Более 500 раз! Беркли | Предлагаемое кольцо Внимание, преобразование на фрагменты, поддержка контекста до 100 млн!
введение
В последние годы Transformer стал базовой архитектурой многих современных систем искусственного интеллекта и продемонстрировал впечатляющую производительность в различных приложениях искусственного интеллекта, таких как ChatGPT, GPT-4, ChatGLM, PanGu и т. д. Однако требования Transformer к памяти ограничивают его способность обрабатывать длинные последовательности, что усложняет выполнение задач, зависящих от длинных последовательностей.
В ответ на этот вызов,Университет Беркли придумал уникальный подход:Вызвать внимание,Обрабатывайте более длинные входные последовательности, сохраняя при этом эффективность памяти.,В несколько раз дольше, чем современные технологии,Достигнут максимальный размер контекста более 100M.。

Paper:https://browse.arxiv.org/pdf/2310.01889.pdf
Code:coming soon~
Предыстория
Архитектура Transformer в основном состоит из механизмов самообслуживания и упреждения положения. Эти компоненты помогают фиксировать зависимости между входными токенами и достигать масштабируемости за счет высокопараллельных вычислений.
Благодаря архитектуре Transformer с самообслуживанием стоимость его памяти имеет квадратичную зависимость от длины входной последовательности, что затрудняет масштабирование до более длинных входных последовательностей. Однако Transformer, который может поддерживать длинные последовательности, имеет решающее значение для приложений моделей искусственного интеллекта. Например, его можно применять для обработки длинных книг, изображений с высоким разрешением, длинных видео и библиотек кода. И уже существуют языковые модели, поддерживающие длинные последовательности. Например, ChatGPT может поддерживать длину контекста 16 КБ, GPT-4 может поддерживать длину контекста 32 КБ, MPT может поддерживать длину контекста 65 КБ, а Claude может поддерживать длину контекста 100 КБ.
Чтобы снизить затраты памяти Transformer, его можно применять для задач с более длинной последовательностью. Исследователи обнаружили, что расчет матрицы softmax при самостоятельном внимании не обязательно должен рассчитываться в полной матрице, что способствовало развитию вычислений с самообслуживанием и блоками прямой связи. Хотя этот тип метода уменьшает объем памяти, хранение каждого из них. Выходной слой по-прежнему Есть проблемы. Поскольку самовнимание последующих слоев зависит от выходных данных предыдущего уровня, если выходные данные промежуточного процесса не сохраняются, вычислительные затраты будут увеличиваться экспоненциально.
Потому что без хранилища каждый вывод пришлось бы пересчитывать для каждого элемента последовательности, что непрактично для более длинных последовательностей. С точки зрения требований к памяти, даже при размере пакета 1, обработка 100 миллионов токенов потребует более 1000 ГБ памяти для обычной модели со скрытым размером 1024. Это намного превышает мощность нынешних графических процессоров и TPU.
Ring Attention
Для увеличения длины последовательности, которую может поддерживать Transformer. Авторы предлагают выполнять сетевые вычисления с самообслуживанием и прямой связью по частям, распределяя измерения последовательности между несколькими хост-устройствами, тем самым обеспечивая одновременные вычисления и связь, поскольку этот метод сочетает в себе блочную связь ключ-значение между хост-устройствами в кольце с Блок вычислений Overlap, отсюда и его название: Ring Attention.
конкретное место,Этот метод находится вПостройте внешний цикл блока расчета внимания между хост-устройством и устройством.,Каждое Хозяин-устройство имеет блок запросов.,и пройти по кольцу устройства Хозяин через блоки «ключ-значение»,Внимание и вычисления в сети с прямой связью поблочно. При расчете внимания,Каждый Хозяин отправляет блок ключевых значений следующему Хозяину,При этом получите блок «ключ-значение» от предыдущего Хозяина. Здесь автор использует оригинальные модели Transformer Архитектура, но расчеты реорганизованы.
