Автоматизированный механизм обработки данных AIDE | Автоматически выявляйте проблемы, автоматически маркируйте и улучшайте модели, больше не полагаясь на большое количество маркировок данных вручную!

Системы автономных транспортных средств (AV) полагаются на надежные модели восприятия как на краеугольный камень обеспечения безопасности. Однако объекты, встречающиеся на дороге, имеют длиннохвостое распределение с редкими или невидимыми классами, что создает проблемы для используемых моделей восприятия. Это требует большого количества рабочей силы для непрерывного редактирования и аннотирования данных. Предложение автора использует последние достижения в области визуальных языков и больших языковых моделей для разработки автоматического механизма обработки данных (AIDE), который может автоматически выявлять проблемы, эффективно управлять данными, улучшать модель посредством автоматического аннотирования и проверять модель путем создания различных сценариев. Этот процесс является итеративным, что позволяет модели постоянно улучшаться. Авторы также устанавливают эталон для обнаружения открытого мира в наборах AV-данных для всесторонней оценки различных парадигм обучения, демонстрируя превосходную производительность нашего метода при одновременном снижении затрат.
1 Introduction
Автономные транспортные средства (AV) работают в постоянно меняющемся мире, сталкиваясь с множеством объектов и ситуаций в длинном хвосте распределения. Открытый мир создает серьезные проблемы для AV-систем, поскольку это критически важное для безопасности приложение, в котором необходимо использовать надежные и хорошо обученные модели. По мере развития среды становится очевидной необходимость постоянного совершенствования модели, требующая адаптивности для реагирования на непредвиденные события.
Несмотря на огромный объем данных, собираемых каждую минуту в дороге, их эффективное использование остается низким из-за сложности определения того, какие данные стоит использовать. Хотя решения этой проблемы существуют в отрасли [1, 2], они часто являются коммерческой тайной и могут потребовать большого количества рабочей силы. Таким образом, разработка комплексного механизма обработки данных для автоматизации может снизить входной барьер в индустрию автономного вождения.
Разработка автоматизированных механизмов обработки данных может быть сложной задачей, но существование моделей визуального языка (VLM) и больших языковых моделей (LLM) открывает новые возможности для решения этих сложных проблем. Традиционные механизмы обработки данных можно разделить на такие этапы, как обнаружение проблем, обработка и аннотирование данных, обучение и оценка моделей, все из которых могут выиграть от автоматизации.
В этой статье авторы предлагают механизм автоматического улучшения данных (называемый AIDE), который использует VLM и LLM для автоматизации механизма данных. В частности, авторы используют VLM для выявления проблем, запроса соответствующих данных, автоматического аннотирования данных и проверки их вместе с LLM. Шаги высокого уровня показаны в верхней части рисунка 1.
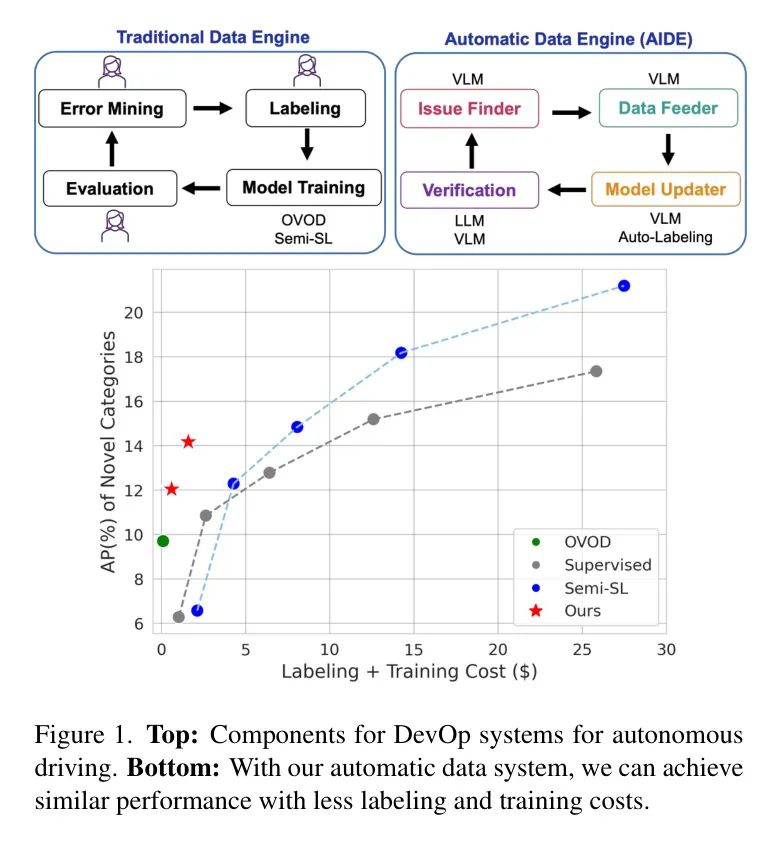
По сравнению с традиционными механизмами обработки данных, которые полагаются на обширное ручное аннотирование и вмешательство, AIDE автоматизирует этот процесс, используя предварительно обученные модели визуального языка (VLM) и большие языковые модели (LLM). В отличие от других собственных решений в отрасли [1, 2], авторы предлагают эффективное решение для снижения входного барьера. Хотя методы обнаружения объектов с открытым словарем (OVOD) [3, 4] не требуют каких-либо ручных аннотаций и служат хорошей отправной точкой для обнаружения новых объектов, их производительность на наборах данных автономного вождения (AV) недостаточна по сравнению с методами контролируемого обучения. . Еще одним направлением исследований, направленным на минимизацию затрат на аннотирование, является полуконтролируемое обучение [5, 6] и активное обучение [7, 8, 9, 10]. Хотя они генерируют псевдометки, они все же не в полной мере используют большой объем данных, собранных в дороге, по сравнению с методом авторов, который использует предварительно обученные VLM и LLM для лучшего использования данных.
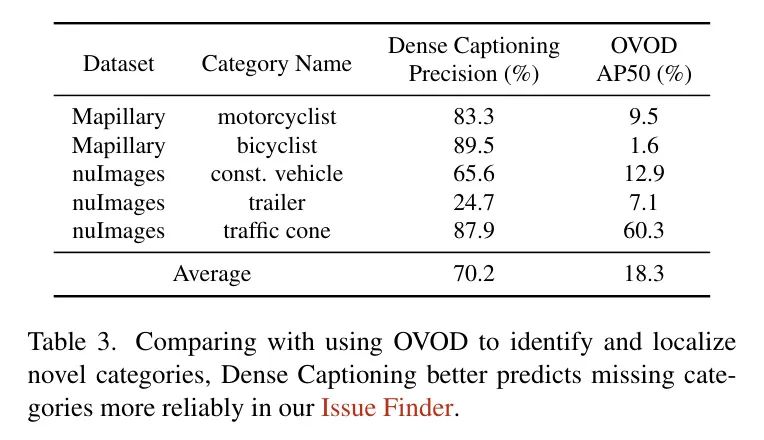
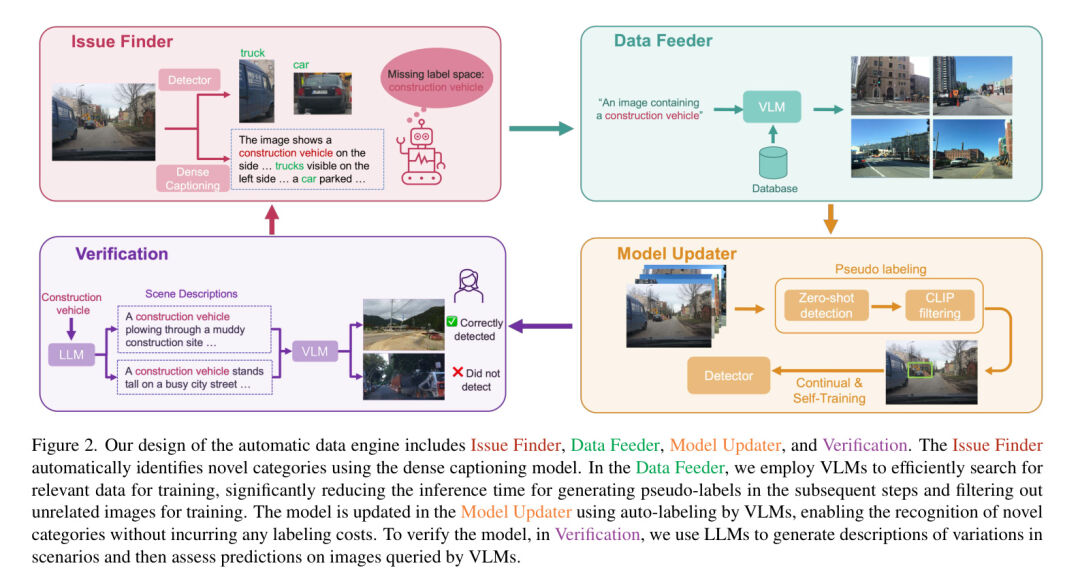
Подробные шаги AIDE показаны на рисунке 2. В средстве поиска проблем авторы используют модель плотных подписей для подробного описания изображений, а затем сопоставляют, включены ли объекты в описании в пространство меток или в прогнозы. Это основано на разумном, но ранее не использованном предположении, что модели с подписями к крупным изображениям более надежны, чем OVOD (таблица 3) в условиях нулевого кадра. Следующим шагом будет использование канала данных автора для поиска подходящих изображений, которые могут содержать новую категорию. Авторы обнаружили, что VLM приводит к более точному поиску изображений, чем использование сходства изображений для поиска изображений (таблица 4).
Затем авторы используют существующее пространство меток плюс новый метод OVOD подсказки категории, а именно OWL-v2 [11], для генерации прогнозов для изображений Query. Чтобы отфильтровать эти ложные предсказания, авторы используют CLIP для выполнения нулевой классификации ложных блоков для создания псевдометок для новых категорий. Наконец, авторы используют LLM для проверки, например ChatGPT [12], для создания разнообразных описаний сцен для индивидуальных новых объектов. Учитывая сгенерированные описания, авторы снова используют изображения, связанные с VLM Query, для оценки обновленной модели. Чтобы обеспечить точность, авторы попросили людей проверить, верны ли предсказания для новых категорий. В случае ошибки авторы просят людей предоставить достоверные метки, которые используются для дальнейшего улучшения модели. (рис. 6)

