Big Data NiFi (20): синхронизируйте данные MySQL с Hive в режиме реального времени.
Синхронизируйте данные MySQL с Hive в режиме реального времени.
Пример: синхронизировать вновь добавленные данные в MySQL с Hive в режиме реального времени.
В приведенном выше случае требуются процессоры: «CaptureChangeMySQL», «RouteOnAttribute», «EvaluateJsonPath», «ReplaceText», «PutHiveQL».
Сначала прочитайте изменения данных в MySQL через «CaptureChangeMySQL» (необходимо включить журнал binlog MySQL), синхронизируйте измененные данные в Binlog с процессором «RouteOnAttribute», получите атрибуты восходящих данных через этот процессор и получите соответствующий тип операции binlog, а затем направьте данные, которые вы хотите обработать, в процессор «EvaluateJsonPath», который может анализировать данные binlog в формате json с помощью специального json. Выражение получает атрибуты из данных json и помещает их в атрибут FlowFile. FlowFile получает восходящий атрибут FowFile через процессор «ReplaceText». Динамически соединяет SQL-код для замены всего содержимого FlowFile. FlowFile и направляется в «PutHiveQL» для записи данных. Введите таблицу Hive.
1. Включите журнал binlog MySQL.
mysql-binlog — это двоичный журнал базы данных MySQL, в котором записывается вся информация об операторах DDL и DML (кроме операторов запроса данных). Вообще говоря, включение двоичного журнала приведет к потере производительности примерно на 1%. Здесь вам необходимо включить журнал binlog MySQL, чтобы облегчить позднее использование процессора CaptureChangeMySQL для получения событий CDC в MySQL. Лучшая версия MySQL — версия 5.7 или выше.
1. Войдите в MySQL, чтобы проверить, включен ли MySQL binlog.
[root@node2 ~]# mysql -u root -p123456
mysql> show variables like 'log_%';
2. Откройте журнал binlog MySQL.
Напишите следующее содержимое в разделе [mysqld] файла /etc/my.cnf:
[mysqld]
#Случайным образом указать строку, которая не может иметь то же имя, что и машина в других кластерах
server-id=123
#Конфигурацияжурнал каталог бинлога, журнал будет автоматически открыт после настройки бинлога и напишите в этот каталог
log-bin=/var/lib/mysql/mysql-bin3. Перезапустите службу MySQL и еще раз проверьте binlog.
[root@node2 ~]# service mysqld restart
[root@node2 ~]# mysql -u root -p123456
mysql> show variables like 'log_%';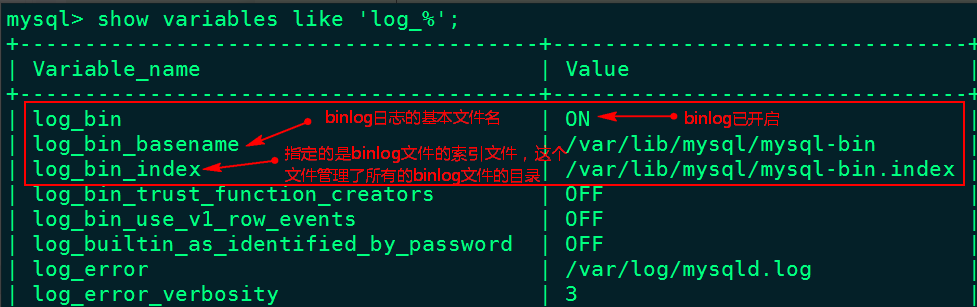
2. Настройте процессор CaptureChangeMySQL.
«CaptureChangeMySQL» в основном фиксирует события CDC (Change Data Capture) из базы данных MySQL. События CDC включают операции INSERT, UPDATE и DELETE, и эти события выводятся в отдельные файлы FlowFile в том порядке, в котором происходят операции.
Описание основной настройки «Свойства» процессора «CaptureChangeMySQL» следующее:
Элементы конфигурации | значение по умолчанию | разрешенные значения | описывать |
|---|---|---|---|
MySQL-хосты (узел MySQL) | Список записей имени хоста/порта, соответствующих узлам кластера MySQL. Несколько узлов разделяются запятыми в формате: хост1:порт, хост2:порт..., и процессор попытается подключиться к хостам в списке по порядку. Если узел выходит из строя и в кластере включено аварийное переключение, процессор подключается к активному узлу. | ||
Имя класса драйвера MySQL (имя драйвера MySQL) | com.mysql.jdbc.Driver | Имя класса драйвера базы данных MySQL. | |
Расположение драйверов MySQL (расположение драйвера MySQL) | Список файлов/папок и/или URL-адресов, разделенных запятыми, содержащих пакет драйвера MySQL и его зависимости, если таковые имеются, например «/var/tmp/mysql-connector-java-5.1.38-bin.jar». | ||
Имя пользователя (имя пользователя) | Имя пользователя для доступа к кластеру MySQL. | ||
Пароль (пароль) | Пароль для доступа к кластеру MySQL. | ||
Шаблон имени базы данных/схемы (База данных совпадений/схема) | Регулярное выражение, используемое для сопоставления базы данных (или схемы, в зависимости от типа СУБД) со списком событий CDC. Регулярное выражение должно соответствовать имени базы данных, хранящейся в СУБД. Если свойство не установлено, имя базы данных не будет использоваться для фильтрации событий CDC. | ||
Шаблон имени таблицы (соответствующая таблица) | Регулярное выражение (регулярное выражение), используемое для сопоставления событий CDC, влияющих на таблицу соответствия. Регулярное выражение должно соответствовать имени таблицы, хранящейся в базе данных. Если свойство не установлено, никакие события не будут фильтроваться по имени таблицы. | ||
Максимальное время ожидания (Максимальное время ожидания соединения) | 30 seconds | Максимальное время, отведенное для установления соединения, ноль означает, что фактически ограничений нет. | |
Клиент распределенного кэша карт (Клиент распределенного кэша) | Указывает службу клиентского контроллера кэша распределенной карты, которая содержит различные таблицы, столбцы и т. д., необходимые процессору. Если не указано, созданное событие не будет включать такую информацию, как тип или имя столбца. | ||
Получить все записи (получить все записи) | true | ▪true ▪false | Указывает, получать ли все доступные события CDC независимо от текущего имени или местоположения файла binlog. Значение этого атрибута игнорируется, если в статусе процессора присутствуют имя файла binlog и значения местоположения. Это позволяет использовать 4 различные конфигурации: 1). Если данные binlog существуют в состоянии процессора, состояние используется для определения начальной позиции, а значение «Получить все записи» игнорируется. (В настоящее время существует проблема с тестированием версии NiFi) 2). Если данные binlog не существуют в состоянии процессора, установка этого значения в true означает чтение данных binlog с нуля. 3) Если в состоянии процессора нет данных бинлога, а имя и местоположение файла бинлога не указаны, установка для этого значения значения false означает чтение данных с конца бинлога. 4) Если данные бинлога не существуют в состоянии процессора, а имя и местоположение файла бинлога указаны, установка для этого значения значения false означает чтение данных, начиная с конца указанного бинлога. |
Включить события начала/фиксации (Включает события запуска/фиксации) | false | ▪true ▪false | Указывает, следует ли создавать события, соответствующие событиям запуска или фиксации, в двоичном журнале. Установите значение true, если в нисходящем потоке требуются события запуска/фиксации, в противном случае установите значение false, что подавляет генерацию этих событий и может повысить производительность потока. |
Включить события DDL (стандартные имена таблиц/столбцов) | false | ▪true ▪false | Указывает, создавать ли события, соответствующие событиям языка определения данных (DDL), например ALTER TABLE, TRUNCATE TABLE. Установите значение true, если события DDL требуются в нисходящем потоке, в противном случае установите значение false. Если установлено значение false, генерация этих событий будет подавлена, что может улучшить производительность потоковой передачи. |
Шаги настройки следующие:
1. Создайте процессор CaptureChangeMySQL.

