Больше, чем просто понимание: как ИИ меняет интерпретацию видео?
С тех пор, как Сора взорвал область генерации видео, исследования и применения в мультимодальных областях, таких как видео, достигли значительного прогресса, и это стало будущей тенденцией развития больших моделей искусственного интеллекта.

С другой стороны, создание видеороликов с использованием ИИ также требует, чтобы ИИ мог понимать контент в видео, чтобы он мог эффективно генерировать результаты для различного контента. Таким образом, понимание видео ИИ стало еще одной важной областью, подобной умному мозгу, анализирующему тайны визуального мира.
В этой статье в основном представлены две важные модели понимания видео, а именно GPT4Video и MiniGPT4-Video.
GPT4Video
Первая модель называется моделью GPT4Video, которая обучена Tencent AI LAB на основе большой модели. Она имеет два основных преимущества:
1) Он демонстрирует впечатляющие возможности как в понимании видео, так и в создании сцен. Например, GPT4Video превосходит Valley на 11,8% в задаче видеоответов на вопросы и на 2,3% превосходит NExt-GPT в задаче преобразования текста в видео.
2) Расширение возможностей LLM/MLLM для создания видео без необходимости дополнительных параметров обучения и возможность гибкого подключения к нескольким моделям для создания видео.
Отображение эффектов
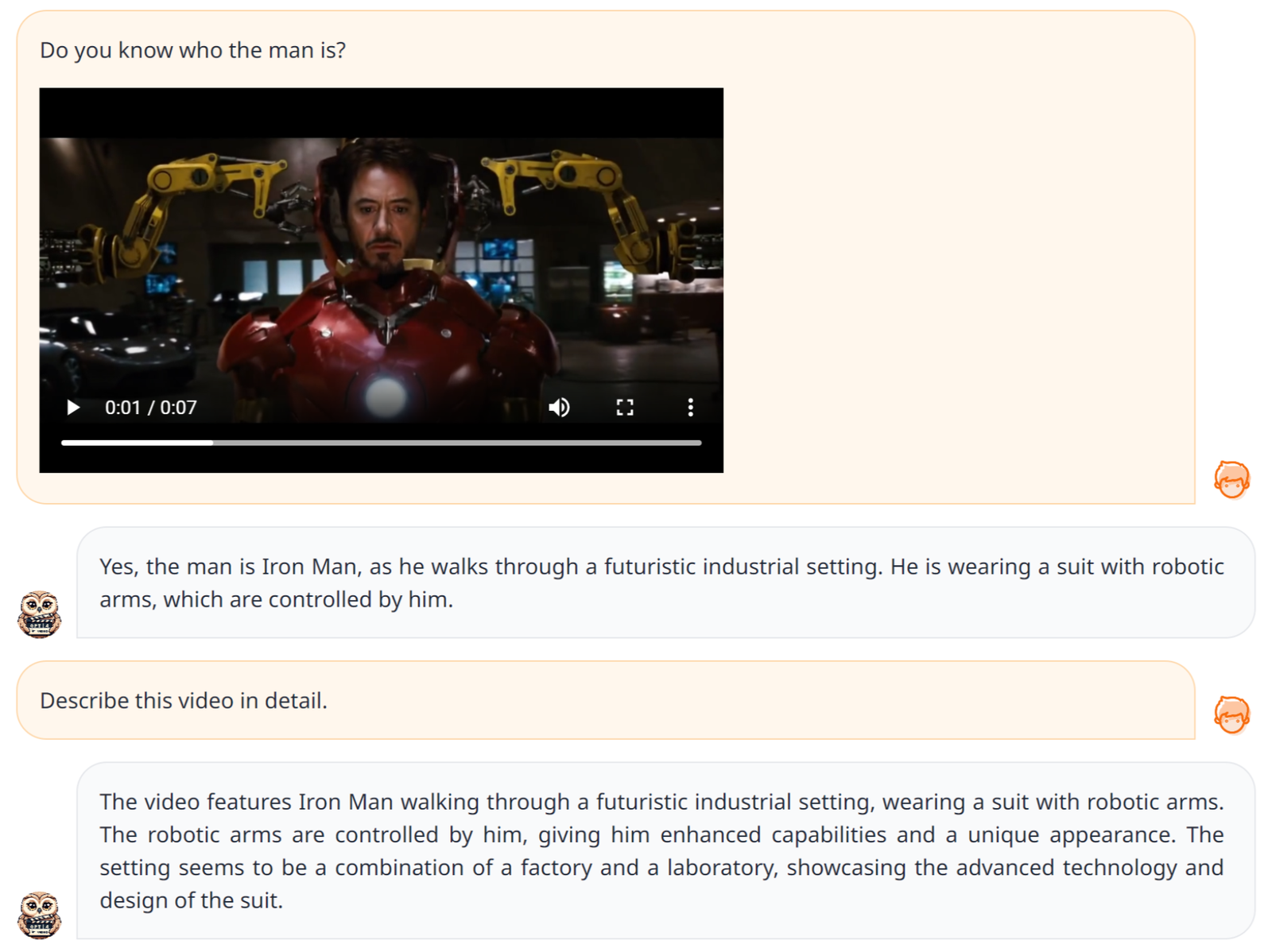
Загрузите видео с Железным Человеком и пусть оно описывает содержание видео:
AI: В видео Железный Человек носит костюм с роботизированными руками и идет по индустриальной среде будущего. Он управляет роботизированными руками, что придает ему расширенные способности и уникальный внешний вид. Окружающая среда выглядит как смесь фабрики и лаборатории, демонстрируя передовые технологии и дизайн костюма.