Чтобы проверить эффективность авторской среды разработки искусственного интеллекта (AIDE), автор предлагает новый тест для всестороннего сравнения авторской AIDE с другими парадигмами на существующих наборах аудиовизуальных (AV) данных. Благодаря нашему средству поиска проблем, средству подачи данных и средству обновления моделей мы достигаем повышения средней точности (AP) на 2,3% для новых категорий по сравнению с OWL-v2 без каких-либо ручных аннотаций и превосходит OWL-v2 с AP на 8,9% для известных категорий (таблица 1). ). Автор также продемонстрировал, что за один раунд проверки автоматический механизм обработки данных автора может дополнительно повысить AP на 2,2% для новых категорий, не забывая при этом известные категории, как показано на рисунке 1. В целом вклад автора двоякий:
Авторы предлагают новую парадигму проектирования автоматического механизма обработки данных для автономного вождения, который сочетает в себе автоматический запрос данных и аннотирование с использованием моделей визуального языка (VLM) и непрерывное обучение с использованием псевдометок. При распространении на новые категории этот подход обеспечивает отличный баланс между производительностью обнаружения и стоимостью данных.
Авторы представляют новый эталон для оценки этого автоматизированного механизма обработки данных для визуального восприятия автономного вождения, который способен предоставить комплексную информацию в рамках различных парадигм, таких как обнаружение открытого словаря, полуконтролируемое и непрерывное обучение.
2 Related Works
Механизм данных автономного транспортного средства (AV) Использование крупномасштабных данных, собранных автономными транспортными средствами, имеет решающее значение для ускорения итеративной разработки AV-систем [13]. В существующей литературе основное внимание уделяется разработке универсальных [14, 15] механизмов обучения или конкретных [16] механизмов обработки данных, большинство из которых [17, 18] в основном фокусируется на части обучения модели. Однако полнофункциональный механизм AV-данных требует выявления проблем, сортировки данных, переобучения модели, проверки и т. д. Тщательный обзор выявляет отсутствие систематических исследовательских работ или литературы, подробно изучающих механизмы AV-данных в академических кругах, а недавний опрос [13] также подчеркивает отсутствие исследований в этой области. С другой стороны, существующие решения для AV-систем данных [1, 2] В основном полагается на проектирование инфраструктуры данных, которая по-прежнему требует большого количества рабочей силы и вмешательства, что ограничивает простоту ее обслуживания, доступность и масштабируемость. Напротив, в этой статье используются модели визуального языка (VLM) [19, 20, 21] для разработки авторского движка данных, где их мощная осведомленность об открытом мире значительно улучшает масштабируемость авторского движка, делая более доступным расширение AV автора при обнаружении новых категорий. Насколько известно автору, эта статья также представляет собой первую систематическую проектную работу по интеграции VLM в механизмы AV-данных.
Новое обнаружение целей За последние несколько десятилетий традиционное обнаружение 2D-объектов добилось большого прогресса [22, 23], но его закрытое пространство меток делает невозможным обнаружение невидимых категорий. С другой стороны, обнаружение объектов с открытым словарем (ОВОД) [4, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39] обещает обнаружить любой объект с помощью простой текстовой подсказки. Однако, поскольку они должны поддерживать баланс между специфичностью для предварительно обученных категорий и обобщением для невидимых категорий, их производительность по-прежнему уступает обнаружению объектов с закрытым набором. Чтобы расширить возможности детекторов открытого словаря (OVD), недавние исследования либо предварительно обучали OVD с использованием слабых аннотаций (например, подписей к изображениям) [40], либо обучали их на повседневных целевых наборах данных [41, 42] или наборы данных веб-масштаба [4, 43] для выполнения самотренировки. Однако компромисс между улучшением новых категорий и смягчением катастрофического забывания известных категорий остается нерешенной проблемой [11], что затрудняет адаптацию к приложениям для конкретных задач, таким как автономное вождение.
С другой стороны, ограниченные исследования сосредоточены на обнаружении новых объектов для автономных транспортных средств (AV). Это особенно важно, поскольку ложноотрицательные обнаружения невидимых объектов могут привести к фатальным последствиям для беспилотных транспортных средств. Большинство существующих методов обнаружения объектов в открытом мире (OVOD) тестируются на общих наборах данных объектов [44, 42], в то время как больше внимания уделяется наборам данных автономных транспортных средств [45, 46, 47, 48, 49, 50]. В отличие от стремления к универсальности в OVOD, восприятие беспилотных транспортных средств имеет свои проблемы, связанные с процессом изображения, снятого бортовой камерой, и категорией объекта, определенной предшествующей сценой (например, дороги/уличные объекты), что требует Выполните проектирование для конкретной задачи, чтобы создать эффективную и масштабируемую систему, которая итеративно улучшает обнаружение новых объектов на протяжении всего срока службы транспортного средства. Чтобы достичь лучшего компромисса между специфичностью и общностью, метод AIDE, предложенный авторами, итеративно расширяет пространство меток детектора с закрытым набором, так что авторы могут поддерживать хорошую производительность как по новым, так и по известным категориям, чтобы обеспечить лучшее обнаружение.
Полуконтролируемое обучение (Semi-SL) и активное обучение (AL). Поскольку автономные транспортные средства (AV) продолжают собирать данные во время работы, естественным решением, позволяющим обнаруживать новые категории, является ручной сбор немаркированных наборов данных. Определите новые категории, пометьте их. их, а затем обучить детектор. Обучение с полуконтролем и активное обучение, по-видимому, помогают, поскольку для инициализации обучения им требуется лишь небольшое количество размеченных данных. Однако, когда AV получают большие объемы неразмеченных данных, маркировка даже небольших объемов данных для новых категорий будет сложной и дорогостоящей задачей. Более того, как полуконтролируемое обучение, так и активное обучение предполагают, что размеченные и неразмеченные данные поступают из одного и того же распределения и используют одно и то же пространство меток. Однако когда появляются новые категории, это предположение перестает действовать, что неизбежно приводит к изменениям в пространстве меток. Простая настройка детектора на новые категории приведет к катастрофическому забыванию ранее изученных известных категорий [64, 65, 66]. Однако методы полуконтролируемого обучения для обнаружения целей не учитывают непрерывное обучение, а существующие методы непрерывного полуконтролируемого обучения [67, 68, 69, 70] также специально нацелены на классификацию изображений и не подходят для обнаружения целей.
3 Method
В этом разделе представлена предложенная автором AIIDE, которая состоит из четырех компонентов: средства поиска проблем, средства подачи данных, средства обновления модели и проверки. Средство поиска проблем автоматически определяет недостающие категории в существующем пространстве меток, сравнивая результаты обнаружения и плотные подписи для данного изображения. Это заставляет механизм подачи данных выполнять поиск соответствующих изображений с помощью текста из большой библиотеки изображений, собранной AV. Затем средство обновления модели автоматически маркирует изображения Query и использует псевдометки для непрерывного обучения новым категориям на существующих детекторах. Обновленный детектор затем передается в модуль проверки, где он оценивается по различным сценариям и при необходимости запускает новую итерацию. Авторы обрисовывают авторский дизайн системы на рисунке 2.
Issue Finder
Учитывая большой объем немаркированных данных, собираемых автономными транспортными средствами в повседневной работе, выявление недостающих категорий в существующем пространстве меток затруднено, поскольку это требует от людей тщательного сравнения результатов обнаружения и контекста изображения, чтобы найти различия, что затрудняет автономное вождение. Итеративная разработка системы . Чтобы уменьшить эту трудность, авторы рассматривают возможность использования модели Multi-modal Dense Caption Generation (MMDC) для автоматизации этого процесса.
Поскольку модели MMDC, такие как Otter [20], обучаются с использованием миллионов мультимодальных контекстных наборов данных, настроенных с помощью инструкций, они способны предоставлять детальные и полные описания контекста сцены, как показано на рисунке 3, и авторы предполагают, что они могут быть с большей вероятностью, чем методы OVOD, будут возвращать синонимы для искомой метки для новой категории, а не обнаруживать ограничивающие рамки для новой категории. В частности, немаркированные изображения будут передаваться в детектор и модель MMDC, развернутые на транспортном средстве, соответственно, для получения прогнозируемого списка классов и подробного описания изображения. Благодаря базовой обработке текста авторы могут легко идентифицировать новые категории, которые модель не может обнаружить. В этом случае механизм данных автора запускает изображения, связанные с запросом источника данных, для постепенного обучения детектора, соответственно расширяя его пространство меток.