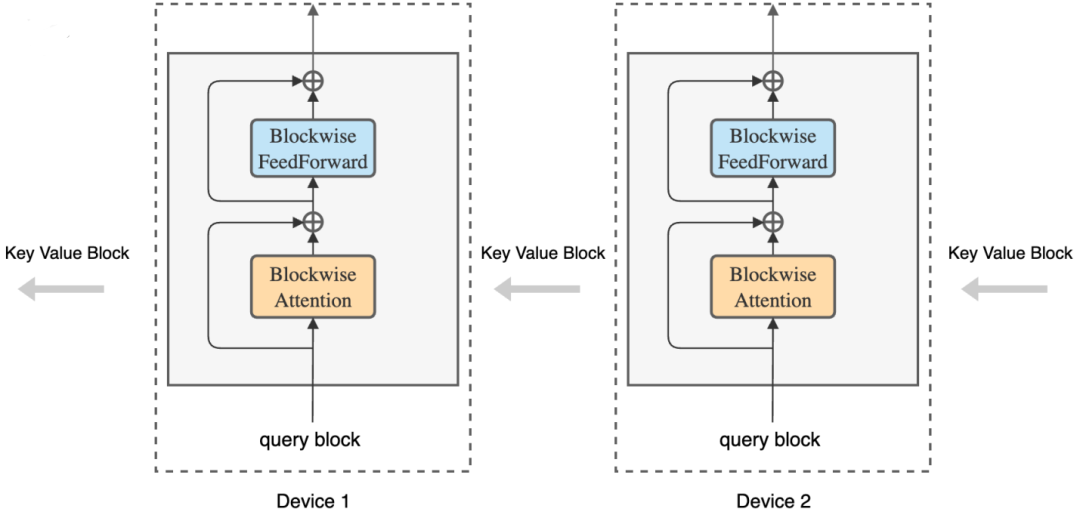
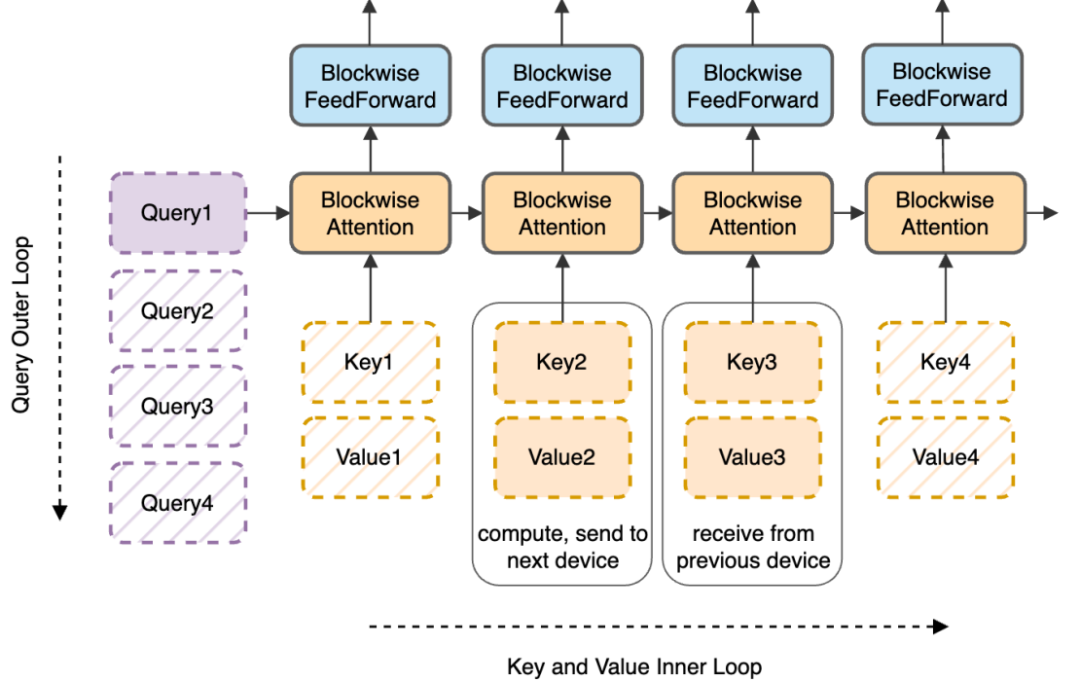
Во внутреннем цикле каждое устройство вычисляет свои собственные блочные операции внимания и прямой связи.。во время внутреннего кровообращения,Каждое устройство отправляет копию блока «ключ-значение», используемого для блочных вычислений, следующему устройству в кольце.,Также получает блок «ключ-значение» от предыдущего устройства. Поскольку вычисление блока занимает больше времени, чем передача блока,По сравнению со стандартным Трансформером,Этот процесс не добавляет накладных расходов. Подробности показаны на рисунке ниже:
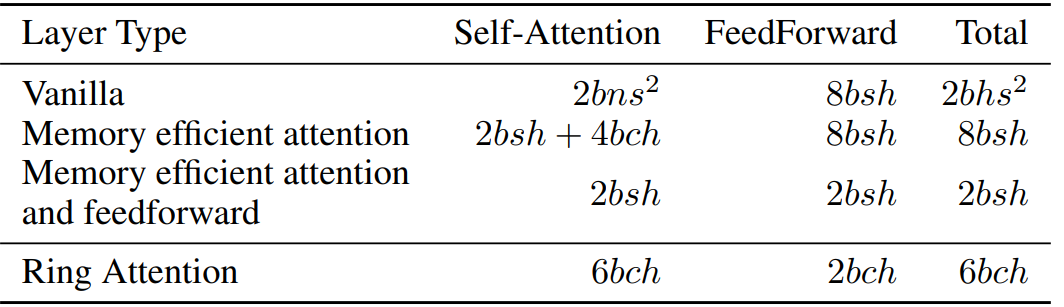
При использовании RingAttention требования к памяти каждого устройства линейно связаны с размером блока и не зависят от исходной длины входной последовательности, что также устраняет ограничения памяти, налагаемые отдельными устройствами. где b — размер пакета, h — скрытое измерение, n — количество головок, s — длина последовательности, а c — размер блока.