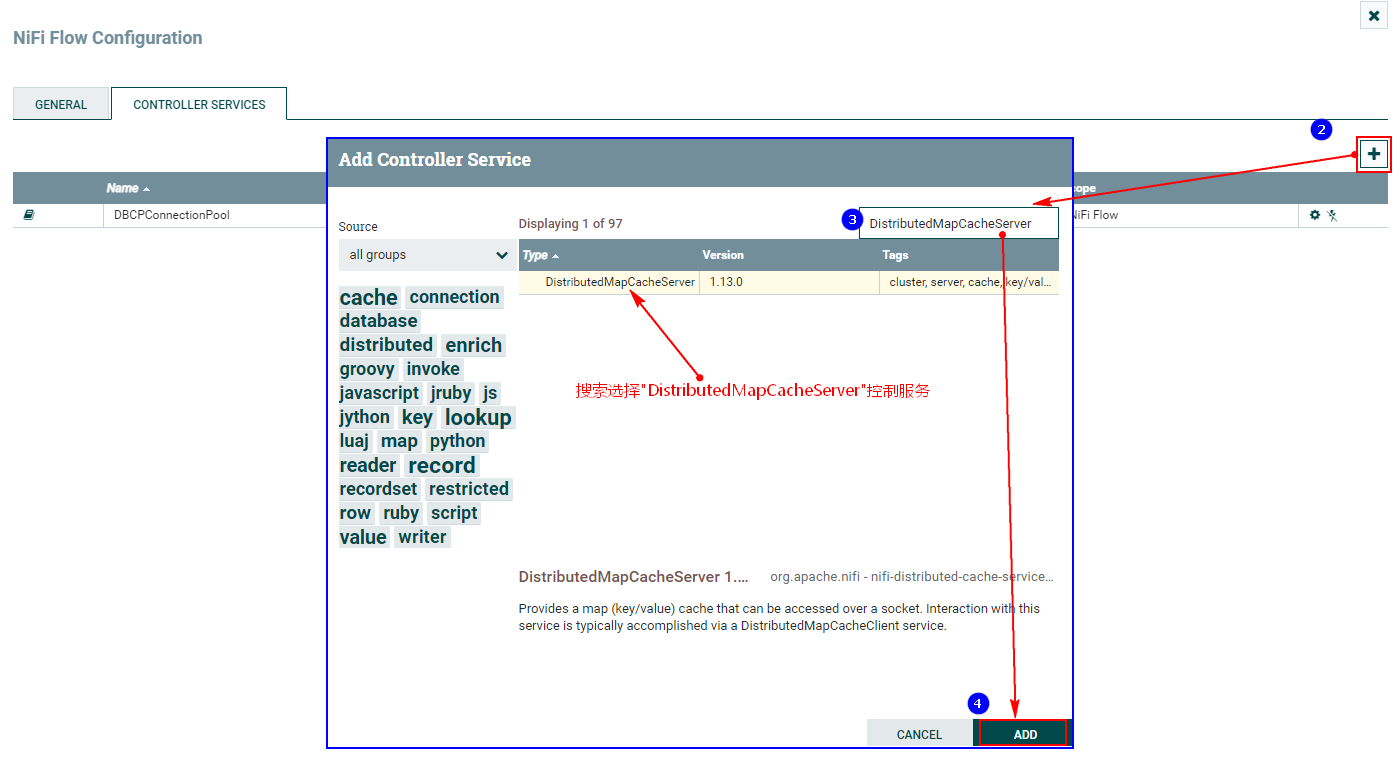
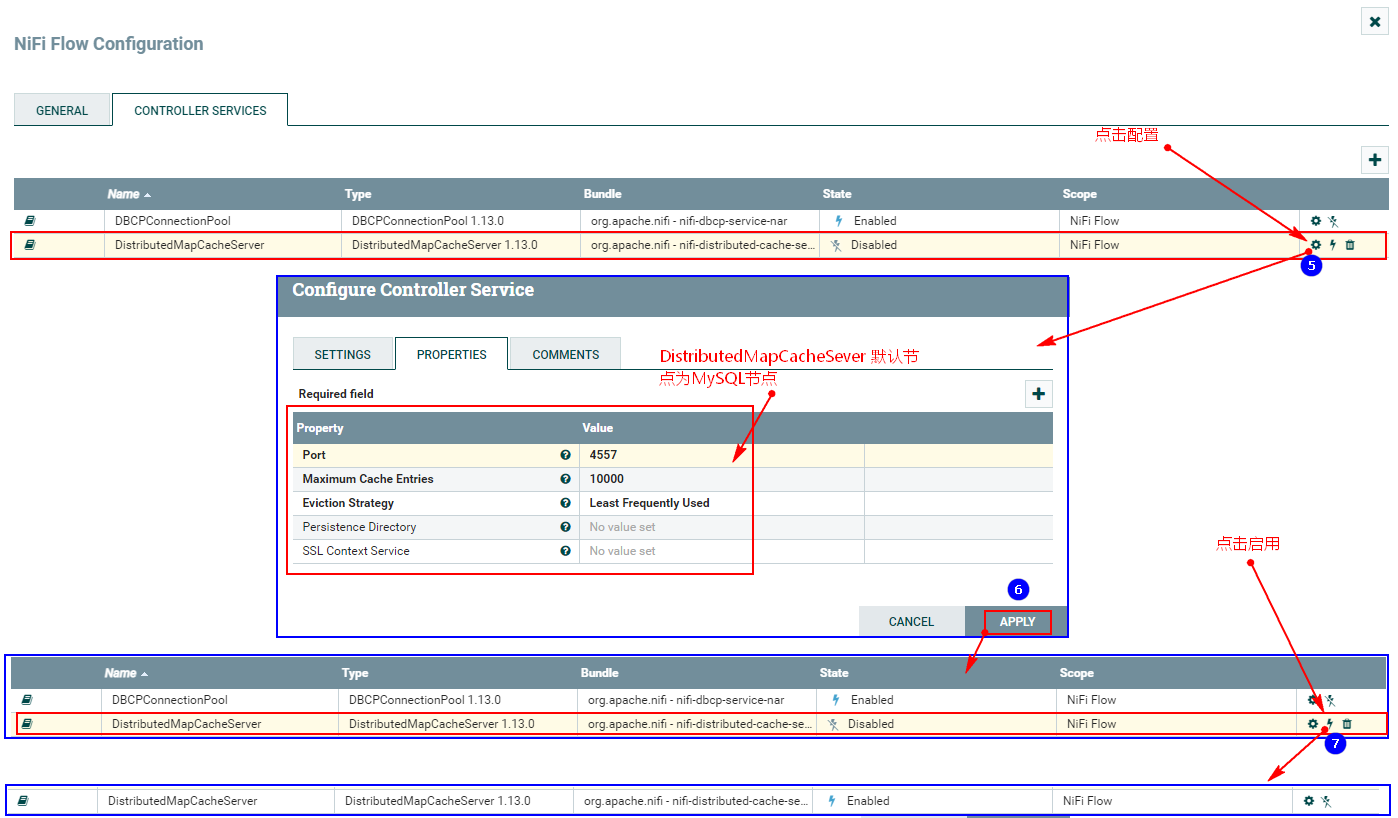
2. Настройте службу управления DistributeMapCacheServer.
Для отслеживания изменений MySQL необходимо настроить службу управления DistributedMapCacheClient. На соответствующем сервере хранятся различные таблицы, столбцы и другая информация, необходимая процессору, поэтому сначала необходимо настроить службу управления DistributeMapCacheServer.
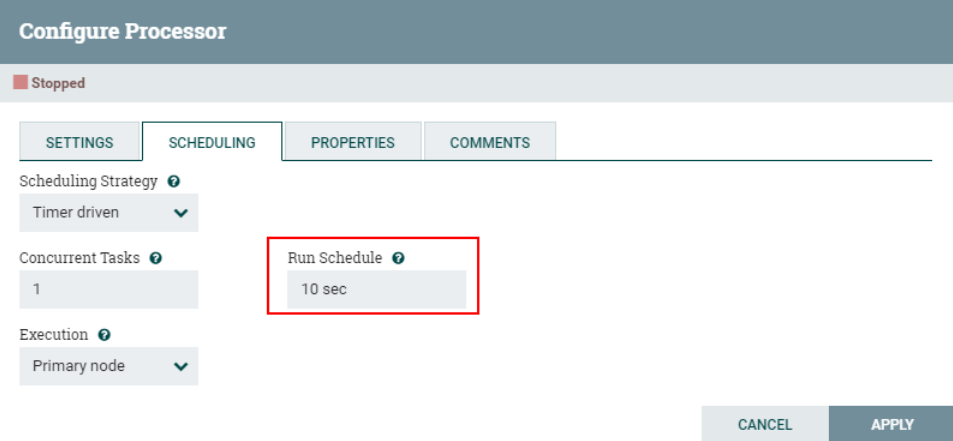
3. Настройте «РАСПИСАНИЕ»
Поскольку здесь используется процессор CaptureChangeMySQL для мониторинга данных в MySQL, цикл доступа к расписанию установлен на «10 с», чтобы предотвратить непрерывный мониторинг данных бинлога MySQL, что приведет к снижению производительности.
4. Настройте «СВОЙСТВА»
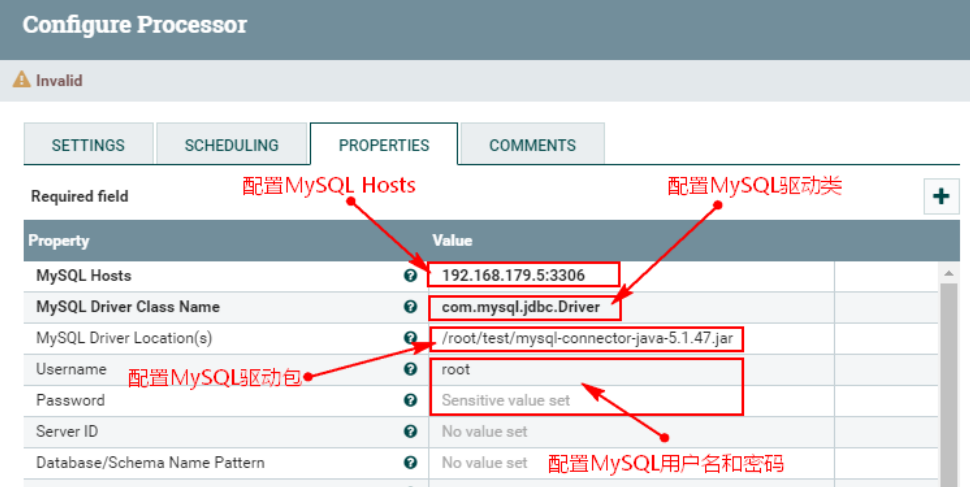
Настройте «СВОЙСТВА» в процессоре «CaptureChangeMySQL» следующим образом:
- MySQL Host : 192.168.179.5:3306
- MySQL Driver Class Name:com.mysql.jdbc.Driver
- MySQL Driver Location(s):/root/test/mysql-connector-java-5.1.47.jar
Примечание. Здесь вам необходимо создать соответствующий каталог на каждом узле NiFi и загрузить пакет драйверов mysql.
Конфигурация «СВОЙСТВА» следующая:
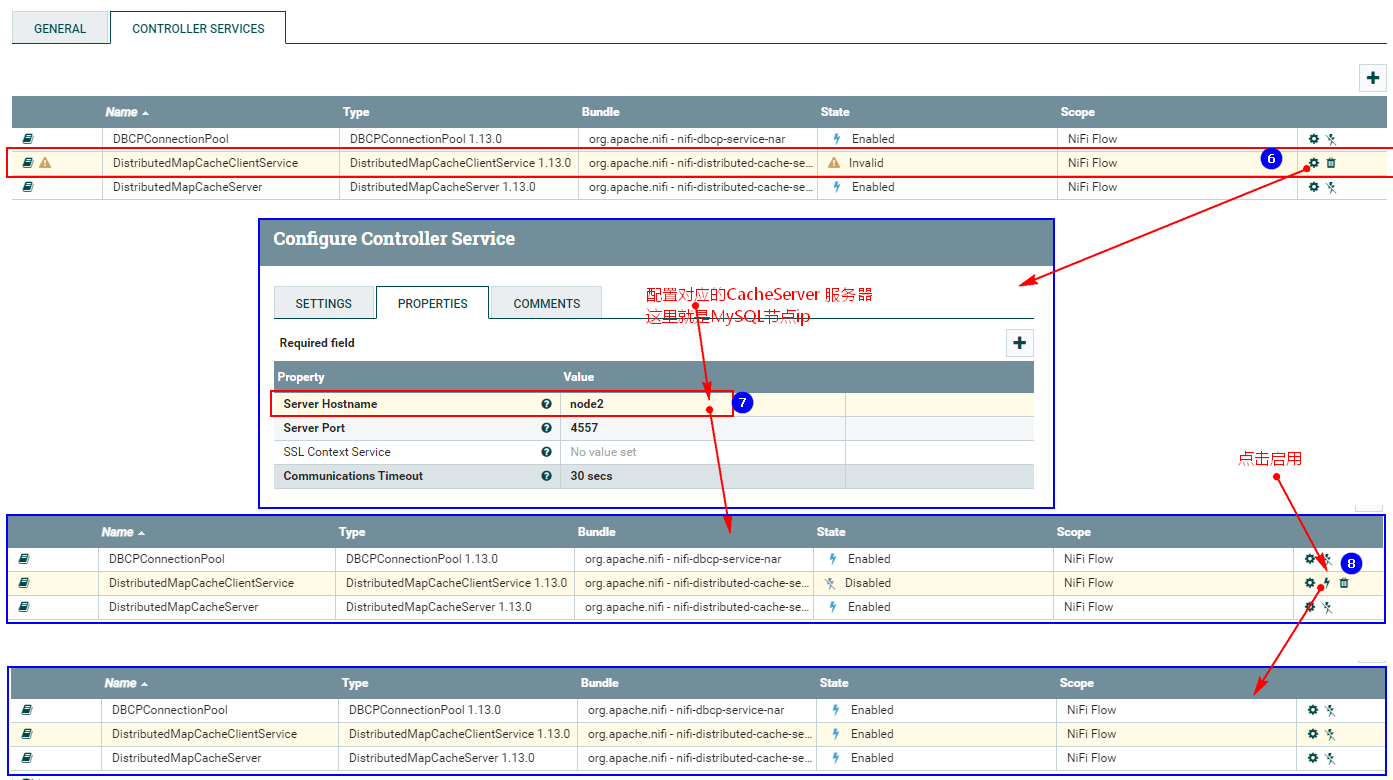
Кроме того, вам также необходимо настроить службу управления «Клиент распределенного кэша карт» в «СВОЙСТВАХ» для чтения данных кэша в службе управления «DistributeMapCacheServer»:


Кроме того, здесь мы отслеживаем только события CDC, соответствующие таблице «test2». Здесь мы устанавливаем имя соответствующей таблицы «test2». Окончательная конфигурация «PROPERTIES» выглядит следующим образом:
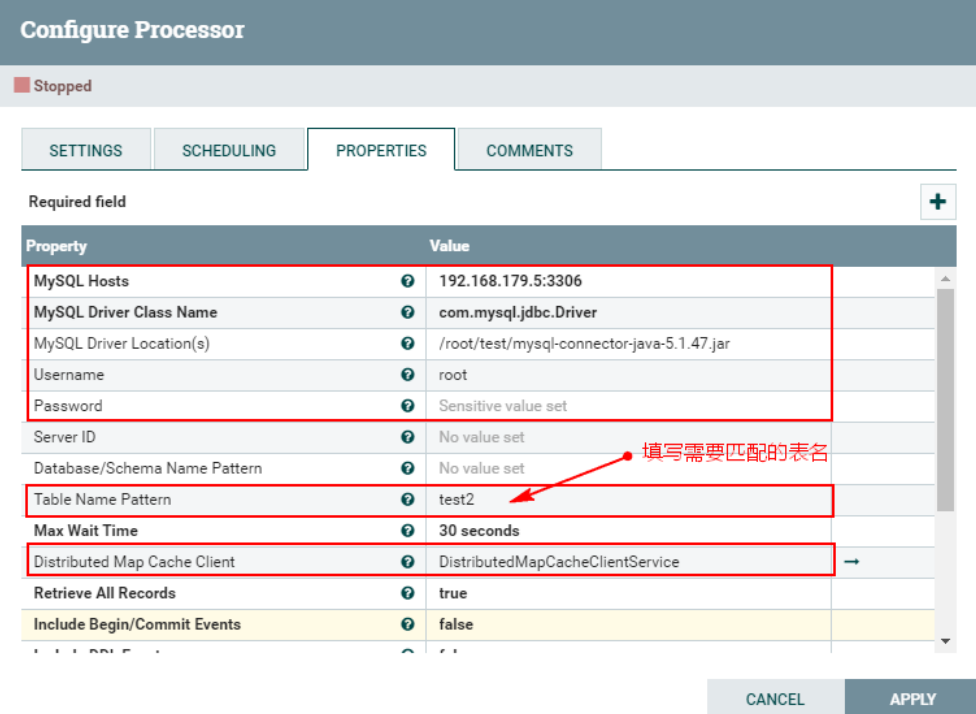
Примечание. Значение, соответствующее приведенной выше конфигурации «Шаблон имени таблицы», здесь: test2, или его не нужно настраивать, будут отслеживаться события binlog, соответствующие изменениям во всех таблицах MySQL. Когда новые и обновленные данные будут вставлены в таблицу Hive позже, соответствующая таблица метаданных в MySQL также изменится, и соответствующие события binlog также будут отслеживаться. Чтобы избежать последующего мониторинга логов binlog других таблиц, рекомендуется настроить «test2».
5. Запустите MySQL, создайте таблицу «test2» для проверки процессора «CaptureChangeMySQL».
Войдите в MySQL, используйте библиотеку «mynifi» и создайте таблицу «test2». Временно настройте процессор CaptureChangeMySQL на автоматическое завершение и запуск события «успех». Вставьте соответствующие данные в таблицу, чтобы проверить, может ли процессор CaptureChangeMySQL нормально отслеживать это событие.
Создайте соответствующую таблицу в MySQL:
use mynifi;
create table test2 (id int,name varchar(255),age int);Запустите обработчик «CaptureChangeMySQL»:
Вставьте следующие данные в таблицу «test2»:
insert into test2 values (1,"zs",18);
update test2 set name = "ls" where id = 1;
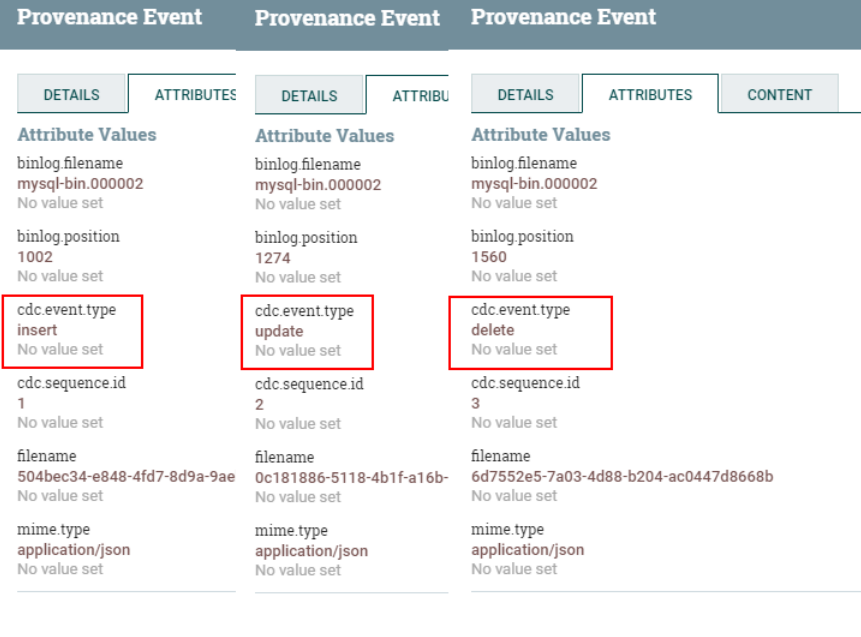
delete from test2 where id = 1;Вы можете щелкнуть правой кнопкой мыши «Просмотр происхождения данных» в процессоре «CaptureChangeMySQL», чтобы просмотреть захваченные события «вставка», «обновление» и «удаление»:
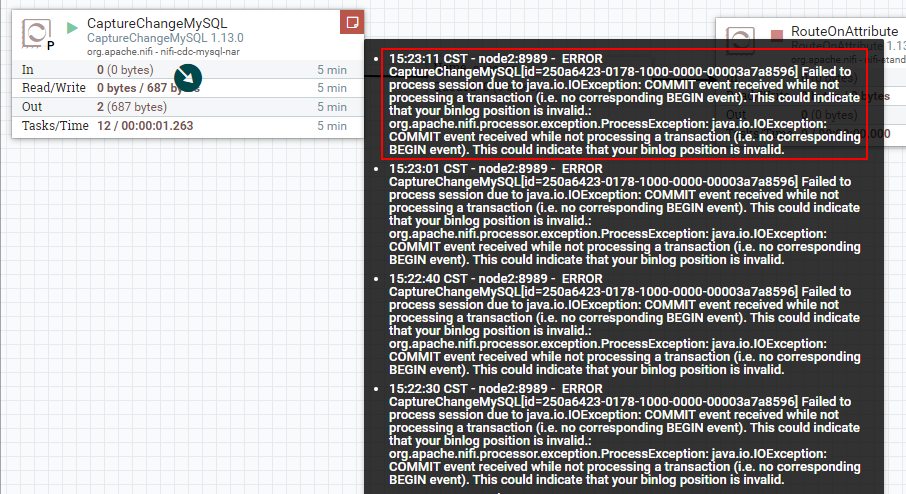
Примечание. После настройки процессора CaptureChangeMySQL на запуск, когда данные вставляются, изменяются или удаляются в MySQL, текущий процессор будет читать журнал binlog MySql и записывать статус местоположения бинлога, прочитанного в текущем процессоре. Обычно, если вы закроете процессор «CaptureChangeMySQL» и запустите его снова, сохраненная позиция binlog продолжит читаться (вы можете обратиться к инструкциям по настройке «Получить все записи» в атрибуте «PROPERTIES»), но после тестирования это Версия NiFi имеет следующую ошибку (Неверное местоположение binlog, визуальная проверка — ошибка версии):
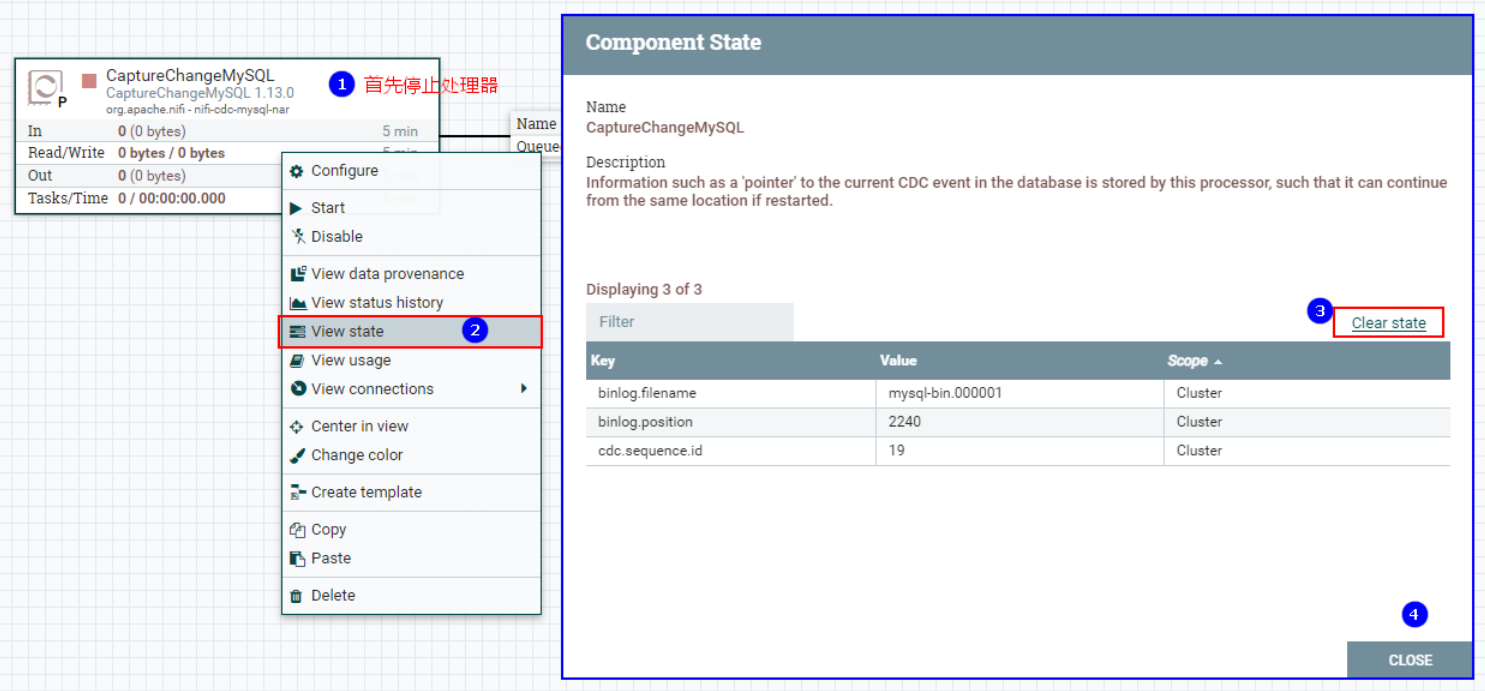
Поэтому в последующих тестах мы можем очистить статус бинлога, прочитанного процессором «CaptureChangeMysql», а затем запустить его снова. Вновь добавленные, измененные и удаленные данные, которые MySQL ранее обнаружил, будут прочитаны повторно.
Очистите «CaptureChangeMysql» и прочитайте статус бинлога:
3. Настройте процессор RouteOnAttribute.
«RouteOnAttribute» использует выражения атрибутов для маршрутизации данных на основе атрибутов FlowFile.
Описание основной настройки «Свойства» процессора «RouteOnAttribute» следующее:
Элементы конфигурации | значение по умолчанию | описывать |
|---|---|---|
Стратегия маршрутизации | Route to Property name | Указывает, какое отношение используется при оценке языка выражений. На выбор предлагается несколько отношений: ▪Маршрут к имени свойства Копия FlowFile будет направлена к каждой связи, для которой соответствующее выражение имеет значение «истина». ▪Направить к совпадению, если все совпадают. Все определяемые пользователем выражения должны иметь значение «истина», прежде чем FlowFile будет считаться совпадающим. ▪Направить к «соответствию», если есть совпадения. FlowFile считается совпадающим только в том случае, если хотя бы одно пользовательское выражение имеет значение «истина». |
Примечание. Этот процессор позволяет пользователям настраивать атрибуты и указывать соответствующие выражения для этого атрибута. Атрибуты FileFlow, соответствующие выражению атрибута, указанному в динамическом атрибуте, сопоставляются с динамическим атрибутом.
Конфигурация следующая:
1. Создайте процессор RouteOnAttribute.
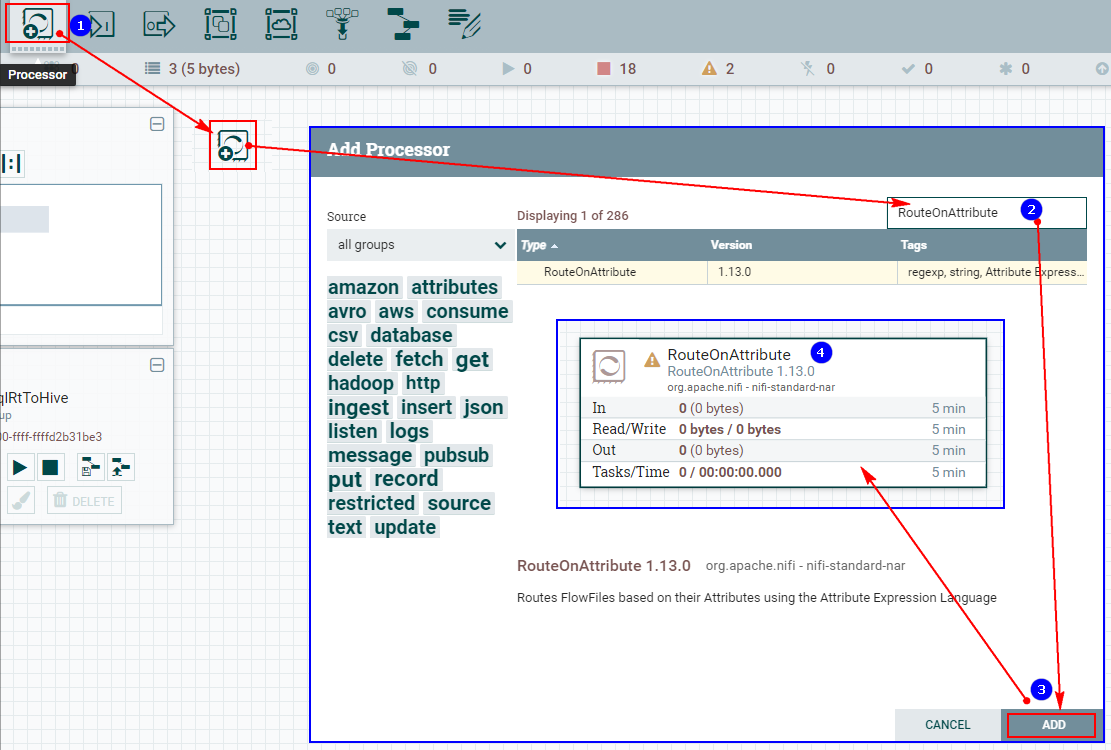
2. Настройте пользовательские свойства «СВОЙСТВА».
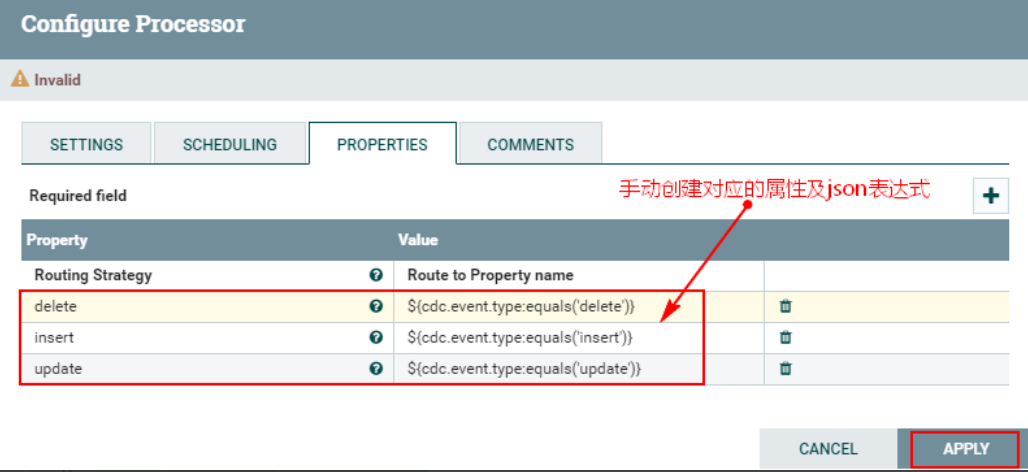
Примечание. Выражения json, соответствующие обновлению, вставке и удалению в приведенных выше настраиваемых атрибутах, записываются как: ${cdc.event.type:equals('delete')}, что означает соответствие соответствующему типу FlowFile "cdc. event.type» — это атрибут в восходящем FlowFile, «equales» — соответствующий метод, а «delete» заключено в одинарные кавычки, чтобы указать соответствующее событие CDC.
3. Соедините процессор «CaptureChangeMySQL» и процессор «RouteOnAttribute».