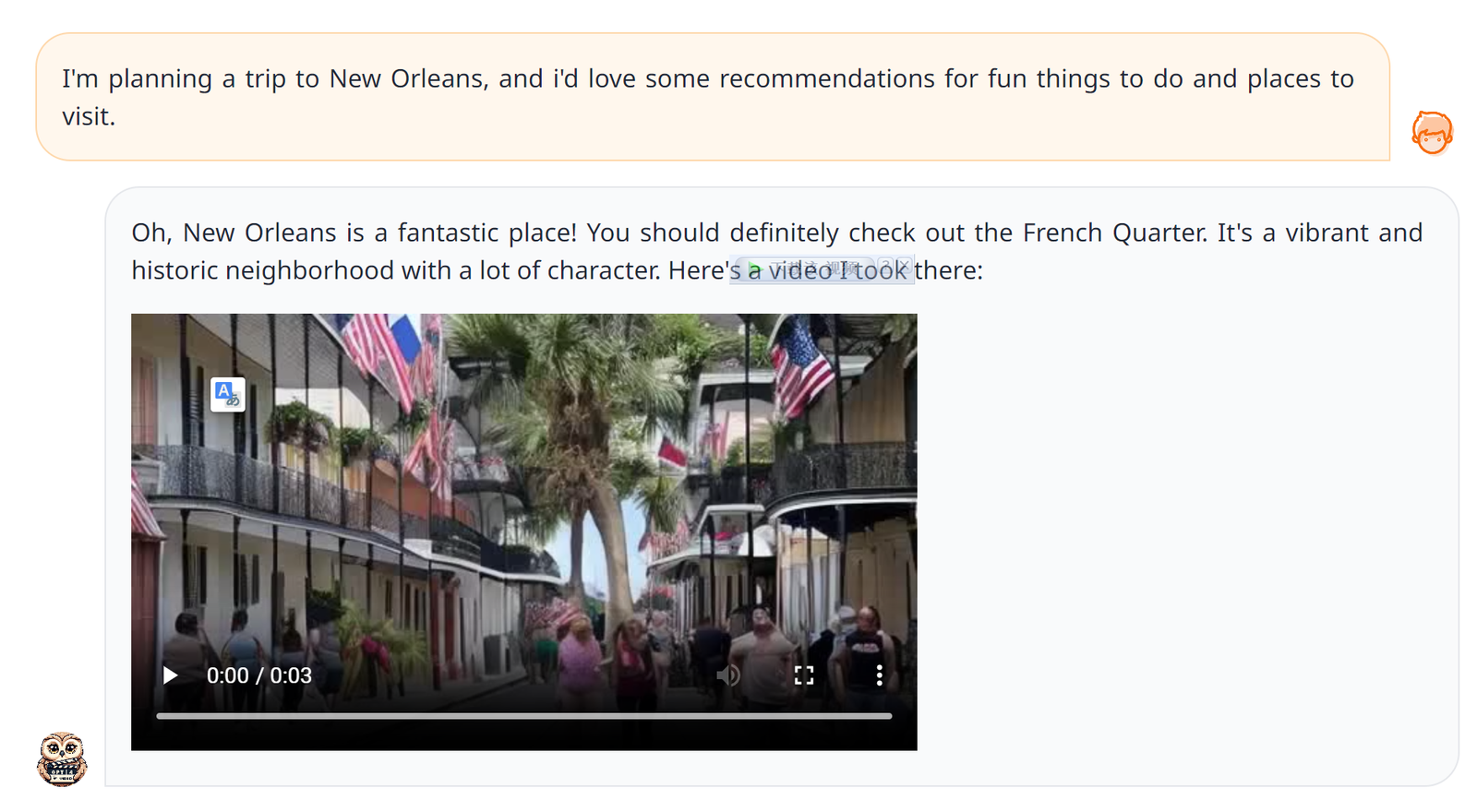
Если во время путешествия вам нужны планы поездок, вы можете напрямую позволить ему создавать соответствующие видео:
Новый Орлеан – такое прекрасное место! Вам обязательно стоит заглянуть во Французский квартал. Это яркий, исторический и характерный район. Вот видео, которое я там снял:
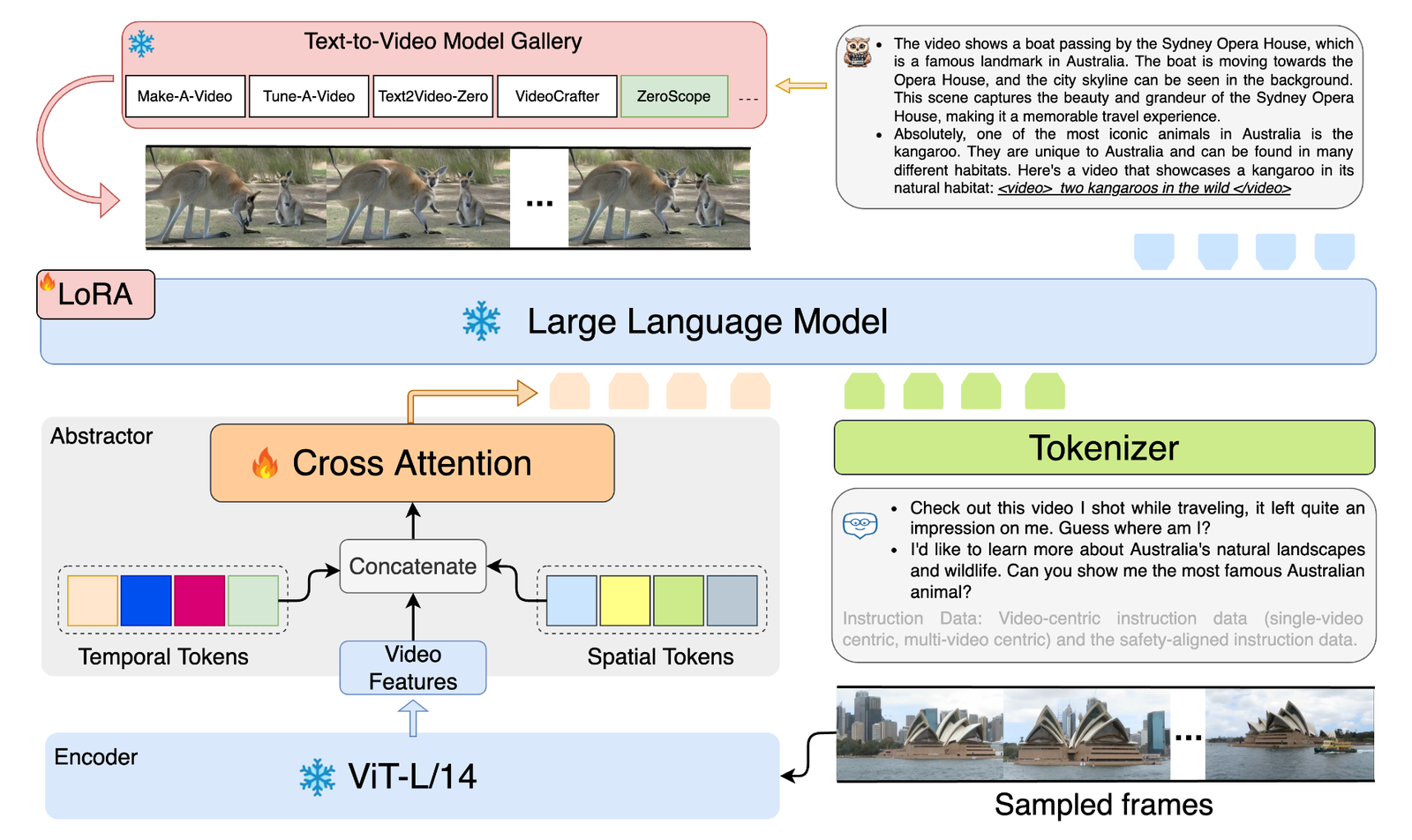
технические детали
Модель в основном состоит из трех различных модулей:
- Этап кодирования видео: модуль кодирования видео использует замороженную модель ViT-L/14 для захвата исходных функций видео.
- Вывод LLM для большой модели. Ядро GPT4Video основано на замороженной модели LLaMA и эффективно настроено с помощью LoRA. LLM обучается с использованием пользовательских видеоориентированных и надежно согласованных данных, что позволяет ему понимать видео и генерировать соответствующие видеоподсказки.