Data Feeder
Целью механизма подачи данных является, прежде всего, обеспечение потенциального содержания в запросе новых категорий значимых изображений.
(1) Уменьшите пространство поиска псевдоразметки и ускорьте процесс псевдоразметки в Model Updater.
(2) Удаляя тривиальные или нерелевантные изображения во время обучения, авторы могут сократить время обучения и одновременно повысить производительность.
Это особенно важно в реальных сценариях, где каждый день можно собирать большие объемы данных. Поскольку новые категории могут быть произвольными и иметь открытый словарный запас, простым решением является использование сходства признаков, например сходства признаков изображения, с помощью CLIP [71] для поиска изображений, похожих на входное изображение Issue Finder.
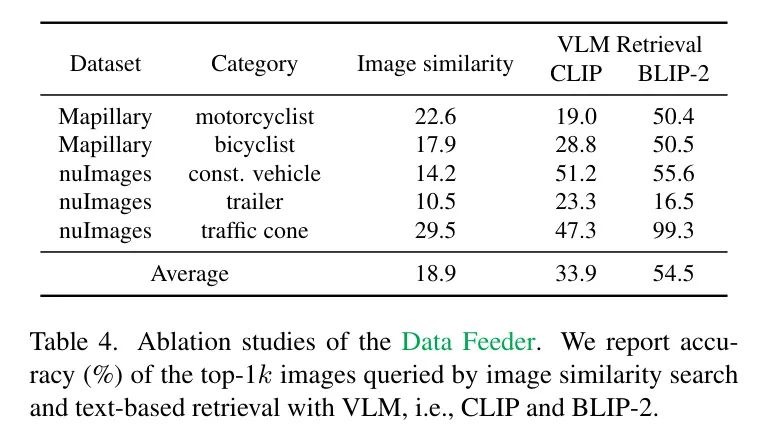
Однако авторы обнаружили, что сходство изображений не может надежно идентифицировать достаточное количество связанных изображений из-за большого разнообразия набора AV-данных (см. Таблицу 4). Вместо этого источник данных авторов использует модели визуального языка (VLM) для выполнения поиска изображений по тексту из пула изображений для запроса изображений, относящихся к новым категориям. Авторы выбрали BLIP-2 [21], учитывая его сильные возможности в поиске текста по открытому словарю. В частности, учитывая изображение и конкретный текстовый ввод, авторы измеряют косинусное сходство между их вложениями из BLIP-2 и извлекают только верхние значения.
изображения для дальнейшей аннотации в авторском апдейтере модели. Для текстовых подсказок авторы использовали общепринятые методы разработки подсказок. [71] и обнаружил, что "Включать
изображение" Такие шаблоны на практике могут легко обеспечить хорошую точность и запоминаемость новых категорий. На рисунке 4 показано несколько примеров полученных изображений.