4. Настройте процессор «EvaluatejsonPath».
Процессор «EvaluatejsonPath» сопоставляет содержимое с атрибутом FlowFile на основе события, соответствующего восходящему «RouteOnAttribute», чтобы облегчить последующее объединение SQL для получения данных. Формат данных в FlowFile, соответствующий восходящему потоку:

EvaluatejsonPath”процессор Конфигурация следующая:
1. Настройте атрибут «СВОЙСТВА» для «EvaluatejsonPath».
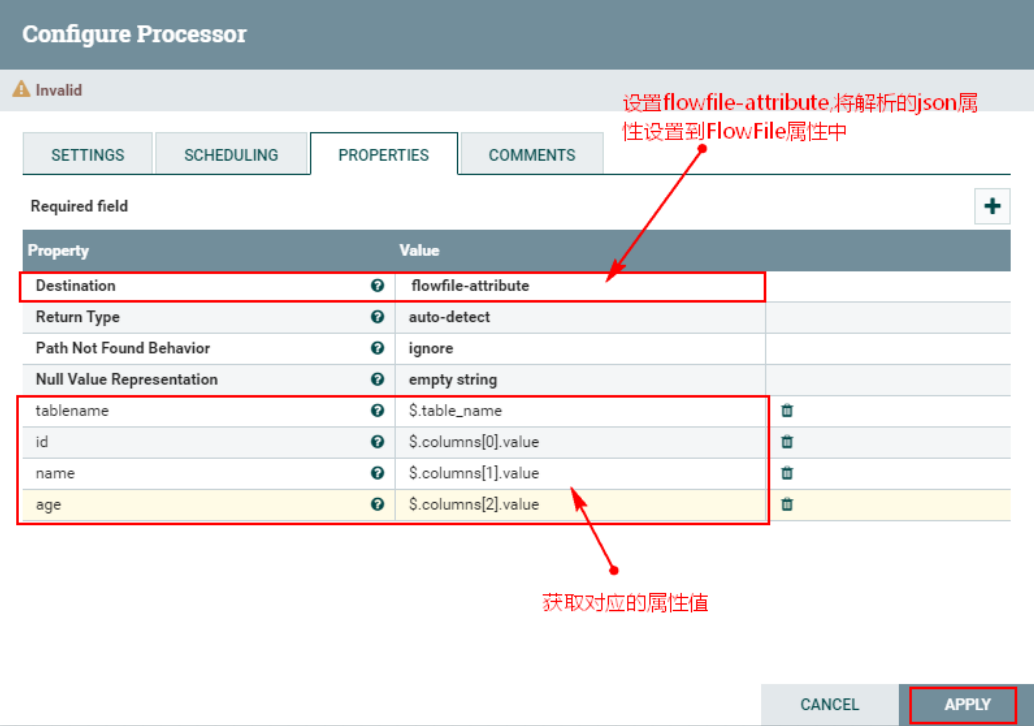
2. Соедините процессор «RouteOnAttribute» и процессор «EvaluatejsonPath».
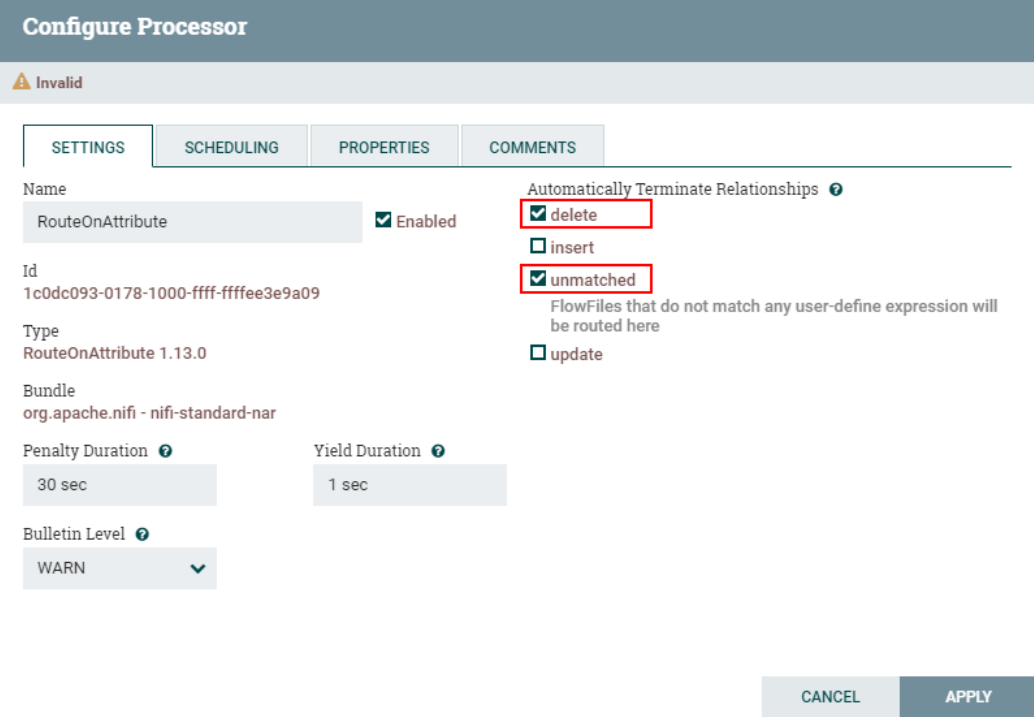
В отношениях соединения мы фокусируемся здесь только на данных «вставки» и «обновления». Позже мы получим соответствующие атрибуты и вставим вставленные и обновленные данные в таблицу Hive. Данные «удаления» можно перенаправить в другие отношения. , например Вставьте удаленные данные в другую таблицу Hive, а затем настройте ветвь для обработки. Здесь мы устанавливаем данные «удаление» и «отказ» для автоматического прекращения отношений.