- Генерация видео. Подсказки, сгенерированные LLM, затем используются в качестве текстового ввода в галерее моделей преобразования текста в видео и могут быть сгенерированы напрямую без тонкой настройки.
Модель MiniGPT4-Видео
Вторая модель позволяет развернуть ее самостоятельно и получить бесплатно. В то же время он достиг последних результатов в понимании видео с помощью искусственного интеллекта.
локальное развертывание
В репозитории github minigpt4-video приведены подробные инструкции по развертыванию:
- Клонировать код репозитория
git clone https://github.com/Vision-CAIR/MiniGPT4-video.git
cd MiniGPT4-video- Установите и активируйте среду
conda env create -f environment.yml- Запустить код
# Llama2
python minigpt4_video_demo.py --ckpt path_to_video_checkpoint --cfg-path test_configs/llama2_test_config.yaml
# Mistral
python minigpt4_video_demo.py --ckpt path_to_video_checkpoint --cfg-path test_configs/mistral_test_config.yamlОтображение эффектов
Официальный представитель развернул соответствующую демонстрацию кода. Если вам интересно, вы можете попробовать:
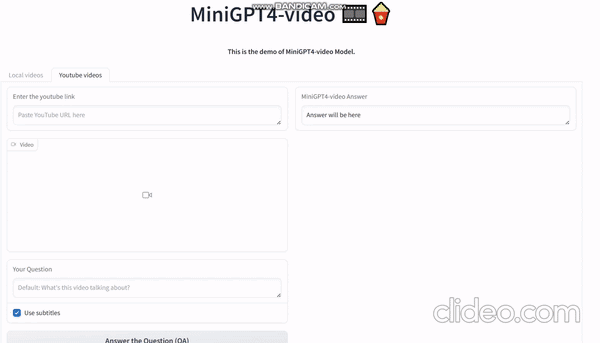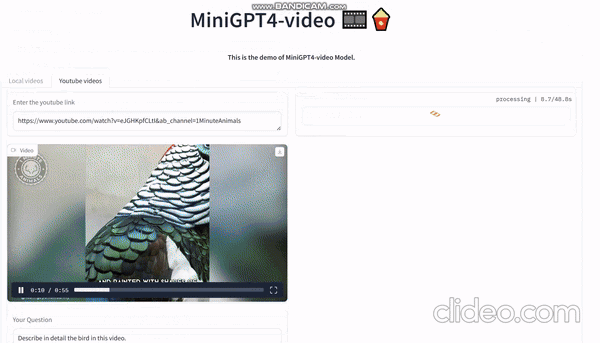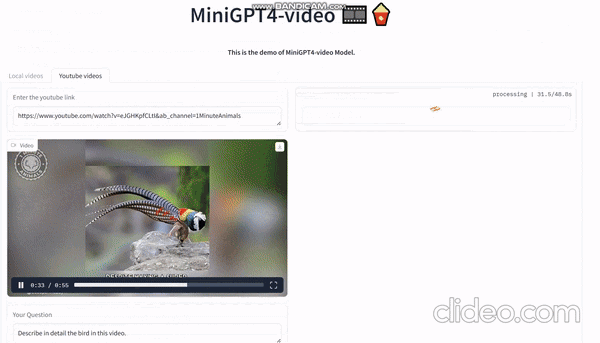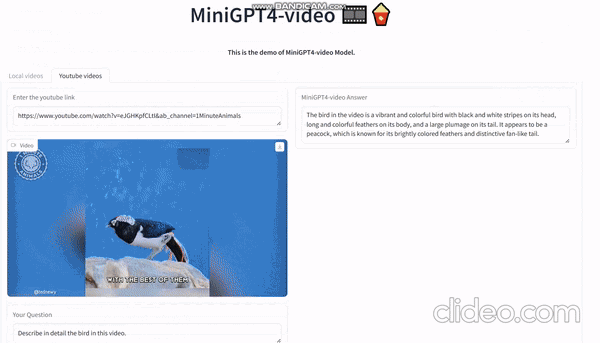
Судя по официальной демонстрации, вы можете напрямую ввести любое видео на YouTube, а затем попросить его описать видео. Он может описывать содержимое экрана на основе видео:
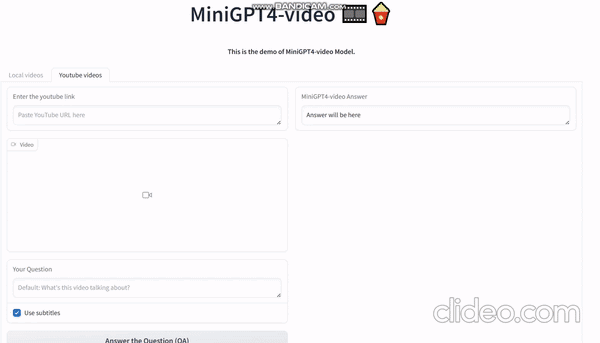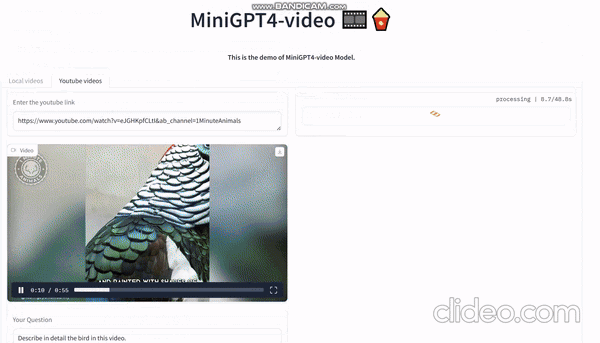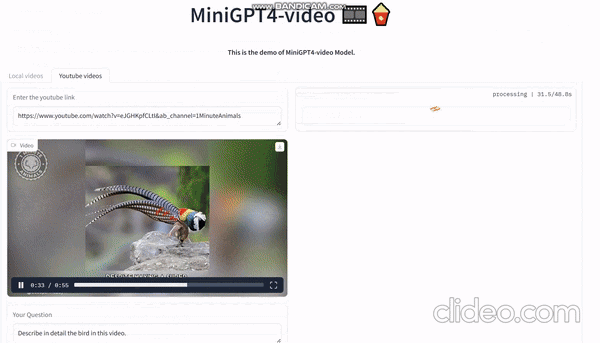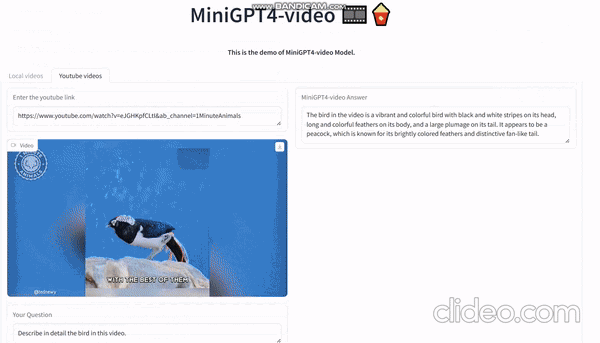
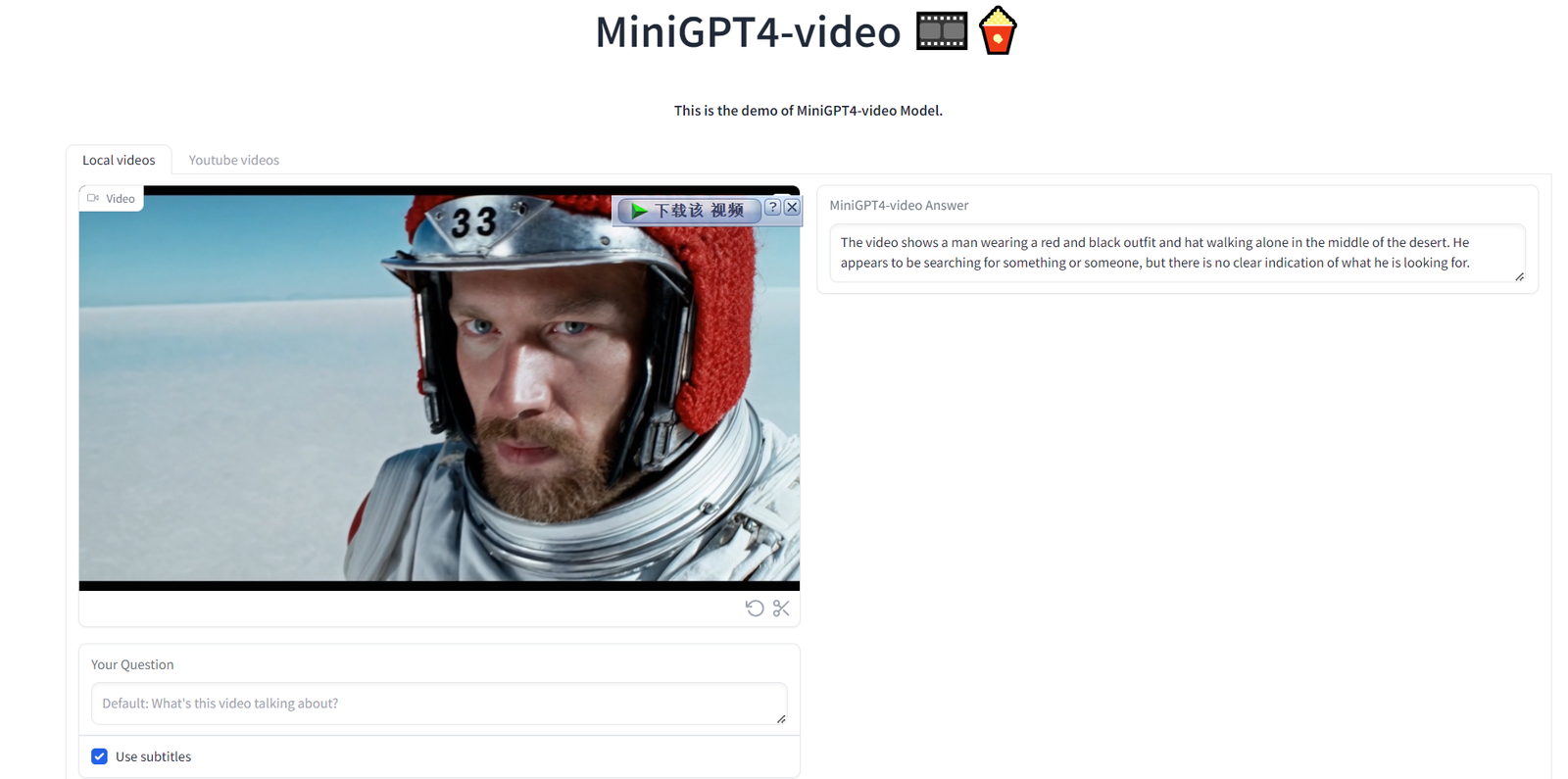
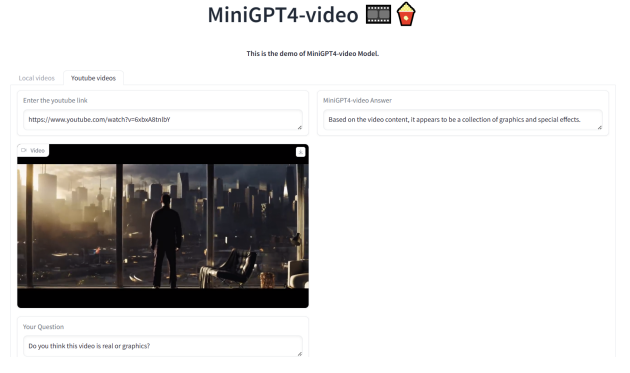
Видео, сгенерированное sora, загружено сюда и дайте ему разобрать:
На видео видно, как мужчина в красно-черной одежде и шляпе идет один посреди пустыни. Он как будто ищет что-то или кого-то, но нет четкого указания на то, что он ищет.
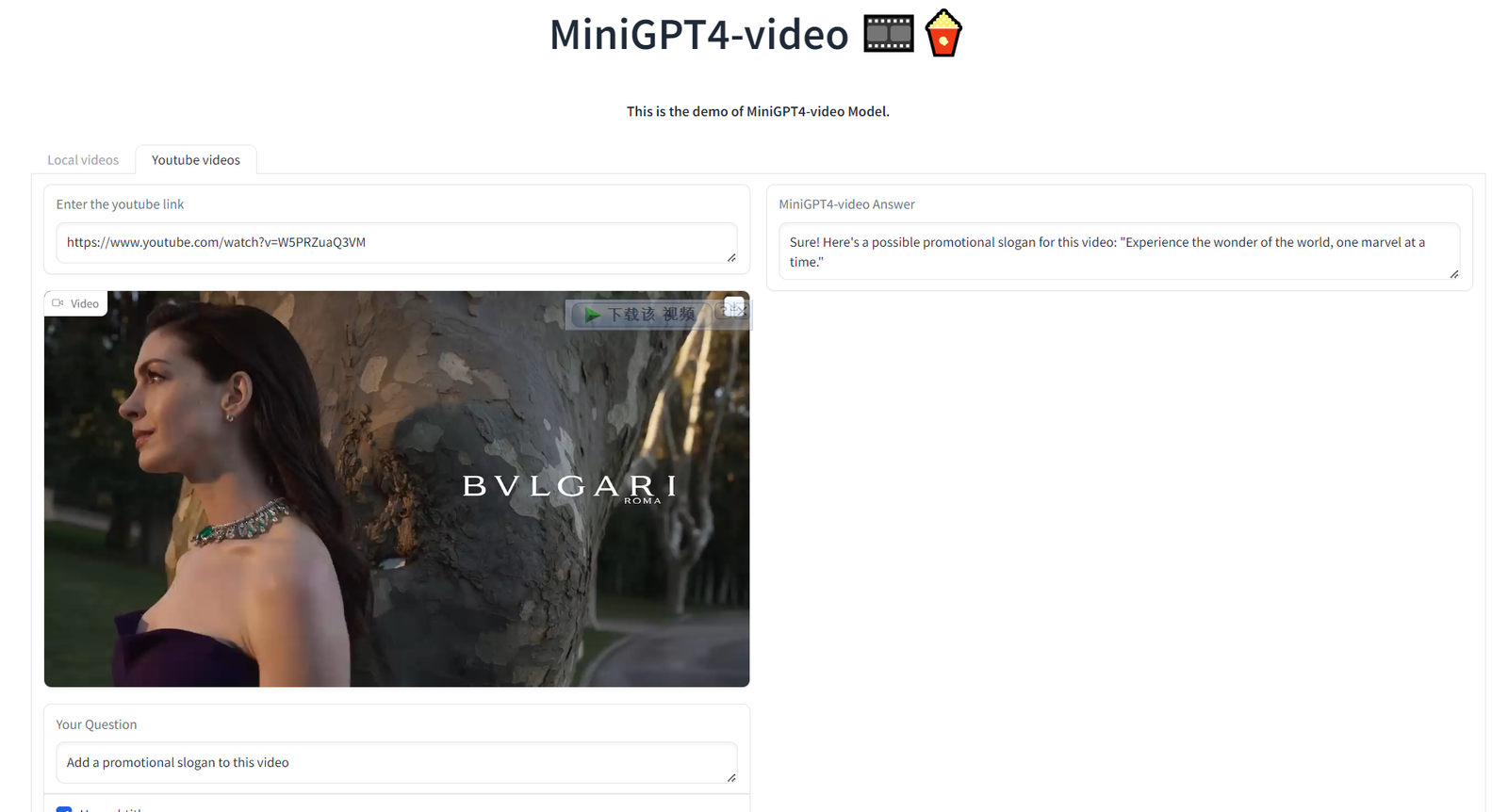
Мы также можем загрузить видео Bulgari и позволить ИИ помочь нам подобрать заголовок или слоган, что действительно выглядит немного блефом.
Испытайте чудеса света, одно чудо за раз.
Даже некоторые технологии, использованные в видео, можно узнать:
Судя по содержанию видео, оно представляет собой набор графики и спецэффектов.
С точки зрения представления рекламного креатива, по сравнению с VideoChatGPT, рекламные слоганы, генерируемые MiniGPT4-Video, более детальны, а контент гораздо ярче:
Название: Солнце светит тебе в лицо Сцена: Красивый пляж и человек со светлой кожей. Появилась бутылка мольстюнера, и человек нанес ее на кожу, и она почувствовала прохладу и освежающее ощущение, подчеркивая название продукта и ключевые ингредиенты.....