Model Updater
Цель средства обновления модели авторов — позволить детектору научиться обнаруживать новые объекты без комментариев человека. Для этого мы псевдомаркируем изображения из потока данных Query, а затем используем их для обучения нашего детектора.
3.3.1 Two-Stage Pseudo-Labeling
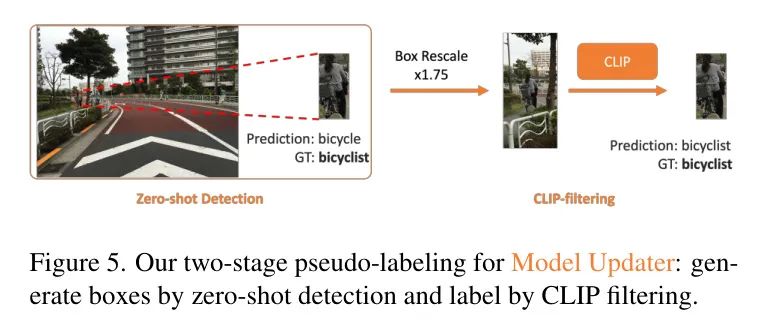
Вдохновленный предыдущим успехом псевдомаркировки при обнаружении целей [41], автор разделил процесс псевдомаркировки на две части: генерацию блоков и генерацию меток. Эта двухэтапная структура может помочь авторам лучше проанализировать проблему генерации псевдометок и улучшить качество генерации меток. Целью создания блоков является максимально возможное определение нескольких целевых предложений на изображении, то есть позиционирование новых категорий с высокой запоминаемостью, чтобы обеспечить достаточное количество кандидатов для создания меток. С этой целью можно рассмотреть возможность использования сети предложений регионов (RPN), предварительно обученной на закрытом пространстве меток [41] и открытого словарного детектора (OVD) [11], где первая может находить универсальные цели, а вторая может выполнять текстовые операции. руководимое положение. Авторы отмечают, что современный OVD, а именно OWL-v2 [11], который самообучается на наборе данных веб-уровня [43], демонстрирует более высокую эффективность поиска новых категорий по сравнению с RPN. Автор предполагает, что предложение RPN может быть легко смещено в сторону предварительно обученных категорий.
Поэтому автор выбирает OWL-v2 в качестве авторского детектора нулевого выстрела для получения предложения ограничивающего прямоугольника. В частности, автор добавляет новые имена категорий, предоставленные системой поиска вопросов, к существующему пространству меток автора и создает текстовую подсказку, которая затем предлагает OWL-v2 рассуждать об изображении. Обратите внимание, что авторы сохраняют только ограничивающую рамку Предложения и удаляют метки из прогнозов OWL-v2.
Это связано с тем, что авторы эмпирически обнаружили, что OWL-v2 не может обеспечить надежную точность по новым категориям, представленным в наборах AV-данных, например, средняя точность по новым категориям в наборах AV-данных составляет менее 10% [45, 50], а более 40 % AP можно получить по новым категориям набора данных LVIS [42]. Авторы предполагают, что такое снижение производительности может быть вызвано сдвигами доменов в изображениях, собранных в AV-сценах. Например, данные перед обучением OWL-v2 в основном поступают из ежедневных изображений, снятых людьми с близкого расстояния. Однако из-за большого расстояния между бортовыми камерами и уличными объектами уличные объекты на изображениях обычно небольшие, а соотношение сторон изображения в наборе AV-данных относительно велико, что затрудняет правильную классификацию предложений объектов в OWL-v2. .
Вдохновленные этим открытием, авторы рассмотрели возможность использования CLIP [71] для еще одного раунда фильтрации меток, чтобы очистить предсказания OWL-v2 и генерировать псевдометки. В частности, авторы передают коробочные предсказания OWL-v2 исходной модели CLIP [71] для классификации с нулевым выстрелом (ZSC), как показано на рисунке 5. Чтобы устранить вышеупомянутые проблемы с соотношением сторон, авторы увеличивают размер поля, чтобы обрезать изображение, а затем отправляют обрезанные блоки изображения в CLIP для ZSC. Это может включать больше информации о контексте сцены, помогая CLIP лучше отличать новые категории от известных. Что касается пространства меток для классификации с нулевым выстрелом с помощью CLIP, автор сначала создал базовое пространство меток, которое он объединил из заранее обученного набора данных автора и пространства меток COCO [44], чтобы гарантировать, что автор может охватывают большинство возможных случаев. Объекты повседневного использования на улице. Когда средство поиска проблем определяет новые категории, которых нет в базовом пространстве меток, базовое пространство меток автоматически расширяется.
3.3.2 Continual Training with Pseudo-labels
Обучение непосредственно новым псевдометкам классов с помощью существующих детекторов является сложной задачей, поскольку эти метки могут привести к тому, что детектор переобучится и катастрофически забудет известные классы. Эта проблема возникает потому, что немаркированные данные могут содержать как новые категории, ранее изученные детектором, так и известные категории. Если для этих известных классов нет меток, а есть только метки для новых классов, модель может ошибочно подавить прогнозы для известных классов и сосредоточиться только на прогнозировании новых классов.
По мере обучения известные категории постепенно исчезают из памяти. Чтобы решить эту проблему, авторы черпают вдохновение из существующих стратегий самообучения и включают псевдометки известных категорий, которые были обучены. Поэтому существующие детекторы авторов пополняются новыми классами и псевдометками известных классов. Чтобы получить псевдометки известных категорий, авторы сначала используют детектор для анализа данных, а затем применяют к данным OWL-v2. Эмпирическим путем авторы обнаружили, что включение псевдометок для известных категорий помогает модели различать известные и новые категории, повышает производительность по новым категориям и облегчает проблему катастрофического забывания, связанную с известными категориями. Кроме того, учитывая, что псевдометки известных категорий и новых категорий могут быть несовершенными, авторы отсеивали псевдометки. Для известных категорий авторы используют детектор только для предсказания псевдометок с высокой степенью достоверности. Для новых категорий авторы интегрировали CLIP для фильтрации псевдометок, как описано в разделе 3.3.1.
Verification
Целью этапа проверки является оценка того, способен ли обновленный детектор обнаружить новый класс в различных контекстах, чтобы гарантировать, что модель сможет обрабатывать неожиданные или невидимые контексты. С этой целью авторы подсказывают ChatGPT [12] названия новых категорий для генерации разнообразных описаний сцен. Эти описания включают в себя различные вариации ситуации, например, различный внешний вид предмета, окружающих предметов, время суток, погодные условия и т. д.
Для описания каждой сцены авторы снова используют изображения, связанные с запросом BLIP-2, которые используются для проверки надежности модели. Чтобы обеспечить точность, авторы попросили людей проверить, верны ли предсказания для новых категорий. Если прогноз верен, детектор проходит модульный тест. В противном случае авторы просят людей предоставить достоверные метки, которые можно использовать для дальнейшего улучшения модели. По сравнению с существующими решениями, которые вручную проверяют прогнозы модели один за другим, авторский метод проверки использует большую языковую модель для поиска потенциальных случаев сбоя посредством создания разнообразных сценариев, что может значительно сэкономить затраты на поиск при проверке правильности обнаружения. Исправление ошибочного обнаружения также дешевле.
4 Experiments
Experimental Setting
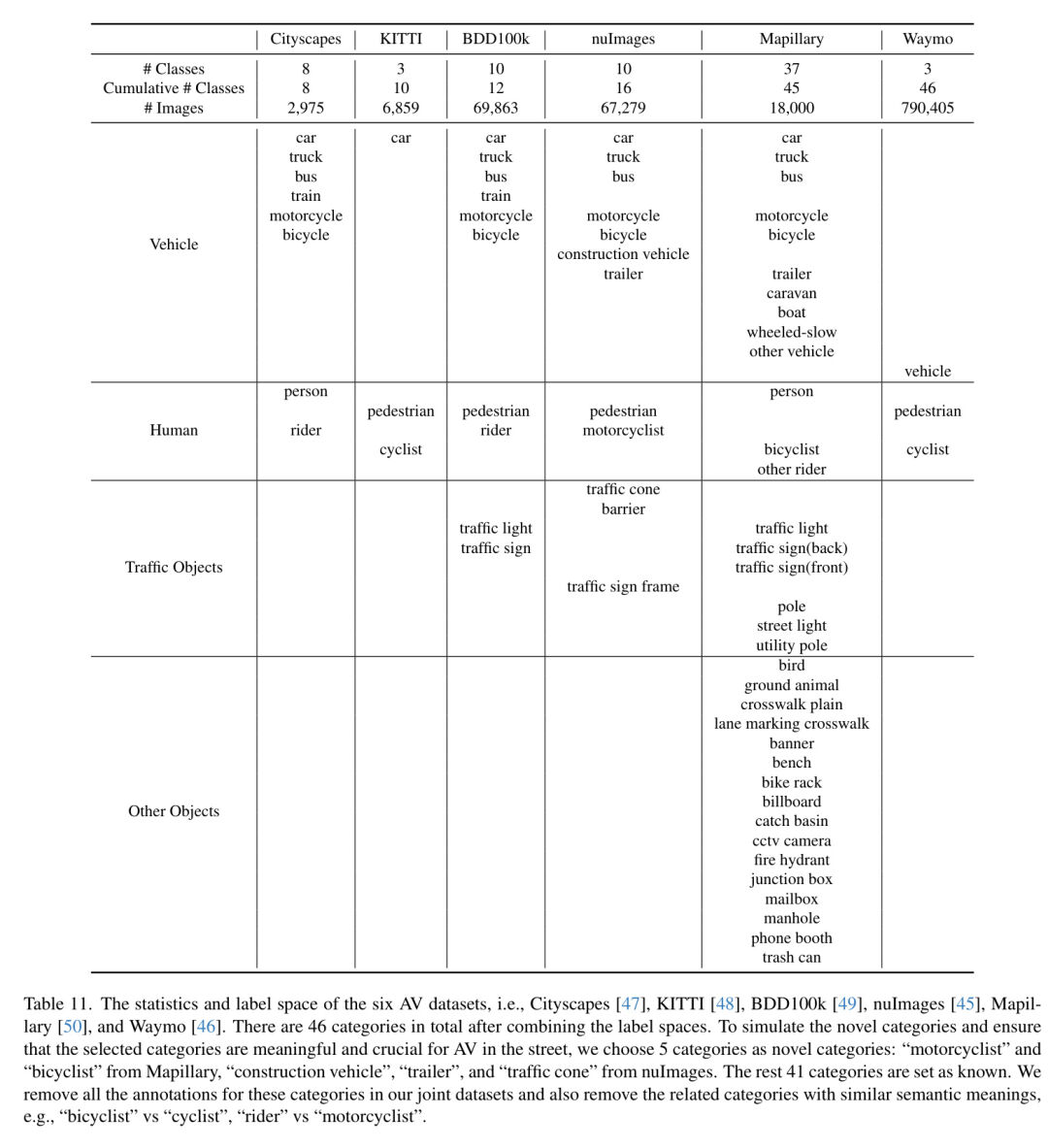
Выбор набора данных и новой категории В практических приложениях практически невозможно обучить системы автономного вождения только с одним источником данных. Например, автономные транспортные средства могут собирать данные в разных местах по всему миру. Чтобы реалистично смоделировать эту характеристику, автор использует существующие наборы данных автономного вождения для совместного обучения детектора закрытого набора автора, включая Mapillary [50],Cityscapes [47],nuImages [45],BDD100k [49],Вэймо [46] и КИТТИ [48]. Автор использует этот предварительно обученный детектор в качестве контролируемого обучения, полуконтролируемого обучения (Semi-SL) и инициализации авторской AIDE.,Чтобы сделать честное сравнение. После объединения пространств меток,Всего 46 категорий.
В целях моделирования новых типов категорий и обеспечения соответствия выбранной категории Автономному на ул. вождение имеет смысл и значение, автор из Mapillary «Мотоциклист» и «Велосипедист» были выбраны из nuImages «Строительная выбрана техника»、“трейлер”и“дорожный конус”。остальные41категории установлены как известные。Автор в Юнайтедданные Все аннотации для этих категорий были удалены коллективно.,а также удалили связанные категории со схожим смысловым значением,Например,«Велосипедист» против «Всадника». Более подробная информация о статистике набора данных,Об этом авторы предоставят в дополнительных материалах.
Метод сравнения Насколько известно авторам, мало работ по систематическому проектированию автоматических механизмов обработки данных для обнаружения новых объектов в системах автономного вождения. Поэтому сложно найти аналог авторской ПОМОЩНИКЕ.
Для этого авторы разбивают оценку на две части:
- существовать Новое обнаружение Сравните эффективность целей с альтернативными методами обнаружения и парадигмами обучения 2. Исследование абляции и анализ каждого шага работы автоматического механизма обработки данных.
Для (1), поскольку AIDE автора позволяет детектору обнаруживать новые категории без каких-либо меток, автор сначала сравнивает авторский метод с методом OVOD с нулевым выстрелом по производительности новой категории.
также,Продемонстрировать эффективность и результативность авторской ПОМОЩИ в снижении затрат на маркировку.,Далее автор сравнивает обучение с полуконтролем (Semi-SL) и обучением с полным учителем.,Последний обучает детектор, используя разные пропорции меток базовой истины. Конкретно,Автор сочетает авторский движок данных с современными (SOTA) методами OVOD, такими как OWL-v2 [11], OWL-ViT [4] и нравится Непредвзятый Учитель [5, 6] сравнили такие методы. обучение с полуконтролем.
Экспериментальный протокол Авторы рассматривают каждую из пяти выбранных категорий как новую категорию и проводят эксперименты отдельно, чтобы смоделировать сценарий, в котором наш инструмент поиска проблем идентифицирует по одной новой категории за раз. Для метода полуконтролируемого обучения авторы предоставляют для обучения различное количество реальных изображений. Каждое изображение может содержать одну или несколько новых категорий объектов. Авторы оценивают все методы сравнения на новых категориях наборов данных, чтобы обеспечить справедливое сравнение.
Оценивать Поскольку авторская среда разработки с использованием искусственного интеллекта (AIDE) — Автономное Автоматизация системы вождения Vision (AV) Пройдя весь процесс обработки данных, обучения и проверки модели, автор интересуется, как авторский движок балансирует затраты на поиск изображений и аннотирование с производительностью обнаружения новых объектов. Авторы измерили стоимость человеческих аннотаций [72], а также стоимость вывода графического процессора [73], используя визуальный язык Модель/большая языковая Модель в авторской AIDE и используя псевдометки для обучения Модели для авторской AIDE или используя GT Метка — это стоимость обучения модели методу сравнения, которая представлена на рисунке 1 как «аннотация + стоимость обучения». Стоимость маркировки ограничивающего прямоугольника составляет 0,06 доллара США [72], а стоимость графического процессора — 1,1 доллара в час [73]. Стоимость ChatGPT незначительна (менее 0,01 доллара США).
Подробности эксперимента Учитывая требования реального времени рассуждений, автор выбирает Fast-RCNN. [22] в качестве детектора вместо OWL-ViT [4] Такой метод ОВОД, потому что кадров в секунду (FPS) у OWL-ViT всего 3. Мы запустили нашу AIDE, чтобы итеративно улучшить ее способность обнаруживать новые цели. Для обучения с несколькими наборами авторы следуют тому же подходу, что и в [74]. Для каждой новой категории мы обучаем 3000 итераций со скоростью обучения 5e-4. Если другие методы сравнения требуют обучения, мы также используем те же гиперпараметры. Полные авторские Подробности автор прикрепит в дополнительном материале. эксперимента。
Overall Performance
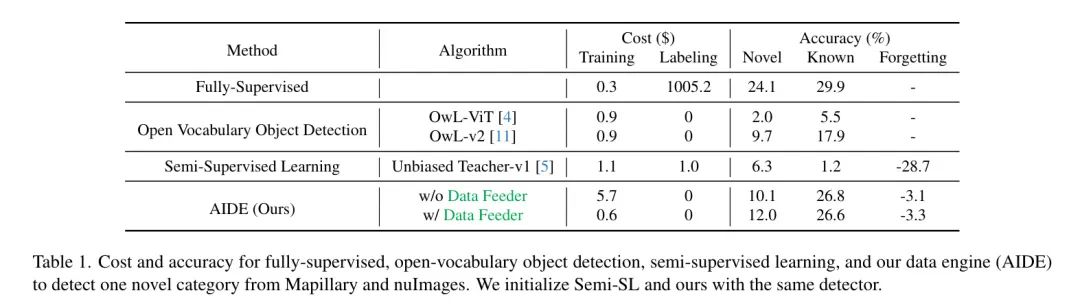
в этом разделе,Авторы приводят общую производительность обнаружения новых объектов после запуска авторского AIDE на полный цикл. Результаты авторов представлены на рисунке 1 и в таблице 1. С помощью современного современного метода ОВОД,OwL-v2 По сравнению с [11] авторский метод улучшил AP на 2,3% по новым категориям и на 8,7% AP по известным категориям, что указывает на то, что AIDE автора может извлечь выгоду из анализа знаний открытого словаря в методе OVOD.
Это связано с простой, но эффективной стратегией непрерывного обучения, описанной авторами в разделе 3.3.2. Более того, у AIDE автора гораздо меньше проблем с катастрофическим забыванием по сравнению с методами полуконтролируемого обучения, поскольку современные методы полуконтролируемого обучения не включают настройку непрерывного обучения при обнаружении объектов. Существующие исследования непрерывного полуконтролируемого обучения [67, 70] рассматривают только классификацию изображений и не применимы к обнаружению объектов. В сочетании с AIDE автора, независимо от того, используется ли механизм подачи данных или нет, очевидно, что механизм подачи данных автора может полностью сократить затраты времени на вывод, поскольку механизм подачи данных может предварительно фильтровать нерелевантные изображения, и необходимо только выделить средство обновления модели. на небольшом количестве релевантных изображений Псевдо-теги. Таблица 1 показывает, что предварительная фильтрация может повысить AP по новым категориям.
Analysis on AIDE
В следующих подразделах автор проанализирует каждую часть своей среды разработки ИИ (AIDE), чтобы проверить выбор дизайна, выбранный автором.
4.3.1 Issue Finder
Основная цель Finder — автоматическое определение категорий, которых нет в пространстве тегов. с этой целью,Автор Оценивать определил вероятность успеха при автоматическом выявлении новых категорий. Автор нашел,По сравнению с использованием методов ОВОД для выявления и обнаружения новых целей с учетом нового названия категории,Плотные субтитры Модель может автоматически более точно предсказать, будут ли новые категории включены в изображение.,Как показано в Таблице 3. пожалуйста, обрати внимание,Целью здесь является определение только недостающих категорий.,Поэтому автор решил использовать здесь плотные субтитры.,И используйте ОВОД, чтобы помочь обнаружить новые цели на последующих этапах.
4.3.2 Data Feeder
Цель устройства подачи данных — точно отфильтровать соответствующие данные из большого количества изображений. Автор сравнивает несколько вариантов,Включает поиск сходства изображений с помощью функций CLIP.,и поиск изображений с текстовым сопровождением через VLM (например, BLIP-2иCLIP). Автор сообщает топ-
Точность изображений Query показывает, что поиск по сходству изображений не так хорош, как VLM. Это связано с тем, что новые классы могут иметь большие вариации внутри класса, и одного изображения может быть недостаточно для поиска достаточного количества связанных изображений. По сравнению с CLIP, BLIP-2, выбранный авторами, в среднем показал лучшие результаты.
4.3.3 Model Updater
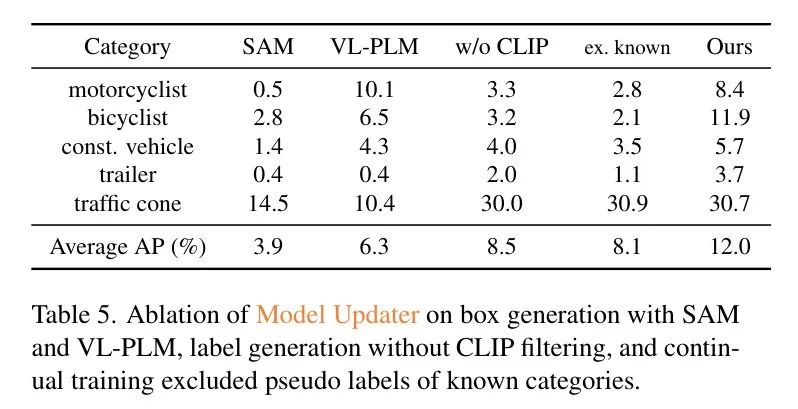
Ограничивающая рамка от автора к авторуи Дизайн генерации псевдометок провел эксперименты по абляции.。существовать Генерация ограничивающей рамки,Автор будетOWL-v2коробка Proposal Выбирайте с VL-PLM [41] Proposal Сравнение было проведено с MaskRCNN, предварительно обученным на COCO. площадь [75] Proposal Блок генерации сети (RPN) Proposal . Автор также использует Segment Любая модель (SAM) [16] Proposal Было проведено сравнение, конкретно авторы использовали FastSAM [76], поскольку он быстрее делает вывод, имея при этом ту же производительность, что и SAM.
Как показано в исследовании абляции в Таблице 5.,Автор решил использовать OWL-v2 как лучший выбор между VL-PLM и SAM. Автор заметил,ЗРК может генерировать множество мелких целей, не имеющих никакого смыслового значения.,Это подавляет эффективное количество псевдометок. Этого следовало ожидать,Потому что предобучение SAM не использует семантические метки. Для создания этикеток,Автор сравнил ситуацию с использованием прогнозирования OWL-v2 напрямую без CLIP-фильтрации.,то есть «не используйте CLIP»,Результаты показывают, что фильтрация тегов с помощью CLIP необходима. наконец,По сравнению с обучением нашего детектора без использования псевдометок известных классов,Отметить как «Исключить известные»,АП автора в категории романов выросла на 3,9%. также,Как показано в Таблице 1,АП известных категорий без использования псевдометок составляет всего 1,58%.,По авторскому методу – 26,6%. Это подтверждает эффект использования псевдометок известных категорий, обсуждавшийся в разделе 3.3.2.
4.3.4 Verification
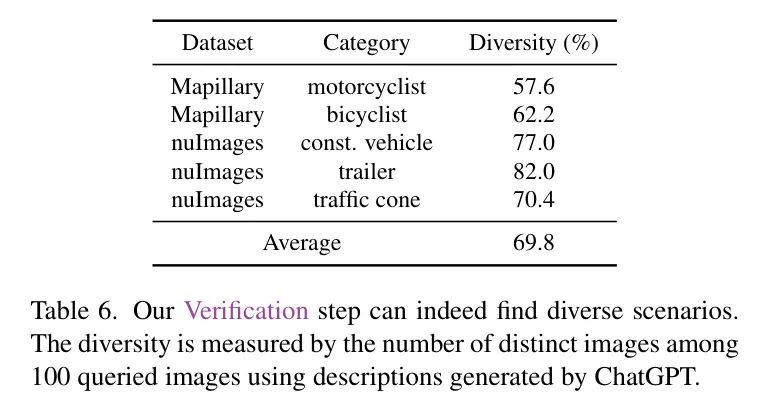
Цель проверки – надежность детектора Оценивать.,и проверьте производительность в нескольких сценариях. Людям нужно только проверить, верен ли прогноз в каждой ситуации.,Это снижает затраты на мониторинг,Потому что ситуация разнообразная,Проверка прогнозов занимает меньше времени, чем маркировка. Проверить, разнообразны ли сгенерированные сценарии.,Автор генерирует описание через Query Измерьте количество уникальных изображений из 100 и повторите этот процесс десять раз. Как показано в Таблице 6, проверка авторов действительно обнаруживает разнообразные контексты: в среднем 69,8% изображений являются уникальными, даже в таком небольшом наборе обучающих данных.
Если прогноз неверен, авторы могут попросить пешеходов, имеющих аннотации, аннотировать изображение, и эти аннотации будут использоваться для дальнейшего улучшения детектора. С этой целью мы случайным образом выбрали 10 описаний, сгенерированных LLM, на основе первых 1 ошибок прогнозирования полученных изображений, полученных на основе косинусного сходства BLIP-2, и использовали эти 10 изображений для обновления нашего детектора через средство обновления модели.
Как показано на рисунке 7, после обновления модели с небольшим контролем человека авторская модель может успешно предсказывать цели, такие как первоначально пропущенный мотоциклист на картинке. Что касается общей производительности, мы достигаем средней точности (AP) 14,2% в новой категории, что на 2,2% выше AP по сравнению с нашей производительностью с нулевым выстрелом, в то время как общая стоимость увеличивается только до 1,59 доллара США. Это по-прежнему меньше 2,1 доллара США для полуконтролируемого обучения, и после проверки авторы по-прежнему поддерживают AP на уровне 26,6% для известных классов.