Установите другие соответствующие отношения маршрутизации процессора «RouteOnAttribute» для автоматического завершения:
5. Настройте процессор «ReplaceText».
Процессор «ReplaceText» может получить свойства в FlowFile после преобразования «EvaluatejsonPath», чтобы заменить исходные данные для формирования «вставки». into ... values (... ...)" для облегчения последующей вставки данных в Hive. Конфигурация процессора "ReplaceText" следующая:
1. Настройте атрибут «PROPERTIES» процессора «RelaceText».
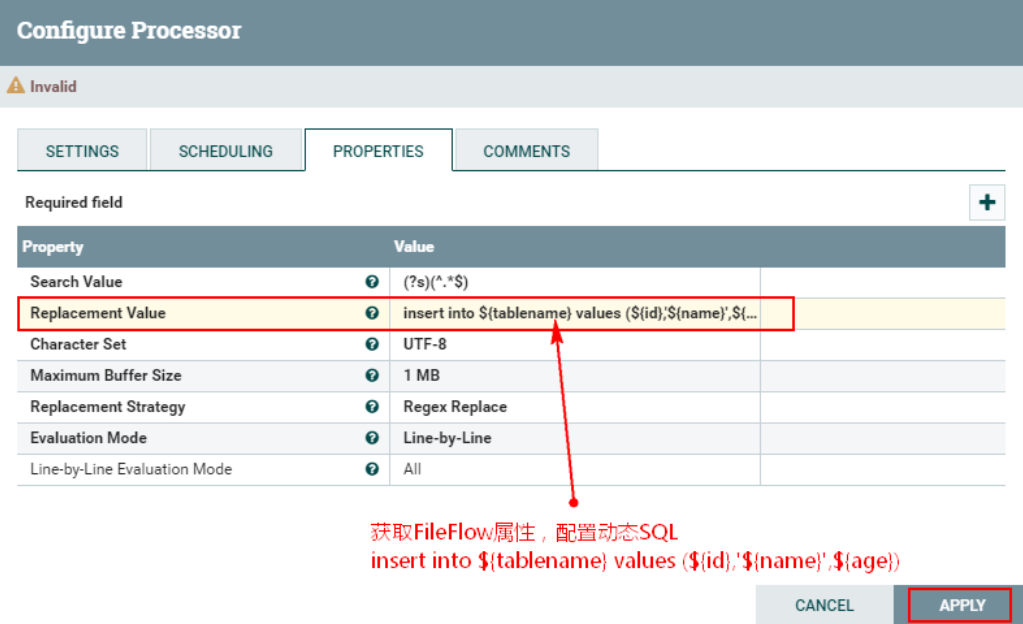
Настройте «вставить в ${tablename} значения (${id},'${name}',${age})» в «Значение замены»
Уведомление:
Полученное выше имя таблицы — «test2». Следующий SQL-запрос предназначен для вставки данных в Hive, поэтому имя таблицы «test2» также должно быть создано в Hive или имя таблицы должно быть записано как фиксированная таблица, а затем в Hive. Просто создайте соответствующую таблицу.
Кроме того, следует отметить, что ${name} соответствует строке при вставке в Hive, и здесь необходимы одинарные кавычки.
2. Соедините процессор «EvaluatejsonPath» и процессор «ReplaceText».

