
Что людям нравится в использовании Trino, так это то, что он быстро выполняет запросы и может решать бизнес-задачи с помощью интуитивно понятных сообщений об ошибках, интерактивного взаимодействия и объединенных запросов. Большой давней проблемой является то, что Trino очень сложно настраивать, настраивать и управлять им для длительных рабочих нагрузок ETL. Вот некоторые проблемы, с которыми вам придется столкнуться:
- Надежное время выполнения. Запросы, которые выполняются часами, могут завершиться неудачей, а их перезапуск с нуля приводит к потере ресурсов и усложняет соблюдение требований ко времени выполнения.
- Экономичный изкластер: для выполнения запроса нам нужен кластер распределенной памяти уровня TB Trino;
- Параллелизм: несколько независимых клиентов могут отправлять запросы одновременно. Некоторые из этих запросов, возможно, придется прекратить и перезапустить через определенный период времени из-за нехватки доступных ресурсов в какой-то момент, что делает время завершения задания более непредсказуемым.
Чтобы решить вышеуказанные проблемы, нам может потребоваться помощь команды экспертов, но для большинства пользователей это невозможно. Цель проекта Tardigrade — предоставить «нестандартное» решение вышеуказанных проблем. Сообщество разработало новую отказоустойчивую архитектуру выполнения, которая позволяет нам реализовать расширенное планирование с учетом ресурсов и детализированные повторные попытки. Вот результаты проекта Tardigrade:
- Когда при длительно выполняющихся запросах возникают сбои, нам не нужно запускать их заново.
- Когда запросам требуется больше памяти, чем доступно в данный момент в кластере, они все равно могут успешно выполняться;
- Когда одновременно отправляется несколько запросов, они могут справедливо распределять ресурсы и работать стабильно.
Trino выполняет всю тяжелую работу за кулисами по распределению, настройке и поддержке обработки запросов. Вместо того, чтобы тратить время на настройку кластера Trino в соответствии с потребностями нашей рабочей нагрузки или реорганизацию рабочей нагрузки в соответствии с возможностями нашего кластера Trino, мы можем потратить время на анализ и предоставление бизнес-ценности.
Tardigrade проектпринцип Введение
Trino — это вычислительная машина без сохранения состояния, поэтому для реализации ETL требуется множество модификаций Trino. С точки зрения реализации между Trino и PrestoDB есть некоторые различия. Чтобы поддерживать как ETL, так и запросы в реальном времени, PrestoDB на ранней стадии разработал проект под кодовым названием Presto Unlimited. Он в основном делил таблицу на сегменты. данные в каждом сегменте были независимыми, поэтому их можно вычислить независимо, если вычисление данных одного сегмента не удалось, просто повторите вычисление, связанное с данными сегмента. Эту часть принципа можно найти в разделе Presto в Spark: Поддержка. мгновенный запрос и пакетная обработка, а также Presto в Spark: пройти Spark для расширения Presto и других статей. Хотя Presto Unlimited решает некоторые проблемы, он не решает полностью проблему отказоустойчивости и не улучшает изоляцию и управление ресурсами. Для реализации этих функций, несомненно, потребуется множество модификаций Presto, и эти задачи на самом деле реализованы аналогичным образом в других движках (таких как Spark, Flink и другие вычислительные движки), а затем реализовать их в Presto — это немного заново изобрести велосипед; PrestoDB Сообщество представило Presto в Spark, который представляет собой интеграцию Presto и Spark. Он использует компилятор/оценку Presto в качестве библиотеки классов и использует RDD API Spark для управления встроенной оценкой Presto. реализация аналогична тому, как Google решил встроить запрос F1 в свою структуру MapReduce.
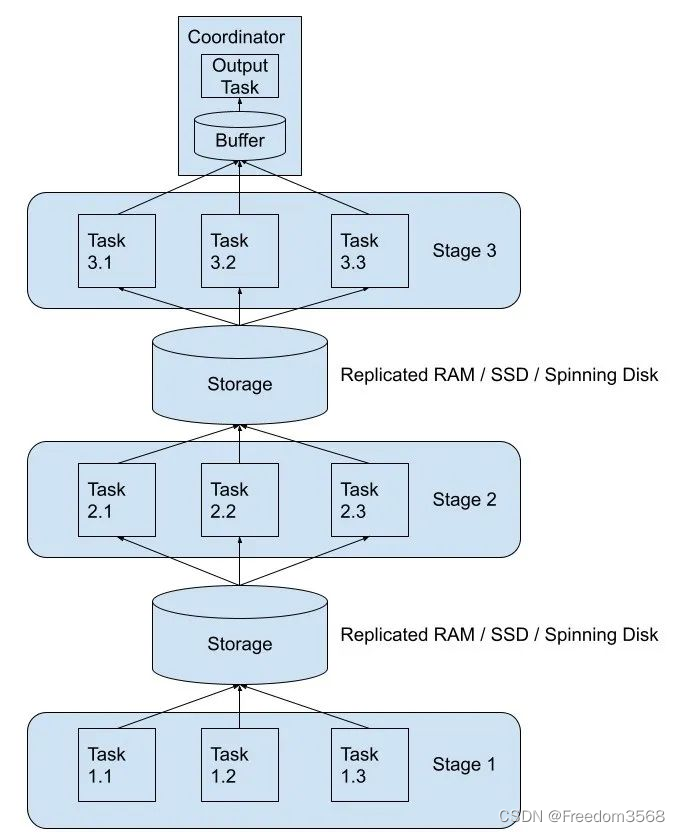
Но, глядя на Trino, идея его реализации отличается от описанной выше. Tardigrade Trino, похоже, реализует основные функции, такие как отказоустойчивость, повтор запроса/задачи и перемешивание непосредственно в Trino. Trino записывает данные восходящего этапа в случайном порядке на диск. Это поддерживает запись данных в AWS A3, Google Cloud Storage, Azure Blob Storage и локальное хранилище файлов (это для тестирования). .