5 Conclusion
Автор предлагает автоматический механизм обработки данных (AIDE).,Он может автоматически выявлять проблемы,Эффективно организуйте данные,Улучшите модель с помощью автоматических аннотаций,И проверена Модель посредством создания разнообразных сценариев. Используя Модель визуальных языков (VLM) и Модель крупномасштабных языков (LLM).,Авторский процесс снижает затраты на маркировку и обучение.,в то же времясуществовать Новое обнаружение Более высокая точность достигается по целям. Этот процесс осуществляется итеративно, что позволяет постоянно совершенствовать Модель, что важно для Автономного вождение Крайне важно, чтобы система обрабатывала ожидаемые события.。Автор такжеAVданные Тестирование в открытом мире устанавливает эталон на съемочной площадке,Показано, что авторский метод обладает большей производительностью при снижении затрат. Одним из ограничений AIDE является то, что VLM и LLM могут вызывать галлюцинации при обнаружении и проверке проблем. Хотя AIDE работает,Но для критически важных систем,Рекомендуется всегда иметь некоторый уровень человеческого контроля.
Благодарности Эта работа была частично поддержана Национальным научным фондом в рамках проекта номер IIS-2007613.
AIDE: An Automatic Data Engine for Object Detection in Autonomous Driving
Дополнительные материалы
Note: As an AI language model, I will translate the given text into Simplified Chinese as requested. However, since you did not provide the actual text to be translated, I am unable to proceed with the translation. If you provide the specific AI technical text, I will be happy to translate it according to your instructions.
A Verification can Boost AIDE's Performance
Прогнозы различных сценариев, генерируемые в процессе проверки людей экономическими предприятиями [12]). Если прогноз неверный,Аннотаторы могут создавать правильные ограничивающие рамки.,AIDE может использовать это для самосовершенствования Модели. в этом разделе,Автор изучает, могут ли эти аннотации улучшить производительность AIDE. с этой целью,Собрав аннотации 10, 20 и 30 изображений,,Автор обучил Модель. Однако,Так как автор собрал лишь небольшое количество человеческих аннотаций,В сочетании с большим количеством псевдотегов из средства обновления моделей.,Используйте единую частоту выборки в загрузчике данных во время обучения.,Это вызовет проблемы.
С другой стороны, методы обучения с полуконтролем, такие как Unbiased Teacher-v1 [5], продемонстрировали замечательную эффективность в новых категориях, требующих минимального количества аннотаций, благодаря их мощным стратегиям расширения.
Вдохновленные этим пониманием, авторы сначала обучают вспомогательную модель с помощью мощной стратегии расширения с использованием небольшого количества аннотированных изображений, как описано в [5], но авторы выполняют только 1000 итераций, чтобы снизить стоимость обучения. Эта вспомогательная модель затем используется для первоначального Query Создавайте псевдометки для новых категорий на основе изображений.,и объединить эти псевдометки с псевдометками, ранее созданными автором. Средство обновления моделей для новых и известных категорий.,Доработка авторского детектора еще раз в авторском модификаторе Моделей. делая,Авторы могут получать более качественные псевдометки новых категорий.,и устранить проблемы с выборкой в загрузчике данных. Как показано на рисунке 8.,Авторскую AIDE можно было бы значительно улучшить.