технические детали
Краткое описание некоторых методов модели:
- MiniGPT4-Video основан на MiniGPT-v2, который отлично справляется с преобразованием визуальных функций в пространство LLM для отдельных изображений и достигает хороших результатов в различных тестах изображения и текста.
- Модель объединяет каждые четыре соседних визуальных токена в один, чтобы уменьшить потерю информации, а также включает субтитры, что улучшает способность модели понимать видеоконтент.
Метод обучения:
- Используйте крупномасштабное предварительное обучение пары изображение-текст и предварительное обучение пары видео-текст, которые используются для адаптации модели к видеоконтенту.
- Модель использует линейный слой на этапе предварительного обучения для сопоставления визуальных функций с текстовым пространством LLM, а также использует визуальный кодировщик EVA-CLIP и технологию LoRA для детальной настройки.
В частности, обучение состоит из трех этапов:
- Предварительное обучение выравниванию изображения и текста. Первым шагом является использование модели EVA-Clip для предварительного обучения, чтобы позволить модели понять изображение и соответствующее ему описание.
- Предварительная тренировка выравнивания видеотекста. Поскольку видео представляет собой объединение нескольких кадров изображения, его можно сконструировать в покадровые изображения плюс текст и ввести в последующие слои модели.
- Тонкая настройка видеоответов на вопросы: точная настройка больших моделей (LLM) с использованием некоторых высококачественных наборов данных вопросов и ответов.
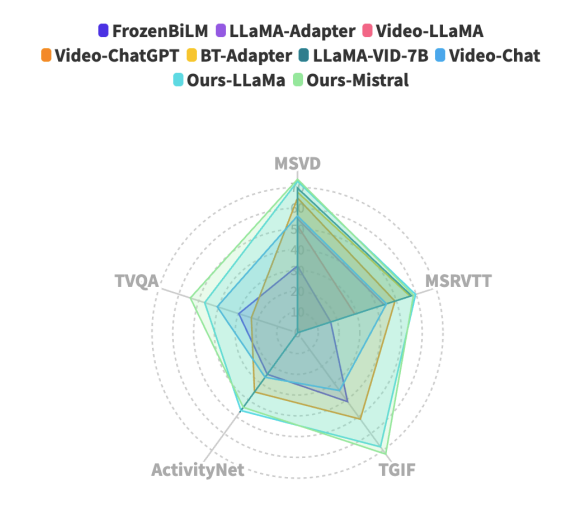
MiniGPT4-Video хорошо работает в нескольких тестах видео, включая MSVD, MSRVTT, TGIF и TVQA, достигая значительного улучшения производительности в этих тестах.
В целом, эта модель продемонстрировала потенциал для первоначального захвата видеоконтента, но ей еще предстоит пройти долгий путь, чтобы достичь удивительного уровня ChatGPT.
Выше — все содержание этого выпуска. Меня зовут Лев. Увидимся в следующем выпуске~.