Настройте отношения маршрутизации «сбой» и «несоответствие» процессора «EvaluatjsonPath» для автоматического завершения.
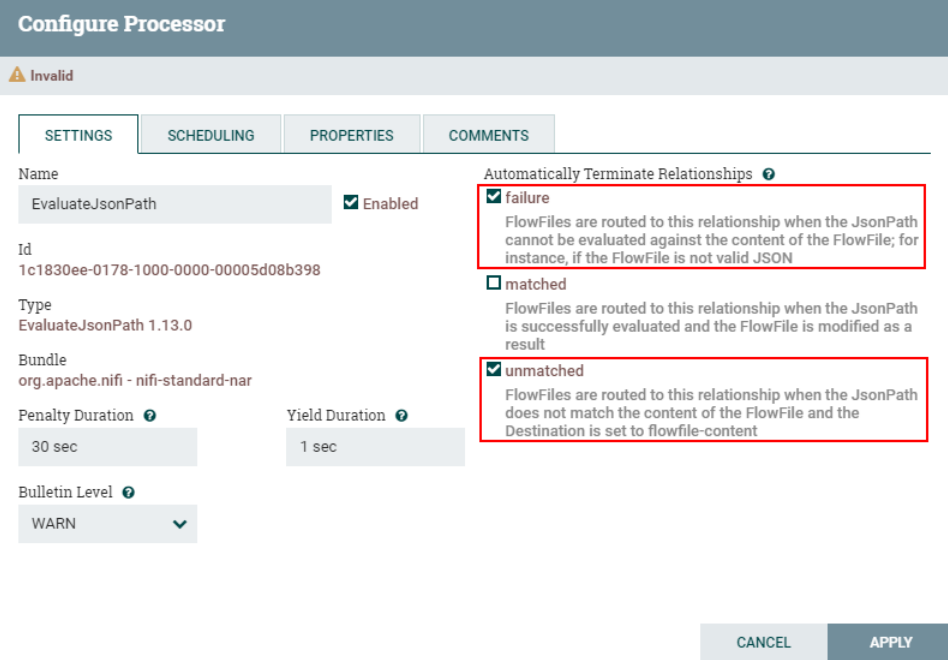
6. Настройте Hive для поддержки HiveServer2.
Доступ к Hive возможен двумя способами: HiveServer2 и Hive Client требует наличия JAR-пакетов Hive и Hadoop и конфигурации среды. HiveServer2 делает клиент, подключенный к Hive, независимым от кластеров Yarn и HDFS, устраняя необходимость настройки JAR-пакетов Hive и Hadoop, а также ряда сред в каждой точке.
NiFi использует HiveServer2 для подключения к Hive, поэтому здесь необходимо настроить HiveServer2.
Шаги по настройке HiveServer2 следующие:
1. Настройте hive-site.xml на сервере Hive.
#существоватьулей Сервер Конфигурация в $HIVE_HOME/etc/hive-site.xml:
<!-- Настроить hiveserver2 -->
<property>
<name>hive.server2.thrift.port</name>
<value>10000</value>
</property>
<property>
<name>hive.server2.thrift.bind.host</name>
<value>192.168.179.4</value>
</property>2. Настройте core-site.xml на каждом узле Hadoop.
<!-- Настройка пользователей доступа к прокси -->
<property>
<name>hadoop.proxyuser.root.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.root.groups</name>
<value>*</value>
</property>3. Перезапустите HDFS и Hive, а также запустите службы Metastore и HiveServer2 на сервере Hive.
nohup hive --service metastore >> ./nohup.out 2>&1 &
nohup hive --service hiveserver2 >> ./nohup.out 2>&1 &4. Подключаем Hive через билайн на клиенте
[root@node3 test]# beeline
beeline> !connect jdbc:hive2://node1:10000 root
Enter password for jdbc:hive2://node1:10000: Если у вас нет пароля, просто пропустите его.
0: jdbc:hive2://node1:10000> show tables;
+------------------------------------+
| tab_name |
+------------------------------------+
| personinfo |
| test2 |
+------------------------------------+После завершения вышеуказанной настройки вам также необходимо отправить настроенный файл core-site.xml по пути /root/test, соответствующему каждому узлу NiFi, чтобы заменить исходный файл core-site.xml. Затем перезапустите кластер NiFi и выполните команду на каждом узле NiFi:
service nifi restart7. Настройте процессор PutHiveQL.
«PutHiveQL» в основном выполняет команды HiveQL DDL/DML. Содержимое FlowFile, передаваемое процессору, является выполняемой командой HiveQL. Команды HiveQL могут использовать «?» для указания параметров. В этом случае параметры должны существовать в свойствах FlowFile. Соглашение об именах — hiveql.args.N.type и hiveql.args.N.value, где N — положительное значение. целое число.