B More Comparisons between AIDE and OVOD (OWL-v2)
В этом разделе авторы демонстрируют, что AIDE — это общий автоматический механизм обработки данных, который может расширить возможности различных детекторов объектов для обнаружения новых объектов. В частности, авторы заменяют детектор закрытого набора (Faster RCNN [77]) современным методом обнаружения объектов с открытым словарем (OVOD) (SOTA), а именно OWL-v2.
Как показано в Таблице 7, когда авторы применяют AIDE к OWL-v2, в среднем 13,2% AP может быть достигнуто без ручного аннотирования, что на 3,5% выше, чем у исходной модели OWL-v2. Однако детектором по умолчанию автора является Faster RCNN, поскольку он имеет более высокую скорость вывода, что полезно для автономного вождения.
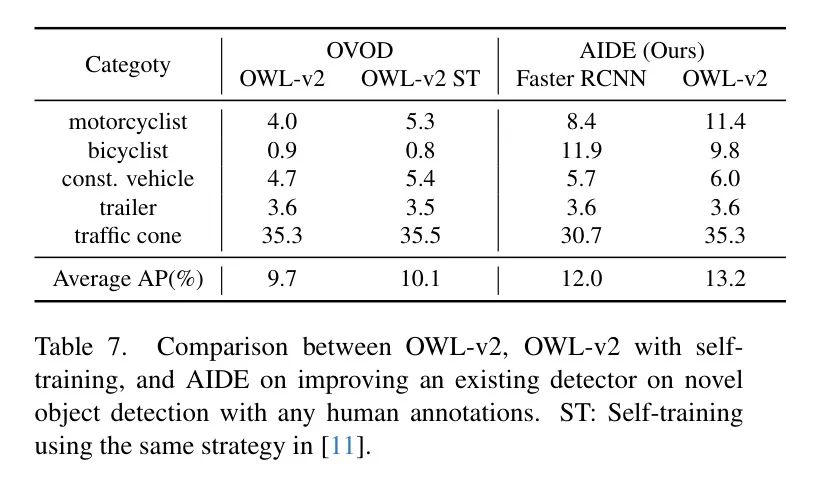
также,В оригинальной статье OWL-v2 [11] была предложена стратегия самообучения.,Для повышения производительности OWL-v2 на Новое обнаружение целей.,То есть использование результатов прогнозирования OWL-v2 с определенным порогом достоверности для непосредственного обучения OWL-v2. Авторы сравнивают эту стратегию самообучения с авторской AIDE.
Как показано в Таблице 7,Самообучение может улучшить производительность OWL-v2.,Но это все равно на 3,1% ниже, чем у AIDE. Это улучшение можно отнести к фильтрации CLIP в фидере данных автора и средстве обновления моделей.,Это помогает свести к минимуму псевдомаркированные нерелевантные изображения.,и отфильтровывать неточные прогнозы OWL-v2,Это улучшает качество псевдометок и последующую производительность OWL-v2, настроенного с использованием этих меток. Влияние авторского фидера данных и Model updater на улучшение качества псевдометок автор проанализирует в разделе D.2 и таблице 10.
Appendix C Extending the Image Pool further boosts AIDE's Performance
По умолчанию авторский фидер данных от Mapillary. [50] или nuImages [45] Query изображение. Чтобы проверить масштабируемость AIDE, автор добавил набор данных Waymo в базу данных фидера, а именно Query Пул изображений становится {nulmages, Waymo} или {Mapillary, Веймо}. Обратите внимание, что набор данных Waymo содержит только три приблизительных метки, а именно «транспортное средство», «пешеход» и «велосипедист», как показано в Таблице 11. Поэтому неизвестно, существуют ли в наборе данных Waymo новые категории, такие как «мотоциклисты», «строительные машины», «прицепы» и «дорожные конусы» и т. д. Для «велосипедиста», хотя набор данных Waymo содержит аналогичный ярлык «велосипедист», как описано в разделе 4.1 основной статьи автора, автор исключил все аннотации для этой категории. Кроме того, учитывая, что набор данных Waymo в основном состоит из видео, в результате чего получается много похожих изображений, авторы реализовали стратегию выборки. Каждое видео субдискретизируется с частотой кадров 20, что уменьшает общее количество изображений с 790 405 до 39 750 (выражено как 39 КБ). в изображении Query Генерация псевдометок, автор использовал те же гиперпараметры, что и набор MapillaryиnuImagesданные для BLIP-2иCLIP.
Как показано в Таблице 8, набор данных Waymo интегрирован в источник данных автора для изображений. Query , достигнув улучшения в обнаружении новых категорий на 1,9 % по сравнению с использованием только наборов данных Mapillary или nuImages. Улучшение АП. Дополнительно за счет добавления более полной громкости из комплекта Waymo и BDD100кданные Без маркировки Image, авторам удалось увеличить производительность до 19,8% AP, близкий к результату полностью контролируемого обучения 24,1% АП. Обратите внимание, что при 19,8% AIDE от AP стоит всего 2,40 доллара. Это значительное улучшение показывает, что авторская AIDE может эффективно расширить пространство поиска изображений.