RingAttention требует лишь очень маленькой кольцевой топологии и поддерживает как графический процессор, так и TPU. Минимальный размер блока определяется числом FLOP/односторонней пропускной способностью и может быть легко достигнут путем использования эффективного внимания к блоку и ffn на каждом устройстве.

Результаты эксперимента
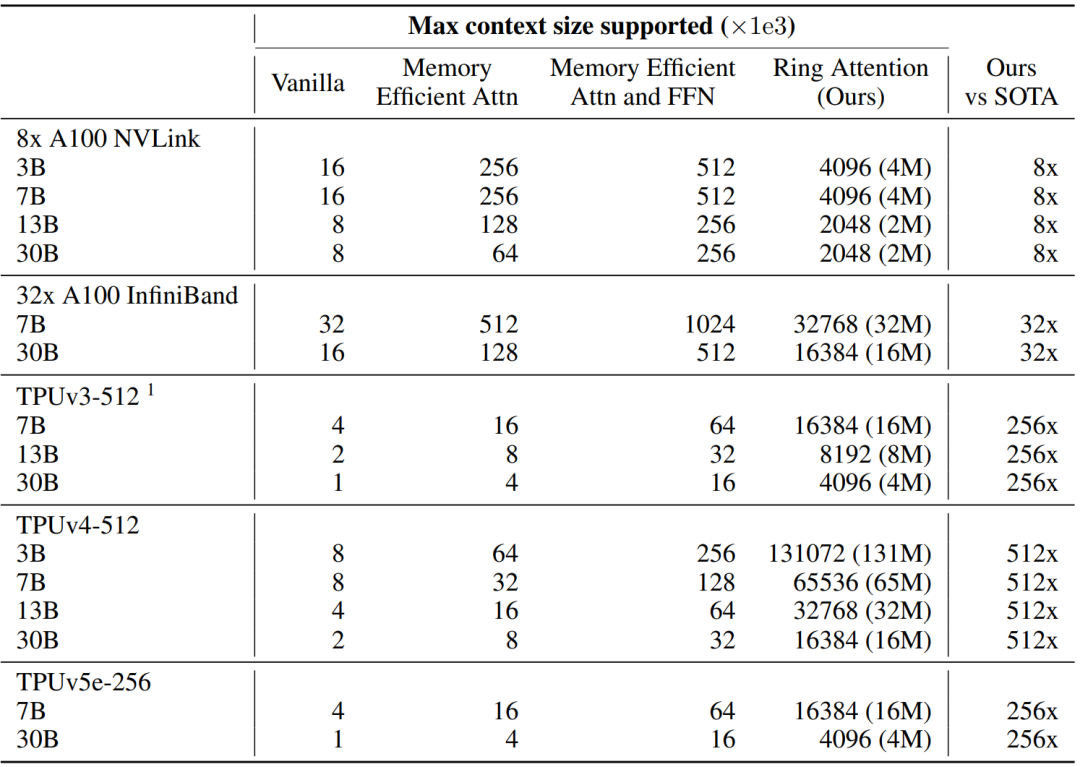
В следующей таблице показана максимальная длина контекста, поддерживаемая памятью устройства в различных моделях и кластерах ускорителей. Ring Attention значительно превосходит базовый Transformer и в несколько раз длиннее современного, достигая размера контекста более 100 МБ.