Углубленный анализ переполнения памяти CUDA: OutOfMemoryError: CUDA не хватает памяти. Попыталась выделить 3,21 Ги Б (GPU 0; всего 8,00 Ги Б).

[Решено] ошибка установки conda. Среда решения: не удалось выполнить первоначальное зависание. Повторная попытка с помощью файла (графическое руководство).

Прочитайте нейросетевую модель Трансформера в одной статье

.ART Теплые зимние предложения уже открыты

Сравнительная таблица описания кодов ошибок Amap

Уведомление о последних правилах Points Mall в декабре 2022 года.

Даже новички могут быстро приступить к работе с легким сервером приложений.

Взгляд на RSAC 2024|Защита конфиденциальности в эпоху больших моделей

Вы используете ИИ каждый день и до сих пор не знаете, как ИИ дает обратную связь? Одна статья для понимания реализации в коде Python общих функций потерь генеративных моделей + анализ принципов расчета.

Используйте (внутренний) почтовый ящик для образовательных учреждений, чтобы использовать Microsoft Family Bucket (1T дискового пространства на одном диске и версию Office 365 для образовательных учреждений)

Руководство по началу работы с оперативным проектом (7) Практическое сочетание оперативного письма — оперативного письма на основе интеллектуальной системы вопросов и ответов службы поддержки клиентов

[docker] Версия сервера «Чтение 3» — создайте свою собственную программу чтения веб-текста

Обзор Cloud-init и этапы создания в рамках PVE

Корпоративные пользователи используют пакет регистрационных ресурсов для регистрации ICP для веб-сайта и активации оплаты WeChat H5 (с кодом платежного узла версии API V3)

Подробное объяснение таких показателей производительности с высоким уровнем параллелизма, как QPS, TPS, RT и пропускная способность.

Удачи в конкурсе Python Essay Challenge, станьте первым, кто испытает новую функцию сообщества [Запускать блоки кода онлайн] и выиграйте множество изысканных подарков!

[Техническая посадка травы] Кровавая рвота и отделка позволяют вам необычным образом ощипывать гусиные перья! Не распространяйте информацию! ! !

[Официальное ограниченное по времени мероприятие] Сейчас ноябрь, напишите и получите приз

Прочтите это в одной статье: Учебник для няни по созданию сервера Huanshou Parlu на базе CVM-сервера.

Cloud Native | Что такое CRD (настраиваемые определения ресурсов) в K8s?

Как использовать Cloudflare CDN для настройки узла (CF самостоятельно выбирает IP) Гонконг, Китай/Азия узел/сводка и рекомендации внутреннего высокоскоростного IP-сегмента

Дополнительные правила вознаграждения амбассадоров акции в марте 2023 г.

Можно ли открыть частный сервер Phantom Beast Palu одним щелчком мыши? Супер простой урок для начинающих! (Прилагается метод обновления сервера)

[Играйте с Phantom Beast Palu] Обновите игровой сервер Phantom Beast Pallu одним щелчком мыши

Maotouhu делится: последний доступный внутри страны адрес склада исходного образа Docker 2024 года (обновлено 1 декабря)

Кодирование Base64 в MultipartFile

5 точек расширения SpringBoot, супер практично!

Глубокое понимание сопоставления индексов Elasticsearch.

15 рекомендуемых платформ разработки с нулевым кодом корпоративного уровня. Всегда найдется та, которая вам понравится.