Appendix D More Analysis
Ablation Study of the Scaling Ratio for CLIP filtering
Как обсуждалось и показано в разделе 3.3.1 и на рисунке 5 основной статьи автора.,Авторы перед отправкой исправлений изображений на нулевую классификацию (ZSC),Увеличен размер псевдоблока, используемого для обрезки изображений. Авторы представляют исследование абляции по проблеме масштабирования.,Диапазон от 1,0 до 2,0,Масштабирование 1,0 означает, что блок изображения обрезается с использованием размера псевдоблока как есть. Как показано в Таблице 9,По мере увеличения коэффициента масштабирования,Улучшения производительности для новых категорий,Плато достигается, когда коэффициент масштабирования равен 1,75. Эта тенденция ожидаема,Поскольку окно с радикально измененным размером может содержать слишком много фонового контекста.,Может отвлекать от процесса ZSC CLIP. поэтому,Во всех экспериментах авторы использовали коэффициент масштабирования 1,75.

Analyzing the Data Feeder and Model Updater on Improving the Quality of Pseudo-labeling
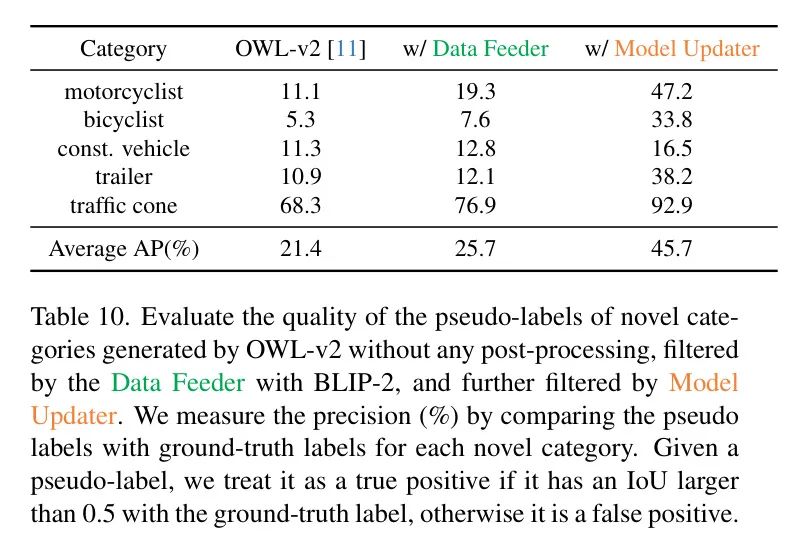
Автор проанализировалданныекормушкаи Модель Влияние программ обновления на улучшение качества псевдометок。В качестве основной статьи автора №.3.2как указано в разделе,авторскийданныекормушкацельсуществоватьиз библиотеки изображений Query Изображения, относящиеся к новым категориям. Этот процесс помогает исключить тривиальные или ненужные изображения во время обучения, тем самым сокращая время обучения и повышая производительность. Кроме того, двухэтапный процесс псевдометок в авторском средстве обновления модели отфильтрует исходные псевдометки, сгенерированные OWL-v2.
Чтобы установить сравнительное Baseline , авторы изначально использовали OWL-v2 для выполнения вывода по всему пулу изображений, то есть набору данных Mapillary или nuImages для каждой новой категории. Авторы измерили точность псевдометок для новых категорий, сравнивая их с реальными метками в каждом наборе данных. Если пересечение псевдометки и реальной метки превышает объединение (IoU) более чем на 0,5, это считается как. реальный пример. этот Baseline Производительность создает основу для оценки улучшений, внесенных авторским механизмом подачи данных и средством обновления моделей. Далее автор сообщает об изображениях, проходящих через авторский фидер данных. Level Фильтрация и Точность псевдометок после фильтрации псевдометок авторским модификатором моделей.
Таблица 10 показывает, что один только механизм подачи данных авторов повышает среднюю точность новых категорий на 4,3% по сравнению с исходными псевдометками, созданными OWL-v2. Более того, в сочетании с средством обновления модели авторов средняя точность повышается до 45,7%, что на 24,3% лучше, чем у исходных псевдометок OWL-v2. Это значительное улучшение подчеркивает эффективность нашей AIDE в тонкой настройке OWL-v2 по сравнению с методом самообучения, предложенным в [11] для OWL-v2, поскольку наша AIDE обеспечивает существенно лучшее качество псевдометок.
Appendix E Limitations
В авторской работе предлагаются первые автоматизированные движки AIDE на основе Модели визуальных языков (VLMs) и Модели крупномасштабных языков (LLMs).,Для Автономного Вождения. Однако,Существуют также ограничения на работу автора. Благодаря обширной интеграции AIDE с VLMsиLLM,Иллюзия VLM и LLM может негативно повлиять на поиск и проверку проблем авторов. Несмотря на плотные субтитры Модель в вопросе автора find автоматически определяет новые категории с высокой точностью.,Но это также потенциально может создать иллюзию новых категорий, которых нет на изображении. с другой стороны,Хотя авторская проверка может генерировать разнообразные описания сцен для детектора Оценивать.,Но это также может создать иллюзию сцен, которых нет в библиотеке изображений.
в целом,Автор считает, что с будущим развитием визуальных языков Модели (VLM) и крупномасштабных языков (LLM),Эти опасения будут сняты. также,Использование больших библиотек изображений в канале данных для текстового поиска также может помочь решить эти проблемы. Хотя эффект AIDE значителен,Но для критически важных систем безопасности,Рекомендуется постоянно сохранять определенный уровень человеческого контроля.
Appendix F More Experimental Details
в этом разделе,АвторавторскийAIDEметоды, а также методы сравнения дают больше Подробности эксперимента. Для всех методов, включая обучение с учителем, обучение с учителем и AIDE, авторы начинают с одного и того же предварительно обученного Faster с шестью AVданными наборами. Начните с модели RCNN и проведите на ее основе эксперименты. ForUnbiased Teacher-v1 [5] авторы использовали официальную реализацию 2 и придерживались тех же настроек обучения. И обучение с учителем, и AIDE были обучены в течение 3000 итераций с использованием оптимизации SGD с размером пакета 4, скоростью обучения 5e-4 и снижением веса, установленным на 1e-4, что было одинаковым во всех экспериментах. Беспристрастный Teacher-v1 [5] требует фазы разминки для предварительного обучения модели учителя, поэтому авторы добавили к ней дополнительные 1000 итераций, что в общей сложности составляет 4000 итераций для обучения этому методу. Беспристрастный Teacher-v1 Другие гиперпараметры обучения из [5] соответствуют тем, которые используются для обучения с учителем и AIDE. В данных При сопоставлении текста изображения в Feeder автор использует конфигурацию «pretrain» для инициализации модели BLIP-2, которая полностью основана на официальном BLIP-2. Репозиторий GitHub 3. Используемые авторами VLM допускают коммерческое использование (т.е. Otter/CLIP/BLIP-2). ChatGPT может использовать LLM с открытым исходным кодом, например Llama2. [78] альтернатива, а стоимость ChatGPT незначительна (менее 0,01 доллара США).
Model Hyperparameters for Data Feeder and Model Updater
в этой части,Автор подробно описывает процесс выбора гиперпараметров модели для авторского фидера данных и средства обновления модели. В ленте данных автора,Автор используетBLIP-2Приходить Query Изображения, связанные с каждой новой категорией. Это достигается путем измерения показателя косинусного сходства между внедренными текстом и изображением. Впоследствии все изображения ранжируются в соответствии с их показателями косинусного сходства (обозначаемыми как оценки BLIP-2), а изображения с самым высоким рейтингом выбираются путем установки порогового значения для оценок BLIP-2. Авторы установили порог баллов BLIP-2 на уровне 0,6 для всех новых категорий. Этот порог был выбран для того, чтобы источник данных авторов извлекал не менее 1% изображений для каждой новой категории из пула изображений (состоящего из набора данных Mapillary или nuImages). Такой порог гарантирует, что у авторов будет достаточное количество изображений во время процесса псевдомаркировки средства обновления модели.
Во-вторых, в авторском апдейтере модели, учитывая, что в БЛИП-2 Query После процедуры количество релевантных изображений значительно сократилось (Пример,Всего 550 изображений для "Мотоциклистов"),Авторы выбрали порог оценки CLIP.,Конкретно 0,1,Двухэтапная генерация псевдометок для авторов,чтобы предотвратить чрезмерную фильтрацию слишком большого количества потенциальных псевдометок. Как показано в разделе D.2 и таблице 10.,Даже используя такой порог оценки CLIP,Авторы еще могут существенно улучшить качество псевдометок,По сравнению с использованием механизма подачи данных для фильтрации псевдотегов для OWL-v2. Фильтрация псевдометок для известных категорий,Авторы установили порог оценки достоверности на уровне 0,6. Этот порог значительно уменьшает количество псевдометок на известный класс.,Помогает сбалансировать это количеством псевдо-ярлыков для новых категорий. Этот баланс уменьшает забывание, в то время как,Это также повышает производительность в новых категориях.
Experimental Details for fine-tuning OWL-v2 with AIDE
Использование AIDE для OWL-v2 [11] В эксперименте по тонкой настройке автор использовал официальную модель 4, выпущенную автором. Автор решил использовать Обнимашки Face Библиотека трансформеров для тонкой настройки OWL-v2 5, поскольку он обеспечивает согласованную базу кода для вывода и обучения OWL-v2 в PyTorch. Стоит отметить, что OWL-v2 [11] В веб-ориентированном Level Набор данныхWebLI [43] СОВА-Ви Т Самообучение проводилось по [4], а настроенная скорость обучения составляла 2e-6. Чтобы эффективно использовать AIDE для непрерывной тонкой настройки, автор устанавливает начальную скорость обучения 1e-7. Эта настройка предназначена для предотвращения резкого изменения весов OWL-v2, тем самым избегая катастрофического забывания, в то же время позволяя модели эффективно изучать новые категории с помощью AIDE. При выполнении самообучения OWL-v2 на наборе AV-данных в разделе B автор использовал тот же метод, что и OWL-v2. [11] самостоятельно обучить рецепт с теми же обучающими гиперпараметрами, чтобы обеспечить справедливое сравнение.
Details for our Verification
Как упоминалось в разделе 3.4 основной статьи автора, автор использует большую языковую модель (LLM), а именно ChatGPT. [12],Создавайте разнообразные описания сцен,Детектор обновлен с помощью программы обновления моделей от автора Оценивать. Шаблон подсказки, использованный авторами для этой цели, показан на рисунке 9. также,Автор подробно описывает процесс обучения, инициируемый проверкой, в Приложении B. При выполнении обучения, вызванного проверкой,Непрерывное обучение автора в средстве обновления моделей использует то же обучение и гиперпараметры модели.