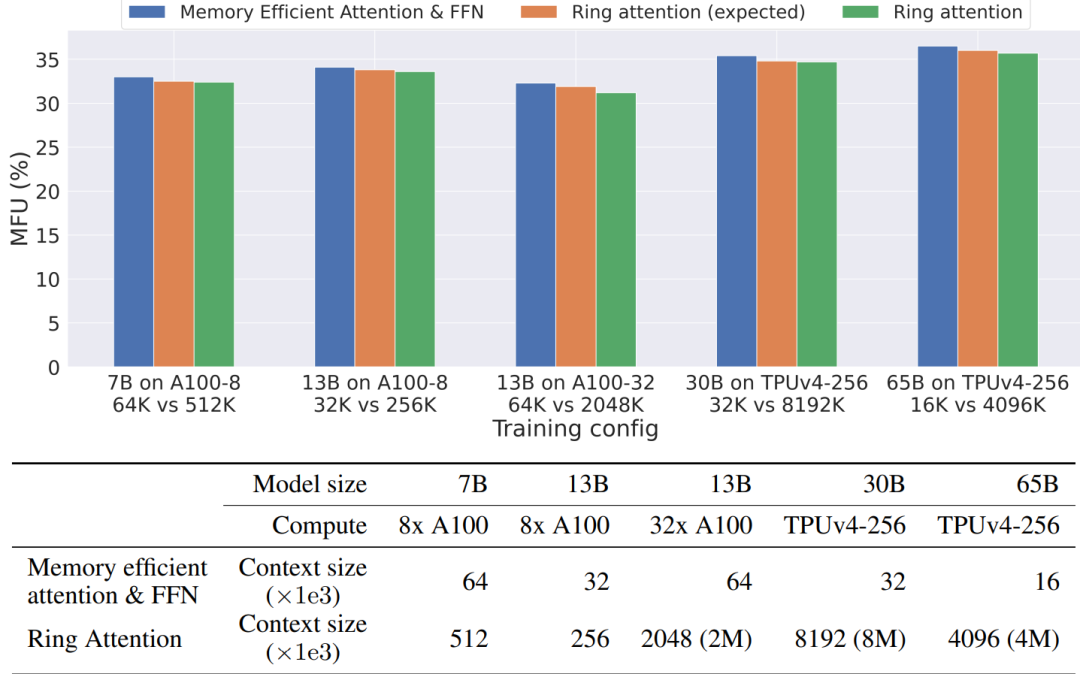
В следующей таблице показано MFU (использование ошибок модели) при различных конфигурациях обучения. Ring Attention может обучать большие модели (30B–65B) с размерами контекста, превышающими 8M, с незначительными накладными расходами.
в заключение
В этой статье предлагается метод Ring Attention для снижения требований к памяти Transformer. Такой подход позволяет линейно масштабировать длину контекста в зависимости от количества устройств, сохраняя при этом производительность и устраняя узкие места памяти на отдельных устройствах. Ring Attention значительно превосходит базовый Transformer и в несколько раз длиннее современного, достигая размера контекста более 100 МБ.
Хотя этот метод достиг современного уровня с точки зрения длины контекста модели Трансформера, существуют определенные ограничения: 1) Из-за ограничений вычислительного бюджета эксперименты в этой статье сосредоточены на оценке эффективности предлагаемого метода. 2) Хотя Ring Attention может масштабировать длину контекста линейно в зависимости от количества устройств и поддерживать производительность, низкоуровневые операции также необходимо оптимизировать для достижения оптимальной производительности вычислений.
Рекомендуем к прочтению
[1]Сентябрь 2023 г., обзор популярных статей и последние научные достижения!
[2]RAIN: Большие модели можно выравнивать без тонкой настройки! !
[3]TrafficGPT: большая модель городского транспорта!
[4] Большая модель мамонта! Большая математическая модель теперь превосходит GPT-4!
[5] Используйте 200 фрагментов данных, чтобы точно настроить модель и превзойти MiniGPT-4!
[6]Хорошая вещь! Краткое описание метода цепочки, управление различными большими моделями!
Чтобы внести свой вклад или запросить освещение, свяжитесь с: ainlperbot



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