Углубленный анализ переполнения памяти CUDA: OutOfMemoryError: CUDA не хватает памяти. Попыталась выделить 3,21 Ги Б (GPU 0; всего 8,00 Ги Б).

[Решено] ошибка установки conda. Среда решения: не удалось выполнить первоначальное зависание. Повторная попытка с помощью файла (графическое руководство).

Прочитайте нейросетевую модель Трансформера в одной статье

.ART Теплые зимние предложения уже открыты

Сравнительная таблица описания кодов ошибок Amap

Уведомление о последних правилах Points Mall в декабре 2022 года.

Даже новички могут быстро приступить к работе с легким сервером приложений.

Взгляд на RSAC 2024|Защита конфиденциальности в эпоху больших моделей

Вы используете ИИ каждый день и до сих пор не знаете, как ИИ дает обратную связь? Одна статья для понимания реализации в коде Python общих функций потерь генеративных моделей + анализ принципов расчета.

Используйте (внутренний) почтовый ящик для образовательных учреждений, чтобы использовать Microsoft Family Bucket (1T дискового пространства на одном диске и версию Office 365 для образовательных учреждений)

Руководство по началу работы с оперативным проектом (7) Практическое сочетание оперативного письма — оперативного письма на основе интеллектуальной системы вопросов и ответов службы поддержки клиентов

[docker] Версия сервера «Чтение 3» — создайте свою собственную программу чтения веб-текста

Обзор Cloud-init и этапы создания в рамках PVE

Корпоративные пользователи используют пакет регистрационных ресурсов для регистрации ICP для веб-сайта и активации оплаты WeChat H5 (с кодом платежного узла версии API V3)

Подробное объяснение таких показателей производительности с высоким уровнем параллелизма, как QPS, TPS, RT и пропускная способность.

Удачи в конкурсе Python Essay Challenge, станьте первым, кто испытает новую функцию сообщества [Запускать блоки кода онлайн] и выиграйте множество изысканных подарков!

[Техническая посадка травы] Кровавая рвота и отделка позволяют вам необычным образом ощипывать гусиные перья! Не распространяйте информацию! ! !

[Официальное ограниченное по времени мероприятие] Сейчас ноябрь, напишите и получите приз

Прочтите это в одной статье: Учебник для няни по созданию сервера Huanshou Parlu на базе CVM-сервера.

Cloud Native | Что такое CRD (настраиваемые определения ресурсов) в K8s?

Как использовать Cloudflare CDN для настройки узла (CF самостоятельно выбирает IP) Гонконг, Китай/Азия узел/сводка и рекомендации внутреннего высокоскоростного IP-сегмента

Дополнительные правила вознаграждения амбассадоров акции в марте 2023 г.

Можно ли открыть частный сервер Phantom Beast Palu одним щелчком мыши? Супер простой урок для начинающих! (Прилагается метод обновления сервера)

[Играйте с Phantom Beast Palu] Обновите игровой сервер Phantom Beast Pallu одним щелчком мыши

Maotouhu делится: последний доступный внутри страны адрес склада исходного образа Docker 2024 года (обновлено 1 декабря)

Кодирование Base64 в MultipartFile

5 точек расширения SpringBoot, супер практично!

Глубокое понимание сопоставления индексов Elasticsearch.

15 рекомендуемых платформ разработки с нулевым кодом корпоративного уровня. Всегда найдется та, которая вам понравится.