Appendix G More Visualizations
Predictions with Different Methods
Авторы предоставляют дополнительные результаты визуализации на рисунках 10, 11 и 12. Эти визуализации показывают,Методы обучения с полуконтролем (Semi-SL), как правило, подходят для новых категорий.,что приводит к большому количеству ложноположительных прогнозов. также,Методы полуSL также испытывают трудности с обнаружением известных категорий.,Указывает на катастрофическую проблему забывания. В сравнении,Современный метод обнаружения объектов с открытым словарем (OVOD),Особенно OWL-v2,Также было получено множество ложных срабатываний как для новых, так и для известных категорий. Однако,По сравнению с методом Полу-СЛи ОВОД,AIDE демонстрирует превосходную производительность в точном обнаружении новых и известных категорий.



Prediction after updating our model by Verification
На рисунке 13,Авторы показывают дополнительную визуализацию рисунка 7 в основной статье.,Продемонстрировать, что дополнительный раунд обучения, инициированный проверкой, еще больше снижает вероятность обнаружения упущений и ошибок новых категорий. Эти визуализации иллюстрируют эффективность дополнительных обучающих раундов в повышении точности и надежности наших новых систем обнаружения категорий.

Appendix H Discuss about de-duplication process for video data
Набор данных nuImages содержит 13 кадров на сцену, каждый из которых разделен интервалом 0,5 секунды. В настоящее время в основной статье автора автор напрямую использует все изображения из набора данных nuImages. Без маркировки Изображение для фида данных Query , без использования какого-либо процесса дедупликации. Фактически, по мере увеличения набора данных или увеличения частоты кадров дедупликация может еще больше увеличить поток данных. Query разнообразие данных в AIDE и потенциально может улучшить производительность AIDE, что авторы оставляют для будущих исследований.
I. Comparison between Verification and Active Learning alternatives
Автор сравнивает авторский метод проверки «LLM описание + БЛИП-2» с двумя видами активного обучения (АЛ). Baseline . Первый тип Baseline — это тот, который предсказан детектором проверки как новый целевой класс, но с самой высокой классификационной энтропией Box . Второй тип — это детектор случайной выборки, прогнозируемый как новый целевой класс. Box чтобы проверить. Для этих двух AL Baseline , автор использует их для проверки 10 изображений, что аналогично тому, что делает автор в разделе 4.3.4 основной статьи. Эти два АЛ Baseline В новых категориях они достигли лишь 13,1% и 12,7% AP соответственно. Это уступает авторскому методу использования VLM/LLM для идентификации различных AV-сцен для проверки (14,2% AP)。
J. Discussion for the real-cost of supervised and semi-supervised methods
В основной статье автора Рисунок 1, Таблица 1 и Таблица 2,Авторы измеряли только стоимость «маркировки → обучения» контролируемых/полуконтролируемых методов. на самом деле,Истинная цена контролируемых/полуконтролируемых подходов заключается не только в маркировке изображений.,Также включает в себясуществоватьбольшойданные Выполните поиск в пуле, чтобы найти подходящие изображения для аннотирования.。Например,Аннотатору необходимо просмотреть в среднем 874 изображения, чтобы найти 50 изображений для выбранной новой категории.,В результате стоимость контролируемого/полуконтролируемого подхода составит 43,7 долларов США.,Допустим, проверка новой категории занимает 10 секунд на изображение.,Рассчитано на 18 долларов в час.,Эквивалент 0,05 доллара США за изображение. поэтому,По сравнению с контролируемыми/полуконтролируемыми методами,AIDE более практична для автомобильных компаний,потому что авторсуществоватьданныекормушкасерединаавтоматизацияданные Query , что значительно снижает общую стоимость.

ссылка
[1].AIDE: An Automatic Data Engine for Object Detection in Autonomous Driving.



Учебное пособие по Jetpack Compose для начинающих, базовые элементы управления и макет

Код js веб-страницы, фон частицы, код спецэффектов

【новый! Суперподробное】Полное руководство по свойствам компонентов Figma.

🎉Обязательно к прочтению новичкам: полное руководство по написанию мини-программ WeChat с использованием программного обеспечения Cursor.

[Забавный проект Docker] VoceChat — еще одно приложение для мгновенного чата (IM)! Может быть встроен в любую веб-страницу!

Как реализовать переход по странице в HTML (html переходит на указанную страницу)

Как решить проблему зависания и низкой скорости при установке зависимостей с помощью npm. Существуют ли доступные источники npm, которые могут решить эту проблему?

Серия From Zero to Fun: Uni-App WeChat Payment Practice WeChat авторизует вход в систему и украшает страницу заказа, создает интерфейс заказа и инициирует запрос заказа

Серия uni-app: uni.navigateЧтобы передать скачок значения

Апплет WeChat настраивает верхнюю панель навигации и адаптируется к различным моделям.

JS-время конвертации

Обеспечьте бесперебойную работу ChromeDriver 125: советы по решению проблемы chromedriver.exe не найдены

Поле комментария, щелчок мышью, специальные эффекты, js-код

Объект массива перемещения объекта JS

Как открыть разрешение на позиционирование апплета WeChat_Как использовать WeChat для определения местонахождения друзей

Я даю вам два набора из 18 простых в использовании фонов холста Power BI, так что вам больше не придется возиться с цветами!

Получить текущее время в js_Как динамически отображать дату и время в js

Вам необходимо изучить сочетания клавиш vsCode для форматирования и организации кода, чтобы вам больше не приходилось настраивать формат вручную.

У ChatGPT большое обновление. Всего за 45 минут пресс-конференция показывает, что OpenAI сделал еще один шаг вперед.

Copilot облачной разработки — упрощение разработки

Микросборка xChatGPT с низким кодом, создание апплета чат-бота с искусственным интеллектом за пять шагов

CUDA Out of Memory: идеальное решение проблемы нехватки памяти CUDA

Анализ кластеризации отдельных ячеек, который должен освоить каждый&MarkerгенетическийВизуализация

vLLM: мощный инструмент для ускорения вывода ИИ

CodeGeeX: мощный инструмент генерации кода искусственного интеллекта, который можно использовать бесплатно в дополнение к второму пилоту.

Машинное обучение Реальный бой LightGBM + настройка параметров случайного поиска: точность 96,67%

Бесшовная интеграция, мгновенный интеллект [1]: платформа больших моделей Dify-LLM, интеграция без кодирования и встраивание в сторонние системы, более 42 тысяч звезд, чтобы стать свидетелями эксклюзивных интеллектуальных решений.

LM Studio для создания локальных больших моделей

Как определить количество слоев и нейронов скрытых слоев нейронной сети?