Описание основной настройки «Свойства» процессора «PutHiveQL» следующее:
Элементы конфигурации | значение по умолчанию | разрешенные значения | описывать |
|---|---|---|---|
Служба пула подключений к базе данных Hive (Служба пула подключений к базе данных Hive) | Служба Hive Controller, используемая для подключения к базе данных Hive. | ||
Размер партии (размер партии) | 100 | Количество FlowFiles, прочитанных за один пакет. | |
Набор символов (кодировка) | UTF-8 | Укажите формат кодирования данных. | |
Разделитель операторов (разделитель операторов) | ; | Разделитель операторов, используемый для разделения операторов SQL в нескольких сценариях операторов. | |
Откат при сбое (откат в случае неудачи) | false | ▪true ▪false | Укажите, как обрабатывать ошибки. Значение по умолчанию false означает, что если при обработке FlowFile возникает ошибка, FlowFile будет перенаправлен в отношение «сбой» или «повторная попытка» в зависимости от типа ошибки, и процессор продолжит обработку следующего FlowFile. Вместо этого ему можно установить значение true, чтобы откатить обрабатываемый в данный момент FlowFile и немедленно прекратить дальнейшую обработку. Если этот параметр включен установкой значения true, неудавшиеся FlowFiles останутся во входной связи и будут обрабатываться повторно до тех пор, пока они не будут успешно обработаны или иным образом не удалены. Вы можете установить достаточно большую продолжительность доходности, чтобы избежать слишком большого количества повторных попыток. |
“PutHiveQL”процессориз Конфигурация следующая:
1. Создайте процессор PutHiveQL.
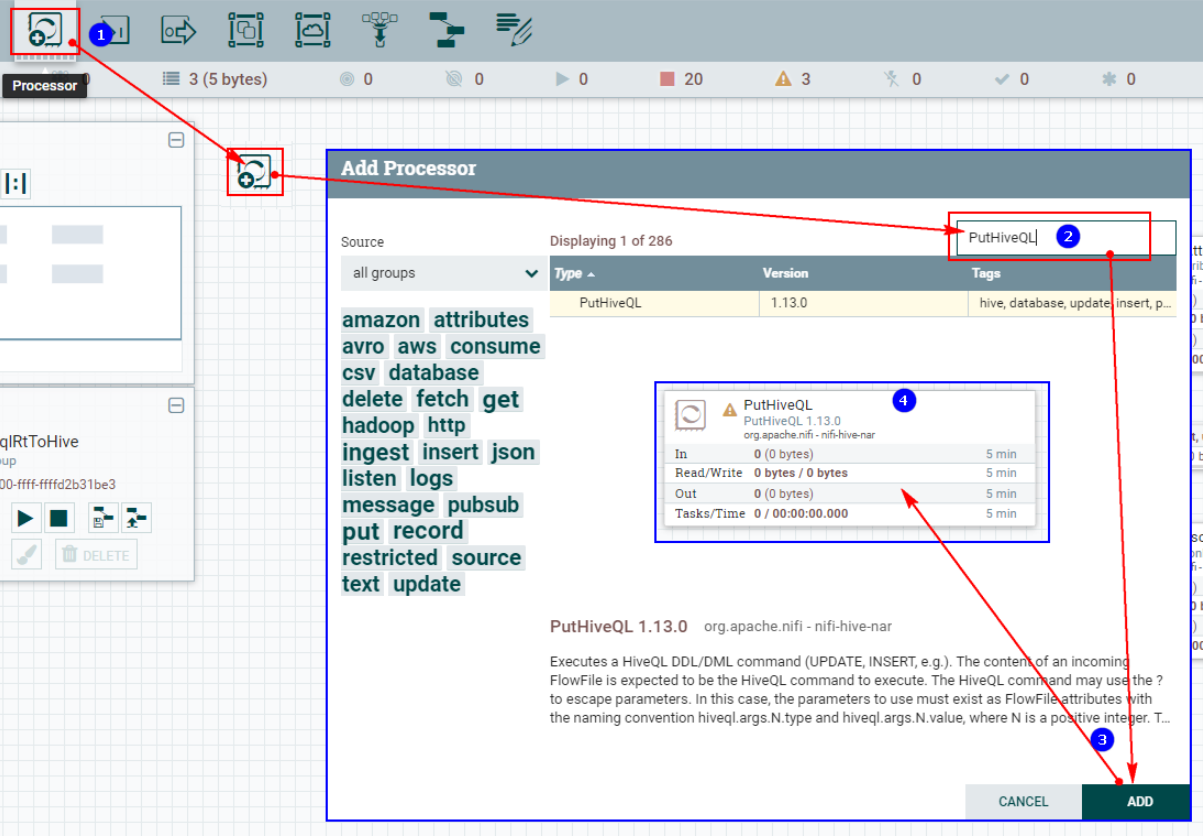
2. Настройте «СВОЙСТВА»
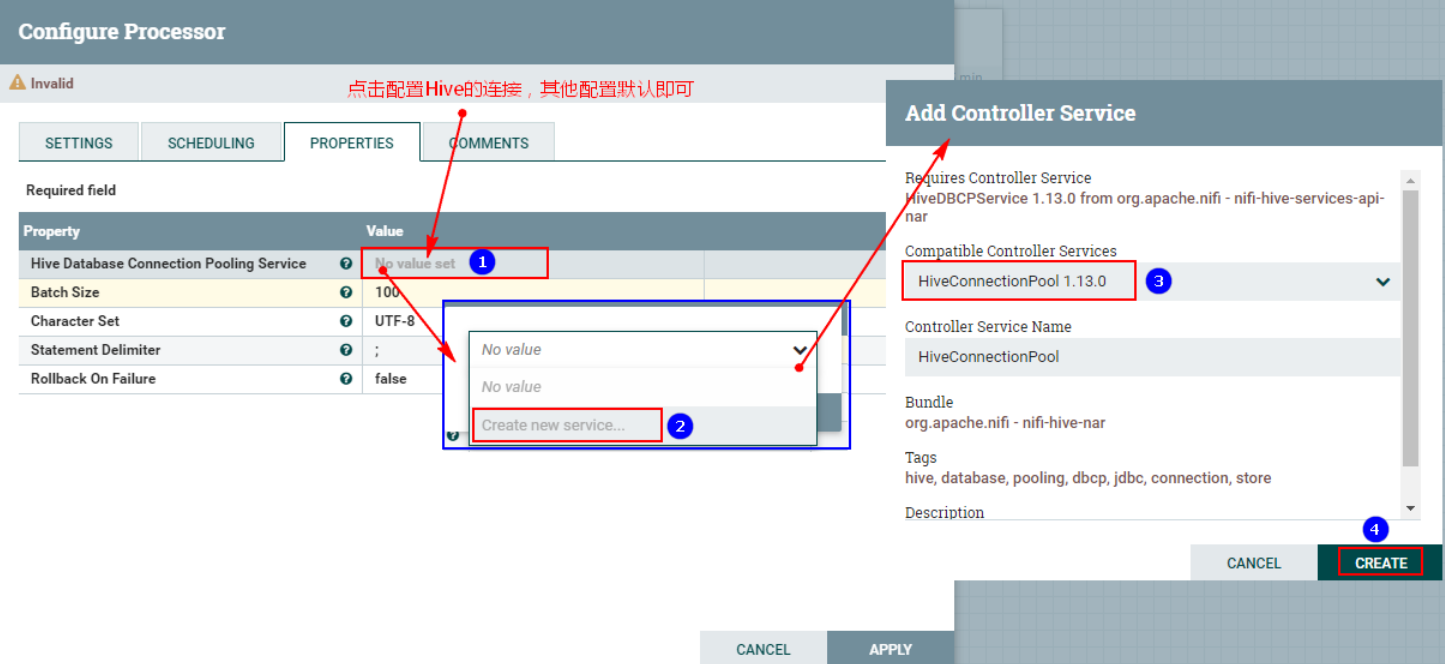
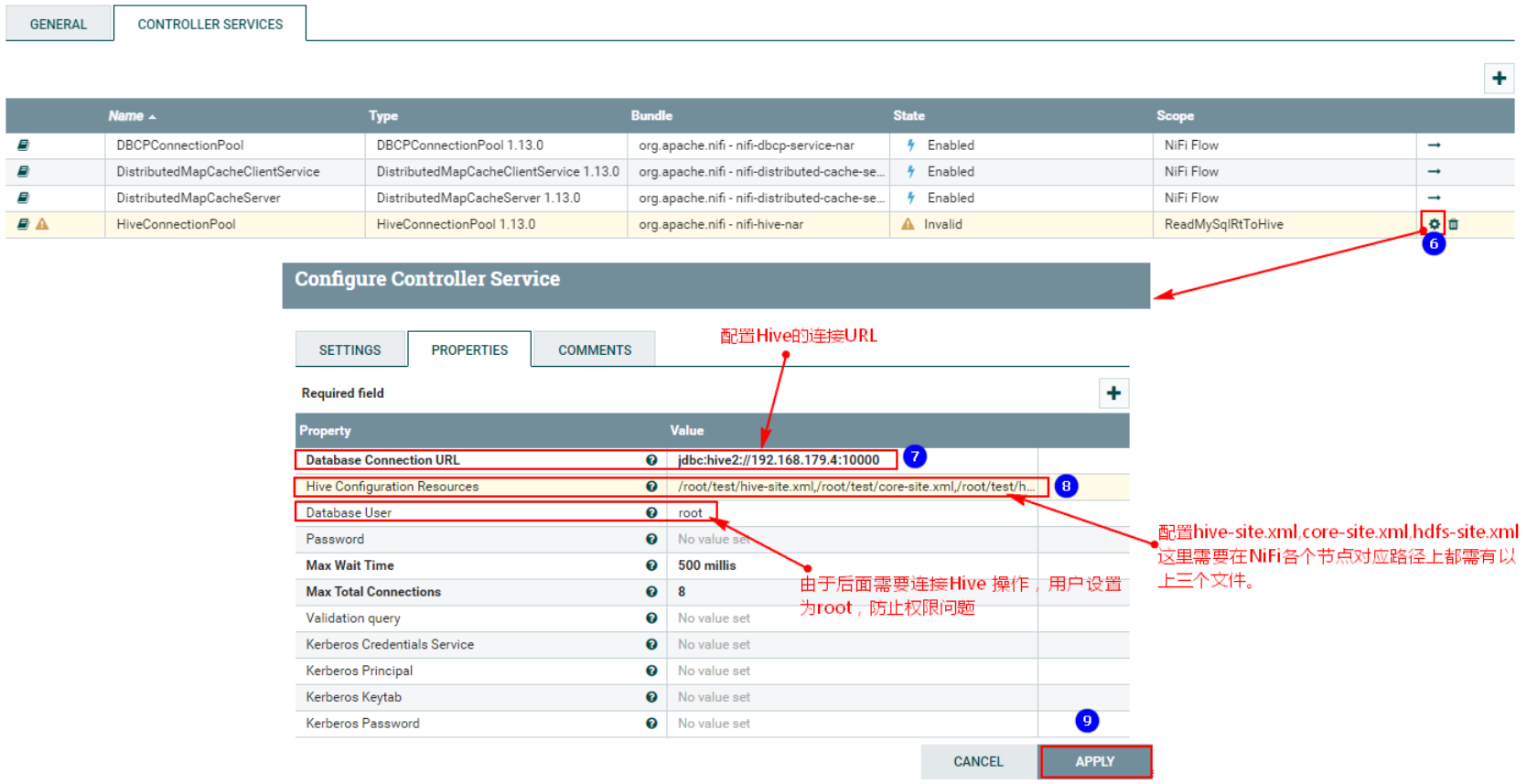
После нажатия настройте службу управления «HiveConnectionPool»:
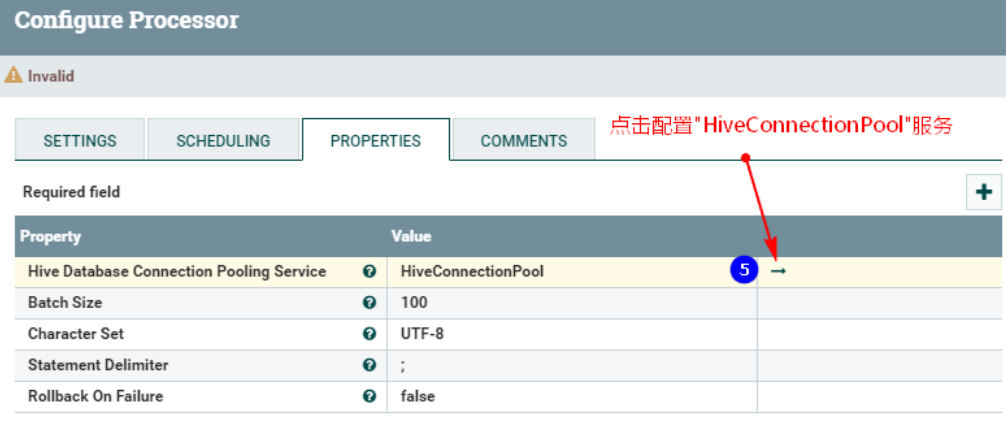
Обратите внимание, что приведенное выше требует настройки:
- «URL-адрес подключения к базе данных»: это узел, запущенный HiveServer2 Hive, который является узлом сервера. "jdbc:hive2://192.168.179.4:10000"
- «Ресурсы конфигурации Hive»: «/root/test/hive-site.xml,/root/test/core-site.xml,/root/test/hdfs-site.xml», сюда необходимо поместить указанные выше файлы. кластер NiFi. Соответствующие позиции каждого узла готовы.
- «Пользователь базы данных»: root, здесь для предотвращения проблем с разрешениями при работе HDFS, соответствующей Hive.
После завершения настройки необходимо включить соответствующую службу управления «HiveConnectionPool»:

Окончательная конфигурация «СВОЙСТВА»:
3. Соедините процессор «ReplaceText» и процессор «PutHiveQL» и установите связь

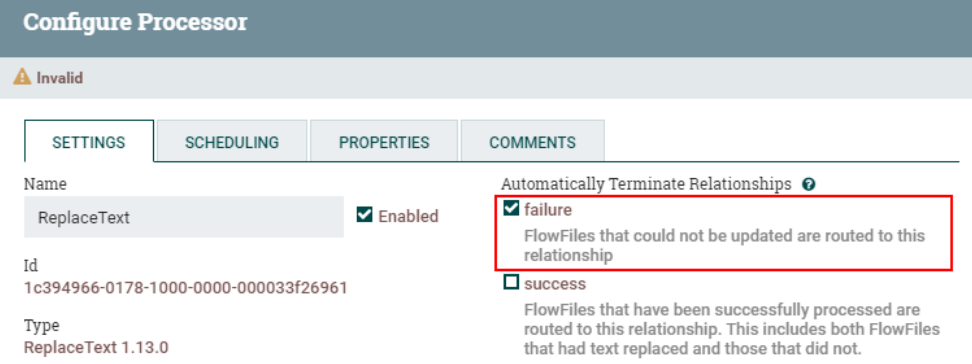
Установите отношение маршрутизации «сбой» обработчика «ReplaceText» для автоматического завершения:
Установите взаимосвязь маршрутизации процессора PutHiveQL для автоматического завершения:
8. Запустите тест
1. Создайте таблицу «test2» в Hive.
Переместите HDFS, запустите сервер и клиент Hive и создайте таблицу «test2».
create table test2 (id int,name string,age int )row format delimited fields terminated by '\t';2. Запустите процесс обработки данных NiFi, запишите данные в MySQL и просмотрите данные таблицы в Hive.
Сначала очистите статус процессора «CaptureChangeMySQL», запустите процессор «CaptureChangeMySQL» отдельно, очистите повторно использованные данные (вышеупомянутое в основном сделано для того, чтобы избежать этой версии ошибки NiFi) и запустите другие процессоры NiFi в текущем случае.
Затем вставьте следующие данные в MySQL:
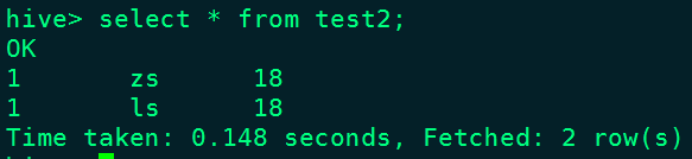
insert into test2 values (1,"zs",18);
update test2 set name = "ls" where id = 1;
delete from test2 where id = 1;Страница Ни Фи:

Результаты в таблице Hive test2:



Углубленный анализ переполнения памяти CUDA: OutOfMemoryError: CUDA не хватает памяти. Попыталась выделить 3,21 Ги Б (GPU 0; всего 8,00 Ги Б).

[Решено] ошибка установки conda. Среда решения: не удалось выполнить первоначальное зависание. Повторная попытка с помощью файла (графическое руководство).

Прочитайте нейросетевую модель Трансформера в одной статье

.ART Теплые зимние предложения уже открыты

Сравнительная таблица описания кодов ошибок Amap

Уведомление о последних правилах Points Mall в декабре 2022 года.

Даже новички могут быстро приступить к работе с легким сервером приложений.

Взгляд на RSAC 2024|Защита конфиденциальности в эпоху больших моделей

Вы используете ИИ каждый день и до сих пор не знаете, как ИИ дает обратную связь? Одна статья для понимания реализации в коде Python общих функций потерь генеративных моделей + анализ принципов расчета.

Используйте (внутренний) почтовый ящик для образовательных учреждений, чтобы использовать Microsoft Family Bucket (1T дискового пространства на одном диске и версию Office 365 для образовательных учреждений)

Руководство по началу работы с оперативным проектом (7) Практическое сочетание оперативного письма — оперативного письма на основе интеллектуальной системы вопросов и ответов службы поддержки клиентов

[docker] Версия сервера «Чтение 3» — создайте свою собственную программу чтения веб-текста

Обзор Cloud-init и этапы создания в рамках PVE

Корпоративные пользователи используют пакет регистрационных ресурсов для регистрации ICP для веб-сайта и активации оплаты WeChat H5 (с кодом платежного узла версии API V3)

Подробное объяснение таких показателей производительности с высоким уровнем параллелизма, как QPS, TPS, RT и пропускная способность.

Удачи в конкурсе Python Essay Challenge, станьте первым, кто испытает новую функцию сообщества [Запускать блоки кода онлайн] и выиграйте множество изысканных подарков!

[Техническая посадка травы] Кровавая рвота и отделка позволяют вам необычным образом ощипывать гусиные перья! Не распространяйте информацию! ! !

[Официальное ограниченное по времени мероприятие] Сейчас ноябрь, напишите и получите приз

Прочтите это в одной статье: Учебник для няни по созданию сервера Huanshou Parlu на базе CVM-сервера.

Cloud Native | Что такое CRD (настраиваемые определения ресурсов) в K8s?

Как использовать Cloudflare CDN для настройки узла (CF самостоятельно выбирает IP) Гонконг, Китай/Азия узел/сводка и рекомендации внутреннего высокоскоростного IP-сегмента

Дополнительные правила вознаграждения амбассадоров акции в марте 2023 г.

Можно ли открыть частный сервер Phantom Beast Palu одним щелчком мыши? Супер простой урок для начинающих! (Прилагается метод обновления сервера)

[Играйте с Phantom Beast Palu] Обновите игровой сервер Phantom Beast Pallu одним щелчком мыши

Maotouhu делится: последний доступный внутри страны адрес склада исходного образа Docker 2024 года (обновлено 1 декабря)

Кодирование Base64 в MultipartFile

5 точек расширения SpringBoot, супер практично!

Глубокое понимание сопоставления индексов Elasticsearch.

15 рекомендуемых платформ разработки с нулевым кодом корпоративного уровня. Всегда найдется та, которая вам понравится.
